back to index
ML Lecture 21-2: Recurrent Neural Network (Part II)
link |
讓大家久等,好,那我們就用旁邊的附木來講,因為中間的,呃,主木不知道為什麼放不出來,那我們上次呢,講到LSTM,總之就是一個複雜的東西,好,那再來的問題是,像recurrent neural network這種架構,它要如何做learning呢,我們之前有說過說,如果要做learning的話,你要定一個cost的function。
link |
來evaluate你的model的parameter是好還是不好,然後你選一個model的parameter,可以讓這個loss增小,那在recurrent neural network裡面,你會怎麼定這個loss呢,以下呢,我們就不寫算式,直接舉個例子,假設我們現在要做的事情呢,是slot theory,那你會有training data,
link |
這個training data是說,給你一些sentence,這個它是,呃,它的光是有的,要這麼近才有,好,我想放在這邊,其實是有的,好,那個,呃,
link |
其實我自己,我沒有辦法看到那個pointer的投影在螢幕上的光點,欸,你要嗎,如果,謝謝,謝謝,謝謝,謝謝,謝謝,太感謝了,好,呃,這個是sentence,ok,
link |
然後呢,你要給sentence的label告訴machine說呢,這個第一個word,它屬於other這個slot,然後台北屬於destination這個slot,它屬於other的slot,member跟second都屬於這個出發,呃,目的地,呃,要抵達時間的slot,然後接下來呢,你希望說,你的cost會怎麼定呢,
link |
把arrive丟到recurrent neural network的時候,recurrent neural network會得到一個output y1,接下來呢,這個y1呢,會和一個reference的vector算它的cost entropy,所以你會希望說,如果我們現在丟進去的是arrive,
link |
那y1,它的reference的vector呢,應該是對應到other那個slot的dimension,value是1,其他是0,這個reference的vector的長度啊,就是你slot的數目,比如說你訂了40個slot,那這個reference vector的長度呢,它的dimension就是40,
link |
那假設現在input的這個word呢,它應該對應到other這個slot的話,那對應到other的dimension就是1,其他的就是0,那現在你把台北丟進去的時候,因為台北屬於destination這個slot,
link |
所以你就希望說把x2丟進去的時候,y2它要跟reference的vector距離越近越好,那y2的reference vector是對應到destination那個slot是1,其他是0,那這邊要注意的事情是,你在丟x2之前,一定要先丟x1,
link |
你在把台北丟進去之前,你一定要先把arrive丟進去,不然你就會不知道存在memory裡面的是多少,所以在做training的時候呢,你也不能夠把你的alternates裡面的這些word呢,
link |
這個word sequence呢,打散來看,word sequence呢,仍然要當這個整體來看,同樣道理,把on丟進去,它的reference vector呢,是對應到other是1,對應到other那個dimension是1,其他是0,
link |
所以你的cost就是每一個時間點的on的output跟reference vector的cross-entropy的合,就是你要去minimize的對象,那現在有了這個loss function以後,training要怎麼做呢?
link |
training呢,其實也是用gradient descent,也就是說,如果我們現在已經定出了loss function大L,我要update這個network裡面的某一個參數w,我要怎麼做呢?
link |
你就計算w對大L的片尾分,這個片尾分計算出來以後,就用gradient descent的方法呢,去update每一個參數,那我們之前在講neural network的時候呢,已經講過很多次了,
link |
那在講這個之前的那個v-forward network的時候,我們說gradient descent用在v-forward network裡面,你要用一個比較有效的演算法叫做backpropagation,在recurrent neural network裡面,gradient descent的原理是一模一樣的,
link |
但是為了要計算方便,所以呢,也有開發一套演算法,這套演算法呢,是backpropagation的進階版,它叫做BPTT,那它跟backpropagation其實是很類似的,
link |
只是因為recurrent neural network它是在time sequence上面做運作,所以BPTT呢,它需要考慮時間的information,那我們在這邊呢,我們就不講BPTT,
link |
反正你只要知道說RNN就是用gradient descent train的,它是可以train的就行了。
link |
然而不幸的就是呢,RNN的training呢,是比較困難的。
link |
一般而言呢,你在做training的時候,你會期待你的這個learning curve呢,是像藍色這一條線,我這邊的這個縱軸呢,是total loss,
link |
這個橫軸呢,是APOC training的時候的APOC的數目,你會希望說呢,隨著APOC越來越多,隨著參數不斷的被update,
link |
Loss呢,應該就是慢慢慢慢的下降,最後趨向收斂。
link |
但是不幸的是,當你在訓練這個recurrent neural network的時候,你有時候會看到綠色這一條線,綠色這一條線。
link |
而這個很重要,如果你是第一次train recurrent neural network,你看到綠色的這樣子的這個learning curve,
link |
這個learning curve呢,非常劇烈的走動,然後走到某個地方,就突然NAN,然後你的程式就segmentation fault了。
link |
而這個時候,你會有什麼想法呢?我相信你的第一個想法就是,程式有bug啊,程式有bug。
link |
好,這個,今年的春天呢,我要那個Thomas Mikolov來台灣,Thomas Mikolov就是發明那個workback的人,
link |
之前說講過了,然後他跟我分享了他當時開發RNN的心得,
link |
他是最早開始做RNN的learning model的人,大概在09年的時候呢,就開始做了。
link |
而有很長一段時間呢,只有他能夠把RNN的learning modeltrain起來,其他人呢,都train不起來。
link |
好,那,他說他,你知道在那個年代,那個年代是沒有像現在有什麼Tensorflow啊DLL之類的,
link |
那個年代做什麼東西呢,都是要徒手刻的,所以他徒手刻了一個RNN,然後train完以後,就發生這樣的現象。
link |
他第一個想法就是,程式有bug,程式有bug,然後努力的抵了bug以後,果然有很多bug。
link |
然後就把所有,但是他後來就把bug修掉,修掉,他覺得應該是沒有bug,但是這個現象還是在,
link |
所以他就覺得很困惑,而其他人就跟他說,放棄啦,放棄啦,這不work這樣子。
link |
他說,嗯,可是我想要,他就想說,他要知道結果,為什麼會這樣,所以他就做分析。
link |
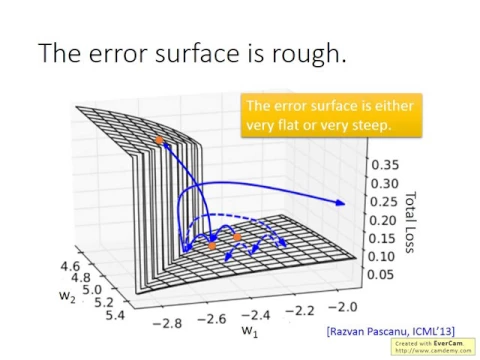
等一下這個圖是來自於他的paper,他分析了一下RNN的性質,他發現說呢,
link |
RNN的error surface,所謂error surface是total loss,對參數的變化是非常的陡峭,
link |
非常崎嶇的,所謂的崎嶇的意思是說,這個error surface,他有一些地方非常平坦,有一些地方非常的陡峭,
link |
所以,底下這是一個,這邊這個通篇上是一個示意圖,縱軸呢,是total loss。
link |
那這個x軸跟y軸呢,代表兩個參數,w1和w2,這個圖上顯示的就是w1、w2這兩個參數,
link |
對total loss的影響,發現說呢,在很多地方都是非常平坦,在某些地方呢,非常的陡峭。
link |
假設你從橙色這個點,當作你的初始的點,用gradient descent開始調整你的參數,
link |
在橙色這個點,你算一下gradient,然後呢,update你的參數,就調到下一個橙色的點。
link |
再算一下gradient,再update你的參數,你可能正好就跳過一個懸崖,
link |
所以你的loss loss呢,就突然暴增,你會看到那個loss呢,上下非常劇烈的震盪。
link |
有時候可能會遇到另外一個更慘的狀況,就是你正好就踩一腳踩在這個懸崖上,正好一腳踩在懸崖上。
link |
那你踩在懸崖上會發生什麼事情呢?你踩在懸崖上,因為在懸崖上的gradient呢,很大。
link |
然後呢,之前的gradient都很小,所以你措手不及,因為之前的gradient很小,所以你可能把learning rate調得比較大。
link |
但是gradient突然很大,很大的gradient再乘上很大的learning rate,結果參數呢,就update很多,然後整個參數呢,就飛出去了。
link |
所以你就按了an,所以程式呢,就segmentation fault。
link |
然後Thomas de Colombe就想說,怎麼辦呢?怎麼辦?他說他不是一個數學家,所以他要用工程師的想法來解決這個問題。
link |
然後他就想了一招,這一招呢,應該是蠻關鍵的,讓很長一段時間,只有他的code呢,可以把RN的learning model傳出來。
link |
那很長一段時間呢,人們是不知道這一招的,因為這一招他覺得實在是太沒什麼,所以沒寫在paper裡面,直到他在寫那個博士論文的時候,那博士論文是比較長的。
link |
所以有些東西就算你覺得trivial,很可能還是會寫進去,直到他在寫博士論文的時候,大家才發現了這個秘密。
link |
這個秘密是什麼呢?這一招呢,說穿了就不值錢,這一招呢,叫做creeping。
link |
creeping的意思是說,當gradient大於某一個threshold的時候,就不要讓它超過那個threshold。
link |
在Thomas Percona的程式裡面,我記得就是,當gradient大於threshold的時候,就等於threshold結束。
link |
好,所以因為gradient現在不會太大,所以當你做creeping的時候,就算是踩在這個懸崖上,也沒有關係,你的參數呢,就不會飛出去。
link |
它會飛到一個比較近的地方,這樣你仍然可以繼續做RN的training。
link |
有人就會問這個,那在接下來的問題就是,為什麼RN會有這種奇特的特性呢?
link |
有人說,有人可能會說,是不是因為來自於sigmoid function,我們之前有講過,在講IELU的exclamation function的時候呢,
link |
我們講過一個問題,叫做gradient vanishing的問題,然後我們說這個問題是從sigmoid function來的,
link |
因為sigmoid的關係,所以有gradient vanishing這個問題,就是說RN會有這種很小的,很平滑的arrow surface,
link |
是因為來自於gradient vanishing,是因為來自於sigmoid function。
link |
這件事情呢,我覺得不是真的,你想想看,如果這個問題是來自於sigmoid function,換成IELU就解決這個問題啊,
link |
所以不是這個問題。可以跟大家講一個秘密,如果你用IELU,你會發現說呢,一般在chain neural network的時候呢,
link |
很少用IELU當作exclamation function,為什麼呢?因為如果你把sigmoid換成IELU,
link |
其實在RN上面performance通常是比較差的,所以exclamation function並不是這個地方的關鍵點。
link |
並不是這個地方的關鍵點。好,那如果說我們今天有講這個backpropagation through time的話,
link |
從式子裡面呢,你會比較容易看出說為什麼會有這個問題。
link |
那我今天沒有講backpropagation through time,沒有關係,我們有一個更直觀的方法可以來知道說一個gradient的大小是什麼樣子。
link |
這個更直觀的方法就是你把某一個參數做小小的變化,看它對network output的變化有多大,
link |
你就可以測出這個參數的gradient的大小。我們這邊呢,舉一個很簡單的RN當作我們的例子。
link |
今天有一個全世界最簡單的RN,它只有一個neural,這個neural是linear,它只有一個input,沒有bias,
link |
input的weight是1,output的weight也是1,那transition的部分呢,transition的部分的weight是W,
link |
也就是從memory接到neural的input的weight是W。
link |
好,現在假設我給這個network的輸入是100000,只有第一個時間點輸入,
link |
1000大家都輸入0,那這個network的output會長什麼樣子呢?
link |
比如說這個network在最後一個時間點,1000個時間點的output,值會是多少?
link |
我相信大家都可以馬上回答我,它的值呢,是W的999次方,對吧?
link |
你把1輸進去,再乘上W,乘上W,乘上W,乘上999次W,輸出就是W的999次方,
link |
後面的輸入都是0嘛,非常貴,只有一開始的1有影響,但是它會通過999次的W。
link |
好,那我們現在來看,假設W是我們要認的參數,我們想要知道它的gradient,
link |
所以我們想要知道當我們改變W的值的時候,對network的output有多大的影響。
link |
現在我們假設W等於1,那Y1000,連我的最後時間點的output也是1。
link |
假設W等於1.01,那Y1000是多少呢?
link |
Y1000是1.01的999次方,1.01的999次方是多少呢?
link |
是2萬,是一個很大的值,這個就跟蝴蝶效應一樣。
link |
而這個W呢,有一點小小的變化,對它的output影響呢,是非常大的。
link |
那可能想說有很大的規定,也沒有什麼,我們只要把它的learning rate設小一點就好。
link |
但是事實上,如果我把W設成0.99,那Y1000呢,就等於1。
link |
如果我把W呢,設0.01,那Y1000還是等於1。
link |
也就是說,在1這個地方,有很大的gradient,但是在0.99的地方,gradient呢,就突然變得非常非常的小。
link |
這個時候,你又需要一個很大的learning rate,就會造成說你設learning rate很麻煩,你的error service很崎嶇。
link |
因為這個gradient呢,是時大時小,而且在非常短的區域之內,gradient就會有很大的變化。
link |
所以從這個例子,其實你可以看出來說,為什麼RNN會有問題。
link |
RNN的training的問題,其實是來自於它把同樣的東西呢,在transition的時候呢,在時間和時間轉換的時候呢,反覆使用。
link |
從memory接到neuron的那一組位,在不同的時間點,都是反覆被使用。
link |
所以這個W呢,只要一有變化,它有可能完全沒有造成任何影響。
link |
但一旦它可以造成影響,那影響都會是天崩地裂的影響。
link |
所以它有時候gradient很大,有時候gradient很小。
link |
所以這個RNN會不好訓練的原因,並不是來自於activation function,而是來自於它有time sequence,
link |
同樣的位在不同的時間點,是會被反覆的,不斷的被使用。
link |
好,那有什麼樣的技巧可以幫助我們解決這個問題呢?
link |
其實現在最廣泛被使用的技巧呢,就是LSTM。
link |
那LSTM呢,可以讓你的error surface不要那麼崎嶇。
link |
它可以做到的事情是,它會把那些比較平坦的地方拿掉。
link |
它可以解決gradient vanishing的問題,但它不會解決gradient explode的問題,
link |
因為你有些地方仍然是會非常的崎嶇的。
link |
你有些地方它仍然是變化非常劇烈的,但是呢,不會有特別平坦的地方。
link |
因為如果你在做LSTM的時候,大部分的地方都變化很劇烈,
link |
所以呢,當你在做這個LSTM的時候呢,你可以放心的把你的learning rate設的小一點。
link |
那它呢,要在learning rate特別小的情況下呢,進行訓練。
link |
那為什麼LSTM可以做到這個handle gradient vanishing的問題呢?
link |
為什麼它可以避免讓gradient特別小呢?
link |
我聽說有人在這個面試某家國際大廠的時候,就被問這個問題。
link |
那個問題是這樣,為什麼我們把RNN換成LSTM?
link |
如果你的答案是,喔,因為LSTM比較吵,因為LSTM比較複雜,
link |
那真正的理由就是,LSTM可以handle gradient vanishing的問題。
link |
但是接下來人家就會問說,為什麼LSTM可以handle gradient vanishing的問題呢?
link |
那這樣子之後如果有人,你口測的時候再問到這個問題的時候呢,
link |
這個如果你想看RNN跟LSTM,他們在面對memory的時候,
link |
他們處理的operation其實是不一樣的,對不對?
link |
你想想看在RNN裡面,在每一個時間點,其實memory裡面的資訊都會被洗掉。
link |
在每一個時間點,neural的output都會被放到memory裡面去,
link |
所以每一個在每一個時間點memory裡面的資訊呢,都會被覆蓋掉,都會被完全洗掉。
link |
它是把原來memory裡面的值乘上一個值,再把input的值呢,
link |
所以它的memory和input是相加的。
link |
所以今天呢,它和RNN不同的地方是,
link |
如果今天你的wait可以影響到memory裡面的值的話,
link |
一旦發生影響,這個影響會永遠都存在。
link |
不像RNN在每一個時間點,值都會被format掉,
link |
所以只要這個影響一被format掉,它就消失了。
link |
但是在LSTM裡面,一旦能夠對memory造成影響,
link |
那個影響會永遠的留著,除非forget gate被使用,
link |
除非forget gate決定要把memory裡面的值洗掉,
link |
不然一旦memory有改變的時候,每一次都只會有新的東西加進來,
link |
而不會把原來存在memory裡面的值洗掉。
link |
所以它不會有灰點vanishing的問題。
link |
你可能會想說,可是現在有forget gate啊,
link |
forget gate就是會把過去存的值洗掉啊。
link |
事實上在LSTM97年的時候就compose了,
link |
那LSTM的第一個版本,其實就是為了解決灰點vanishing的問題,
link |
所以它是沒有forget gate的,forget gate是後來才加上去的。
link |
甚至呢,現在有一個傳言是,你在訓練LSTM的時候,
link |
你要給forget gate特別大的byte,
link |
你要確保forget gate在多數的情況下都是開啟的,
link |
現在有另外一個版本用gate操控memory的Cell,
link |
叫做gated recurrent unit,LSTM有三個gate,
link |
這個gated recurrent unit它只有兩個gate,
link |
所以gated recurrent unit寫是GRU,
link |
相較於LSTM它的gate只有兩個。
link |
所以它在training的時候是比較robust的。
link |
所以如果你今天try train LSTM的時候,
link |
你覺得overfitting的情況很嚴重,
link |
那GRU的精神就是,它怎麼拿掉一個gate呢?
link |
它會把input gate跟forget gate連動起來,
link |
它會把input gate跟forget gate連動起來。
link |
那也就是說,當input gate被打開的時候,
link |
forget gate就會自動的關閉,
link |
當input gate被打開的時候,
link |
forget gate就會format存在memory裡面的值。
link |
當forget gate沒有要format值的時候,
link |
也就是說你要把存在memory裡面的值清掉,
link |
其實還有很多其他的technique,
link |
是來handle gradient vanishing這個問題。
link |
或者是structural constraint recurrent level SDRN等等。
link |
我就把reference留在這邊給大家參考。
link |
他用identity的matrix來initialize,
link |
transition的weight,
link |
然後再使用IOU的acclimation function的時候,
link |
他可以得到很好的performance。
link |
可能說我剛才不是說用IOU的performance會比較差嗎?
link |
如果你是一般的training的方法,
link |
你initialization的weight是random的話呢,
link |
那IOU跟sigmoid function來比的話,
link |
sigmoid function的performance會比較好。
link |
但是如果你今天用了identity的matrix的話,
link |
如果你今天用identity的matrix當做initialization的話,
link |
這個時候用IOU的performance就會比較好。
link |
他performance就可以屌打原來的LSDN。
link |
那其實RNN有很多的application,
link |
在我們前面舉的slot feeding的例子裡面,
link |
我們是假設input和output element的數目是一樣做的。
link |
我們就給每一個word一個slot的label。
link |
比如說input只是一個sequence, output只是一個vector。
link |
比如說你可以做sentiment analysis,
link |
sentiment analysis現在有很多的application,
link |
是positive還是negative,
link |
跟他們產品有關係的那些網路上的文章都爬下來。
link |
所以你可以用一個machine learning的方法,
link |
自動認一個classifier去分類說,
link |
sentiment analysis做的事情,
link |
怎麼讓machine做到這件事情呢?
link |
你就是認一個recurrent neural network,
link |
這個input是一個character sequence,
link |
然後recurrent neural network把這個character sequence讀過一遍。
link |
然後你就可以得到最後的sentiment analysis的prediction。
link |
比如說input這個document,
link |
它是超好雷,好雷,負雷,還是超負雷。
link |
但是input是一個sequence,
link |
所以你需要用RNN來處理這個input。
link |
用RNN來做pattern extraction,
link |
所謂pattern extraction的意思是說,
link |
然後machine要predict說,
link |
然後跟我們在final project裡面的第三個test,
link |
如果你今天能夠收集到一堆training data,
link |
然後這些document都有label說,
link |
哪些詞彙是它對應的keyword的話,
link |
那你就可以直接train一個RNN。
link |
這個RNN把document當作input,
link |
把document的word sequence當作input,
link |
然後通過embedding layer,
link |
然後用RNN把這個document讀過一次,
link |
然後把出現在最後一個時間點的output,
link |
我們發現我們沒有講過attention是什麼,
link |
你可以把重要的information抽出來,
link |
再丟到p4 network裡面去得到最後的output。
link |
比如說當你的input和output都是sequence,
link |
但是output的sequence比input sequence短的時候,
link |
什麼樣的任務是input sequence長,
link |
output sequence短呢?
link |
input是一串acoustic feature sequence,
link |
它的output是character的sequence。
link |
用我們在做slot feeding的那個R文,
link |
所有可能的中文的character,
link |
每一個vector屬於一個character,
link |
每一個vector屬於一個character。
link |
input的這個每一個vector,
link |
因為它就沒有辦法辨識好棒棒,這樣子。
link |
我們不要不只是output所有中文的character,
link |
acoustic feature sequence,
link |
如果我們輸入另外一個sequence,
link |
你手上的training data,
link |
這一串acoustic feature,
link |
對應到這一串character sequence,
link |
這個sequence對應到這個sequence,
link |
好是對應第幾個friend到第幾個friend,
link |
我們不知道好對應到哪幾個friend,
link |
全部都當作是正確的一起去training,
link |
你的RNN的output的target,
link |
如果到那個字和字之間的boundary,
link |
第一個frame就output h,
link |
第二個frame就output no,
link |
第三個frame就output no,
link |
第四個frame就output i,
link |
第五個frame就output s,
link |
那如果你看到output是這個樣子的話,
link |
Machine透過training data,
link |
從來在training data裡面沒有出現過,
link |
叫做Sequence to Sequence Layer,
link |
在Sequence to Sequence Layer裡面,
link |
來做machine translation,
link |
比如說,我們現在要做的是machine translation,
link |
the word sequence,
link |
要把它翻成中文的character sequence。
link |
現在假如input是machine learning,
link |
那我們就把machine learning用RNN讀過去,
link |
把machine learning呢,
link |
就存了所有input的整個sequence的information。
link |
你就讓machine to一個character,
link |
你把machine learning,
link |
然後再讓他output character,
link |
再叫他output下一個character,
link |
你把之前output出來的character呢,
link |
output所有可能的character,
link |
他還有一個可能的output叫做段。
link |
acoustic feature sequence,
link |
character sequence。
link |
還不是state-of-the-art的結果。
link |
但讓人真的surprise的地方就是,
link |
已經可以達到state-of-the-art的結果。
link |
所以是周前放在Rx上面的paper。
link |
sequence-to-sequence learning,
link |
看它能不能夠output正確的中文。
link |
可以直接input一串法文的聲音訊號,
link |
如果你今天在collect translation training data的時候,
link |
所以你要找人來label台語的文字,
link |
未來你在訓練台語轉英文的語音辨識系統的時候,
link |
另外現在還可以用sequence to sequence的技術,
link |
甚至可以做到beyond sequence,
link |
也被用在syntactic的parsing tree裡面,
link |
用在產生syntactic的parsing tree上面,
link |
這個syntactic的parsing tree是什麼呢?
link |
意思就是讓machine開一個句子,
link |
然後它要得到這個句子的文法的結構樹,
link |
要怎麼讓machine得到這樣子的樹狀的結構呢?
link |
過去你可能要用structure learning的技術,
link |
但現在有了sequence to sequence learning的技術以後,
link |
你只要把這個樹狀圖描述成一個sequence,
link |
比如說樹狀圖怎麼描述成sequence,
link |
當然可以描述成一個sequence,
link |
NP,NP下面有DPC跟NNP等等,
link |
所以如果今天是sequence to sequence learning的話,
link |
你就直接run一個sequence to sequence的model,
link |
它的output直接是syntactic的發進去,
link |
它直接output這個是syntactic的發進去,
link |
你可能覺得說這樣真的train得起來嗎?
link |
很surprise,非常surprise,
link |
如果我們訓練今天它長出來的output sequence,
link |
往往會用backword這樣的方法,
link |
但當我們用backword這樣的方法的時候呢,
link |
我們就會忽略掉這個word order的information,
link |
有一個word sequence是,
link |
destroyed an infection,
link |
另外一個word sequence是infection,
link |
destroyed white blood cell,
link |
但是如果你用backword來描述它的話,
link |
但是因為這個詞彙的order是不一樣的,
link |
那我們可以用sequence to sequence,
link |
來在有考慮word sequence的order的情況下,
link |
把一個document變成一個vector。
link |
我們就input一個word sequence,
link |
she didn't find any food,
link |
然後通過一個recurrent neural network,
link |
把它變成一個embedded vector,
link |
然後再把這個embedded vector,
link |
recurrent neural network,
link |
那encoding的這個vector,
link |
就代表了這個input sequence裡面,
link |
才能夠根據這個encoder的vector,
link |
你train這個sequence to sequence,
link |
那這個sequence to sequence,
link |
如果是用sequence to sequence,
link |
input跟output都是同一個句子。
link |
如果你用sequence to sequence,
link |
Mary was hungry得到一個vector,
link |
She didn't find any food得到一個vector,
link |
high level的vector,
link |
再根據每一個sentence的vector,
link |
sentence的sequence,
link |
再變成document level的東西,
link |
再解回sentence的sequence,
link |
sequence是sequence的auto-encoder,
link |
把它變成一個fixed length的vector,
link |
我稱之為audio的word vector,
link |
它是把一個word變成一個vector,
link |
可能你有一個聲音的database,
link |
machine就可以從database裡面,
link |
你就先把,也有一個audio的database,
link |
做segmentation,切成一段一段,
link |
這個audio segment to vector的技術呢,
link |
透過audio segment to vector的技術呢,
link |
怎麼把一個audio的segment,
link |
抽成acoustic feature sequence,
link |
把它存在recurrent neural network裡面去,
link |
而這個recurrent neural network呢,
link |
而這個recurrent neural network,
link |
它讀過這個acoustic feature sequence以後,
link |
它存在memory裡面的值是一個vector,
link |
代表是一整段聲音訊號的vector。
link |
你要同時呢,還要train一個Rn的decoder。
link |
就是它把encoder存在memory裡面的值呢,
link |
然後產生一個acoustic feature sequence。
link |
它們只有一個人,是沒有辦法train。
link |
可以一路從這邊的backup給回來,
link |
你就可以同時trainRn的encoder,
link |
這個sequence to sequence encoder技術呢,
link |
它們的這個word vector的變化呢,
link |
就好像我們之前看到的文字的word vector一樣。
link |
考慮semantic語意的information。
link |
是用sequence to sequence autoencoder呢,
link |
所謂chattbot就是聊天機器人。
link |
那怎麼用這種sequence to sequence呢?
link |
那怎麼用這種sequence to sequence呢?
link |
怎麼用這種sequence to sequence autoencoder呢?
link |
怎麼用這種sequence to sequence learning
link |
來train一個chattbot呢?
link |
有某一個人說How are you?
link |
這個sequence to sequence learning它的input,
link |
當它的input是How are you?的時候,
link |
然後呢,就讓Machine去train。
link |
去學這一個sequence to sequence的model。
link |
去學這一個sequence to sequence的model。
link |
去學這一個sequence to sequence的model。
link |
這個是跟中央大學蔡同漢老師的團隊一起開發的。
link |
是跟中央大學蔡同漢老師的團隊一起開發的。
link |
是跟中央大學蔡同漢老師的團隊一起開發的。
link |
還有另外一種有用到memory的network,
link |
還有另外一種有用到memory的network,
link |
叫做tension-based model。
link |
它可以想成是RNN的一個進階的版本。
link |
它可以想成是RNN的一個進階的版本。
link |
比如說你現在可能同時記得早餐吃了什麼,
link |
比如說你現在可能同時記得早餐吃了什麼,
link |
可能同時記得十年前中二的夏天發生了什麼事,
link |
可能同時記得十年前中二的夏天發生了什麼事,
link |
可能同時記得在這幾門課裡面學到的東西。
link |
可能同時記得在這幾門課裡面學到的東西。
link |
那當然有人問你說什麼是deep learning的時候,
link |
那當然有人問你說什麼是deep learning的時候,
link |
會去提取重要的information,
link |
然後再把這些information組織起來產生答案。
link |
然後再把這些information組織起來產生答案。
link |
然後再把這些information組織起來產生答案。
link |
machine也可以做到類似的事情。
link |
machine也可以有很大的記憶的容量,
link |
machine也可以有很大的記憶的容量,
link |
它也可以有一個很大的database,
link |
它也可以有一個很大的database,
link |
在這個database裡面的每一個vector,
link |
就代表了某種information被存在machine的記憶裡面。
link |
就代表了某種information被存在machine的記憶裡面。
link |
這個input會被丟進一個中央處理器,
link |
這個reading head controller呢,
link |
這個reading head放的位置。
link |
然後machine再從這個reading head放的位置裡面,
link |
那我們就不打算細講這樣的model,
link |
它呢,會去操控一個writing head的controller。
link |
它呢,會去操控一個writing head的controller。
link |
這個writing head的controller呢,
link |
會去決定呢,writing head放的位置。
link |
然後呢,machine會去把它的information,
link |
透過這個writing head呢,
link |
neural turing machine。
link |
有些neural turing machine應該是在,
link |
現在這樣的attention-based model,
link |
常常被用在reading comprehension裡面。
link |
常常被用在reading comprehension裡面。
link |
所謂的reading comprehension呢,
link |
就是讓machine去讀一堆document,
link |
然後把這些document裡面的內容,
link |
去控制了一個reading head controller,
link |
假設呢,machine發現說這個句子,
link |
它就把reading head放在這個地方,
link |
把information讀到中央處理器裡面。
link |
這個讀取information的過程,
link |
並不會只從一個地方讀取information,
link |
它先從這裡讀取information以後,
link |
那它把所有它讀到的information,
link |
以下呢,是Facebook AI Research
link |
在這個Baby這個Corpus上面的一個
link |
那Baby這個Corpus呢,是一個QA
link |
question engine的test,它其實是
link |
document,和一些簡單的問題,
link |
我們需要做的事情就是,讀過這五個句子,
link |
來問它說,what color is gray?
link |
machine attention的位置,
link |
也就是它reading head的位置,
link |
machine的reading head放著的位置。
link |
1 hop 2 hop 3,代表的是時間。
link |
machine呢,先把它的reading head
link |
所以它把這個information提取出來,
link |
它提取gray is a frog的information,
link |
brown is a frog的information,
link |
brown is yellow的information,
link |
認出來的,也就是machine要attent在
link |
並不是去寫程式,告訴machine說
link |
這個句子,再看這個句子,不是,是machine
link |
做visual question answering,
link |
visual question answering就是
link |
question answering怎麼做呢?
link |
這個visual question answering就讓machine
link |
的controller,那這個reading head的controller呢
link |
是有關的,那把information讀到
link |
把information讀到中央處理器裡面
link |
這個question answer,比如說
link |
四個正確的選項裡面呢,machine
link |
那用的model architecture呢,
link |
讓machine先讀一下question,然後把這個
link |
那麼machine了解了question的
link |
這個audio的story的語意以後,
link |
決定在這個audio story裡面,
link |
畫重點一樣。那machine根據它畫的
link |
這個question semantic的
link |
audio story semantic的部分
link |
都是neural network,所以它們就是
link |
你就只要給machine呢,託普聽一聲的考古題,
link |
計中計啦,你可能會覺得應該要選最長的,
link |
semantic,你做那個sequence to sequence
link |
然後你就把它選出來,那你有35%的正確率啊。
link |
那你可以用一些machine learning的方法,比如說用
link |
memory level可以得到39%的正確率,
link |
machine learning了。
link |
我們講了thick learning,
link |
也講了structured learning,
link |
講了structured perceptron和structured SVM,
link |
inputting a sequence, outputting another sequence,
link |
跟使用structured learning的技術,
link |
unidirectional的RNN或LSTM,
link |
用structured learning的話,
link |
透過Viterbi的algorithm,
link |
如果你是用Viterbi的algorithm的話,
link |
structured SVM等等,還是有
link |
他們可以做bi-directional,
link |
一整個句子的information。
link |
舉例來說,你今天在做inference的時候,
link |
下到那個Viterbi的algorithm
link |
每一個label出現的時候,都要連續進行五次。
link |
你可以輕易地用Viterbi algorithm
link |
做到,因為你可以修改Viterbi algorithm,
link |
讓Machine Learning在選擇
link |
給他看這種training data,
link |
Structure Learning似乎
link |
或LSTM,你的cost function
link |
cross entropy,每一個時間點
link |
你的RNN的output跟reference
link |
是用Structure Learning的話,
link |
Structure Learning的cost會是
link |
error的一個upper bound。
link |
所以從這個角度來看,Structure Learning
link |
而HLMCRF,Structure Perceptron,
link |
因為我們定的evaluation function
link |
如果他不是linear的話,你會很麻煩。
link |
你在training的時候會有很多麻煩。
link |
所以他要是linear的,我們才能夠套用
link |
來做influence跟training。
link |
deep learning會佔到很大的優勢。
link |
得到一些state of the art的結果,
link |
這種secret laboring的test
link |
要得到state of the art的結果,
link |
RLLSTM這種secret laboring
link |
如果你的model是linear,你的function space就這麼大,
link |
一個arrow的upper bound,那又怎樣?
link |
因為你所有的function都是壞的,
link |
跟structured learning,
link |
RNN LSTM的output,再作為
link |
HNSCRF structured SVM
link |
HNSCRF structured SVM的
link |
evaluation function。
link |
structured learning的
link |
deep,這邊有structured,
link |
SCRF可以用gradient descent train,
link |
那其實structured SVM,我們好像
link |
沒有講,但是它也可以用gradient descent train。
link |
把deep learning的部分和
link |
structured learning的部分jointly合起來,
link |
一起用gradient descent
link |
deep learning和structured learning合起來,
link |
deep learning的model
link |
如果呢,你要得到最state of the art
link |
還是用這樣子hybrid system
link |
joint probability,或是在structured learning
link |
X跟Y的evaluation function,
link |
emission model,但是把它換成
link |
它可以給我們的offer是invalid
link |
occlusive feature,它告訴你說這個
link |
occlusive feature屬於每一個state
link |
這跟我們要的東西不一樣啊,我們要的是
link |
乘以P of X,除以P of Y。
link |
看,你就可以直接從你的converse
link |
為什麼P of X可以直接無視它呢?
link |
幾率的時候,在influence的時候,
link |
一個thread,每一個thread
link |
丟到RNN,然後問它說,這個thread
link |
這個thread,屬於哪一個form
link |
第二個thread是A,第三個是A,第四個是A
link |
這個label,它都是dependent
link |
對RNN來說,因為它在training的時候
link |
如果我們今天把這個B改成錯在這個地方
link |
在這邊犯一個錯誤和這邊犯一個錯誤是一樣
link |
structure learning的概念才能夠
link |
用bi-directional的LSDN
link |
先用bi-directional的LSDN抽出feature
link |
CRF或者是structure SVN
link |
CRF跟structure SVN都是linear的model
link |
那這個final of SY的feature
link |
你不要直接從row的feature來
link |
你直接從bi-directional的RNN的output
link |
那有人會說structure learning
link |
我們知道structure learning
link |
sequence labeling是少數有好的solution的狀況
link |
structure learning
link |
structure learning
link |
evaluation function
link |
在structure learning裡面
link |
evaluation function
link |
我們就可以把它看作是evaluation function
link |
看看誰可以讓我們的evaluation function
link |
給一個從Gaussian裡面sample出來的noise
link |
它就output一個object出來嗎
link |
不是就是可以讓discriminator
link |
如果discriminator就是evaluation function的話
link |
就是可以讓evaluation function的值
link |
那這個generator的output
link |
當作是在解inference的這個問題
link |
你已經知道了我們怎麼train GAN
link |
大家還記得structure SVM是什麼training嗎
link |
在structure SVM的training裡面
link |
它的evaluation function的分數
link |
大過competitive的example
link |
然後再重新選competitive的example
link |
double competitive的
link |
它應該要讓evaluation function
link |
就是discriminator的值大
link |
然後我們每次用這個generator
link |
也就是可以讓discriminator的值最大的那些x
link |
然後再去train discriminator
link |
正確的,real的,跟generated
link |
要給real的example比較大的值
link |
給那些most competitive的x
link |
就不斷的iterative的進行下去
link |
你會update你的discriminator
link |
然後update你的generator
link |
然後再update你的discriminator
link |
這個structure SEM的training
link |
我們之前在講structure SEM的時候
link |
都是有一個input,有一個output
link |
什麼是conditional的GAN呢
link |
那如果是用conditionalGAN的概念
link |
所以你的process就跟原來的GAN
link |
用文字產生image的這個test上面
link |
在用文字產生image的這個test
link |
this flower has small brown flowers
link |
petals with a bright purple center
link |
discriminator給它看一張image
link |
這個image跟sentence pair
link |
那如果你把discriminator
link |
就是evaluation function
link |
解inference的network algorithm
link |
其實conditional GAN跟structure learning
link |
就是train structure learning的
link |
GAN可以跟energy-based model
link |
GAN可以被視為train energy-based model
link |
所謂的energy-based model其實我們之前有講過
link |
它就是structure learning的
link |
這邊也列一些reference給大家參考
link |
deep and structure
link |
deep and structure
link |
machine learning and heavy lift
link |
deep and structure
link |
machine learning and heavy lift
link |
我們可以用Deep Learning這個書來當作教科書
link |
Machine Learning and Heavy Lift
link |
這個Deep Learning這本教科書
link |
一個part講linear algebra
link |
part 2是講deep learning
link |
part 3的內容雖然它的title叫做Deep Learning Research
link |
part 3講linear vector model
link |
partition function
link |
這個其實都是structure learning的內容
link |
怎麼我為什麼把deep和structure
link |
這個把deep跟structure湊在一起
link |
attention based model
link |
reinforcement learning
link |
deep generative model也要出一個作業
link |
sequence to sequence learning也應該出一個作業
link |
sequence to sequence learning可以做的東西太多
link |
可以做一個video的caption generation
link |
做一個V4W的neural network