back to index
ML Lecture 22: Ensemble
link |
好,那接下來呢,我們要講Ensemble。那Ensemble呢,咦?螢幕沒出來是吧?Ensemble,好,那我們要講Ensemble。
link |
那Ensemble的這種方法呢,其實就是團隊合作,好幾個模型一起上的方法。那在做Ensemble的時候呢,通常狀況是這樣,
link |
你有一打的Classifier,假設你現在做的是分類的問題,你手上有一打的Classifier,F1,F2,F3,那你想把這一打的Classifier呢,集合起來,
link |
去發揮原來一個Classifier所沒有辦法發揮的更強大的力量。那這些Classifier通常你會希望他們是diverse的,每一個Classifier呢,他們有不同的屬性,他們有不同的作用。
link |
就好像說,如果今天大家一起出團去打王的時候,每一個人都有自己需要做的工作,你會需要一個團隊裡面有各種不同的角色,要有人扮演坦,有人扮演補,有人扮演滴滴。
link |
滴滴不知道大家知不知道是什麼,滴滴就是輸出的意思。然後你要把不同的Classifier呢,把它aggregate在一起,把它集合在一起。
link |
這個集合的時候呢,你需要用比較好的方法來把它們集合在一起,這樣就好像是在打王的時候呢,坦普跟滴滴他們有不同的應該要站的位置。
link |
那這個ensemble呢,就最適合在期末的時候講,為什麼呢?因為假設你現在已經開始做final,那我相信你也其實很累了,你可能沒有什麼太多的時間呢,為final的project寫什麼太fancy的大的新的程式了,也許你想要call一下你手上現有的程式,然後調調參數,看可以做到多好。
link |
那其實有一個大招可以讓你迅速的improve你的performance,就是ensemble。如果你今天已經想不到新招數了,因為你現在做一做已經卡住了,不知道有什麼進步的話,通常用ensemble可以讓你的performance再提升一個level。
link |
所以你會發現說,在比那種machine learning的比賽的時候,比如在ARM上的比賽的時候,你要得到,就你有一個好的模型,你可以拿到前幾名,那你要奪得冠軍,你通常都會需要ensemble,你都會需要用群毆的方式,才能夠得到冠軍。
link |
所以我們今天就是要講一下,怎麼來做群毆。群毆的方式呢,有幾種不同的方法,那我們先講begging這個方法。
link |
那要注意一下,我們除了會講begging以外,我們還會講boosting。那begging跟boosting,他們使用的場合是不太一樣的。
link |
那這個大概要特別注意一下。那我們來複習一下我們過去在開學的時候已經講過的東西。我們在開學的時候講過說,我們在做machine learning的時候,有bias跟variance的training。
link |
如果我們今天有一個很簡單的model,我們會有很大的bias,但比較小的variance。如果我們有一個複雜的model,可能是小的bias,但是大的variance。在這兩者的組合下,我們會看到我們的evaluate隨著model的複雜度增加,逐漸下降,然後再逐漸上升。
link |
好,那我們之前也有舉過說,假設現在在不同的世界裡面,我們都在捕捉寶可夢。那在不同的世界裡面,我們都會得到一個模型。
link |
那假設我們現在用的是一個很複雜的模型,那我們會有很大的variance。也就是在不同的世界裡面,我們所預測出來的,可以預測寶可夢CP值的模型,會非常的不一樣。但是,這些結果雖然variance很大,但是他們的bias是小的。
link |
所以我們可以把不同的模型,通通集合起來。我們可以把不同的模型,通通集合起來。我們可以把不同的模型的輸出,做一個平均,得到一個新的模型append。
link |
這個新的模型append,可能就會跟正確的答案是接近的。那Bagging其實就是要體現這件事情。
link |
那所以Bagging要做的事情就是,雖然我們不可能真的到不同的宇宙去收集,從不同的宇宙收集data,但是我們可以自己創造出不同的data set,再用不同的data set,各自去訓練一個複雜的model。那雖然每一個model獨自拿出來看,他可能variance很大,但我們把不同的variance很大的model集合起來以後,他的variance就不會那麼大,但是他的bias會是小的。
link |
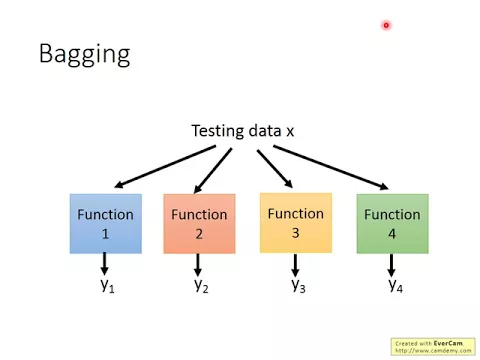
那怎麼自己製造不同的data呢?假設你現在有n筆training data,那你對這n筆training data做sampling。從這n筆training data裡面,每次取n塊筆data,組成一個新的data set。
link |
那你通常在做sampling的時候,你會做replacement,也就是你抽出一筆data以後,你會再把它放到你的port裡面去。那所以這邊通常n塊呢,你可以就設成n,但是雖然你把n塊設成n,你從n這個data set裡面,做n次的sampling with replacement,得到的這個data set,跟原來的這n筆data並不會是一樣。
link |
對不對?因為你可能會反覆抽到同一個sample嘛。好,那總之呢,我們就用sample的方法,建出好幾個data set。每一個data set都有n塊筆data,那每一個data set裡面的data都是不一樣。
link |
接下來,你再用一個複雜的模型,去對這四個data set都去做learning,那你就找出了四個function。接下來在testing的時候,你就把一筆testing data丟到這四個function裡面,那你再把你得出來的結果做平均,或者是做voting。
link |
那通常就會比只有靠一個function的時候,performance還要好。這邊performance還要好是指說你的variance會比較小,所以你得到的結果會是比較robust,比較不容易overfeeding。
link |
那如果今天你做的是regression的方法的時候,你可能會用average的方法,來把四個不同的function的結果組合起來。如果今天是分類的問題的話,你可能會用voting的方法,來把這四個結果組合起來。
link |
你就看說這四個function裡面,哪一個類別有最多classified投票給他,那你就選那個class當作你的model的open。然後注意一下,什麼時候做begging?當你的model很複雜的時候,你擔心他overfeeding的時候,你才做begging。
link |
了解我的意思嗎?所以做begging的目的是為了要減低variance。你的model的bias已經很小,但variance很大,你想要減低variance的時候,你才做begging。
link |
所以適用做begging的情況是,你的model本身已經很複雜,在你的training data上很容易就overfeed,這個時候你會想要用begging。
link |
什麼樣的model很容易overfeed呢?有人會說,NN很容易overfeed。沒有,其實NN沒有那麼容易overfeed,相較於看你跟誰比啦。
link |
很多人就憑著直覺說,一個neural network看起來參數那麼多,應該就是很容易overfeed了吧。如果你今天有實作過neural network的話,我想你其實是不會這麼想的。
link |
所以neural network的時候,你常常遇到的問題是,你沒辦法在training set上overfeed,而不是你非常容易overfeed,對不對?
link |
什麼樣的model非常容易overfeed呢?舉例來說,decision tree就是一個非常容易overfeed的方法。
link |
所以decision tree你只要想的話,你把那個數長得很深,它在training data上,只要數夠深,你都可以拿到100%的正確率。NN你很難拿到100%的正確率,你要拿到100%的正確率,就是在NN上你要好好調參數,你才能拿到100%的正確率。
link |
但是像decision tree這種方法,只要它想,它可以拿到100%的正確率。但是在training data上拿到100%的正確率,不見得有什麼特別厲害的地方,其實就只是overfeeding而已。
link |
所以今天你什麼時候要做begging,model很容易overfeeding的時候要做begging,所以decision tree很需要做begging,random forest就是decision tree做begging的版本,就是random forest。
link |
那我們沒有講過decision tree,其實我覺得也不見得需要講,我知道你們每個人都知道decision tree對不對,我看大家在作業裡面很多人都用到decision tree,都用得很爽,所以這個好像是不太需要講的。
link |
我們就秒講過去,我們現在假設我們每一個object,它有兩個feature,x1和x2,decision tree就是你根據你的training data去建出一棵樹。
link |
這個樹是這樣子,這棵樹告訴我們說如果輸入的object x,x1小於0.5的話就是yes,大於0.5就是no,所以就是在x1等於0.5的地方切一刀,移左就走到左邊這條路上去,往右就走到右邊這條路上去。
link |
再來再看x2,x2小於0.3的時候,就說是class 1就塗藍色,x2大於0.3的時候,就說是class 2就塗紅色。
link |
那如果在右邊呢,右邊如果x2小於0.7的時候就塗紅色,x2大於0.7的時候就塗藍色。那這邊這個decision tree上面問的問題是比較簡單的,它是看一個dimension,你其實可以同時看兩個dimension,你其實可以問更複雜的問題。
link |
要問什麼問題,是人自己決定的。所以說decision tree的時候,會有很多你需要注意的地方,舉例來說,你可能會需要考慮說,比如說在每個節點我要做多少分枝,我要用什麼樣的criterion來做分枝,我要什麼時候停止分枝,
link |
那我的這個可以問的問題的集合裡面有哪些問題等等,有一大堆的,也是有很多的參數要調和額一樣,有一些東西是你需要調整的。
link |
那我們就來舉一個decision tree的例子吧,我們把decision tree實作在底下這個test上面,這個test叫做初音test,這個test是這樣子的,我們有一個分類的問題,這個分類的問題是說這個輸入的feature就是二維,輸入的feature就是二維。
link |
那在這個紅色的部分呢,是屬於class1,在藍色的部分呢,是屬於另外一個class,屬於class2,那這個class1分佈的樣子呢,正好就跟初音是一樣的。
link |
如果你要用這個data的話呢,我放在這邊,你可以載這個data來用,這個是一個初音的test,一般教科書都會用一些什麼方形啊,圈圈啊,那個都太弱,我這個用初音的test。
link |
好,就是class1的分佈就跟初音一樣,那現在decision tree能不能夠在這個test裡面把class1和class2正確的進行分類呢?我們來看一下結果。
link |
那這個decision tree的深度是5,它沒有辦法把class1和class2分開,它只能光說這個一個方塊的地方就是class1。那如果更深的decision tree呢,如果是decision tree的深度升達10的話,看起來就有點初音的樣子了。
link |
不過它有很明顯的鋸齒狀,看起來像是在minecraft的世界裡面看到的初音。那如果depth是15的話,那就看起來更好了,那這個樣子看起來就蠻對的,但有些地方還是有點怪怪的,比如說這邊凸起來一塊。
link |
如果今天decision tree的深度是20的話,那你就可以完美的把class1的位置跟class2的位置區別開來,就可以完美的把初音的樣子勾勒出來。
link |
那這個其實沒有什麼,decision tree只要你想的話,你永遠可以做到error rate是0,你永遠可以做到正確率是1。因為你想想看,最極端的case就是你這個tree一直長下去,每一筆data point就是一個很深的樹的其中一個節點的其中一個leaf,其中一個一片葉子,那這樣你的正確率就一定是100%了。
link |
所以這個沒有什麼,樹夠深,decision tree可以做出任何方法。但是就是因為decision tree它太容易over fitting,所以你單用一顆decision tree,你往往不見得可以達到好的結果。
link |
所以我們要在decision tree做bagging,這個方法就是random forest。那我們可以用傳統的bagging的方法來做random forest,你可以用傳統的剛才講的sample的方法來做bagging,但是如果用那種方法,你得到的tree通常每一顆都沒有差太多,所以光用sample的方法看起來是不太夠。
link |
在做random forest的時候,比較typical的方法是,在每一次要產生decision tree的branch的時候,都random的決定哪一些feature或哪一些問題是不能用的。
link |
你random的決定說,現在要做split的時候,哪些question或哪些feature不能用,就可以促使就算是你用成是一模一樣的data set,每一次你產生的decision tree也會是不一樣。
link |
最後你再把所有decision tree的結果集合起來,那你就得到random forest。那如果你今天是用bagging的方法的話,有一個叫做out of bag的方法可以幫你做validation。
link |
out of bag的方法就是把你手上的training set切成兩塊,你手上原來有level data切成兩塊training set跟validation set。如果你今天是用bagging的方法的話,你可以不要把你的level data切成training set跟validation set,一樣有validation的效果。
link |
怎麼做呢?怎麼做呢?因為我們知道說今天在做bagging的時候,每一個function,你train出來的每一個model,他都只用到部分的data。假設我現在training data裡面有X1到X4總共有4筆data,而F1只用第一筆和第二筆data train,F2只用第三筆第四筆data train,F3只用第三筆data train,F4只用二四筆data train。
link |
那我們就會知道說,實際上我們在train F2跟F4的時候,我們其實沒有用到X1。所以我們可以用F2加F4 bagging的結果去在X1上面testing他的performance。同理我們可以用X2跟X3做bagging的結果去test X2,用F1跟F4做bagging的結果去test X3,
link |
用F1跟F3 bagging的結果去test X4。然後接下來呢,再把X1跟X4的結果呢,把它做平均計算一下error rate,你就得到一個out of bag的error。
link |
雖然我們這邊沒有明確的切出一個validation set,但是我們在做testing的時候,我們所用的model並沒有看過那些testing的data。我們在test X1到X4的時候,這些model並沒有看過X1到X4,並沒有看過X1到X4。
link |
所以這個out of bag error,它其實也是一個可以在testing set上,可以反映testing set的結果的estimation。
link |
好,那我們看一下random forest在初音的這個test上面的結果。那這邊呢,是做100棵樹了。那你會發現說,如果是100棵DEM45的樹,做出來的結果是這個樣子。
link |
這邊要強調一下,做bagging並不會使你的model更能夠fit data。所以DEM45的樹,沒有辦法fit初音那個function,你用random forest,它還是沒有辦法fit初音那個function。
link |
你可以得到的結果只是,現在因為是把5棵樹平均起來,所以你得到的整體的function,它是比較平滑的而已。
link |
好,所以比如說DEM40看起來就是這樣,看起來就比較不像Minecraft的世界就是了。那如果DEM45得到的結果是這樣,看起來很好,但其實它是有一個瑕疵的,它有些地方沒有做好。
link |
好,記得這邊有一條頭髮垂下來,它還沒有把那條頭髮框出來的樣子。我看一下,對,沒錯,如果你是100棵DEM22樹,你就可以完美地把初音框出來。那這邊其實是有一條頭髮,要把這個做出來才是真的正確。
link |
好,那接下來我們要講boosting。那boosting跟剛才的begin是不一樣的。begin是用在很強的model,boosting是用在很弱的,是用在弱的model上面。
link |
當你有一些弱的model,但是問題是你沒有辦法讓他們去fit你的data的時候,這個時候你就會想要用boosting。好,所以boosting是這樣,boosting它可以保證說,它有一個很powerful的guarantee。
link |
這個很powerful的guarantee是這樣說的,假設你有一個ML的algorithm,它可以給你一個錯誤率高過50%的classify,假設我們現在要做分類的問題的話。
link |
那錯誤率高過50%的classify,假設是二元分類的問題,原random猜數值要高過50%,很輕易可以辦到,很爛的模型都可以辦到。只要你能夠做到這件事,只要你能夠做到這件事情,boosting這個方法可以保證你最後把這些錯誤率值僅略高於50%的classify組合起來以後,
link |
它可以讓錯誤率達到0%,有沒有聽起來非常神奇,聽起來就是非常的強。
link |
這整個boosting的framework,整個大架構大概是這樣。首先,你先找一個classify F1,這個classify F1很弱,沒有關係。接下來,你再找一個classify F2,它去輔助F1。
link |
但是你要注意一下,F2跟F1不會很像,它們要是互補的,F2跟F1的特性是互補的。F2要去彌補F1的缺失,F2要去做F1沒有辦法做到的事情,這樣進步量才大。
link |
那boosting呢,等一下我們就會講說,怎麼樣找到一個F2,它跟F1是最互補的。然後你就得到第二個classify F2,然後接下來呢,你再找說,我先找classify F2,那我再找一個F3,跟F2是互補的。
link |
然後接下來我再找一個F4,跟F3是互補的。這個process呢,就繼續下去。你找到一把的classify,你再把這把classify集合起來,你就可以得到很低的error rate。就算是每一個classify,它們都很弱,也沒有關係。
link |
那要注意的地方是,今天在做boosting的時候,這個classify的訓練是有順序的。你要先找出F1,才找得出F2,才找得出F3,它是sequential的。你要先找F1才知道說,怎麼找一個F2跟F1是互補的。
link |
所以它是有順序的。那前面在backing的時候,每一個classify是沒有順序的。你在做100顆tree,你在做random forest,你要train100顆decision tree,這100顆decision tree可以平行做。
link |
那這邊,如果你是要把100個decision tree用boosting的方法,把它變得很強的話,那你要按順序做,沒有辦法,它不是一個平行做的方法。那這邊假設我們考一個test,是一個binary classification的test,就是有一堆training data,x跟y hat,那y hat就等於正負1。
link |
接下來要講的就是,怎麼得到不同的classify。我們剛才在backing的時候講過說,要得到不同的classify,我們可以用製造不同的training set的方式來得到不同的classify。
link |
那在boosting的時候,你也可以這麼做,你可以用resample data的方式來製造不同的training data,然後得到不同的classify。
link |
但是有另外一種方法可以幫你製造出不同的data set,你可以給你的training data裡面的每一筆data一個weight,舉例來說,我們這邊用u來代表每一筆data的weight。
link |
那一開始呢,你可以藉由改變這個weight來製造不同的data set,舉例來說,本來現在你有三筆data,每一筆data的weight都是u。
link |
那你可以把它改成說,現在第一筆data weight是0.4,第二筆data weight是2.0,第三筆data weight是0.7,這樣就等於製造出了一個新的data set。
link |
那其實sampling也可以視同是改了weight,只是sampling,比如說你某一筆data被sample兩次,就代表說它的weight變成2。
link |
只是如果你用sampling的方法的話,你的weight只能是整數,直接調一個weight u的話,你可以給小數就是了。
link |
好,那就算是你改變了這個weight,對training也不會有太大的影響。我們知道在training的時候,原來的objective function是寫成這個樣子。
link |
你有一個loss function,你要去minimize它,這個loss function是summation over所有的training data,對,每一筆training data xn,我們都把它帶到function f裡面去得到f of xn,計算f of xn跟y hat n的差距,這個差距用一個loss function來表示。
link |
這個小l呢,它可以是各種不同的function,反正能夠量f of xn跟y hat n之間的差異就行了。
link |
然後呢,你就用回一點descent的方法,去找一個function f,來minimize這個大l,這個total loss function。
link |
如果今天加上weight的話,有什麼不同呢?沒有什麼不同,唯一的不同只有,你會在每一個小l的function前面乘上u。
link |
你會在每一個小l的function前面乘上那筆data的weight,代表那筆data的權重。
link |
所以今天如果有一筆data它的權重比較重,它的u比較大,那你今天在training的時候,它就會被多考慮一點。
link |
好,那有了這個概念以後,那adaboost的精神是什麼呢?這個boosting有很多的方法,等一下我們要介紹的是,其中最經典的這個adaboost的方法。
link |
這個adaboost的方法是這樣子,adaboost的方法它的想法是說,我們今天呢,要製造一個,我們現在先訓練好一個classified f1。
link |
那我們要去找一組新的training data,所謂的找一組新的training data的意思其實就是reweight我們的training的example。
link |
我們要去找一組新的training data,讓f2在這組新的training data上面的,讓f1在這組新的training data上面,結果是會爛掉,會fail掉,它的正確率會變成只有50%。
link |
我們要找一組新的training data,f1在這組新的training data是做不好的,然後再讓f2在這組新的training data上面去做訓練。
link |
好,那接下來,怎麼找f1,怎麼找一個新的training data可以讓這個f1壞掉呢?假設給你一個f1,你要怎麼找一個training data讓f1壞掉呢?那我們先來看一下這個f1在training data上的error rate怎麼計算。
link |
f1在training data上的error rate,我們這邊寫成x1,這個x1的計算方法就是submission over所有的training example n,submission over所有的training example n。
link |
然後呢,計算說每一筆的training example,每一筆的training example,它的結果是不是對的,如果是對的話就是0,如果是錯的話就是1。
link |
那這些training example,你都還要除以乘上它的weight un,然後你要再做一下normalization,因為這個un的值合起來不見得是1,所以你要做一個normalization。
link |
這個normalization就是submission over所有的u1,submission over所有的weight,就是這個normalization的term。
link |
那這個1呢,它一定會小於0.5,因為我們假設說我們今天的classifier是還可以的,所以不是一個完全random的classifier,所以它的error rate總是可以小於0.5。
link |
如果今天classifier 1,你其實沒有辦法製造一個classifier它的error rate大於0.5,你知道嗎?
link |
如果classifier它的error rate大於0.5,你只要把它的output反過來,它的error rate就小於0.5了。
link |
那現在呢,我們想要做的事情就是,原來training data的weight是1,我們要給一組新的training data的weight的u2。
link |
這組新的training data的weight會使得說,如果我們今天把上面這個算ε1的式子的u1換成u2,得到的結果會變成0.5。
link |
就本來ε1是小於0.5,是在u1作為weight做計算的時候,小於0.5。
link |
那現在把u1換成u2,weight就變成0.5。那這個時候就好像是說,假如我們重新weight了我們的training data,
link |
本來是用u1作為training data的weight,現在用u2作為training data的weight,在這組新的weight上面,f1它的performance就像是隨機的一樣。
link |
然後接下來,我們再拿這組新的training data,用u2當作weight的training data,再去訓練f2,那f2就會跟f1是互補的。
link |
那這樣講也許有點抽象,所以我們舉一個實際的例子。
link |
現在有四筆training data,那這四筆training data的weight就是u1到u4,那我們假設u1、u2、u3、u4統統等於1,這四筆training data的weight是一樣的。
link |
現在我們用這四筆training data去訓練一個模型,去訓練一個classified f1,那假設f1其實它不是一個特別powerful的algorithm,
link |
所以就算是training data,它也沒有辦法每一筆training data都分類正確,我們假設它只分類正確三筆training data,一筆training data是分類錯的。
link |
但是它的error rate,所以它的error rate是0.25,四筆training data分錯一筆,所以它的error rate是0.25。
link |
接下來我們要改變這個data的weight,我們要把u的值變一下,讓f1在這個新的training dataset上,它的error變成0.5。
link |
怎麼改呢?其實有不同的改法,我們這邊假設說,舉例來說,我們假設u1的weight是1除以根號3。
link |
因為我們現在要讓f1的error變大,怎麼讓f1的error變大?就是看它說它答對哪幾題,那幾題的配分就變小,答錯哪幾題,那幾題的配分就變大。
link |
好像考試的時候,你先把考卷寫完,然後老師也改完以後,然後我們再重新去計算配分,看到你答錯的配分就比較高,答對的配分就比較低,然後你就會發狂,就會生氣。
link |
今天要做的事情就是要讓f1生氣。我們先看看它答對哪些,答錯哪些。它答對了,本來先跟它說好每一題的配分都是一樣的,但其實是騙它的。它先答完以後,再改一下題目的配分。
link |
第一題它答對了,所以配分就變成1除以根號3。第二題它答錯,所以配分就增加,變成根號3。第三題跟第四題它也答對了,所以配分就減少,都變成1除以根號3。
link |
如果今天在這筆新的training data的情況下,就會變成f1它就會變得很糟,因為你想想看,它答錯的題目,wait是根號3,它答對的題目,wait是1除以根號3。
link |
有三題,1除以根號3乘3也是根號3,所以答錯的題目跟答對的題目的wait是一樣的。所以今天f1的wait,它的error rate就變成了0.5。
link |
接下來我們在這組新的training data上面,這組新的training data可以讓f1整個爛掉,我們在這組新的training data上面再去訓練f2。f2因為它是看著這組新的wait,它看著這個新的配分去做練習的,它看著這個新的wait去做學習的,所以新的error rate在這組wait上,它的error會是小於0.5。
link |
所以f2可以跟f1是互補,更詳細的證明我們之後會有,我們今天都是講個精神,之後會有完整的證明。
link |
接下來我們來講一下,實際上要怎麼做rewait這件事情呢?要怎麼做rewait這件事情呢?這個做法是這個樣子的。
link |
如果說今天某一筆data xn它會被f1分類錯,那我們就把第n筆data的wait的u1乘上一個值d1變成u2,那這個d1是大於1的值,也就是說xn如果分類錯誤的話,就把那個題目,那筆data的權重提高,乘上d1把它提高。
link |
好,那如果xn是正確的被f1分類的話,那我們就把u1除掉d1,把它變小。
link |
好,那所以錯的就增加,對的就變小。好,那f2會在新的wait,u2上面進行訓練。
link |
接下來的問題就是這個d1的值應該要設多少呢?那這邊沒有什麼高深的數學,其實就是推一下要設什麼樣的d1可以讓u1變成u2以後,可以讓f1的error rate是0.5。
link |
這邊就只是數學是比較繁瑣,但其實很簡單的數學。這個數學是這樣子的,我們現在已經計算出x1的式子是這個樣子,那我們現在希望把u1換成u2,那得到的wait是0.5。
link |
好,那我們的原則就是如果今天dn比data的分類是錯誤的,那就乘上d1,如果分類是正確的,就除掉d1。
link |
好,那我們先看一下上面這邊,上面這邊是指summation over分類錯誤的那些data,上面這邊是指先summation over分類錯誤的那些data。
link |
所以上面的這些u2,它都是分類錯誤的,所以它都會乘上d1。所以上面這個分子的地方,你可以寫成summation over u1乘上d1。
link |
因為上面這幾個data每一筆,上面這些u每一筆都是u1乘上d1,因為它們都是分類錯誤的。好,那再來我們看分子的地方,分子的地方是summation over u2。
link |
那u2有兩個case,一個是如果f1會把這筆data分類錯誤的話,那u2是來自於u1乘以d1。如果是分類正確的話,那u2就是來自於u1除以d1。
link |
所以這整個式子列出來的話,就是這個樣子。然後你把分子的地方帶進去,分母的地方帶進去,得到這個式子。
link |
然後這個式子它是等於0.5的。然後我們把分子和分母導過來,所以左邊分子和分母導過來,右邊就從0.5變成2。
link |
接下來我們發現分子和分母都有共同的這一項,這一項是分子分母所共有的,所以我們知道說這一項除以這一項,這一項除以這一項會等於1。
link |
這告訴我們什麼呢?這告訴我們說,u1除以d1,我們把所有那些f1會答對的data xn拿出來,把他們的u1除以d1,要等於所有f1會答錯的那些xn,他們的u1乘以d1。
link |
那這個式子就算不用剛才推導,其實你也可以很直覺的寫出這個式子。如果你要讓f1在新的weight上的effort weight是0.5的話,那當然它答錯的部分的新的weight,它答對的部分的新的weight,要等於答錯的部分的新的weight。
link |
那接下來呢,你就把d1提出去,你把d1提出去,你把d1提出去,你把d1提出去,d1提出去,d1提出去。
link |
好,那接下來呢,我們知道說,epsilon1可以寫成這個樣子。epsilon1的分子的地方,是對那些答錯的example xn的weight的總和,然後再做normalization。
link |
那這一項出現在這個地方,所以我們可以把這一項用epsilon1把它代換掉。
link |
所以這一項等於z1乘以epsilon1,這一項等於z1乘以epsilon1。那這一項呢,這一項呢,這一項是z1乘以1減epsilon1,對不對?因為這一項加這一項會是z1,這一項加這一項會是z1。
link |
既然它是z1epsilon1,它就是z1乘以1減epsilon1。好,總之呢,經過一番推導以後,經過一番推導以後,你會算出來說,d1等於根號1除以epsilon1,除以epsilon1。
link |
根號1除以epsilon1,除以epsilon1等於d1,拿這個d1去乘或者是除u1,你就可以製造一個training dataset,它是會讓f1fill掉的training dataset。
link |
那這個d1呢,這個d1的值呢,它一定會大於1,為什麼?因為epsilon1一定小於0.5嘛,所以在d1的這個根號的項裡面,分值會大於分母的,所以呢,所以這個d1呢,它都會大於1。
link |
好,那整個AdaBoost的演算法呢,我們可以講完這一頁就好,而且整個AdaBoost的演算法呢,看起來就是這個樣。
link |
現在呢,我們有一筆training data,那有一堆training data,那每一筆training data呢,我們都一開始給它初始的weight呢,都是1,然後接下來呢,你要跑大T的integration。
link |
每一個iteration都會給我們一個classify,都會給我們一個weight的classify,ft,然後最後再把所有的ft集合起來,就變成一個強的classify。
link |
那iteration的時候,每一筆training data都有它自己的weight,這邊寫成,u上標1下標T,u到u上標n下標T,我們用下標T代表的是那一個iteration的weight。
link |
好,那我們用這個weight訓練出ft,然後計算ft在原來的weight上面的arrow,f總T,計算出f總T以後,我們就可以reweight每一筆training data。
link |
如果xn它被ft分類錯誤的話,如果分類錯誤的話怎麼辦呢?就把u上標n下標T乘上d下標T,就把u上標n下標T乘上一個大於1的值,然後得到一組新的weight,這組新的weight會在下一個iteration的時候被使用。
link |
反之呢,就把原來的weight除掉dt,然後得到一組新的weight,這組新的weight要在下一個iteration的時候被使用。
link |
那這個dt我們剛才已經講過了,這個dt就等於根號1-f總T除以f總T。那或者是呢,我們可以寫成,有另外一個這個變數叫做αt,這個αt是natural log根號1-f總T除以f總T。
link |
這麼做呢,是有含義的。這麼做的話,我們可以把dt換成exponential αt,把除dt換成乘exponential-αt,所以本來是有乘有除,現在變成一個是乘exponential αt,一個是乘exponential-αt。
link |
之所以這麼做,是為了要表達式子的時候可以更簡便一點。怎麼樣更簡便一點呢?我們可以把這兩個式子合成一個式子。
link |
我們可以這樣寫,我們可以說,下面這兩個式子差的只有一個負號而已。我們都是要把原來的weight乘上exponential αt,只是這個αt前面,有時候是正1,有時候是負1。
link |
怎麼用一條式子決定αt前面應該是正1還是負1呢?我們就只需要說,我們把y hat乘上ft of xn。
link |
如果說今天是misclassified的情況下,y hat跟ft of x,它是不一樣的,這兩值是不一樣的,所以它是負1。那負1乘負1,αt前面就變成1,就變成這個樣子。
link |
如果是分類正確的情況下,這兩項是一樣的,所以這兩項相乘就是正1,所以再乘上負1,所以這項就變成負1。
link |
總之,今天我們可以直接用這一個式子,一個式子來表示這兩個式子。接下來經過剛才訓練以後,我們就得到了一把classified,f1到ft。
link |
再來就是,怎麼把這把classified集合在一起呢?你可以說,你用uniform的weight,你可以說,我們就說,現在有大7個classified,那叫這大7個classified都得到一個output,
link |
把這個大7個classified的output就加起來,看它是正的還是負的,如果是正的話就代表是class1,如果是負的話就代表是class2。
link |
你就把這個大7個classified的直通加起來,然後取它的正符號。這樣雖然可以,但是這樣子不是最好的方法,因為這大7個classified有好有壞,所以我們應該要給它不同的權重。
link |
怎麼給它不同的權重呢?我們在每一個classified的output前面都乘上一個權重αt,然後再全部加起來以後,再取它的正符號,這樣可以得到比較好的結果。
link |
αt怎麼得到呢?這個αt我們在前一節的試紙有看過,這個αt就是拿來改變weight的,拿來改變maybe training data的weight的那個αt,那個αt我們在前面看過。
link |
我們現在看一下這個αt的精神,如果今天某一個classified它的εt是0.1,它是一個錯誤率比較低的classified,那我們把這個εt等於0.1這件事情帶到這個試紙裡面去算做αt,那它的αt就是1.1,所以錯誤率低的classified它會有比較大的αt。
link |
如果今天有另外一個classified,它的εt是0.4,代表它是一個很爛的classified,它的錯誤率已經接近0.5了。我們把εt等於0.4帶到這個試紙裡面去算αt,我們得到αt是0.2。
link |
所以今天如果有一個比較正確的classified,這個錯誤率比較低的classified,它得到的αt的值是大的,如果有一個比較爛的classified,它得到αt的值是小的。
link |
也就是說我們今天在做weighted sum的時候,如果有一個classified它的正確率,它當初訓練的時候,它的錯誤率是比較大的,那它的weight就比較小。
link |
它當初訓練的時候,它的錯誤率是比較小的,那它的weight就比較大。所以這件事情是非常有道理的,所以這件事情是非常有道理的,這個αt是make sense的。
link |
我們很快把後面這個例子講過好,如果這邊你覺得太快的話,你就回去自己看一下圖文片,我相信這個對大家來說應該非常容易。
link |
那我講的這一段,我們就請助教來講一下作業6。
link |
這個很簡單,我們現在假設說,剛才這個演算法如果你沒有聽懂的話,你看看這個例子你就知道它的意思了。
link |
我們假設我們的Δt就等於3,那我們現在的weak的classified很weak,它不是decision tree也不是neural network,它叫做decision stack。
link |
decision stack沒什麼好講的,你知道嗎?它太簡單了。
link |
它做的事情就是,現在假設我們的feature都分佈在二維屏面上,在二維屏面上選一個dimension,切一刀,其中一邊當作class1,其中另外一邊當作class2,結束。
link |
這個就叫decision stack,那要做boosting你一定要找一個weak classifier,那decision stack它夠weak,所以我們可以把它用在這裡。
link |
好,那現在一開始,每一筆training data的weight都是一模一樣,都是1.0。
link |
好,那我們用decision stack找一個function,這個function是f1,那它的這個boundary就切在這個地方,那依座我就說是positive example,就算是positive的,就是一邊class1是positive的,然後往右就是粉紅色,就是negative。
link |
那你會發現這邊有三筆data,它的分類是錯誤的。好,那計算一下,有三筆data,這邊總共有十筆data,有三筆data分類錯誤,所以error rate是0.3,error rate是0.3的話,d1算出來就是1.53,alpha算出來就是0.42。
link |
你就帶前頁的投影片的公式,你就可以輕易的調出來了。好,那現在我們已經算出f1,d1,alpha1以後,那我們接下來就是去改變一下每一筆training data的weight。
link |
我們說分類正確的weight就要變小,分類錯誤的weight就要變大,分類錯誤的就要乘1.53,分類錯的就要除1.53。所以這三筆分類錯的,它的weight就變大,分類對的weight就變小。
link |
好,現在有了一組新的weight以後,你就可以再去找一次另外一個decision stump。好,那有一組新的weight,那你找出來的decision stump就不一樣了。
link |
新的decision stump切一刀,切在這個地方,往左是positive,往右是negative,往左是藍色,往右是紅色。你會發現說有三筆data的分類是錯的。
link |
再來,f2的error rate是多少呢?你會根據這每一筆data的weight進行一下計算,你就會發現說,第二個classifier它的error rate是0.21,它的d2是1.94,它的alpha2是0.66。
link |
接下來,這三筆data分類錯,所以給它的weight比較大,這三筆data要把它乘上1.94,那剩下的data通通把它除掉1.94。好,那現在我們就找到了第二個classifier。
link |
那每一個classifier的weight就是它的alpha值,那把它的alpha值寫在這個classifier的旁邊。那接下來找第三個classifier,那這個第三個classifier我們把它找出來,第三個classifier說上面是藍色,下面是紅色。
link |
那它這麼講會導致有三筆data分類錯誤。那計算一下,它的error rate是0.13,你可以計算它的d3,你可以計算它的alpha3。好,如果你現在有更多的iteration的話,你會重新去weight你的這個data。
link |
但是現在我們就說只好三個iteration,所以跑完就結束了。我們得到三個classifier還有它們的weight,然後就結束了。好,最後,我們怎麼把這三個classifier組合起來呢?你把每一個classifier都乘上它們對應的weight,通通加起來,再取它的正負號。
link |
那我們來看一下說,這個加起來的結果到底是怎麼回事。現在有三個decision stump,這三個decision stump把整個二維的平面切成六塊。
link |
那左上角,左上角三個classifier都覺得是藍的。那我們看中間這一塊,中間這一塊,它們兩個覺得是藍的,第一個覺得是紅的,但是它們兩個覺得是藍的,合起來的weight比較大,所以上面這一組就是藍的。
link |
右上角,第一個覺得是紅的,第二個覺得是紅的,第三個覺得是藍的,這兩個紅的合起來比藍的大,這兩個紅的的weight合起來比藍的的weight大,所以又是紅的。
link |
左下角呢,左下角是第一個藍的,第二個藍的,第三個紅的,兩個藍的合起來比紅的大,所以是藍的。
link |
下面這個呢,紅的,藍的,紅的,兩個紅的加起來比藍的大,所以是紅的。右下角呢,三個classifier,三個decision stump都說是紅的,紅的,紅的,所以是紅的。
link |
好,所以呢,現在這三個decision stump沒有一個是0%的error rate,它們都有犯一些錯,它們都有犯一些錯。但當我們把這三個decision stump組合起來的時候,它會告訴我們說這三個區塊是屬於藍色,這三個區塊是屬於紅色,而它的正確率是100%。
link |
所以三個weak的classifier,再把它組合起來,它可以得到好的結果。好,接下來呢,我們就請助教呢,來講一下作業六。
link |
好,各位同學,大家早。我們來繼續講那個R.大Boost。那上次講的是R.大Boost的L.weakness。我把前排的燈關一下,等我一下。
link |
好,那這一次要講,現在要講的是這個理論上的證明。那這邊要證明說呢,假設我們按照那個R.大Boost的algorithm來產生我們最後的classifier。
link |
好,這個最後的classifier呢,這邊寫成大H of X。這個最後classifier大H of X呢,是由一堆weak的classifier Ft所組成的。
link |
如果我們R.大Boost的algorithm我們跑大T一個iteration的話,我們就會得到大T一個weak的classifier,從F1到F大T。好,那這每一個weak的classifier它還有weight,它們還有權重。這樣我們就可以知道說,哪些weak的classifier其實我們應該要參考它多一點,哪些應該被參考的少一點。
link |
那這個權重呢,就是αT。好,那我們把所有的weak classifier的output,而且假設你現在要classify某一個object X,你就把X分別丟到每一個weak的classifier Ft裡面,再把Ft的output乘上它的weight,
link |
像αT,再submention over所有的weak classifier,再取它的正負號,你就可以得到最終的分類的結果。好,那這個αT是什麼呢?我們說這個αT跟這個F0T有關,F0T組成了αT。
link |
而F0T又是什麼呢?F0T是arrow rate。隔壁沒有聲音,好,我處理一下。