back to index
ML Lecture 23-1: Deep Reinforcement Learning
link |
Reinforced Learning其實是一個很大的題目,所以我下面加了一個subtitle,就是學一些皮毛,剩下的時間我們就講一些皮毛。
link |
那這年頭呢,講到Deep Reinforced Learning,大家就會覺得說很興奮,為什麼呢?
link |
因為在2015年2月的時候,Google先在Netflix上面發了一篇用Reinforced Learning的方法來玩Atari的小遊戲,然後都可以通電人類。
link |
後來在2016年的春天呢,又有這個大家都耳熟能詳的AlphaGo,也是可以通電人類的。David Silver就有說,他覺得說AI就是Reinforced Learning加Deep Learning,Reinforced Learning加Deep Learning就是Deep Reinforced Learning,所以這個東西現在講起來,大家都覺得很興奮。
link |
那這個Reinforced Learning是什麼呢?在Reinforced Learning裡面呢,你會有一個Agent跟一個Environment,這樣講呢,可能有點抽象,等一下會舉比較具體的例子告訴大家說,這個Agent跟Environment呢,他們分別可以是些什麼?
link |
我找個猴糖出來吃一下。你可能覺得說,為什麼我一直咳嗽都不會好?但是這其實是沒有什麼關係的,我記得我高三的時候不知道怎麼一直咳嗽咳嗽,咳到大顎,然後後來就好了。
link |
那這個Agent呢,他會有Observation,他會去看這個世界,看到世界的某些種種的變化。那這個Observation呢,又叫做State。你在看Deep Reinforced Learning的時候,你常常會看到一個詞叫做State,其實這個State就是Observation。
link |
這個State這個詞啊,我覺得總是很容易讓人誤導,因為你聽到State這個詞,你總是會想的好像是一個,它翻譯應該翻譯成狀態,那這個狀態感覺是系統的狀態,而不是這個State是環境的狀態,這樣大家了解我的意思嗎?
link |
所以我覺得用Observation這個詞或許是更貼切的,就是你的Machine所看到的東西。所以這個State其實指的是這個環境的狀態,也就是你的Machine所看到的東西。
link |
所以在這個Deep Reinforced Learning的領域才會有這個POMDP這種做法,所謂POMDP就是Partial Observed State,就是我們State只能觀察到一部分的情況。如果今天這個State是Machine本身的State,那怎麼會有那種State我會不知道的情況?
link |
所以如果你把State當成Machine的State,你會搞不清楚那個Partial Observed State那一套想法到底是在幹嘛,也就是因為State其實是環境的State,所以機器是有可能沒有辦法看到這個環境是我的狀態,所以才會有這個Partial Observed State的這個想法。
link |
總之我今天沒有要講那個,但是這個State其實就是Observation,如果你以後有機會看看文獻還在看,看我說的對不對。那Machine會做一些事情,它做的事情就叫做Action,然後它做的這些事情會影響環境,會跟環境產生一些互動,對環境造成一些影響。
link |
那因為它對環境造成的一些影響,它會得到Reward,這個Reward就告訴它說,它的影響是好的還是不好。
link |
我這邊舉一個抽象的例子,比如說機器看到一杯水,然後它就Take一個Action,它的Action就是把水打翻了,那Environment它就得到一個Negative的Reward,因為人告訴它說不要這麼做,所以它就得到一個負向的Reward。
link |
接下來因為水被打翻了,在Renforcement Learning裡面這些發生的事情都是連續的,因為水被打翻了,所以接下來它看到的Observation就是水被打翻的狀態。
link |
它看到水被打翻之後,它決定Take另外一個Action,它決定要把它擦乾淨,人覺得它做得很對,它就得到一個Positive的Reward。機器要做的事情,它生來的目標就是,它要去學習採取那些Action,它根據過去得到的Positive和Negative的Reward,它去學習採取那些可以讓Reward被Maximize的那些Action。
link |
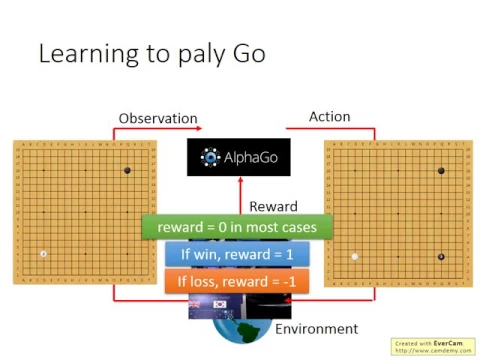
這個就是它存在的目標。如果我們用AlphaGo為例子的話,一開始Machine的Observation是什麼?Machine的Observation就是棋盤,棋盤你可以用一個19X19的Matrix來描述它。
link |
所以如果是AlphaGo,它的Observation就是棋盤。然後接下來它要Take一個Action,它Take的Action是什麼呢?它Take的Action就是落子的位置,它Take的Action就是放一個棋子到棋盤上,下在這裡,下在3-3。
link |
接下來,在圍棋這個遊戲裡面,你的Environment是什麼?你的Environment其實就是你的對手。所以你落子在不同的位置,你就會影響你的對手的反應。
link |
總之你落子以後,你的對手會有反應。所以你看到的這個Observation就變了,假設對手下一個白子在這個地方,你的Observation就變了。
link |
那機器看到另外一個Observation以後,它又要決定它的Action,所以它再Take一個Action,它再採取某一個行動,落子在另外一個位置。
link |
所以下圍棋呢,讓機器下圍棋就是這麼一回事。那今天在圍棋這個Case裡面,它是一個還蠻困難的Reinforcement Learning的Task。
link |
因為在多數的時候,你得到的Reward都是0,因為你落子下去,通常都是什麼事也沒發生,得到Reward就是0。
link |
只有在你贏了或者是輸的時候,你才會得到Reward,如果你贏了,你就得到Reward是1,那如果是輸了,你就得到Reward是-1。
link |
所以做Reinforcement Learning困難的地方就是,有時候你的Reward是很Sparse的,只有少數的Action可以,只有在少數的情況,你才會得到Reward。
link |
所以它的難點就是,機器怎麼在只有少數的Action會得到Reward的情況下,卻發掘正確的Action,這個是一個很困難的問題。
link |
那對Machine來說呢,它要怎麼學習下圍棋呢?它就是不斷地找某一個對手一直下一直下,有時候輸,有時候贏。
link |
然後接下來它就是調整它看到的Observation跟Action之間的關係,它裡面有一個Model,它會調整說看到Observation它要採取什麼Action,它會調整那個Model讓它得到的Reward可以被Maximize。
link |
那我們可以比較一下,如果今天要下圍棋的時候,用Supervised Learning和Unsupervised Learning,你得到的結果會有什麼樣的差別?
link |
你的這個Training方法有什麼樣的差別?如果是Supervised Learning的話,那你就是告訴機器說,看到這樣子的盤勢,你就落子在這個位置,看到另外一個盤勢,你就落子在另外一個位置。
link |
那Supervised Learning會不足的地方是,當我們會用Reinforced Learning的時候,往往是你連人都不知道正確答案是什麼,所以在這個Test你不太容易做Supervised Learning。
link |
因為在圍棋裡面,看到這個盤勢到底下一個位置最好的點是哪裡,其實有時候人也不知道。那機器可以看著棋譜學,但棋譜上面的應對不見得是最Optimal的。
link |
所以用Supervised Learning可以學出一個會下圍棋的Agent,但他可能不是真正最厲害的Agent。如果用Supervised Learning,就是Machine從一個老師那邊學。
link |
然後告訴他說,每次看到這樣子的盤勢,你要下在什麼樣的位置。這個是Supervised Learning。如果是Reinforced Learning,就是讓機器不管他,他就找某一個人去跟他下圍棋。
link |
然後下一下以後,如果贏了,他就得到Positive Reward,輸了就得到Negative Reward。贏了他就知道說,之前的某些下法可能是好的,但是沒有人告訴他什麼樣的下法,在這幾百步裡面,哪幾步是好的,哪幾步是不好的,沒有人告訴他這件事,他要自己想辦法去知道。
link |
在Reinforced Learning裡面,你是從過去的經驗去學習,但是沒有老師告訴你說什麼是好的,什麼是不好的,Machine要自己想辦法。
link |
其實在做Reinforced Learning下圍棋的這個Task裡面,Machine需要大量的Training的Example,他可能要下了三千萬盤以後,他才能夠變得很厲害。但是因為沒有人可以跟Machine下三千萬盤,所以大家都知道AlphaGo的解法就是認兩個Machine,然後他們自己互相。
link |
AlphaGo其實是先做Supervised Learning,讓Machine先認得不錯以後,再讓他去做Reinforced Learning。
link |
Reinforced Learning也可以被用在Chatbot上面,怎麼用呢?我們之前其實也有講過Chatbot是怎麼做的,認一個Sequence-to-Sequence Model,Input是一句話,Output就是機器的回答。
link |
如果你是用Supervised Learning認一個Chatbot,你就是告訴Machine說,如果有人跟你說Hello,你就要講Hi,如果有人跟你說Bye-bye,你就要說Goodbye,這個是Supervised Learning的認法。
link |
如果是Reinforced Learning的認法,就是讓Machine胡亂去跟人講話,講一講以後,人最後就生氣了,Machine就知道說他某一句話可能講得不太好,但是沒有人告訴他說他到底哪一句話講得不好,他要自己去想辦法發掘這件事情。
link |
這個想法聽起來很crazy,但是真的有Chatbot是這樣認的。這個怎麼做呢?因為你要讓Machine去跟人一直講話,然後學習看說人生氣了或者是沒有生氣,然後去學怎麼跟人對話,這個學習太慢了,你可能要講好幾百萬次以後,要跟好幾百萬人對話才會學會。
link |
但是如果一個Agent要跟好幾百萬人對話的話,大家都會很煩,沒有人要跟他對話。所以怎麼辦呢?就用AlphaGo style的講法,他認兩個Agent,然後讓他們互講。
link |
認兩個Chatbot,然後他們就互講。然後他們可能都亂講,要有一個人說See you,然後另外一個人就說See you,然後另外一個人再說See you,就陷入無窮的路了。然後就亂講,就讓兩個Chatbot去對話。然後他對話完以後,還是需要有人告訴他說,他們講得好還是不好。
link |
所以如果是在圍棋裡面比較簡單,因為圍棋的輸贏是很明確的,贏的就是positive,輸的就是negative,輸贏你就寫一個程式來判讀就好了。可是如果是對話的話就很麻煩,因為你可以讓兩個Machine去互相對話,他們兩個可以對話好幾百萬次,但是問題就是你不知道這個對話沒有人告訴那兩個Machine說你們現在聊天到底是聊得好還是聊得不好。
link |
所以這個算是一個上代克服的問題。那這個在文獻上的方法是,這個方法可能不見得是最好的方法,他說就定個rule,我們就人去寫一些規則,那這個規則其實在Pavit裡面也寫得也是蠻簡單的,就蠻簡單的幾條規則。
link |
然後這幾條規則會去檢查說,我看過去那兩個Asian對話的紀錄,如果對講得好的話就給他positive的reward,講得不好就給他negative的reward。我在講好或不好就是人自己主觀定的,所以也不知道人定的好不好。
link |
然後Machine就從這個reward裡面去學說,怎麼樣講才是好。其實我可以在這邊做一個預言,就是我覺得接下來就會有人用電來認這個權霸,雖然現在還沒有看到,但是很快就會有人幹這麼一件事。
link |
這個怎麼做呢?你就認一個discriminator,然後這個discriminator他會看真正人的對話跟那兩個Machine的對話,然後就判斷說,你們現在這兩個Asian的對話像不像人,如果像的話他會去抓說像人還是不像人。
link |
然後接下來呢,那兩個Asian的對話他們就會去想要騙過那個discriminator,讓他講得越來越像人。那個discriminator判斷他說像人或不像人的這個結果就是reward,他等於是用discriminator自動認出給reward的方式。
link |
我相信很快就會有人做這麼一件事了。其實這個reinforcement learning有很多的應用,今天它特別適合的應用就是,如果有一個test,你人也不知道怎麼做,你人不知道怎麼做就沒有label data,這個時候用reinforcement learning是最適合的。
link |
比如說在語音實驗室裡面,我們有讓Machine學會做interactive retrieval,interactive retrieval意思是說有一個搜尋系統,那Machine說我想要找跟US president有關的事情。
link |
那Machine可能覺得說這個US president太廢了,很多人都是美國總統,你到底是要知道跟美國總統什麼有關的事情呢?那Machine會反問他的問題,要求他multiply,他要找跟川普有關的事情。
link |
那Machine可以反問他說你是不是要找的是不是跟選舉有關的事情等等。但是Machine要反問什麼問題,這個人也不知道,我們人也不知道要問什麼樣的問題才是好的。但是你可以用reinforcement learning的方式,來讓Machine學說問什麼樣的問題,它可以得到最高的reward。
link |
那你的reward可能就是最後搜尋的結果,使用者覺得有多好,越好就是reward越高。但是每一次Machine只要每問一個問題,它得到的就是negative,它就會得到一個negative reward。因為每問一個問題,對人來說就是extra effort,所以應該要有一個negative reward。
link |
那reinforcement learning還有很多application,比如說開一個直升機,開一個無人車,或者是據說最近DeepMind用reinforcement learning的方法來幫Google的server節電。
link |
那現在也有reinforcement learning來讓Machine產生句子,在很多task裡面Machine都需要講產生句子,比如說summarization或者是translation。
link |
那這種產生句子的task有時候還蠻麻煩的,為什麼?因為有時候Machine產生出來的句子它是好的,可是卻跟答案不一樣。因為translation有很多種,有一個標準的答案是那樣,但是並不代表Machine現在產生出來的標準答案不一樣,它一定是壞的。
link |
所以這個時候,如果你可以引入reinforcement learning的話,其實是會有幫助的。那reinforcement learning最常用的application就是,現在最常用的application就是打電玩。
link |
那打電玩的application現在已經滿坑滿谷,那如果你想要玩的話,現在都有現成的environment可以讓你在現成的environment上面去玩。
link |
一個叫做Gym,這都是OpenAI公司開發的。那這個Gym比較舊,最近他們又開了一個Universe,Universe裡面有很多那種3D的遊戲。那每次講說讓Machine玩遊戲,就會有一個問題說,可是Machine不是本來就已經會玩遊戲了嗎?
link |
在那些遊戲裡面不是本來就已經有一個AI了嗎?但是現在你要讓Machine用reinforcement learning的方法去學玩遊戲,跟那些已經內建的AI其實是不一樣的。
link |
因為Machine它學怎麼玩這個遊戲其實是跟人一樣,它是坐在螢幕前的,也就是說它看到的東西並不是從那個程式裡面去擷取什麼東西出來,它看到的東西就是那個螢幕畫面,它看到的東西跟人一樣就是pixel。
link |
當你用reinforcement learning讓Machine學習玩這些電玩的時候,Machine看到的就是pixel。然後再來呢,它要take哪一個action,它看到這個畫面,它要做什麼事情,它自己決定。
link |
並不是人寫程式告訴它說,if你看到這個東西,then你做什麼,它是自己學出來的。比喻來說,你可以讓Machine玩Space Invader,Space Invader就是這個叫什麼呢,我想想看,叫小蜜蜂還是大蜂蜂,雖然它的translation不太重要。
link |
我們等一下舉例的時候都用這個來做例子,我們可以稍微解說一下這個遊戲。在這個遊戲裡面你可以take的action有三個,就是左右移動跟開火。
link |
它怎麼玩這個video game呢,整個scenario是這個樣子。首先呢,Machine會看到一個observation,這個observation就是螢幕的畫面,也就是螢幕畫面裡面的pixel。
link |
那開始的observation我們就叫它S1,所以一開始Machine看到一個S1,那這個S1其實就是一個matrix,那這個matrix其實就是每一個pixel就是用一個vector來描述它,所以這邊應該是一個三維的tensor,這個是一個matrix,但是它是有顏色的嘛,所以它是三維的。
link |
那Machine看到這個畫面以後,它要決定它要take哪一個action,它現在只有三個action可以選擇,比如說它決定要往右移。
link |
那每次Machinetake一個action以後,它會得到一個reward,但是因為只是往右移,這個reward是什麼,這個reward就是左上角的這個分數,就是它的reward,那往右移不會得到任何的reward,所以得到的rewardR1呢是零。
link |
那Machinetake完這個action以後,它的action會影響了環境,所以Machine看到的observation就不一樣。
link |
那現在呢,Machine看到的observation叫做S2,有點不一樣,因為它自己往右移了,當然這些外星人也會稍微移動一點,不過這個跟Machinetake的action是沒有關係的,但是有時候環境的變化本來就會跟那個action沒有關係,有時候環境的變化會是純粹隨機的,跟Machinetake的action是沒有關係的。
link |
好,那看到S2,然後接下來呢,我這邊講一下,通常這個環境會有一些random的變化,而環境這個random的變化跟Machinetake的action其實是沒有什麼關係的,比如說這邊突然多出一個子彈,那這些外星人什麼時候要放子彈,我覺得應該就是隨機的。
link |
然後呢,Machine看到S2以後,它要決定它要take哪一個action,這個是A2,假設它就決定說它要射擊了,然後它就決定射擊,然後假設它成功地殺了一隻外星人,它就會得到一個reward,那我發現說殺不同外星人其實得到的分數是不一樣的,假設它殺了一個五分的外星人,那它看到的observation就變了,少了一隻外星人。
link |
所以這個是第三個observation,那這個process就一直進行下去,一直進行下去,直到某一天,我們在T大T的回合的時候,Machine take action,A大T,然後它得到了reward,R大T,進入了另外一個state。
link |
那這個state呢,它會,它是一個terminal的state,它會讓這個遊戲結束,那在這個Space Invader這個遊戲裡面呢,terminal state就是你被殺死了,就結束了。
link |
所以今天這個Machine可能take一個action比如說往左移,那得到reward,然後不好,不小心就撞到了Alien的子彈,然後它就死了,所以遊戲就結束了。好,那從這個遊戲的開始到結束呢,叫做一個episode。
link |
那對Machine來說它要做的事情就是不斷的去玩這個遊戲,那它要學習呢,怎麼在一個episode裡面去maximize它可以得到的reward,去maximize它在整個episode裡面可以得到的這個total的reward。
link |
就是它必須要在死之前殺最多的外星人,它要殺最多的外星人,而且它可能需要閃避外星人的子彈,讓自己不要那麼容易被殺死。那reinforcement learning的難點在哪裡呢?
link |
它有兩個難點。第一個難點呢,是reward的出現往往是會有delay,也就是說,比如說在這個Space Invaders裡面呢,其實只有開火這件事情才能得到reward,都是開火以後才得到reward。
link |
但是你知道如果Machine只知道說開火以後就得到reward,它最後認出來的結果就是它只會瘋狂開火,對它來說,往左移往右移沒有任何reward,它不想做。
link |
但實際上,往左移往右移這些movie,它對開火能不能夠得到reward這件事情是有很關鍵的影響。雖然說這些往左移往右移的action本身沒有辦法讓你得到任何reward,但它可以幫助你在未來得到reward。
link |
那這件事情其實就像是規劃未來一樣,所以Machine需要有這種遠見,它要有這種vision,它才能夠把這些電玩完好。那其實在夏維奇裡面有時候也是一樣,有時候短期的犧牲可以換來最後比較好的結果,就像是虛竹把自己的紙堵死一塊,結果最後反而贏了。
link |
另外一個就是,你的action所採取的行為會影響它之後所看到的東西,所以你的action要學會去探索這個世界。
link |
比如說如果在這個space invader裡面,你的action總是只會往左移往右移,它從來不開火,它就永遠不知道開火可以得到reward,或者是它從來沒有去試著擊殺那個紫色的母艦,它就永遠不知道擊殺那個東西可以得到很高的reward。
link |
所以要讓Machine知道說要去explore這件事情,它要去探索它沒有做過的行為,雖然說這個行為可能有好的結果壞的結果,但是要探索沒有做過的行為,在reinforcement learning裡面也是重要的一件事情。
link |
在下課之前,我們要講一下我們等一下想要講什麼。我知道說reinforcement learning其實有一個typical的講法,就是你要先講Markov decision process,但是如果我們今天想先講Markov decision process的話,講完Markov decision process其實就下課了,你就會只聽到Markov decision process。
link |
而且太多課有講Markov decision process,所以我就覺得我們不要從Markov decision process開始講起。我知道說在reinforcement learning裡面過去很紅的一個方法叫做deep Q-network,但我們今天也不講deep Q-network。
link |
為什麼呢?因為其實那個東西現在都已經被打趴了,現在最強的方法叫做A3C,deep reinforcement learning已經有點退流行了,你會發現說在那個Gene裡面最強的那些agent都是用A3C的,像我剛才看到的那個例子,剛剛看到那個自己玩Space Invader的例子就是用A3C的。
link |
所以我想說我們不如直接來講A3C,就是迎頭趕上的概念,我們直接來講最新的東西。
link |
好,那要講A3C之前,我們需要知道什麼事情呢?我們需要知道說這個reinforcement learning的方法分成兩大塊,一個是policy-based的方法,一個是value-based的方法。
link |
value-based的方法其實應該是比較後來才有,應該先有value-based的方法,所以一般教科書都是講value-based的方法比較多,講policy-based的方法比較少。
link |
如果你看那個Saturn,就是有一本deep reinforcement learning的bible,叫做Saturn寫的,它在一個97版的教科書裡面,policy的方法就講得很少,就一節而已。
link |
但是它今年又再版,它還在撰寫中,我暑假的時候載下來的教科書的內容跟最近載的內容完全不一樣,差很多。
link |
它最近在改一本教科書,policy gradient就有一整個章節在講policy gradient。好,那在policy-based的方法裡面,你會認一個負責做事的actor,
link |
那在value-based的方法裡面,你會認一個不做事的critic,專門批評的不做事,但是我們要把actor跟critic加起來,叫做actor-critic的方法。
link |
那現在最強的方法就是這個asynchronous advantage actor-critic這個方法,它縮寫的叫做A3字,所以我們等一下就講一下actor-critic這個方法。
link |
那你可能會問說,最潮的alpha-code是用什麼方法的?如果你仔細讀一下alpha-code的配合的話,它是各種方法的大雜燴。
link |
它裡面其實有policy gradient的方法,policy-based的方法,它也有value-based的方法,那其實它還有model-based的方法,我就沒有講到model-based的方法。
link |
model-based的方法是指那個multicolor tree search那一段,算是model-based的方法。不過像model-based的方法就是你要預測未來會發生什麼事,你有一個對未來的世界的理解,那你就預測未來會發生什麼事。
link |
這種方法其實應該是在只有棋類遊戲是比較有用的。如果是像打電玩的話,我就沒有看到什麼model-based的方法是成功的結果。在打電玩裡面,我想你要預測未來會發生的狀況是比較難的。
link |
它未來會發生的狀況是難以窮取的。不像圍棋,雖然未來會發生的狀況很多,但你還是可以舉出來。但是如果是電玩的話,我就很少看到model-based的方法,看起來做model-based的方法在電玩上是比較困難。
link |
以下是一些reference,如果你想學更多的話。David Silver有十堂課,他的內容基本上就是被賞識的Certain教科書講的,他講了十堂課有一個半小時。
link |
他沒講太多deep reinforcement learning的東西,但是他有一個deep reinforcement learning的tutorial,在video lecture的網站上可以找到。另外你可以找到OpenAI的Jones Goldman的lecture,他的lecture講的是policy-based的方法。
link |
我們在這邊休息十分鐘,我們11點30分的時候回來。
link |
那我們就先來講怎麼學一個actor,所謂的actor是什麼呢?我們在開學的時候就有說過,machine learning在做的事情其實就是找一個function。
link |
其實在reinforcement learning裡面,reinforcement learning也是machine learning的一種,我們要做的事情也是找一個function。這個function就是所謂的,而且我發現我沒有寫錯,我本來想要說我應該寫actor,但這邊我又寫錯了。
link |
actor就是一個function,這個actor我們通常就寫成pi,我們用pi來代表這個function。這個function的input是什麼?這個function的input就是machine看到的observation。
link |
它的output是什麼?它的output就是machine要採取的action,所以observation就是我們現在要找的function的input,action就是我們現在要找的function的output。
link |
reward來幫助我們找出這個function,也就是幫助我們找出actor。那在有些文獻上,這個actor又叫做policy,所以叫做policy的時候,它指的就是那個actor。
link |
那我們說找這個function有三個步驟,deep learning很簡單的就是三個步驟。第一個步驟就是決定你的function長什麼樣子,決定你的function的space。
link |
他們說neural network,它決定了一個function的space。所以我們今天的actor,它可以就是一個neural network,而如果你的actor就是一個neural network,那你就是在做deep reinforcement。
link |
所以這個neural network的input就是machine看到的observation,這個observation就是一個pixel,你可以把它描述成一個用一個vector來描述,或者是用一個matrix來描述。那output呢?output就是你現在可以採取的action,或者是我們直接看下面這個例子可能會比較清楚。
link |
output是什麼呢?那input就是pixel,那你把neural network當做actor,但它可能不只是一個簡單的deep reinforcement network,因為你的input現在是一張image,所以裡面應該會有convolution layer,所以它應該是會用convolution neural network。
link |
那output的地方呢?你現在有幾個可以採取的action,output就有幾個dimension,假設我們現在在玩space invasion這個遊戲,我們可以採取的action就是左移右移跟開火。
link |
那output呢?就只需要output layer,就只需要三個neural,就只需要三個dimension,分別代表了左移右移跟開火。那這個neural network怎麼決定這個actor要採取哪一個action呢?
link |
通常的做法是這樣,你把這個image丟到neural network裡面去,它就會告訴你說每一個output的dimension,也就是每一個action所對應的分數。
link |
那你可以採取分數最高的action,比如說left的分數最高,那你的machine現在假設你已經找好這個actor,那你的machine看到這個畫面,它可能就採取left。
link |
在做policy gradient的時候呢,我們通常會假設你的actor它是stochastic,你的這個policy是stochastic,所以stochastic的意思是說,你的policy的output其實是一個機率。
link |
也就是說,如果你的分數是0.7,0.2,0.1,那你有70%的機率會left,你有20%的機率會right,你有10%的機率會fire。
link |
看到同樣的畫面的時候,根據機率,其實會,同一個actor它其實會採取不同的action。
link |
那這種stochastic的做法其實很多時候是會有好處的,比如說,想像你要玩猜拳,那你要玩猜拳的時候,如果你的actor是deterministic的,你就可能都只會出石頭,那你就會一直輸掉,就跟小叮噹一樣。
link |
所以有時候我們會需要stochastic的這種policy,那在以下的lecture裡面,我們都假設我們的actor是stochastic。
link |
那用neural network來當作這個actor,有什麼好處呢?
link |
那傳統的做法是直接存一個table,而這個table告訴我說,看到這個observation,我就採取這個action,看到另外一個observation,我就採取另外一個action。
link |
那這個做法,你要玩這種電玩是不行的,因為電玩的input是pixel,你要窮取所有可能的pixel是沒有辦法做到的。
link |
所以你一定要用neural network才能夠讓machine來把這個電玩玩好。用neural network的好處就是,neural network它是可以舉一反三的。
link |
今天就算有些畫面,你完全沒有看過,machine從來沒有看過,但是因為neural network的特性,你給它input一個東西,它總是會有output,所以就算是它沒有看過的東西,它也有可能可以得到一個合理的結果。
link |
所以用neural network的好處就是,它是比較generalized。
link |
再來第二個步驟就是,我們要決定一個function的好壞,也就是我們要決定一個actor的好壞。
link |
那在supervised learning裡面,我們怎麼決定一個function的好壞呢?我們會說,給我們一個neural network,它的參數,假設我們已經知道了就是theta,我有一堆training example,我就說,假設說image的classification,我就把image丟進去,然後看它的output跟target像不像。
link |
如果越像的話,代表這個function就越好,然後定一個東西叫做loss,然後我們會算每一個example的loss合起來就是total loss,我們需要找一個參數去minimize這個total loss。
link |
那其實在reinforcement learning裡面,一個actor的好壞的定義是非常類似的,怎麼樣類似法呢?假設我們現在有一個actor,我們知道actor就是一個neural network,這個neural network我們假設它的參數就是一個theta。
link |
所以一個actor我們會用pi下標theta來表示它,一個actor是一個function,它的input就是一個s,這個s就是machine看到的actor看到的這個observation。
link |
那怎麼知道一個actor它表現的是好還是不好呢?我們就讓這個actor實際的去玩一下這個遊戲。假設我們拿theta這個actor,實際上去玩一個遊戲,然後他就玩了一個episode,
link |
他說他看到S1配A1得到R1,再看到S2配A2再得到R2,最後就結束了。那這個時候呢,他在玩完這個遊戲以後,他得到的total reward我們可以寫成Rtheta,
link |
這個Rtheta就是R1加R2一直加到R大T,把所有在每一個step得到的reward合起來,就是在這一個episode裡面你得到的total reward。而episode裡面的total reward才是我們要去maximize的對象。
link |
我們不是要去maximize每一個step的reward,我們是要去maximize整個遊戲玩完的時候我們會得到的total reward。但是今天就算是我們拿的是同一個actor來玩這個遊戲,每次玩的時候Rtheta其實都會是不一樣的。
link |
為什麼?因為兩個原因。首先你的actor本身如果是stochastic,看到同樣的場景,他也會採取不同的action。所以就算是同一個actor,同一組參數,每次玩的時候你得到Rtheta,也會是不一樣。
link |
再來,遊戲本身他也有隨機性,就算你採取同樣的action,你看到的observation,每一次也可能都不一樣。所以遊戲本身也有隨機性,所以Rtheta其實是一個random variable。
link |
所以我們希望做的事情不是去maximize某一次玩遊戲的時候得到的Rtheta,我們希望去maximize的其實是Rtheta的期望值。就我們拿這個actor玩了千百次的遊戲以後,最後同一個actor玩千百次遊戲以後,每次的Rtheta都不一樣,但這個Rtheta的期望值是多少?
link |
我們這邊用Rtheta來表示他的期望值,我們希望這個期望值越大越好。這個期望值就衡量了某一個actor他的好壞,好的actor他的期望值就應該要比較大。
link |
那這個期望值實際上要怎麼計算出來呢?你可以這麼做,我們假設一場遊戲就是一個trajectory tau,一場遊戲我們就用一個tau來表示。
link |
那tau是一個sequence,裡面包含了state,還有看到這個state,看到這個observation,裡面包含observation,看到這個observation以後take的action,還有得到的reward,還有see的observation,take的action得到的reward等等,它是一個sequence。
link |
那R的tau代表說,這個trajectory在這場遊戲裡面最後得到total reward,就是把所有的小Rsummation起來就是total的reward。
link |
那當我們用某一個actor去玩這個遊戲的時候,每一個tau都會有一個出現的機率,這個大家可以想像嗎?就是tau代表某一種可能的從遊戲開始到結束的過程。
link |
它代表了某一種過程,那這個過程有千千百百種,但是當你選擇了一個actor去玩這個遊戲的時候,你可能只會看到某一些的過程,某一些過程特別容易出現,某一些過程比較不容易出現。
link |
比如說你現在的這個actor,他是一個很智障的actor,他看到敵人的子彈就要湊上去被自殺,那你看到的每一個tau都是你自己控制的太空船挪一下就被自殺了。
link |
所以當你選擇actor的時候,你就會只有某一些tau特別容易出現,只有某一些遊戲的過程特別容易出現,那每一個遊戲出現的過程你可以用一個機率來描述它。
link |
所以我們這邊寫一個P of tau,d,θ,就是說當我的actor的參數是θ的時候,tau這個過程出現的機率。如果你可以接受這樣子的話,那Rθ的期望值這個Rθ bar就寫成了summation over所有可能的tau,就是所有可能的遊戲進行的過程。
link |
當然這個非常非常非常的多,尤其今天如果我們又是玩電玩,它是連續的,它有非常非常多的可能,這個tau是難以窮取的。
link |
我們現在假設我們可以窮取它,那每一個tau都有一個機率,用tau,d,θ,每一個tau的reward,R的tau,把這兩個乘起來,再summation over所有遊戲可能的tau的話,那你就得到了你這個actor他的期望的reward。
link |
實際上要窮取所有的tau是不可能的,所以怎麼做?你讓你的actor去玩這個遊戲,玩n場,得到tau1,tau2,到tauN。
link |
這n場就好像是n比training data這個樣子。玩n場這個遊戲,就好像是你從P of tau given theta去sample出大N的tau來,對不對?
link |
假設我某一個tau,它的這個機率特別大,那它就特別容易在n次sample裡面被sample出來,你這個sample出來的tau應該跟這個機率是成正比。
link |
所以當我們用這個actor去玩n場遊戲的時候,就好像是從P of tau given theta這個機率裡面去做n次sample一樣。
link |
好,那你最後得到的結果是什麼?你最後就是把這個大N的tau的reward都算出來,然後再平均起來,你就可以拿這一下去近似這一下,對不對?
link |
因為這個應該沒有什麼問題,所以接下來你要記得說,submission over你的n次sample做平均,對你的n次sample做平均,其實就可以近似從theta sample tau出來,再submission over所有的tau。
link |
submission over所有的tau乘上機率這件事情跟samplen次這件事情是可以近似的。
link |
接下來我們就進入最後第三步,我們知道怎麼衡量一個actor,接下來就是要選一個最好的actor。
link |
選一個最好的actor,其實我們就是用gradient descent,因為我們現在已經有我們的objective function,我們已經找到目標了,我們的目標就是要最大化這個rtheta,最大化這個rtheta bar,我們找一個參數,最大化rtheta bar,rtheta bar的式子也有了,就寫在這邊。
link |
所以接下來我們就可以用gradient ascent的方法去找一個theta,讓rtheta bar的值最大,這邊不是用gradient descent,gradient descent是要去minimize一個東西用gradient descent,maximize一個東西用gradient ascent。
link |
那怎麼做呢?那很簡單,你就先隨機的找一個初始的theta0,隨機找一個初始的actor,然後計算說在使用初始的actor的情況下,在使用初始的actor的情況下,你的這個參數對rtheta bar的微分。
link |
你算出你的參數對rtheta bar的微分,然後再去update你的參數得到theta1,接下來再算theta1對rbar的微分,然後再update theta1得到theta2。
link |
做這個process,最後你就可以得到一個可以讓rbar最大的actor,當然你會有什麼local argument等等問題,就我們做deep learning的時候試一下。
link |
那所謂的這個rtheta bar的gradient是什麼呢?就假設這個theta裡面就是一堆參數,有一堆weight,有一堆bias,那你就是把所有的weight跟所有的bias都對rtheta bar去偏微分,把它串起來變成一個vector,就是這個gradient。
link |
好,那接下來就是實際來這個運算一下。好,如果我們要計算rtheta bar的gradient,那rtheta bar呢,它等於summation over the total R of tau times P of tau given theta。
link |
這個R of tau跟theta是沒任何關係的啦,只有P of tau given theta跟theta才是有關係的。
link |
所以你做gradient的時候,你只需要對P of tau given theta做gradient就好,R of tau呢,不需要對theta做gradient。
link |
所以R of tau就算是不可微的,也沒差,因為我們本來就沒有要微分它。就算R of tau它是一個hater,我們不知道它的式子,我們只知道說,把tau代進去,R的output會是什麼,也無所謂,也能夠做。
link |
因為我們在這邊,我們完全不需要知道,在這邊呢,好,我們換一下,我們用那個。
link |
好,這邊呢,就算R of tau不可微,或者是不知道它的function,也沒差,因為我們不需要對它做微分,所以我們根本就不需要知道它長什麼樣子,我們只需要知道,把tau放進去的時候,它output的值會是多少就行了,所以它可以完全徹頭徹尾就是個hater。
link |
那實際上對我們來說,R of tau也確實徹頭徹尾就是個hater,因為R of tau其實它是取決於我們會得到多少reward,那個reward是環境給我們,所以我們通常對環境是沒有理解的。
link |
比如說,在玩Atari的遊戲裡面,那個reward是那個Atari的那個程式給我們,那如果程式裡面是有一些隨機的東西的話,你會根本搞不清楚那個程式它的內容是什麼,所以我們其實根本不知道R of tau是長什麼樣子,不過反正你不需要知道它長什麼樣子。
link |
好,那接下來怎麼做呢?接下來要做一件事情,做這件事情是為了要讓P of tau given theta出現,那把P of tau given theta放在分子的地方,也放在分母的地方,所以等於什麼事都沒有做。
link |
接下來,這一項會等於這一項,為什麼?你知道這個,dx分之d log f of x,會等於這個f of x分之dx分之d f of x,所以對log P of tau given theta做歸點,等於對P of tau given theta做歸點,再除以P of tau given theta。
link |
所以這一項就是這一項,然後我們之前看到說,如果你看到summation over所有的tau,再乘上P of tau given theta的話,當我們看到這個紅色的框框的時候,我們可以把它換成sampling。
link |
所以這件事情,我們可以換成拿theta去玩n次遊戲得到tau1跟taun,對tau1跟taun,我們都算出它的out of tau,再summation over所有sample出來的結果再去平均。
link |
接下來的問題就是,怎麼計算這一項,怎麼計算log P of tau given theta的歸點,其實這一項也不難算,所以我們可以很快的帶過去。
link |
要算這一項,你要知道P of tau given theta,怎麼算P of tau given theta,首先你要知道這個P of tau given theta等於P of s1,也就是遊戲開始的畫面出現的機率。
link |
像Space Invaders,我記得它每次出現的開始畫面應該都是一樣,所以P of s1只有某一個畫面的機率是1,其他都是0。那有些遊戲每次起始的畫面是不一樣的,所以這邊需要有個機率。
link |
接下來,根據你的theta,你在s1會有某一個機率採取a1,然後接下來,根據你在s1採取a1這件事情,你會得到r1然後跳到s2,這中間是有一個機率的,取決於那個遊戲。
link |
接下來,你在s2採取a2,這個機率取決於你的model theta,接下來看到s2a2,你得到r2跟s3,這個是取決於那個遊戲。
link |
所以,整個畫起來就是這個樣子,其中某些項跟你的actor是沒關係的,只有畫紅色底線這一項跟你的actor是有關係的,actor這個我們可以略過。
link |
接下來,你就取個log,取log就只是相乘變相加而已。
link |
接下來,你可以要對theta做歸點,那跟theta無關的項,跟你的actor無關的項只取決於那個遊戲的主機,遊戲的部分那一項就可以直接被刪掉。
link |
都跟歸點是無關的,所以這一項可以刪掉,這一項可以刪掉,就只剩下這個部分。
link |
最後,我們算出來的結果就是,rtheta bar的歸點,它可以被approximate成什麼樣子呢?它可以被approximate成sample出n個tau,每個tau都算出它的reward,再乘上每一個tau出現的機率的log的歸點。
link |
那出現的機率的log的歸點,我們又可以把它算成就是summation over在這個tau裡面,我們所有採取過的action,它的機率取log的歸點。
link |
這一項就等於這一項,我只是把它置換下來。
link |
把這個summation移出去,把這個r乘進來,我們可以寫成這樣一個式子。這個式子告訴我們什麼?
link |
這個式子告訴我們說,我們現在要做的事情就是,假設在我們的sample data裡面,在s上標n下標t這個state,我們曾經採取了這個a上標n下標t這個action,我們就計算這件事情根據我們的model現在發生的機率,然後把它取log,然後計算它的歸點。
link |
這項歸點前面會呈現一項,呈現這一項是這一個trajectory,在那一次玩遊戲裡面,在看到這個s產生這個a的那一次遊戲裡面,我們總共得到的total reward。
link |
這件事情,這整個式子其實是非常直覺的,你用這一項去update你的model其實是非常直覺的,因為它的意思就是說,假設在某一次玩遊戲的過程中,在某一次玩遊戲的過程,在TaoN這一次玩遊戲的過程中,
link |
我們在snt採取了action,a上標n下標t,而最後導致的結果是整個遊戲的out of Tao是正的,我得到一個正的reward,那我們就會希望說這個機率是越大越好。
link |
我在某一次玩遊戲的時候,我在看到某一個observation的時候,我採取某一個action,而最後整個遊戲得到了好的結果,那我們就要調整我們的參數,讓在這個observation採取那個action的機率變大。
link |
反之呢,如果我們在玩遊戲的過程中發現說,我採取在某一個state採取某一個action,結果發現得到的reward居然是負的,那之後呢,在看到同樣的state的時候,在看到同樣的observation的時候,
link |
我們就希望採取會讓我們看到negative reward的那個action,它的機率是變小的,所以這整個式子是非常直覺的。
link |
那這邊要注意的事情就是,這一項是在某一個時間點t的observation採取的某一個action,但是我們必須要把它乘上整個trajectory的reward,而不是採取那個action以後所產生的reward。
link |
那這件事情也是非常直覺的,你直覺想,你就應該這麼做。假設我們現在不是考慮整個trajectory的reward,而是考慮採取actionA上標N下標T以後得到rewardR上標N下標T的話,那會變成說只有fire會得到reward。
link |
其他的action你只要採取left或right,你只要移動得到reward,都是零。所以你的machine就永遠不會想要讓left跟right產生的機率增加,它只會讓fire的機率增加。最後你認出來的agent,它就只會一直在原地開火而已。
link |
所以這個式子其實是很直覺的。那這邊其實還有一個問題,就是為什麼要取log呢?
link |
這件事情也是有辦法解釋的,這一項我們說它其實就是對P的微分再除掉P的機率,那是微分再除掉機率。
link |
你可能會想說,加這一項多不自然啊,把這一項就直接換成分子這一項,不是感覺很好嗎?為什麼下面還要除一個P of A given S的機率呢?
link |
但是你想想看,這件事情是很有道理的。假設我們現在讓machine去玩N次遊戲,某一個state在第13次、第15次、第17次、第33次的遊戲裡面,我們看到了這個observation,看到了同一個observation。
link |
那因為我們現在的actor它其實是stochastic,所以它有一個機率,所以看到同樣的S,它不見得採取同樣的action。
link |
所以假設在第13個trajectory,它採取actionA,那在第17個它採取B,在15個採取B,在33也採取B,然後最後呢,toss13的這個trajectory得到的reward比較大,是2,另外3次得到的reward比較小,是1。
link |
但是今天實際上你在做update的時候啊,它會偏好那些出現次數比較多的action,就算那些action並沒有真的比較好,對不對?
link |
因為你是submission over所有你sample到的結果,所以如果tag actionB這件事情出現的次數比較多,就算它得到的reward沒有比較大,machine把這件事情的機率調高,也可以增加最後這一項的結果。
link |
而雖然這個action感覺比較好,但是因為它很罕見,所以你調高這個action出現的機率,最後也不會對你的cost function,最後對你的要maximize的對象,對你的objective的影響也是比較小的,所以machine就會變成不想要maximize actionA出現的機率,轉而maximize actionB出現的機率。
link |
所以這就是為什麼我們這邊需要除掉一個機率,除掉這個機率的好處就是做一個normalization,如果有某一個action,它本來出現的機率就比較高,那它除掉的值就比較大,你讓它除掉一個比較大的值,machine最後在optimize的時候,就不會偏好那些出現機率比較高的action。
link |
然後另外一件事情是,這個聽起來都很ok,但是這邊有一個問題,什麼樣的問題呢?你有沒有想過假設out of all永遠是正的,會發生什麼事呢?
link |
因為像玩space invader,你得到的reward都是正的,你殺了外星人就得到正的分數,最糟就是殺不到外星人得到的分數是零而已,所以這個out of all永遠都是正的,在理想的狀況下這件事情不會構成問題。
link |
為什麼?假設在某一個state我們可以採取三個action A B C,那這三個action採取的結果我們得到的out of all都是正,但是這個正有大有小,假設A跟C的out of all比較大,B的out of all比較小,那經過update以後,你還是會讓B出現的機率變小,AC出現的機率變大。
link |
因為這邊是一個機率,所以它其實會做normalization,或者是你為了要讓它是機率,你的最後network的output它是softmax layer,所以就算是在算規定的時候,你想讓這三個action的機率增加,但是增加量比較少的那一個,最後它的機率其實是會減小,所以聽起來不太成為問題。
link |
但是實作的時候,我們做的事情是sampling,所以今天某一個state你可以採取ABC三個action,但是有可能你就只sample到B這個action跟C這個action,而A這個action你就沒sample到,這很有可能,你sample就幾次而已,所以你可能A這個action,machine從來就沒玩過它,沒試過它,不知道它的out of all到底有多大。
link |
這個時候你就遇到問題了,因為B跟C他們機率都會增加,那A沒sample到,沒sample到的人機率就自動減少,被sample到的人在做完規定後機率自動就會增加,這樣就變成問題了。
link |
所以怎麼辦?這邊有一個很簡單的想法就是,我們希望這個out of all有正有負,不要都是正,那怎麼避免它都是正的呢?你要把out of all減掉一個bias,這個bias你其實要自己設計,你要自己設計一下有一個bias到底應該要放什麼值,設計一下這個bias,讓你的out of all如果都是正的,減掉一個正的bias,讓它有正有負。
link |
如果你今天的trajectory某一個tau1它是特別好的,它好過這個b叫做baseline,它好過baseline你才把那個action的機率增加,小於baseline你把那個action的機率減少,那這樣子就不會造成說某個action沒被sample到,它的機率就會變小。
link |
因為快要下課了,所以我們不見得需要講完quity,quity是什麼呢?quity就是我們認一個network它不做事,其實也可以從quity裡面得到一個actor,這個東西就是q倫理,但我們今天就不要講q倫理。
link |
quity就是這樣子,你認一個function,這個function可以告訴你說,我們現在看到某一個observation的時候,這個observation有多好。
link |
比如說如果今天看到這樣子的observation,把它丟到quity裡面去,它可能會output一個很大的正值,因為我們還有很多alien可以殺,所以你會得到很高的分數。
link |
看到這個狀況,你可能就會得到相對比較少的值,因為alien變得比較少,而且你的那個屏障已經消失了,紅色是屏障,屏障消失了,所以你可能很快就會死了。
link |
actor跟quity可以合在一起train,合在一起train的好處就是,我們不一定需要在這堂課解釋完,我們永遠可以留到下學期MLDS再講。
link |
我最後只是想要demo一下,到底如果用actor跟quity這種方法可以做到什麼樣的地步。
link |
現在用actor跟quity這些東西,大家都在玩3D遊戲了。
link |
這個就是machine就自己認,它會走它沒有看過的迷宮,它會知道要去吃綠色的蘋果。
link |
雖然這是個3D遊戲,它看到的就是pixel,跟我們人一樣。
link |
所以用A3C可以硬玩這種遊戲,這個是硬玩一發賽車遊戲,硬開個賽車。
link |
它看到的就是pixel,跟我們人一樣。
link |
我記得它的reward好像是速度,就是速度越快,reward就越高,所以它會拼命想要加速。
link |
但是撞到東西就會減速,所以它會避免撞到東西,比如說前面有一輛車,然後它就避開。
link |
這學期上課就上到這邊,我本來想要講一個感性的結論,但我其實沒有什麼感性的結論。
link |
而且已經快下課了,所以不太好講什麼感性的結論。
link |
其實這學期有一個東西很重要的沒有教的是什麼呢?
link |
是machine learning裡面比較偏向統計理論的部分,比如說VC dimension。
link |
但是電機系未來會有其他課教machine learning裡面比較統計的部分。就我所知,王逸祥老師也要開統計機器學習。
link |
但是他會講比較偏向統計理論的東西,所以我們這學期內容是沒有有關統計理論的部分。
link |
有人可能說,如果你覺得我教得太簡單了,那你就可以去聽王逸祥老師的課。
link |
如果你覺得我教得太難了,那沒有關係,余天麗老師要開機器學習導論是給大學生的,所以你以後可以先修機器學習導論。
link |
所以以後電機系會有很多機器學習的課。
link |
那其實我上課的內容跟宣田的機器學習的基石還有技法,其實我是盡量有錯開的,所以就算是你修過基石跟技法,我相信你在這門課裡面應該也是有聽到不一樣的東西。
link |
或者是你之後再去聽基石跟技法,你也會發現說我講的東西跟宣田講的東西,其實是我盡量沒有做到太多的重複。
link |
好,我們這邊上課就上到這邊,謝謝大家,謝謝。