back to index
ML Lecture 23-2: Policy Gradient (Supplementary Explanation)
link |
那我猜剛才那個policy規點的這個部分啊,你其實沒有聽得太懂。就算你聽得懂了四字,你也不知道要如何實作。
link |
好,所以我們來講一下,如果是實際實作的時候,你到底是怎麼做的?
link |
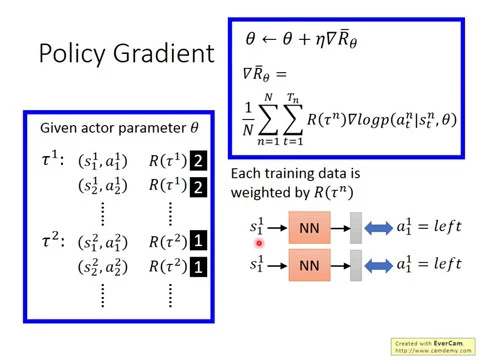
怎麼做呢?首先這整個大的picture是這樣,我們先有一個actor,他的參數是theta,那一開始呢,你就先random initialize就好了。
link |
好,接下來呢,你有了這個初始的actor,theta以後,你就拿這個初始的actor,theta,去玩n次遊戲。
link |
那玩n次遊戲,你就收集到n個trajectory,那假設你收集到一個trajectory1,那這個trajectory1裡面有state1,在state1呢,採取了actionA1,我把我的雷射筆交出來。
link |
好,在state2呢,採取了actionA2,然後玩完這個遊戲以後呢,你可以算出一個total reward out of all。好,那有一個trajectory2,在trajectory2裡面,你也有trajectory2的state1,還有在state1採取了actionA1,你有trajectory2的state2,你有在state2裡面採取了actionA2,一樣可以算出trajectory2的reward。
link |
好,那這個東西都沒有什麼問題,你有一個policy,random初始的,去玩n次小遊戲,這個實作上沒有什麼問題,你把state action都記錄下來,沒有什麼問題。
link |
好,那有了這些data以後,你就拿這些data去update你的參數setup。
link |
怎麼拿這些dataupdate你的參數setup呢?就用剛才我們在前頁投影片裡面推出來的這個式子。那等一下呢,我們會再詳細解釋一下,這個式子,到底實作上,你要怎麼implement。
link |
現在看起來有點複雜,或者是式子你懂,實際上要怎麼做你也許不太清楚,那沒關係,反正就是我們收集,等於我們等一下再解釋,反正我們就是收集到一堆data以後,我們可以拿這些data去update我們的參數。
link |
那update完參數以後,你有了一個新的actor,你有了一個新的actor以後,你再去玩n次遊戲,因為actor是新的,他跟之前的actor不一樣了,所以在玩n次遊戲的時候,你可能會得到不太一樣的分佈,你會得到一個不太一樣的結果。
link |
那你再把這個結果再收集起來,再去調你的model,然後有了新的model以後,再去跟環境互動n次,再收集資料,再調你的model,再收集資料,再調你的model,就這樣,陷入一個循環。
link |
所以我想,這個應該是很清楚的,對吧?這個大家有問題嗎?好,如果大家沒有問題的話,接下來的問題就是,這一項到底是什麼意思?
link |
這個summation over所有的trajectory,你知道,summation over某一個trajectory所有的time step,這個意思你也知道,out of town,你也知道,就個參數下你知道,但是gradient log p of at given st,到底是什麼?也許你有點困惑。
link |
好,那我們來考慮另外一個case,我們假設我們現在要做的是一個分類的問題,我們現在有一個network,我們現在有一個actor,我們把這個actor就當作是一個classifier,這個classifier做的事情是given一個畫面x,它分類說我們現在應該要採取哪一個action。
link |
現在有三個可以採取的action,就是說現在是一個有三個類別的分類的問題。那我們說,我們在做分類的時候,你要train一個classifier,你要有label data,你要給你的network一個target,你要給你的network一個目標,那我們就說,現在的目標是100,也就是1 left是正確的類別。
link |
right跟fire是錯誤的類別。那我們把network的output叫做yi,把target叫做yi hat,那你記不記得我們說在做classification problem的時候,我們minimize的是什麼呢?我們minimize的是cross entropy,對不對?
link |
我們記不記得我們說,我們今天要train一個可以拿來做classification network的時候,或者是我們在做regression的時候,我們都做了minimize的,就是cross entropy。
link |
那cross entropy就是submission over每一個dimension,submission over所有的class,然後把yi hat乘上logyi的前面去,負號。那但是因為多數的yi hat都是0,這邊y2 hat跟y3 hat是0,只有y1 hat是1。
link |
所以呢,實際上我們在做的事情,這邊本來是一個負號加minimize,負號加minimize可以看做是maximize。
link |
好,所以我們實際上在做的事情就是maximize logyi,實際上做的事情就是maximize logyi。那我們知道說所謂的yi,其實就是P of left,所謂的y1,這邊我應該把它寫y1比較對啦,因為今天在這個specific的例子裡面,
link |
y1 hat是1,所以只有logy1會被留下來,所以這項應該是logy1。logy1其實就是log P of left given x,就是這個network覺得要採取action left的機率。
link |
好,那如果你今天要做的事情是minimize這一個cross entropy,或者是同等的maximize下面這一下,你會怎麼做呢?你是不是就說,這是我們的objective function,我要去maximize它,我當然就是對它算一個gradient。
link |
好,所以我們就對log P of left given x求它的gradient,再乘上learning rate,再加給你的參數,來用這一項去update你的參數。
link |
所以當你看到你update的式子裡面有這個項的時候,當你看到你update的式子裡面有這個gradient log P of left given x的時候,它的意思其實是說,我們希望這一個objective function越大越好,或這一個objective function越小越好。
link |
或者是說,我們其實是在解一個分類的問題,然後我們希望我們network的output跟我們定下來的target越接近越好,而在我們的target裡面,就是left,就是正確的類別,而其他的是錯誤的類別。
link |
這樣大家了解我的意思嗎?假如你可以了解這個意思的話,那接下來我們怎麼解釋這個式子呢?怎麼解釋這個式子呢?我們先把r拿掉,我們先把r超拿掉,就當作那一項等於1,就當作所有的target可以得到的reward都是1,就不要管它了。
link |
那這個gradient log P of at given st是什麼意思?它的意思就是說,我們現在的training data裡面有一個S1,A1,有一個S1,A1,那我們假設說這個A1就是left,那我們要做的事情就是,我們把S1丟到network裡面,它給我們left,right跟fire的機率。
link |
那我們希望這個機率跟100越接近越好,因為現在的A1是left,所以就告訴我們說left是正確的,我們希望left的分數越大越好,然後right跟fire的分數越接近0越好。
link |
好,那今天如果我們有一個state2,那如果今天我們在另外一個trajectory裡面,我們有一個state上標2下標1,那麼state上標2下標1也丟到這個network裡面,
link |
那我們假設在state,這個S1在第二個trajectory,第一個state的時候,我們採取的action是fire的話,那意思就是說,我們希望這個fire的分數越大,我們希望這個fire的分數是1,其他的分數是0。
link |
所以這就變成了一個分類的問題,你有發現嗎?這其實就是一個分類的問題。你就實際上,我們在update這個式子的時候,我們真正在做的事情是,我們希望說,等於是machine告訴我們說,現在有一筆training data,它的input就是這個樣子,它的target就是這個樣子,
link |
它的input就是這個樣子,它的target就是這個樣子,input就是這個樣子,它的target就是這個樣子,然後你把這個分類問題做對。之前machine看到S1的時候,它就採取了A1這個action。
link |
那今天machine learning的目標就是一樣,今天machine learning的目標就是希望在input S1的時候,它的目標就是要採取action A1。那你可能會想說,那不就跟machine原來做的事情是一樣的嗎?
link |
machine本來就是input S1就會採取A1,那你說,你現在要run一個network,它的目標就是input S1,output就是target A1,那不就跟原來的network做的事情,原來的actor做的事情是一樣的嗎?
link |
但是有個不一樣的地方就是,我們前面有了reward,我們會把每一個example,在我們假設把它當作一個分類問題的話,我們會把這個分類問題的每一個example前面都乘上out of tolerance,每一個分類問題前面我們都乘上out of tolerance。
link |
好,那這件事情到底是什麼意思呢?把每一筆training data都乘上out of tolerance,到底是什麼意思呢?如果簡單的講,假設現在out of tolerance的值是2,假設out of tolerance的值是1,
link |
那我們說把每一筆training data前面都weighted by the out of tolerance,意思就是說,我們現在把input S1 1, output要是left這件事情,這個example複製兩次,因為它的reward是2,所以就複製兩次。
link |
那input S2 1, output fire這件事情,它的reward只有1,所以我們就複製一次,然後拿這個東西去train我們的network,然後你就可以update一次你的network參數,然後再重新去sample,再重新去sample得到新的training data,再用這個方法去update參數,再去sample data,再去update參數,就結束了。
link |
這樣有沒有覺得很簡單呢?這樣有沒有覺得這個實作很簡單呢?你唯一需要的只有你需要在run classifier的時候,給你的training的example給它weight,你唯一需要改程式的只有這個部分。
link |
那甚至keras我如果沒有記錯的話,它其實是有支援這個功能的,那其他部分,你根本就不用改你的code了。這樣大家了解我的意思嗎?所以其實有人會覺得說reinforcement learning很難,沒有很難,你不用改code就可以做reinforcement learning了,只是很花時間可能就是真的。
link |
因為你每一次收集完data以後,你都要解一次分類的問題,就train一次neural network,然後再去收集data,再train一次neural network,跟我們之前做分類的問題不一樣,我們之前做分類的問題,data收集好就在那邊train完一次,就結束了。
link |
但在reinforcement learning的問題裡面,你要等於你要train你的neural networktrain很多次。