back to index
Review: Basic Structures for Deep Learning Models (Part I)
link |
各位同學大家好,我們來上課吧,那等一下最後一堂課,助教會來講一下作業一,那我們現在就來開始上課。
link |
我不知道等一下講的內容對大家來說會不會太快還是太慢,如果你有問題的話,其實就可以問。
link |
那開場就是這個講過N次的開場,deep learning就是三個step。
link |
那第一個step就是我們要逗一個network,這個network就是我們的model,它是一個function set。
link |
那這個function set裡面的function呢,它都是由一些簡單的function所組起來的,而這些簡單的function呢,就是neural。
link |
那通常我們需要自己決定這個structure長什麼樣子,那今天這堂課我們要focus的呢,就是有哪些常見的structure。
link |
那第二個step呢,就是你要定一個cost function,根據training data告訴你的machine說什麼樣的function是好的,什麼樣的function是不好的,什麼樣的network參數是好的,什麼樣的network參數是不好的。
link |
那怎麼定cost的function其實就是case by case dependent,你先要出一個問題是什麼,你手上有什麼樣的training data。
link |
那第三個step就是,有了step1和step2以後,用gradient descent找出一個最好的function就結束了,那我們之後會講一些過去在NL沒有提過的gradient descent的trick。
link |
那我們今天呢,要講的是step1,那接下來三週的計畫是這個樣子,這一週呢,是複習一些最basic的structure,但是我講的內容跟過去提過的東西是不會重複的。
link |
所以三個最basic的structure就是fully connected的layer,一個是fully connected的layer,然後recurrent的layer,還有convolution,還有pooling的layer。
link |
好,那下週就我們要上課,下週是助教要來講tensorflow,那我只想要加一句就是,你知道,你在外面啊,因為現在deep learning很紅啊,你在修一個tensorflow的課的話,你至少要繳個一千元吧。
link |
所以下週你來上課你就賺到了,要現賺一千。好,然後下下週我們要講一些特別的structure,然後下下下週呢,我們要講sequence to sequence跟attention model。
link |
好,這些呢,呃,是,呃,我假設你是聽過這些video,知道這些video裡面的內容,好,那我們就先從fully connected layer開始,然後相信在座的大家都知道什麼是fully connected layer。
link |
所以講fully connected layer,最主要目的只是synchronize一下,告訴你說我習慣用的notation長什麼樣,然後確定我們大家都可以看懂這些notation,之後上課會比較方便。
link |
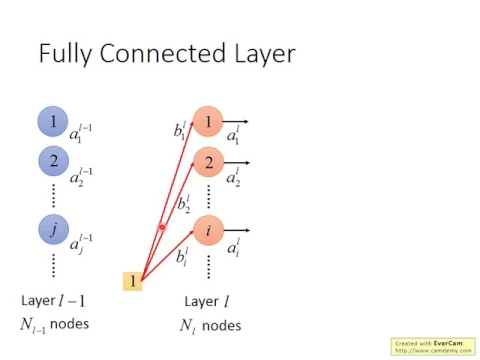
好,什麼是fully connected layer?我們有兩個layer,ok,一個是layer L,它有大NL個node,大NL個neuron,還有一個layer L-1,有大NL-1個neuron。
link |
好,那這些neuron呢,會有,每一個neuron都有一個output,好,這個output呢,我們這邊呢,用A一個上標和一個下標來表示這個output。
link |
而這個上標是什麼意思?這個上標L呢,代表說這個neuron是在D小L個layer裡面,那這個下標I呢,代表說呢,它是在DL個layer裡面的DI個neuron。
link |
所以layer L裡面的這大NL跟neuron的output,就是A上標L下標1,A上標L下標2,A上標L下標IE之類的。
link |
那我們呢,習慣把一個layer所有的neuron的output通通集合起來,這邊有一排scatter嘛,一排一排scatter串在一起,它就變成了一個vector。我們習慣把同一層的neuron的output放在一起,把它當作一個vector來看待。
link |
那這個vector呢,我們用A上標L來表示這個vector,我把下標代表一個element,如果我們把下標拿掉,只有上標的話呢,代表的是一個vector。
link |
我習慣用上標來代表一個object,代表一個整體的東西,用下標來代表一個整體的東西裡面的其中一個element。
link |
大家都知道說fully connected layer,就是兩個layer間的neuron都是兩兩相接的。那這個neuron和neuron之間的connection呢,有一個weight,這個weight我們用W來表示它。
link |
這個W呢,它有一個上標跟兩個下標,那這個上標,W上標L的意思是說呢,這個W呢,它連接了layer L-1跟layer L。
link |
那這個下標IJ是什麼意思呢?這個下標IJ的意思是說,這個weight,它連接了DL-1個layer的D這個neuron。
link |
而這個箭頭的起始的位置是L-1個layer的D這個neuron,它的箭頭的尾巴的位置是DI的neuron,起始的位置是D這個neuron,尾巴的位置是DI的neuron,才寫成IJ。
link |
所以你可能會有一個困惑的地方就是,這個J在左邊,I在右邊,你不覺得先寫J再寫I比較自然嗎?
link |
但是這麼做呢,等一下你會發現說它是有深意的,這麼做等一下會讓notation變得比較elegant。如果你不喜歡這個I放在左邊,J放在右邊的話,你也可以把這個network左右相反啦。我不知道為什麼左右相反是讓人覺得很不舒服就是了,總覺得network的input應該在左邊,output應該在右邊。
link |
所以這個WIJL的意思就是這樣子,這個W上標L下標IJ的意思就是從J這個node畫一個箭頭指向I的意思。
link |
好,那我們現在有一大堆的weight,這些兩個layer間的neuron,它們兩兩間都有一個weight,你把這些weight通通拿出來,根據它的下標的這兩個index,你就可以把它排成一個矩陣,排成一個matrix。
link |
好,那我們知道說呢,根據這個矩陣的index的慣例,如果你有修過線性代數的話,你就會知道說我們是第一個index指的是row,第二個index指的是column,如果你有修過線性代數的話呢,第二個index指的是column,第二個index指的是row,這件事情呢,你應該是知道的。
link |
大家知道為什麼第一個是row,第二個是column嗎?那就是因為說,你會先講R才講C,R、C合起來是剛骨節,C、R不知道是什麼,所以先說row再說column。
link |
我是這樣記的。好,那我們說,第一個index指的是layer L,layer L有NL個node,所以這個matrix高呢,是NL,那它的寬呢,它的寬是NL-1,因為第二個index指的是L-1,input的地方是第二個index,所以寬呢,是NL-1。
link |
好,那現在有一個matrix,把這些位的排起來變成一個matrix,這個matrix我們用大寫的W來表示,加一個上標代表說,這個matrix呢,是L-1的layer和DL的layer之間的weight。
link |
好啊,那現在有了這些以後,除了weight以外,還有一個bias,好像大家都知道說,每一個neuron呢,都有一個bias。那DL的layer的第一個neuron,它的bias就是B上標L下標E,第二個就是B上標L下標2,到B上標L下標I。
link |
好,那有時候我們會把bias省略,其實你蠻常讀到paper有把bias省略的,但是這個並不是說不用bias,通常都是要bias的,只是常常寫的時候,把它省略掉。
link |
因為我們知道說,我們可以把這個bias,也想成是呢,這個weight的一部分,只是你在input的地方,要做一個extension,要多加一個scalar1,你要把這個input呢,extend,多加一個scalar1,那就可以把B呢,視為是matrix的一部分,視為是那個weight的一部分。
link |
好,那B上標L下標I,代表的是layerL的第一個neuron的bias,把這些bias呢,通通串起來,變成一個vector。
link |
那這個B上標L呢,把下面的index拿掉,代表的就是第L個layer的bias所成的vector,就是B上標L。好,那接下來呢,接下來我們要算這個A上標L下標I,也是第L個layer的第一個neuron的output,
link |
跟前一個layer的output間有什麼樣的關係,知道他們有什麼樣的關係。
link |
好,那在計算他們的關係之前呢,我們要計算這個activation function的input,activation function的input呢,我們用Z來表示。
link |
Z上標L下標I,就是第L個layer的第一個neuron,它的activation function的input。好,Z代表activation function的input。
link |
那Z上標L呢,就是把同一個layer,把第L個layer的所有的activation function,所有的neuron的activation function的input,通通集合起來,排成一個vector,就是Z上標L。
link |
好,那接下來我們看一下呢,Z上標L下標I,跟input前一個layer所有的output有什麼樣的關係。
link |
他們的關係呢,是這樣子的。好,他們的關係是這樣子的。如果你把這個前面的layer的neuron的output,通通都乘上了他們對應的weight,再加上bias,就變成這個Z。
link |
那這個A上標L-1下標1呢,它乘上的weight是W上標L下標I1。為什麼呢?因為這個下標I1,代表是從1指向I。
link |
所以A下標1上標L-1,它是乘上W下標I1,從1指向I。所以同樣的A2就乘上WI2,所以從2指向I。
link |
好,那把這些W跟A通通乘起來以後,加上bias,你就得到第一個neuron的activation function的input。好,那你可以把這個W跟A這邊呢,用summation通通加起來。
link |
你summation over L-1個layer的neuron的output,你summation over 1到NL-1,然後呢,把A跟W加起來,再加上bias,你就可以得到Z。
link |
好,這個呢,我想對大家來說應該都是非常容易的。好,那我們現在呢,要考慮的是一整個layer的output。我們剛才考慮的是一個neuron的output,那我們現在要考慮的是一整個layer的output。
link |
我們想要知道說,如果我們把第L個layer所有的neuron的output通通串起來,變成A上標L跟前一個layer所有的output串起來,A上標L-1,他們之間呢,有什麼樣的關係?
link |
好,在計算他們的關係之前,我們呢,先來計算一下Z上標L。所謂的Z上標L就是把第L個layer的neuron的exclamation function的input通通集合起來,就得到Z上標L。
link |
我們先來計算Al-1跟Z上標L之間的關係。好,那怎麼計算他們的關係呢?我們剛才已經會算一個Z,Z上標L的其中一個element跟前面這些neuron的output之間的關係。
link |
我們把它的式子呢,寫成這個樣子。Z1就是A1乘以W11加上A2乘以W12,以此類推。同樣,Z2等於A1乘以W21加上A2乘以W22,以此類推。
link |
好,那我們把每一個Z的式子呢,通通列出來。我們把Z1的式子列出來,把Z2的式子列出來,一直到把Z上標L下標I的式子通通都列出來。那我們可以把這些式子做一下整理。
link |
變成這個matrix和vector的operation。怎麼做一下整理呢?我們把等號的左邊的Z啊,每一個element呢,通通拿起來,就拼成一個vector。
link |
我們把所有的W呢,通通集合起來,就變成一個matrix。我們把所有的A上標L-1,我們把這邊所有的A通通集合起來,就變成一個vector。
link |
我們把所有的B呢,集合起來,也變成一個vector。這上面這個方程組啊,就等於下面這個matrix的operation。
link |
這個Z的vector,我們可以把這個vector,我們可以用ZL來代換它。這個matrix呢,我們可以用W上標L來代換它。這個vector呢,我們可以用A上標L-1來代換它。
link |
上面這個vector呢,我們可以用B上標L來代換它。所以,上面這個方程組,如果我們要用矩陣運算的形式來寫它的話,它的長相呢,就是Z上標L這個vector,
link |
等於呢,這個A上標L-1的這個vector,乘上WL加上BL這個vector。那這邊啊,假設我們今天這個IJ的定義是相反的話,
link |
假設我們不是從J指向I,而是從I指向J,如果我們今天IJ的定義相反的話,那到時候我們整理出來呢,這個WL呢,你就必須要加一個transpose。
link |
了解我的意思嗎?如果你今天這個I跟J的這個index反過來WL,你就必須要加,你整理完這個式子以後呢,WL你就要加一個transpose。那這樣其實也沒有什麼不對。
link |
文線上呢,它每次乘上這個weight的時候呢,都是有transpose,就是因為這個index的定義不一樣。所以有時候,你會看到有的文線是有乘transpose的,有的文線呢,是沒有乘transpose。但是有乘transpose就讓你感覺比較沒有那麼elegant,有點不太舒服。
link |
所以呢,我們特別把index的定義定成這樣,為了要讓我們在做matrix operation,為了要讓我們在計算AL減一個ZL的關係的時候,這個WL呢,不需要乘上一個,不需要加上一個transpose。
link |
好,那我們現在已經知道這個AL跟ZL之間的關係,接下來要計算的就是ZL和AL之間的關係。我們知道,我們如果可以知道這個跟這個的關係,AL減一和ZL之間的關係,又知道ZL跟AL之間的關係,我們就可以算出AL減一跟AL之間的關係。
link |
那怎麼計算ZL跟AL之間的關係呢?我們可以輕易的知道說,這個Z上標L下標I跟這個A上標L下標I之間有什麼樣的關係。
link |
這個很trivial,如果我們假設neuron的estimation function就是sigma的話,你就把Z上標L下標I帶進sigma這個function裡面,這個Z上標L下標I是一個scalar,它是一個數值。把這個數值帶到一個function裡面,得到另外一個數值,A上標L下標I,就是我們這個Z跟A之間的關係。
link |
那我們現在有一排Z跟一排A,要找它們之間的關係也沒有什麼問題,你就把那一排Z通通都丟到sigma裡面去,你就得到一排A。
link |
你把一排Z丟到sigma裡面去,你就得到一排A。但這樣寫法是比較麻煩的,所以在文件展會常常看到會abuse這個notation,我們會這樣說,我們直接把一個vector ZL丟到一個estimation function裡面,我們就得到另外一個vector AL。
link |
有人會很困惑說,這個estimation function不就是一個scalar output一個scalar嗎?你怎麼可以input一個vector output一個vector呢?
link |
當我們直接把ZL這個vector丟到estimation function裡面去的時候,我們指的意思是說,我們把ZL裡面的每一個element通通帶進去estimation function,然後我們得到一組output,再把另外一組output按照它的式序把它串起來,按照它原來的排列把它串起來就變成AL。
link |
所以這個sigma它有時候可以input一個scalar,有時候它可以input一個vector,有時候甚至它可以input一個metric,但意思都是把input的object裡面的每一個element通通丟進estimation function再拿出來,就是這邊這個estimation function的意思。
link |
好啦,那現在我們什麼都有了,我們知道ZL跟AL-1之間的關係,ZL是AL-1乘上一個weight的WL再加上一個bias的vector BL,就是ZL跟AL-1之間的關係。
link |
我們也知道AL跟ZL之間的關係,把ZL丟到estimation function裡面就得到AL,那最後就是把這兩個東西串起來,我們就知道AL跟AL-1之間的關係,就是把AL-1乘上WL再加上bias再取sigma就得到AL。
link |
所以一個fully connected layer它就是有很多的這樣的layer,那要計算layer和layer之間的關係,你就套下面這個式子,你就可以把layer和layer之間的關係計算出來。
link |
好,那怎麼想這個呢?大家應該是沒什麼特別的問題,對吧?好,再來我們就來複習一下recurrent structure。
link |
在講recurrent structure的時候,你比較常聽到的講法是說recurrent structure就是我們給neural network加上了memory,給它有了記憶,我今天沒有要用這個講法。
link |
過去用這個講法是因為那樣講其實是比較吵的,你的neural network有記憶聽起來就比較吵,我們今天要換另外一個講法,今天的講法是這樣,所謂recurrent structure它就是把同一個structure反覆的應用,叫做recurrent structure。
link |
了解嗎?就好像是在堆積木一樣,把同樣形狀的積木反覆的使用,這個叫做recurrent structure。
link |
它的好處就是,因為我們是把同樣的network反覆的使用,所以今天就算我們的input是一個,等一下我會講到input是比較複雜的東西,是一個sequence,
link |
我們的需要的不同種類的block並不會隨著input的sequence的長度而改變,不管input多長的sequence,我們的network需要的參數量永遠都是一樣,這個就是recurrent structure的奧妙所在。
link |
這邊我列了一個reference,我列了那個NS Graph寫的recurrent neural network的教科書,這個教科書你可以在網路上download到preprint的版本,
link |
裡面其實什麼都有,LSTM、CTC都講得非常的仔細,所以是還不錯的教科書,比較遺憾的地方就是它是比較早出的,我覺得應該是2012年出的,
link |
那個時候還沒有sequence-to-sequence learning,所以它這裡面是沒有sequence-to-sequence learning的。
link |
Sequence-to-sequence learning現在非常的潮,你有沒有看過那個decision tree,那個decision tree就告訴你怎麼做NLP相關的研究。
link |
首先第一個節點就是,你的問題能不能formulate成sequence-to-sequence的劃本,如果不行就放棄。
link |
後面還有很多節點,比如說可以formulate成sequence-to-sequence以後,你手上有沒有data可以train,沒有也放棄。
link |
再來就是你手上有沒有很多的GPU可以train,沒有也放棄。最後你就可以發一個NLP的paper。
link |
我們來看一下recurrent neural network,recurrent neural network是這樣子的,我們有一個function,這個function我們等一下會看說它的內容是什麼,
link |
它就是由neural所組成的,它裡面就是一堆矩陣的運算,但我們先不管它的內容是什麼,
link |
現在我有一個function f,這個function它吃兩個input,這兩個input h跟x它們都是vector,
link |
這個function f它吃h跟x這兩個vector,它會吐出兩個input,這兩個input是h'跟y都是vector,
link |
所以f這個function它就是吃兩個vector,吐兩個vector,所以我們現在如果給這個f function丟一個vector xy,
link |
丟一個vector hd,它經過一番運算以後,它裡面什麼運算我們就不管它,它得到兩個vector,一個是h1,一個是y1。
link |
那這個recurrent neural network它的精神就是這個f要反覆的被使用,也就是說現在有一個新的input x2進來,
link |
我們拿同樣的f也吃這個x2,然後這個f它要吃同樣的function的output當作input,
link |
所以因為這個f它必須要把另外一個跟它一模一樣的function的output當作input,所以今天這個h跟h'在設計這個f的時候,你要特別設計好,
link |
要特別設計好讓這個h跟h'它們的dimension是一樣的,這樣到時候你才能夠把它們就好像堆樂高一樣把它們接在一起。
link |
如果今天這個f的input的這個h跟output的這個h'的dimension不一樣的話,那你這個設計就失敗,就無法接在一起。
link |
所以這邊要特別注意一下,不管f裡面的運算是什麼樣,你要把h和h'的dimension設成一樣,只要設成一樣就沒事了,
link |
只要設成一樣就可以把這個f串在一起。這個f也是吃兩個vector就output另外兩個vector,我們再把同樣的f拿過來,
link |
它吃x3跟前面這個f的output,然後它會再產生新的output,這個process就會這樣一直下去一直下去。
link |
所以今天不管你的input的這個sequence x有多長,就後面有x3x4一直到x1000萬都沒有關係,
link |
你的network的參數永遠都不會增加,你需要的就只有function f,你並不需要額外的參數來處理不同長度的sequence。
link |
你需要的這個sequence的長度,你需要的這個function就只有一個,你就需要的就只有f而已,不管你今天input的長度有多長,需要的都只有f而已。
link |
那這個RNN它當然可以是定格的,今天如果我們不是用RNN來解這個問題,如果我們今天不是用RNN來解這個問題,
link |
而是比如說我們用fee forward network來解這個問題,你想要弄一個fee forward network input x1, x2, x3, output y1, y2, y3,
link |
你當然可以做得到,這也是沒有什麼好做不到的對不對,你把x1, x2, x3把它接起來拼成一個比較長的vector,
link |
再丟到fee forward network裡面,讓它凸一個比較長的vector,y1, y2, y3,這個問題不就解決了嗎?
link |
所以你確實可以去做,但是在處理sequence的時候,還是用RNN比較方便,是因為如果你今天的sequence非常的長,
link |
如果sequence有長有短,其實fee forward network也可以處理,你把不足的部分補齡就好了,對不對?
link |
所以今天sequence有長有短,其實fee forward network也可以處理,但是之所以在處理sequence的時候不喜歡用fee forward network的原因是因為sequence可以很長,
link |
而如果當sequence很長的時候,假設這邊是x1, x2,一直到x100,你把x1到x100統統拼起來,你就得到一個很長很長的vector,
link |
那你把它這個很長的vector丟到fee forward network裡面,那這個fee forward network它至少在input layer的地方要很大,它才能夠吃得下這個很長的vector,
link |
那你的data,你的參數比多,你就容易overfitting,所以其實如果你用fee forward network,你當然可以來處理sequence,
link |
而且你甚至在training data上會得到比較好的結果,因為它參數比較多,但是它容易overfitting,所以結果容易壞掉,
link |
那RNN的好處並不是因為它比較複雜,或者是一些有的沒的,它用在處理sequence上特別的好處就是,我們需要比較少的參數來處理這個問題,
link |
所以它比較不容易overfitting,它比較難train,你比較難在training data上得到好的結果,但一旦你train起來,它就比較有可能在testing data上給你好的結果,
link |
好,那這個可以做deep,RNN可以做deep,那怎麼做deep呢?其實也很容易,我們原來只要一個function f1,
link |
它的input是兩個vector,h跟x,output是另外兩個vector,h'跟y,那我們現在需要另外一個function f2,
link |
這個另外一個function f2,它input也是兩個vector,我這邊寫成b跟y都是vector,它output也是另外兩個vector,就是b'跟c它們都是vector,
link |
那這邊注意一下,h'跟h dimension要一樣,b'跟b dimension要一樣,而且這個y跟這個y,它們是指的就是同樣的y,
link |
它們的dimension必須要一樣,你才能夠把f1跟f2接在一起,它們這個cos必須要一樣,你才能把它們接在一起,
link |
所以你就把這個f1的output y1丟到f2裡面,然後再把b0丟進去,那f2就給你b1跟c1,
link |
你再把b1跟y2丟到f2裡面去,它就給你c2跟b2,那你再把y3跟b2丟到f2裡面去,就得到c3跟b3,
link |
然後這個process可以一直下去,不只在橫的地方可以一直下去,在縱軸的地方也可以一直下去,
link |
如果你用f1,f2,f3到f100,你就可以丟一個100層的RNN,那這邊注意一下就是,
link |
這個f1的output跟f2的input,它們必須要dimension一樣,才能夠把它卡在一起,只要能夠把它卡在一起,
link |
f1跟f2那個function,你要怎麼設計都是可以的,好,那這個bidirectional的RNN也沒什麼差別,
link |
就是我們現在有一個f1,它是一個fee-forward的network,它處理的是fee-forward的部分,
link |
然後有另外一個f2,它處理的是backward的部分,那這個f2呢,它跟f1一樣,它也吃這個x,
link |
然後它另外吃一個b,然後它會突出b跟c,好,那你需要第三個function,
link |
你需要第三個function,這邊是f3,好,這個f3呢,吃一個a跟一個c當作input,然後你就得到y,
link |
好,所以我有一個f3,它吃a跟c就得到y,有一個f3吃a跟c又得到y,吃a跟c又得到y,
link |
這個f3存在的目的啊,就是為了要把f1跟f2的output,讓它們能夠合在一起,
link |
那至於f1,f2,f3裡面是什麼,我剛剛講過很多次,就是你不用管它,就你自己設計這樣,
link |
好,那這邊還有一個,就是如果你在用頂RNN的時候,有時候你可能會想要疊pyramid RNN,
link |
這個pyramid RNN是這樣子的,我們現在有一個input sequence,這個input sequence非常長,
link |
那邊是xy到xt,然後這邊呢,是bi-directional的這個RNN,所以呢,它是雙向,
link |
這個圖是從William Chan iPad 16的paper裡面截下來的,然後這個應該是William Chan在Google intern的時候做的一個test,
link |
這個test呢,是一個很瘋狂的test,它要做語音辨識,然後它要用sequence-to-sequence model,硬做一個語音辨識。
link |
那sequence-to-sequence model,我不知道大家知不知道,就是input一個sequence,然後就可以output另外一個sequence,
link |
就兜一個很複雜的function,然後做語音辨識,語音辨識input就是聲音訊號的sequence嘛,
link |
output就是character sequence嘛,然後就這樣子,就直接兜一個model,input聲音訊號,
link |
inputcharacter sequence,然後這個遊戲就結束了,其他都不要玩,就硬拳下去。
link |
那就是,我其實曾經也有過這樣的想法,但我就覺得,這真的可以成功嗎?
link |
那看這個paper的結果,這真的是可以,我可能。
link |
那這中間有一個很重要的trick,就是,在這個paper裡面,在這個作者在conference裡面報告的時候,
link |
他有講說,他原來用的不是Pyramid的,他是Pyramid的RNN,他用的就是一般的RNN就疊了很多層,
link |
然後他說,他train了好幾個月,都不收斂啊,然後我想說,哇,竟然從在Google工作的人嘴裡聽到,
link |
他有train不出來的東西,然後他說,最關鍵的影響,最後可以讓他整個sequence-to-sequence,
link |
你可以做起來的關鍵,就是改成用了Pyramid的RNN,改成用Pyramid的RNN,訓練速度就快很多了。
link |
那Pyramid的RNN在第二層的時候,這第二層的每一個block,每一個function,
link |
他都是吃前面一個layer的幾個block的open,他吃前面那個layer幾個block的,
link |
他把前面那個layer的幾個block的open合起來當作input,一次處理好幾個block的information。
link |
他這樣做的好處,就是他可以把他的sequence縮短。
link |
如果你在每一個layer,你的function都是吃前面那個layer的好幾個block的open一起處理的話,
link |
那你就可以把sequence隨著這個deep的RNN疊得越來越深,你的sequence就會越來越短。
link |
有的人可能會覺得說,這樣子也許並沒有減少太多運算量啊,
link |
因為你可能會想說,雖然說現在這個sequence變短了,
link |
但是每一個block需要處理的input變多了,也許total來說,你的運算量並沒有什麼差別。
link |
但是如果你從平行運算的角度來看的話,雖然說一個block裡面的運算量變多了,
link |
但是一個block裡面的運算往往是可以平行的,但是一個sequence的運算是沒有辦法平行的。
link |
sequence的運算比較難平行,你要先算完,你要先看X1的input算完,
link |
才會知道說,X2丟到這個block的時候,你應該要有什麼樣的open。
link |
所以sequence的部分是無法平行的,所以sequence越長,
link |
你就算有很多平行的資源,sequence越長,你的需要的時間還是越長。
link |
所以雖然在這個架構裡面,每一個block的運算量是增加了,
link |
但是如果sequence變短,我相信在加速上面還是會非常有理的。
link |
好,那現在接下來我們要講的是,這一個function,它到底應該長什麼樣子?這個f到底應該長什麼樣子?
link |
我們有一個input X,我們把input X乘上一個matrix Wi,再加上另外一個input H乘上另外一個matrix Wh。
link |
我們剛才講說,如果你從layer L-1到layer L的話,你就是乘上一個matrix。
link |
所以你可以把X跟H講成是前一個layer的input,然後把它乘上matrix就得到下一個layer的output,
link |
然後這邊把bias就ignore掉。
link |
好,我們把X乘上Wi,加上H乘上Wh,然後把它通過這個sigmoid function,通過一個activation function,
link |
它不一定要是sigmoid,你要用什麼就用什麼。
link |
然後你又通過一個activation function,你就得到H',這個H'就是network的output。
link |
那其實這個Y它並不是從X跟H算出來的,它其實是從H'算出來的。
link |
那你要把它考慮X跟H也完全是可以的,這裡面都是你可以自己隨便設計,我這邊講的只是一個常見的版本而已。
link |
好,那如果要得到這個Y呢,你就把這邊算出來的這個H'乘上Wo,通過activation function就得到Y。
link |
如果今天Y是最後一個layer,然後你又希望最後的output是機率的話,那你可能會加一個softmax的function。
link |
好,這個是最簡單的Naive的這個RNN。
link |
那我們大家都知道說現在流行用LSTM,那過去我在講LSTM的時候都是很簡單的隨便講一講這樣子。
link |
然後就講得很快,然後大家其實是聽不太懂,最後就笑一笑說你其實沒有聽懂對不對,然後就結束了這樣子。
link |
好,那我們如果從bug的角度來看它,LSTM長什麼樣子呢?
link |
跟Naive的RNN一樣,它有一個inputX,然後呢,Naive的RNN呢,它有一個inputH,這個H它之後的output呢,要去接同樣的RNN。
link |
那在LSTM裡面,它的input呢,它要拿來卡榫的東西呢,有兩個vector,一個叫做C,一個叫做H。
link |
所以inputCT-1跟HT-1,然後LSTM之後會outputCT跟HT,然後這個CT跟HT是要拿去接別的LSTM。
link |
大家了解我的意思吧?那它會有一個outputY,然後跟Naive的RNN一樣。
link |
這邊看起來LSTM跟RNN呢,唯一不同的地方就是,原來RNNinput只有一個vector,然後這邊input有兩個vector,一個是H,一個是C。
link |
那你可能說,input兩個vector有很厲害嗎?我把這兩個vector合起來,不就也是一個vector了嗎?
link |
所以看起來跟原來的RNN是沒有太大的不同的,對不對?大家了解我的意思了吧?
link |
H跟C,把這個藍色的H跟紅色的C,併成一個vector,那其實你就可以把它當成綠色的H來看待。
link |
但是這邊LSTM它一個特別的地方就是,它的這個C跟H啊,扮演了不同的角色。
link |
扮演不同的角色是說,這個CT-1跟這個CT的關係,還有HT-1跟HT的關係,它們之間的關係有很大的不同。
link |
什麼意思呢?這個C它的變化是很慢的。
link |
通常呢,在LSTM裡面,這個CT跟CP-1啊,它們中間的關係是相加的關係。
link |
所以你把CT-1呢,加了一些什麼以後,變成CT,所以通常這個CT裡面都還包含了CT-1。
link |
但是這個,它也有傳得很快的部分,它也有變化很快的部分,就是H,這邊的藍色的H呢,它的變化是很快的。
link |
所以通常看到說,HT和HT-1它們中間的關係呢,是很小的。
link |
所以可以看到說,LSTM它在把訊息呢,它把input的訊息傳遞出去的時候,它其實有兩條路徑,一條是快的,一條是慢的。
link |
那這一條路徑就可以記,它的變化比較慢,它可以記得比較過去,比較long term以前的information。
link |
那LSTM的架構呢,是這樣,首先input就是三個input,對不對?
link |
就是XT,H跟C,我們把X,H跟C畫在這邊,我們把X跟H畫在一起,但意思是一樣的。
link |
好,那這三個input怎麼得到這三個output呢?
link |
這邊的運算是這樣,把X跟H並在一起,變成一個比較長的vector,變成比較長的vector。
link |
然後呢,把它們乘上一個matrix W,再取一個activation function,得到一個vector Z。
link |
這邊呢,你可以看作是這個X跟H把它接在一起,再乘上W,跟你把X乘上一個matrix,然後H乘上另外一個matrix,得到的這個意思呢,其實是完全一模一樣的。
link |
我想大家應該知道我的意思嘛,這個地方的意思其實是這樣子。
link |
意思是說,我們今天呢,有一個H,有一個X,然後呢,我們有一個W,它去乘上了H跟X,就得到了另外一個vector,我們這邊寫作Z。
link |
但是呢,你其實也可以把這個W呢,就拆成兩個部分,拆成W1跟W2,然後它的意思呢,其實就是呢,這個W1呢,乘上H,加上這個W2呢,乘上這個X。
link |
這邊想要表達的東西呢,是一樣的,在文件上會看到不同的寫法,意思是一樣。
link |
好,那我們把H跟X合起來,乘上一個matrix W呢,就得到Z。
link |
這個箭頭跟這個matrix,它的顏色是一樣的,代表它們是一樣的東西。
link |
好,那X跟H併在一起,再乘上另外一個matrix,這邊寫成W上標I,再通過一個activation function,這個activation function這邊通常會用sigmoid function。
link |
這個activation function通常會用sigmoid function,得到ZI,所以把這個vector乘上一個matrix,得到ZI。
link |
然後把這個vector再乘上另外一個matrix,再乘上另外一個matrix,WF呢,你就得到ZF。
link |
然後把這個vector再乘上另外一個matrix,你就得到ZO。
link |
好,所以就把這個vector乘上四個不同的matrix,然後你就會得到四個不同的vector。
link |
而今天一般你在implement LSTM的時候,都已經有現成的library,code個LSTM layer就有LSTM了。
link |
其實過去呢,如果你在implement LSTM的時候,你就自己要注意一下,其實呢,這些,這四個matrix乘上X跟H的vector,再寫vector這件事呢,它們是可以平行運算。
link |
所以這邊呢,把這四個matrix operation平行運算的話,你可以加速很多。不過現在我想這件事情大概沒那麼重要,因為反正就是其他人都已經幫你寫好了。
link |
好,那接下來呢,C有什麼作用呢?這個C有時候你也可以把它接下來放在這裡,有時候你也可以把C拿來跟X跟H接在一起。
link |
這件事情呢,叫做piphole,這件事情還蠻常見,還蠻standard。那如果加上piphole的話,理論上呢,你的input的這個vector呢,變長了,因為現在是X加H加C,這個vector變長了。
link |
所以這個W呢,也應該要變得比較寬,對不對?你要跟著變寬,這個寬的W才能夠乘上這個比較長的vector,然後最後得到Z。
link |
但是呢,在實作上,對應到C的這個部分,這個matrix通常是會強制它變成diagonal的。
link |
這樣大家知道我的意思嗎?就是這個W在對應到X的部分,就X會乘上,就是說我們現在把這個vector乘上這個長的matrix,就等於是把W分成三個部分嘛,對不對?然後前半部分乘上XT,中間乘上H,然後最後一部分乘上C。
link |
通常會強制C的部分呢,那個matrix呢,是diagonal的,這樣你可以減少你的參數。
link |
我好像沒有看過有人在這邊不是diagonal的,我自己是沒有試過說如果這邊不是diagonal的,結果會怎樣。
link |
那感覺說,加上C呢,這邊多加一個C,等一下我們會看到各種不同的LSTM的變形,還有它的performance。這邊加上這個C感覺已經不太有幫助了。
link |
感覺已經可能會overfitting,這邊如果再更多參數的話,可能是沒有用。所以一般這邊就強制它是diagonal。
link |
那對ZO、ZF、ZI也都做一模一樣的事,只是這邊這個W的參數呢,是不一樣的而已。
link |
好,那接下來呢,有了這四個vector以後,接下來我們要做什麼事呢?接下來要做的事情就是把Z跟ZI相乘,這個圈圈中一點,這個是elementwise相乘的意思。
link |
就兩個vector,elementwise相乘的意思。那為了要讓它們elementwise相乘,這個Z跟ZI顯然它們的dimension必須要是一樣,它們才能夠做elementwise的相乘。
link |
而接下來呢,把這個ZF跟CT-1也做elementwise的相乘。那把這兩個elementwise相乘的結果呢,相加。那我們一般都會說,這個ZI它就是implicate,它決定Z的information能不能流進去。
link |
然後ZF呢,是bogey gate,它決定這個C呢,這個memory呢,能不能夠被傳到下一個時間點。
link |
那把這兩項elementwise的相乘,把這兩項elementwise的相乘相加以後,你就得到下一個時間點的CT,你就得到這個output CT了。接下來呢,這個HT是CT乘上這個hyperbolic tangent,然後再做elementwise的相乘。
link |
這個hyperbolic tangent我這邊有特別把它寫出來,因為據說這一項的存在與否呢,其實是會有一些影響,所以我們把這一項把它寫出來。
link |
把這個CT取hyperbolic tangent以後呢,乘上ZO,所以ZO做elementwise的相乘,就得到HT。然後最後呢,所以我們現在有HT了,我們有這個C了,也有H了,剩下最後的Y這個是哪來的呢?
link |
這個Y呢,就是把HT乘上另外一個matrixW'再取sigmoid function得到Y,我們這邊如果有乘上一個matrix的話,我們就用一個粗的箭頭來表示,細的箭頭代表什麼事都沒有發生,有乘matrix就用粗的箭頭來表示。
link |
所以把這邊elementwise的相乘是HT,HT乘上一個matrix變成YT,而這個東西呢,就是LSTM。然後接下來呢,LSTM就跟剛才說的那個RNN一樣,就是把這個block反覆的使用。
link |
所以現在有一個LSTM的block,它input是C,H跟X,它output就是C,H跟Y。然後接下來你就是要把這個C呢,再接到另外一個LSTM的block,把這個H呢,再接到另外一個LSTM的block。
link |
那這個LSTM跟這個LSTM是一模一樣,它們參數是一模一樣,你只要把同一個block拿出來呢,反覆使用而已。所以如果我們把這個X呢,拿來放在這邊,把它跟H呢,接在一起,然後反覆剛才我們已經做過的運作。
link |
乘上四個不同的matrix,得到四個不同的vector,然後再把Z跟Zi呢,做elementwise的相乘,然後把這個跟Zf做elementwise的相乘,加起來,你就得到CT加1,而CT加1就是這個時候新的C,output的C。
link |
然後再來你要得到新的H,你得到新的H,然後呢,你又會得到新的Y,所以LSTM呢,就是反覆這個步驟。
link |
那我們知道說,除了LSTM以外,還有另外一個最近,也許儼然有取代LSTM的趨勢,叫做GRU。GRU它是Gated Recurrent Unit的縮寫,那我把這個LSTM掛在這邊。GRU呢,就block的大架構來看,它跟一般的Naive的RNN是一模一樣。
link |
它不像LSTM有明確的分層說,我有一個變化很快的memoryH跟變化很快的memoryC,我有一個變化很快的input跟變化很快的H跟一個變化很快的C,這個LSTM有的。
link |
但是GRU沒有,它只有input H,output H,跟一般的RNN是在外觀上來看是一樣的,但它內部是很像LSTM,它內部是這個樣子,它內部這樣,就是我們來input一個H跟input一個X,我們input一個H,input一個X。
link |
接下來我們先把H跟X拿來把它們併在一起,因為今天在這整個model裡面H跟X做的事情,它們都有兩個角色,所以我今天畫一個虛線代表說這是它的分身,但它們是一樣是同一個東西,我再把它拿來放在這邊。
link |
這個GRU我其實畫了很久,除了兜來兜去,總覺得不是很好看,這是我現在畫出來我覺得比較好看的版本。
link |
我們把這個H跟X併在一起,然後乘上一個matrix,我們用粗的箭頭就表示乘上一個matrix,這邊就不把notation寫出來了,這邊就是乘上一個matrix,再通過inservation function得到R,這個R我們叫做reset gate。
link |
它這個有通過sigmoid function,只是介於0到1之間的,我們稱之為一個reset gate,其實它就是一個vector。
link |
把這個H跟X再乘上另外一個matrix得到Z,它得到的這個vector叫做update gate。然後接下來把H乘上R做element wise的相乘,這個H跟這個R做element wise相乘,這邊的output顯然是另外一個vector。
link |
我現在就沒有把它畫出來,這邊你會得到另外一個vector。那把這邊這個vector跟Xt併在一起,它們去乘上另外一個matrix,這個matrix是黃色的,把它畫成黃色的,然後就得到H'.
link |
然後接下來呢,我們把這個Z跟H做element wise的相乘,把E-Z跟H'做element wise的相乘。
link |
所以這邊有個E-,所以Ht-1是跟Z做element wise的相乘,H'是跟E-Z做element wise的相乘,再把它加起來。
link |
這個部分我有寫一個,寫把式子列出來,這邊就是這樣,把Z跟,發現這個寫錯,這應該是T-1,這邊應該是T-1,對不對?我先發現,上次有一個同學發現說整個作業的deadline都是錯誤的,告訴我你的名字。
link |
好,那我們把Z跟Ht-1做element wise的相乘,這個是Ht-1,然後把E-Z跟H'做element wise的相乘,把它加起來。
link |
然後加起來後的結果就是Ht,然後把Ht乘上另外一個matrix就得到Yt,所以我們這樣,input H, input X, input H, input X,得到H跟Y,得到H跟Y。
link |
好吧,也許你會想說,這有啥好?你就很無聊的把一個看起來很像的東西都再講一遍。
link |
它的一個好處,比較常被提到的好處是,你會發現說,我們知道這邊粗的箭頭就代表一個matrix,所以這邊有四個matrix,這邊只有三個matrix。
link |
在這個黃色的跟這個黃色的,我們是把這個Ht跟這個alpha並起來,才乘上黃色這個matrix,所以這兩個黃色的箭頭合起來是一個matrix。所以我們這邊有三個matrix,這邊只有四個matrix,所以GRU的運算量是比較少的。
link |
或者是說,它運算量比較少,所以它用的參數比較少,所以比較不容易overfitting。這個聽起來還蠻合理的,我想你大概可以接受。
link |
但是,這個算是仔細想想又有一些奇怪的地方。如果你仔細想想的話,減少參數量不一定要用拿掉一個gate來完成,不是嗎?減少參數量的方法很多啊。
link |
比如說你把LSTM的這個C這個vector跟H這個vector的dimension變小,你其實也可以減少參數量啊。所以,拿掉一個gate的好處到底是什麼,我就覺得沒有那麼清楚。
link |
這個地方其實還需要更多的比較。如果我們只是說,我們讓LSTM跟GRU他們input的H的dimension是一樣的,然後說GRU的參數比較少,這樣比較不容易overfitting,我覺得這樣好像聽起來不太對。
link |
他們兩個比較的時候,應該是GRU跟LSTM要故意調到參數是一樣的,然後LSTM有四個gate,但是它的參數H的dimension比較小,所以它的參數跟GRU一樣再來比,我是覺得是比較公平的。
link |
也許這是一個可以作為留言終結者的題目。在下課前我們來想一下,GRU跟LSTM他們中間到底有什麼樣的關係呢?你可以自己想想看他們有什麼樣的關係。
link |
我的解讀是這樣子,一般人會想說這個東西是memory,所以跟memory相乘的東西就是forget gate,跟memory相乘的東西就是forget gate。
link |
不過這樣就變成有兩個forget gate了,我會覺得說這個東西R其實有點像是output gate,你可以把這個H想成是memory,然後我們這個memory會乘上output gate,所以這個R可能就是output gate。
link |
但是它那個output gate的output會乘上一個transform以後,這個很難解釋,在LSTM裡面有這個C跟H,我覺得這個GRU的H是C,然後它跟reset gate相乘以後這邊沒劃出來的vector是H。
link |
所以這邊這個才是H,然後跟memory相乘的gate,這邊這個是forget gate,然後這邊這個是input gate,然後今天這個input gate跟forget gate是連動的。
link |
所以要input gate打開的時候,forget gate就是說你要把新的東西加進去,就需要把舊的東西忘記。你要把舊的東西忘記,你就要把新的東西加進去。
link |
所以這個可以看作forget gate,這個可以看作input gate,然後它們是連動,然後把它們的output加起來,加起來得到新的memory裡面的值,然後在下一個時間點再算一次output gate,然後得到output。
link |
不知道各位有沒有聽得很懂,不然也沒有什麼關係。到底為什麼GRU會好,這個還是個謎,你可以自己查理看看。
link |
好,那這邊我想要講一些不同的recurrent neural network之間的performance的比較。
link |
這個實驗其實不是我自己做的,是從LSGraph的教科書拿出來的,Android的實驗是做在Timmy上面。
link |
Timmy是一個語音辨識的coder,本來作業裡我想要用Timmy,用Timmy大家就緊張了,因為你在網路上找不到現成的code。
link |
下學期應該要用Timmy。Timmy是這樣子,它不是真正的語音辨識,真正的語音辨識太難做了,一般人做不起來,它是一個簡化版的語音辨識。
link |
它是這樣子的,它要做的東西叫做friend classification,所謂的friend classification是說我們現在有一大堆的句子,一大堆的聲音訊號。
link |
對聲音訊號的每一小段每一小段我們都抽一個feature,每一小段通常是0.01秒那麼長那麼短的時間,我們用一個vector來描述它。
link |
所以每一段聲音訊號都是一排vector,都是一排vector。
link |
Timmy要我們做的事情就是,它只是一個單純的分類的問題,我們要決定說這邊的每一個x呢,它是屬於哪一個phony。
link |
而如果你是不知道phony是什麼的話,你就把它當作是英文的音標就好,所以這邊這個應該是青色這樣。
link |
你的model要決定說第一段聲音第一個0.01秒是7,第二個0.01秒也是7,第四個0.01秒是1,後面這些是n,這是s,這是r,等等等等。
link |
這不是語音辨識,因為得到這個東西得到這個output仍然不是語音辨識的結果,你要再接其他model才能得到語音辨識的結果,這個是一個比較簡單的問題。
link |
每一個x所對應的label我們就稱之為y,你可以把它單純當作一個分類的問題,用一般的freeform label做,你也可以用RNN來做,就是input一個sequence, output另外一個sequence。
link |
如果你今天用的是unidirectional的RNN的話,其實有一個絕招可以用的,有一個tip可以用。
link |
這個tip叫做target delay,這個target delay的意思是這樣,這一招是說假設你的真正的label,真正的label就是說這個聲音,這三段聲音確實就對應到7,這兩個frame確實就對應到1,這三個frame確實就對應到n。
link |
理論上你在做learning的時候,你用RNN做learning的時候,你就會希望說input第一個frame,這個每一個vector就叫做一個frame,input第一個frame,它就output7,input第二個frame,output7,第三個frame,output7,等等。
link |
但是有一個方法可以讓你的performance比較好,把所有的label都往右移一些。大家可以看得出為什麼這樣會比較好嗎?把所有的label都往右移一些。
link |
其實是1,但是你在教你的model的時候,你在教你的label的時候,你告訴他說,看到這個東西,你要說是7,不要說是1。
link |
它雖然實際上這段聲音是1,但你的model output要是7。然後你說後面這三個n怎麼辦呢?後面這三個n它就沒有對應的input,怎麼辦呢?沒關係,給它0。
link |
丟三個dominantframe進去,dominantframe就是frame的值都是0,丟三個dominantframe進去就結束了。為什麼這樣會比較好呢?你想想看,假如你用的是unidirectional的RNN,它由左而右看過來,
link |
它看到這個1的時候,它才看了前面四個frame。也就是說,它才看了這個1的開頭,你就叫它決定說,現在你聽到的聲音就是1。這樣對它來說會不會太勉強了呢?
link |
對不對?因為它才聽到這個1的開頭,你就要求它在這個時間點的output就是1,也許對它來說根本就是強人所難。如果你可以把所有的target通通往右移幾個frame的話,比如說往右移三個frame的話,
link |
那你要求machine output1的時候,它已經把完整的這個1的聲音訊號看完了。它是看完完整的聲音訊號以後才output1。對machine來說,這個learning是比較容易的。
link |
那在實作上,它這麼做,確實可以讓它learn得比較好。如果聽不懂就算了,因為這招只有unidirectional的RNN用得上,比如說bidirectional的話,你其實也用不上這一招就是了。
link |
這就是我從LSGRAPH教科書裡面取出來做的teaming上的結果。那我們來看一下這個圖,不知道大家看不看得清楚。這邊有三條線,最下面這一條線是MLP,MLP就是Multilayer Perception,其實就是一般的Feedforward Network。
link |
然後呢,縱軸是分類的正確率,當然是越高越好。橫軸是什麼?橫軸是,如果是MLP的話,它是window size。
link |
Window size是什麼意思呢?意思是說,我們現在input是一排thread,我們input是一排thread。那在你的想像裡面呢,我們可能就是把每一個thread丟到一個NN裡面去,然後問它說這個東西是什麼。
link |
但是你想想看,這個聲音,它很短才0.01秒,叫你聽0.01秒的聲音,你也不見得聽得出來它是什麼聲音。所以一個很簡單的方法可以讓NN做得更好。
link |
怎麼做呢?讓它不要每次只看一個thread,讓它每次看好幾個thread。那看的那個thread的數目啊,就是所謂的window size。比如說我們可以讓它看一次看三個thread。所謂一次看三個thread的意思就只是,我們這邊的thread假設是X1,X2,X3。
link |
我們就只是把X1,X2,X3接起來,變成一個比較長的vector,丟到NN裡面去,讓它根據這個比較長的vector去判斷說,現在中間的這一個thread,它對應的phony是什麼。
link |
你可以想像說,NN現在看的比較多的information,顯然是會做得比較好。所以看這個NLP的結果,你這個window size越大,它這邊的window size的定義應該是看前幾個後幾個。比如說像這個case,看前一個後一個,所以window size應該是1。
link |
所以這邊它才會從0開始。如果是0的話,就只有看中間那個thread,沒看旁邊。performance果然就很差這樣子。那你會發現說,現在window size如果越來越大,只要看前10後10,那它的performance就到這個地方。
link |
接下來我們看這個透明的正方形的label這條線,它是RNN的結果。那這個橫軸呢,它是unidirectional的RNN,它這個橫軸就是我們剛才講的time delay。
link |
你要把你的label往右shift幾格,你可以shift0格,shift1格,shift2格,一直到shift10格。那你會發現說呢,不管我們shift多少格,RNN就是比這個NV4N還要好一點。
link |
你看NV4N它考慮到前10後10的thread的時候,考慮的那個時間點已經很長了。那它還是比RNN略遜一籌,因為RNN可以考慮的是從這個句子開始到結尾所有的thread,它都可以把它考慮進來。
link |
那shift有一點幫助啦,但shift太多也就沒有幫助了。那接下來這個黑色的正方形呢,是LSTM,你看LSTM在所有的case都是比RNN還要好的。
link |
它還可以做target delay,那也會有一些幫助。然後這邊有一些比較語音specific的我們就不要講了。我們看一下bRNN,就bidirectional的RNN,它是擬制的是這個點。
link |
那它bidirectional的RNN一加上bidirectional,因為加bidirectional的時候,你的network會看由句子開頭走到現在這個時間點的訊息,跟從句子結尾走到現在這個時間點的訊息。它考慮整個alternates的訊息,所以performance當然是比較好。
link |
那bidirectional就沒有,就不需要做target delay了,所以就是這個點。那bidirectional LSTM它是XX這個點,又比bidirectional的RNN還要好一點。
link |
所以等於得到的結論是這樣,LSTM比RNN好,比C4NN好,還有bidirectional是比unidirectional還要好的。
link |
這邊是一些visualization的結果,你可以看說這個是正確的答案,這個句子是105,這邊這個英文字WANHN,這個是phony。
link |
就是說在這個時間點,你應該要預測說這個地方的phony是W,這個時間點你應該預測說這個地方的phony是OW。
link |
這個是bidirectional的RNN它預測的結果,你會發現說它的結果跟正確的答案幾乎是一模一樣。
link |
那正確的答案它是比較極端的,就是說要嘛就是1,要嘛就是0,RNN在某些地方,比如說這個位置,它覺得有可能是青色的這個phone,其實青色的這個phone是silent,是沒有聲音的意思。
link |
也有一點點可能是F這個phony,但是是silent的機率是比較大的,所以最後辨識出來的結果還是會覺得說在這個時間點應該是silent。
link |
這個是bidirectional的結果,那你也可以把這個Vforward的部分跟backward的部分分開來看。
link |
如果你今天只有Vforward的direction,只有從頭到尾的direction,你會發現說其實也做得不錯了,在很多地方也做得還可以這樣子。
link |
但是你會發現說它還是有一些錯,比如說這邊應該有一個藍色的peak,在這邊好像就沒有把藍色的peak顯示出來。
link |
那如果我們看backward的話,backward其實做得比較差,你會發現forward做得比較好,backward做得比較差。
link |
我覺得這其實也是合理的,也許我們在辨識一段聲音的時候,從頭開始聽跟從尾巴開始聽的難度是不一樣的。
link |
我們自己在辨識的時候,一個句子我們也是從頭開始聽,也許從頭開始,從一個句子從頭開始聽,然後辨識說現在聽到什麼聲音是比較容易的。
link |
從尾巴開始倒過來聽,要覺得辨識什麼聲音也許是比較困難的。
link |
所以你會發現backward做得是比forward還要差,但是forward跟backward其實是互補。
link |
比如說像藍色這個地方,forward做不起來,backward這個櫃台已經被蓋住了,backward這邊就可以做得起來。
link |
也許我們在聽聲音的時候,我們是先forward聽一遍,然後有大部分的form我們可以辨識得正確,我說人在做這件事的時候,
link |
然後之後再回頭過來想想,自己做一個backward pass,回頭過來想想,把這些辨識不好的地方再把它補正。
link |
然後你可能會想說,LSTM這麼複雜,雖然說performance比較好,也許它比較複雜,train的時間比較久,也許搞不好這個壞處跟好處相比,好處就被抵銷了。
link |
那這邊顯示的是training的epoch和performance之間的關係,如果我們看不同的model的話。那這邊我們先看NLOP,黑色這條線是NLOP在training set上的結果。
link |
這一條線是NLOP在testing set上的結果,這是RNN在training set上的結果,這是RNN在testing set上的結果,這是bidirectional LSTM在training set上的結果,這是bidirectional LSTM在testing set上的結果。
link |
那你會發現說呢,LSTM它不只performance比較好,它train的速度,它收斂的速度是比較快的,你看它大概不到50個epoch,我假設大家知道epoch是什麼,不到50個epoch,它就train得差不多了。
link |
不像RNN,你要train到200多個epoch才能夠算train得差不多,這件事情也是合理的,這個我們之後會解釋,RNN的training是比LSTM,之後我們會解釋說LSTM的training是比RNN還要容易的。
link |
因為LSTM比較不會有灰點vanishing的問題,你比較容易給它一個好的learning rate,因為你可以比較容易給它一個好的learning rate,它train的速度比較快,RNN比較難給它好的learning rate,所以通常就是把它的learning rate收很小。
link |
你有時候會碰到一些很卡,它整個error service很平坦的地方,它train的速度就會比較慢,這個我們之後再講。那你可能會想說,LSTM這麼複雜,當初到底是怎麼來的,它每一個設計都有用嗎?
link |
所以這邊這個paper是來自,我記得那個paper的名字好像是什麼,LSTM Search Space Odyssey的那篇paper,Odyssey的意思就是那個河馬寫的奧德賽小說,那個史詩,那個伊利亞的奧德賽。
link |
奧德賽可能就是指的是漂流的意思,因為我知道說那個太空漫遊那個電影,它的英文不是也是Space Odyssey嗎?那這篇paper的title也是LSTM Space Odyssey,就是在LSTM的space上面做漫遊。
link |
然後他說呢,他做了各種不同的實驗,他嘗試了各種LSTM不同的sculpture,那他很自豪的在paper的開頭就說,這些實驗如果用CPU跑的話,總共要跑15年,要從2002年開始跑到今天才能跑完。
link |
但是他用GPU跑,所以可能沒跑那麼久就失了啦。這個是他的paper,他paper裡面用了三個Corpus,這個是其中一個Corpus,就是Timmy那個Corpus。
link |
橫軸是什麼,不知道大家看不看得清楚,橫軸是分類的錯誤,縱軸是訓練的時間,所以越往上代表訓練時間越長,越往右代表這個model performance越差。
link |
顏色,這邊圖上有很多不同的顏色對不對,不同的顏色就代表了一個LSTM的架構,要把LSTM的架構改來改去,每一個顏色就代表一個架構。
link |
而青色怎麼這麼多點呢,那是因為一樣的架構可以用不同的參數去train,不同的learning rate,不同的hidden layer的size等等去train,所以每一組參數就是這個圖上的一個點。
link |
而且這個實驗用CPU跑要跑15年。然後呢,他這邊得到什麼結論,等一下我們會有一個比較清楚的結論,可以自己先看一下這個圖上有什麼特別顯眼的東西,比如說青色這些點。
link |
青色這個往右是classification error rate大,而青色這些點顯然是做得特別差。它是什麼呢,它是沒有,這個青色點是noaf,noaf是沒有output的activation function。
link |
我剛才不是有說memory那個C要先通過一個activation function hyperbolic tangent,然後特別把它畫在那個圖上。
link |
他說沒有這個東西的話,結果還蠻容易壞掉的,如果你把那個hyperbolic tangent拿掉,聽起來hyperbolic tangent也沒啥,你把那個東西拿掉,你得到的就是青色這些點,它的error都是特大。
link |
那如果我們看一下,這邊有一些淺綠色的叉叉,你看到了嗎,那它的performance是不錯的,但是它的訓練的時間是比較長,淺綠色的叉叉訓練的時間比較長。
link |
它是什麼呢,它對應的英文是FGR,這個是forget recurrent,過去LSDM其實有一招,現在比較少用了,因為它沒有什麼特別的幫助,它是這樣子,它是說我們把,我們剛才在決定一個gate的signal的時候,我們不是只看h跟x嗎?
link |
他說不要只看h跟x,我們把前一個時間點的input gate、forget gate跟output gate的information,通通拉來跟h跟x並在一起,產生一個很長的vector。
link |
總之就是一個比較複雜的LSDM,但是它performance也不錯,至少沒比較差,但它的訓練時間顯然就是比較長的。
link |
然後這邊有一些點,有藍色的點,它這邊有很多藍色的點,它分佈在比較外圍的地方,所以它就是相較於其他的model,它是訓練時間比較長的,performance又比較差的。
link |
所以什麼model比較不好呢?它這個藍色點對應到是NFG,NFG就是沒有forget gate,所以forget gate很重要,沒把forget gate拿掉,不只訓練得比較慢,而且它的performance也會變得比較差。
link |
好,那我們來看一下這個paper上面整理過的結果。這個是什麼呢?你看後面這個淺灰色的bar,這個淺灰色的bar代表那個model的參數,
link |
它這邊總共有9個model,這個V就是一般的LSDM,CIFG,couple input跟forget gate,就是把input跟forget gate讓它們是連動的,有點GRU的感覺。
link |
那FGR我剛才講過,full gate recurrent,就是一個比較複雜的model,那NP是沒有peephole,NOG是沒有output gate,NIAF是沒有input activation function,
link |
NIG是沒有input gate,NFG是沒有forget gate,NOAVF是沒有output activation function,就很複雜,然後灰色的這些bar就代表那個model的參數,所以這個full gate recurrent是參數特別多的。
link |
那這個performer怎麼看呢?這種圖大家應該會看吧?在這個圖上你可以明顯的看出來說,首先這個畫藍色粗體的方塊代表說,
link |
這些架構是明顯的比原來的LSDM差,所以什麼樣的架構是明顯的比原來的LSDM差呢?如果你沒有output gate,沒有input activation function,
link |
沒有input gate,沒有forget gate,還有沒有output activation function,顯然是會比原來的LSDM差。
link |
那這邊payment的結論是這樣子,首先原來的LSDM就work的不錯,最左邊這個是原來的LSDM,相較於其他的練習,原來的LSDM並沒有比較差,
link |
但是有一些方法是可以讓原來的LSDM減少參數,但是performance也沒有比較差的,就是couple input和forget gate,
link |
有點像是GRU做的事情,他說你看這個couple input和forget gate是這個,參數少了,但是performance沒有變得比較差。
link |
然後他說如果沒有這個peak hold的話,performance是稍微有點下降,所以peak hold也是有一些影響。
link |
然後如果你看沒有output gate的話,整個結果會爛掉,沒有output activation function的話,他整個結果會爛掉,所以output activation function這個hyperbolic tension其實是很重要的,
link |
雖然聽起來感覺沒什麼,但那個是很重要,沒那個結果會爛掉。
link |
這個是另外一篇paper,他還是做了很多的實驗來比較各種不同的LSDM架構。
link |
他做了三個不同的couples,一個是算術的couple,算術的task,那個task很瘋狂,就是給LSDM兩排數字,那你可能用八進位來表示,然後你要把那兩個數字相加或相減,那LSDM要output正確的結果。
link |
那XML是給LSDM看XML的file,他要predict接下來的character是什麼,那PTP這個是做language model,這是我們作驗一要做的事情,就是你要給你串文字,然後predict接下來下一個文字,下一個詞彙是什麼,下一個word是什麼。
link |
因為詞彙很多嘛,所以你看這個predict的正確率其實是頗低的。然後這個hyperbody tangent這個就是一般的RNN沒有做LSDM的結果。
link |
那如果做LSDM的話是第二個color,如果今天拿掉forget-gay,-f就是拿掉forget-gay是這個color,-i就是拿掉input-gay,-o就是拿掉output-gay。-b是什麼意思呢?-b是一個傳說,就是傳說如果給forget-gay比較大的bias的話,performance會比較好。
link |
作者在這個paper有強調說,這件事情很多人都不知道這個theme。給forget-gay比較大的bias的意思就是,希望他不要太常forget,他如果能夠記得是比較好的,不要太常forget。
link |
然後這邊還有一個gru的結果。那這邊的結論是怎樣呢?如果我們比較f跟i跟o的話,顯然你會發現說,如果拿掉forget-gay,在第一個test跟第二個test,結果會爆爛。
link |
而這個值都是越大越好。所以拿掉f的話,你會發現結果就爆爛。但是在這個ptb上面,結果也是稍微變差一點。在三個test上,拿掉forget-gay都是變差的。
link |
如果比較LSTM跟RNN的話,這邊是說LSTM明顯是都比RNN好。
link |
如果我們今天拿掉input-gay的話,也是在這三個test上面都會變差。但是如果我們比較ptb跟其他兩個test的趨勢的話,會發現說,拿掉forget-gay跟拿掉input-gay的趨勢是不一樣的。
link |
如果比較-iz行跟-fz行,第一個test跟第二個test都是有變好,但是第三個test卻是變差的。ptb這個感覺是比較不合群的。
link |
那這個output,如果看output的話,拿掉output-gay的影響是比較小。所以今天得到的結論是,拿掉forget-gay的影響比較大,大過拿掉input-gay的影響,大過拿掉output-gay的影響。
link |
然後發現說,如果給forget-gay比較大的bias的話,在這個test上面,如果我們比較LSTM跟LSTM-b,也就是給forget-gay比較大的bias,發現在三個test上面都是有幫助的。
link |
這個就算是在這幾個test上面證實了之前那個留言,就是給比較大的bias的話是有幫助的這件事。如果看GRU跟LSTM的比較的話,你會發現說,我們看GRU跟LSTM的比較的話,
link |
會發現說GRU在這三個test上,它在第一個test上比較差,在第二個跟第三個比較好,看不出來它一定有比LSTM好的樣子。
link |
然後你可能會很好奇說,下面這三個是什麼呢?下面這三個Mute1,Mute2,Mute3,看起來performance蠻好的,他們是什麼呢?
link |
在這個parameters裡面,它做了一個很神奇的事,它說,我們來找最好的RNN的structure吧,我們用基因演算法來找。
link |
你就先把LSTM跟GRU當作是主先,然後把LSTM跟GRU混合在一起,有時候在這邊加一個Hyperbolic Tangent,有時候在那邊再多加一個Gate。
link |
它會說,拿到這三個test上面去試,看它有沒有比較好,比較好的那幾個structure就留下來,之後再把那些好的structure再混合,再去測試一次,再把好的structure留下來。
link |
如果你知道基因演算法的話,你就會知道我在說什麼。
link |
如果你不知道,就想成它試各種不同的structure,看看什麼樣的structure的performance最好。
link |
那它到底試出來的結果怎麼樣呢?我本來想要畫個圖,我發現這三個看起來都差不多,好像沒有什麼特別好畫的,所以我就看一下這個。
link |
我們就把這個式子列出來就好,這是這三個它找出來的最好的structure,他們的樣子。
link |
有看出什麼特別的地方嗎?我覺得也還好。但這三個structure你會發現它們都蠻像的。
link |
再來我覺得它們其實都蠻像GRU的。我們剛剛看到GRU有那個乘Z跟乘1-Z這個東西,對不對?
link |
就是說GRU的input gate跟forget gate是連動的,所以它有一項是乘Z,另外一項是乘1-Z,代表說這兩個gate是連動的。
link |
那這三個演化出來的結果,這三個找出來最好的structure,它們都有這個GRU的特性。
link |
所以這個GRU的特性也許是蠻重要的,所以它才會演化的過程中被保留下來。
link |
不過這個也很難講啦,如果你看那篇paper的話,它在結論的地方是也沒有那麼confident。
link |
因為你在找這些structure的時候,你是從GRU和LCM開始找的,所以你最後找出來的structure跟GRU,它們的祖先都是GRU跟LCM。
link |
所以你找出來的structure很像GRU,感覺也還好這樣子,感覺也沒有說特別驚人。
link |
如果你說是憑空開始找structure,最後找出來像GRU,那就挺驚人的。
link |
那如果是拿GRU做歧視,找出來像GRU,就感覺是還好。
link |
好,那我們接下來要跳出來講一下language model,這個部分是很重要的。