back to index
Review: Basic Structures for Deep Learning Models (Part II)
link |
好,我們上次在挑出來講Language Model之前呢,我們講到這邊,講到RNN。
link |
那在結束RNN的複習,進入CNN的複習之前呢,我加了一頁投影片。這頁投影片呢,講的是SEC RNN。
link |
一般的RNN呢,其實也是一個function,然後這個function呢,有一個input x,然後有一個output y。
link |
那它同時呢,也會接一個input h,然後output另外一個output h'.
link |
那這邊的input跟這邊的output,它們的dimension呢,是一樣的。這樣我們才能夠把RNN的block串在一起。
link |
那SEC RNN說的是什麼呢?在這個RNN的block上面,你其實可以任意設計,我們上次看了LSTM,GRU等等。
link |
那SEC RNN呢,這個設計非常非常的多,我真的講不完。SEC RNN呢,我只想要舉另外一個例子。
link |
那這個SEC RNN那個unique的地方是,它的這個input的這個vector啊,可以是非常非常的大,甚至你可以把它想像成是無窮大呢,也沒有關係。
link |
那如果一般的RNN呢,或是LSTM,你不能這麼做,因為如果你input的h,隨著你input的這個h變大,那你的model的參數就會變多。
link |
最後你終究會,比如說你的這個GPU吃不下去,或者是,就算你的GPU吃不下去,它也會很嚴重的overfitting。
link |
但是這個SEC RNN呢,它不是這樣。就算是,它的這個需要的參數量,跟現在input的這個vector呢,的這個size呢,是無關的。
link |
所以就算你input這個vector的size呢,是無窮大,也無所謂。那它input這個vector呢,叫做stack。
link |
好,那SEC RNN它做的事情是,它不會使用整個stack裡面所有的information。它每次就只固定pick這個stack的前幾個element。
link |
那就設定好,你要pick前幾個element。比如說在這個例子裡面,就只把這個input的這個stack裡面的前三個element呢,拿出來做運算。
link |
然後在這個SEC RNN裡面呢,它會把這個stack的前幾個element呢,丟進一個function裡面。然後呢,這個function會吐出什麼呢?
link |
這個function會吐出要放到stack裡面的information,就是這個綠色的方塊。那這邊呢,我們把要放到stack裡面的information呢,用一個scalar來表示它。
link |
那在原始的paper裡面,也是它store information的,也就是一個scalar。但是我相信這個要把它extend到一個vector,應該是沒有什麼問題的。
link |
好,那這個f呢,除了output一個information,要被放到stack的information以外呢,它還會output另外三個value。
link |
所以這個f的output呢,它就是四個字尾。這個f其實也會吃這個x啊,它吃這個x跟這個stack前面幾個value,然後output四個value。
link |
那這四個value分別就是呢,store在stack裡面的information,push,pop,還有nothing。而這個push,pop,還有nothing是什麼意思呢?
link |
我相信大家都會寫程式,所以push,pop是什麼意思,我想你是知道。但是在這裡是什麼意思?在這些push跟pop的意思是這樣子。
link |
所謂push的意思就是,我們把這個綠色的information放到現在輸入的這個stack的最前面。
link |
所以這個是push,把這個新的informationpush到stack裡面去。那pop呢,就是把現在input的stack,pop它最上面那個value,把最上面那個value丟掉。
link |
所以原來最上面有一個深藍色的value,pop呢,就是把它丟掉。那nothing呢,就是什麼事都沒有做。
link |
好,那現在這個push,pop跟nothing呢,它們這三個operation各有一個value。以這個例子而言,push是0.7,pop是0.2,nothing是0.1。
link |
也就是它想要出七成力來做push,兩成力來做pop,一成力來做nothing。也就是說呢,我們就把push,pop跟nothing這三件事,對input的這個stack各做一次,得到這三個vector。
link |
然後再把這三個vector分別乘上0.7,0.2,0.1,然後再把它加起來,你就得到新的stack的value,就再把這個新的stack的value傳到下一個時間點。
link |
那下一個時間點呢,會有一個一模一樣的block去吃這個新的stack的value。那你會發現說呢,我們現在需要的參數量是跟stack的長度沒有關係的。
link |
所以你可以有一個非常非常長的stack,那它可以儲存很大量的long term的information。
link |
好,那接下來呢,我們很快的複習一下convolution和pooling的layer。那convolution和pooling呢,它們設計的精神是,它們也是要去簡化我們的neural network。
link |
只是它們用了一些query knowledge來簡化我們的neural network。根據我們現在要考慮的問題的特性,設計了這些layer,而它們所需要的參數量是會比fully connected的layer還要少。
link |
好,那convolution的layer呢,它有兩個特性。如果是,這邊我們舉一個例子,這個1到5呢,是前面那個layer的output,1到4呢,是下一個layer的output。
link |
如果是一個fully connected layer的話呢,那這邊的第一個output,它會考慮前一個layer所有的output以後,才決定第一個output是什麼,那第二個output也是一樣一直在推。
link |
如果是convolutional的layer的話呢,它第一個特性是sparse的connection,也就是說每一個neural並不會連到前一個layer所有的neural。
link |
我們要計算在這個紅色layer的第一個neural的output的時候,我們並不會考慮藍色那個layer裡面所有的neural的output,我們只會考慮藍色那個layer裡面部分neural的output。
link |
至於這個所謂的部分有多大,哪些node,哪些藍色layer裡面哪些output合起來,算是一個部分,這個是你自己決定的,是設計network的人自己決定的。
link |
好,所以每一個neural呢,它都只連接到前一個neural的其中一塊,那這一塊呢,它有一個名字叫做receptive field,那這個名字呢,是從生物那邊過來的。
link |
那因為在這個生物的神經上啊,有時候會有每一個神經元只負責一個區間這樣子的結構,比如說人體的皮膚呢,有很多的神經元,但是呢,每一個神經元只管皮膚的一小塊區間。
link |
如果你讓一個神經元管人體整個所有的皮膚的話,那神經元太累了,它沒辦法做那麼多事。所以每一個神經元呢,它都只管皮膚的一小部分,這個呢,就叫做神經元所管轄的範圍就是receptive field。
link |
那sparse connection呢,它的概念跟這個生物上的receptive field呢,是類似的,就每一個neural它只管前面那個layer的一部分。那第二個特性呢,是parameter sharing,也就是說不同的neural它們可以有一模一樣的參數,在訓練的時候我們強制它必須要有一模一樣的參數。
link |
當然,是不同的receptive field的neural我們才可以讓它有一樣的參數,如果同一個receptive field的neural,你就讓它有一樣的參數,那這兩個neural做的事情就一模一樣了,那它們其中一個人就融掉,所以你不會這麼設計。
link |
好,那舉例來說,這邊我們讓第一個和第三個neural它們的參數一樣,第二個和第四個neural它們的參數一樣。那如果你用parameter sharing的好處就是,有了parameter sharing加上sparse connection,那你的好處就是我們只需要少量的參數,遠比fully connected layer更少的參數,我們就可以來做我們要做的事情。
link |
好,那我們會把同樣,如果今天有不同的neural,但是它們的參數是shared的,那我們就會把那一組參數稱之為filter。
link |
所以,今天第一個和第三個neural它們代表了同一個filter,我們這邊說它是filter1,有時候我們又把這個filter叫做kernel。同理,這邊第二個和第四個neural它們shared同一個parameter,這種parameter就是filter2,那它們是第二個kernel。
link |
好,那所謂的filter size或者是kernel size的意思就是,這個filter它的大小,所謂的filter的大小的意思就是現在這個filter所涵蓋的receptive field有多大,比如說在這個case,receptive field都是3,所以這些filter的大小都是3。
link |
那這個receptive field和receptive field之間的間距就叫做stripe,你可以想像說今天filter1被放在這一個field,也被放在這一個field,就好像把filter1從這個field滑行或者是走一步到下一個field。
link |
而這兩個field中間的間隔是兩個neural,所以這個stripe就是2。
link |
那至於kernel size,filter的number,stripe等等,都是你需要在設計自己的network架構的時候手動去設計的。
link |
好,接下來是舉一些example,這個convolutional layer可以怎麼用,其實可以在Yankee Fellow的教科書上面找到一個表格,整理一個表格告訴你說convolutional layer可以怎麼用。
link |
那可以分成6個case,你可以有input是1-dimensional information,2-dimensional information,3-dimensional information,然後每一種狀況又都可以分成是single channel還有multiple channel。
link |
好,所以我們就來看看說,如果是1-dimension,1-dimension single channel的話,要怎麼用呢?
link |
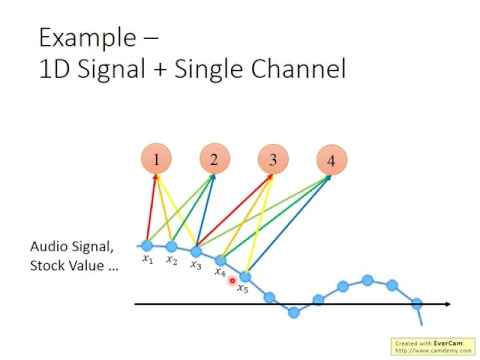
那有什麼樣的訊號是1-dimension single channel呢?比如說我們可以想像說,聲音訊號其實就是1-dimension single channel。你知道一個聲音訊號,你就是用你錄音的時候的取樣點來表示它嘛。
link |
反正你可以想像,每一個點X1到X5就是一個聲音訊號的取樣點,或者是某支股票的指數的上下波動,其實也可以想像成是一個1-dimensional single channel的case。
link |
好,那今天如果你要把convolutional用在這個case上面的話,那你的用法就是,你的一個receptive field就是某一個時間的區間,比如說X1到X3算是一個receptive field,那可以放不同的filter。
link |
那X3到X5算是另外一個receptive field,那可以放不同的filter。那這些filter的output,你再拿去接其他的東西,比如再接另外的CNN,或者再接Fully Connected Layer,就可以做各種事,比如說predict未來會發生什麼事,或者是做分類等等。
link |
好,那如果是1-dimensional multiple channel的case呢,如果是1-dimensional multiple channel case這邊舉的是,假如你input是一個document的時候,而一個document就是由一個word sequence所構成,這個東西我們可以把它想像成是一個1-dimensional multiple channel的case。
link |
那這個1-dimensional的第一個dimensional就是一個document裡面這個詞彙的順序,比如這個document是說我很喜歡這個電影,I like this movie very much,那這個詞彙的順序就是第一個dimensional。
link |
那multiple channel是什麼意思呢?這個multiple channel的意思是說,在這個dimension上的每一個時間點,我們並不是用一個value去描述它。在前一個影片的case,在聲音訊號上,我們是用一個value去描述一個時間點,但是在這個地方,我們會用一個vector來描述一個時間點。
link |
比如說,每一個詞彙,我想這個大家都知道,每一個詞彙你可以用word embedding,或者是用one-of-a-kind coding來描述它,把一個word的vector representation,不管它是one-of-a-kind coding,還是word embedding,拿來表示每一個word的話,那個vector的每一個dimension就代表了不同的channel。
link |
好,那今天這個receptive field只會在我們現在唯一的這個,通常只會在時間軸上,我們唯一的一個dimension上滑動。
link |
它要看呢,就一直要看所有的channel,通常不會只看部分的channel。你可能會問說,看部分的channel,難道不行嗎?
link |
所謂看部分的channel,意思是說,為什麼我們不把這個case,我們為什麼一定要把這個case看作one-dimensional,multiple-channel case,我們為什麼不能把它看作two-dimensional,single-channel case,我們為什麼不把它看作一張image來看待,然後我們的receptive field是,比如說這樣是一個receptive field,然後這樣是一個,這樣是一個呢?
link |
那其實你想的話,你永遠可以這麼做啊,你也可以把它當作是一個留言終結者的題目,看看說如果你這樣子做呢,會發生什麼事。
link |
那我是沒有這樣做過,但是如果你想一想的話,會覺得這樣做也許是不合理的。舉例來說,現在假如說有一篇document裡面有ABCD四個詞彙,ABCD四個詞彙,然後你用one-off encoding來表示所有的詞彙。
link |
那今天呢,你說W1是A,所以它的vector representation就是1,0,0,0,那W2呢,是B,它就是0,1,0,0,然後C就是0,0,1,0,然後它就是0,0,0,1,假設現在這個document正好就是ABCD四個詞彙。
link |
那你會發現說,這個pattern跟這個pattern,它們是一樣的pattern,對不對?所以它們會被同樣的filter,會被這樣同樣的pattern呢?
link |
但是這件事情是不合理的,就如果我們用眼睛看起來覺得它是同樣的pattern,但是實際上你沒有辦法把它當作同樣的pattern,因為在這個case是有AB這兩個word出現,在這個case是有CD這兩個word出現,那你說有AB出現,意思就等同於是有CD出現,這件事情是奇怪的。
link |
所以如果你是這樣子設計你的receptive field,我認為是不合理的,但你永遠可以在你自己的test上試試看,如果你這樣子設計receptive field的話呢,會發生什麼事?
link |
這樣講大家有問題嗎?沒有啊,好。那下一個例子是,如果是two dimension,single channel的話,那你的filter會怎麼設計呢?
link |
那這個圖呢,我想大家都在,大家可能都已經看過了,這個圖的case就是,我們現在的receptive field呢,是3x3的receptive field,那stripe的呢,是1。
link |
好,那如果是two dimensional,multiple channel的case呢,什麼時候會是two dimensional,multiple channel的case呢?這個很常出現,如果是彩色的image,就是two dimensional,multiple channel,那每一個channel就代表了一個顏色。
link |
每一個pixel是由RGB三個顏色所表成,那RGB分別就是一個channel。好,那這個two dimensional,multiple channel的case呢,你的receptive field呢,就是一個3x3x3的立方體,不是3x3的正方形,是3x3的立方體。
link |
所以你的每一個這個neuron呢,它不是接到9個pixel,在這個case,它是接到12個pixel,不是接到9個pixel,而是27個pixel,雖然我這邊只有畫9條街角,但每一個街角呢,其實是接3個pixel。
link |
所以其實這個每一個neuron呢,應該有這個3x3x3,也就是27個街角才對。
link |
好,那其實呢,你也可以很輕易的把它推廣到three dimensional,這邊我就沒有畫出來,因為畫這個太麻煩了。如果是three dimensional是什麼case呢,如果今天是video,你就有three dimensional了。
link |
如果今天是黑白的video,就是three dimensional,single channel,那這個時候呢,你的filter就是一個立方體。如果今天是彩色的video,如果是彩色的video的話,就是three dimensional,multiple channel。
link |
這個時候你的每一個filter就不只是立方體,它是一個four dimensional的東西,對不對?如果今天是一個彩色的video,你的filter就應該是四維的tensor,而不只是一個三維的東西。
link |
好,那這個padding這個可能大家都知道,如果你沒有做padding的話,做convolution你會少考慮到邊緣的地方,所以你的image就會越做越小。
link |
如果你不喜歡這樣子的話呢,你可以做zero padding,但是zero padding其實有很多種,也不一定有哪一種比較好,其實有時候你需要猜猜看,看哪一種的performance會給你比較好的performance。
link |
舉例來說,如果我們今天有一個filter,它的receptive fill是可以考慮前面五個input,有一個filter它可以考慮前面五個input。
link |
那你可以說,假設這個沒有塗黑的圈圈就代表是padding,是有值的,是真正的input。
link |
我只padding兩個,然後呢,讓每一次做convolution以後,input和output的image是一樣大。
link |
但是你也可以說,我要padding多一點,我要padding四個,如果你的receptive fill可以考慮五個input的話,你要padding四個是完全沒有問題的。
link |
因為最邊邊的filter還是會產生output,但如果你今天padding五個的話就不make sense,如果你今天padding五個的話,那最邊邊的filter吃進去的input就都是零,但是最多你可以padding到四個。
link |
所以今天到底要padding多少呢?你其實需要在實作的時候自己try一下,自己用dev settry一下。
link |
那接下來要講的是pooling的layer,那這個pooling做的是什麼事呢?pooling做的事情就是把前一個layer的k個outputgroup成一群。比如說這邊有n個output,那我們就說第1到第k個output一群,第k加1到2k個output的一群。
link |
那每一個group我們就用一個值來summarize它,我們用一個值來代表這個group裡面所有的value的特性,這件事情就是pooling。
link |
所以在第l個layer,在下一個layer裡面,如果我們今天是把k個output,我們把前一個layer的k個outputgroup起來,那每一個group選一個代表的話,那在下一個layer的output就有n除以k個output。
link |
也就是說,我們這邊把a上標l-1下標1,跟a上標l-1到下標k,用一個值a上標l下標1來代表它,那這邊就以此類推。
link |
那問題是我們要怎麼選出代表的值呢?我們怎麼選一個值來代表前一個layer的k個output呢?那這件事情其實有不同的做法,比如說你可以做average pooling,把前k個值平均起來,就當作它們的代表。
link |
平均當然可以當作代表嘛,對不對?那你可以做max pooling,選最大的那一個當作代表。我們可以把前面k個值取一個最大的當作代表。
link |
你可以做L2 pooling,如果覺得max pooling太武斷了,只選最大的那一個,你可以選L2 pooling,你把所有的值都平方開根號再除以k。
link |
那你可能就會很糾結說,我到底要選哪一個pooling呢?就開始糾結。那其實你其實也不一定要那麼糾結,因為你可以做一個東西叫做mixed pooling,也就是說你並不一定只能用一個值來代表一個group,你可以說我就用兩個值來代表一個group了。
link |
其中一個值就是min,另外一個值就是max,這樣你就高興,就不用糾結在這個問題上面了。文件上確實有人這樣做過,我看一下,也有得到好像比較好的performance。
link |
那其實你也不一定只能做max pooling,就max不一定只能max一個,你其實可以max top k一個,那至於k要選多少你還可以自己決定,你可以說我要選top3,那就是用3個value來summarize前面那個group,你也可以top5就5個value來summarize前面那個group。
link |
所以有各種各式各樣的做法。好,那再來的問題就是哪些output,前一個layer的哪些neuron的output需要被group在一起呢?應該把誰合在一起,應該把誰視為一個group呢?這個也有不同的做法。
link |
那一個做法是說,我們說如果今天有neuron它屬於同樣的filter,那我們把它group在一起,我們把同樣的filter的outputgroup在一起,比如說這邊是1跟3屬於同一個filter,2跟4屬於同一個filter,我們把同一個filter的outputgroup在一起。
link |
這可能是你比較常見的做法。那這樣可以做到的事情就是sub-sampling,因為如果今天這兩個receptive field,1,2,3跟3,4,5這樣的receptive field,它們的距離很近,那apply同樣的filter,搞不好output根本就差不多,那我們就只選其中一個去代表性的出來做代表就好了。
link |
這樣做的事情就是sub-sampling,丟掉一些可能是redundant的information。但是其實還有別的做法,舉例來說,你可以說,我不要把同樣的filter的outputgroup在一起,我要把不同的filter,但是對應到同樣的receptive field的neurongroup在一起。
link |
比如說這邊有1,2,3這個receptive field,然後我們apply四個filter,分別產生1,2,3,4這個output,然後我們說我們要把1,2group在一起,3,4group在一起,當然可以。
link |
其實常常會有人來問我說,我這樣做可不可以,那樣做可不可以,其實都可以,只是有時候會有好壞之分,但是沒有什麼方法是不對的,方法之間並沒有所謂的對錯,它其實只有好壞之分而已,但是這個方法其實也不會給你差的結果,這樣子比較少見,但是它也是有道理的。
link |
其實如果你這個receptive field你把它擴展到整個input,也就是其實我們是在考慮fully connected的network而不是convolutional network,假設這個receptive field其實是前面layer所有的output,那就是fully connected的network了嘛,就不是convolutional network了嘛,對不對。
link |
如果今天在這個case,我們把不同的field group在一起,其實我們做的就是mixed out network,其實我們做的就是mixed out network,那這麼做有什麼好處呢?這麼做,這麼做的network可以把長得不像的pattern,但是是同一類的東西,長得不像,把它歸類在一起。
link |
舉例來說,如果有一個火車,火車正面看是個正方形,側面看是個長方形,不像,它們會有不同的field來detect,那這個時候machine就可以把它group在一起。
link |
我這邊舉個例子是這樣子,就是1有很多種寫法,你可以寫這樣,也可以寫這樣,那可能第一個field負責偵測這種1,第二個field負責偵測這種1,或者是7可以寫這樣,也可以寫這樣,第三個field負責偵測這種7,第四個field負責偵測這種7。
link |
但是我們可以把1跟2group起來,所以今天只要有一個1進來,不管它是長什麼樣子,只要它能夠activate,它只要是這種pattern或這種pattern的其中一個,只要它可以activate neuron1或者是neuron2的其中一個,我們就可以判斷它是1。
link |
或者是有一個7進來,不管它是長這個樣子還是長這個樣子,只要它能夠activate其中一個neuron,我們就有辦法判斷它是7。那這個時候你就會有一個,在這邊我接下來問大家有沒有人有問題呢?
link |
有嗎?沒有嗎?沒有嗎?其實這邊有些人就會糾結在一個問題,你怎麼知道第一個和第二個neuron是偵測同樣的pattern呢?你怎麼知道它們偵測的pattern都是代表1呢?對不對?
link |
我們這邊說1跟2偵測到同樣都是代表1的pattern,所以我們可以把它group起來去match,只要其中一個被activate,我們就可以偵測出1了。但是你怎麼知道1跟2代表1,3跟4代表7,所以我們把它group在一起呢?你根本不知道啊!
link |
所以其實這個是這樣子的,這個想法很神聊,這個很難解釋,你要反過來想這個問題,並不是因為它們偵測到同樣的pattern,我們把它們group在一起,而是因為我們把它們group在一起,經過training以後,它們會偵測同樣的pattern。
link |
這樣大家聽得懂嗎?這句話其實應該是很有哲理的,讓大家回去思考一下。我再重複一次,它們並不是因為偵測到同樣的pattern所以在一起,它們是因為我們把它們放在一起,所以它們才偵測到同樣的pattern。
link |
好,那最後,要為我們這部分很快複習了一下,Fully Connected Network, RNN,還有Convolutional Network,那我們這邊就只是做一個summary。
link |
那我們要怎麼summary呢?常常有人會問說,我可不可以把CNN、RNN疊在一起?當然可以,而且這是一個還頗typical的做法。
link |
那這邊就是舉一個真正的例子來說明怎麼hybrid這種不同的network。舉例來說,這邊有一個network是拿來做語音辨識的,這個Google paper發表在InterState的2015。前幾個layer是用CNN,接下來幾個layer是用LSTM,最後一個layer用Fully Connected的layer。
link |
那其實這種先用CNN,再用LSTM,最後再加一點Fully Connected這個架構,在語音辨識上現在算是蠻standard的做法。
link |
那但這篇paper還蠻特別的,它特別的地方是什麼呢?它特別的地方是,它沒有tone feature。所謂的tone feature的意思是說,一般語音的聲音訊號,你不會真的拿聲音訊號來做語音辨識。
link |
聲音訊號就是你錄音以後得到的那個,比如說PCM,你不會直接拿來做辨識,你會做什麼?你會先tone feature,比如說至少先做個fural transform,然後再過一些filter back,最後經過一些step,然後取出一個NLCC,然後NLCC來做語音辨識,這樣才能得到好的結果。
link |
這篇paper的做法就是,它特別的地方就是,它什麼都沒有,它的input就是聲音訊號的sampling,它連做fural transform都沒有。
link |
那output,output這邊就是,這邊output其實是detect的那個state啦,然後先detect出state以後,再有一個decoder會把state轉成文字,所以它這邊應該不是直接output文字。不過它這邊的input是raw的waveform,是沒有經過任何處理的聲音訊號,也就是比如說一秒八千個這種sampling。
link |
那你看它就說,input一個raw的waveform,這個raw的waveform總共有大N個sample。
link |
好,那它就說,這個是input,有大N個sample,然後接下來呢,在時間的這個方向上呢,這個就是我們剛才看到的one-dimensional single channel的case,在one-dimensional方向上apply convolution,然後這邊這幾個東西呢,是filter。
link |
這邊的filter呢,也就是一維的。這樣大家了解我的意思嗎?就是現在有一個input的聲音訊號,雖然這邊畫成一個波浪的樣子,但是你的聲音訊號就是每一秒有八千個點嘛,對不對?
link |
那接下來呢,你apply一個filter。這個filter呢,也是one-dimensional的。這個filter是one-dimensional的,這是一個filter。
link |
那雖然我這邊畫成這個waveform的樣子,但是你的filter它就是一排數字啊,就是一排數字,你把這一排數字按照它的value高低畫出來,就變成一個這樣子的waveform。
link |
然後呢,接下來再shift一下,因為它的receptive field是,就這一段是它的receptive field,然後接下來下一個receptive field在這邊,那receptive field和receptive field之間呢,有些重疊。
link |
所以這個filter,apply在這個地方得到一個值,apply在這個地方得到一個值,apply在這個地方得到一個值,就是投影片上所畫的這個部分。
link |
好,那接下來呢,取max pooling。這邊有總共,你看這邊它說n乘以p個weight是什麼意思呢?n是filter的長度,所以那個receptive field的長度是n。p是說這邊有p個filter,這個filter長什麼樣子是自己學出來的。
link |
好,然後呢,接下來做,就是你會得到一排值,你會得到n減n加一個值,你直接回去算算看是不是每個filter都給你n減n加一個值。
link |
接下來做max pooling,所以總共有p個filter你就得到p個值,那這個就是一個p-weight的vector,那這個p-weight的vector會成為下一個block的input。
link |
所以,Maker很好奇說,那這邊的這些filter,它認出來是什麼東西呢?它認出來是這個樣子,這個圖不知道大家看不看得懂。
link |
最左邊這個圖是人手design的filter,這個是人手design的filter,這邊是filter編號0到,應該是filter編號40,那每一個color,每一個藍代表了一個filter。
link |
那縱軸是什麼?縱軸代表的是frequency,如果你聽不懂這個就沒有關係啦,電子機器人應該是聽得懂啦。
link |
所以這邊就是有一大堆bandpassfilter,黑色的部分就是它的passband,我們把這些bandpassfilter,由它的passband由低頻排到高頻,你會發現低頻的比較多。為什麼?因為人聲音訊號在低頻的地方是比較informative,高頻的地方是沒有那麼多訊號的。
link |
所以高頻的地方訊號比較少,高頻的地方每一個bandpassfilter的passband比較大,而且它比較粗,但是在低頻的地方要比較細,那這個就是人手定的。
link |
右邊這兩個是machine在不同的case學出來的filter,你就把每一個filter當作一個訊號來看,然後做filter transform,算它的bandpass。
link |
你會發現說我們也是認出一排filter,相較於這個人手design的filter,它其實在低頻的地方,我們看中間這個例子,在低頻的地方的filter是更多的。
link |
然後在高頻的地方的filter,每一個filter佔的passband又更大。這件事也是合理的,因為人的聲音訊號需要的資訊應該都小於4kHz,這就是為什麼電話線是the sampling rate是8kHz,因為我們要聽清楚聲音只需要4kHz的訊號就好。
link |
所以你看這邊,它在4kHz大概是這個範圍,在這條線以下放了很多filter,在這上面就只放幾個filter,這個是machine自動認出來的。
link |
所以你這邊完全不用管它是什麼,如果你沒有學過訊號系統,不知道這個圖是在幹嘛的話,也沒有關係,因為反正machine自己會認出來,你就都不用學訊號系統了。你如果兜起來,印券下去,它就自己學會做filter transform了。
link |
然後這邊我們就得到一個vector,這是time domain上的convolution,這邊的每一個點其實就代表了某一個frequency的domain,某一個frequency上面有沒有值。
link |
因為其實你只要認出來每一個filter,基本上其實就是對應一個frequency,它就是一個bandpass filter。然後接下來做frequency domain上的convolution。
link |
這個convolution,它的receptive field是在frequency domain上。這件事情其實也是make sense的,因為有時候不同的pattern,同樣的pattern它可能會出現在低頻的地方,出現在高頻的地方。
link |
比如說男生跟女生說話,他們說的同樣的音速,他們發的同樣的聲音,你聽起來很不一樣,但是他們在頻率上看起來的pattern可能是一樣,他們只是頻率的高低不一樣。
link |
所以這邊做一個在frequency方向上的filter。
link |
好,那接下來frequency方向上的filter,這邊就是一個convolution layer,就給你另外一個output,就丟到LSTM裡面去。然後接下來,其實這邊每一個,這邊input只有n個sample,所以他們其實就只考慮一個區間而已。
link |
所以對一段很長的聲音訊號,你要apply這整個network很多次,對最左邊這個紅色方塊,apply兩次convolution,LSTM,LSTM要做三次,再做DNN,然後得到output,就告訴你說,對一段聲音訊號,它是對應到哪一個辨識的state。
link |
如果你不知道state是什麼,你就想成是音標好了,雖然它其實比音標還要小的東西。好,那這個要反覆apply很多次,最後你再把這個network的output拿去做decode,把這個state解回原來的語音辨識的結果。
link |
總之這個例子想要表達的是,你可以把CNN、LSTM和DNN混著用,你要怎麼設計你的model的架構,都是可以的,都會看你高興。