back to index
Computational Graph & Backpropagation
link |
可以做gradient descent就可以train neural network,那我們今天要講的是怎麼算gradient,那我們當然都知道說算gradient就是用backpropagation,
link |
backpropagation就是一個很有效率的來算這個gradient的方法,那算出gradient以後你就可以做gradient descent,那當然backpropagation過去也講過很多次了,
link |
我把一些過去上課錄影的錄影放在這邊,那其實這邊講的,今天要講的跟傳統的typical的講法比較不一樣,
link |
這邊要用computational的graph來講算gradient這件事,我們要講說什麼是computational的graph,然後怎麼用computational的graph來算gradient,
link |
那像tensorflow,fiano,cmtk基本上都是based on computational graph來算這個gradient的,那什麼是computational的graph呢,
link |
所謂的computational graph的意思就是說,這個graph它是一種語言,這個語言是拿來描述一個function用的,
link |
我們知道一個neural network就是一個function嘛,所以我們會需要描述function的語言,那computational graph就是一種語言,
link |
你可以看了它的graph以後,一眼就可以知道說現在我們要描述的這個function長什麼樣子,那在這種graph上面,其實這種graph有不同的定法,
link |
那你只要統一就行了,那所以在這份投影片裡面,其實我平常在畫那些neural network的時候,其實也沒有用computational graph的畫法來畫,
link |
因為有時候那樣畫會不太簡潔,所以其實只有在這一頁投影片裡面,我們才會統一用computational graph的畫法來畫一個neural network。
link |
好,那這邊呢,每一個node代表一個variable,每一個node它可以是一個scalar,它也可以是一個vector,它也甚至可以是一個metric,
link |
不只是二維的,它可以是更高維的metric,這邊的每一個edge代表了一個operation,所以operation就是一個simple的function。
link |
以下舉一個例子,假設我今天有一個function叫做y等於f of g of h of x,如果用computational graph的話要怎麼畫呢?
link |
那我們先把這個function拆解成比較簡單的樣子,u等於h of x,v再把u帶到g裡面得到v,v等於g of u,再把v帶到f裡面得到y,y等於f of v。
link |
好,那我們這邊呢,x是一個variable,把x帶到h裡面去就得到u,這一條箭頭就代表了h這個function,那h連著x指向u,
link |
意思就是說把x丟到h這個function裡面,我們就得到u這個output,既然現在把u丟到g這個function裡面,我們就得到v這個output,把v丟到f這個function裡面,我們就得到y這個output。
link |
那有時候一個function它可以有不只一個input,如果有一個function不只一個input,我們怎麼表示它呢?
link |
那就是這樣,假設有一個function f,它input b跟c,output a,那我們表示它的方法就是,我們有b跟c這兩個變數,這兩個變數我們都只連到a,然後這兩個箭頭合起來就是我們的function f,
link |
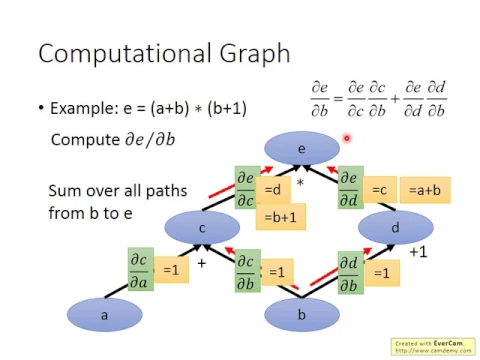
然後a是output,跟a相連的這些b跟c就是它的input。那computational graph怎麼畫呢?那我們這邊再舉一個例子,這個1等於a加b乘以b加1,這個是小學生的數學。
link |
我們就定說c等於a加b,然後d等於b加1,然後e等於c乘以d,然後你就可以把這個computational graph表示出來,我們有a跟b這兩個變數,它們是整個graph的leaf,它們前面沒有其他東西了。
link |
那a跟b相加,a跟b相加得到c,b加上1得到d,這個箭頭代表的是加1這個function,然後c乘上d就得到了1。
link |
那如果你今天有了這個graph以後,你要實際計算abcde的數值是很容易的,就說a代2,b代1,然後你就把2跟1順著這個graph一路讓它漲上去,你就把a加上b得到c,b加上1得到d,再把c跟d乘起來就得到了1。
link |
那在講下去之前,這個graph有什麼好處呢?這個graph的好處就是,我們在這個graph上面算每一個variable的gradient是容易的,我們等一下可以輕易地用這個graph來算出每一個variable的gradient。
link |
但是在做這件事情之前,我們需要嵌弱,這邊是秒複習一下嵌弱。有一個function z等於f of x,然後y等於g of x,z等於h of y,然後呢,這邊如果你把它的這個graph,computation graph畫出來,就是x有放到g裡面得到y,y放到h裡面得到c。
link |
那如果按照嵌弱,我要算底x分之底z的話怎麼辦呢?我們知道底x分之底z,因為我們從這個computation graph上面我們可以看到說,x會影響y,y會影響z,所以底x分之底z就是底y分之底z乘以底x分之底y,這樣對不對?
link |
好,那這邊有一個case 2,那case 2是什麼呢?case 2是說,z等於f of x,然後這個f of x長什麼樣子呢?x等於g of x,y等於h of x,z等於k of x,y,如果把computation graph畫出來,就是s帶到某一個function得到x,s帶到某一個function得到y,x跟y帶到某一個function得到z。
link |
如果我們今天要算底x分之底z的話怎麼辦呢?我們可以從computation graph上面看出來說,s影響了x跟y,x跟y又影響了z,所以底x分之底z就是x對,就是s對z的片尾。
link |
這邊有寫錯嗎?沒有寫錯,不好意思。這個是s對x的尾分乘上x對z的片尾分,s對y的尾分乘上y對z的片尾分,這個地方就代表了這一條路徑,然後這個地方就代表了這一條路徑。
link |
所以今天給我們看一個computation graph,就等於是告訴我們,我們要怎麼用這個圈若來表示一個尾分,所以這邊就用剛才的example來做個例子。
link |
假如我們要算partial b分之partial 1,我們要算b對1的尾分的話,怎麼做呢?因為b會透過c再走到1,b也可以透過d再走到1,所以b對1的尾分有兩條路徑,一條是b影響cc影響1,b影響cc影響1,一條是b影響d,d影響1,b影響d,d影響1。
link |
好,那如果我們今天要真的做這個片尾分的話,首先你第一件事情就是把這邊每一個箭頭,把每一個箭頭的這個片尾分都算出來。
link |
什麼意思呢?你就算出,比如這個箭頭是連接a跟c的箭頭,你就算出a對c的片尾分,這個箭頭是連接b跟c的箭頭,你就算出b跟c的片尾分,你就把每一個箭頭上的片尾分都算出了。
link |
這個很容易,因為我們其實知道每一個variable之間的關係,所以要算某一個箭頭上面的片尾分是容易的,a對c的片尾分就是1,對不對?然後因為c等於a加b,所以這邊就是1,然後這個也是1,這個也是1,這邊是d,因為1是c乘以d,所以1對c做片尾分會得到d。
link |
然後我們又知道d等於b加1,所以我們可以直接代說d等於b加1,那d對1的片尾分呢?因為1是c乘以d,所以d對1的片尾分就是c,然後c就是a加b,所以你可以輕易的把這個箭頭上的片尾分都算出來。
link |
那這個時候,你要算某一個node上面的variable對另外一個node上面的variable的片尾分就很容易了,舉例來說,如果我們要算b對1的片尾分,我們就是找出所有b到1的path,從b這個node走到1的這個node有哪些走法,所有的路徑都找出來,你可以走這一條路,也可以走這一條路。
link |
再把一路上所有的,你算出來的這個片尾分的值相乘,你要把一路上所有的這個片尾分都乘起來,走這一條路,你得到1乘以b加1的片尾分,走這一條路,你得到1乘以a加b的片尾分,對不對?
link |
那你就把這一條路上的片尾分跟這一條路上的片尾分加起來,那你就得到Path of b分之Path of e,就結束了。你可以自己check一下,看看這個做法算出來對不對,這個是很簡單的,隨便微分一下就可以得到答案。
link |
好,我們來上課吧,剛才講到這一頁,剛才用的是symbol來描述它,你當然可以用數字來描述它,你就先代,比如說a等於3,b等於2,a等於3,b等於2的時候,c等於5,d等於3,這個也是秒算,那e等於15。
link |
你先要做一次這個fee forward,把所有的variable,這個verb上的variable數字都算出來,然後呢,這個微分的部分,它的這個value其實就是這個verb上面某一個node的value,所以d你就可以把它的值3拿過來,如果是c你就可以把它的值5拿過來。
link |
那現在如果叫你算這個b對1的片尾分的數值,如果要你算b對1的片尾分的值在a等於3,b等於2的condition下的時候怎麼算呢?你先把所有的edge上面的值都算出來,然後接下來在b這個地方放1,然後你把你從b這個點往前走,找出所有可以走到1的path,
link |
比如說他走這條path,1乘上1還是1,然後再把1乘上3得到3,然後這邊1乘上1還是1,1乘上5得到5,然後你把這個3跟5加起來就得到8,所以這個微分的結果就是8。
link |
那如果你今天要換算這個a對1的片尾分在a等於3,b等於2的情況下,那其實也是一樣,找出a到1的所有路徑,然後就從這個a開始走,一路走到1。
link |
a走到c要乘上1,所以你就把1這個值放在這邊,然後你就把1這個值放在c的這個點,然後c走到1要乘上3,所以a對1的片尾分就是3。
link |
這個應該很容易吧,我想這個應該是沒有什麼問題,然後如果今天要同時算a對1的片尾分還有b對1的片尾分在a等於3,b等於2的情況下,要同時算這兩者的話,怎麼做呢?
link |
我們需要一個reserve mode,我們需要一個反向的做法,我們剛才看的都是正向的做法,就從b走到1,從a走到1。但是如果要我們要求我們是同時算出a對1的片尾分,b對1的片尾分,這個時候我們就要用反向的做法是比較有效率的。
link |
當然你可以分兩次做,先算出a對1的片尾分,再算出b對1的片尾分,但比較慢。如果我們今天用反向的做法,我們可以同時算出a對1的片尾分和b對1的片尾分,怎麼做呢?
link |
從1開始走,把數字1放在1的這個node,然後從這個node就散播出去,通過這個3的path在這邊你得到3,通過這個5的path在這邊你得到5,再把3乘以1加5乘以1你就得到8,再把3乘以1你就得到3。
link |
就把3呢,透過這條路徑再走下來你就得到3,然後把3乘以1加5乘以1你就得到8,那在這個點上你就得到partial a分之partial e,在這個點上你就得到partial b分之partial c。
link |
事實上在這個地方你也可以得到這個值對1的片尾分,你也可以得到這個值對1的片尾分。那假設今天這個graph它只有一個root,那你從這個root開始走,你就可以把這個graph上面所有的variable它的片尾分都一次算出來。
link |
那這樣子做的好處是,如果你今天這個computational graph只有一個root,也就是說你的最終的function它的output只有一個value,而你又需要同時算大量的不同的值的片尾分的時候,用reverse mode會比剛才我們看的forward mode還要更有效率。
link |
而在做neural network的時候,我們需要的就是這個reverse mode,為什麼呢?因為我們在做neural network的時候,我們要計算片尾分的對象其實是那個cost function對不對?我們是要對,又或者是叫loose function,我們要對這個cost function算片尾分,而cost function,這個function它的output就是一個scatter。
link |
所以如果你把cost function用computational graph來描述的話,它只有一個output。那今天我們又要同時算這個neural裡面所有參數跟cost function的片尾分,所以我們從root開始做reverse mode,在對cost function算片尾分是比較有效率的。
link |
那另外一個狀況是,有時候我們會有parameter sharing這種狀況,也就是說同樣的variable它出現在這個graph數個地方,這個時候怎麼算它的片尾分呢?
link |
這件事情在neural network裡面常常發生,比如說我們看CNN,它就有shared variable,對不對?我們才剛講過,RNN它其實也是shared variable,它把同一個function在整個time sequence上反覆使用,它也是shared variable。
link |
有shared variable的話怎麼做呢?這邊舉個例子,假設一個function y等於x乘上exponential的x平方,這個式子如果我們要把它用computational graph來描述的話,它長什麼樣子呢?把x跟x相乘得到v,把v取exponential得到u,把u再乘上x得到y,那我們就得到這個computational graph。
link |
接下來我們計算partial x分之partial y,如果我們要計算partial x分之partial y的話怎麼做呢?我們先把每一個edge上面的微分都算出來。
link |
如果把這個x對v做微分,我們得到的值是什麼呢?我們得到的值就是v等於x平方。就是說,你說v等於x平方微分,對x微分不是應該是2x嗎?
link |
可是現在這個是比較難理解的地方,我們必須要先把每一個node上面的x當作不同的x來看待。你就假設這些x都是由下表的,這個是x編號1號,這個x編號2號,這個x編號3號。
link |
所以這個x編號1號乘x編號2號等於v,所以你把這個x編號1號對v做偏微分,你得到的是x編號2號,但它其實還是x。
link |
所以這邊也是x,這邊也是x,然後v對u做偏微分,你得到的還是u,對不對?因為v是exponential u,因為u是exponential v,exponential v對v做偏微分還是exponential v,所以得到的值就是u。
link |
這邊u乘上x得到y,這邊做偏微分就是x,這邊做偏微分就是u。
link |
那你看這裡,這邊這個u啊,u是什麼呢?u你可以,因為u的值我們是知道的,u就是exponential的x平方,那這個u就是exponential的x平方。
link |
偏微分的這個symbol我們都算出來了,那partial x分之partial y它的值應該是什麼呢?我們現在先把這三個x當作視同不同的variable來看,那這個x對y的偏微分就是從y走過來,也就是exponential的x平方。
link |
那y從這條路徑走過來,它會得到另外兩個x的偏微分,那y從這個路徑走過來,你得到的是x乘1的x平方再乘x,然後y從這個路徑走過來,你是得到x乘1的x平方再乘x,得到這個路徑。
link |
好,那接下來呢,實際上x對y的偏微分是什麼呢?我們現在有三個偏微分,它的值呢不是一樣,那實際上x對y的偏微分其實就是把這三項加起來,就是x對y的偏微分。
link |
所以今天如果你要考慮share variable的配置,那你可以自己check看看,因為這個你要做,自己算偏微分還蠻容易的嘛,這個你要算微分還蠻容易的,你就自己算算看,看看對不對。
link |
那今天如果是share variable的情況下呢,我們就要把同樣的參數先當作不一樣的參數來看,然後算完以後再加起來。
link |
這樣大家了解我的意思嗎?你先把這三個x當作x編號1,x編號2,x編號3來看,然後再把他們的偏微分分別算出來,然後再把他們通通加起來,那你就可以得到x對y的微分。
link |
這樣講出來大家有問題嗎?好,那接下來就進入neural network的部分,剛才講的東西是general,跟neural network沒有直接的關係。
link |
那現在呢,我們就要講說,如果有一個fully connected的free-forward network,用computational graph來算它的微分的話,我們要怎麼做?
link |
那我們先來很快的複習一下一般的講法,一般我們說要算微分就用back propagation,這個back propagation裡面呢,分成兩個階段,一個是forward path,一個是backward path。
link |
那這個,每一個參數啊,比如wijl,wijl是dL over layer的weight,它從dL減一個layer的d這個neural,直到dL over layer的dI。
link |
我們把這個weight對c呢,做偏微分,那這個偏微分呢,等於這個weight對z做偏微分,這個z呢,是i的這一個,也就是這個weight所連到的那個neural的activation function的input,這個z呢,是dI的neural的activation function的input。
link |
把這個z呢,對w做偏微分,乘上把c呢,對z做偏微分。
link |
好,那我們只需要用forward path和backward path,分別把這兩項走出來再相乘,我們就可以計算出w對c的偏微分。
link |
好,那我們先來看forward path,w對z的偏微分怎麼算呢?那這邊我們就不需要推導,我們就直接告訴大家結果,w對z的偏微分就是前面dL減一個layer的output。
link |
ok,就是w前面是從誰來的,是從d這個neural來的,那d這個neural的output就是w對z的偏微分,那如果d最後這個L減一個neural已經是input的話,那這個偏微分的結果呢,就是input,就是input的d這個dimension的feature。
link |
ok,好,那所以要求到這個值,你只需要一個forward path,就是一般的before and after的運算就可以把這個值求出來,那接下來看一下這個backward path。
link |
那backward path呢,我們要求一個值叫做這個error signal,那這個error signal呢,是我們對dL個layer的dI個neural,我們可以求一個error signal。
link |
這個值就是partial z分之partial c,怎麼求它呢,我們要做一個backward path,那這個backward path呢,就是我們要把原來的neural逆轉,不是把原來的neural逆轉,把原來的整個network逆轉。
link |
那這個network的input就是y對c的歸零,這個network的input呢,就是一個vector,這個vector裡面,這個vector呢,就是y對c的歸零,把這個vector呢,丟給一個,丟給一排neural。
link |
而這排neural呢,它們的activation function呢,並不是z-mode,它們是一排這個op-amplify這樣子,然後這每一個op-amplify它放大的倍率呢,就是它的微分值,就是它每一個op-amplify其實在正向的network裡面都對到一個neural。
link |
那個neural的activation function的微分值呢,就是這個op-amplify的那個放大倍率這樣子。好,那你把這個gradient呢,丟到這排op-amplify裡面得到一排output,這個output呢,再乘上一組weight。
link |
這組weight是什麼呢?這組weight是原來第L個layer的那個weight matrix的transpose,我們原來在做forward的時候乘上WL,在做backward的時候乘上WL的transpose,然後再丟到下一組op-amplify裡面,然後就可以算出這個值,然後再把紅色框框值和綠色框框值相乘,就得到最後微分的結果,一般是這麼說的。
link |
而現在我們用computational graph來算一下,那在用computational graph來算微分之前,我們當然要先兜出network的computational graph,它長什麼樣子呢?
link |
那我們知道一個network呢,就是一堆矩陣的operation,那如果把這個operation用一個graph來表示它的話,那它長什麼樣子呢?首先input的地方呢,是一個variable x,還有我們需要一個variable w1,你知道這個variable可以是matrix,所以w1是一個matrix,我們需要一個variable b1。
link |
好,接下來我們先把w1乘x加b1,w1乘x加b1得到z1,所以呢,我們有一個operation,這個operation呢,它是吃x跟w1跟b1,它的這個operation呢,就是把w1乘上x加b,這個operation,這個有三個箭頭的operation,就是把w1乘x加b得到z1。
link |
然後再把z1呢,通過一個activation function得到a1,所以這個箭頭代表的是activation function,input一個vector z1得到另外一個vector a1。
link |
然後另外呢,這邊又有兩個weight,w2和b2,又有兩個variable,w2和b2,把w2和b2跟a1一起,再通過這個operation得到z2,把z2通過sigmoid function得到y,這裡不叫sigmoid function,這是一個activation function。
link |
最後一個layer的activation function可能是softmax,這個畫法跟一般typical文化neural network畫法不太一樣,對不對,因為一般畫neural network是我們習慣說,w應該被放在a跟z中間,我們比較習慣這樣畫。
link |
但是如果放畫的是computational graph的話,每一個node都是一個variable,那我們現在我們的參數w跟b也是variable,所以w跟b也是node。
link |
所以他們像是從外面再加到主幹裡面,跟a再一起產生z,如果是computational graph正確的話,你應該畫成這樣,而不是把w插在a跟z中間。
link |
但是我們其實並不是,我們接下來要做歸根descent,我們要算微分,但我們算微分的對象並不是y,我們算微分的對象其實是cost function。
link |
怎麼算cost function呢?cost function就是,我們這邊有另外一個variable,y hat,y hat代表的是,它是個vector,它代表的是標準答案,那我們把y hat,y hat帶到一個function l裡面,得到一個值c。
link |
那這個l就是你的loss function,看你要怎麼去evaluate這個y hat跟y,你如果是一個regression的problem,你或許會選擇square loss,如果你今天是classification的problem,或許你會選擇cross entropy等等。
link |
這邊就depend on your case,你會選擇一個適當的l,那我們就是用這兩個箭頭代表l這個function。
link |
好,那接下來我們就是要計算w1,w2,b1,b2,對c,對最後這個c的這個片尾分,那注意一下,c是一個scalar,對所有的level來說,最後它的那個cost function的output,那個loss的值,那個value,它都是一個scalar,所以你input很多東西,你input很多東西,那output最後就是只有一個數值而已。
link |
好,那就按照我們剛才學的做法,首先第一步就是我們要把每一個edge上面的這個尾分都算出來,每一個edge上面的片尾分都算出來。
link |
然後算出來以後呢,就用reverse mode,從c這個地方一路逆向走回來,你從c這個地方,假設每一個edge上面的尾分都算好了,那我們就可以一路逆向走回來,逆向走回來,逆向走回來。
link |
你就可以把所有的參數,對c的片尾分都算出來了。那等一下的那個投影片呢,它的符號比較多,我相信一定會有錯,大家可以仔細的檢查一下。
link |
好,那我們這邊呢,其實就遇到的第一個問題就是,你看啊,這邊這個什麼br是vector,a是vector,z是vector,w是matrix,我們今天要算每一個edge,我們都要算它的input的variable對output的variable的片尾分。
link |
可是一個vector,比如說我們這邊舉的是z1跟a1,一個vector z1對另外一個vector a1的片尾分到底是什麼意思呢?我把一個vector對另外一個vector的片尾分到底是什麼意思呢?
link |
那我知道這個呢,在微積分裡面呢,我至少在電機系的微積分是沒有講這個的,所以我們可以用一頁的投影片很快的講一下。我們把vector對vector做片尾分,我們得到的東西其實就是,講後面的matrix。
link |
什麼意思呢?我們現在有一個function,y等於f of x,x跟y都是vector,x是三維的vector,它有三個component,x1,x2,x3,y是二維的vector,它有兩個component,y1,y2。
link |
把x對y做片尾分的話,那我們得到的是什麼呢?我們得到的就是一個矩陣,我們得到的就是一個matrix。定義就是這樣,把一個vector對另外一個vector做片尾分,我們得到的就是一個matrix。
link |
這個matrix的高啊,也就是它的這個row的數目啊,就是分母的那個vector的dimension,那它的color的數目就是分子的那個vector的dimension。
link |
了解嗎?就是現在y有兩維,所以這個jacobian matrix,這個matrix就叫jacobian matrix,這個matrix它的高呢,就是兩維,它的寬呢,就是三維。
link |
好,那這個matrix的value分別是什麼呢?這個matrix裡面的value就是,就x呢,你就把x1,x2,x3放在這邊,y你就把y1,y2放在這邊,然後你把這個x1對y1做片尾分,x1對y2做片尾分,x2對y1做片尾分,x2對y2做片尾分,x3對y1做片尾分,x3對y2做片尾分。
link |
你拿這三個值,對,這兩個值,都去分別做片尾分,得到六個值,然後把它放到這個matrix裡面,就是jacobian的matrix。
link |
好,再來我們舉個例子,這邊有一個function,input是x1,x2,x3,output呢,y1,y2就是x1加x2,x3,二兩倍的x3,我覺得應該寫個y啦,y等於這個東西,y等於這個東西。
link |
我們來算x對y的jacobian matrix,它應該長什麼樣子呢,y是二維,所以它的高就是二維,x是三維,所以它的寬就是三維,然後接下來呢,第一個value,左上角這個value是什麼,它是x1對y1的片尾分,所以是1。
link |
第二個value,上面中間這個value,它是x2對y1的片尾分,x2對y1的片尾分,所以它是x3。
link |
右邊這個呢,它是x3對y1的片尾分,所以它是x2。那下面呢,下面都是對y2的片尾分,下面這三個值都是對y2的片尾分,x1對y2的片尾分是0,x2對y2的片尾分也是0,x3對y2的片尾分是2。
link |
那所以我們就把這個jacobian的matrix算出來。所以我們用computational graph來算這個,我們現在用computational graph,我們需要算所有edge上面的片尾分,如果今天這個edge的兩邊都是vector的話,那我們其實就是得到的,得到的就是一個matrix,就是一個jacobian matrix。
link |
好,那所以我們現在就從c這個地方一路往回走,一路把一路上的片尾分通通很麻煩的把它算一算,那我們算一下y對c的片尾分,我們來算一下y對c的片尾分。
link |
這個c它是只有一維對不對,它只有一維,然後y是一個vector,所以這個東西它算出來就是一個扁的長條狀的東西,了解吧?
link |
就是因為這個c只有一維,所以如果這個東西你用jacobian matrix來表示的話,它的高就是一個dimension,它的寬就是看你output的那個y有幾個dimension,就是做digital classification,那y就是十維,長條狀的東西寬就是十,高就是一。
link |
好,那計算一下y對c的片尾分,那就要depend on your loss function怎麼定義了。
link |
那如果是分類的問題的話,一般你的y hat就是用one-half的那個code來表示對不對,就是只有其中一維是1,其他都是0。
link |
那我們假設是1的那一維叫做第r維,那這個時候我們的loss function會怎麼定義呢?
link |
我們會定義說c就等於負的logyr對不對,cross entropy的定義就是這個樣子,所以c等於負的logyr。
link |
這個yr是這個network output的第r維,但是這個r是哪一維取決於它取決於這個target的哪一維之一。
link |
所以network的output跟target都有用到,network提供了yr的value,output的target提供了到底這個r是哪一個dimension。
link |
好啊,那如果我們算partial y分之partial c的話,我們得到的是什麼東西呢?我們剛才有講過說這是一個長條狀的vector。
link |
那這個vector其實大多數的地方應該都是0吧,因為只有在i等於r的時候,如果今天拿yi,y的其中一個element,yi對c做片尾分,
link |
在i等於r的時候,我們會算出來的片尾分就是負的yr分之1。
link |
你把yr對這個做片尾分就是負的yr分之1。
link |
那如果i不等於y的話,那那個y就跟cross function是沒有關係的,所以它就等於0。
link |
所以得到了一個vector,那它只有在某一個dimension是負1除以yr,其他都是0。
link |
好啊,那接下來呢,再繼續往回走,我們現在遇到的是z2對y的片尾分。
link |
而z2跟y的中間就差了一個activation function,z2代入activation function就得到y。
link |
那z2對y的片尾分就是一個Jacobian matrix,這個matrix的高是y的dimension,寬是z2的dimension。
link |
那這邊呢,它會是方形的,對不對,因為z2跟y的dimension一定是一樣的,
link |
通過一個activation function並不會改變這個vector的維度,所以這個Jacobian matrix是個方形的東西。
link |
好,那這個Jacobian matrix的第i個row,第j個column,它的值應該是什麼呢?
link |
第i個row,第j個column就是partialyi除以partialz2的dj位。
link |
ok,就是row是由分母來決定,column是由分子來決定。
link |
怎麼算?如果i不等於j,那這個微分值應該是多少呢?
link |
如果i不等於j,這個微分值是不是應該就是0呢?因為zj跟yi,如果i不等於j,
link |
zj跟yi是八竿子打不著的東西,如果你的activation function是比如說sigmoid,il,那些,
link |
通通都是八竿子打不著的東西,ok,所以就是0,ok,那如果i等於j呢?
link |
如果i等於j的話,那就需要用到activation function,因為yi等於sigmazi,ok,
link |
那這個時候呢,你的這個微分的值呢,就是看說我們現在的zi,
link |
假設我們activation function是sigmoid function,你就看zi落在哪裡,
link |
然後看zi的所在的位置的切線斜率,這個切線斜率呢,
link |
好了,所以總體來說呢,總體來說,今天這個partial z to partial y呢,
link |
它是一個diagonal的matrix,因為它只有在i等於j的時候是有值的,
link |
那其他地方都是0,它是一個diagonal的matrix,那再來就是,
link |
如果今天用的不是sigmoid function,是一個softmax呢,
link |
我們在output的時候常常會想要用softmax function,
link |
如果是softmax function,你覺得它還會是diagonal的嗎?
link |
好了,如果今天這個sigma換成softmax的話,它還是diagonal的,
link |
你覺得它是diagonal的,同學舉手一下。
link |
你覺得它不是diagonal的,同學舉手一下。
link |
好,謝謝,謝謝,好,大多數同學覺得它不是diagonal,
link |
沒錯,如果今天這邊換成softmax的話,它就不是diagonal了,
link |
為什麼,因為今天在做softmax的時候,
link |
z的每一個dimension都會影響到y的每一個dimension,
link |
所以就不會有這種i不等於j,微分就是0的狀況,沒有這種狀況,
link |
所以如果今天換成softmax,它就不是diagonal了。
link |
好,那接下來就是繼續一路算下去,一路算下去。
link |
我這邊把那個bias都拿掉了,讓它比較簡單一點,
link |
這個z2跟a1和w2的關係是這樣子一個相乘的關係。
link |
我們先算partial a1分之partial z2,
link |
這個可能是比,也許這個比較好算一點。
link |
好,那我們得到,這個東西是一個Jacobian的matrix,
link |
它z有多少dimension,它高的就是多少。
link |
現在要問的問題就是,di的row,dj的column,它的值應該是多少呢?
link |
di的row,dj的column,也就是partial a這一分之partial zi,
link |
那這個很容易,你就把這個z跟a的關係寫出來,
link |
這我們在第一堂課的時候講過,把它寫出來,就是這樣。
link |
那寫出來你就會發現說,zi等於a1乘上wi1,
link |
加上a2乘上wi2,一直加到an乘上wi,
link |
那這邊裡面會有一項是wij乘上aj,
link |
那你得到的就是wij,所以我們得到的就是wij。
link |
所以di的row,dj的column,我們得到的就是w的di的row,dj的column的值。
link |
那所以這一個matrix不正好就是w2嗎?
link |
對不對,因為它的di的row,dj的column就是w2的di的row,dj的column,
link |
這一個講後面的matrix正好就是w2,我就把它換掉。
link |
我們要把w2對z2做偏為分,算它講後面的matrix。
link |
那這個w2它是個matrix,我們可以假設它是一個n乘以n為的matrix,
link |
如果它是一個n乘以n為的matrix的話,
link |
如果它是n乘以n為的matrix,那顯然,z2就是n為,a1就是n為。
link |
我們這邊可以把w2當作一個vector來看,其實是這樣子的,
link |
這邊我們可以把w2對z2的偏為分看作是一個tensor,
link |
但是我知道說,因為在我們線性代數裡面沒有講過超過二為的tensor的運算,
link |
所以我們就把它當作說這個w2它是一個vector,
link |
它的dimension就是n乘以n為,它是一個n乘以n為的vector,
link |
這樣做會讓算出來的結果有點不elegant,
link |
如果你用tensor來考慮它的話,用三為的matrix來描述這個偏為分的話,
link |
結果會比較elegant,如果是二為的話,硬把它弄成二為感覺沒有那麼elegant,
link |
好,那這個w2對z2的偏為分它長什麼樣子呢?
link |
w2本來是一個matrix把它硬拉成一個vector,所以它是n乘以n為,
link |
那現在呢,wij對zi的偏為分是什麼呢?
link |
其實我們只要算出wij對zi的偏為分,
link |
那wij對zi的偏為分放在這個Jacobian matrix的哪一個位置呢?
link |
它的高是di的row,分母的地方是有下標i,di的row。
link |
分值的地方是,因為我們把這個ij硬拉成值了,
link |
所以這個column的index就是j乘以1乘以n加上k。
link |
好,如果今天i不等於j的時候,會發生什麼事呢?
link |
你看這邊,這個zi只跟wi有相關的位則是有關。
link |
那這個wij跟zi就是沒半毛錢的關係,
link |
如果i等於j的話,它們就變得有關係了。
link |
如果i等於j的話,下面這個j換成i的話,
link |
下面這個j換成i的話,它們就有關係了。
link |
會是這個a1的d,會是這個a1的dk位。
link |
這邊只想講一下說沒有用tensor講。
link |
這邊是a1,然後這邊是a1,這邊是a1。
link |
我們也可以順便算一下x對z1的片尾分,
link |
接下來,假如我們要算比如說w1對c的片尾分的話,
link |
我們把partial y分之partial c乘上partial z2分之partial y,
link |
它的高就會是最左邊的這個matrix的高,
link |
最左邊這個matrix是長條狀的東西,
link |
那這個最後一個matrix的寬是w1的element的數目,
link |
w1裡面有幾個element,它的寬就有多少,
link |
所以它的寬就是w1的element的數目,
link |
那這裡面你乘完以後這裡面的每一個值,
link |
就對應到w裡面的某一個element對c的片尾分,
link |
跟這個用forward pass和backward pass算出來的結果,
link |
感覺起來好像我們今天在用computational graph的時候,
link |
我們是用reverse mode算所有參數的片尾分,
link |
感覺好像只有backward pass,沒有forward pass,
link |
但這邊傳統的講法有forward pass也有backward pass,
link |
這邊好像只有backward pass,forward pass在哪裡,
link |
你還是需要forward pass,
link |
因為你想想看,我們要得到這些metric的值,
link |
我們要得到這些metric真正的值,
link |
我們需要知道這個節點的value是多少,
link |
我們需要知道這個節點的value是多少,
link |
所以你還是需要先算一個forward pass,
link |
你才能夠算出所有的edge上面的片尾分,
link |
所以我們還是先需要一個forward pass,
link |
假設你自己回去想要check一下說,
link |
這邊的delta是一個vector,
link |
這個matrix的size跟weight matrix,
link |
這個時候你需要對被wordpress得到的delta,
link |
這個recurrent neural,
link |
你就把computational graph畫出來,
link |
然後在reverse mode跑一發,
link |
我們來看一下recurrent neural network的function,
link |
如果我們要把一個recurrent neural network,
link |
表示成一個computational graph的話,
link |
這兩個相乘得到一個vector n1,
link |
就是上一個時間點的hidden layer的output,
link |
z1透過activation function,得到h1,
link |
把h1乘上output位wo,得到o1,
link |
最後再通過softmax,得到y1,
link |
整個recurrent neural network的computational graph,
link |
因為你要把這個recurrent neural network,
link |
這個recurrent neural network的,
link |
我們假設現在input有三個element,
link |
input sequence長度是3,
link |
我們要把input sequence長度是3的,
link |
ion的完整computational graph畫出來的話,
link |
事實上在computational graph裡面,
link |
我定義一個很複雜的function,
link |
再去sigmoid function得到h,t,
link |
所以我們可以定義一個function,
link |
這個是r,n的computational way,
link |
我們還沒有算它的cost function的computational way,
link |
那它的cost function的computational way,
link |
我們把y,1跟y,1 hat一起得到c,1,
link |
把y,2跟y,2 hat一起得到c,2,
link |
把y,3跟y,3 hat一起得到c,3,
link |
但是r,n真正考慮的是total的cost,
link |
它考慮的是整個sequence的cost,
link |
所以你要把c1,c2,c3通通加起來得到c,
link |
你要把c1,c2,c3加起來得到c,
link |
接下來我們就需要把每一個edge上面的偏微分都算出來,
link |
假設我們現在要求partial w,h,partial c,
link |
我們要求w,h這個matrix對c的偏微分,
link |
我們從c開始做reverse law,
link |
這三個edge的微分是比較容易算的,
link |
而接下來其他這些就是你需要花一點時間,
link |
你就可以算出這邊這個w,h對c的偏微分,
link |
我們要把這個edge的偏微分算出來,
link |
我們要把這個edge的偏微分算出來,
link |
我們要把這個edge的偏微分算出來,
link |
然後再把這兩條路徑算出來的值加起來,
link |
那我們要算最開頭的地方w,h的偏微分怎麼做呢?
link |
這邊這三個partial w,h分之partial c,
link |
因為這邊這三個w,h它們其實是共用參數,
link |
所以你要把這三個partial w,h分之partial c
link |
那我們先算這一個第一個partial w,h分之partial c,
link |
這個第一個partial w,h分之partial c是什麼呢?
link |
就我們在w,h跟c中間總共有三條path,
link |
這是第一條path,這是第二條path,
link |
這三條path,這三條path,這三條path,
link |
它們最後收尾的地方都有一個partial w,h分之partial h1,
link |
只算了一個partial w,h分之partial c,
link |
第二個你要算一發,然後我就懶得把它打出來,
link |
2比較簡單,因為它只有兩條path,
link |
把它全部加起來,你才得到真正的partial w,h分之partial c,
link |
連成好多次partial h,c-1分之partial h,t,
link |
所以這個會造成Chain R認證有一些問題,
link |
如果LSTM你把computation都會有畫出來的話,
link |
然後這個教科書的chapter6.5有講computation,
link |
另外還放了兩個比較清楚的blog給大家參考。