back to index
Deep Learning for Language Modeling
link |
來講一下用RNN做Language Model這件事情,這個就是作業一要做的事。
link |
好,那什麼是Language Model?
link |
Language Model要做的事情就是估測一個word sequence,也就是一句話的機率。
link |
也就是說給你一個句子,一個句子就是用一串詞彙呢,word所構成的。
link |
在這個圖上的這個W就代表的是word,你有N個word,W1到WN,這個W1、W2合起來就是一個句子。
link |
那Language Model做的事情就是你要找一個function告訴我們說,這一個sequence,這個句子它的出現的機率有多大。
link |
你要估測P of W1、W2到WN。那這個東西有什麼用呢?這個實在是太有用了。
link |
比如說你會用在語音辨識上面,在語音辨識上你一定需要Language Model。
link |
因為在做語音辨識的時候有時候不同的word sequence它可能有同樣的發音,它可能有同樣的發音。
link |
舉例來說,比較常舉的例子是recognize speech跟recognize speech,它的發音其實是一樣的,它的form sequence其實是一樣的。
link |
recognize speech,rec是破壞的意思,就是破壞一個海灘跟語音辨識的聲音,英文的發音其實是一模一樣的。
link |
其實我這邊本來想舉的例子是殭屍裡的例子,但是我知道沒有人聽得懂,所以就算了。
link |
對不起,這個真的太無聊了。殭屍裡那個殭可以是君君,它是一個離子,但是沒有人知道殭屍裡是誰,所以這個例子就不是很好。
link |
殭屍裡是仙武的魔君,我女朋友叫我不要舉這個例子,會被當作是怪人。
link |
那就是recognize speech,所以你光聽聲音你沒有辦法分辨說到底應該是語音辨識還是破壞一個海灘,所以你要估個機率,發現語音辨識這個句子出現的機率是比破壞海灘出現的機率還要大,因為我們不太常常破壞海灘,所以最後得到的output就是語音辨識。
link |
翻譯的時候你其實有時候也需要這個language model,它其實還有一個很好的應用,就是sentence generation,如果你今天有一個application是要讓你的machine說一句話,這個時候你就需要用到language model。
link |
這個之後我們會簡單講成說,比如說現在machine有好多個句子是可以選擇的,它可以用language model去選說哪一個句子是最有可能。
link |
比如說你在做對話系統的時候,machine現在有好多個句子都是可以的回應,用language model選一個文法最對的句子,這樣你的machine就不會講話很像machine這樣子。
link |
所以今天這個作業一是很重要,它是我們之後其他作業的基石,我們之後要做medium的caption generation還有checkbox,什麼都要用到作業一的code,所以你如果沒有好好寫之後你就會後悔。
link |
好,那現在我們來看一下傳統上language model是怎麼做的呢?如果你不用neural network的話,你怎麼做呢?你就用ngrain的language model。好,那怎麼estimate一句話的機率?
link |
當然機率這個東西大家都知道,我們可以去collect一個很大的database,然後就去count說W1到Wn出現的次數,然後我們就可以知道說W1到Wn它如果要說一句話的話,它出現的機率是多少。
link |
但是麻煩的就是,同樣這個W1到Wn這個句子,你在corpus裡面八成一次都沒有出現過,對不對?那所以怎麼辦呢?我們必須要把P of W1到Wn這個機率拆成比較小的component。
link |
而每一個component的機率是我們可以從這個database裡面估測出來的,我們再把每一個component的機率通通乘起來,就變成這一整個sequence的機率。
link |
所以ngrain的language model概念就是說,我們把W1到Wn的機率拆解成P of W1 given star乘上P of W2 given W1,一直乘到P of Wn given Wn-1。
link |
而這裡面的每一個機率,這P of W2 given W1到P of Wn given Wn-1,都是可以從training database裡面去估測出來的。假設我們要估測說P of beach given nice的機率是多大的話,那很簡單。
link |
我們要估測nice這個詞彙後面這些beach的機率有多大的話,我們只要去計算nice和beach這兩個詞彙在整個training dataset裡面出現的次數,再除掉nice這個詞彙出現的次數,你就得到P of beach given nice的機率。
link |
那上面這個例子叫做by-grain的language model,如果你的每一個component只考慮前一個word的話,這個叫做by-grain,而如果考慮前兩個word就是tri-grain,考慮前三個word就是fore-grain。
link |
然後現在我講的這個統計的方法非常容易,你就可以把它generalize,一般化到tri-grain、fore-grain等等。
link |
好,如果用NN做language model要怎麼做呢?我們先講它怎麼做,然後再講它的為什麼要怎麼做。
link |
好,那如果用NN train language model要怎麼做呢?首先你就要收集一大堆的training data,去PTT上爬就好,一大堆的文字。
link |
然後接下來你就認一個NN,這個NN它做的事情就是predict下一個詞彙,我們認一個NN,它的input是潮水跟退的,然後它的output目標就是joke。
link |
然後你就用cross entropy去minimize你的network的output,還有它的target。那input是退的跟joke,然後它的output就要是知道,然後input是joke跟知道,它的output就要是誰。
link |
NN-based language model就是這個樣子。那有了這個neural network以後,接下來你要怎麼算一個句子的機率呢?你就這麼做,我們一樣把一個句子拆成by-grain的機率的相乘。
link |
所以rank-nice-beach就是rank在句首的機率,rank後面接nice的機率,nice後面接beach的機率。但是我們現在在,如果我們用的是NN-based language model的話,這些機率就不是從統計來的,我們就不是去cut database裡面那些詞彙出現的次數來得到這個機率。
link |
這個機率就是network的output。也就是說,假設我們想要知道rank放在句首的機率的話,我們需要有一個token代表說是句子的起始。
link |
我們把句子的起始這件事情也當作是一個詞彙來看待。所以我們neural network就input句子的起始這個token,然後讓它去預測rank這個word是下一個word的機率。
link |
可以把這個機率拿出來,就放在這個地方。接下來,你把rank這個詞彙用one-of-a-kind coding來表示,然後把它丟到network裡面,然後讓它predictrank下一個詞彙是什麼。
link |
也就是說,你知道這個network的output其實是less than size,假設世界上有十萬個詞彙,它的output就有十萬維。每一維都會有一個數字,你把rank丟進去的時候,每一個詞彙都會有一個數字,代表這個詞彙是rank的下一個詞彙的機率。
link |
那你就看說a的機率是多少,它就是rank後面接a的機率。所以這個process就反覆下去,後面接nice的機率,nice後面接b的機率,把所有的值都重新乘起來,你就得到這個句子的機率了。
link |
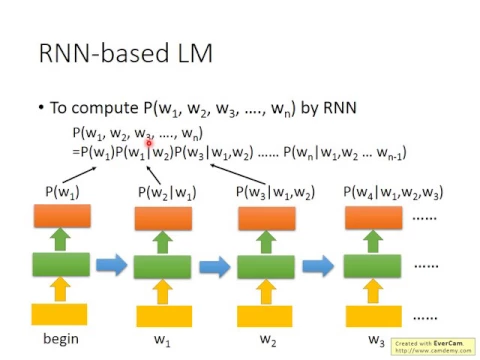
如果今天是RNN-based language model,它的training也是一樣的。你就說,我收集到一大堆PTT的data,這個RNNinputBegin的時候,它就要output潮水,input潮水它就要output退了,input退了它就要output舊,input舊它就要output知道。
link |
那跟NN不一樣的地方就是,它在output知道的時候,它是看了這個潮水退了舊這麼多的詞彙,才決定說接下來的output應該是知道。如果是NN的話,它就只看現在的input,就predict output。
link |
如果是RN的話,它會看這個句子之前所有的詞彙,再決定它的output。那怎麼使用這個RNN-based language model呢?你怎麼估測這個機率呢?那你就這樣做。
link |
你把RNN認出來以後,你就丟一個begin進去,那看它在W1那個詞彙的分數,這個就是P of W1。接下來你把W1丟進去,你就得到P of W2 given W1的機率。
link |
你把W2丟進去,那你再看W3的分數,就是P of W3 given W1、W2的機率,以此類推。你再把所有的機率統統乘起來,你就得到一個句子的機率。
link |
用RNN的好處就是它可以model比較long-term的information,不一定要用簡單RNN,你也可以用GRU,也可以用LSTM,它不一定要一成,它也可以是多成的。
link |
那如果要講RNN-based language model,也許講到這邊就可以結束了。我想RNN-based language model,大家其實多少也是知道知道的。那你也不太需要講說,為什麼我們要用RNN-based的理由。
link |
反正這個deep learning就是草,把它用在任何地方是不需要理由的。不過接下來我們還是來解釋一下,為什麼我們需要用到RNN-based language model呢?用RNN-based language model相較於傳統的model有什麼好處?
link |
那我們首先要看一下傳統的RNN-based language model,它有什麼樣的問題?傳統的estimate RNN的方法最大的問題就是,那個機率啊,你很難估的準。
link |
為什麼那個機率很難估的準?因為我們永遠沒有足夠的data可以讓我們把機率真的估的很準。尤其是當我們的N很大的時候,我們會遇到data sparsity的問題。
link |
因為我們的data不夠,所以我們沒有辦法把所有的n-grain通通都在data-based裡面觀察到,所以有一些n-grain的機率我們是估不準。舉例來說,假設我training data裡面有一個句子是the dog ran,有另外一個句子是the cat jumped。
link |
那如果你在估測一個training language model的機率的時候,the dog後面接jump的機率就會變成是0,而the dog後面接ran是有機率的,但是接jump的機率就會變成0。
link |
the cat後面可以接jump,但它後面接ran的機率就會變成0。但是這件事情並不是正確的,因為狗不只會跑,牠其實也會跳,貓不只會跳,牠也會跑。
link |
這是因為我們的data base太小了。如果你可以把全世界所有人類古往今來搜過的句子通通收集起來的話,你就可以正確地用n-grain language model估測出機率。但我們沒有辦法做這件事情,所以我們估測的機率是不準的。
link |
有一些n-grain,the dog後面接jump,the cat後面接ran的n-grain機率是0,但是實際上它並不一定是0,它其實還是有可能會出現的,只是因為data base不夠大,所以我們沒有辦法觀察到這個現象。
link |
所以怎麼辦?傳統的一個解法叫做smoothing,smoothing就是說不要真的給一個n-grain機率0,你給它一個小小的機率。那當然怎麼做n-grain其實也是一個很大的學問,那我們在這邊就不討論這個問題。
link |
好,那今天如果我們用NN的話,用這個leap learning有什麼好處呢?我們先來看一下,這種想到data sparsity的問題,你會想到什麼呢?你會不會想到metric的factorization。
link |
我們今天可以把這個n-grain的機率看作是一個table,這個table的其中一個dimension代表的是history,然後另外一個dimension代表的是vocabulary。
link |
這個table上面的每一個element,每一個空格代表的是,given某一個history,它之後接下一個word的機率。
link |
比如說這個0.2這邊代表的是,看到cat作為history,如果cat是history,接下來接的是jump的機率,cat後面就是jump的機率是0.2。
link |
所以我們可以estimate一個bi-grain的language model,然後把這個bi-grain的language model的值寫作是一個table。
link |
當然你也可以很輕易的generalize到tri-grain,fo-grain,什麼都可以,你只要把這邊的history改成有兩個詞彙,改成三個詞彙,你就可以一般化到tri-grain,fo-grain,都可以。
link |
那你會發現說,在這個表格裡面,大部分的空格其實都是0。
link |
很多bi-grain,你在你的database裡面,一次都沒有看到,所以它estimate出來的機率都是0。
link |
但是它的機率是0,並不代表說它真的是0,只是我們的database不夠大,所以我們沒有看到而已。
link |
如果你今天,你想想看,這個問題是不是跟那種推薦系統的問題是一樣的呢?推薦系統這種問題大家應該很熟悉吧?
link |
我們把history換成是customer,然後把vocabulary換成是product,中間這個數值就是某一個人,某一個customer有沒有買過這個product。
link |
那如果有一個customer,他買那個product,根據你的統計資料是0,並不代表他之後不會買那個product,他只是還沒有買而已。
link |
你統計的數目不夠多,所以你還不知道這件事情。
link |
所以我們可以套用推薦系統的方法來解這個問題。每一個history,我們都用一個vector來表示它,比如說dog就是h1,cat就是h2。
link |
每一個vocabulary,我們也都用一個vector來描述它,比如說ran就是v1,jump就是v2,等等。
link |
那這個v跟h,它的dimension要是一樣的,因為等下要把它們做inner product,dimension要是一樣的才乘得起來。
link |
這個v跟h是要被學出來的,那怎麼學它呢?你要去minimize右下角的objective function。
link |
假設說這個table裡面的每一個element,我們都用n加兩個下標來表示,這個n11就是0.2,n22就是0.2。
link |
那你希望minimize的東西就是,你希望讓vi跟hj做inner product的時候,它的值跟nij越接近越好。
link |
你就希望說h2跟v2做inner product的時候跟0.2越接近越好,v1跟h1做inner product的時候跟0.2越接近越好,h2跟v1做inner product的時候跟0.3越接近越好。
link |
你把這個東西當作你的loss function,當作你的criterion,接下來你用gradient descent去印算一番,你就可以把h跟v的vector通通都找出來。
link |
你就可以給每一個history一個vector,你就可以給vocabulary裡面的每一個詞彙一個vector。
link |
接下來,你就可以根據我們所找出來的vector,把這些是0的數值填進去。
link |
就是說,n12就變成是h1乘v2,n12就變成h1跟v2的inner product,n21就變成是v2跟h1的inner product,n21就變成是v1跟,我有沒有寫錯呢?
link |
這邊,哦,沒有,v21是這個,不好意思,v21跟n12是這個,剛才講的是反的,n21就是v2跟h1的inner product。
link |
那你就可以把那些是0的東西,是0的空格的分數把它算出來,他們相乘的時候不會是0。
link |
那你的好處是這樣子,如果今天有兩個詞彙,他們是很相近的,有兩個history他們是很相近的,比如說dog跟cat,他們其實是很相近的,他們有接近的h這個vector,hdog跟hcat是很接近的。
link |
那如果vjump跟hcat是很搭,那vjump跟hdog也會跟著他的值得很搭。
link |
就算是你今天在training data裡面,你從來沒有看過dog後面接jump,但是憑著dog的vector和cat的vector很像這件事情,
link |
你就可以估測出既然cat跟jump相接的機率很大,那dog跟jump相接的機率也會很大。
link |
那這個跟一般的smoothing不一樣,你用這個metric vectorization的方法,你等於也是做了smoothing,但是跟一般的smoothing的方法不一樣。
link |
一般的smoothing的方法,你沒有辦法真的去考慮這些詞彙它的意思是什麼,你只是說這邊0.2太大,減一點,然後分給其他是0的值。
link |
但是如果你今天用的是metric vectorization的方法,你可以真的把詞彙的含義考慮進去,
link |
你會知道說這個dog和jump,他們這邊這個0可能是有值的,但是dog跟quiet,dog跟length這個0的值應該是比較小的。
link |
那講這麼多,這個東西跟NN有什麼關係呢?其實metric vectorization是可以寫成NN的,它可以寫成只有一個layer的neural network,大家知道這件事嗎?
link |
你可以這樣想,因為我們這邊需要考慮的是機率,所以每一個column的和要是1,它才會是機率。
link |
因為我們今天算的是某一個history後面接某一個vocabulary的機率,所以每一個column的和必須要是1,它才是一個機率。
link |
所以我們這邊要做一個小小小小的更動,這個小小小小的更動是什麼呢?我們假設dog這個history,它的vector就是hdog,然後把它寫在這邊。
link |
那我們可以把hdog乘上vran,我們可以把hdog跟vran做inner product,我們可以把hdog跟vquiet做inner product,我們可以對每一個vocabulary的v做inner product,每一個vocabulary你就可以得到一個數值。
link |
但是這些數值的和你沒有辦法當機率來看,因為它和不是1,而且它甚至有可能是負的,那怎麼辦呢?你就做個solvemax。
link |
你做一個solvemax以後,你就可以把vdog跟vran做inner product的結果通過solvemax以後看作是dog後面接ran的機率。
link |
你就可以把hdog跟vquiet做inner product的結果通過solvemax以後看作是dog後面接quiet的機率。
link |
接下來在training的時候,因為我們知道說根據training data,假設dog後面接ran的機率是0.2,dog後面接quiet的機率是0,那這個vector就是你的target。
link |
那你在認你的參數的時候,你就會希望說這些做完inner product的結果跟這個target,它們的cost entropy是被minimize的。
link |
那這件事情呢,其實你可以把它想成就是一個nn,怎麼說呢?我們這個history就是這個nn的input,然後history的dimension,這個input dimension就是看你的history有幾個可能。
link |
假設我們今天考慮vran,那history就是vocabulary size,那你input的這個vector就是vocabulary size。那input的每一個dimension跟hidden layer相接的這些weight,就是那一個history對應的vector。
link |
就是對應到cat的那個history,它跟hidden layer的dimension相接的這些weight,就是hcat。對應到dog的那個dimension,跟中間的hidden layer相接的這些value,就是hdog。
link |
那你今天呢,如果input你就是用one of an encoding來表示,假設你今天看到的history是dog的話,用one of an encoding來表示的話,就是只有dog那一位是1,其他都是0。
link |
那你把這個只有dog那一位是1,其他都是0的vector,丟到這個network裡面去,那你中間hidden layer的output,假設我們不考慮activation function的話,那你得到的就是hdog。
link |
然後接下來,乘以v這件事情,你就可以把它想成是另外一個layer。你把這邊的hdog跟每一個vocabulary的v做相乘這件事情,做inner product這件事情,你可以把它想成是另外一個layer,然後再通過softmax得到一個layer的output,然後這邊是它的type。
link |
那你就有這個neural network,接下來就沒有接下來,就是剩下去就對了。這個呢,就是為什麼用nn來作為language model的一個理由。
link |
那其實呢,在這種umbran的language model啊,像這種新的language model的方法,大概在2010年以後呢,才比較風行。那最開始風行的時候,最開始風行的時候所用的方法,其實也不是這種nn-based的方法。
link |
一開始就是用那個metric factorization的方法來做,但是後來大家發現說,確實用nn的performance是比較好的。如果用nn的話,你不只可以疊一層,你還可以考慮recurrent的neural network。
link |
那你會發現說,我們今天用nn到底為什麼會有好處呢?你會發現說,如果我們比較現在用nn這件事情,跟做umbran language model所需要的參數量,你會發現nn所需要的參數量是比較少的。
link |
對不對?如果我們今天做umbran的language model,你需要estimate的參數,假設我們今天是,你需要estimate的參數有多少,是不是history的數目乘上vocabulary的數目呢?
link |
但是在這個neural network裡面,你需要estimate的參數有多少,是不是遠小於history的數目乘以vocabulary的數目呢?你要estimate的參數是,每一個history都給它一個vector h,每一個vocabulary裡面的word都給它一個vector v。
link |
那這個v的dimension,如果你,如果這個v的dimension跟h的dimension,你不要給它設太大,那你neural network所需要的參數,其實是遠小於一個language model所需要的參數了。
link |
大家知道我的意思嗎?就是說,假設history的數目是有h的絕對值的,那vocabulary的數目是v的絕對值的。
link |
如果你今天用N-gram的language model的話,N-gram的language model裡面,你需要估測的是p of v given h,那你的參數的量,你需要估測的參數是h的絕對值乘以v的絕對值,而這個東西大到不行。
link |
如果你今天是用N-gram based的language model的話,你需要哪些參數呢?你為每一個history都有一個vector,那個vector的dimension你可以自己決定,假設它是k,那k你就不要設太大,比如說k等於100之類的。
link |
然後呢,為每一個vocabulary都給它一個vector,這個vector的dimension也是k。那這個東西啊,它其實會遠小於這個數值。所以當你用N-gram的好處,其實並不是說N-gram很大,N-gram很多層,然後所以它可以暴力的去fit你。
link |
其實不是,你用N-gram才是暴力的方法,它參數很多,你用neural network的時候,你用的參數是比較少的,所以它比較不容易overfitting,所以你會得到比較好的performance。
link |
這就是我一直想要,就大部分人都想像說N-gram就是個暴力的東西,deep learning就是個暴力的東西,我一直在強調說其實就不是這樣,因為deep learning往往會有好處,通常都是因為你用的參數比較少,你比較不會overfitting。
link |
那為什麼要用RNN?用RNN的好處也是,用RNN我們又可以更減少參數。怎麼更減少參數呢?如果我們今天要考慮的history非常的長,如果我們今天想要考慮的history是非常的長的,
link |
由W1到Wt個word那麼長,我們要考慮前t個詞彙,那前t個詞彙所組成的history有多少可能呢?是不是這個V的t次方那麼多呢?
link |
所以這個如果你今天vocabulary size至少也有個10萬的話,那這個可能的history的數目就變成一個天文數字。你用1-overfitting coding來描述它顯然是不行的,怎麼辦呢?我們用RNN來描述它。
link |
我們就認一堆,RNN就是反覆用某一個function,所以把一個function f拿出來,然後每次把W1丟到f裡面產生h1,把W2再丟到function裡面產生h2,一直在推。
link |
最後把Wt丟進去的時候產生ht,這個ht就是這一整個history的representation,就是這一整個history我們就用RNN最後的outputht來表示它,不管你這個history有多長,RNN的參數都不會變多。
link |
再把這個ht乘上每一個vocabulary裡面的每一個word的V,你就可以再通過softmax就可以算出每一個word的機率。
link |
那在training的時候呢,你就看說這個historyW1到Wt後面的Wt加1是哪一個詞彙,那你那個target就是哪一個詞彙是1,其他都是0。那你其實不需要特別去統計說W1到Wt後面接的Wt加1的distribution是什麼。
link |
因為W1到Wt這個詞彙在你的training compass裡面可能就只出現一次而已,它可能不會出現兩次以上讓你可以統計出一個distribution,它可能就只出現一次而已。
link |
所以在實作上呢,你的target就只是一個one-hot的vector,就是W1到Wt後面接的詞彙Wt加1的只是1,那其他就是0,它就是一個one-hot的vector。
link |
好,那我不知道後面還要不要講,我們這個應該就可以直接接到作業應該就沒有問題了,對吧?對不對?我也是這麼覺得。你們要講什麼class-based language嗎?我們就來講作業吧。