back to index
Spatial Transformer Layer
link |
好,接下來我們要講一下Special Transformer,所以接下來這份投影片要講的是一些特別的,特別但是有用的Layers的架構,第一個我想要講的是Special Transformer的Layer,那什麼是Special Transformer的Layer呢?為什麼會想講這個?
link |
我常常會遇到的問題就是,有人就會問說,不知道為什麼大家都有一個想法就是覺得CNN是Scale Invariant或者是Rotation Invariant,我不太確定這個想法是怎麼來的,我大家好像都這麼相信,事實上並不完全是這樣子。
link |
你想想看,如果是Scale Invariant的話,你可能期待說,我的圖片裡面有一個很小的狗,然後CNN知道它是狗,然後把那個狗放大,佔滿整個圖片,它也自己知道說那個是狗。
link |
CNN做得到這件事嗎?它其實應該是做不到這件事的。你想想看,有什麼機制可以讓它做到這件事嗎?每個Field的Size就是一個固定的啊,那個Field如果認出來是Detect小隻的狗,它就是Detect小隻的狗。Detect大隻的狗,它認出來是Detect大隻的狗,就是Detect大隻的狗。
link |
它沒有學到Scale Invariant這件事情,那如果你說你的CNN可以Detect大隻的狗和小隻的狗,它會認出來是狗,那只是因為圈Data裡面有大隻的狗也有小隻的狗而已。所以我並不認為它有Scale Invariant這個特性。
link |
它其實也沒有Rotation Invariant的特性,或者是它的Rotation Invariant特性並沒有真的很強。意思是說,如果我們今天給它,比如說你給它畫一個數字3,然後你把這個數字3放倒,變成一個麥當勞這樣子。
link |
那對它來說那個就是麥當勞,那個就不是數字3,對它來說那個就是不一樣的東西。這個CNN並不能夠真的做到Rotation Invariant。
link |
那它有Translation Invariant,有一些Translation Invariant,就是你把你Image裡面的某一個Object挪動一點點,對它來說可能是一樣,那這是因為Max Pooling的關係,就是你的圖片的左上角一個人,然後那個人稍微往右走一步,對CNN來說可能是一樣。
link |
但是如果今天這個人從左上角移到右下角,對CNN來說它還是不一樣。所以我覺得CNN有一些Translation Invariant,但它沒有完全的Translation Invariant。
link |
所以也就是說,假設我們現在要做Digit的Classification,那我們Input的Image長的是這樣子,或者是這樣子。對CNN來說,這個東西可能就不像是5,這個東西可能就不像是6。
link |
所以對它來說,5長的就是這樣,6長的就是這樣。你把它縮小變成一點點,對它來說就是不一樣的東西。
link |
那所以怎麼辦呢?這邊這個Special Transformer的Layer是它想要真的認一個Layer,這個Layer它可以對Input的Image做旋轉縮放。這個Layer它的功用就是對Input的Image做旋轉縮放。
link |
所以這邊它會對這一小塊做放大,讓它變成這樣。再丟到CNN裡面,CNN就可能真的可以認出它是5。
link |
那這個是6,然後它知道說6就是這一小塊,把這一小塊放大,丟到CNN裡面,CNN就可以得到正確的辨識結果。那這個Special Transformer Layer它既然是Layer,所以它也是一個Neural Network,它也是Neural Network。
link |
而且它可以跟CNN就能認,也就是說你只是在原來CNN的Layer前面再多疊了一個Layer,只是這個Layer是特別設計的,但是它也是一個Layer,它也是Neural Network,它也是由那些Weight什麼所構成的。
link |
所以你也可以就直接用Backpropagation,把這個Layer的參數跟CNN的參數一起Train。所以這是一個你可以做End-to-End的Training。
link |
然後它不只可以Transform Input的Image,其實你也可以TransformCNN的每一個Feature Map。為什麼?因為其實一個Feature Map你也可以把它想成是一個Image,只是那個Image的Channel,它的Channel是不是dependent,你有幾個Filter。
link |
因為你有500個Filter,那它的Channel就是500。所以這個Transformer Layer它不只可以Transform Input的Image,它也可以Transform每一個Feature Map的Layer,所以它也可以被放在CNN裡面去Transform那些Feature Map。
link |
好,那這個Special Transformer Layer其實我覺得它也還蠻難解釋的,所以來解釋給大家聽看看。我們要怎麼對一個Image做Transform呢?或者怎麼對一個Feature Map做Transform呢?
link |
我們假設左邊這個Image是Transform前的結果,右邊這個Image是Transform後的結果,那你可以很明顯的看出這個Transform是把Image由上往下做一個PE而已。
link |
好,那我們假設Transform前的結果就是Layer L-1,Transform後的結果就是Layer L的Output,就Transform前是某一個Layer的Input,或者是前一個Layer的Output,那Transform後是哪一個Special Transformer Layer的Output。
link |
那In General而言,一個General的Layer,它的式子可以寫成下面這個樣子,對不對?一個Fully Connected的Layer,我們可以寫成下面這個樣子。
link |
D,L個Layer裡面的每一個Neuron的Output,A上標L下標N,N跟M代表它的Index,這邊的每一個A你可以說它就是Input的這個L-1的Layer裡面每一個Element的Linear Combination,所有的Element都乘上一個Weight,然後加起來就得到下一個Layer的Output。
link |
那這個Weight,這個W有四個下標,N,M,I,J,意思是說從I,J這個Index連到N,N這個Index。
link |
In General而言,一個Fully Connected的Layer,它可以寫成這個樣子。
link |
那其實這個Fully Connected的Layer,它其實是可以做到Transformation,假設我們今天這個Transformation是要對這個Image做一下平移,那怎麼做呢?我們只要適當的去調這些Weight,只要這個Weight是一個適當的值,我們就可以做到平移這件事。
link |
那什麼樣的Weight可以讓我們做到平移這件事呢?我們看說,這個我們想要做Translate,也就是說第L個Layer的第N,N個這個Value會等於N減,前一個Layer的N減1,M這個Index的Value,而這個Value等於這個Value,這個Value等於這個Value,我想大家應該知道我的意思。
link |
那怎麼做到這件事呢?怎麼做到這個平移呢?其實你只需要說我們的Weight設計成,我們的Weight設計成對Index在NN的Neural而言,假設我們現在要算的下標是N跟M的話,那如果今天這個IJR,I是N減1,J是M,那Weight就是1,在其他Case,Weight是0。
link |
如果你這樣子設你的Weight的話,你其實就可以做到平移。所以,我們想要把一張Image做旋轉縮放變成另外一張Image,我們需要的其實只是把這個Weight做不同的設計,我們就可以做到旋轉縮放這件事。
link |
舉例來說,如果我們現在的Weight的設計是,這個點連到這個點,這個點連到其他都是0,這個點連到這個點,這個點連到其他都是0,那這樣子我們就是向下平移。
link |
如果我們做說,這個點連到這個點,這個點連到他的Weight是1,這個點連到其他點的Weight都是0,這個點連到這個點的Weight是1,連到其他點的Weight都是0,這個點連到這個點的Weight是1,其他都是0,以此類推,那我們就可以做到類似旋轉的功能。
link |
所以,我們只要妥當的找到這些Weight,我們就可以做各種旋轉縮放。但是,問題就是,怎麼找這些Weight呢?
link |
我們可以用NN來控制這兩個Image之間的Weight的連接方式,這聽起來真的很玄,我們來講說,怎麼用NN來控制兩個Layer之間的Weight的連接方式。
link |
在概念上就是,把這個L-1的Layer的Output丟到一個NN裡面,讓NNOutput一些參數,然後根據那些參數,就可以決定這裡的每一個Neuron要怎麼連到前一個Layer的Output。
link |
一樣,把這些所有的東西丟到NN裡面去,NNOutput一組參數,它會決定這裡的每一個Neuron要怎麼連到前一個Layer的Output。
link |
我們在現代的時候,極少數學過說,如果我們要對一個Image做平移旋轉縮放的話,我們要怎麼做?假設我現在這邊有一張Image。
link |
這是預版美琪。如果我們要把這個Image放大的話,要怎麼做呢?我們做法就是,假設我們先把每一個Image上面的Pixel都給它一個座標,所以每一個Image上面的Pixel都有一個座標XY。
link |
那我們把每一個Pixel在XY的位置的Pixel移到一個新的位置,X' Y'。你只要妥當的設計XY跟X' Y'的關係,我們就可以把一張Image放大。
link |
怎麼做呢?你只要說,比如說如果我想要放大兩倍,那我的做法就是XY乘以一個Matrix,這個Matrix是2002,然後再加上00,這邊代表說沒有平移,最後這項要控制平移,所以沒有平移,那我就得到X' Y'。
link |
那如果我把XY的位置挪到X' Y'的位置,那這張Image就會放大兩倍。那如果我今天想要把這張Image縮小,然後塞到右上角的話,那我要怎麼做呢?我要怎麼設計這個XY和X' Y'之間的關係呢?
link |
我要列出這樣一個式子,我這邊假設這個高是1,這邊的高是1,這邊的寬是1,那我們如果把XY乘上0.5,0,0.5的話,那這張Image就變成原來的2分之1,然後再加0.5,再加0.5,再加0.5,再加0.5,我們就把它移到右上。
link |
那或者是如果今天想要做旋轉,那如果要做旋轉要怎麼做呢?假設這邊有一個Image,這個是良工春日,有個知道的人說一下。
link |
然後這個Image如果要旋轉的話,怎麼旋轉呢?比如說我們要把它逆時鐘旋轉,那怎麼把它逆時鐘旋轉呢?我們就把原來的IndexXY乘上一個Matrix,Cosine,負Sine,跟Sine, Cosine,就可以變成X' Y'。
link |
把原來在XY的點挪到X' Y',我們就做了旋轉這件事情。
link |
那所以今天如果我們要控制這個兩張Image之間的關係,如果我們要控制這個兩張Image之間的關係,我們要怎麼做呢?其實如果只是旋轉平移縮放的話,其實這個叫做Phyton Form,如果只是Phyton Form的話,我們其實只需要六個參數,我們只需要六個參數。
link |
也就是說我們只需要知道ABCD跟EF這六個參數,我們就可以把一張Image變成另外一張Image。
link |
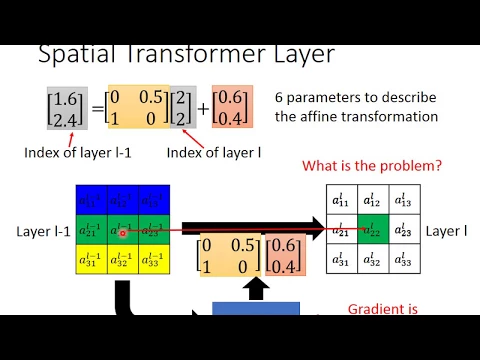
所以我們今天的Network,我們今天在Control L-1和L這兩個Layer之間的關係的Network,它需要的就只是輸出六個值而已。所以這個Network,它的Input是整張Image,但它的Output就是一個六維的Vector,它Output就是六個值。
link |
這六個值分別就代表了ABCD和EF,它的前四個值就是這個Matrix,它的後兩個值就是E跟F。
link |
那接下來這個XY跟X'Y'分別是什麼呢?我們可以假設XY就是第L個Layer的每一個Neuron的Index,比如說這個點,它就是X等於1,Y等於1,這個Neuron它就是X等於2,Y等於2,這個Neuron就是X等於3,Y等於2。
link |
在原始的Paper裡面,它其實不是Exactly這樣做的,但是概念是一樣的。我就這樣解釋比較簡單一點,它概念是一樣的。
link |
好,那在X'Y'裡面,在X'Y'是什麼呢?X'Y'就是第L減一個Layer,它裡面的每一個值的Index。或者是我們舉一個實際的例子。
link |
假設現在這個Neuron它的Output的六個值分別是0,1,1,0,-1,-1,分別是0,1,1,0,-1,-1,那意思就是說這個ABCD就是0,1,1,0,EF就是-1,-1。
link |
那我們現在把這邊的每一個Pixel都去計算說它應該對應到把第L個Layer裡面的每一個Pixel,把第L個Layer裡面的每一個Neuron的Output都去計算說它應該對應到第L減一個Layer的哪一個Neuron的Output。
link |
那怎麼做呢?比如說我們考慮這個二乘,我們考慮二二這個Neuron,我們管二二這個Neuron,現在X等於二,Y等於二,把X等於二,Y等於二代進去,那你算出來,你有沒有辦法心算一下呢?
link |
是不是得到一跟一,對不對?就如果你這個X代二,Y代二,然後這個值跟這個值是知道的,這個metric跟這個metric是知道的,計算一下,你就得到Xπ等於一,Yπ等於一。
link |
意思就是說,A二二,A上標L下標二二,這一個Neuron,它的input就是接到A上標L減一,下標一一,這一個Output,接到其他地方的就是零。
link |
或者是我們可以再計算一下,這邊是二三,我們把二三乘上,這個一一零零一,然後乘,啊寫反了。
link |
零一一零,然後乘上二三,然後加上負一負一,會得到多少呢?這個就是得到一跟二,小學數學,得到一跟二,得到二分。
link |
好,那但是呢,這樣並沒有結束,這個現在啊,現在你算出來這邊XY你帶個整數進去,Output正好是一個整數,那是因為這個metric跟這個weight也都是整數啊。
link |
如果它不是整數呢?如果我今天Output是這個樣子,一零點五一零,零點六零點四,那會發生什麼事呢?那我們來看看A二二的這個case。
link |
如果X等於二,Y等於二,代入這個式子以後算出來,X'是一點六,Y'是二點四,所以A二二L,根據這個式子它應該接到一個X等於一點六,Y等於二點四的Output。
link |
它應該接到一個Index是X等於一點六,Y等於二點四的Output,但是問題就是沒有人有這種Index啊,Index都是整數,那怎麼辦?你可以說,那沒關係,就找一個最近的。
link |
一點六跟二點四,取四捨五入以後,取四捨五入以後,應該就是接到X'等於二,Y'等於二的case。
link |
所以這個case就應該接到這個case。好啊,那你覺得這樣OK嗎?你可以接受這樣的做法嗎?你有發現這個有什麼問題嗎?
link |
那第一個問題就是,你覺得這樣子的做法,你可以用Gradient Descent來解嗎?你可能會說,這個式子這麼怪怪的,這顯然不是一個可為的,它顯然不是一個在每一個點都可為分的function。
link |
應該不能用Gradient Descent解吧?這不是在每一個點都可為分的function,還是可以用Gradient Descent解,你記得嗎?
link |
就是IOU的Examination Function,Max Out Network,Max Pooling,它們都不是在每一個地方都可為,但它們是可以用Gradient Descent解的。
link |
那今天這個case,你覺得它可以用Gradient Descent解嗎?給大家十秒鐘的時間想一下。好啊,你覺得它可以用Gradient Descent解嗎?
link |
你竟然有Propose這個方法,顯然是可以做的,對不對?那你覺得它可以用Gradient Descent解的同學舉手一下。沒有人嗎?有一些人嗎?
link |
然後手放下,謝謝。你覺得它不能用Gradient Descent解的同學舉手一下。有一些人覺得,少部分人覺得行,少部分人覺得不行。其實這個case是不能用Gradient Descent解的,所以仔細想一下為什麼它不能用Gradient Descent解。
link |
什麼是Gradient?Gradient就是如果我們今天把參數做小小的變化,它的output會有什麼樣的影響,對不對?那如果我們今天把這個NN的參數做小小的改變,那它的output會有小小的改變。
link |
它的output有小小的改變,這個值算出來,這邊這個黃色的metric跟紅色的vector有小小的改變,當然最後X'跟Y'會有小小的改變。
link |
但是問題就是現在假設我1.6變成1.61,2.4變成2.39,它還是接到同一個,就這個layer L裡面的A上標L下標22,還是接到layer L-1的同一個位置。
link |
它們還接到同一個位置,所以output不會有任何變化,所以微分是零,所以對這個NN來說,它裡面的每一個參數,對cost function的微分都是零。
link |
所以根本沒辦法,你根本無法train這個NN,你根本無法train這個NN。
link |
那所以怎麼辦呢?所以實際上真的要做這個方法的時候,你需要做interpolation。
link |
這個意思是這樣,這個1.6,2.4它其實是介於四個前一個layer的output中間的,對不對?1.6,2.4它介於A下標12,A下標13,A下標22,A下標23中間。
link |
它介於這四個點中間,它跟這個點的Y座標的距離是0.6,X座標的距離是0.4。
link |
它對這個點的Y座標的距離是0.6,X座標的距離也是0.6。
link |
它對這個點的Y座標的距離是0.4,X座標的距離是0.6。
link |
它對這個點的X座標、Y座標的距離都是0.4,0.4。所以我們不要把這個A22所對應的out值,直接設成跟它最近的那個value。
link |
如果把它直接設成跟它最近的那個value,可能是會有一些問題的,因為你會變得沒有辦法為分。
link |
所以怎麼辦?我們的做法應該是,所以這個第L個layer的A22就等於這個A12,A13,A22,A23等於第L減一個layer的這四個pixel的value的interpolation。
link |
那這個interpolation的weight就取決於這四個pixel,這四個value它們跟1.6,2.4間的距離。
link |
所以第L個layer的A22就是第L減一個layer的A22乘上1減0.4,1減0.4。
link |
A12乘上1減0.6,1減0.4。A13乘上1減0.6,1減0.6。A23乘上1減0.4,1減0.6。
link |
那於是呢,這個問題現在就可以用gradient descent解了。為什麼呢?當這個transformer的,為什麼呢?
link |
因為我們發現說呢,當這六個參數有些微的變化的時候,這個值呢,1.6,2.4這個值呢,會有些微的變化。
link |
比如說變成1.61,變成2.39等等。當這裡的值有些微變化的時候呢,這個A22呢,第L個layer的A22呢,它的值也會有些微的變化。
link |
因為這些值變了嘛,這些值變了,所以這個值會有些微的變化,所以你就可以算得出它的gradient,你就可以用gradient descent去optimize這個network。
link |
這個是原始的paper上的圖,它就把這個畫成這樣。這個U呢,是input的image。
link |
它這邊呢,不只是一個image,它是一個feature map,所以它畫成一個立方體,它的channel是很寬的,它有很多channel。
link |
那通過一個localization的network,localization的network呢,就是我剛才講的會open六個參數的那個network。那它就會做一個transformation,告訴你說,下一個layer的每一個open,它應該接到input的那個layer的哪個地方,哪一個neuron。
link |
那這個東西我們現在用一個菱形來表示它。那這個菱形呢,它不只可以,我們剛剛有講過,它不只可以放在network的最前面。
link |
假設我們要做手寫數字辨識,就是input一個image,output就是看是0到9的那個數字。
link |
它不只可以放在input這個地方,它也可以放在任何的feature map的output。
link |
就是你每次做完convolution得到一個feature map,你都可以再加上這個spatial transformer的layer。那甚至,spatial transformer的layer,你不只可以只有一個,你可以在同一層裡面放兩個transformer的layer。
link |
我們等一下會看到,如果這樣做會發生什麼事。你可以在同一層做兩種不同的transformer,得到兩個不同的output,然後再看看後面的network要怎麼處理這兩個不同的output。
link |
我要切回那個,我要切回鍵號才能夠點,對不對?
link |
這個是要說什麼呢?這個圖是要說,現在它就是做在at least上,等一下會看到at least以外的例子,它現在就做在at least上。
link |
做在at least上呢,這個是input嘛,它用的這個是distorted at least,所以它的at least是有故意做一些奇怪的變化,然後故意讓它很難做。
link |
這是input的image,然後這個是spatial transformation的結果。
link |
這是spatial transformation的layer,經過spatial transformation以後得到這個output,然後最後再去丟給classifier。
link |
然後在這邊做的時候是故意給不同的input,把input的image應該是做一下平移,然後看看說在這個spatial transformation的layer的output會發生什麼事。
link |
好,這邊就是把input做平移,但是你發現對output來說它是幾乎沒有動的,所以CNN看到的output是不會動的,所以CNN就可以正確的classify這些image。
link |
這個是input做旋轉,對CNN來說,CNN看到的input是沒有旋轉的。
link |
重點就是對CNN來說,它的input都是固定的。
link |
這個是做一個更複雜的test,它其實也是數字辨識,不是手寫的數字辨識,它是門牌數字辨識。
link |
然後這個門牌數字辨識的test,它在這個image裡面會有不止一個數字,比如在這個case裡面,image的input是260還是280,哎呀,搞不好我比machine還弱,是260,應該是260吧。
link |
是260這邊有一個答案,然後這邊是這樣,它這個output的network會有55維的output,什麼意思呢?
link |
因為這個image裡面最多就只有5個數字,最多就只有5個數字。
link |
然後output55維的意思就是說,現在每11維對應到一個數字,大家了解我的意思嗎?
link |
就是前11維這個有11維,那前面10維就是對應到0到9,最後一維是什麼?最後一維代表說沒有數字。
link |
然後output就是總共有5個11維,所以總共55維。
link |
所以如果這55維裡面有3個0,那就代表這個image裡面只有2個數字,你再看出那2個不是0的數字是多少,那就是你的答案。
link |
所以這邊output其實應該是有55維,那只是其中有2個11維是0,剩下3個11維分別就output260,所以答案就是260。
link |
那這個是一些實驗的結果,這是一些過去的方法。
link |
那這邊應該是算sequence error,我猜應該是sequence error全對,就整個sequence全對,你才算是對的。
link |
那如果你加上transformation的layer的話,可以得到更好的performance。
link |
那他有做single transformation,就是transformation一次,然後multiple transformation就是像下面這個圖一樣,transformation很多次,每次只要過完convolution就做一次transformation。
link |
那這邊是一個visualization的式子,他就說如果把這4次的transformation加起來,那Neo做了什麼事呢?
link |
如果把這4次的transformation加起來,Neo做的事情就是把這個比較小的260放大變成這樣,或把104放大變成這樣,這個大概是6吧?還是0?
link |
這個真的很難耶,人也不見得能夠做對。
link |
那這個也是數字辨識,有時候不是數字辨識,而是鳥的辨識,就是分類說現在input裡面的image是哪一種鳥。
link |
那他的network是這樣子的,input一張image以後,這個image會通過兩個transformation,而這兩個transformation分別會給你不同的transformation的結果。
link |
第一個transformation說我們要把這張image變成這個樣子,第二個transformation說我們要把這張image變成這樣。
link |
然後再分別丟到inception裡面去,就是一個很deep的network,然後把outputconcatenate起來,再看辨識出來,總共有200種鳥和200種鳥哪一種。
link |
那另外在這邊呢,這個transformation layer其實有做一些特別的設計,剛才是說要output6個數字,要output6個數字來控制圖片的旋轉縮放。
link |
那現在只output4個數字,假設這兩維就固定是0,只output4個數字,如果只output4個數字就無法旋轉,他只能夠做縮放。
link |
那這個有點像是focus的味道,就是你看著這張鳥,然後你看不清楚,然後你決定把他放大變成這邊,然後放大變成這邊,他就只能做縮放而已,他就只能做縮放跟平移。
link |
那這當然實驗結果是會比較好的,那這邊是一些實驗結果,那紅色的框框跟綠色的框框就是那兩個transformation分別做transform的位置。
link |
也就是說第一個kage,machine看這張image,第一個transformation說他要把這張圖截出來,那第二個transformation說他要把綠色的框框截出來。
link |
那你會發現說在這個example裡面,大多數時候,我覺得除了這一張以外,紅色的框框都是看那個鳥的頭,都是看鳥的頭和鳥的嘴的地方。
link |
也就是說我們去想要先,他一方面要確認一下鳥的頭跟他的會長什麼樣子,那另外一個框框呢,綠色框框都是focus在鳥的翅膀的地方,或者是鳥的身體的地方。
link |
也就是說他仔細看鳥的頭的位置,在鳥的身體的地方,最後決定說他是哪一種鳥。
link |
好,這個是Spatial Transformation的內容。