back to index
Highway Network & Grid LSTM
link |
下一個要講的是Highway Network和Gree的LSTM,那我們先比較一下Feed Forward Network和Recurrent Network,你可能覺得說他們是沒有什麼關係的,但其實他們是有關係的,今天Highway Network要做的事情呢,就是要把RNN用在很多個,用在這個Feed Forward Network上,這聽起來很奇怪,我等一下會解釋這到底什麼意思。
link |
我們先來看一下Feed Forward Network,Feed Forward Network做的事情就是,input一個x,通過第一個function f1得到a1,再通過第二個function f2得到a2,一直類推,一直得到最後的y。
link |
那這邊的這個index是代表的是layer,這邊數字越來越大代表的是越來越多的layer,其實平常我畫這個的時候都是畫,Feed Forward Network都是畫縱向,它代表的是越來越深。
link |
那RNN呢,RNN說我input x1和h0,我通過一個function f5得到h1,再加上一個x2,再通過一模一樣的function f得到h2,反覆執行這個步驟,然後在某一個地方你可以再apply一個function g,然後得到第四個時間點的output y4。
link |
那今天你如果比較Feed Forward Network和Recurrent Network,你會發現說它們其實還是有蠻多相似之處。在這個Recurrent Network裡面,這邊每一個output代表的是時間點,這邊上標代表的是時間,在Feed Forward Network裡面這邊上標代表的是layer。
link |
Feed Forward Network跟Recurrent Network不同的地方是第一個是,Feed Forward Network沒有在每一個時間點都有input x,它只有在第一個時間點有input x,你可以把這個x就想成h0的話,如果你把這個Recurrent Network的這個部分,每一個時間點input x的部分都補離,或者都把它拿掉,那其實它就跟Feed Forward Network很像。
link |
在另外一個不一樣的地方就是,Feed Forward Network每一個layer都是不同的,每一個layer都是不同的function,都用了不同的參數。
link |
在Recurrent Network裡面,因為有這個sequence可能可以是,你不知道有多長,每一次input sequence的長度可能都是不一樣,所以我們不會給每一個timestamp都給它一個不同的function,每一個timestamp用的function都是一樣,都是f。其實就這兩點不同而已。
link |
所以你完全可以把一個RNN豎起來,就當作一個Feed Forward Network來用。大家了解我的意思嗎?就平常RNN是放橫的,那你敢不敢把它豎起來,就當作一個Feed Forward Network來用。
link |
我們知道說在RNN裡面,我們會用gated recurrent network,比如說LSTM或GRU。如果我們知道說LSTM跟GRU它在train這個很長的sequence的時候是比較有用的,它可以記住比較長的sequence,它在長的sequence的performance是比較好的。
link |
那你敢不敢把LSTM豎直,比如說LSTM可以train很長,可以train100個layer,那你敢不敢把它豎直,就當作一個Dex100的Feed Forward Network。當然就是可以的。
link |
那這個東西呢,就是我最早看到的版本了,就是Highway Network。那我們等一下會看一下說我們怎麼把GRU改成Highway Network。
link |
在Highway Network的paper的開頭它就有說,這個想法就是來自於要把recurrent network豎直。所以把recurrent network豎直這件事並不是我隨便亂講的。它這個paper開頭就說,它想做的事情就是把recurrent network豎直。
link |
就把LSTM豎直,然後看看這樣子可不可以run一個很deep很deep的network。但是我們還是需要做一些改變,Feed Forward Network跟RM還是一些不同的事情,要根據它的不同點做一些修改。
link |
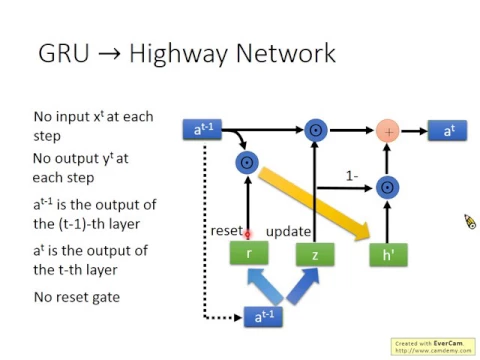
但是修改的地方並不多。我們從GRU改成,我們可以把GRU,我們從GRU來改成Highway Network,因為Highway Network其實是比較像GRU的。首先,右邊這個圖就是我們上上週看到的GRU的圖。
link |
那inputX呢,首先要把inputX拿掉。在recurrent network每個時間點都有inputXT,但是在Feed Forward Network裡面沒有,所以把XT拿掉。
link |
那YT也拿掉,在recurrent network裡面每個時間點都output一個YT,但是在Feed Forward Network裡面在最後一個時間點再output就好了,只是最後一個時間點再outputY,最後一個layer再outputY就好,不用每個layer都outputY,所以把YT也拿掉。
link |
那接下來呢,我改一個notation,因為一般recurrent network,recurrent neural network我都用h來表示h跟layer的output,但是之前Feed Forward Network我們都用a來表示layer的output,所以我做一件完全不太有意義,完全沒有影響的事情,就是把h改成a。
link |
所以本來h-1代表在時間t-1的時候的t跟layer的output,現在把它改成at-1,意味著是第t-1個layer的output,就是它很地合很地合,然後第t-1個layer的output就是at-1,然後第t-1個layer就是at,所以at-1就是第t-1個layer的output,at就是第t-1個layer的output。
link |
然後這邊我們要把reset gate拿掉,為什麼要把reset gate拿掉呢?因為你可以想像說reset gate的作用是要讓GRU忘記之前發生過的事情,但是今天在highway network裡面你不應該忘記過去發生的事情。
link |
為什麼?因為在GRU裡面,你每一個時間點都會有新的information進來,所以你可以忘記過去的事情,過去有些事情不重要,比如說你在辨識一段很長的話,某些詞彙已經完全辨識出來了,那你就可以把過去記得的東西就忘掉。
link |
但是在highway network裡面,它是一個fee-forward network,所以它只有在一開始的地方有一個input,之後就通通沒有input了,所以如果你在中間突然reset gate把之前的information都reset掉的話,那你就沒有任何information了,因為只有在input一開始的時候是有information,之後都沒有information,所以這邊不需要reset gate。
link |
那另外一個把reset gate拿掉的另外一個理由就是,你就少了很多參數,不要忘了現在是fee-forward network,所以每一個layer用的參數都是不一樣,所以在用recurrent neural network的時候,每個時間點的parameter都是一樣,
link |
但在fee-forward network裡面,每一個時間點的黃色的箭頭參數跟藍色的箭頭參數都是不一樣,所以參數其實是越少越好。
link |
那講到這邊,大家有問題嗎?沒有的話,我們看下一張圖,這個圖跟前頁講的圖是一模一樣,只是把它豎起來,前頁是橫的,把它豎起來。
link |
input是at-1,output是at,那at-1,第t-1個layer的output怎麼變成第t-1個layer的output呢?
link |
首先,這個at-1要乘上一個weight w,變成h',h'就是這裡,如果再前一個layer,如果再前一個圖,它就是這個h'.
link |
好,那這邊有一個gate,剛才那個GRU其實只有兩個gate,我們把reset gate拿掉,剩下update gate而已,所以這邊唯一的gate就是update gate。
link |
update gate的值是把at-1乘上w'得到z,所以把at-1乘上w'得到z,這個z操控紅色箭頭的位置。
link |
最後,at就是z乘上at-1加上1-z乘上h,ok,z乘上at-1加上1-z乘上h。
link |
我們知道說在GRU裡面,update gate是input gate跟forget gate的綜合,所以它的input gate跟forget gate是連動的,所以z一方面又乘上1-z,另外一方面1-z又乘上h,合起來就得到了at。
link |
這個是highway network,那有了highway network以後,後來Microsoft又設計了一個更精簡的版本,這個叫做residual network,那我相信很多人都聽過residual network。
link |
這個residual network你可以train個150層,其實在那個paper裡面還有試1000層,只是1000層沒有比150層還要好就是了。
link |
這個residual network就是這樣子,你有一個at-1,那怎麼得到output at呢?你把at-1乘上一些transform,這邊不只過一個layer,它可能過好幾個layer得到h'.
link |
把h'直接跟at-1相加,就得到at。
link |
在這邊,h'跟at-1它們中間還有一個gate,自己來control,那這邊就不control了,h'跟at-1就當作是一樣重要,把它們兩個直接加起來,得到at。
link |
那其實residual network,我記得有一陣子在advertise residual network的時候,也有人會說residual network就是把LSTM述職,就是residual network。
link |
那這種highway network的好處就是,你等於是可以自動control你要用多少個layer,假設我們有一個三個layer的highway network。
link |
那如果今天呢,我們中間這個layer的gate往左搬,上下這兩個layer的gate都往右搬的話,那變成說這個wait跟這個wait就沒有作用了,就被拿掉。
link |
那你就變成說,你在做這個test的時候,你在處理這個input和output之間的關係的時候,你只用一個layer。
link |
但你也可以用多個layer,如果今天是第一層和第三層gate往左搬,第二層gate往右搬的話,那把沒用的東西拿掉,剩下第一層跟第三層,那就是通過兩個e的layer。
link |
你input和output之間的關係,就用兩個layer來處理。
link |
所以可以說highway network是在自動決定我們要用多少個layer。
link |
那真的是這樣嗎?在highway network的pack裡面其實是有這方面的verification,是有這方面的實驗來佐證。
link |
那他把這個50層的highway network分別train在at least和siphon 10上面。
link |
所以左邊是50層的highway networktrain在at least上的結果,右邊是50層的highway networktrain在siphon 10上的結果。
link |
那這邊做的這個實驗是什麼呢?今天做的實驗是說,現在有50個layer,那這邊的每一個點就代表一個layer。
link |
所以你看這邊是橫軸,希望大家看得清楚,橫軸是1到50,橫軸是1到50。
link |
然後縱軸呢,縱軸是loss,就是我們今天的這個highway network在training data上面算出來的loss。
link |
那這邊他的做法是說,假設我們已經先認好的highway network,然後我們把這個認好的highway network拔掉一層,
link |
然後看說他在training data上,就拔掉以後就不再存權了,就拔掉以後,看在training data上面影響有多大。
link |
那如果今天拔掉某一層以後發現沒有影響,那意味著什麼?意味著那一層是沒有被用到的。
link |
那一層通常都是繞過了那個non-linear的transform,直接把at-1接到at。
link |
如果今天拔掉某一層沒有影響的話,就代表說那一層其實是沒有被用上。
link |
就network自動學到說不要用那一層。
link |
那你會發現說,在at least的case裡面,在這麼多的layer,這邊有好多layer,這大概有30個layer以上,
link |
這30個layer拔掉對結果幾乎都是沒有影響。
link |
也就是說,還會network自己學到說,今天在做at least這個test的時候,可能只有前面這十幾個layer是真正需要用到。
link |
這十幾個layer常常會需要用到他們的transform,但這30幾個layer通常就是直接就不要他們的transform,就直接把input copy到output就好。
link |
那右邊這個圖呢,右邊這個圖是說,寸在Cypher10上,那你會發現,寸在Cypher10上,幾乎每一個layer拿掉,
link |
都是會對你的performance有一些傷害。
link |
所以在Cypher10上,因為Cypher10是一個比較複雜的test,它比at least還要複雜,所以你需要比較多的layer才能夠solve這個problem。
link |
好,那我們剛才已經講到說,把LSTM豎直,它本來是橫的,把它豎直。
link |
那我們可不可以有一個LSTM同時又是橫的,同時又是直的呢?
link |
當然是可以的,這個東西就叫做Grid LSTM。
link |
原來的LSTM是,它input一個C跟一個H,C是memory,H是heaterlayer的output,得到C'跟H'.
link |
好,那有一個Grid LSTM,它inputC跟H,outputC'跟H'.
link |
這個地方是時間的方向,原來LSTM就有這個東西。
link |
那它還有一個深度的方向,它的深度的方向就是inputA跟B,output就是A'跟B'.
link |
所以我們有時間方向的memory,也有深度方向的memory。
link |
那怎麼把這些Grid LSTM的block兜起來呢?
link |
那你要在橫的方向兜,也要在縱的方向兜。
link |
在橫的方向上的LSTM,這Grid LSTM的參數都是一樣,但是在縱的方向上,Grid LSTM的參數應該要是不一樣的。
link |
那其實也可以一樣的,你看那個Grid LSTM原始的,可以把它做兩個時間。
link |
就是你可以每一個layer的Grid LSTM通通都是一樣的,那你也可以每一個layer都是不一樣的。
link |
所以今天有時間軸上的memory,從ct-1到ct-1到ct-1,有這個深度的memory,al-1到al-1到al-1。
link |
那這個Grid LSTM,它裡面長什麼樣子呢?你怎麼input兩套東西,output這另外兩套東西呢?
link |
我們原來的LSTM,我們上週講過,就長這麼樣子,對不對?就是你input一個H,然後,這邊沒有X,這邊沒有X。
link |
你input一個H,然後產生,這個是input的information,這是input gate,這是forget gate,這是output gate。
link |
把input information乘上input gate,然後再把forget gate乘上memory,然後加起來,然後再乘上output gate得到最後的output。
link |
那這個Grid LSTM現在有兩套memory,兩套hidden layer的output,有C跟A,還有H跟B,那把它們放在哪裡呢?
link |
你就把A跟C放在一起串成一個比較長的vector,B跟H放在一起串成一個比較長的vector,
link |
用H跟B一起去產生這些control的information,把C跟A一起當作他們的memory,最後output就是outputC'跟A'然後outputH'跟B'。
link |
好,這個H'就會送到時間的方向,B'就會送到深度的方向,C'就送到時間的方向,A'就送到深度的方向。
link |
那剛才這邊看到的是2D的Grid LSTM,那當然也可以是3D的Grid LSTM,那什麼時候你要用到它,你就自己想想看。
link |
你這邊inputC跟H,然後inputE跟F,然後inputA跟B,那C跟H是時間的方向,A跟B是深度的方向,至於E跟F需要什麼方向,你就可以自己想想看你什麼時候需要這個東西。
link |
然後在時間方向上inputC'H',在深度方向上inputA'B',在不知道可以做什麼,你可以想像的方向上inputE'跟F'.
link |
這個圖是我自己畫的,那右邊那個圖就不是我自己畫的,這payment上直接截下來。
link |
然後你把這些三維的Grid LSTM通通疊在一起,你就可以拿它來做你想要做的事情。
link |
好,那今天5點20,我們就上到這邊,謝謝。