back to index
Recursive Network
link |
然後第三節的時候呢,助教會來講一下作業二跟final。
link |
好,那上一次呢,我們講到recursive的network。
link |
那recursive network是什麼呢?recursive network呢,是recurrent network的一種更generalized的形式。
link |
大家都知道recurrent network,那recursive network呢,是這個recurrent network更generalized,所以recurrent network是recursive network的一個subset。
link |
好,那我們這邊呢,用這個sentiment analysis呢,來當作例子。
link |
我發現我今天講話特別大聲,有一個很強的回音。
link |
好,那個這個sentiment analysis要做的事情是這樣。
link |
input一個word sequence,然後machine要決定說,這個word sequence呢,它的sentiment是什麼。
link |
也就是它是正面、負面還是這個中性的等等。
link |
好,那這個word sequence呢,就會被表示成一個vector sequence。
link |
你可能用word embedding來表示每個word,它就變成一個vector sequence。
link |
或每個word可以用one of encoding來表示它。
link |
好,那最後的output呢,就是sentiment,也就是說假設你把這個sentiment呢,從最正向到最負向分成五個等級。
link |
那你要output的就是一個五維的vector。
link |
那如果用recurrent network呢,recurrent的structure來solve這個problem的話,那你做的事情呢,這我想大家都應該知道。
link |
input h0,然後通過某一個function f,output h1,再把h1跟x2丟到一個一模一樣的function f,得到h2,再把h2跟x3丟進一個一模一樣的function f,得到h3。
link |
最後呢,等把整個sequence讀完,就把最後一個time step的呢,這個f的output呢,丟到另外一個function g裡面。
link |
這個g可能就是幾個hidden layer,最後得到最終的output。
link |
那如果用recursive structure的話,你會怎麼solve呢?
link |
在recursive structure裡面,你需要先決定這四個input的word,他們中間有什麼樣的關係,他們的structure呢,長什麼樣子。
link |
然後呢,你要根據這input的四個word呢,得到output的這個sentiment的factor。
link |
那如果是用recursive structure,假設你的structure已經決定好了,那你做的事情呢,可能是這樣。
link |
把x1跟x2丟到一個function f裡面,f呢,得到h1。
link |
接下來呢,把x3跟x4丟到function f裡面,得到另外一個output,h2。
link |
這兩個function是一模一樣的,但是丟進去不一樣的東西,所以output就不一樣。
link |
至於為什麼把x1跟x2算成一起,x3跟x4算成一起,這個是你要事先根據你對這個task的理解先決定好的。
link |
好,那接下來呢,再把這個f,同一個f再拿出來一次,把h1跟h2呢,丟到f裡面,你就得到h3。
link |
最後把h3呢,丟每個function g,g呢,得到最後的output,就是你要的東西。
link |
好,那這邊呢,為了要讓這些f呢,前後可以相接,所以在做的時候呢,你需要做一些設計。
link |
你需要讓這個h跟x的dimension是一樣的,你要讓h跟x的dimension是一樣的,這樣你才能夠把這些f呢,堆疊起來。
link |
那你會發現說,recurrent network其實是recursive network的一個special case,recurrent跟recursive意思聽起來是這個實在是很像,
link |
而如果你要翻譯它的話,我們就都翻譯成定回式網路,反正中文你根本就分不出來。
link |
那,但是這個recurrent network你可以看成是recursive network的一個structure,如果你今天訂好說,這個h0要先跟x1接起來,
link |
然後他們的output再跟x2接起來,他們的output再跟x3接起來,如果你定義的這個compose的結合的這個順序,
link |
如果你把recursive structure定義的這個結合順序跟recurrent一樣的話,那recursive就變成recurrent。
link |
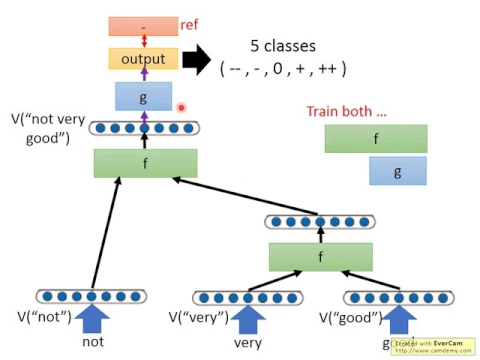
接下來我們講一個比較具體的例子,假如說我們現在要做sentiment analysis,那input的句子是not very good,
link |
那machine要決定說not very good是positive還是negative,那首先如果是給你一個這個人類語言的句子,
link |
那你其實可以得到這個語言的文法結構,你可以找到一些現成的parser,比如說這個stanford的parser,
link |
他就可以你給他一句英文,他就告訴你說他的文法結構呢,長什麼樣子,怎麼產生文法結構這件事呢,
link |
不是我們這一門課要討論的,我們就假設說文法結構是一致的,而如果是其他的test,比如說你要讓machine處理一個數學式,
link |
那其實這個文法結構更清楚,那些括號什麼的就告訴你文法結構長什麼樣子。
link |
好,那所以文法結構告訴你說very跟good呢,要先合在一起,然後他們合起來的結果very good是一個phrase,
link |
然後再把not加進來,not very good是另外一個更high level的phrase。好,所以如果我們今天要apply recursive network到這個not very good這個input的sequence上面的話,
link |
那我們會怎麼做呢?首先呢,先把所有的這個word都用一個vector來表示,比如用它的word embedding來表示,
link |
接下來呢,你拿出那個function f,那個function f它結合的順序呢,就跟這個文法的結構,跟這個syntactic的structure是一樣的。
link |
先把very跟good的vector丟到f裡面,然後呢,這個f就會output另外一個vector。
link |
那我們這邊假設呢,假設這些word vector呢,它的dimension呢,都是z的話,那你今天呢,這一個network,這個f呢,它的input呢,就是兩倍的z,它的output呢,就是z。
link |
你一定要設定好說這個output呢,跟這個input呢,你一定要設定好說input是這個兩倍的output,不然等一下呢,你沒有辦法再重複的apply同一個function f。
link |
好,那當我們apply這個function f的時候,得到的這個output我們要怎麼解讀它呢?
link |
我們可以把這個output想成是,這個vector代表了very的意思,這個vector代表了good的意思,而這個vector我們希望它就代表了verygood的意思,我們就希望它代表了verygood的meaning。
link |
好,那這邊這個f呢,它可能不是一個簡單的function,你可能需要用到neural network,因為這一個verygood的vector不會只是單純是very的vector,直接加上good的vector就得到verygood的vector。
link |
它們之間的關係顯然不會是這麼單純的,因為你可以想像說,今天這個not它可能是一個中性的字眼,而good是一個正面的字眼,但是我們不能說直接把not加good合起來就變成一個介於中性和正面的字眼,就是唯正面的字眼。
link |
其實不是,因為把not跟good加起來它就變成一個負面的字眼,所以中間這個f的轉換它其實可能是需要很複雜的。
link |
在中文也有同樣的問題,比如說你知道棒是非常正面的,好棒是非常非常正面,但是如果我們把棒加好棒的話,它變成超級正面它就變成負面的意思。
link |
所以我們需要一個network來幫我們處理這個問題,我們希望這個network可以做到說,舉例來說,我們現在的input是not跟good,那它的output,good是正面的意思,但not good要變成負面的意思。
link |
如果我們input not跟bad,bad是負面的意思,所以用紅色表是負面的意思,用藍色表是正面的意思,但not bad就要是正面的意思。所以machine要自動學到說,假設它看到not所代表的vector,它就要把另外一個輸入的vector轉向。
link |
它看到not的這個vector,如果輸的是good,它就把它好像成立一個負一一樣,就把它轉向變成紅色的,看到紅色的就把它轉向變成藍色的。
link |
但是它不能只會做到轉向這件事,它有很多其他的operation,舉例來說,如果input very跟good,good是微正面,但是very good就是非常正面,或是input bad,但是加上very的話,本來bad是負面,但是very bad就變得非常的負面。
link |
所以machine也要知道說,如果今天input very所代表的vector,它要做的事情就是emphasize另外一個vector,把原來正面的東西變得更正面,把原來負面的東西變得更負面。
link |
那你說machine怎麼自動做到這些事情呢?這個function f怎麼自動做到這些事情呢?這個f怎麼做到這些事情,就是透過training data自動學出來的。也就是說,現在我們就用這個f把very跟good結合起來,得到very跟good的well-embedded。
link |
接下來,你把not的vector跟very good的vector,再丟到同一個f裡面,再得到另外一個vector,這個vector代表了not very good的well-embedded。
link |
接下來,你把not very good,也就是整個sentence的embedded,丟到一個function g裡面,然後g的output告訴你說,那g的output就是sentiment。假設你今天定義五個sentiment,從非常positive++到非常negative減減的話,那output就有五個dimension。
link |
那麼接下來呢,我們會有training data,也就是training data告訴你說,這個sentence,它的sentiment是屬於哪一個class,比如說not very good,它是屬於減這個class。
link |
那你就可以根據這個reference跟output的差距,一路back propagate回來,把g跟f通通都train起來。那如果你這麼做的話,希望你train出來的f就可以做到我們剛才說的事情。
link |
比如說看到not,就把另外一個vector轉向,看到very,就強化另外一個vector。好,講到這邊,大家有問題嗎?那你趕快懷疑說,這個f到底應該要長什麼樣子?
link |
我再強調一次,這個東西它就是一個network,你可以把它的computational graph畫出來,那你在做這個gradient的時候,你就從reference跟output的difference這邊一路算下來,就可以把整個network裡面的f、g的參數都自動求出來。
link |
只要自動學的,你不用去設定它。但是這個f應該要長什麼樣子呢?最簡單的樣子就是我們把藍色的vector跟黃色的vector串接在一起,
link |
你就把它當作只有一個layer的neural network,把a跟b串接在一起,乘上一個參數w,參數w是要學出來的,再通過一個activation function得到這個綠色的output。
link |
但是如果這樣做的話,你可能沒有辦法得到特別好的結果,因為一個問題就是,我們現在在考慮的是a和b之間的interaction,我們希望a的每一個component對b的component會有,就a和b的component他們之間是要互相影響。
link |
如果你只是這麼做的話,那你的這個綠色的dimension,你的這個綠色的vector裡面的每一個dimension,都是a的某一些component加上b的某一些component的值。
link |
但是他沒有辦法做到,像我們剛才說的,如果是看到not就把另外一個vector轉向,看到very就把另外一個vector強化這件事情。
link |
你要做到轉向或強化,你可能需要的是相乘的關係,如果只有相加的關係,可能是不夠的。所以今天,你可能需要設計更複雜的function。
link |
今天下面講的這個network叫做recursive neural tensor network,它是一個recursive network,而它裡面的每一個component的function f,它有tensor network在裡面。這個tensor network做的事情是什麼呢?
link |
除了我們剛才已經看到的這個部分以外,它會做另外一件事情,把這個藍色跟黃色的vector串起來變成一個vector,這個vector乘上一個vector w,乘上一個matrix w,再把這個matrix w乘上x的transpose,乘上同一個vector的transpose。
link |
我們假設這個叫做x,這個叫做w,這個叫做x的transpose,如果你這麼做的話,你會得到什麼呢?如果你把這個vector乘上這個matrix,再乘上這個平坦的vector,你得到的其實是一個scalar,對吧?
link |
你得到的是一個scalar,如果你熟悉線性代數的話,這邊的dimension是1,這邊的dimension是1,所以這三個東西乘起來,它們是一個scalar。
link |
這個scalar的數值是什麼呢?如果你真的乘一下,你就會知道說,這個scalar的數值就是submission over所有的ij,這個ij就是你把這個x這個vector裡面取兩個component出來,就是Cn取2取兩個component出來,一個index是i,一個index是j。
link |
然後你把indexi的value乘上indexj的value,最後再乘上這個matrixw裡面的wij,然後再把所有的可能,這邊應該不是Cn取2,應該是n平方,再把這個n平方項通通加起來,那你就得到這個scalar。
link |
所以在這裡面,你就會得到相乘的關係,假如這個xi是來自於藍色這個vector,xj是來自於黃色這個vector,你就可以得到藍色的vector和黃色的vector相乘的關係。
link |
不過這樣你得到的只有一個scalar,而這邊得到的是一個二維的,假設這邊是兩個dimension,這邊是兩個dimension,這個matrix是2x4,2x4的matrix,那你這邊得到的是二維的vector,那這邊只有一個scalar,配不起來。
link |
那怎麼辦呢?把這件事情再做一次,但是這一次的這個matrix是不一樣的,上面這個黑色裡面的點都是黑色的w,下面這個點都是黃色的w,他們的數值是不一樣的。
link |
所以你再做一次同樣的運算,把x乘上這個w,再乘上這個x,你得到的是另外一個scalar,把這兩個scalar串在一起,你就得到一個vector,然後你最後再經過相加以後,你就得到最後這個綠色的vector。
link |
其實這個f它可以很複雜,然後你可以自己去設計它。那以下是在文獻上面,根據我們剛才在前一頁看到的recursive的這個neural tensor network所得到的結果。
link |
那這個task做的就是sentiment的analysis,那在那個task裡面,sentiment就被分成五種,而且有一個demo的system在網路上,來看看說這個model做起來是怎麼樣。
link |
那像它有很多不同的版本,在那個neural tensor network propose之前,其實還有另外一個版本,這個版本是metric vector recursive network,那這個版本其實我覺得聽起來比剛才講的那個tensor network還要更有道理一點。
link |
但是在文獻上比較起來,這個方法performance是比較差的,但是我們可以看看它當時設計的時候是有一些想法在裡面。
link |
這個model設計的想法是這樣子,這個vector其實包含了兩個部分,就是一個word的embedding它其實包含了兩個部分,一部分是這個word本身的意思,另外一部分是這個word如果跟其他的word去做compose的時候,它去如何影響其他的word。
link |
所以一個wordembedding包含了兩種意思,一個是它本身的意思,一個是如果它要影響別人的時候,它會怎麼影響別人。
link |
所以今天這整個function f它很複雜,我們用一個很大的框框來表示它。
link |
今天一個vector進來的時候它被拆成兩部分,一部分是一個vector A,這個部分代表了這個詞彙它原來的意思,另外剩下的部分被排成一個matrix大A,這個大A代表說這個word如果要影響別人的話,它會如何影響別人。
link |
黃色這個vector也做一樣的事情,一部分變成一個vector B,另外一部分變成一個matrix大B。至於哪一部分要變成vector,哪一部分要變成matrix,這個就是事先決定好的。
link |
這個又遇到一個老梗的問題就是,你怎麼知道這個vector的前兩維它代表了word本身上的意思,後面四維代表了它如何影響別人呢?這個問題我們上次上課的時候已經有講過了。
link |
這是一個充滿哲學性的問題,它並不是因為它代表了如何影響別人,所以我們才說它是屬於它,才把它變成一個matrix,而是因為我們把它變成一個matrix,所以最後認出來它會去影響別人。
link |
這樣大家聽得懂嗎?你可以回去慢慢去體悟這個想法。
link |
我們現在有了這個vector A,我們要把這個藍色的vector跟黃色的vector組合在一起的時候,它們就會互相影響。
link |
所以藍色的vector這個word,藍色的這個詞彙,它本來的意思A就會被大B這個matrix所影響,得到了另外一個意思。
link |
如果今天這個B呢,它也會被大A這個matrix所影響,所以它又得到了另外一個意思。比如舉例來說,如果你今天你input的這個詞彙是not,那另外一個詞彙是good,那你可以想像說not本身其實沒有什麼意思。
link |
所以小A這個vector它可能是一個zero的vector,而B呢,good它本身有意思,所以今天這個vector可能就是代表了一個positive的information。
link |
接下來如果我們看這個matrix的話,good它可能不會去影響別人,所以good的這個matrix它就是identity的,它跟別人相稱後不會去影響別人。
link |
而A這個matrix呢,它可能就是-1乘上identity,因為其他詞彙加上not的意思會變相反,所以這個A就會是-1乘上identity。
link |
所以你把A的這個matrix拿去乘別人,它的意思就變了。你把B這個matrix拿去乘別人,它的意思可能就會原來差不多。
link |
接下來呢,你就把這兩個vector接在一起,乘上W,得到output,這個output就代表not good這個詞彙的意思。
link |
然後你再把這兩個matrix接在一起,再乘上另外一個matrix,再得到,這個W跟Wm都是參數,它們是要被認出來。
link |
你把這個Wm乘上這個長方形的matrix,那就得到另外一個matrix,然後這個東西就變成這個very good這個詞彙要影響別人的matrix。
link |
最後呢,你再把這個vector跟這個matrix拉平,就變成這個function的output。
link |
所以這個matrix vector recursive network,它中間的運算是很複雜的,它用了很多human knowledge,你覺得說這些vector應該要怎麼互相影響在裡面。
link |
還有另外一個更複雜的架構叫tree的LSTM,我們之前有講說LSTM是這樣子,我們有一個function,
link |
那這個function呢,它會input一個h,input一個m,然後會得到另外一個h,得到另外一個m。
link |
你當然可以把h跟m組合起來變成一個比較長的vector,然後說LSTM就是input一個比較長的vector,得到另外一個比較長的vector。
link |
但這個h跟m呢,它扮演了不同的角色,h代表了這個比較,h的input跟output呢,它的差別會很大,m的input跟output差別是比較小的,所以LSTM可以記得long term memory。
link |
那你一樣可以有一個tree的版本的LSTM,什麼叫tree的版本的LSTM呢?
link |
你只是把這邊的f換成LSTM,LSTM的input就要有兩種vector,m跟h,但這邊的f呢,它有兩條input,一個是從左下角的f來,另外一個是從右下角的f來。
link |
那這些左下角跟右下角的f呢,它們也是常用的LSTM,它們都會output一個h,input一個m,所以上面這個f呢,它就是input h1跟m1是左下角這個f的output,跟input h2、m2是右下角這個f的output。
link |
把它們組合起來以後呢,得到h3跟m3,那你就反覆apply這個LSTM,在這個structure裡面,你就得到了這個tree的LSTM。
link |
那除了sentiment analysis以外呢,這種recursive的structure啊,它還有很多application。
link |
那基本上如果你今天要處理的是sentence的話,只要你想,基本上,今天如果你要處理的東西是一個sequence,而這個sequence的某種它背後的結構你是知道的,
link |
比如說語言,你完全,你通常可以找到一個synthetic parser得到這個句子背後的架構,那你就可以apply這種recursive的network。
link |
那recursive network跟這個recurrent network比起來是比較強調的dependent,說你後面那個structure有多make sense。
link |
比如說把這種recursive network拿來apply數學式,它的performance就會遠勝這個recurrent network,因為數學式的structure是很明確的。
link |
語言上的話就是小贏,因為你的synthetic parser也不見得完全是正確的。
link |
那它可以做別的事,比如說可以拿來偵測說兩個句子是不是換句話說,講的是不是同樣的意思。
link |
怎麼做呢?你就說我有兩個recursive network,它們的參數是一樣的。
link |
把sentence1丟進去recursive network,你得到一個整個sentence的embedding,把sentence2丟到一個recursive network得到另外一個embedding,
link |
把這兩個embedding丟到一個neural network裡面去,這個neural network做的事情就是判斷說這兩個句子有什麼樣的關係。
link |
比如說它們的關係是換句話說還是它們的意思是相反的等等,就把換句話說當作一個class,相反當作一個class。
link |
那就收集很多data,也就是收集很多句子的pair,然後把它們的關係label好,接下來backpropagation train,
link |
你就會把這個n跟下面兩個recursive network都train出來,接下來你就可以把它拿來偵測兩個sentence之間的關係。
link |
那以下就是一個paper的例子,比如說它知道說a woman is slicing a potato跟a woman is cutting a potato的意思是一樣的。
link |
那這邊數字代表說network偵測它們的意思是一樣的程度,或者是如果你把它倒裝,potato are being sliced by a woman,machine也知道說就算是倒裝,它的意思也是一樣。
link |
好,那講到這邊,大家有問題嗎?沒有嗎?我本來想要講的。