back to index
Conditional Generation by RNN & Attention
link |
那接下來要講的呢,其實是,這本圖裡面有四件事。第一件事情就是,我們怎麼產生一個有structure的東西。
link |
然後第二件事情呢,要講的是Attention。Attention這個東西其實是產生Structure Option的一個輔助。最後呢,會講一些和Generate Structure Option有關的Tips,那這些很重要,也許你可以用在作業上。
link |
最後呢,如果有時間講Point和Name,但這個是Option,我們可能講不到這裡就是。好,那我們現在要做的是什麼?我們要產生一個有Structure的Object。
link |
那假設這個有Structure的Object它可以拆成很多的Component的話,以下我們要講的方法就是用RNN把這些Component一個一個的產生出來。
link |
事實上這件事情,你已經知道要怎麼做了。舉例來說,我們怎麼讓Machine產生一段句子呢?怎麼讓它比如說寫一首詩或者是寫一篇文章呢?
link |
那我知道一個句子就是由Word或者是Character所組成的,對不對?它是用詞彙或者是字所組成的。這個有個地方或許可以提醒一下大家,就是在英文裡面所謂的Character就是A到Z,
link |
Word就是由空白所分割的。但是在中文裡面所謂的Word指的是一個有意義的單位,比如說葡萄是一個Word,但是葡跟桃分別是兩個Character。
link |
所以在中文裡面Word的定義有時候是比較Vague的。這件事情可能不是每個人都知道,有時候有人就會說,葡萄不是一個字,葡萄是個詞,然後葡跟桃分別是個字。
link |
那我們這邊怎麼解釋這個問題呢?如果你有一個RNN,你就可以用RNN把Character或者是Word一個一個的產生出來。
link |
舉例來說,這件事情你其實已經有辦法做了,我們在作業一裡面不是train了一個Language Model嗎?我們train了一個Language Model,這個Language Model可以predict,給你一個Word Sequence,它可以predict下一個Word的出現的機率。
link |
那今天我們需要的也就是一個Language Model,你要產生一個句子,你需要的也就是一個Language Model。假設我們現在train了一個中文的Character的Language Model,這個RNN-based的Language Model。
link |
然後呢,我們一開始就丟一個Token,這個Token代表Begin of Sentence,這個BOS代表說Sentence的起始,那通常把Sentence的起始用一個特殊的符號來表示,就把它當作是一個特殊的字,特殊的Character來看待。
link |
那你把這個BOS這個特別的symbol丟到RNN裡面,RNN就會告訴你說,接下來的W1的機率是多少。所以你會得到一個Character的,在RNN的Output會給你一個Character的Distribution,然後你再從這個Character的Distribution去做Sample。
link |
都根據這個Distribution Sample出一個Character出來,比如說你Sample出來是個床這個Character。然後接下來呢,你再把床這個Character再丟到RNN裡面,那RNN就會告訴你說,現在Input這個床這個Character,那接下來要接的Character的Distribution,然後再從這個Distribution再做Sample,你就Sample出錢。
link |
就一直反覆這個Process,你把錢再丟到RNN裡面,這個時候RNN就會Predict說,如果Input是W1、W2,也就是床跟錢,然後接下來它Output的Character的每一個Character,它Output的第三個Character的機率可能就是越,然後就可以寫一首詩。
link |
那其實呢,我這邊就想到一個很無聊的東西,其實這個鄉民的推文裡面,也是曾經有用這個方法寫一首詩的。我想試著找這個case的例子,但是我找了很久,我只找到一個例子。
link |
這個例子發生在2007年,也就是10年前,也就是這10年來都沒有辦法再用推文寫一首詩了。好像沒有人聽得懂我在說什麼算了算了,我把例子放在這邊,大家再自己看。
link |
就是鄉民的推文啊,鄉民的推文就是自動產生了一首詩,後來這個巧合都沒有再發生過了。那其實同樣的道理呢,你也可以拿來Generate其他的東西,你不是只能Generate文章,你也可以Generate一張Image。
link |
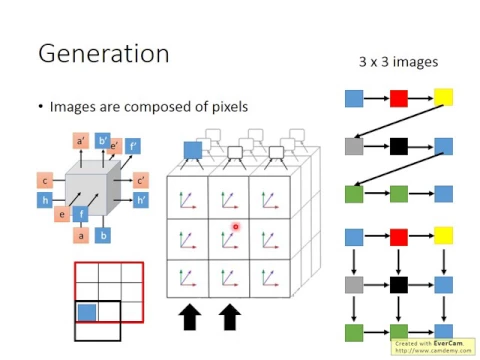
我們知道Image是由Pixel所構成的,所以你也可以用RNN來GeneratePixel,你說怎麼做呢?其實很簡單,用你現在手上的Language Model程式就可以做到。
link |
然後你把一個Image,假設這個Image是3x3的Image,它只有9個Pixel,你把這個Image看成是一個Sentence,一個Image怎麼看成是一個Sentence?就這樣看,第一個Pixel是Blue,所以這個Sentence裡面第一個詞彙就是Blue啊。
link |
第二個Pixel是紅色,是Red,那這個Sentence第二個詞彙就是Red,第三個Pixel是黃的,所以這個Sentence裡面第三個Pixel,第三個Sentence裡面第三個詞彙,第三個Word就是Yellow,第四個Word就是Grey,以此類推。
link |
所以今天這個Image其實就是一個有9個Word的Sentence,然後接下來你就直接把你作業1的Language Model程式,本來你是Train在那個Fuller模式上面,
link |
所以你現在用那個Language Model做淺音樂從裡面講Sampling,可能就Sample出Fuller模式裡面的段落,整個句子的一個段落。那如果你今天把這樣的程式拿來用Image來Train的話,你就可以做一個產生Image的RM了。
link |
你就把你手上收集到的Image通通都轉成這樣子的句子,然後用你手上的Language Model去Train下去,然後接下來你就可以用你手上的這個RM的Language Model去產生一個Image。
link |
你丟一個Begin of Sentence,然後它就Output說我現在要Generate一個紅色的Pixel,那你再把紅色丟進去,它就說我要Generate一個藍色的Pixel,你再把藍色丟進去,那RM就會考慮說已經產生紅色跟藍色,接下來要產生一個粉紅色的Pixel。
link |
那你再把粉紅色丟進去,RM就會說有看到紅色、藍色、粉紅色,接下來可能要再產生一個藍色的Pixel等等。其實用這個方法,你真的可以產生Image,你可以自己回去試試看。
link |
那如果上學期有修ML的話,ML裡面我們是Generate那個寶可夢嘛,其實就是用這個方法做的,我就直接拿一個我原來手上有的Language Model程式,然後在Image上Train下去,我也沒做其他Fancy的東西,做出來結果就還不錯。
link |
所以你現在你用你手上那個作業的程式,你其實也可以自動的畫各種圖出來。那你可能會覺得說這樣做好像不是最厲害的方法,感覺有很多瑕疵啊,因為剛才那個做法看起來是這樣,我先產生左上角的Pixel,接下來產生紅色的,接下來產生黃色的,
link |
接下來呢,一行已經過去了,一個Row已經過去了,所以接下來就要產生灰色的Pixel,灰色Pixel是根據藍色、紅色和黃色Pixel所產生的,接下來產生黑的,產生藍的,產生綠的,以此類推。
link |
你可能會覺得說這樣子不太對勁,因為你沒有考慮到一個Image的Pixel和Pixel間的幾何關係,比如說這個灰色和這個藍色是很接近的,所以這個藍色顯然會對這個灰色有很大的影響,而這個黃色應該對這個灰色是沒有什麼影響。
link |
這個綠色應該對灰色,這個灰色應該對綠色有很大的影響,這個藍色對綠色應該是沒什麼影響,但Machine考慮不到這件事。
link |
那其實,因為今天你用的是RNN,所以在產生這個灰色的時候,它其實也是考慮了前面所有你產生過的Pixel,所以它其實不會忽視曾經看過藍色的Pixel這件事,它其實如果你RNNTrain得夠好,它可以學到說在三個Step前的那個Pixel很有影響力,
link |
它其實學到這件事情只是可能比較困難而已。
link |
所以一個比較理想的方法,一個比較理想的產生Image的方法是這樣子,我們說用這個藍色的產生紅色的,紅色的產生黃色的,但是我們產生灰色的時候呢,它是根據這個藍色的Pixel去產生灰色的。
link |
我們產生中間這個黑色Pixel的時候呢,它是根據紅色和灰色的Pixel,所以產生黑色的Pixel。那產生右邊這個藍色的,它是根據黃色和黑色產生藍色,以此類推,以此類推。
link |
如果是這樣子的話,你就可以把Pixel和Pixel間的幾何關係,這個Image的幾何關係考慮起來。那怎麼做這個東西呢?你要做這個東西,你就可以用上我們上一堂課所講的3Dimensional Grid LSTM。
link |
記得我們上次上課有講這個3Dimensional Grid LSTM,我不是說你可以回去想想看它可以做什麼用,它其實可以用在這邊。
link |
我們今天講說3Dimensional Grid LSTM,它就是它可以input三個東西,它input三組東西,然後再output另外三組東西,然後把這個3Dimensional Grid LSTM疊起來,就變成這樣。
link |
你看它產生這邊output,就是這張Image。怎麼做呢?假設這個是我們要產生的Image的畫布,3x3的畫布,一開始上面沒有任何東西。
link |
然後接下來,你在這個左下角放一個Composition的filter,然後把這個Composition的filter所得到的output丟給3D的Grid LSTM左下角的這個Pixel。
link |
這個圖真的很難畫,我覺得我畫的,這個圖不是我自己畫的,這個圖不是我自己畫的,然後我試著在這邊加了一些有的沒有的東西,我覺得也不是很清楚。
link |
這個你要發揮一點想像力才知道我在說什麼。
link |
左下角這四個東西接到這邊左下角的這個Grid LSTM,然後這邊有一排LSTM,它在這個縱軸這邊也是有memory的,然後就一排Grid LSTM就process這個input,然後跑這邊就得到我們要產生的藍色的Pixel。
link |
接下來就把藍色的Pixel放到image的左下角,就產生了一個藍色的Pixel。
link |
接下來你把filter再往右邊移,然後這個時候filter會看到這個藍色的Pixel,所以它知道說之前已經generate過藍色的Pixel,它會把之前generate藍色的Pixel這件事情考慮進去。
link |
然後把這個結果從這邊丟進去,一路跑上來,一路跑上來的時候還會考慮左邊這一排Grid LSTM的output,左邊這一排Grid LSTM它會把它們的output往三個方向丟,上面這個深度的地方還要往右丟。
link |
所以當你做這一排,當你把input從這邊丟進來,這一路處理的時候你又會考慮左邊的這些Grid LSTM所考慮的東西,最後產生紅色的Pixel。
link |
再把紅色的Pixel放進來,再把filter往右移,filter知道說你已經產生過紅色的Pixel,接下來把filter的output丟到這邊,然後往上走就產生黃色。
link |
接下來就是比較難解釋的地方,整個嘴巴解釋圖有點難解釋。
link |
把filter放在這裡,然後它的input是在這個地方,大家知道這是什麼意思嗎?就是後面,這是它後面的意思,它在它的後面,然後就跑上去,跑上去,跑上去。
link |
同時也會看到前面這一排LSTM丟給它的information,它就產生灰色的Pixel,把灰色的Pixel放在這邊。
link |
接下來你再把filter放在這邊,這個filter知道說它已經在左邊已經有灰色的,左下已經有綠色的,藍色的,左下已經有紅色的,然後把這個information丟進去。
link |
這個箭頭指的是三乘以三的魔術方塊的中間那一條,知道嗎?中間那一條,幾乎沒有辦法解釋,中間那一條。
link |
中間那一條會考慮前面這一條丟給它的information,它也會考慮灰色的這一條LSTM,就產生灰色Pixel的這一條LSTM給它的information。
link |
接下來它就產生黑色的Pixel,然後再把黑色的Pixel填上去,然後就以此類推,就可以產生整張image。
link |
其實現在比較stand of the art的方法,確實就是用這個方法產生的,這不是我隨便亂編造的一個方法,可以自己看看文獻,只是細節上略有不同,但概念上就是這麼做的。
link |
以下我就列一些其他的reference,比如說你可以generate image,我剛才已經示範過怎麼generate image,你可以generate video,可以generate handwriting,可以generate手寫的文字,模仿別人的筆記之類的,可以generate speech,這個就是引頂大名的webnet。
link |
但是光是只能用RNNgenerate東西是非常不夠的,為什麼呢?因為如果你只是拿RNNgenerate的東西,比如說我們要generate sentence,那你generate出來的就是一個句子,它看起來像是合乎文法的句子,但是你沒有辦法控制它要說什麼。
link |
因為在很多場合我們並不是要machine random的產生一個句子,而是希望它說一些和情境有關的句子,它希望它說一些我們想要它說的句子。
link |
什麼意思呢?舉例來說,我們今天如果要做caption generation,做caption generation就給machine看一張圖,或者是看一個video,比如說它看到,我知道應該念新元節還是新環節,你在跳舞,然後它就應該說,a young girl is dancing。
link |
然後如果你要做checkbox,machine就是要看使用者說什麼,比如使用者說hello,它就要回答nice to see you。
link |
所以machine產生的句子必須要根據某些condition來產生,而不是隨機的產生。
link |
舉例來說,我們要怎麼讓我們去看一個image就說一句話來說明這個image呢?如果我們只是拿一個,比如說你在做一圈好的RNN出來的話,那沒有用,因為它產生的句子就是隨機的句子,跟image是完全沒有關係的。
link |
所以我們希望這個image可以影響RNN所產生的句子,怎麼做呢?你就要把這個image,比如說先通過一個事先check好的CNN,然後把它變成一個vector。
link |
現在有很多現成的model zoo在網路上,有一個image變成一個vector,然後你把這個vector當作RNN的input,丟給RNN。
link |
這樣子RNN在產生output的時候,如果你今天丟進去的image是不一樣的,那RNN的事物不一樣,它output當然就不一樣。
link |
你今天丟進去不同的image,它的vector representation,你就可以影響RNN的output。比如說你丟進去這張image,它可能就會知道說,在下一個時間點,它應該要產生woman。
link |
因為紅色這個vector的information會一路影響過來,所以它可能會影響這個RNN在產生第二個詞彙的時候,產生一個woman。
link |
如果你擔心說,只在第一個時間點把這個image的vector丟進去,那可能影響不夠大,因為可能在第二個時間點,Machine就會忘記它看到的image長什麼樣子。
link |
其實這個solution很容易,就在所有的時間點,每次都丟一個image,每次都把這個image的vector,在所有的時間點,每次RNN要output一個word之前,都把這個紅色的vector丟進去。
link |
那RNN就會反覆的複習它看到這張image,它就可能不會這個句子產生到後來,就忘記了自己要說什麼了。
link |
那同樣的方法呢,也可以拿來做很多其他的事情,比如說你可以拿來做machine translation,你可以拿來做機器翻譯。
link |
也就是說,假設現在使用者輸入一句話機器學習,你想把中文翻成英文,要把機器學習翻成machine learning,怎麼做呢?
link |
你現在有一個generator,它可以拿來產生英文的句子,但是現在這個input跟這個generator是沒有關係的。
link |
你要想辦法把這個input跟這個generator牽扯在一起,把它們兜在一起,把它們接在一起,這樣你才能夠input機器學習,希望machine output就是machine learning。
link |
那怎麼把它們接在一起呢?首先我們要把這個input的sequence表示成一個vector,如果我們可以把這個input的sequence表示成一個vector,我們就可以用跟前一頁投影片一模一樣的做法。
link |
前一頁投影片就是把image表示成一個vector,然後就丟到RNN裡面嘛。
link |
現在我們需要的也只是把input的這個句子表示成一個vector,就可以丟到後面的RNN產生句子的generator裡面。
link |
那怎麼做呢?我們就把這個機器學習這四個character一個一個的丟到另外一個綠色的RNN裡面,然後在最後一個時間點把綠色的RNN的最後一個時間點的hidden layer的output抽出來。
link |
那這個hidden layer的output可能就包含了input的這個句子的所有information。
link |
接下來呢,把這個紅色的vector呢,就跟剛才caption generation一樣丟給RNN,那它可能就產生machine,在下一個時間點再丟一次,它可能就產生learning,然後最後它產生句號,就結束了這個翻譯的過程。
link |
其實同樣的方法你也可以拿來做確保,比如說input是你好嗎,然後output可能就是我很好這樣子,所以同樣的技術你也可以拿來做確保。
link |
好,那前面這個部分呢,是一個encoder,前面這個部分呢,把input變成一個vector,然後丟給generator這件事情,我們稱之為encoder。
link |
後半部,根據這個code產生句子這件事情呢,我們稱之為decoder。
link |
那這個encoder和decoder其實是jointly trained,你可以jointly trained,也就是說你只要給機器現在這個encoder的input,還有decoder該有的output,你就可以jointly trainedencoder和decoder的參數。
link |
那另外一個問題就是,encoder和decoder它們的參數是要一樣的還是不一樣的呢?這邊有一個RNN,這邊有另外一個RNN,這兩個RNN是一樣的還是不一樣的呢?其實都可以。
link |
在我這個例子裡面,我用不同的顏色,所以代表說這個encoder的RNN跟這個decoder的RNN的參數是不一樣的,但是等一下在作業2的說明裡面呢,助教會講一個參數是一樣的encoder跟decoder。
link |
但是這樣子參數是一樣的好處就是,你比較不容易overfitting,參數比較少嘛。那如果你data比較多的時候,你當然可以說encoder跟decoder的參數不一樣,然後希望得到比較好的performance。
link |
總之encoder跟decoder是可以jointly trained,這個東西就是sequence to sequence的learning。如果你今天是要做一個check bar的話,你可能會需要考慮一個更複雜的問題。
link |
舉例來說,今天如果是user跟你的機器說hi,那你的機器很自然的答覆也可能是說hi,那你只需要train一個sequence to sequence的model,把hi丟進一個encoder裡面變成一個code,然後再從這個code decode出machine的response。
link |
可能你input是hi,那output可能decode出來的結果可能也就是hi。但是我們知道說在對話的時候,有可能是motor turn的對話,所以這個對話是需要考慮history的,machine需要考慮它之前說過什麼,才能夠做出合理的response。
link |
舉例來說,假設這整個對話是這樣,machine在一開始已經說過hello,然後user就給他一個回應說hi,那machine在說hi就顯得很宅很智障。
link |
其實這件事情在人類身上也是會發生的,你可以看一下下面這個連結,這個是Sheldon第一次遇到Penny的時候的interaction。Sheldon說一個hi,然後Penny也說一個hi,Sheldon又再說一次hi。
link |
其實也是一個缺乏,人類的反應其實跟缺乏是差不多的。所以我們今天需要考慮比較長的context,machine至少要知道說它之前已經說過hello,所以它就不要再說一次hi,就不用打招呼兩次。
link |
甚至machine可以記更長的information,比如說使用者到底已經說了什麼話。比如說使用者可能已經說過我叫什麼名字,我叫什麼某某某,那machine就不要再問一次你叫什麼名字,等等之類的。
link |
那要怎麼讓machine能夠考慮這種long term的information呢?那當然有很多不同的解法,一個直覺的解法就是你其實可以把那些long term的information通通變成condition,通通變成code。
link |
只要你的encoder有辦法把那些long term的information都變成code再丟給encoder,你就可以把long term的information考慮進來。舉例來說,這邊有一個做法是我們可以有一個雙層的encoder。
link |
這個雙層的encoder首先會把每一個過去已經互動過的sentence,比如說之前machine已經說過hello,接下來user說了hi,這些句子通通通過RN變成一個code。
link |
而接下來再有第二層的RN,這第二層的RN把過去所有互動的記錄從頭到尾讀一遍,變成一個code。
link |
然後再把根據過去的interaction的記錄和看過的句子,這個第二層的RN會把過去所有講過的句子通通考慮過一遍,然後再把這個結果丟給decoder。
link |
那如果decoder知道說之前已經說過hello,說過一次,他可能就不會再response hi這樣子。
link |
好,那接下來我們要講的是這個attention。
link |
那attention是什麼呢?attention就是一種動態的conditional generation。
link |
什麼意思呢?我們剛才在講這個generation的時候,我們說為了要讓encoder可以去影響decoder,所以我們把encoder的output在每一個時間點都接給decoder。
link |
但是我們可以把這件事情做得更好,我們可以讓這個decoder在每一個時間點看到的information都是不一樣。
link |
這樣做有什麼好處呢?一個好處是,有可能你的encoder沒有辦法把input的整個sequence變成code。
link |
如果你的input的information很複雜,也許根本沒有辦法用一個vector來描述它。
link |
如果input的information沒有辦法用一個vector來描述它,那每次decoder看到的vector都是一樣的,那他其實沒有辦法得到好的結果。
link |
那另外一個好處是說,我們可以讓decoder考慮比較需要的information。
link |
就原來呢,decoder它的input是整個句子的information,原來input是整個句子的information。
link |
但是我們可以讓machine在產生machine這個,我本來是讓他一瞬間以為這個拼錯了,但是那是因為他是直的,所以我才覺得他拼錯了,所以其實這邊是沒有拼錯。
link |
這個input,希望machine在產生machine這個詞彙的時候,他只需要去考慮input這個句子機器這個部分就好了。
link |
因為只有機器這個部分跟machine是有關的,如果我們只把機器這個部分information丟給他,那machine其實可以學得更好。
link |
他不需要再從整個sentence的information裡面去把需要的部分擷取出來,他可以直接就把相關的information讀進來,他只考慮相關的information就好。
link |
或者是他在考慮learning的時候,他只需要看學習這兩個character,他就可以generate learning。
link |
這件事怎麼做呢?我們以下就用機器翻譯來做為例子。
link |
這個model就叫做attention model。
link |
現在一樣有一個input的句子,input這個句子會用RNN做一番處理,所以在每一個時間點,每一個詞彙都可以用一個vector來表示它。
link |
這個vector就是RNN的hidden layer的open。
link |
接下來,有一個初始的vector,z0。
link |
這個初始的vector,z0你可以把它當作一個network的參數,它是可以根據training data學出來的。
link |
有一個z0,這個z0會有一個match function,這個match是一個function。
link |
你把h1跟z0丟進去,他就得到alpha上標以下標的。
link |
這個上標的意思是說,今天這個z0是跟h1算他們有多match。
link |
那這個下標0代表說現在是在時間等於0的時候,在初始的時候去計算這個相匹配的程度。
link |
那這個match它是什麼樣的一個function呢?其實你就可以自己設計。
link |
這方面的研究還頗多,那現在其實也沒有一個固定的做法,你可以在作業裡面自己設計。
link |
你也可以把這個當作一個留言終結者的題目。
link |
舉例來說,你可以說match這個function裡面其實沒有任何需要learn的參數。
link |
它就是簡單的h1跟z0算cosine similarity。
link |
當然這個前提是h1跟z0的dimension要一樣,可以直接算cosine similarity。
link |
你可以說match其實是一個neural network,它input就是把h1跟z0compatible起來。
link |
這個就是一個vector,output就是一個scalar。
link |
你可以說match裡面有一個參數w,這個參數w是一個matrix,這個matrix它是要被學出來。
link |
你把z乘上這個w,再乘上h的transpose,你會得到一個scalar alpha。
link |
這個alpha就是這個alpha上標1,下標0,都可以。
link |
那如果這個match function裡面有參數的話,那這個match function裡面的參數會跟network的其他部分一起學出來,懂嗎?
link |
你只要給這個networkinput跟output,那match這個function裡面就算有參數也沒有關係,
link |
它會跟其network的其他部分一起,就你的0一起學出來。
link |
好,那現在呢,有一個z0,那用這個z0你就可以對每一個h呢,都去算一個attention的,
link |
就可以去算一個這個match的程度的分數,算一個match的分數。
link |
那所以我們就得到alpha上標1,下標0,alpha上標2,下標0,alpha上標3,下標0,alpha上標4,下標0,以此類推。
link |
那這邊呢,我們可以做一個softmax的normalization。
link |
那我們,我們實驗室曾經有同學做一個實驗,把這一步拿掉以後就performance比較好。
link |
所以你也可以把這個當作一個留言中寫者的題目,看看你怎麼做比較好。
link |
softmax呢,也不見得一定是需要的。
link |
好,那今天假設我們做了一個softmax,把它做normalization。
link |
就是讓這四個值呢,四個alpha的值合起來是1。
link |
好,那這邊normal來以後的值呢,就給它一個上標hat。
link |
好,接下來呢,我們把根據這四個值,我們可以得到一個vector c0。
link |
這個c0就是我們把這h1到h4,分別乘上這四個scalar,alpha1到alpha4,再加起來就得到這個h0。
link |
這個式子呢,就寫在右下角,把hi乘上alphai,加起來得到c0。
link |
舉例來說,如果現在a1是0.5,a2是0.5,a3是0.0,a4是0.0的話,那c0是什麼呢?
link |
c0就是0.5倍的h1加上0.5倍的h2,就得到c0。
link |
好,接下來呢,我們就是把c0呢,當作decoder的input去丟給decoder。
link |
那你可以想像說現在,如果我們的這個match的weight啊,它是在第一個位置和第二個位置是0.5,
link |
那顯然這個decoder的input它包含的information,就是跟器,跟機器有關的information。
link |
那你把它丟到這個decoder裡面,那decoder呢,可能就output一個machine。
link |
好,那這個z1呢,這個z1呢,它是把這個c0丟到rn裡面以後,那個rn的hidden layer的output。
link |
那接下來,你可以用z1呢,再去算一次這個match的分數。
link |
你可以用z1呢,再去算一次match的分數。
link |
那這個z1呢,也不一定要是rn的hidden layer的output,它還是各式各樣的東西。
link |
你也可以把這個當作一個留言終結者,比如說你可以把rn的output通過一個hidden layer才得到z1。
link |
你要怎麼做都是可以的,現在也沒有一個共認最好的做法。
link |
好,那把z1乘上h1,我們現在得到α上標1下標1,上標代表是h1在算match的分數,
link |
下標1代表說現在是用z1在算,不是c等於0,是下一個時間點的時候在算這個match的分數。
link |
一樣,得到四個match的分數,你再做一下solve math,然後再得到一個vector c1。
link |
今天假設說a1是0.0,a2是0.0,a3是0.5,a4是0.5,那c1是什麼?
link |
c1就是0.0乘h1,0.0乘h2,0.5乘h3,0.5乘h4,你就得到這個c1。
link |
所以這個c1就當作decoder下一個時間點的input,decoder下一個時間點的input包含的資訊是學跟習。
link |
可以想像說,看到了學跟習所組成的這個vector,machine可能就output learning。
link |
這個process就繼續下去,你有z2,你就可以再算一次match的分數,然後再得到c2,
link |
這個process就一直下去,直到machine generate這個句點的時候才停止。
link |
同樣的技術也可以用在語音辨識上面,剛才machine translation是input,
link |
比如說中文的character sequence, output英文的word sequence。
link |
語音辨識你就是input聲音訊號,聲音訊號你可以用vector sequence來表示它。
link |
output是什麼?output就直接是,比如說你辨識是英文的話,它output就是英文的character sequence。
link |
舉例來說,這個是Google的paper,這是真實的例子。
link |
input一段聲音訊號,你可以把這個想成就是一排vector sequence,每一個時間點大概0.01秒的時間用一個vector來表示。
link |
接下來,今天machine一開始,它先算一次match score,它會對這邊的這整排vector都算match score,
link |
然後發現說這個地方的match score特別高,就代表說machine現在要產生下一個character的時候,
link |
這個地方match score特別高,你把它丟到decoder裡面,machine就output一個h,
link |
然後再算一次match score,發現在這個地方分數特別高,就得到一個o,再算一次match score就得到w。
link |
它不只會產生字母a到z,它還會自動產生空白,該產生空白的時候,它就產生空白。
link |
接下來,它再產生n,然後就會decode出,它就會辨識出一整句話。
link |
這句話其實是how much wood would you chop chop這樣子。
link |
這個WER就是word error rate,它只是越小越好。
link |
上面這個DNNHAN是傳統的方法,可以得到word error rate,在一個clean跟noise的情況下,error rate是8.0跟8.9。
link |
上面這個方法就是這邊的LAS的方法。
link |
這個LAS的方法呢,這個paper的開頭是listen, attempt and spell。
link |
如果有attention的paper的話,你就要用三個動詞當作paper的開頭,這樣才會吵。
link |
它縮寫的就是LAS,LAS做出來是14.0跟16.5。
link |
然後有做一些rescoring,這個我們就不要解釋這是什麼好了,有得到一些稍微好一點,但是都輸給傳統的方法就是了。
link |
其實這個方法到目前為止,我還沒有看過有人做出說你可以真的贏過傳統,用這個sequence to sequence的方法,用這個方法硬做可以贏過傳統方法的結果。
link |
但是這個方法它仍然是非常有價值,非常驚人。
link |
我覺得這個方法它厲害的地方就是,你看可以這麼做,結果沒有爛掉。
link |
因為你看傳統方法你都會需要考慮比如說lexicon等等human knowledge,在這個方法裡面完全沒有用到human knowledge,需要的就只有語音跟它對應的英文字母。
link |
這邊是如果你要做image的caption,你怎麼加上剛才說的這個attention based model呢?
link |
如果image你只有用一個vector來描述它,你沒有辦法做attention based model。
link |
但是你可以用一排一組vector來描述image,怎麼用一組vector來描述image呢?
link |
如果你今天取的是CMN大家都已經熟了,如果你是把CMN的fully connected layer的hidden layer取出來,那一張image只有一個vector。
link |
但是如果你把每一個region的filter的output取出來,那你得到的就是一排的。
link |
就是如果你把CMN做flatten之前的vector取出來的話,做flatten之前的filter output取出來的話,那就是每一個region會被一個vector來表示。
link |
在這個例子裡面我們假設這張image是用六個vector來表示。
link |
那如果現在input一個z0,那你就先用z0去對每一個vector算個match score,那假設這個z0跟左上角的region算算match score是0.7,然後跟第二個算算0.1,0.1,0.1,0,0這樣子。
link |
然後你就把這六個vector做weighted sum,得到紅色這個vector,然後再把這個紅色的vector丟進去Rn的decoder,那就產生第一個word。
link |
然後接下來你再把z1去跟這六個region再算一次similarity,得到另外一組similarity,再做weighted sum得到另外一組weighted,再把它丟到Rn的decoder,就產生第二個word。
link |
你看這篇paper也是show,attach,tell,這樣子。
link |
就是如果你要寫attachment paper,一定要開頭用三個動詞。
link |
然後這個結果是這樣,這個圖怎麼看呢?
link |
下面這個是machine看到圖片以後產生的attachment,
link |
右邊這個圖呢,亮的地方就是machine在產生這個畫底線的詞彙的時候,畫底線這個word的時候,它attach的位置。
link |
所以看到這張image,machine說,a woman is throwing a frisbee in a park.
link |
所以在frisbee,在飛盤這個地方,當要產生飛盤這個詞彙的時候,machine就attach在飛盤這個地方。
link |
這邊,a dog is怎樣怎樣怎樣,machine要產生dog這個詞彙的時候,它是attach在dog這個地方才產生詞彙。
link |
它要產生stop的時候,它是attach在stop sign上面,它才產生stop。
link |
或者是說,它attach在people上產生people。
link |
這個,你看它說,a giraffe standing in a forest with trees in the background.
link |
雖然說這圖裡面有一支場景錄,但它在產生tree這個詞彙的時候,你看,attachment的位置是正好避開場景錄,
link |
是attach在森林的地方,所以它才說出了tree這個詞彙。
link |
那也有一些generate caption,generate失敗的例子。
link |
但是這些失敗的例子,從attachment裡面,你還是可以了解,為什麼machine會產生這樣子的結果。
link |
然後我的電腦卡住了,沒有卡,又跑了。
link |
好,那比如說,這個第一張圖,它說,a large white bird standing in a forest,然後鳥在哪裡?
link |
你看,attachment的地方,machineattach在這個地方,所以它說是一隻鳥。
link |
所以它覺得說,這個看起來像是一隻鳥,這是兩個翅膀,這是鳥的腳。
link |
或者說,a woman holding a clock,clock在哪裡呢?
link |
這個clock是在這個人的衣服上面,在這個人的衣服上面。
link |
或者是machine這邊說,它看到一個skateboard,skateboard是什麼呢?
link |
它覺得這個小提琴是一個skateboard。
link |
或者它說,它看到一個surfboard,它是把這個帆船的帆呢,看成這個surfboard。
link |
或者說,它看到pizza,這個東西是,其實你遠遠看,我想你大概也不知道它是什麼啦,所以machinegenerate,你八成也覺得是pizza。
link |
然後它說,a man is holding a cell phone,它說有一個人拿著一個手機,它覺得這個人手上的,其實在你那個距離你也看不出來它是什麼啦,它覺得這個是一個比較大的手機。
link |
所以你看,machine雖然說它generate caption是錯的,但是從attachment裡面你可以了解說,從它產生這個指揮focus的位置你可以知道說,它為什麼會犯這些錯。
link |
那不只可以從一個image裡面產生一段說明,也可以從一段影片裡面產生一個說明。
link |
舉例來說,你給machine看這段影片,那machine正確答案是,a man and a woman ride a motorcycle。
link |
那machine產生的是,這個是文獻上的結果,a man and a woman are talking on the road。
link |
那你從attachment裡面其實可以看到一些東西,比如說,當machine要產生man這個指揮的時候,它focus在這個地方跟這個地方。
link |
一個video就是由一串的frame所組成的嘛,一串的image所組成。
link |
所以machine要產生man的時候,它先看這個地方跟看這個地方,它都有人。
link |
而且a woman的時候呢,它就看這個地方,這個地方,這個地方,而且a road的時候呢,它是看到這個地方,所以它說了road。
link |
我們看這個例子,這個例子是說,a woman is frying food,那machine說,someone is frying a fish in a pot。
link |
那它的attachment是這個樣子,那machine看到這個圖的時候,它說,有相關。它看到這個圖的時候,它說,是在炸東西。
link |
然後它看到這個圖的時候,它說,它看到了一個塔。
link |
那其實我們作業二呢,就是要做這個東西啦,看看你能不能夠做跟這個例子一樣好。
link |
那其實呢,你知道說,這個結果的好壞呢,其實是主觀的。比如說你看下面這個例子,正確解答是a woman is frying food。
link |
那我覺得下面這個句子搞不好還比較好一點啊,如果說這個真的是個魚的話,那它有可能不是魚啊,如果不是魚就錯了。
link |
但是如果這個是魚的話,那我覺得下面這個句子,generator,machine產生的句子其實是比較好的啊。
link |
所以說你其實在這種caption generation test裡面,你很難找到一個公平的評比。
link |
所以我們在作業二裡面呢,會有同學互評,等一下助教會講一下細節。
link |
好,我們接下來講memory network跟rotary machine。
link |
那它們呢,是在memory上面做attention。
link |
那這邊我們可以稍微講得快一點,然後等一下花多一點時間呢,再講generate一個sentence的tip。
link |
好,memory network是什麼意思呢?memory network最常被用在,它最開始的應用是被用在reading comprehension上面,也就是給machine看一個document,然後你問它問題,看它能不能夠generate一個答案。
link |
好,那所以你的狀況就是這樣,有一個文章,然後有一個問題,然後要generate一個答案。
link |
那文章裡面,文章就是一個,就是有很多句子所組成的,文章裡面每一個句子呢,我們都用一個vector來描述它,那假設有n個句子,就是x1到xn。
link |
那這個句子,這個文章怎麼描述成句子,你可以就是用paragraph vector把它認出來,等等,或是用back of word來表示一個句子。
link |
好,那input的query呢,也被用一個vector來描述它,接下來呢,就把用這個q呢,去對每一個document裡面的句子呢,去算它們的max score,來得到α1到αn。
link |
接下來呢,你把α1和αn對x1和xn做weight sum,你把α1到αn對xn做weight sum,這個意思就是,你把query input進來的時候,你根據這個query的內容,從這個document裡面去選有關係的內容。
link |
就好像把這個document裡面和query相關的部分呢,抽出來。接下來呢,你把query和這個相關的部分都丟到dll裡面,最後呢,你就得到你的答案,輸出你的答案。
link |
那這整個network呢,它是可以救你的一拳,包括你怎麼把document裡面的sentence變成一個vector,這件事其實你也可以跟network的其他部分一起訓練出來。
link |
那memory network呢,有一個更複雜的版本,這個版本是這樣的,算match的部分跟抽information的部分,不見得需要是一樣的。
link |
如果它們是不一樣的,其實你會得到更好的performance。所以你可以把document裡面的同一個句子變成兩組不同的vector。
link |
你只要有兩組不同的參數,你就可以把同一個句子變成兩個不同的vector。你可以想像說,現在首先document裡面的每一個句子你都用一個backward來表示,它是一個high dimensional的vector。
link |
接下來把那個high dimensional的vector,從乘上一個matrix變成x,乘上另外一個matrix變成h,而這兩個不同的matrix它都可以是自動學出來的。
link |
好,那現在有兩組vector,那這個query對x這組vector算attention,但是它是用h來表示每一個句子的information。
link |
你就把這些attention乘上這些h,得到extract出來的information。那這個部分,就怎麼產生這兩組vector,它是可以跟network的其他部分一起join的理論出來。
link |
接下來,這個vector你當然可以丟到document裡面去產生你的答案,但是你可以把這個vector丟給q,你可以把這個vector跟q加在一起,得到一個新的q,然後再重新去算match,再重新extract information。
link |
這邊可以跑好幾個循環,這件事情叫做hopping,就好像是machine在反覆的思考一下,那你輸入一個query,machine得到一個答案,接下來它覺得得到答案以後再想想看對不對,然後再重新得到一個答案,然後再想想看對不對,反覆的思考,最後會得到更正確的結果。
link |
剛才那件事情,就是那個hopping那件事情,如果你沒有辦法想清楚的話,這邊用另外一個圖示的方法來講hopping這件事。
link |
首先,一篇document用兩組vector來表示它,現在有一個query,q進來,它用綠色的vector算出attention,跟用橙色的vector去抽information,接下來你把抽出來的information跟qsummation起來,
link |
接下來這個document會在,其實這邊這組藍色的vector跟這組藍色的vector,它們可以是一樣的也可以是不一樣的,就depend你今天要認多少參數。
link |
你可以這四個embedding都是不一樣的matrix,你也可以說這兩組,第一組跟第三組的embedding是一樣,第二組跟第四組的embedding的matrix是一樣,這個就depend你要怎麼設計都可以。
link |
好,那現在把check出來的information跟q加起來,然後再去算一次attention,再check一次information,再把它跟這個地方的output再加起來,丟到em裡面,得到最後的答案。
link |
好,所以這整件事情你就可以把它看成是一個,好像是一個兩個layer的network,那這個answer的地方你是有training data的,所以到時候在train的時候你就可以一路backpropagate回來,一路backpropagate回來,你就可以train這個network裡面所有的參數。
link |
那它其實是可以更複雜的,舉例來說,我們剛才在前一堂課講的tree structure的LSTM,可以跟attention這件事放在同一個model裡面,是就你的理論,這個部分比較複雜,也許我們就把這個部分挑過。
link |
好,那另外一個要講的是neural tree machine,剛才講的memory network,它是在memory上面去做attention,然後從memory裡面把information取出來。
link |
neural tree machine不只是從memory裡面share出information,它還可以根據你的那些match score去修改存在memory裡面的內容,也就是說你不只是從memory裡面讀information,你還可以把information寫到memory裡面去,然後在之後的timestamp再把它讀出來。
link |
這邊這兩句話就是我剛才講的,neural tree machine不只是讀memory,還可以改memory的內容。
link |
怎麼做呢?首先,你有一組memory,這個memory就是一個vector sequence,然後接下來你會有一組attention的weight,你會有一組初始的attention的weight。
link |
根據這種初始的attention的weight,還有這個memory的vector,你可以extract出一個information,你就把這些vector跟這些alpha的值做weighted sum,就得到一個vector R0,然後把這個R0丟給另外一個network。
link |
這個network它就是一個controller,這個controller其實就是一個function,這個function要用什麼東西來表示都是可以的,你可以說它是一個DMN,你可以說它是一個LSDF,你可以說它是一個GRU,都是可以的,你可以任意設計這個function。
link |
你把R丟進去以後,再加上第一個時間點的input,這個controller會output幾個vector,這些vector要做的事情就是去操控這些memory,它會去決定說新的attention長什麼樣子,它會去決定說新的memory,memory裡面接下來要存的值要如何做修改。
link |
怎麼產生attention呢?這個K,這個K上標1,它的作用就是來產生attention,你把這個K跟這邊M1到M4做cosine similarity,你就得到四個match的score,然後接下來再做softmax,你就得到新的attention的distribution。
link |
其實這是一個簡化的,簡化再簡化的版本,真正的neuroturing machine,它從K加memory產生這個attention的步驟,其實有五個步驟,它長得是這個樣子的,我相信你一定沒有興趣知道它,所以就把它跳過。
link |
接下來我們產生這個attention以後,根據這個attention還有另外兩個vector,E1跟E2,就會去修改memory的值。
link |
E1的作用是要把原來memory裡面的值清空,A1的作用是要把新的值寫到memory裡面去。
link |
怎麼做呢?現在如果有,我們就把這四個vector裡面的其中一個mI拿出來,把這個mI減掉attention的weight,如果它是m2的話,你就把它減掉這個alpha2的值,乘上E1的這個vector跟mI做analyze相乘的結果。
link |
而這個符號代表analyze的相乘。這樣做有什麼意思呢?首先你先看這個attention的distribution,你先看這個distribution,如果某一個memory的vector它被attended比較多,那之後E1跟A就會去專注於修改那個位置。
link |
通常這個attention的distribution會非常非常sharp,就是那個neural tree machine的設計就是會讓某一個dimension特別sharp,所以某一維能很接近E,其他都接近E。
link |
所以這個E跟AR其實是通常只會主要去更動某一個vector的值而已,所以假設現在alpha2這個alpha2很大,那alpha2很大的話,那erase這個E這個vector它的作用是erase是清空的意思,它會對這個mI有特別大的影響。
link |
那這個E的每一個dimension的output都是介於0到1之間,所以你可以想像說,假設這個alphaI是E,假設這個EI的每一個dimension是E,那你就是把mI直接減mI,就是把memory裡面原來的值format掉。
link |
然後你可以加上新的值,把A1的值加進來,得到下一個時間點的同一個位置的memory,所以就把這四個vector通過這個轉換以後變成另外四個vector。
link |
接下來,根據這個distribution,根據這四個vector,你又得到新的一個vectorR1,然後再加上新的輸入x2,你就可以得到,輸入這個function,你就可以得到新的output。
link |
這個新的output會去再操控這個distribution跟這個matrix,然後就可以產生下一個時間點的distribution跟下一個時間點存在memory的值。
link |
那這個f,它可以是recurrent level,如果它是recurrent level的話會怎樣呢?
link |
就是前一個時間點的f,它不只會output那些control memory的那些vector,它還會output另外一個vectorh1,代表這個controller自己的記憶,再把這個h1丟到f裡面去。
link |
然後產生在下一個時間點操控這些memory的參數。
link |
好,那我們就很快的講過neural turing machine,接下來要講training,如果你今天要產生一個句子的時候,有哪些技巧,以示在你的作業中是用得上。
link |
好,那舉例來說,現在假如我們要做video的caption generation,給你的machine看一段這樣子的video。
link |
那如果你今天用的是attention-based model的話,那machine在每一個時間點會給這個video裡面的每一個frame,也就是每一張image,一個attention。
link |
那我們用alpha上標i,下標t來代表一個attention,上標代表說是第i的controller,下標t代表說是這段video裡面的第幾個frame。
link |
所以一開始,你會在第一個時間點,你會對1,2,3,4,假設這個video很短只有4個frame,這4個frame你都產生一個attention。
link |
然後你就產生word1,然後同樣的process就反覆繼續下去,第二個時間點,每個video都有一個attention,產生word2,第三個時間點,每個video都有一個attention,產生word3,第四個時間點,每個video都有一個attention,產生第四個word。
link |
那你要注意一下,其實你可以給attention設regulation,你可以強迫你的attention長的是你喜歡的樣子,因為有時候有一些attention是不好的attention,什麼樣的attention是不好的attention呢?
link |
舉例來說,我們舉個例子,假設你現在的attention的分佈長的是這個樣子,也就是說,多數的時候,你的attention都只focus在第二個frame上面,尤其是在產生第二個word的時候,它主要是focus在第二個frame上面。
link |
它看到一個人,所以它看到一個女人,所以它說woman,可是接下來在第四個時間點產生第四個word的時候,它又再次focus在第二個frame上面,它又再看到一次woman,所以它又說一次woman。
link |
所以這個句子可能就會變成說什麼,a woman and a woman在怎樣怎樣怎樣,所以其實到時候你自己做一下video conferencing generation的時候,你會發現說這種情況還蠻常發生的,你才會產生那種怪怪的句子,就a woman and a woman is doing a woman之類的。
link |
這個時候它就是因為它attention在同一個地方好幾次,而且它都沒看到cooking,因為它都attention在這個frame上,它沒有attention在別的frame上,所以它沒看到cooking這件事,所以整個句子產生的句子就很差。
link |
一個好的attention,它應該要cover input的各個frame,你至少要把input的每一個frame都有稍微有attent一下,而且每一個frame這個attent的量又不要太多,最好input的video每一個frame,它們的attention的量是同等級的,是差不多的。
link |
那你怎麼知道這件事呢?其實有很多不同的做法,我這邊只是舉一個最簡單的例子,這個是ICML15的paper,在這個例子裡面,我們在這個例子裡面希望說每一個frame,它在整個generation process的過程中,所有attention weight的累加就有接近一個值,這個值叫做tau。
link |
這個tau這個值就是一個參數,就像learning rate或regulation的weight一樣的參數,這個你要自己tune它。
link |
所以這邊希望做到的事情就是summation over對某一個component i,比如說對第二個frame,summation over整個generation process,那個是我得到的attention。如果你這樣做,你就會發現說,第二個frame它的summation值很大,134的summation值很小,這樣子你就會得到比較大的loss。
link |
因為你會把tau這個值減掉每一個frame在整個process裡面得到的attention的總和,然後看說它們跟tau的差距有多大,那這個case可能跟tau的差距很大,這三個case也可能跟tau的差距很大。
link |
那你的machine就會學到說,為了要讓這個regulation的tau的loss變小,它就會把一些attention分散到其他的frame上,這樣你就可以得到比較好的結果。
link |
當然你永遠可以設計自己的attention的regulation,看看怎麼做可以把它做得更好。
link |
好,那另外一個我們要講的是,你可能覺得generate一個sentence聽起來很簡單就沒有什麼,但是其實裡面有很多枝枝節節的trick,而是你自己如果文獻很快,你過去的時候你不會注意到的。
link |
你有沒有發現說,其實在training跟testing的時候是有一個mismatch? 怎麼說呢?
link |
在training的時候,我們是怎麼train的? 你回想一下,這就是作業一,作業一的時候,你是怎麼train一個language model?
link |
假設我知道我有一個句子叫做ABC,那我希望說在第一個時間點,我的machine的output要跟A越接近越好。
link |
我這邊加一個粉紅色的vector,這個vector代表condition,因為我們之後要做的都是這種condition的generation,你會因不同的condition得到不同的output。
link |
我們現在假設input這個粉紅色的condition,你就要output A、B、B。
link |
那你的reference是這樣告訴你的,所以你output粉紅色的condition的時候,在第一個時間點要output A。
link |
接下來根據language model的train法,你會把你的reference拿來當作input,也就是你希望說你的model在input A跟你的condition的時候,在第二個時間點output B。
link |
然後接下來你會希望你會把B拿來當作input,也就是說你會希望你的RNN在input A、input B以後,它output在第三個時間點跟reference的B越接近越好。
link |
所以每一次你的RNN所看到的input是來自於reference,是來自於正確的解答。
link |
這樣大家有問題嗎?好,沒有。那你想想看,這邊是要講說,接下來你要做的事情就是minimize A跟這個distribution cross-entropy,
link |
minimize B跟這個distribution cross-entropy,把這些cross-entropy加起來,那你要minimize他們的total summation。
link |
想想看在generation的時候會是怎麼做。你在generation的時候,你的做法其實是這樣。
link |
我們現在把一個condition跟一個beginner sentence丟進去,然後output一個distribution。我們假設這個世界上只有兩個word,A跟B,這樣才能簡化我們的圖示。
link |
好,那顏色越深代表機率越大。它產生distribution告訴我們說B的機率比較大,所以我們去現在的output B。這邊在產生B的時候你有兩個做法。
link |
一個是看誰比較大就output誰。那這樣子你每次input同一張image,output就是同樣的caption。
link |
你可能會說,我想要讓它更flexible一點,那你這邊可以用一個sample,你可以根據這個distribution做一個sample,那你input同一個image,那你可能會每次講的caption都有一些不一樣。
link |
好,那再來第二步的時候,先output一個B,第二步問題就來。我們剛才在training的時候,在下一個時間點我們看到的input,
link |
在下一個時間點RNN看到的input其實是reference,但是在testing的時候,在generation的時候,我們沒有reference啊,
link |
就是testing data,我們並不知道我們output東西要什麼。那現在怎麼辦?現在RNN在下一個時間點,它的input是什麼?
link |
我們就只好把RNN的output,在前一個時間點的output,B呢,接過來,當作第二個時間點的input。
link |
我們剛才這邊接的是reference,但是沒有reference,沒有正確解答,只好把RNN自己的output接進來,當作下一個時間點的input。
link |
好,那現在呢,假設在接下來產生A,現在根據這個產生一個distribution,跟這個distribution,A的機率比較大,所以我們訊號會A。
link |
再把A當作下一個時間點的input,那麼需要產生新的distribution,它產生BAA這個sentence。
link |
這邊發現training跟testing的時候有一些不一致,testing的時候呢,你的input是前一個時間點model自己的output。
link |
在training,在這個training的時候,你每一個時間點的input是真正的答案。
link |
這件事情呢,叫做exposure的bias。那你可能覺得說,這件事情聽起來沒什麼大不了,那我以下下頁舉個例子告訴你說,這件事情會產生什麼樣的影響。
link |
好,上面這個case是training的時候,你直接把正確的答案接下來,下面這個case是testing的時候,你把我們訊號的output接到下一個時間點。
link |
到底有何不同呢?我們現在來看上面這個case,我們用一個樹狀圖來表示這個RNN,不知道大家能不能了解我的意思。
link |
我們有一個初始的initial的state,這個初始的initial的state,第一個時間點的state就是這邊。
link |
接下來我們可以outputA或B,如果我們這邊outputA,那你把A接進來,如果我們這邊把A接進來,我們就會得到另外一個state。
link |
如果把B接進來,就會得到另外一個state,就這邊放A跟B的時候,我們得到的heater layer的output是不一樣的。
link |
假設我這邊接的是A,我就走這一條路徑。假設我這邊接的是B,我們就走這一條路徑。
link |
當然在training的時候,我們知道reference日是ABB,所以我這邊永遠會接A。
link |
這個希望大家知道我的意思。所以machine在learn的時候,它會知道說,在第一個time step,我們希望machineoutput的是A。
link |
所以machine會知道說,在A和B之間,它要選擇A。
link |
接下來在第二個時間點,如果在training的時候,我們就會直接告訴它說,input就是A。
link |
input就是A,那就是這個case。machine會知道說,今天在input是A的這個case,我們要在A、B之間選一個,我們應該要選B。
link |
接下來,我們會在第三個時間告訴machine說,input就是B。根據reference,在training的時候,input就是B。
link |
所以machine會學到說,今天在這個case,今天在input已經看到A跟B的這個case,接下來outputA跟B之間,你要選一個的話,你要選B。
link |
所以machine會學到說,在A、B中間,你要選A。今天如果已經選了A的前提之下,在A、B中間,你要選B。
link |
今天如果已經選了A、B的前提之下,它在A、B中間,你要選B。
link |
這個是在training的時候,我們教給machine的。這樣大家有問題嗎?
link |
我們今天假設,在training的時候,你也沒有辦法得到100%的正確率,對不對?假設machine犯了一個錯,
link |
它沒有辦法學會在一開始初始的這個狀態的時候,它要選A。它會犯錯,它要選B。
link |
你可能覺得說,犯一個錯,我至少還答對了66%。
link |
但是在testing的時候,你會發現說,這樣一個錯誤,會讓你在testing的時候,你的正確不是66%。
link |
我們假設在testing的時候,我們丟的就是一個一模一樣的句子,就training跟testing的時候丟的就是一模一樣的句子,一模一樣的condition。
link |
好,那在training的時候,我們只有犯一個錯。在testing的時候,你就會發現說,我們在一開始的時候,就說machine在看到初始的state的時候,它會犯錯,它會選B。
link |
它選了B以後,所以output這邊output是B,所以它把B當作下一個時間點的input。
link |
對machine來說,它在training的時候,它從來沒有看過在第一個time state把B當作input應該是什麼case,對不對?
link |
因為它在training的時候,它從來沒有走到這裡過啊,它從來不知道說今天,它知道在這個state它要選B,這個state它從來不知道它應該選擇A還是B啊。
link |
它從來沒有在training的時候看過這個state,它從來沒有在training的時候看過這種狀況,所以它就崩潰了,所以它會亂選,它的結果就會變成你無法預期。
link |
也許它接下來選的都是A也說不定,因為它training的時候從來沒有看過這樣子的case,所以你有可能在training的時候,一模一樣的同一個example,training的時候只犯,你覺得你只有一個錯,所以你loss還蠻低的。
link |
在testing的時候,整個就壞掉了,所以你可以發現說,這個小小的training和testing的差距,有可能會造成很大的影響。
link |
下面這個呢,就是一步錯,步步錯的概念,一步錯,接下來就通通都錯。
link |
那你想說要解決這個問題好像也沒有很難,所以training的時候,這個training跟testing就是mismatch啊,所以要改一下training的process才對,改一下train法,所以我們training的時候應該是要這樣做。
link |
我們training的時候應該就是說,現在我的model如果sample出來的是A,在第一個時間點它sample出來的是B,那我們就應該把B接到當作下一個時間點的理論。
link |
原來在training的時候我們會把reference的A當作下一個時間點的理論,但我們不應該這麼做,我們應該說,machine如果output是B,就算是錯的跟reference不一樣,它也應該是下一個時間點的理論。
link |
這邊output是A,跟reference不一樣,那它也應該是下一個時間點的理論。
link |
如果你這樣train,那training跟testing就會是match的了,對不對,training跟testing都是一樣的。
link |
這樣聽起來很理想,但是事實的狀況就是,這麼train,在實作上你會有問題,你train不起來。
link |
你可以自己,你可以把這個當作一個留言終結者提供看看,你在這樣子training的時候,你有沒有辦法train起來。
link |
為什麼這樣training的時候會有問題呢?
link |
我們這邊舉個例子說明,為什麼這樣training的時候可能會很困難。
link |
你看這邊,第一個時間點的答案是A,所以歸零點會告訴我們說,machine如果你給它一個歸零點decent去做training,
link |
以今天的歸零點方向告訴你說,我們來把A調大,我們把這個機率A的機率調大。
link |
接下來在第二個時間點,machine要學到說,現在看到B當作input,看到condition,那我們應該要把這個B調大。
link |
第二個時間點的output是B,第二個時間點把A調大,在第二個時間點看到B當作input,我們要把B調大,這樣答案就對了。
link |
但是事實上麻煩的就是,當這兩件事同時發生的時候,你其實會讓你的level變得很難train。
link |
為什麼?因為想想看,今天假設你的歸零點方向告訴你說,你要讓這個A上升,要讓這個B的值上升。
link |
但是你讓這個A的值上升,你在下一個時間點,你如果讓A的值上升,那這邊level output不就變了嗎?
link |
那在下一個時間點的input就變了。也就是說,因為你的machine是學到說,在input B的時候,在第二個時間點input B的時候,它可以讓B的機率上升。
link |
但是如果在前一個時間點,A的機率上升了,那第二個時間點的input整個就不一樣了,那它之前學的讓B上升就沒有意義了,反而可能會得到奇怪的結果。
link |
就變成說,你update你的參數,你以為根據歸零點你的結果會變好,但update一次出去以後,結果反而有可能是變差的。
link |
所以導致說,如果今天你用這種方式做training,你反而不太容易train起來。
link |
所以怎麼辦呢?有一個方法叫做schedule sampling。這個schedule sampling就是說,我們用一個綜合的方法來train我們的network。
link |
什麼叫綜合的方法呢?就是說,我們現在糾結的點就是說,到底下一個時間點的input應該是從model的output來呢,還是從reference來呢?
link |
那schedule sampling的方法就是說,給它一個機率。在這邊有質疑是同版,如果同版是正面,我們就把reference當作input,如果同版是反面,就把model的output當作input。
link |
然後呢,你現在有時候是拿reference當作input,有時候是拿model當作input,然後看看下一個時間點會產生什麼。然後接下來呢,在第三個時間點,
link |
你也有兩個選擇,你可以把model的output當作下一個時間點,你可以把reference當作下一個時間點的input,但是你就用schedule sampling的方式做一個sample,
link |
決定說看是要看model的output,還是看reference。好,那如果你看一下這個schedule sampling的這個機率的設計,你就會知道它為什麼可能會work。
link |
這邊的這個機率的設計是這個樣子的。在那個paper裡面呢,它設計了幾種不同的機率啦,那我並不覺得明顯有哪一種比較好,你可以自己當作留言仲介者的題目自己試試看。
link |
好,那它的機率你會發現說都是下降,這個縱軸啊,這個縱軸指的是看那個reference,直到reference的機率,縱軸是直到reference的機率。
link |
所以一開始都是只看reference,不看model的output,然後接下來呢,接下來才慢慢的說,看reference的機率逐漸見效,看model的機率逐漸的上升。
link |
就一開始都只看reference,所以一開始的training跟原來我們說的那個mismatch的training是一模一樣。
link |
之後才把model的部分慢慢的加進來,之後才把model的部分慢慢的,之後才把model的部分慢慢的加進來。
link |
如果是這樣train的話,你就有可能得到比總是看reference更好的結果。以下是Schedule 7的那篇paper的一些原始的數據,它做的是image的caption的generation。
link |
那這邊比較了三個case,第一個就是總是看reference,也就是原來的train法。
link |
那這邊橫軸是同一個test,但是不同的evaluation的measure,就是這種evaluate一個sentence好不好用不同的evaluate的方法。
link |
那等一下助教會跟你講第一個這個blue score是什麼東西。
link |
那第二個是,假設我們永遠只從model,我們永遠用model的output當下一個timestamp,就我們之前講的一個最理想的做法。
link |
但是如同我剛才講的,這樣直接transfer不起來了,所以這個結果很差。
link |
如果我們用Schedule sampling,machine一開始都把reference當作input,等它train的穩定以後,再有時候去看一下model自己的output。
link |
通常它一開始都只看reference,之後有時候才看一下model的output,這個時候你其實是可以認得最好的。
link |
另外一個我們要講的東西是這個bin search。
link |
那bin search是這個樣子,這個tree structure我們剛才已經看過了,所以我想大家應該沒有什麼問題。
link |
我們現在假設說,在第一個timestamp,這個distribution是A的機率是,A的分數是0.6,B的機率是0.4。
link |
所以machine會選擇這個,這邊右上角這個圖我覺得我放的不太對,我應該放testing的時候的圖,那這張圖是training的時候的圖。
link |
好,那在第一個timestamp,有A跟B兩個選擇,machine說,RNN說它的output是A的機率比較大,B的機率比較小。
link |
所以你就把A當作下一個時間點的input,所以你就走到這個狀態。
link |
接下來呢,machine說B的機率比較大,所以B的分數比較大,所以machine接下來會把B當作下一個時間點的input,所以你就走到這個狀態。
link |
接下來呢,machine又說A的機率比較大,所以你又走這條路,所以你得到的機率就是0.6,0.6,0.6。
link |
你如果輸出ABB的話,它們的分數就是0.6乘0.6乘0.6。
link |
那你會發現說這其實是一個Griddy的search,對不對?
link |
如果我們今天要找這個樹狀結構上分數最高的那個path的話,用這個Griddy的方法找出來的分數不見得是最高的。
link |
因為有一個可能是這樣子,也許我們先決定走B,雖然B的分數低一點。
link |
但是如果我們走到這個state,B的分數會變得特別高,是0.9。
link |
也許我們再走這個state,B的分數變得特別高,是0.9。
link |
這個時候如果你走綠色這條路徑,先output B,把B當作下一個時間點的input走到這個state,再output B,把B當作下一個時間點的input再走這個state,你會得到一條path,它的分數是0.4乘0.9乘0.9。
link |
那這個時候,綠色這條path的分數是比粉紅色這條path的分數還要高的。
link |
所以也許綠色這條path的分數,綠色這條path,你的rnoutput BBB才是一個比較好的選擇。
link |
但是今天這個case當然是一個比較簡單的case,每一個時間點我們只有兩個選擇。
link |
但是在真正的,在你們準備要做那個task裡面,這個output是vocabulary的size,它是所有英文可能的詞彙。
link |
你每次都有一萬個分支,你是沒辦法處理這個問題的,你沒有辦法check每一條path說哪一條path的分數是最大。
link |
那怎麼辦呢?當然你可以用greedy的方法,但是用greedy的方法的話,你不見得可以得到最好的結果。
link |
所以有一個介於greedy和報收所有路徑之間的方法,叫做bin search。
link |
bin search是說,在每一個時間點,我們都只keep分數最高的某幾條path。
link |
也就是說,我們現在呢,在第一個時間點,我們可以選擇A或B,我們A、B都看。
link |
好,那接下來呢,在下一個時間點,我們變成有四個可能,你可以是A、A、A、B、B、A、B、D。
link |
那如果今天是這邊選擇一萬個的話,你現在就有一萬個平方的選擇。
link |
但是我們不要把一萬個平方的選擇都存起來,我們只選分數最高的兩條path。
link |
我們保留的分數最高的path的量呢,就是這個bin的size。
link |
那我們現在假設我們設bin的size是2,我們就check這四條路徑的分數。
link |
假設我們發現說,在這邊選A走B,然後選B走B,分數是最高的。
link |
那我們就保留這一條path跟這一條path。
link |
好,接下來就繼續走下去,接下來呢,一樣有四個選擇。
link |
你選AB以後,你有A和B這樣的選擇,你選BB以後,你有A和B這樣的選擇。
link |
那你再check說,這四條路徑,哪兩條的分數是最高的。
link |
那假設說,選AB後選B,選BB後選B,分數是最高的,那你就把這兩條路徑保留下來。
link |
那最後,假設已經走到這個樹的尾巴了,走到它的葉子了,
link |
那你就看說,哪一條剩下在你的bin裡面,你保留下來的path,
link |
哪些path的分數最高,就把那些path保留下來。
link |
好,下一張圖呢,是我在一個Github上找到的,這張圖畫得非常的好。
link |
這張圖畫得非常清楚,告訴你說,如果我們在使用pin search的時候呢,大概是怎麼樣。
link |
好,在第一個時間點,你會input一個begin of sentence的token。
link |
然後machine會output一個所有word的distribution。
link |
那現在假設說呢,世界上就是只有三個word,w、x、y,
link |
還有加上代表句尾的符號,也就是代表這個句點的這個符號。
link |
你input一個begin of sentence,然後它告訴你w、x、y和句尾的符號的機率。
link |
那我們假設今天我們的bin的size就設為3,所以每次只會保留最好的三個path。
link |
這邊有四個可能,但是我們看這四個可能裡面,哪三個分數最高。
link |
假設x、y、w分數最高的話,那下一個時間點,我們就分別丟x、y、w。
link |
就丟進,你丟x進去,會得到一個distribution。
link |
你丟y進去,會得到另外一個distribution。
link |
你丟w進去,會得到另外一個distribution。
link |
大家了解嗎?丟x、丟y、丟w是分別分開三次丟進去的。
link |
因為它們是三條不同的路徑,所以分開三次丟進去,得到三組不同的distribution。
link |
再看這三組不同的distribution裡面,哪三個path分數是最高的。
link |
你現在其實有4乘以3,就是12個path。
link |
你要看這12個path裡面,哪三個分數是最高。
link |
假設這個黃色的x跟y,還有綠色的y,它們分數是最高的。
link |
然後接下來呢,你看這邊雖然都是y,但它們是在不同的path上的y。
link |
希望你可以懂丟,你可以了解這個圖的意思。
link |
再把x跟黃色的y還有綠色的y分別都丟進去R輪,又得到三組不同的distribution。
link |
再看這三組不同的distribution裡面的12個選擇,哪三個分數最高。
link |
在下一個時間點發現,黃色的x、紅色的x跟綠色的x分數最高。
link |
你就這樣一路做下去,每次都保留三個path。
link |
走到底的時候,走到decode的結尾的時候,你還是只有三個path。
link |
就測哪一個path的分數最高,就哪一個分數最高的path倒出來。
link |
等一下助教其實會有一個更詳細的解釋這件事情。
link |
如果你現在聽不懂的話,也許助教等一下做的demo可以給你一些啟發。
link |
接下來有一個題目,也許也是一個可以作為留言終結者的題目。
link |
你有沒有想過,為什麼這邊要丟sample的字?
link |
為什麼不直接丟這個distribution當作下一個時間點的input呢?
link |
如果直接丟distribution當作下一個時間點的input,感覺有很多的好處。
link |
第一個好處是,假設我們考慮testing的時候,
link |
因為你這邊可以選擇拿b當作input,可以選擇拿a當作input,
link |
那就會變成你有bin search的problem,對不對?
link |
你會有bin search的problem是因為你有不同的選擇。
link |
今天我們就一次把整個distribution丟進去,
link |
我們就不用管說有很多條path這件事了。
link |
所以在decode的時候你就每次都把distribution丟進去,
link |
然後得到output,你就不用做bin search這件事情。
link |
在training的時候感覺有另外一個好處。
link |
在training的時候,這個model可以end-to-end train,
link |
所謂的可以end-to-end train的意思是說,
link |
因為我們把這個network這邊的output接到這裡,
link |
所以在做bin publication的時候,
link |
因為我們是直接把network的output接到下一個時間點的input。
link |
這個distribution並不是它,
link |
這個b是從這個distribution sample出來的沒錯,
link |
但是sample這件事情,你沒辦法做gradient descent,
link |
你沒有辦法把它放到整個微分的式子裡面去,
link |
所以你的那個gradient並不會從這裡通過sample這條path,
link |
然後影響這個distribution,並不會。
link |
你覺得我有說服你這個結果會比較好嗎?
link |
好,那你覺得還是左邊這樣有sample的方法比較好,
link |
你覺得右邊這個比較好的,舉手給大家。
link |
雖然右邊的我剛才講了幾個理由會比較好,
link |
那我舉個例子來說明為什麼我覺得右邊的結果會有問題。
link |
你想想看這樣子,假設我們現在吹個圈吧,
link |
那Machine說我高興的想笑或難過的想哭。
link |
那Machine比如說會難過或高興,
link |
好,那Machine回答,不管是回答高興想笑,
link |
它不能拗個高興想哭,或者是難過想笑,
link |
你Input,因為你現在在第一個Word,
link |
你在Input Begin of Sentence的時候,
link |
這個Distribution,它其實應該是很Flat的。
link |
但是拗過跟難過的Distribution,
link |
那就把高興接到下一個時間點當作一個。
link |
我們去看到說現在的Input是高興,
link |
這個時候想笑的機率就會遠比想哭還要高。
link |
因為現在高興跟難過的機率幾乎是一樣的,
link |
所以這個Distribution高興跟難過的機率幾乎是一樣的,
link |
那你把高興跟難過的機率幾乎是一樣的這個Case
link |
那A跟B是想笑跟想哭的機率可能也是很接近的。
link |
所以今天如果說第一個Distribution是高興跟難過的機率很接近,
link |
那你丟到這個Distribution想笑跟想哭的機率是很接近的,
link |
你一不小心就有可能會產生高興想哭難過想笑的這樣的句子。
link |
接下來最後我們要講的是Object Level和Component Level的問題。
link |
那等下我們講完就直接主要就來講作業了。
link |
那Object Level跟Component Level是講什麼的?
link |
我們現在要Generate的是一整個Sentence,
link |
所以我們在考量說Generate的結果好不好的時候,
link |
舉例來說,看到這張圖你應該說有一個狗,
link |
你就是用Cross Entropy,
link |
你就算每一個詞彙的Cross Entropy,
link |
好,那現在假設縱軸就是你的Cross Entropy,
link |
所有的Time Step的Cross Entropy的總和,
link |
舉例來說,如果你今天你的Model Output是有一個Cat,
link |
Output的Dog is isFat,
link |
但是這個句子跟Ground Truth比起來,
link |
變成The Dog is running fast,
link |
你要Minimize的對象是Cross Entropy,
link |
是每一個詞彙的Cross Entropy的總和的話,
link |
在Testing Setup好一下,
link |
它的Generate出來的句子還沒有很好,
link |
那是因為我們今天在Training的時候,
link |
是每一個word的Cross Entropy。
link |
如果我們換一個Evaluation的Measure,
link |
如果我們今天的Evaluation,
link |
是對整個Sentence的好壞來做Evaluate,
link |
對整個SentenceEvaluate的,
link |
現在其實還沒有一個很好的EvaluationMeasure,
link |
一個SentenceGenerate出來的是,
link |
有一些EvaluationMeasure,
link |
但那EvaluationMeasure並不是Perfect,
link |
但我們假設有這樣子的一個EvaluationMeasure,
link |
我們假設有一個EvaluationMeasure叫做R,
link |
Yhat代表是你的MachineGenerate出來的句子,
link |
Yhat代表是GroundTruth,
link |
這個Up to Level criterion的話,
link |
我們先假設這個Up to Level criterion R是存在,
link |
但是如果你用這個R當作你的Loss Function,
link |
現在Y跟GroundTruth Yhat,
link |
它跟Y跟GroundTruth Yhat比起來,
link |
你覺得這可以做Gradient Descent嗎?
link |
今天你的Model的Output其實是Discrete,
link |
也就是說你今天調整了一下你的Model的參數,
link |
你微幅的調整一下你Ratio的參數,
link |
但是你得到的機率最大的Word是不會變的,
link |
告訴你說它的Distribution是這樣子的,
link |
但是你從這個Distribution裡面,
link |
你如果用這樣的EvaluationMeasure,
link |
你改變了這個Distribution的時候,
link |
CrossEntropy的值算出來那個Loss就變了,
link |
你可以做,用CrossEntropy可以做為分,
link |
用Reinforcement Learning的方法,
link |
來Change Generator,
link |
我們會講Reinforcement Learning,
link |
如果你拿Reinforcement Learning,
link |
就是你的操控器的搖板上面有幾個按鈕,
link |
當作是Reinforcement Learning來做,
link |
不是會Input一個Conditional,
link |
Method of Begin of Sentence嗎?
link |
每一個Word就當作是一個Action,
link |
就是你的可以選擇的Action Set,
link |
那在Reinforcement Learning裡面,
link |
你就會看到不一樣的Observation,
link |
所以現在Machine Take一個Action B,
link |
那它現在在下一個時間點的Input,
link |
它看到的Observation就不一樣,
link |
它看到Observation就不一樣,
link |
你之前Generate第一個Word的時候,
link |
所以Generate第二個Word的時候,
link |
假設你把整個句子都Generate完了,
link |
假設Generate出來的句子就是BAA,
link |
然後就把那個BAA跟Reference,
link |
Object Level的Function R,
link |
去算BAA跟Reference之間的,
link |
只有最後一個Action會給你Reward,
link |
在GenerateSentence的過程中,
link |
直到整個Sentence被Generate完的時候,
link |
你會把你Generate出來的Sentence,
link |
就是這整個Reinforcement Learning,
link |
這整個Interaction Process的Reward,
link |
Reinforcement Learning會去做的事情,
link |
不就是要Maximize Reward嗎?
link |
Reinforcement Learning會做的事情就是,
link |
調整你的參數去Maximize Reward,
link |
所以現在如果把這整個Problem,
link |
Formulate成一個Reinforcement Learning的問題,
link |
你就可以調整這個Decoder的參數,
link |
這個句子是Maximize Reward,
link |
Object Level的Criterion,
link |
所以你就可以去Maximize一個,
link |
你訂好的Object Level的Criterion,
link |
這個DAD就是Schedule Sampling,
link |
Mixer就是Reinforcement Learning,
link |
其實它並沒有完全用Reinforcement Learning,
link |
它是用Reinforcement Learning加傳統的方法,
link |
不過這個細節就大家自己在選擇Paper就好,
link |
Machine Translation,
link |
用Sequence to Sequence的方法解它,
link |
你再做一個Translate Model的方法,
link |
它們的Performance的差異,
link |
Schedule Sampling在這兩個Task有比較好,
link |
大家就自己Check一下Paper,
link |
紅色這個方法其實就很像是我剛才講的,
link |
你看,就Reforcement Learning,
link |
這個是Machine Translation,
link |
這個是Image Caption Generation,
link |
橫坐標是那個Bin Width的Size,
link |
我們剛才不是都講Bin Width嗎?
link |
顯然Performance通常是越好,
link |
不過在Caption Generation的幫助好像有點小,
link |
Schedule Sampling在這兩個Case,
link |
這個黑色這條線是Reforcement Learning的方法,
link |
會發現說Reforcement Learning的方法,
link |
Performance是會比其他方法好的,
link |
這個Case如果你做Schedule Sampling的話,
link |
可以贏過Reforcement Learning,
link |
那Reforcement Learning可以,
link |
你在Decode的時候也可以開Bin Width,
link |
黑色這條線是沒有開Bin Width,
link |
那你也可以開Bin Width等於十,
link |
那Performance又會再好一點,