back to index
Batch Normalization
link |
講一下Batch Normalization,這個Batch Normalization是一個非常新的方法,這個paper是在15年的時候publish,雖然它15年才publish,但是它的citation我看已經超過1500次了,
link |
它是現在在deep learning的training裡面,其實已經是一個非常difficult常常被使用的技術。記得說這個15年第一次教deep learning的時候,even沒有include Batch Normalization,因為那時候根本沒有這個技術。
link |
但現在有這個技術,所以我們應該要來講一下Batch Normalization。那什麼是Batch Normalization呢?我們先從feature的scaling,或者是又叫做feature的normalization,或者是叫做feature的centralization說起。
link |
那不管你是不是做deep learning的方法,其實你都會想要做feature scaling,為什麼呢?今天往往你input的feature每一個dimension它會有不同的scale,你現在train一個model,這個model是不是deep都無所謂,
link |
它input有x1跟x2,x1乘上w1,x2乘上w2,加上bias B,得到A。如果是一個shallow的model,這個A可能就是model最終的output,如果是一個deep的model,A會是其他neuron的input。
link |
好,現在假設這兩個dimension,x1跟x2,它們的scale差距很大,比如說x1的值都是1,2,x2的值都是100,200這樣的scale,這樣會發生什麼事?這樣如果你把w1和w2,也就是對應到x1和x2的那兩個參數,w1和w2拿出來看的話,
link |
你把w1和w2對應到loss的關係拿出來做圖,你看起來會像是這個樣子。因為x1它的值很小,x2它的值很大。
link |
那麼今天如果假設x1和x2它是一樣重要的題材,它們的結果的影響力是一樣的,這意味著什麼?這意味著這個w1的scale會比較大,或者是你可以換一個角度來看,因為x1的數值比較小。
link |
所以今天w1和w2如果它們有一個同等的變化的話,因為w1前面乘的值比較小,所以它對output的結果的影響小,w2它前面乘的值比較大,所以它對output的結果的影響比較大。
link |
所以你把w1和w2對loss拿來做圖的話,你會發現說,在w1這個方向上的變化,它的斜率是比較小的,它的gradient是比較小的,因為w1對結果的影響是比較小的,而w2對結果的影響是比較大。
link |
如果我們今天把feature做scale,把不同的feature讓它們有同樣的range,比如說你把x2的值通通除上100,你讓x1和x2有同樣的range,那你的這個arrow surface對w1和w2來看,它就會比較接近正圓形。
link |
那變成橢圓形或變成正圓形有什麼樣的不同呢?如果你今天你的這個arrow surface上面,你的gradient的變化是非常大,你的gradient在橫的這個方向上和縱的方向上變化非常大,這會讓你的training變得比較不容易,
link |
因為不同的方向上你要給它非常不一樣的learning rate,你要在橫的方向上給比較大的learning rate,縱的方向上給比較小的learning rate,那你要給不同的參數不同的learning rate,這件事情當然是有辦法的,但不見得那麼好做。
link |
如果你今天可以把不同的feature做normalization,讓你的這個arrow surface看起來比較接近正圓的話,這會讓你的training容易得多。那這個不管你是不是deep learning的方法,你都會用到feature scaling這個技術。
link |
那通常typical的feature scaling的方法是怎麼做的呢?現在給你一大堆的data,你的training data總共有大R比data,接下來你就對每一個dimension去計算那個dimension的mean跟那個dimension的standard deviation。
link |
假設你這個input是39維,比如說來作業1,而input是NLCC,所以是39維,所以你就算出39個mean跟39個standard deviation。然後對每一維中的數值,假設你取第i維中的某一個數值出來,你就把它減掉第i維的mean,除掉第i維的standard deviation。
link |
就做了一個normalization,你就會讓第i維的feature它的分布,mean是0,variance是1。那in general如果你今天做了這個feature scaling這件事情,往往會讓你的training變得比較快速。
link |
剛才都是還沒有講到deep learning,現在我們進入deep learning的部分。我們知道說在deep learning裡面它的賣點就是有很多個layer,你有一個X1進來,通過一個layer你得到A1,把A1當作layer2的input得到輸出A2。
link |
那我們當然會對layer1輸入的featureX做feature scaling,但是你仔細想想,從layer2的角度來看,其實它的input的feature是A1。我們可以把layer1的前幾個layer想成是一個feature的detractor,我們知道說layer1的前幾個layer的工作其實就是在抽比較好的feature,讓後面幾個layer當作classifier可以做得更好。
link |
所以對layer2來說,它吃到的feature就是layer1的outputA1。如果我們覺得說feature scaling是有幫助的,那我們也應該對layer2的feature,也就是layer1的outputA1做feature scaling。
link |
同理,layer2的輸出A2,它是下一個layer,layer3的輸入,它是下一個layer的feature,那我們應該要做一下normalization,讓接下來的layer可以run得更好。其實對每一個layer做normalization這件事情,在deep learning上面是很有幫助的。
link |
因為它解決了一個叫做internal covariance shift的問題,它可以讓internal covariance shift這個問題比較輕微一點。
link |
Internal covariance shift這個問題是什麼意思呢?它是說,你就想成說,現在每一個人代表一個layer,然後他們中間是用話筒連在一起。今天,當要當一個人手上的兩邊話筒被接在一起的時候,整個network的傳輸才會順利,才會得到好的performance。
link |
你會發現說,如果我們看中間這個人的話,他左手邊的話筒比較高,他的右手邊的話筒比較低。這個時候他就會學到說,比如說他左手邊的人就告訴他說,你把話筒放低一點,而右手邊的人告訴他說,你把話筒拉高一點。
link |
所以他就把左手邊的話筒放低,右手邊的話筒放高,結果這樣。那會造成什麼樣的現象呢?結果他有可能移動太多,結果變成這樣。那這樣子就跟原來是沒有辦法做得比較好。
link |
本來右手邊的話筒要升高,是在左手邊的話筒是在這個位置的前提下要升高,左手邊的話筒要下降,是在右手邊的話筒是在這個位置的前提下應該要下降。但是問題是,當兩個都變的時候就糟了,結果反而壞掉。如果只變一個還好,兩個都變,結果壞掉。
link |
那為了解決這個問題怎麼辦呢?在過去一個傳統的方法是,learning rate設小一點。你今天之所以會移動這麼多就是learning rate設太大,learning rate設小一點。但learning rate設小一點的問題是,就是training很慢嘛,你就不想要learning rate設小一點,所以怎麼辦?
link |
我們等一下講這個batch normalization,也就是對每一個layer做feature scaling這件事情,就可以來處理internal covariance shift這個問題。為什麼呢?
link |
因為如果我們今天把每一個layer的feature都做normalization,我們把每一個layer的feature的output,每一個layer的output都做normalization,讓它們永遠都是,比如說,missing variance之一。
link |
那對下一個layer來看,前一個layer的statistic就會是固定的,那它的training可能就會更容易一點。這可能可以讓大家,大家可以比較一下,大家記不記得之前在講那個RNN的decoder的時候,我們說講到schedule sampling嗎?
link |
我們說schedule sampling之所以要加RNN是因為,我們有說我們要加schedule sampling嘛,然後schedule sampling是說,我們其實有兩個選擇,一個是可以從前一個timestamp把output接進來,另外一個是可以用正確的答案。
link |
那我們有說,如果把前一個timestamp的output接進來,會不好train,因為當你後面的timestamp跟前面的timestamp學好的時候,前面的timestamp可能又變了。當一個deep level非常深的時候,其實狀況也是一樣的。
link |
當你後面的layer按照前面的layer的參數學好的時候,前面的layer就變了,對不對?因為前面的layer,它的參數也是不斷的變的。後面的layer按照前面的layer原來的參數去做調整,希望可以讓最後performance變好。
link |
但等後面的layer調整的時候,前面的layer其實也動了,而最後大家都動,結果就壞掉了。所以,今天這個normalization的一個好處就是,至少可以確保在每一個layer output的statistic是固定的。
link |
但是現在麻煩的地方是,你其實不太容易讓他們的statistic固定。這跟input的feature不一樣。input的feature它永遠是固定的,你輕易的就可以算出mean跟variance,然後就可以做normalization,對不對?
link |
但是每一個layer的output,它的mean跟variance是不斷的變化的。為什麼每一個layer的output的mean跟variance是不斷的變化的呢?因為在整個training的過程中,你的network的參數是一直變的。你network的參數一變,每一個hidden layer的output就變了。network的參數一變,hidden layer的output就變了,它的mean跟variance就變了。
link |
所以,今天在training的過程中,每一個hidden layer的output,它的mean跟variance是不斷的變化的。你沒有辦法用很簡單的方法一下子就知道它的mean跟variance,然後把它減掉、除掉。所以我們需要一個新的技術,這個技術就叫做batch normalization。
link |
講到這邊,大家有沒有問題呢?沒有的話,我們就繼續。好,在講batch normalization之前,我們講一下batch。batch其實大家都知道,但我們還是很快的複習一下。什麼是batch呢?比如說,我們今天在training的時候,我們不是只挑一個example出來train,而是會挑一把example出來train。
link |
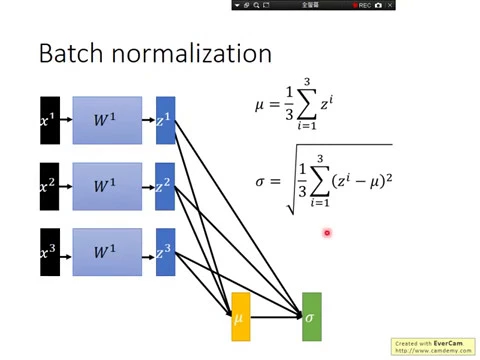
比如說,就拿x1、x2、x3三個example出來train,這個batch的size是3。我們今天實際在進行計算的時候,x1、x2、x3其實是平行計算的,它們會一起乘上w1得到,我們這邊寫z1、z2、z3,然後會通過secure function得到a1、a2、a3,再丟給下一個hidden layer。
link |
實際上,GPU在運作的時候,它會把x1、x2、x3拼在一起,把本來這三個vector排在一起變成一個matrix,把這個matrix乘上w1得到z1、z2、z3。
link |
因為今天是matrix對matrix,你如果把matrix對matrix做平行運算,可以比matrix對三個vector分開來進行運算的速度還要快,這個就是GPU加速batch運算的原理。這個batch我想大家都知道。
link |
好,今天接下來我們要做batch normalization。batch normalization怎麼做呢?我們現在想要做的事情是,對第一個hidden layer的output z1、z2、z3做normalization,我們用z來代表activation function的input,用a來代表activation function的output。
link |
其實batch normalization你可以apply在activation function的input,也可以apply在activation function的output。現在我在文獻上看到比較多的是apply在activation function的input,也就是apply在這個z上面,就是先做normalization才通過activation function。
link |
所以我們今天等一下在講的時候,我們就講先做normalization才通過activation function。你想要通過activation function再做normalization,其實也是可以的。先做normalization再通過activation function有什麼好處呢?
link |
其實是有好處的,因為你知道你的activation function,舉例來說,如果你用type of body tangent或者是sigmoid,它通常是有那個saturation的region,其實你很不喜歡你的input是落在saturation的region,因為像gradient的時候會有問題,它會有gradient vanishing的問題。
link |
你其實比較喜歡你的input是落在那個微分比較大的地方,也就是零的前後,零的附近。如果你今天先做normalization,你就比較能夠確保說在進入activation function之前,你的值是落在零的附近。
link |
好,那我們現在來做normalization,怎麼做呢?你想要先算出一個μ,先算出一個μ,先算出這些Z的μ,這個μ這個vector出來,就很簡單,Z1加Z2加Z3,除以三分之一得到μ。
link |
接下來算一下standard deviation sigma,sigma怎麼算呢?這個都是國中的機率有教,你就把Zi減掉μ取平方,然後再平均,然後再開根號,得到Z1、Z2、Z3的standard deviation。
link |
好,那接下來呢?這邊有一件事情要跟大家強調一下,就是μ是dependent on Z1、Z2、Z3的,sigma是dependent on μ跟Z1、Z2、Z3的,這個等一下會用上。
link |
好,那這邊有一件事情要注意的事情是說,在做nationalization的時候,這個μ跟σ,我們其實希望它代表的是整個training set全體的statistic,但是因為實作上統計整個training set全體的statistic是非常耗費時間的,而且不要忘了這個W1的數值是不斷的在改變的。
link |
你不能說我把整個training set被它倒出來,算個μ,然後W1值改變以後,每次update參數以後再把整個training set倒出來再算一次μ,這個是不切實際的做法。
link |
所以現在呢,我們在算這個μ跟σ的時候,只會在batch裡面算,那這意味著什麼?這意味著說你的batch size一定要夠大,你的batch size如果太小的話,nationalization performance就會很差,因為你沒有辦法從一個batch裡面估測整個data的μ跟σ。
link |
舉例來說,你可以想想很極端的case,如果今天batch size是1,你根本不能夠apply這套想法。
link |
接下來呢,我們就把Z減掉μ這個vector,然後除掉σ,這邊這個notation有點abuse,我這個除掉σ的意思是對,σ也是一個vector,它每一個dimension就代表了Z的每一個dimension的standard deviation。
link |
這個是analyze除的意思,這個大家知道我的意思就好。好,那我們做完這個normalization以後呢,就得到了Z調達。
link |
經過這個normalization以後呢,這個Z調達的每一個dimension,它的μ就會是0,它的variance就會是1,那你高階的話就把它通過simulation function得到a,然後再丟到下一個layer。
link |
那batch normalization你通常會每一個layer都做,所以每一個layer的Z,你都會在進入每一個activation function之前,你都會做這件事情。
link |
那這邊有一個其實大家可能比較不知道的事情是,有batch normalization的時候,怎麼做training?
link |
很多同學的想法是說,有做batch normalization的時候,training也許跟原來沒有做batch normalization沒有什麼不同,反正就是把Z減掉一個constantμ再除一個constant,那constant在微分的時候反正也沒什麼作用,然後就直接做back propagation。
link |
其實不是這樣的,真正在train這個batch normalization的時候,會把整個batch裡面所有的data一起考慮,我不知道大家聽不聽得懂我的意思。
link |
你在train batch normalization的時候,你要想成你有一個非常巨大的network,然後你的input就是X1,X2,X3,然後得到Z1,Z2,Z3,中間還會算兩個東西μ跟σ,它會產生Zθ,Z1θ,Z2θ,Z3θ。
link |
back propagation的時候,你一路back propagation回來的時候,它是會通過σ,通過μ,然後去updateZ的。這樣大家了解我的意思嗎?為什麼要這樣?因為你想想看,假設你不這麼做,你把μ跟σ視為是一個constant。
link |
當你實際在train你的network的時候,你back propagation的時候,你改了這個w的值,你會改動這個Z的值。改動這個Z的值,其實你就等同於改動了μ跟σ的值。但是如果你在training的時候沒有把這件事情考慮進去,會是有問題的。
link |
所以其實在做batch normalization的時候,這個Z對μ和σ的影響是會被在training的時候考慮進去的。今天你要想成是,你有一個非常巨大的network,input就是一整個batch。
link |
back propagation的時候,它這個arrow的signal也會從這個path回來。所以這個Z對μ和σ的影響是會在training的時候被考慮進去的。這樣講大家有問題嗎?
link |
如果你這邊你沒有聽懂的話也沒有關係,因為其實你一般在framework裡面就call一個batch normalization layer而已,所以你其實也不知道這個具體是怎麼做的就是了。
link |
好,那沒有關係,我們就繼續講。現在我們把Z normalize成Z tilde。但是有時候你會遇到一個狀況是,你可能不希望你的activation function的input是μ是0,variance是1。
link |
也許有些特別的activation function你現在想不到是什麼,它的μ跟variance是別的值,performance更好。你可以再加上一個σ跟β,把你現在的distribution的μ跟variance再做一下改動。
link |
你可以把你的Z tilde再乘上這個γ,然後再加上β得到Z hat,然後再把Z hat透過sigmoid function當作下一個layer的input。
link |
那這個β跟γ你就把它當作是network的參數,它也是可以跟著network一起被認出來的。
link |
那這邊有人可能會有一個問題是,那如果我今天的γ正好等於σ,我如果今天的μ正好等於β,如果γ正好等於σ,μ正好等於β,那這個normalization不就是有做跟沒做一樣嗎?
link |
就是我們把Z normalize成Z tilde,再把Z tilde normalize成Z hat,但是如果今天γ等於σ,β等於μ的話就等於沒有做事,確實是如此。
link |
但是加上β跟γ,跟μ和σ還是有不一樣的地方,因為μ跟σ它是受到β所影響的,它是受到β所掌控的。
link |
但是今天你的β跟γ它是independent,它是獨立的,它是跟你的input的β是沒有關係的,它是network自己根據現在它想要加什麼樣的β跟γ自己加上去的,它是不會受到input的feature所影響的,所以它們還是有些不一樣的地方。
link |
那我們看一下在test的時候怎麼做,假設我們知道training的時候怎麼做,我們就train出一個network,這個network其實它在train的時候它是考慮一整個batch的,所以它其實要吃一整個batch才work,它其實要吃一整個batch。
link |
然後它得到一個Z,它會對Z減掉μ除以σ,那μ跟σ是從一整個batch的data來的,然後它會得到ZΔ,ZΔ會乘上γ再加上β,γ跟β是network參數的一部分,得到Zπ。
link |
那test的時候你就有問題了,因為你不知道怎麼算μ跟σ,對不對?因為test的時候你input一整個batch才算出一整個batch的μ跟σ,這是training的時候,但是test的時候你就有點問題,因為你只有一筆data進來,所以你估不出μ跟σ。
link |
那有一個ideal的solution是說,既然μ跟σ代表的是整個data set的mean跟standard deviation,整個data set的feature的mean跟standard deviation,而現在的training的process已經結束了,所以整個network的參數已經固定下來了,
link |
我們train好這個network以後,再把它apply到整個training set上面,然後你就可以估測現在Z的μ跟σ,你就可以另外從training set上再估測一次training set上的μ跟σ,因為現在之前沒有辦法直接一次估出來,是因為我們network的參數不斷的在變,
link |
在你的training結束以後,把training的參數,training好的參數fix住,你就可以算Z的distribution,就可以估出μ跟σ。這是一個理想的做法,但在實作上有時候你沒有辦法這麼做,一個理由是有時候你的training set太大,可能你把整個training set的data都倒出來再重新算一次μ跟σ,這個effort也許你都不太想做。
link |
而另外一個可能是你的training其實是online training,你的data是一筆一筆進來的,你並沒有把data存下來,你data一個batch進來,你update參數以後,那個batch就丟掉了,你的訓練資料量非常非常大,所以你的訓練資料量是不存下來的,你每次只進來一個batch,也許你的training set根本就沒有留下來,所以你也沒有辦法估測training set的μ跟σ。
link |
所以有一個practical solution是怎麼做的呢?這個practical solution是說,把過去在update的過程中的μ都算出來。這個是update的過程,每次你就取一個batch出來再update一次參數,取一個batch出來再update一次參數。
link |
隨著training的過程,正確率會緩緩地上升。假設第一次取一個batch的時候算出來是μ1,第一百次是μ100,第三百次是μ300,那你可以說,我把過去所有的μ總共比例起來,當作是整個data的certificate。
link |
不過這樣做也不見得太好,為什麼?因為今天在訓練過程中的參數是不斷地變化的,所以這個地方算出來的μ跟這個地方算出來的μ顯然是差很多的,因為真正最後訓練完的參數會比較接近這個地方得到的參數,這個地方得到的參數跟你訓練的時候得到的參數是差很多的。
link |
所以這個地方的μ跟你實際上你訓練好network以後它會算出來的這個Z的μ是差很多的。所以在實作上呢,你會給靠近training結束的這些μ比較大的weight,然後給前面這些人比較少的weight,有點像是那個rnsprog,如果你記得那個是什麼的話,如果你不記得也沒有關係,反正就是training比較接近結束的時候weight比較大,training剛起始的時候weight比較小。
link |
好,接下來最後講一下說batch normalization有什麼好處呢?那我剛才講說batch normalization的好處就是解決了internal covariate shift的問題,那internal covariate shift讓我們的learning rate只能夠設很小,那今天有batch normalization以後呢,你的learning rate可以設大一點,所以你的training就快一點。
link |
另外一個好處是batch normalization對防止的gradient vanishing這件事情是有幫助的。我們之前有講說如果你用sigmoid function,你很容易遇到gradient vanishing的問題,因為如果你今天的input是落在很靠近值很大或值很小的地方,你就很容易gradient vanishing。
link |
但是今天如果你有加batch normalization,你就可以確保說activation function的input都在零附近,都是這個斜率比較大的地方,就不會有gradient vanishing的問題,所以它特別對這個sigmoid、hyperbody tension這種有saturation region的activation function特別有幫助。
link |
那還有另外一個好處是,當你今天apply這個batch normalization的時候,它對參數的initialization的影響是比較小的。很多方法對參數的initialization是非常sensitive,當你加batch normalization以後,參數的initialization的影響就會比較小。
link |
怎麼說,假設我現在把w1都乘k倍,那它的output z當然也就乘上k倍,那今天做normalization的時候,它的μ當然也是乘上k倍,那算了一下它的σ當然也是乘上k倍,今天分子乘k倍、分母乘k倍,做完normalization以後就是什麼事都沒發生。
link |
所以如果你今天在initialize的時候,你的w的參數乘上k倍,對它的output的結果是沒有影響的,所以這就是batch normalization的另外一個好處,它對你的參數的initialization比較不sensitive。
link |
batch normalization還有一個副產品是,據說它比較能夠對抗overfeeding,那你加batch normalization的時候,你等同於是做了regularization這件事情,那這個也是很直觀,因為現在如果把所有的feature都normalize到固定的mean,一樣的variant,那如果你今天在testing的時候,有一個noise進來,讓你的mean有一個shift,那沒有關係,反正你會做normalization,shift,你會做normalization,
link |
所以就算是有noise導致你的data的mean有一個shift,batch normalization也可以把它normalize回來,所以batch normalization有一些對抗overfeeding的效果,所以我們剛才一開始都講說,你看到一個方法的時候,要想說它到底是在training的performance不好的時候有用,還是testing的performance不好的時候有用。
link |
那其實batch normalization應該是兩個stage都有用,不過它主要的作用還是在training不好的時候幫助比較大。testing,如果你今天是training已經很好,testing不好,那你可能也有很多其他的方法,可以有快不見得要用batch normalization。
link |
好,這個是要講什麼呢?這個是要講說,後來如果你今天你把Lenny Ray乘5倍,Lenny Ray乘5倍發生什麼事呢?
link |
結果飆好快的這個藍色的現象,突然就暴增,暴增比這個紅色的還有黑色的還要快很多。好,這邊它的Lenny Ray乘30倍是藍色的實現,其實Lenny Ray乘30倍不知道為什麼沒有比較好,沒有比較快。
link |
最後收斂的結果比較好,但沒有比較快,然後黑本命就說不知道為什麼。好,這是很多不知道為什麼的東西。好,這個是batch normalization,但是用sigmoid function。如果用sigmoid function的話,你得到的是這個粉紅色的這一條線,你會發現說當你用sigmoid function,其實這邊為什麼沒有sigmoid function,沒做batch normalization呢?
link |
因為如果你不做batch normalization的話,sigmoid function是train不起來的,所以要加了batch normalization以後,sigmoid function才能train得起來,而且它看起來跟Ray Liu的。