back to index
SELU
link |
自從有了ReLU以後,就有各式各樣的變形。舉例來說,有一個東西叫做Leaky ReLU。
link |
Leaky ReLU就是說,小於0的地方,我們不是乘0,我們小於0的地方乘上0.01。
link |
那馬上就會有人問說,為什麼是乘0.01呢?那沒有關係,就出現了Parametric的ReLU。
link |
Parametric ReLU就是說,小於0的地方,是小於0的地方,我們就乘上一個α。至於α值多少,根據training data把它認出來。
link |
後來又有人想了一招叫randomized ReLU。就我所知,randomized ReLU應該是沒有paper的,但是某一個比賽的時候,有人用了這一招。
link |
然後就得到好的結果,所以就被廣為流傳,這個叫randomized ReLU。
link |
它是說,我們今天呢,小於0的地方一樣是乘上α,但是α的值也不是從data認出來的,它是從distribution做random sample sample出來的。
link |
也就是說,你今天在做training的時候,每次你的α值都是不一樣的,但是在testing的時候,你會fix住你的α值。
link |
它就想要做到類似有點抓抱的效果。後來又有人提出了一個ReLU的進化版,叫做eLU,eLU就是exponential linear unit的意思。
link |
eLU它在這個大於0的地方跟其他的ReLU的家族是一樣的,不一樣的地方是在小於0的地方。
link |
它在小於0的地方,它是α乘上1的z次方減1,z就是那個activation function的input,它把activation function的input取potential減1再乘上α。
link |
所以你可以想像說,假設z等於0的時候,z等於0,1的0次方是1,所以output是0,所以這邊是接在一起的。
link |
而z如果趨近負窮大的時候,1的負窮大次方是多少?1的負窮大次方是0,0減負1是負1,然後再乘α,所以是負α。
link |
所以今天這個綠色的線會收斂在負α,這個是eLU。那你可能又要問說,α要設多少呢?
link |
我告訴你,後來就有一個新的東西叫做CELU。CELU就是告訴你說,首先它告訴你說α應該設多少,接下來它再做了另外一個變化。
link |
它的變化就是,現在把每一個值的前面都乘上一個λ,好像沒有做什麼,但是就是乘上一個λ。
link |
然後它告訴你說,λ跟α應該設多少呢?它說α要設1.67326324,λ要設1.050700987這樣子。
link |
這個感覺好像是隨便亂講,但它真的不是隨便亂講的。你如果看那個作者release的code,它就是這樣寫的,它就是這樣寫的,我是直接copy出來的。
link |
然後你可以看一下這個作者的keyhub的code,等一下會講說這個奇怪的數字是哪裡來的,其實還經過一番推導以後出來的呢。
link |
這個是,如果我們今天α設1.67326324,λ設1.050700987,這個是個巧合,987,這是個巧合。
link |
它的function就是長這樣。我們在下課之前先來看一下它有什麼樣的特色。
link |
它的第一個特色是它的值有正有負,但這個還好,因為在整個ReLU的family裡面,除了一開始最原始的那個ReLU以外都有負值,所以這個特性還好。
link |
然後它有那個saturation region,就是其他的ReLU它們沒有saturation region,但是它有這個saturation region在這個地方。
link |
不過ReLU其實也有這種saturation region,因為ReLU就只是ReLU乘上一個λ而已,所以ReLU有的東西ReLU也有,但ReLU有一個ReLU沒有的東西就是它乘上了這個λ。
link |
乘上這個λ有什麼不同呢?乘上這個λ讓它在某些區域的斜率是大於1的,意味著說你進來一個比較小的變化,通過這個region以後,它會把你的變化放大1.0700987倍。
link |
所以它的input是會被放大的,而且這是它一個L沒有的特色。
link |
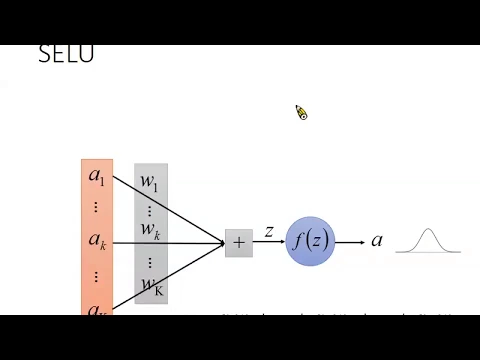
現在就是要講那個謎之數字是怎麼來的。這個不是隨便random算出來的,這個是有理論基礎的。這邊的理論要證什麼呢?這邊的假設是這樣,它希望假設我們今天的input有一堆distribution。
link |
假設這邊有一個我們常見的neuron,那我們知道說neuron的input就是A1到A大K,我們可以把它視為大K一個random variable。
link |
今天我們做一些簡單的假設,我們假設這大K一個random variable是IID的。為什麼它是IID?這個是假設,假設它是IID。然後它的mean是μ,variance是σ,square是0。
link |
我們假設它的μ等於0,假設它的variance等於1。這些input的random variable,它的distribution不需要是高懸,它的distribution可以是任何樣子,以下的推論都成立。
link |
現在我們希望的事情是找一個activation function,這個activation function可以達到什麼效果呢?它可以達到的效果是說,假設mean是0,variance是1。
link |
假設input的這些random variable,mean是0,variance是1。通過這個activation function以後,希望得到的output,它的mean也是0,variance也是1。這個是希望我們SALU可以得到的效果。
link |
接下來就進行一番推導。首先,我們先來看Z的distribution。我們知道說,Z就是A1到A大K的weighted sum,就得到Z。
link |
所以我們現在先求Z的distribution。先求完Z的distribution以後,我們再來看說,這個activation function應該長什麼樣子,才能夠讓今天output的這個A,它也是mean是0,variance是1。
link |
我們先來看一下Z這個distribution,我們來算它的mean跟variance,我們來看它的mean。我們怎麼算Z的mean呢?很簡單,就對Z取期望值。
link |
對Z取期望值怎麼算呢?根據國中紀律,我們就知道說,我們可以把Z是A1到A大K的weighted sum,然後我們可以把期望值放進去,
link |
我們只對AK取期望值乘上WK,然後再把它加起來。那AK的期望值是多少呢?AK的期望值就是A的平均,我們已經說過,它就是μ,μ就是等於0。
link |
我們先假設我們不知道μ的值,那你可以把μ的提出來,你可以把μ的提出來,所以右邊就變成summation over WK等於1到大KWK。這個summation over K等於1到大KWK,其實就是W這個參數的平均值的K倍。
link |
我想這個大家應該沒有問題吧?等一下會講說這個參數到底有什麼用。好,那現在呢,我們知道說μ就是等於0,所以其實μZ就是等於0。
link |
因為input的這些distribution它的平均都是0,經過weighted sum以後,那這個Z的平均值,Z的期望值也是0。我們這邊做一個額外的假設,等一下會用到,是假設這個weight的平均值也是0,
link |
因為這個weight是有正有負的,所以它的平均值也是0。好,我們現在知道Z的平均值是0,然後weight的平均值我們也假設它是0。接下來,我們要算Z的variance,這邊我應該要有一項平方,但是我漏掉了。
link |
好,那Z的variance是什麼呢?當然就是Z減掉Z的平均值μZ的平方取expectation。那我們知道說μZ就等於0,我們前面已經算過了,μZ就等於0,把0代進去,得到Z平方的期望值。
link |
那我們要算Z平方的期望值,那Z是什麼呢?我們知道Z就是A1W1加A2WQ只加到AKWK的平方,然後取期望值。那在這個平方項裡面,有兩種不同的項,有一種項是AK乘上WK的平方。
link |
那AK乘上WK的平方,我們可以把WK提出來,只算AK平方的期望值。我們可以把WK平方提出來,只算AK平方的期望值。那AK平方的期望值是多少?
link |
AK平方的期望值,我們知道它就是1,AK平方的期望值就是1。假設有一個參數它的mean是0,variance是1,那它的平方的期望值當然就是1。
link |
好,那現在有另外一項是AI乘AJ乘上WI乘WJ。那在這一項裡面,我們可以把WI跟WJ提出來,因為AI跟AJ它們是independent的,所以你可以把它拆開。
link |
本來是E of AI AJ,你可以拆成E of AI乘上E of AJ。那這一項是什麼?這一項等於0,因為我們知道E of AI等於0,E of AJ也等於0。
link |
好,那有了這些以後呢,我們現在知道說E of AI AJ WI WJ這些是等於0。所以在這個平方項裡面,只有AK WK的平方是我們需要考慮的。那我們知道說AK WK的平方就是WK平方乘以σ的平方。
link |
所以我們知道說Z的variance就是summation over K等於1到大K WK的平方σ的平方。好,那現在當然σ的平方這一項可以提出來,剩下summation over K等於1到大K WK的平方。
link |
這一項是什麼?這一項其實是這個W的variance乘以K,這一項其實是W的variance的K倍,是W variance的K倍。
link |
那這是在那個μW等於0的前提之下,所以這個summation over K等於1到大K WK的平方就是這個W這個weight的variance。好,那有了這些東西以後呢,我們現在再做一個額外的假設。
link |
我們已經知道這個variance是1,那我們假設這個weight的variance也是1。我們假設K乘以weight的variance是1,所以weight的variance是K分之1。
link |
那有了這些假設以後,那我們知道說呢,Z這個參數呢,Z的這個random variable呢,它的variance也是1。好,那有了這些以後,有了這些以後,那假設前面這些你跟不上的話也沒有關係。
link |
你只要記得一件事,你只要記得說,現在根據一些運算和假設之後,Z的這個random variable,它的mean是0,它的variance是1。那麼根據什麼假設呢?
link |
我們根據每一個輸入的random variable,它的mean都是0,variance都是1。我們還有另外一個假設是,我們假設這一組weight它的mean是0,它的variance是K分之1。
link |
有了這些假設,我們知道Z的mean是多少,我們知道Z的variance是多少。但是你可能會覺得這樣還不夠,因為我們只知道Z的mean跟variance它可以是任何形狀啊,對不對?
link |
我們從來沒有說過它是,它應該是Gaussian,而且這些input其實也沒有說它是Gaussian,input可以是任何distribution。但是我們這邊可以直接假設,Z它可能是很接近Gaussian。
link |
為什麼?有人在網路上評論說這個假設好像太強了,但其實還好,因為根據中央極限定理,中央極限定理大家知道嗎?
link |
假設你是,不管你知不知道,假設你是知道,根據中央極限定理啊,把一堆IID的random variable合起來,它會變成一個Gaussian distribution。
link |
就假設你把一堆IID的random variable合起來,加得越多,它就越接近Gaussian distribution。而今天既然Z是很多IID的distribution的和,那它應該會很接近Gaussian distribution。
link |
尤其是在neural network裡面,這個K可能是上千,那Z可能就真的很接近Gaussian distribution。
link |
接下來,假設Z的distribution,我們已經知道,它就是一個min是0,variance是1的Gaussian distribution。接下來要推導的是說,有沒有哪一個activation function,
link |
可以讓我們做到說,把一個normal distribution通過這個activation function以後,它仍然min是0,variance是1。
link |
那在推導死路的時候,它其實已經假設說這個activation function它的形狀就跟L一模一樣,只是有兩個未知數我不知道,一個就是α,一個就是λ。
link |
所以接下來,設兩條式子,把未知數解出來,就結束了。第一條式子是,今天這個Z的distribution,我們已經知道它是一個normal distribution。
link |
通過這個activation function以後,它的min要是0。今天Z的distribution,通過這個activation function以後,它的variance要是1。
link |
這中間當然你會需要用到積分,不管你知不知道這個怎麼算,反正一直算一發,你就算出那個α的λ了。
link |
好,那這個當然後面數學部分就沒什麼好推導的,但是太過複雜,我們就不會推導。它其實花了非常大的力氣,做了一個非常冗長的推導,告訴你說,
link |
只要我的min落在某一個range之內,variance落在某一個range之內,我的參數的min落在某一個range之內,我的參數的variance落在某一個range之內,
link |
那最後我的輸出就會一直趨向於某一個min跟variance。不管你聽不聽得懂啊,它最後給了我們一個……
link |
好,那現在是這樣子的,我兜了一個50層的network。要弄50層network其實很簡單,在keras裡面你用for回圈,for i等於1到50就好了。
link |
先試一下relook,因為時間的關係,我們只跑三個α。看看結果如何,用一下relook,50層。
link |
好,來問一下大家的意見好了。你覺得它……哦,它還是跑了。好,沒train起來。所以剛才relook10層的時候,我以前有demo過它是train得起來的,50層就train不起來了。
link |
哦,對,keras有內建selu。欸,它的update很快欸,selu的paper也是夏天的時候才放到archive上,它馬上就內建selu。不過內建selu其實很容易啦,不就一行code而已嘛。
link |
好,改成selu。你覺得它會work嗎?你覺得它performance會比IOU好的同學舉手一下?
link |
好,開始跑了,好。哇,沒train起來。
link |
有上去一點點,但是如果你跟relook比的話,好了3%,但還是蠻差的。那我就想到一件事情,我想到說,你記不記得在推導selu的時候,它有一個假設,每一個neuron的input是min40,variance是1的iid。
link |
所以你的feature應該要先做一下normalize吧,至少讓input的時候要min40,variance是1吧,normalize一下。
link |
好,試一下。啊,你覺得會比較好嗎?你覺得有加normalization以後performance會比較好嗎?
link |
你覺得會,好。沒有變好,這其實是一個季中計,所以寫在註解裡面大家其實沒有變好了。
link |
為什麼會這樣子呢?我又在想說,你記不記得剛才在推selu的時候,我們對weight的min跟variance是有假設的,你記得嗎?我們假設weight的min是0,weight的variance是k分之1。
link |
當然我沒有辦法在training的時候保證weight一直都是處於這個狀態,但我們至少可以在initialize的時候把它initialize成這個狀態吧,這樣子我們到時候train的時候,weight的min跟variance就不會差太多。
link |
怎麼做?其實你可以讓你的variance,你可以直接在initialize的時候,讓你的weight的variancemin是0,variance是k分之1,你只要用一個這個lock normal就行了。
link |
好,你覺得加lock normal以後performance會比較好嗎?
link |
想想看,當時推selu的時候是有假設的,所以我們也需要把這個假設加進去。你看,加lock normal的performance就不一樣了。
link |
所以在deep learning裡面就是這樣,差一個小細節就是天差地遠。那你可能會想說,也許真正強的是lock normal,不是relu。
link |
好,你覺得relu會比現在的performance還要好嗎?你覺得不會?那會不會是季中季其實是會的?其實真正強的是lock normal。
link |
所以你看,確實selu加lock normal以後performance是好的。
link |
好,那就來實證一下,看看說這個acclimation function到底有沒有用。
link |
上面這個藍色的線就是一般的training,就是用batch normalization,下面這個snn就是用selu。
link |
那selu以後它的曲線是非常平滑的。那用batch normalization就是會有高級起伏這個問題,為什麼?因為你其實是用一個batch來估測整個statistics,所以你在估測的時候有時候是不太穩定的。
link |
那在cyphertest上的結果也是一樣。下面這個是做在我記得是121個machine learning的test上面,然後比較不同的方法,比較每一個方法在所有的方法裡面的排名。
link |
中間這個數字代表每一個方法的排名。那實際上它在呈現的時候,它是把每一個方法的平均排名減掉一個數字,然後呈現在這邊。
link |
所以今天反正這個數字越小,代表說這個方法的排名在越前面。那這邊比了很多,snn就是用selu,nsra init,你可以想像當然是nsra propose了,就是一種initialization的方法,特別適合用在redu上面。
link |
layer normalization,highway network,residual network,normalization還有很多,還有weight normalization,還有batch normalization。我們今天只講batch normalization,其實還有layer normalization,weight normalization是今天還沒有講的。
link |
總之,selu的performance最好。接下來,把selu跟其他方法比一下,這邊就比了svn,random forest等等,發現說selu也是贏svn跟random forest的。這邊數字越小就代表排名在越前面。
link |
所以有個有趣的事就是,你發現說,其實svn是贏其他deep learning的方法的,其實真的就是這樣。在那個121個machine learning的corpus裡面,deep learning其實並沒有特別強。
link |
svn其實少數可以deep learning base,然後打敗其他machine learning方法的pro.但其實在machine learning的那幾個task上面,svn跟random forest其實還是頗強的。
link |
我本來想做個demo,不知道做不做得起來,做不起來就算了,我們再看一次,做不起來我就回去錄一下好了。還有一個新的activation function叫做switch,switch的activation function長什麼樣子呢?
link |
它是一個非常神奇的activation function,它把sigmoid乘上z得到它的output。它中間有一個beta是可以調的,如果beta設1.0的時候長這個樣子,可以調beta值得到不同的形狀。
link |
所以大家看paper裡面好像beta得設1.0的時候performance就已經不錯了,所以這個是一個特別的東西,叫做switch。等一下我們再解釋它是怎麼來的。其實我實際試一下switch好像沒有比celu好。
link |
這邊是paper裡面有把switch跟其他的方法做一下比較,這邊把switch跟relu,leaky relu,parametric relu,softplus,elucelu,還有一個今天沒講的gailu來比一下。
link |
今天什麼時候switch贏過baseline呢?在多數的case,switch都贏過baseline,它就比了九個不同的task,才發現說比如說switch跟celu比,在九個task裡面switch都是贏的,跟leaky relu比,在七個case贏,一個平局一個輸。
link |
跟比如說elu比,八個贏,一個輸,跟celu比,八個贏,一個平局。然後看起來好像這個switch真的是非常強。