back to index
Interesting things about deep learning
link |
整理&字幕由Amara.org社区提供
link |
卡在local minima其實是一個迷思,因為我們可能是卡在central point而不是local minima。
link |
那有一個很簡單的說法來說明這件事是,這個是我們非常直觀的講法來解釋說,為什麼我們比較有可能卡在central point而不是local minima。
link |
而這個比較直觀的講法是說,假設每一個dimension,假設你要是一個local minima,那你每一個dimension都必須是這樣凹的,對不對,都是必須是這樣凹的。
link |
那我們假設說,這樣凹的機率,你在Amara.org上面找一個點,這樣凹的機率是P,然後你的dimension是1000,而你的參數量有1000,那你今天要找到一個點,它是一個local minima的機率是P的1400,其實是非常低的。
link |
所以通常多數的點,如果它的這個微分的值是0,它通常是有的地方凹向,有的地方向上,有的地方是向下。
link |
那有的地方向上,有的地方向下,那它其實是一個central point,而且現在今日多數人都已經相信這個說法。
link |
其實也有人驗證過這件事情,要驗證這件事情其實也不難,對不對,你就train the network,然後卡住的時候你就分析一下說我現在卡的地方是local minima還是central point,
link |
你會發現說多數的時候你其實是卡在central point,這個也有人做實驗驗證過了。
link |
其實這件事情我發現在Andrew Nick新開的deep learning的課程裡面,他也有提到這件事,他還講到central point的時候,他還特別強調說,你知道central point這個central就是馬鞍的意思,因為這個長得像馬鞍。
link |
然後他還現場在下面畫了一隻馬,真的,他現場畫了一個馬,就跟Buddy Rose一樣小畫家畫了一個馬,真的非常強。
link |
但是呢,Ian Goodfellow曾經說過,前面的這個想法也可能只是一個迷思,有可能事實的真相是,當你發現你train train卡住的時候,未必代表你真的卡在central point,為什麼?
link |
因為卡在central point或local minima意味著那個區域它的歸點非常小。但是他舉了一個例子,這個有放在他的教科書裡面,他舉了一個例子說,他train了一個error rate不斷下降,很快就卡住了。
link |
他把這個歸點plot出來,他把卡住的時候歸點plot出來,發現說其實歸點是很大的。所以這代表說,其實現在雖然說你的error rate不再下降,並不代表你卡在某一個central point,而是比較常有可能的狀況是,你走到一個山谷裡面,然後在山谷裡面呢,就是來回的震盪。
link |
所以你的歸點仍然很大,但是你的loss已經不會下降。但是你光看到loss不會下降,可能就會以為說,哦,我卡住了,卡在central point。其實不是,因為你的歸點仍然很大,所以它不是卡住了,它是在一個山谷中可能來回的彈跳。
link |
所以這是一個可能性。所以今天你不能夠一train network一卡住就說,哦,我卡在central point,其實也未必,因為你其實沒有檢查你的歸點啊。你要檢查一下你的歸點真的值很小,你才是卡在central point。如果你的歸點值沒有很小,你其實可能是遇到這個在山谷避險彈射的情況。
link |
接下來另外一個最近的新聞是,在IGOR有一篇paper告訴我們說,他train一個network,然後發現說,network可能只是用暴力記住他所學到的東西。
link |
他這個實驗是這樣子的,他說,我們先拿一個正常的training section,然後這個loss跟training的amplitude之間的關係是藍色的這一條線。接下來,我們把input做一些shuffle。input做的是影像辨識,input做shuffle,我覺得如果是固定的shuffle沒什麼影響,因為你只是把第一個pick,假設你的shuffle是固定的,也就是說,比如說你把第一個pick放到第二個位置,第二個pick放到第三個位置。
link |
如果每一張影像都是用同樣的方法做shuffle,那其實對你的training是沒什麼影響的,對不對?所以你得到的是綠色這一條線。
link |
接下來,如果他對input做完,每一張image的shuffle都不一樣,或者是說,input就乾脆是每一個pixel就是給他一個高渲的noise,結果train到後來,他的error還是可以train到0。甚至說,我們現在就給你的networkrandom的label這樣子,他的label就是random的,所以network學不到任何東西,但是你的loss還是可以train到0。
link |
大家看到這個東西就嚇到吃手了。我們的networkcapacity都夠大,大到他可以硬背這個corpus而沒學到東西。但是有的人可能會覺得說,啊,這個顯示了deep learning不work。
link |
我覺得這個實驗其實並不是顯示deep learning不work,這個實驗主要告訴我們的事情應該是說,因為我們已經知道deep learning是讓很多testerswork,他主要告訴我們的事情應該是說,我們的network是如此的巨大,大到他可以硬背corpus,但是實際上在training的時候,他卻沒有選擇這麼做。
link |
我們正在問的應該是這個問題,他可以硬背,他想的話他可以硬背,他沒有選擇這麼做,為什麼?現在還沒有很好的答案。這個實驗應該是告訴了我們這一件事情。
link |
在這篇ICLR的paper以後,馬上就有人寫paper反駁,讓他就是network不是只有做memory,這個實驗是這樣子的。在實驗的設計上跟前一篇paper是類似的,他怎麼做呢?
link |
他說他把他的label做random的置換,這邊的數字0,0.2,0.4,0.6,0.8,0是代表label全部都是對的,0.2就是20%換掉,0.4就是40%換掉,60%換掉,80%換掉。
link |
如果你看他的training跟testing的curve的變化的話,這邊虛線,這五條虛線是testing的accuracy,這五條實線是training的accuracy。
link |
你看現在就算是加了一大堆的nodes,代表說你的training data裡面有80%的東西是不make sense的,你只能憑著印記把它記下來,但是反正network可以印記下來,記憶力很好,印記下來他也得到100%的正確率,不管你有多少的random。
link |
但是在testing上,反正你random越多,performance當然就越差,這個沒有什麼好特別surprise的。但是你看這個training的process,你會發現說,其實testing的performance是先增後降的,對不對?
link |
你會發現說,testing的performance是先增加後來才下降的,我們看這個80%error的case,他也是先上升一些,然後再下降,顯示說network其實一開始他先學了一些有道理的東西,之後才崩潰的。
link |
他在崩潰之前,他是先學了一些有道理的東西的。所以那篇pattern給我們一個觀察是說,network在training的時候,他整個training的process可能是他先學簡單的pattern,他先學有道理的pattern,之後再把奇怪的東西例外強記下來。
link |
所以這個實驗是想要顯示這件事情。那如果你看右邊這個圖,右邊這個圖他的重軸講的是ratio of critical point,ratio of critical point是什麼意思?
link |
他是說把training data裡面的一個point拿出來。這什麼叫critical point?他把training data裡面的一個point拿出來,然後再看說在那個point的某一個距離之內有沒有其他point的label跟這個point是不一樣的。如果有,代表說這個function在這個point的附近特別的崎嶇,因為它的label變了嘛,所以代表比較崎嶇。
link |
所以ratio of critical point他想要衡量的是說,現在我們的network認完以後,他的model所得到的function有多複雜。ratio of critical point值越大,代表現在這個function越複雜。
link |
那隨著training的進行,你會發現說function越來越複雜。而如果你今天你的label noise越大,顏色最深的代表noise越大,noise大代表network必須要記很多的奇奇怪怪的例外,所以它的function是特別複雜。
link |
但你會發現說這些function並不是一開始就那麼複雜,它們一開始是比較簡單的,是隨著簡單慢慢地變得複雜。
link |
一開始他只想要記比較簡單的事情,比較有規律的東西,但後來把簡單有規律的東西記完以後,他就去記那些例外的東西。如果看左邊這個圖,一開始只記有規律的東西,所以performance值會變好,但後來開始記了奇奇怪怪的例外以後,performance就變差了。
link |
還有另外一個有趣的事,也許這個是舊文,大家都知道,叫knowledge destination。knowledge destination這個詞可能是來自於Hinton的15年的paper。
link |
同樣的概念,在13年的時候,一個Microsoft的researcher寫了《Do deep networks really need to be deep?》這篇paper,他就propose過一樣的想法了。
link |
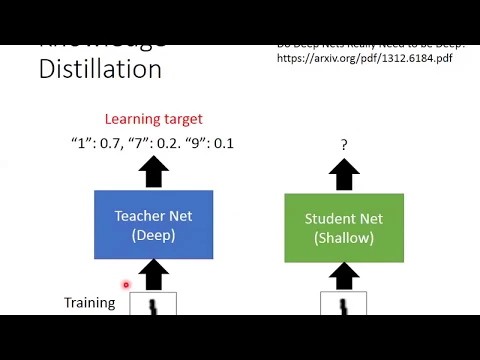
在knowledge destination裡面,一開始我們有一個teacher network,它可能是一個比較深的network,然後我們拿它去做training,我們train好一個teacher network。
link |
接下來我們把training data丟到teacher network裡面,那當然teacher network的正確率其實也不是百分之百,你知道我們network的output不是一個distribution嗎?
link |
output就是中國的softmax嘛,所以你得到的是一個distribution,所以你input一個image1,那teacher network就說這個image11的機率是70%,7的機率是20%,9的機率是10%。
link |
接下來你有一個student net,student net通常是一個又寬又扁的network,它是一個矮胖的network,而這個矮胖的network它要做的事情是,它去學teacher network的output。
link |
照理說network就是看那個training data正確的network學嘛,但今天這個矮胖的network它不管那個正確的data,它就看teacher network的output。
link |
teacher network告訴它說,看到這張image要output70%的1,20%的7,9,10%的9,它就照著這樣output,它去minimize它跟teacher network之間的cross entropy。
link |
照理說本來應該是,這張image是1,它應該就是要讓1的機率越大越好,而其他的數字的機率越小越好,但現在不是這樣,它希望說1的機率是70,7的機率是20,9的機率是10,這個student net它就完全去學這個teacher network。
link |
如果用這一招的話來達成什麼效果呢?用這一招達成的效果是,本來如果你想要認一個shallow的network,很寬,又寬矮胖的network,認不起來,它performance不好。
link |
但是一旦它今天學習的對象變成teacher network以後,它的performance就變好了,這是一個很神奇的事情。
link |
而這個是那篇paper的實驗結果,紅色的這個點是一個shallow的network,用shallow network train。
link |
這個實驗就是停坐在team裡上,就是大家作業一的common,跟大家作業一的實驗做的是一樣的,縱軸是正確率,橫軸是network的參數量,今天如果你是一個shallow的network,隨著參數量越來越多,其實performance你也進步不了多少。
link |
綠色的是deep的network,其實它deep的network沒有真的很deep,我記得就是三層而已,不過不要忘了這是2013年的時候做的,是四年前做的,我感覺這四年好像過了一個世紀一樣。
link |
那個時候三層其實也是很deep的,雖然現在三層感覺很shallow就是了。接下來,讓這個矮胖的network去學另外一個network。
link |
它學習的對象其實是一個convolutional neural network,這個粉紅色的是一個convolutional net,它很強,然後還有一個ensemble的convolutional net,它更強。這個藍色的對象應該是去學那個convolutional net的performance,它的老師就是convolutional net,它想要它的output跟convolutional net一樣。
link |
那你會發現說,這個藍色的線跟紅色的線,那兩個network是一樣的,照理說它們的capacity就是一樣,它們定義的functional space是一樣的。
link |
但是你直接trade shallow的時候,你挑出來的是一個不好的方式。但是你如果讓你的network去學另外一個network,去學一個很強的,比如說convolutional的network,你會發現它的performance就上漲了。這是一個蠻有趣的現象,大家可以再看一下paper,看看裡面的討論。