back to index
Generative Adversarial Network
link |
字幕由 Amara.org 社群提供
link |
講的東西呢,講一講,所以我們就先講Git,然後我覺得Registered Postal Machine之前已經講過了,所以去年講過了,而且又有上課的錄影,所以再講一次你也不見得覺得特別有意思,而且它跟作業沒有那麼直接的關係,或許你用不太上,那沒有關係,我就把這個連結呢,呃,呃,這個留在,留在這邊,然後給大家參考這樣子,好,感謝大家這個期中考都來上課,
link |
因為我們不需要講RBM,所以就省下一些時間,如果講得完的話,我們其實也可以提早下課,這樣,啊,對,第三節的時候要請那個作業二最好的三組來講一下,這樣,啊,希望這三組現在在這邊,有嗎,啊,作業一,不好意思,說錯了,好,希望這三組在這邊,謝謝,好,那如果有關Git的話呢,有一個很好的Tutorial是這個Young Fellow呢,
link |
在2016的Talk,那,呃,它不只有這個文,紙本的Paper,然後還有錄影,那就留在這邊呢,給大家參考,好,那在開始講Game之前呢,假設你上學期有修我的Machine Learning的話,其實我們是有提到一些跟Game有關的東西的,我們很快的來複習一下我們之前說了什麼,然後呢,再來講一下實際上Game的原理是什麼。
link |
好,那現在我們要做的事情是什麼呢?我們要做的事情是生成,是Generation,也就是說,讓機器看一大堆的Object以後呢,它生成出類似的東西,舉例來說,機器看了唐詩三百首以後生成一首詩,或者是機器看了一大堆動畫以後呢,合出動漫的圖,這樣,那,呃,有什麼樣的方法可以幫助我們做到這些事情呢?也許你還記得Auto Encoder。
link |
我們可以Train一個Auto Encoder,Auto Encoder做的事情是,呃,我們有一個NN的Encoder,把一張Image丟到NN的Encoder,它變成一個Code,有一個NN的Decoder,把Code丟到NN的Decoder裡面,它變回一張Image,在Train的時候,Encoder和Decoder是Jointly一起Train的,我們希望Input和Output越接近越好,當我們學好這個NN的,當我們學好這個Auto Encoder以後呢,
link |
我們就可以把Decoder的部分呢,拿出來,我們就可以把Decoder的部分拿出來,它可以幫我們生成Image,因為在Train的時候,這個Decoder它只要吃一個Code,這個Code其實就是一個Low Dimensional的Vector,它就可以產生一張Image,所以我們今天把這個Auto Encoder,Encoder和Decoder一起訓練好以後,我們只要把Decoder拿出來,給它一個Code,這個Code就是一個Random的Vector,它理論上就可以產生一張Image。
link |
舉例來說,你可以實際的做一下,這個還蠻容易的,你在Enlist,手寫數字辨識的那個Code上,Train一下Auto Encoder,你Train一個Auto Encoder,它的Code是Two Dimensional,那你就可以丟一個Two Dimensional的Code到Decoder裡面,然後合出一張數字來,舉例來說,你Train好這個NN的Decoder以後,以下是真實的實驗結果,你輸入給Decoder,-1.50這個Vector,
link |
你把這個Vector丟到Decoder裡面,它的Output就是0,你把1.50這個Vector丟到Decoder裡面,它的Output就是1,然後如果你在X軸是正負1.5之間,Y軸是正負1.5之間,等距的做Sample的話,你得到的結果會像是這個樣子。
link |
就是說,這個橫軸代表從圈圈變到一束的這個變化過程,縱軸代表了這個數字的角度。這個是Auto Encoder,那我們也有講說,如果單用Auto Encoder的話,它不見得是最適合拿來做生成的。
link |
如果你要生成出比較Realistic的Image的話,你會用Variational的Auto Encoder。這個Variational的Auto Encoder呢,我把它的Paper放在這邊,我們今天就沒有詳細講它的推導,等一下我們會花很多時間講Game的推導,我們就不要講VAE的推導。
link |
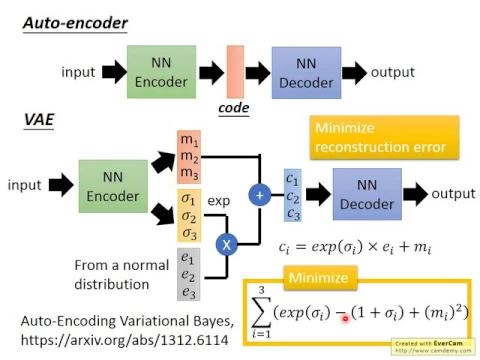
那VAE它做的事情是這樣,我們一樣有一個Encoder,一樣有一個Decoder,但是跟一般的Auto Encoder不一樣的地方是,這個Variational的Auto Encoder跟原來的Auto Encoder不一樣的地方是呢,這個Encoder首先它會產生一個Code,這邊用,這個Code是三維,我們用N1,N2,N3來表示。
link |
除了這個三維的Code以外,它會產生另外一個三維的Vector,這邊表示成Sigma1,Sigma2和Sigma3,那它還會隨機的Sample一個Noise出來,它會隨機的Sample出一個Noise的Vector出來。
link |
這個你每次在Train這個VAE的時候,除了給它一張Image,叫它Recontract回一模一樣的Image以外,你還要隨機的Sample出一個Noise,Noise的Vector,這個Noise的Vector通常就是從比如說Normal Distribution裡面Sample出一個Vector。
link |
然後接下來呢,你會把Sigma做Exponential,讓它變成正值,然後呢,把它乘上這些Noise,再把這些Noise呢,再把Sigma跟Noise相乘的結果呢,加給Add,得到C。
link |
那你這邊做的事情呢,就是我們把原來的Vector,這個M1,M2,M3呢,加上一些Noise,讓它變成C1,C2,C3,再把C1,C2,C3丟到NN的Decoder裡面去,那Training的時候呢,跟原來的Auto Encoder一樣,你希望Input跟Output越接近越好。
link |
但是如果你只有這樣做的話是不夠的,因為如果你只有這樣做的話,你會遇到的問題是呢,因為這個Sigma其實是Noise,它會干擾你的Decoder做Reconstruction,它是把這個Noise加到你的Code上,它干擾你的Decoder做Reconstruction。
link |
所以如果你只是要Minimize Input跟Output的這個Euclidean Distance,你只要讓Input跟Output最像的話,最後學出來的結果很有可能就是Sigma是等於零的,就跟原來的Auto Encoder是一模一樣。
link |
所以在Train Variation Auto Encoder的時候,你還會加上另外一個假設,這個假設是希望呢,會對Sigma做一個Contraint,這個Contraint還蠻特別的,其實可以證明說這樣子做呢,可以Maximize一個Likelihood,可以Maximize一個Likelihood的Lower Bound,但我們今天就不要講這個。
link |
這個Contraint就告訴我們說,我們希望呢,這個Exponential的Sigma減掉1加Sigma呢,它們越接近零越好,然後N1呢越接近零越好,你可以把這個Ni越接近零越好,這件事想成是L2的Regularization,那Exponential Sigma要讓它接近1加Exponential Sigma是什麼意思呢,那什麼時候這兩者會一樣呢?
link |
當Sigma等於零的時候,這兩者會一樣,Exponential零減1加零的值是一樣的,也就是說你會希望Sigma呢,越接近零越好,也就是取Exponential以後呢,越接近1越好。
link |
這個都是之前講過的東西,但是VAE呢,有一個問題,這個問題是什麼呢?VAE雖然你可以得到一個Decoder,它可以Input一個Code,Output一個Image,但是VAE我們在學這個Autoencoder的時候,我們並沒有要這個Decoder,它真的學會產生Image。
link |
什麼意思呢?因為我們要Decoder的Output跟Input越接近越好,也就是我們要Decoder的Output跟某一張Image越接近越好,但是一個,就是這個Decoder的Output跟這個Image是否接近這件事情,跟人覺得說,今天Decoder的Output是不是Realistic,像不像真正的Image,這兩件事情其實有可能是不相干的。
link |
舉例來說,現在呢,有這兩張Image,左邊這張Image呢,它跟這個Image差了一個Pixel,這張Image跟這個Image也差了一個Pixel,但是它們差的地方不一樣,對Machine來說呢,左邊這張Image就比較Realistic,右邊這張Image呢,對人來說呢,左邊這張Image比較Realistic,右邊這張Image顯然就是錯的,顯然就是覺得人壞的。
link |
但是對Machine來說,這兩張Image跟這個正確的答案的距離是一樣的,所以對Machine來說,對Decoder來說,它在學習的時候,這兩張Image是一樣好的。
link |
所以有另外一個方法來幫助我們Generate更Realistic的Image,這個方法叫做Generative Adversarial Network,它做的事情呢,就很像是在做演化一樣,首先你有一個第一代的Generator,第一代的Generator產生一些Image,然後你有一個第一代的Discriminator,第一代的Discriminator是一個Binary的Classifier。
link |
這個Binary的Classifier呢,會看說現在GeneratorGenerate的Image跟真正的Image,就它是一個Binary的Classifier,它做的事情是認說現在,它做的事情是認說現在呢,輸入的Image是Generator產生的Image還是Realistic的Image。
link |
那一開始呢,你的Generator很破,你一開始Generator的參數幾乎是隨機的,所以它Generate出來的Image是很奇怪的,也許比,假設你現在要產生數字辨識的話,我相信它產生的應該是比這些Image更加的模糊,這邊Image已經算是產生的很好了,它應該是產生的更加模糊。
link |
那這個Discriminator呢,它可以分辨出一張Input的Image,它是真正的Image還是Generator產生的Image,你就認出這樣一個Discriminator,有了這個Discriminator v1以後呢,根據Discriminator v1會產生Generator v2。
link |
那Generator v2做的事情呢,是它產生的Image可以騙過第一代的Discriminator,第二代的Generator它產生的Image可以讓第一代的Discriminator覺得它是Realistic的,然後有了第二代的。
link |
然後呢,接下來Train一個第二代的Discriminator,第二代的Discriminator可以分辨Real的Image跟第二代的Generator產生出來的Image之間的差別,你把Real的ImageInput到第二代的Discriminator,它的Output會是1,而你把第二代的GeneratorGenerator的ImageInput到Discriminator裡面去呢,它的Output會是0。
link |
有了這些Information可以產生第三代的Generator,第三代的Generator可以騙過第二代的Generator,第三代的Generator產生出來的Image丟到第二代的Generator會被判斷成是真正的Image。
link |
那接下來呢,就在產生第三代的Discriminator,這個第三代的Discriminator呢,可以分辨第三代的Generator產生的Image跟真正的Image之間的差別。
link |
好,那這件事情實際上是怎麼做的呢?實際上是這樣,這跟前一頁是一樣的。
link |
這件事情是怎麼做的呢?首先你要有一個Discriminator,這個Discriminator就是一個Binary的Classifier,你Input一張Image,那它告訴你說這個Image是Real的還是Fake的。
link |
如果是Real的就Output1,如果是Fake的就Output0,它是一個Binary的Classifier,這個Binary的Classifier它裡面要有幾個Layer,要不要用CMN什麼的,通通都是你自己決定的,你要自己決定這件事。
link |
好,接下來呢,我們有一個Generator,Generator做的事情是什麼呢?這個Generator它做的事情呢,就跟VAE的Decoder是一模一樣,是一模一樣,就是Input一個Random的Vector,那它可以Output一張Image,而你Input不同的Vector,它Output出來的Image呢,就長得不一樣。
link |
只是說在Train那個VAE的Decoder的時候,我們是要去Minimize一個Reconstruction的Error,那這邊這個Generator,它的這個架構跟VAE的Decoder是一樣的,只是它做的事情也是一樣的,只是在訓練的時候,訓練的方法是不一樣。
link |
好,那我先,那怎麼Train這個Generator跟Discriminator呢?首先呢,你先Random Initialize一個Generator,一開始你先有一個Generator的Structure,然後它裡面的參數都是隨機產生的,你有這個Generator以後呢,你就丟進去一組Vector,然後產生一打假的Image,然後你再從你的Database裡面挑出一打真的Image。
link |
然後呢,你把真的Image通通標成Positive Example,這邊用1來表示Positive Example,你把這些產生出來的Image通通標0,代表它是Negative Example,接下來把這些Positive的Example和Negative Example丟給Discriminator,Discriminator就可以去學會說,怎麼鑑別Positive Example和Negative Example,怎麼鑑別說一張Image是Generator產生的還是真正的Image。
link |
好,用這個方法可以認一個Discriminator,再來怎麼認一個Generator呢?這個怎麼認一個Generator呢?因為我們現在啊,如果認好這個Discriminator以後,然後我們隨機丟一個Vector進去,Discriminator會產生一張Image,然後Generator知道這是一張假的Image,這個Generator產生一張Image,然後Discriminator知道這是一張假的Image,
link |
它會Output一個很低的分數,很接近0的分數,代表說這一張Image其實是假的。
link |
第二代的Generator,第一代的Discriminator,第二代的Generator它產生出來的Image,要讓第一代的Generator覺得它很像是真正的Image,也就是說第二代Generator產生出來的Image丟到Discriminator以後,丟到第一代Discriminator以後,它的Output應該是1。
link |
這個怎麼Train呢?這個很容易,因為Generator跟Discriminator把它接起來,就是一個Network,就是Generator是有很多的Hidden Layer,Input一個Vector,Output一個Image,那Image你就可以想成就只是一個比較寬的Hidden Layer而已。
link |
如果你現在說At least的話,每張Image都是28x28的Pixel,那你可以想成說這是一個很多的Hidden Layer的Network,後面幾個Layer屬於Discriminator,前面幾個Layer屬於Generator,中間有一個Layer它的寬度正好就跟Image一樣,它的Output就代表一張Image。
link |
那它的Output的每一個Dimension的Value就代表那個對應的Pixel,它的這個顏色的深淺。如果你在說At least的話,它就是灰階的嘛,所以你就會用一個數字來代表說這個灰階的顏色有多深。
link |
某一個在中間這個Hidden Layer,它Output的Value就代表那個灰階的顏色,然後你就用Gradient Descent去調Generator的參數,讓它Random Input一個Vector的時候,Output的這個值是越接近1越好。
link |
但是你要Fix住這個Discriminator,因為我們只要Train Generator去騙過Discriminator,你不要跟著一起去Train Discriminator,如果一起跟著去Train Discriminator的話,那其實只要Discriminator學會,看到什麼東西Output就是1就好了,所以就等於什麼都沒有學到這樣。
link |
這個其實都是我們講過的東西啦,那之前呢,在上學前我想要做一下寶可夢的Game的煉成,那做半天都做不出來,那我在學期我做出另外一個東西了,我做出二次元的人物頭像煉成啦。
link |
其實這個說實在還蠻簡單的,其實網路上有Database啦,這個是從一個叫何志源的研究生的部落格上找下來的,然後就用那個DC Game來Train就好。
link |
那DC Game是什麼呢?它跟原來的Game是一模一樣的,唯一不一樣的地方只有它的Layer的架構通通都是CNN,所謂DC就是Deep Convolutional的意思。
link |
它就是很多層CNN,那我發現直接跑這個Code也不用調參數就做出來了,這Code裡面參數都幫你寫好了,那你可能會問做起來怎麼樣呢?上面這個是Training Data,並不是Machine產生的。
link |
做出來,我跑了,那個Generator不是會一直Update嗎?第一代第二代這樣一直Update下去,我Update一百次以後得到的結果是這個樣子。
link |
可是你可以看到說它其實隱隱約約是有人的樣子,是有人頭的樣子,而且其實Update一百次很快啊,Update一百次超快的,可能五分鐘都不用就Update一百次了。
link |
然後這個是Update一千次的結果,Update一千次其實你就可以看到眼睛了,它有不同顏色的頭髮,有藍色的頭髮,有粉紅色的頭髮,有黑色的頭髮,但都有眼睛,都有眼睛。
link |
然後接下來呢,Update兩千次以後就得到這樣的結果了,就是比剛才又更好了,現在眼睛都比較大了,而且它臉可能會有,這個頭髮還有點不同的樣子,因為它都有嘴巴,這是金髮,這是荷髮,然後它都有嘴巴,都有嘴巴。
link |
然後這個是五千次的結果,而且它發現說動漫人物就是要有水汪汪的大眼睛,它都有畫出水汪汪的大眼睛,有頭髮有嘴巴。
link |
然後這是Update一萬次以後的結果,你會發現說有一些圖其實就還畫得不錯,這些圖的感覺看起來像是水彩畫的,有一些地方我覺得比較模糊,但是你都可以看出說它想要畫的是一個動漫人物,大概可以知道它想要畫什麼。
link |
比如說這一張,這一張也還可以,都有眼睛都有嘴巴,有一些比較崩壞的就是了,但是基本上都可以看出說是有一個大眼睛的。
link |
這個是兩萬次的結果,最後我就停在五萬次的地方,這個跑起來蠻快的,就是去睡一覺隔天早上起來就有了,然後發現說也有一些崩壞的,但是有一些確實是可以以假亂真。
link |
比如說這個也許可以是以假亂真,你說是人畫的也許都有人相信,這個是綠色的頭髮,還有綠色的眼睛,然後這個就有點崩壞,然後這個也還不錯,這個也很崩壞,這個也很崩壞,這個也還不錯,總之畫出蠻多還蠻好的圖的。
link |
好,那我們接下來要講一下,我們作業三就是要做個game,那我們來講一下真正的game的原理,前面就只是簡單的概要性的敘述一下。
link |
為什麼可以產生realistic的image,這個部分數學式比較多,所以如果你有問題的話,你就舉手打斷我,這邊就講慢一點。
link |
我們先從maximum likelihood estimation開始說起,我相信其實多數同學都知道什麼是maximum likelihood estimation,這個對你來說一點都不陌生。
link |
我們現在要做的事情是這樣,我們有一個data的distribution,這個data的distribution呢,我們寫作p data of x,這邊的x你就可以想成是一張image,一個image你就把它所有的pixel統統串起來,就是一個很長的vector。
link |
那你把這些vector集合起來,你把所有的database裡面的image的代表vector統統集合起來,它也是一個distribution,這個distribution就寫作p下標data of x。
link |
那我們現在如果要產生一張image的話,我們要怎麼做呢?我們要去找一個distribution,這個distribution是受控於一組parameter theta,我們要找一個distribution,這個distribution叫做p下標g of x。
link |
這個p下標g of x,它是受到一組參數theta所操控,這個theta決定了這個p下標g of x,它長得是什麼樣。
link |
你可能會問說,我們為什麼要找一個p g,跟這個p data很像呢?那是因為這個p data,你可以想成說,這個p data,我們不太容易從它裡面做sample,就是說我們可以從,我們這個p data是我們手上已經有,它就代表了我們現在手上的image。
link |
那現在你要多sample一張p data of x,其實有點麻煩,你要找一個漫畫家來幫你畫一張動漫的圖才行。
link |
所以我們要找一個p g of x,這個p g of x,它裡面的theta就是受我們的操控,我們知道這個裡面的theta是什麼,所以我們現在有這個p g of x,我們就可以要畫多少張圖就可以畫多少張圖。
link |
那這個p g of x是什麼呢?其實你不用想得太複雜,這個p g of x,可能是你知道的,可以是你知道的東西,舉例來說,p g of x,它可以是一個Gaussian mixture model。
link |
那這個theta就是這個Gaussian mixture model裡面每一個Gaussian的mean跟variance,我們知道theta的值,我們知道Gaussian mixture model裡面的每一個mean跟每一個mixture的mean跟variance,我們就可以從,我們也知道每一個Gaussian的mixture weight,我們就可以從這個Gaussian裡面去sample出data。
link |
所以這個p g可以是Gaussian mixture model,只是我們等一下要用的不是Gaussian mixture model,是neural network來表示這個p g。那我們要做的事情就是找到一個theta,可以讓p g跟p data越接近越好。
link |
怎麼做這件事情呢?如果是Gaussian mixture model的話,或者是一些其他,你就想Gaussian mixture model,如果是Gaussian mixture model的話你可以這麼做,我們從p data裡面去sample一堆的training data,我們去p data裡面去sample出一堆的example,比如說sample出x1,x2到xn。
link |
舉例來說它的分布就像右邊這樣。然後接下來我們有辦法去計算,如果給我們一個參數theta,p g這一個,就假設這個theta已經給定的話,p g這個distribution sample出xi的機率,假設這件事情我們是可以計算的。
link |
接下來呢,你就可以定一個東西叫做likelihood,這個likelihood的意思就是說,今天給我們一個theta,給我們一個theta,我們就定義出p g,那這個p g產生這一堆example x1到xn,它的可能性有多大,這個東西就是likelihood。
link |
那這個likelihood就寫成呢,我們把database裡面的每一個,我們把sample出來的每一筆example xi都去計算它的p g of xi,把每一筆data的p g of xi都算出來,然後通通把它乘起來,這個就是我們的likelihood。
link |
那接下來,給我們一組參數theta,我們可以算likelihood,接下來我們做的事情就是,找一個參數theta star,這個theta star可以讓likelihood被maximize,可以讓likelihood越大越好。
link |
如果今天是Gaussian mixture model,那你要找的就是Gaussian的mean跟variance還有mixture的weight,那假設我們就先設好說呢,有三個mixture,那你可能找出來的mean就是這三點,那找出來的variance可能就是像是藍色的圈圈這個樣子。
link |
好,那這個maximum likelihood呢,我們可以對它做一下轉換,我們可以把這個likelihood的這個式子呢,前面取一個log,不會影響到我們找出來的theta,然後呢,我們可以把這個log的相乘變成相加,然後取log。
link |
然後呢,這個,因為啊,我們現在的x1到xn,都是從ptheta,x裡面sample出來的n-theta,所以這一個式子,其實就是在approximate呢,我們從x裡面,我們從這個ptheta這個distribution裡面sample x,然後去計算這個x產生的這個機率取log的期望值。
link |
這邊是用sample的方式來計算,但是那是因為我們實際上並沒有辦法對這個distribution做積分,所以我們用sample的方式呢,來approximate這個distribution。
link |
好,那接下來呢,這個從ptheta這個distribution去sample x,再計算每一個x的這個log的機率這件事情呢,如果你把它取積分的話,我們要做的事情其實就是像下面這個樣子。
link |
我們要做的事情就是,積分over所有的x,然後呢,算這個ptheta的x,再乘上log pg of x。
link |
那這一項呢,後面可以減掉這個,你可以減掉一項,你可以減掉這一項,這一項呢,只跟ptheta有關,跟theta完全無關,所以減掉這一項並不會影響你找出來的theta。
link |
這一項只是為了我們要把這個maximum likelihood這件事情,劃減成minimize KL divergence。好,那這一項跟theta是沒有關係的,所以減在這邊是沒有關係的。
link |
那接下來呢,我們就可以把這個同樣都是積分over x,所以你可以把積分裡面的部分呢,放在一起,然後呢,乘在log前面的東西也一樣都是ptheta,所以你可以把它提出來。
link |
你就得到呢,ptheta,你就得到呢,你在積分裡面就是積分over x,ptheta,然後log,然後pg,pg除以這個ptheta這樣子。
link |
然後呢,我們本來是要maximize這一項,但是你可以改成minimize這一項,然後呢,把log裡面的分子和分母呢,把它對調,這是等價的。
link |
這樣做以後呢,這一項就是ptheta和pg的KL divergence。好,所以我們在做maximum likelihood的時候,我們要做的事情,我們在做maximum likelihood的時候,我們要做的事情就是,
link |
我們想要找一個參數theta,根據這個theta所定義出來的pg,它和我們的這個theta的ptheta呢,它們的KL divergence的越接近越好。
link |
所以這一切事情呢,都是很合理的。那KL divergence我想大家都知道吧,就算你沒有修過information theory,你可能也知道,它就是定義兩個distribution有多相近。
link |
那KL divergence越小,代表這兩個distribution呢,越相近。但是現在問題來了,pg到底應該是什麼?我們剛才說pg就是Gaussian mixture model,但是Gaussian mixture model非常的不generalized。
link |
Gaussian mixture model是有限制的,Gaussian mixture model它沒有辦法model所有不同的ptheta。那事實上如果你今天用Gaussian mixture model去產生image的話,你可以用Gaussian mixture model去產生image。
link |
其實產生image這件事情並不是非常新的題目,那這個題目大概二三十年前就有人做了,只是最早的時候,在還沒有變之前呢,在最早的時候可能是用Gaussian mixture model做的。
link |
你做出來的image都非常非常的模糊,都是糊成一團,就一整張都是同一個色塊,有什麼東西都看不出來。那就是因為Gaussian mixture model它沒有辦法真的去逼近,就假設這個ptheta,假設這個x是image,這個ptheta的x就是image的分布。
link |
Gaussian mixture model它跟ptheta差太多了,它沒有辦法真的去模擬這個ptheta,它沒有辦法真的跟ptheta很像,那你sample出來的東西呢,就都跟這個真正的image差很多,都非常的模糊。
link |
所以Gaussian mixture model帶給我們的第一件事情,第一個好處就是,我們可以有一個非常複雜的PG,我們可以有一個非常flexible,非常一般化的PG。
link |
怎麼樣有一個非常一般化的PG呢?那就是把你的PG用一個NN來定義,也就是說我們的這個theta呢,其實就是neural network的參數,這個PG of x呢,其實是用一個neural network所產生的。
link |
因為neural network如果你今天疊很多層,它可以很powerful,或者是說我們今天的這個PG是怎麼來的呢?我們就說我們有一個neural network,這個neural network呢,我們就寫成一個function g,我們知道一個neural network如果參數給定的時候,它就是一個function。
link |
這個neural network它的input呢,是一個vector z,那通常z呢,你會設成一個低微的vector,比如說你要產生的image可能是96x96這麼大張的image,但是你的vector會設得小一點,你的vector比如說設個32微、64微之類的,你的z可能會設一個32微64微之類的低微度的vector。
link |
你把這個z這個vector丟到g裡面,你把z這個vector丟到g這個function裡面,它的output呢,可以得到一個x,這個x呢,就是一張image,這個x呢,它的dimension呢,跟一張image呢,是一樣。
link |
至於這個nn,它可以input一個vector產生一個vector,它怎麼定義一個distribution呢?它是怎麼定義一個distribution呢?如果我們今天input的這個z是一個distribution的話,那這個nn的output就可以把它看作是一個distribution。
link |
這樣大家知道我的意思嗎?假設這個z呢,是從一個Gaussian的distribution裡面sample出來的,是從一個normal distribution,假設這個z是從一個normal distribution裡面sample出來的,我們把這個sample出來的z,通過g得到一組x,那這個x呢,就是另外一個distribution。
link |
那你不需要太擔心說,我今天input的是一個normal distribution,這個z是一個normal distribution,那會不會我通過這個nn產生出來的distribution,沒有辦法產生太複雜的樣子,因為input就是一個normal,就是一個很簡單的distribution嘛。
link |
會不會產生出來的distribution其實就也很接近normal,這樣不是也就跟我們剛才說用Gaussian mixture model的意思差不多嗎?你其實不需要太擔心這件事情,因為我們知道說,neural network,如果你,就算只有一個hidden layer,只要那個hidden layer夠寬,它可以模擬任何的continuous function。
link |
所以這個,一個neural network它是可以非常generalize,你就算只是input一個非常簡單的normal distribution,通過一個neural network的轉換,它也可以變得非常的複雜。
link |
所以今天我們只要找出這個neural network的參數,我們把這個neural network設不同的參數,我們就可以得到非常不一樣的distribution,就算是input的distribution都只是一個normal distribution,但是隨著這個neural network的參數的不一樣,我們可以產生出各式各樣複雜的不同的distribution。
link |
這樣大家可以接受嗎?大家可以了解說,我們可以用一個neural network定義一個distribution這件事嗎?
link |
那如果你可以接受這件事以後,接下來我們要做的事情,就是我們希望找一個neural network的參數,讓這個參數所定義的distribution跟真正的data所定義的distribution越接近越好。
link |
這個圖就是從OpenAI的這個blog上面載下來的,就是希望說這個neural network,這邊就說是一個generator,這個generator產生出來的distribution跟真正的distribution越接近越好。
link |
可是現在問題就是,這個neural network的distribution,如果你要把它寫成式子的話,它到底應該長什麼樣子?如果要寫成式子的話,我覺得你可以寫成這樣。
link |
x出現的機率,從neural network裡面sample出x的機率,假設neural network的參數set已經給定了,就這個g這個function已經知道了,從neural network裡面sample出x的機率到底是多少呢?等於積分over所有可能的z。
link |
然後呢,每一個z它出現的機率不一樣嘛,有的z出現機率高,有的出現機率低,你要乘上這個z它的quire,就是z如果出現在Gaussian的中間,當然機率比較高啊,non-determinant中間機率比較高,離原點遠當然機率比較低。
link |
你再看說,每一個z呢,通過G這個function以後得到一個x,它是不是等,正好等於你現在要考慮的這個x。如果等於的話就是1,如果不等於的話就是0。我這邊用identity function,用這個i加一個下標來代表identity function。
link |
如果下標裡面的這個statement是true的話呢,這個identity functionoutput就是1,反之就是output是0。我們可以寫成這樣,但寫成這樣,你沒辦法算likelihood啦,之前的Gaussian distribution給你一個x,你可以輕易地算出這個x出現的機率,對不對?
link |
但是今天如果是一個這個nn的話,給你一個x,就算你知道這個quire的distribution,自己的分布長什麼樣,因為G很複雜,所以你要求出x的機率會變得很困難,你可能是沒有辦法做的,你不知道怎麼做,沒有簡單的方法可以幫我們做到這件事,所以現在就卡在這個地方。
link |
所以Gauss最大的貢獻就是解決了這個問題,怎麼解決這個問題呢?我們現在如果在無法算likelihood的情況下,我們怎麼樣調整network,調整generator的參數setup,讓generator產生distribution,接近data的distribution呢?這個就是Gauss最大的貢獻。
link |
好,那我們再重新formulate我們的問題,我們假設我們有一個generator G,G就是一個function,其實它就是一個function,它不是network也沒有關係,懂嗎?它就是一個function,它可以不是neural network,它可以是任何的function,只是一般我們現在都用neural network來表示這個function,因為這個function很複雜,我們現在都用neural network來表示。
link |
至於neural network裡面有什麼樣的結構,要不要用CNN什麼的,這都是你自己決定的。好,這個function,input就是一個Z,Z這個vector,output就是一個X這個vector,然後我們有先定義好一個quire的distribution,這邊寫成Pquire of Z,有了這個quire的distribution,又知道這個function G,我們可以定義出一個distribution叫PG of X,然後我們不知道怎麼算PG,就給我一個X,我其實不會算PG of X。
link |
好,接下來有一個discriminator,這個discriminator也是一個function,就現在突然天外飛來一個discriminator,這個discriminator也是一個function,它的input就是X,它的output是一個scalar,那這個discriminator它的作用是什麼呢?
link |
這個discriminator它的作用就是在衡量PG跟Pdata有多相近,或有多不相近,這個等一下我們就會詳加解釋。就假設現在給你一個G,我們本來說,因為我不能算likelihood,所以我不知道說,我沒有辦法算出說,這個G所定義的PG跟Pdata的KL divergence是多少。
link |
但沒有關係,突然來一個discriminator,這個discriminator它會算PG跟Pdata之間的,它算的不是KL divergence,你其實也可以讓它算KL divergence,但在原來的game它算的不是KL divergence,它算的是另外一種divergence,但它就是可以算兩個distribution之間的divergence。
link |
它怎麼算兩個distribution之間的divergence呢?你要讓它去解下面這個問題。先定義一個function叫做V of GD,這個function就是給一個G,給一個generator,給一個discriminator,它會output一個數值。
link |
它會output一個數值,這個V of GD是一個這樣的function。接下來,我們要找的generator,我們要找的那個跟data distribution最接近的generatorG star,其實就是從下面這個式子找出來。
link |
我們要找一個D去maximize V of GD,再找一個G去minimize, maximize V of GD。你聽得一頭霧水,對不對?我們先看下下一頁。
link |
今天這件事情,這整個equation到底是什麼意思呢?這個equation的意思是這樣,我們先看右上角畫紅線的地方,右上角畫紅線的地方是說,我們要找一個D,這個D可以去maximize V of GD。
link |
我們假設說現在的G,就是generator,只有三個選擇,就是G1、G2跟G3。假設我們現在只有三個選擇,就是G1、G2跟G3,世界上只有三個generator。
link |
但實際上,因為generator是由network所定義的,network的參數不同,就是不同的generator,參數有無窮多種可能,所以你的generator有無窮多種可能。它是continuous,它不是discrete的。那為了比較方便講,我們就假設discrete的generator就三個。
link |
好,那我們假設這個V of GD就是一個function,它是一個G跟D的function。如果我現在已經定住G1,我去定住G1,那改變這個D,這個discriminator,我就會得到不同的數值。
link |
當然discriminator它也可以是一個neural network,所以我沒有辦法用一個dimension來表示discriminator的參數,但我們在這個圖上就簡單用一個dimension來表示這個discriminator的參數。你先固定好G1,給它不同的discriminator,你就得到不同的V of G1D。
link |
同理,給定G2,你得到不同的V of G2D,給定G3,你得到不同的V of G3D。所謂的maxD,找一個D,它可以讓V of GD最大的意思就是說,這邊G已經給定了。
link |
如果G就是G1的話,那這個maxV of GD就是這個點的數值。假設G就是G2的話,那maxV of GD就是這個點的數值。假設G就是G3的話,那maxV of GD就是這個點的數值。
link |
接下來,我們要找一個G,它可以minimize畫紅線的這個部分。畫紅線的部分,它會受G1的影響。G1的時候,畫紅線的部分的值就是這個。G2的時候,畫紅線的部分的值就是這個。G3的時候,畫紅線的部分的值就是這個。
link |
如果我們今天要找一個G star,它可以minimize畫紅線的部分,那你覺得是G1、G2還是G3呢?給大家十秒鐘的時間想一下。這樣行嗎?我知道有min又有max,其實會讓人非常confuse的。
link |
好啦,十秒鐘過去了。你覺得現在假設V的定義就是像下面這個樣子啦。那我們G解出來,G star等於G1的同學舉手一下。你覺得G star等於G2的同學舉手一下。你覺得G star等於G3的同學舉手一下。
link |
太好了,所有人都覺得這樣。好,手放下。沒錯,就是G3。我想大家應該都有聽懂了。好,所以這個min、max的problem,它解出來的就是G3。
link |
這件事情成立的話呢,那我們不只找出G star等於G3,那我們找出來的最好的D呢,就是這個位置產生這個點的D。我想大家應該知道我的意思。
link |
那V怎麼定義呢?我們先不要管這個式子怎麼來的,V就寫成這樣。當我們把V寫成這樣的時候,我們可以有什麼好處呢?當我們把V寫成這個樣子的時候,給定一個generator,不然它是G1、G2還是G3。
link |
Max V of GD就是這個generator跟data之間的某種divergence,就是這個generator和這個data之間的差異。也就是說呢,這個值就是G1和data,就假設你V這樣定義的話。
link |
那這個值,就這邊這個高啊,這邊這個高,就是G1和data之間的差距。這邊這個高,就是G2和data之間的差距。這邊這個高,就是G3和data之間的差距。如果你選擇只有G1、G2、G3的話,G3和data之間的差距最小,所以G3就是我們現在要找的generator。
link |
所以神奇的地方就是,我們這樣定了V以後,Max V,就給定G的情況下,Max,找一個D可以讓V最大,找出來的這個值,就是G跟,就是generator跟data之間的divergence,就是如此的神奇。
link |
所以接下來,你只要找一個G,可以讓這個divergence最小就好了。接下來就是要說明說,為什麼是這個樣子?
link |
那現在第一個要說明的事情是,給定一個G的時候,假設我們已經定義好這個V了,給定一個G的時候,到底哪一個D star可以讓V最大?
link |
V是一個已經寫好的式子,G假設也已經固定住了,那哪一個D star可以讓這個式子被maximize?這個式子到底在寫些什麼?
link |
這個式子在寫說,我們從P data裡面去sampleX出來,取logD of X的期望值。你把從P data裡面sample出來的X,丟進這個discriminator,discriminator是一個function嘛,而不是一個scalar,然後取它log的期望值,再加上從G裡面去sample出X,再取log1-D of X的期望值。
link |
到底哪一個D,給定G的話就是給定了這個distribution,給定這個distribution,給定G就是給定這邊這個distribution嘛,那個P data不是你可以控制的,所以這個distribution是給定的。
link |
哪一個D可以讓這個V值最大?那我們就把它做一下展開,這邊從X裡面sampleP data,就是G分overP data的data的機率乘上logD of X,加上G分overPG的機率乘上log1-D of X。
link |
這邊都沒有什麼,接下來因為這個都是G分overX,我們把G分overX的部分提出來,把G分裡面的部分放在一起,把G分裡面的部分放在一起,我們就得到這樣一個中括號裡面的式子。
link |
接下來我們先假設D of X可以是任何function,D of X的output可以是任何value,就是說就算我們今天用一個network來定義D這個discriminator,一個network如果它的structure,它的neuron不是無窮多的話,它可以定義的function還是有限的,或者一些function它沒辦法model嘛,對不對?
link |
它沒有辦法說,噢,我今天input X等於0.1,D of X output是-100萬,然後我今天input X就動一點點,是0.11,然後output就是1000萬,這個就是network還是有限制的,它沒有辦法定義任何function。
link |
那我們現在先不要管那個限制,我們假設D of X可以是任何function,input一個X我們要它是什麼值,它就可以是什麼值,在這個前提之下,D要怎麼定義我們可以讓這個式子最大呢?
link |
假設D你可以要怎樣就怎樣,你要怎麼設這個D讓這個V最大的,那因為D可以是任何function,所以這個括號裡面的項,就積分over X中括號裡面的每一項我們可以分開考慮,也就是說我們只要找到一個D,我們可以把每一個X,不同的X都分開考慮,對每一個X我們都只要找到可以讓中括號裡面的這個數字最大,
link |
對每一個X我們都只要找到可以讓中括號裡面的數字最大,那summation以後它自然就是最大的值了。
link |
那接下來還有一個問題就是,我們怎麼讓中括號裡面的,到底D of X等於多少的時候,我們可以讓這個中括號裡面的數字最大。
link |
這中括號裡面我就念一下,它是Pdata of X乘以logD of X加上Pg of X乘以log1-D of X,那現在為了簡化起見D of X,我們就都用D來表示,Pdata of X是給定的,data distribution是給定的,所以Pdata of X就是一個值,是一個scalar,我們就用A來描述。
link |
Pg of X,G也是給定的,我們假設G已經給定的情況下去找最好的D,G是給定的,Pg of X就是給定的,所以它是一個scalar就是B。
link |
現在我們可以調的就是D,你要怎麼調調調調D讓上面這個式子最大呢?接下來感覺就是國小數學。就是找一個D我們可以讓A乘以logD加B乘以log1-D最大。那怎麼找它的最極值呢?怎麼找它的最大值呢?
link |
微分求出極值,再看哪一個極值最大。先做微分,把這個式子對D做微分,你就得到A除D,logD微分就是D分之1,加B乘上log1-D微分就是1除以1-D乘上-1,反正微分就是這樣。
link |
找它的極值,所以令它等於0,然後我們把D求出來。令它等於0的話,這邊就持很簡單的數學法,把這個式子挪到右邊去,變成A乘上1除以D star等於B乘上1除以1-D star,就D star會滿足這個式子,D star會讓這個微分為0,所以D star會滿足這個式子。
link |
接下來就是展開,把1-D star乘上去,把D star乘上去,變成A乘1-D star等於B乘D star,再挪一挪換一換位置,把它乘開,A-A乘上D star等於B乘上D star,然後D star就是A除以A加B。
link |
它再把A、B都帶回去,A就是data的機率,B就是generator產生x的機率,所以最好的D star,你給它一個x,它output的值應該就是data的機率除掉data的機率,分母就是data的機率加上generator的機率。
link |
這個值會介於0到1之間,你想想看分母一定比較大,所以它小於1,然後它一定是正的,所以大於0。
link |
所以你這個d這個function的output,如果你是neural network的話,你可以說它的output就是一個,你就output就加一個sigmoid,那它的output就可以讓neural的output變成0到1之間,因為現在最好的d的output,它一定是在0到1之間的。
link |
所以我們現在就是找出了給定一個G的時候,哪一個d會是最好的d。也就是說我們現在如果給定G1的話,哪一個d可以產生這個點呢?
link |
哪一個d可以產生這個點呢?就是符合這個式子的d,就是d1 star,它就可以產生這個點。如果G2已經給定了,那d2 star符合這個式子的d,也就是d2 star,就可以產生這個點。
link |
接下來我們要做的就是,我們已經知道說d1 star可以讓值最大,接下來我們要求出這個高是多少?
link |
要求出這個高是多少?我們只要把d1 star再帶到這個function裡面去,跟G1一起求出V of G1,跟G1一起求出V of G1,d1 star的值。這個值呢,我們下一頁馬上就要說明了就是說,這個值就是在衡量PG1跟data之間的某種divergence,它在衡量PG1跟data它們之間的difference。
link |
那怎麼說它們就是在衡量某種difference呢?這個很簡單,我們要做的事情呢,就是我們已經知道d star就是長這個樣子,把d star帶進去,我們就可以求出這一個有max的數字的數值,也就是我們就要計算V of G和d star,G是給定的,d star會受到G的影響,但我們知道說,反正d star和G的關係就是這個樣子,給定G,d star就是長這樣。
link |
所以把d star也帶進去,我們要求這個數值,這個數值到底是什麼呢?我們需要用到原來V的定義,那把d star等於這個式子,把這個式子帶到D裡面,我們得到就是這個樣子,1減d star的話,那就是分子的地方變成PG,這個我想對大家來說不成問題。
link |
在這邊把求期望值這件事情改成積分,所以這邊只是把原來求期望值改成積分,也沒做什麼特別的事情。
link |
接下來把上下的分子和分母都除二分之一,也沒有改變任何事情。那我們可以把二分之一這一項拿出來,因為這邊是在log裡面相乘,所以可以變成log相加。
link |
前面又是積分over P data,前面又是積分over PG,積分over PG就是1,總之你回去自己check一下,你可以把二分之一拿掉,然後再另外加上2乘以log二分之一,就不會影響你計算的結果。
link |
2log二分之一就是-2log2,總之就是這麼回事。所以我們今天把d star帶進去以後,給定一個G,把d star帶進去以後,我們算出來的結果就是這樣。
link |
這個東西是什麼呢?這個東西第一項是P data的distribution跟二分之一P data加PG的KL divergence。如果你記得KL divergence的定義的話,這個式子就是P data這個distribution跟P data和PG的平均distribution,它的KL divergence。
link |
那下面這一項呢?下面這一項就是PG這個distribution跟P data和PG的平均的KL divergence。所以下面這一項就是PG和二分之一P data加PG的KL divergence。
link |
其實從這個式子就可以很直覺地看出來說,現在這個東西它就是P data和PG之間的divergence。或者是說,實際上這個divergence,因為我們知道KL是非對稱的嘛,對不對?
link |
如果我們今天單看一項KL,我把P data放在左邊跟P data放在右邊得到的值是不一樣的。但是我們現在算的不是直接算P data和PG之間的KL divergence,我們是算P data和二分之一P data加PG的KL divergence,和PG和二分之一P data加PG的KL divergence,把這兩項加起來就會變成是對稱的。
link |
因為你發現你改變PG跟P data的關係根本不會影響你算出來的結果,所以這個divergence是對稱。這個divergence是有名字的。
link |
如果我們今天有一個divergence叫做Jason-Chanon divergence,JS divergence,有兩個distribution P跟Q,他們的JS divergence就是你另外去計算一個distribution N,N是P跟Q的平均,然後你計算P跟N的KL divergence和Q跟N的KL divergence,再把它們平均起來,這個就是JS divergence。
link |
所以我們得到的結論就是說,這一項這兩個KL divergence合起來其實就是兩倍的JS divergence,這兩個KL divergence合起來就是兩倍的data和PG的JS divergence。
link |
JS divergence是對稱的,所以這個PG跟P data調換也沒有什麼關係。所以我們現在就知道說,這一件事情,找一個d可以讓V of Gd值最大,在給定G的情況下,它確實在衡量G和data之間的差距,如果你妥善的定你的這個V的話。
link |
而且你還可以定不同的V,你最後就可以量不同的divergence,那現在是因為用,我們先講那個最原始的版本的gap,定法就是前面看到那樣,所以量出來就是JS divergence,所以你完全可以定別的,讓它產生別的divergence。
link |
所以就統整一下我們剛才說過的事情,我們說我們有一個generator,有一個discriminator,我們定好了一個V的value function,V的value function和這個data是有關係的,和P data是有關係的。
link |
那我們要找一個G star,G star它是下面這個optimization的問題的解。然後在這個optimization的問題裡面,找一個d讓V of Gd最大這件事情,它跟JS divergence的大小是一致的,它們的大小是一致的。
link |
那這個式子到底有多大呢?JS divergence最大是log2,如果今天兩個distribution完全沒有任何交集,JS divergence它仍然有定義,你可以自己算它仍然有定義,兩個distribution完全沒有任何交集的時候,JS divergence算出來的值就是log2。
link |
如果今天兩個distribution它們完全一模一樣的話,JS divergence算出來的值就是0。所以你會發現說如果最大值是log2的話,那maxV of Gd這個式子最大的值其實就是0,最小值就是-2log2。
link |
好,那現在我們要做的事情就是,找一個G它可以讓這個式子最小。哪一個G可以讓這個式子最小?如果今天G正好就等於,如果G所定義的distribution Pg正好就等於P data的話,
link |
它就可以讓這個JS divergence等於0,這樣它就可以讓max的這個式子最小。所以你今天解上面這個optimization的problem,你所得到的solution,你所得到的G,就是那一個它的distribution跟P data一樣的G,它定義出來的distribution跟P data一樣的G。
link |
好,那所以現在我們唯一剩下的問題只有解這個東西而已,did好了這個以後,你要做的就是解這個問題,解這個optimization的problem。
link |
怎麼解呢?我們先把這個藍色框框裡面的東西寫成log,因為這個藍色框框裡面的東西只跟G有關嘛,對不對?雖然V跟G和D有關,但是這邊有一個maxD,所以給定G的時候,你就找一個最大的D可以讓這個值最大,所以給定G的時候就給定藍色框框裡面的值,我們就把它寫成log。
link |
這個log就是G這個generator的loss function,我們知道我們在train neural network的時候,我們需要的就是一個loss function,我們要找neural network的參數去minimize loss function。
link |
我們現在也有一個loss function了,就是log,所以要做的事情就是用gradient descent去找一組參數,它可以minimize log,就結束了。
link |
這個東西用的其實就是gradient descent,你就算θG對L of G的偏微分,然後用這個gradient去update你的參數θG。
link |
那現在的問題就是,這裡面有max,你能微分嗎?你仔細想想,有max,你能用gradient descent解嗎?仔細想想,是可以的,對不對?我們之前看過太多這種例子了。
link |
什麼max out of network,max pooling,裡面都有max,你還不是照用gradient descent去解,所以其實就是可以解的,怎麼做呢?我們現在先想一個比較簡單的case。我們假設我們現在有一個function叫做f of x,這個f of x裡面,它就是d1,d2,d3這三個function的max的值,它有一個max,它跟這邊一樣。
link |
只是這邊這個d有無窮多本,它是continuous,這邊d有限格,就三個。假設d1 of x就是這一條直線,當然這個跟是不是直線沒有關係,但是曲線不會有什麼影響,d2就是這一條線,d3就是這一條線。
link |
那如果我今天要求x對f of x的微分,它的值應該是多少呢?是不是你就看說,你就看現在的區域,你那個x落在哪一個區域裡面。如果你x落在這個區域裡面,那這個微分的結果就是x對d1做微分。
link |
如果你的x落在這個區域,那x對f微分的結果就是d2對x做微分。如果你x落在這個區域,那x對f微分的結果就是x對d3做微分。所以這個微分值就取決於說,看看你的x落在哪一個區域,現在哪個區域裡面誰是最大的d,那你就拿那個x去對現在最大的d做微分就好。
link |
所以實際上,如果你要用歸顛descent去minimize這個function的話,雖然它裡面有max,你其實還是可以做的,你就random在這個地方初始,然後看一下哪一個d最大,你要算一下,求一下這個d1,d2,d3誰最大,發現是d1最大,那微分就是dx of d1,然後dx of d1告訴你要往右走,你就得到一個新的值。
link |
再求一下說現在誰的值最大,發現d2最大,然後再算一下x對d2的微分,再往右走,然後就可以了。
link |
所以這個不是什麼問題。所以要怎麼找一個g可以minimize這個function呢?你的做法就是,有一個初始的g0,然後你先找一下說,在給定初始的g0的情況下,哪一個d可以讓這個v of gd最大。
link |
哪一個d可以讓v of g,在給定g0的情況下,哪一個d可以讓這個式子最大。那個d我們現在用d0 star來表示。
link |
接下來呢,你就計算一下這個set g對這個v的歸點,在給定的g0 star的情況下算一下歸點,然後你就可以update你的g,得到g1。
link |
然後接下來呢,你就會找一個,你就得到g1,接下來再找說在給定g1的情況下,哪一個d可以讓這個v of gd最大,你發現是d1 star,那你再計算一下set g對v of g,d1 star的歸點,然後再update你的參數,得到g2,然後就以此類推,你就可以找到你要找的g了。
link |
所以就這樣。所以今天這整件事情呢,你可以想成是,我們說,當我們找到這個d0 star,當我們給定g0找到這個g0 star的時候,v of g0找到d0 star的時候,v of g0 d0 star,其實就是p of g0跟p data的js divergence。
link |
這一項跟js divergence是只差了一個常數項。那接下來呢,下面這個update參數是什麼意思呢?下面這個update參數你就可以想成是,我們要找一個新的g,把g0update成g1,那希望g1可以decrease jl divergence,可以減小jl divergence。
link |
那接下來呢,我們在計算呢,有了新的g1,我們在計算g1的js divergence,我剛好講成kl divergence,還是說錯,是js divergence,我們要找一個g1,然後這個g1呢,要最小化,找一個g1,然後我們根據d1 star呢,就可以衡量一下呢,這個g1和真正的data的js divergence。
link |
接下來我們再找一個g2,g2呢,它可以讓這個js divergence變小。
link |
想要問大家有問題嗎?沒有嗎?這邊也許有一個小小的問題,但不知道有多嚴重。這邊這個小小的問題是這個樣子的。我們現在呢,說給定一個g0,把d0 star帶到v這個function裡面,我們可以量出js divergence。
link |
然後你說,我們update一下g0,把g0變成g1,然後g0變成g1的時候呢,我們會讓定住這個d0 star的情況下,就d0 star是給定的,從g0update到g1的時候,會讓v of g1 d0 star小於v of g0 d0 star。
link |
但是,這樣並不保證我們新的g1它的js divergence一定會比g0小啊,對不對?因為搞不好這個distribution就長這麼怪,它就是要長這樣子,你也沒辦法。
link |
那這邊就是,你知道這只能假設說,d0 star跟d1 star可能是很接近的。所以,我們今天在update這個參數的時候啊,可能你就不好update這個g太多。
link |
但是這個問題其實也沒有那麼嚴重,你想想看這個,在做gradient descent的時候,你本來你的gradient踏得太大步,你就有可能讓你的loss function不減反增,對不對?所以今天其實也是一樣的道理。
link |
如果你今天這個update的時候,你這個參數,這個learning rate設的很小,那個d0 star跟d1 star是很接近的,那你今天update你的generator從g0到g1的時候,可能就會真的讓你的js divergence變小。
link |
但如果你update的步伐太大,本來就不保證你可以讓你的js divergence一定會變小。講到這邊,大家有問題嗎?沒有嗎?理論上是這樣,那接下來是實作上怎麼做呢?
link |
因為實作上v的定義就是寫成右邊這個式子,但是這邊這個期望值實際上你是不能做的,所以你要去approximate這個期望值。
link |
怎麼approximate這個期望值呢?這個做法就是,我們沒有辦法真的對p data做積分,沒有辦法真的對p data的distribution做積分,因為它的分布的範圍空間是所有可能的image,不可能真的對它做積分。
link |
但是我們可以做sample,我們從裡面從p data of x sample出m個點出來,從p g of x裡面,不可能真的對p g這個distribution做積分,但我們可以從p g of x裡面另外也sample m個點出來,我們這邊用delta來代表是從p g裡面sample出來的點。
link |
接下來我們其實不是去maximize這個v,我們把這個v用一個v delta來代替它,這個v delta就是把原來積分的部分換成平均,我們原來是要對p data distribution做積分,現在改成從p data裡面sample m個點出來,這m個點都去算log of dx再做平均。
link |
我們本來是要從p g,對p g算期望值,但是對p g沒有辦法做積分,所以從p g裡面sample m個點出來,然後把這m個點都算log1-d of x,然後再算平均。
link |
這個式子你有沒有看了覺得很眼熟呢?有嗎?沒有嗎?這個式子一般的binary classifier,它在做optimization的時候,其實就是在maximize這個式子,或者是minimize這個式子乘上負號,不信你自己回去check一下。
link |
我們現在假設有一個binary classifier,這個binary classifier,它的output我們就寫作d of x。
link |
這個我們一般的binary classifier的時候,我們都是說我們要minimize cross entropy,minimize binary的cross entropy,我們有一個target,然後我們要讓你的function output去minimize跟target之間的binary的cross entropy。
link |
也就是說今天假設有一個x,它是一個positive sample,我們就要minimize負log d of x,我們要讓d of x越大越好,也就是讓負log d of x越小越好。
link |
或者是說我們x是一個negative sample,我們就是要minimize負log 1-d of x,因為我們會想要讓d of x越接近0越好,也就是越接近0越好,也就是這個式子越接近0越好,它越接近1越好,也就是負log 1-d of x它越小越好。
link |
所以,總之呢,如果你想要maximize這個式子,它等同於是你做了以下那件事,這件事情是什麼呢?這件事情就是我們有一個binary的classifier,這個classifier當然它是可以是一個deep neural network,它的output就是d of x。
link |
我們的這個d這個discriminator,它就是一個binary的classifier,那這個binary的classifier怎麼train呢?我們從p data的distribution裡面sample m比data出來,當作positive sample,我們從p g裡面,g是已經給定的,我們從p g裡面sample另外m比data出來,當作negative sample,然後呢,我們去minimize cross entropy,你原來怎麼算,你原來怎麼train一個binary的classifier,現在就一樣train。
link |
一樣train下去,你就是在minimize這一項,或者是,我是不是寫錯一個地方啊?嗯,我寫錯一個地方,你有發現嗎?
link |
這邊應該有一個負號,這個負號,對不對?這是一個loss function,它其實下面這個v delta取一個負號這樣子,好,所以,大家了解我的意思嗎?所以這邊有點寫錯,不過沒有關係,如果你聽不懂的話,你就記得說,我們現在到底要怎麼找一個d去maximize v啊?
link |
我們說找一個d maximize v,我們求出來的值就是js divergence,那怎麼找一個d去maximize v啊?其實就是train一個binary的classifier,sample一些data,train一個binary的classifier,這一個classifier,它classifier的loss有多少?
link |
這個如果classifier的loss小,就代表js divergence大,如果這個classifier的loss,train的時候loss大,就代表它的js divergence小,這樣,好,而且這件事情其實還,還頗直覺的,對不對?
link |
因為如果我現在有兩個distribution,p data跟p g,我們分別從它裡面samplen比data出來,我run一個binary classifier,如果這個binary classifier的loss很大,代表這個classifier沒辦法分辨p data跟p g產生出來的example,那就代表說他們的js divergence很大,如果binary classifier的loss很小,它可以分辨p g跟p data產生出來的example,代表他們的js divergence就很大,這樣,
link |
所以今天binary classifier的loss就告訴了我們說,今天p data跟p g,他們的這個divergence有多大,那本來我們不知道怎麼量p g跟p data的divergence,但是藉由一個discriminator,也就是一個binary classifier,你就突然可以算這個東西了。
link |
整個algorithm實作上就是像以下這樣,首先有一個參數theta d,有一個參數theta g,random initialize theta d跟theta g,這樣你就得到一個初始的discriminator跟一個初始的generator。
link |
接下來每次train這個參數,每次這個up,在每一個iteration裡面你做以下的事情,首先從p data裡面sample n比theta出來,從p prior裡面,從p datasample n比theta就是,這怎麼做呢?
link |
如果你是像要做二次元動漫人物的產生的話,你就是先收集很多動漫的圖片,然後從裡面sample n張出來,就當作是從p data裡面sample theta出來。好,然後接下來呢,有一個prior distribution,p prior of z,p prior of z是一個簡單的distribution,but uniform distribution或是normal distribution是你自己定的,你知道怎麼從它裡面sample theta。
link |
接下來呢,你把z1到zn丟到generator裡面去,它會給你x1 delta到xn delta,x1 delta到xn delta就是generator產生的generated data。
link |
然後接下來呢,我們要update discriminator的參數theta d,這個discriminator的參數,它要去maximize v這個value function,這個discriminator要在給定generator的情況下去maximize下面這個value function,因為是maximize,所以我們這邊是用gradient ascent而不是用gradient descent,那怎麼maximize就是用gradient ascent去算一發就對了。
link |
好,那經過這個步驟以後呢,前面這個部分,我們是在學這個d,那通常呢,這個步驟我們會重複k次,會重複多次,為什麼這個步驟要重複多次呢?
link |
為什麼這個步驟要重複多次呢?因為像它這個步驟做的是什麼?這個步驟是要在量JS divergence,要量JS divergence,我們是要找一個d它可以maximize value function,那我們當然要update參數很多次,才能夠找到可以讓這個value function最大的那個d啊,我們當然要update這個d的參數很多次,我們才能夠找到可以讓這個value function最大的d。
link |
而實際上在實作的時候,因為我們是在train neural network,所以你不見得能夠找到global optimal的值,你不一定能夠找到global的maximum的值,你可能只是卡在local maxima的地方,所以實際上呢,我們只能夠找到這個數值的lower bound,理論上我們可以透過這個東西算出一個JS divergence,但實際上我們只能夠算出JS divergence的lower bound而已。
link |
這個是train discriminator的部分,接下來呢,要train generator的部分。
link |
那一樣去sample另外n個z,然後呢,再把這個n個z丟到generator裡面去,你就可以得到n個x tilde,那其實這邊你也不一定要另外sample啦,你用之前sample的東西也可以就是了。
link |
然後接下來呢,我們要做的事情就是,我們要找一個這個generator的參數θg,它可以minimize下面這個式子,那本來θd是要maximize這個式子,現在θg呢,是在給定discriminator的情況下要minimize這個式子。
link |
然後這個g出現在哪裡呢,它出現在這個地方,因為這個x tilde是把z帶進這個g裡面所算出來的,那你會發現說在這個objective function裡面呢,前半部呢,是跟generator完全沒有關係的。
link |
它就是前半部呢,就是samplen比,前半部就是sample,從data distribution裡面samplen比data,然後再去算那個discriminator的值。
link |
所以前半部不是generator可以控制的,所以前半部就把它拿掉,然後接下來呢,你再用gradient descent去update你的generator。
link |
好,所以下面這個步驟就是去認一個generator,那在這邊呢,你通常只會update一次,因為我們剛才有說過說,這個generator呢,你不能update太多,如果你update太多的話,你可能就沒有辦法真的讓js divergence下架。
link |
所以整個iteration的process就是在這個,這邊這個是for each iteration process,所以這個藍色框框加紅色框框合起來是一次iteration。只是這個藍色框框裡面,為了要找真正的max,你可能會重複好多次藍色框框裡面的步驟,然後只做一次紅色框框裡面的步驟。
link |
那我記得EM Goodfellow有說,在他tutorial裡面有說說,他自己習慣上前面這個步驟其實也只要做一次就好。
link |
好,那接下來呢,有一個實作上的issue,本來我們說呢,我們是要找一個generator,他可以minimize我們這邊寫的這一個式子,但是實際上從有game被proposed以來,好像就不是在minimize這一個式子。
link |
從EM Goodfellow第一篇的game的paper裡面,他就說他覺得不應該minimize這個式子,雖然理論上告訴我們應該要minimize這個式子,但實際上minimize這個式子的時候發生了一些問題,是什麼樣的問題呢?
link |
如果我們把log1-Dx畫出來,Dx是橫軸,log1-Dx是紅色這一條曲線,那你會發現說呢,在Dx很小的時候,這條紅色曲線是比較平滑的,在Dx很大的時候,紅色的曲線是非常陡峭。
link |
Dx的指小代表什麼意思?Dx的指小代表說,你現在你的generator所generate出來的一個x,會沒有辦法騙過discriminator,discriminator可以很明確的認出說,這一個x是generator所generate出來的東西。
link |
那你在training的起始的時候,你的generator的參數幾乎是random的時候要產生出來的x,會很容易的被discriminator發現,所以在一開始的時候,通常Dx的指是小的。
link |
也就是說,你在training的初始的時候,你sample出來的x,它的Dx都集中在這個區域,那集中在這個區域的壞處就是,這個區域的微分是很小的,所以你的訓練會變得很慢。
link |
那怎麼辦呢?改一下optimization的式子,把本來的log1-Dx改成-logDx。原來log1-Dx它的式子長成這樣子,-logDx它的式子長成這樣子。
link |
它們是一致的,所謂的一致的意思是說,當它大的時候,它也會大,當它小的時候,它也會小。
link |
但是不一致的地方是說,今天在初始的時候,因為多數的sample出來的x都集中在這個區域,所以它的微分的值會很大,所以你的訓練會比較快一點。
link |
當你的generate出來的x越來越好,Dx的值越來越大的時候,這個訓練會慢慢地慢下來。
link |
這比較符合我們在learning的時候期待,就是你今天離你的目標遠的時候,你learning rate稍微大一點,你要update快一點,你離你的目標近的時候,你要update慢一點等等。
link |
所以這個我想應該是很直覺的。這件事情並沒有太多理論上的保證,說這麼做在理論上是好的。
link |
甚至在WGAN的同學paper,在propose,WGAN大家都知道對不對?我不知道為什麼是因為大家都知道。大家不知道是嗎?知道WGAN是什麼同學舉手一下。哇,這麼多人知道,把手放下。
link |
我就說大家都知道,不知道為什麼。WGAN的前一天paper裡面就有講到說,如果你其實是在minimize這個式子的時候,你是在minimize一個很奇怪的divergence。
link |
你在minimize的對象是KL-divergence,而且那個其實不是KL-divergence,它是reverse KL-divergence,是reverse KL-divergence,減掉兩倍的JS-divergence,是一個比較奇怪的東西。反正實作上就是這麼做的就是了。
link |
而且這麼做其實有一個實作上的好處,什麼實作上的好處呢?你如果把式子寫成這個樣子的時候,你在update你的PG的時候,等同於是讓PG所產生的data當作是discriminative的positive example。這樣大家了解我的意思嗎?
link |
如果式子寫成這樣的時候,你沒有辦法說PG產生的data就是positive example,如果這樣子的話,你在實作的時候,你一樣是change一個classifier,然後把PG的output當作positive example。
link |
沒關係,這個你自己回去想一下實作的細節,你就知道了。我這邊其實,你在train game的時候,你常常會遇到一個問題,就是我們說discriminator的output,discriminator的loss,就是拿來衡量JS-divergence, loss大,divergence就大。
link |
所以你可以靠著JS-divergence的value來調你的generator,但是這個是理想上的狀況。實際上你會發現說,剛才忘了給大家看一下discriminator的數值,其實多數時候discriminator的loss都是0的。
link |
你train那個binary classifier,它有100%的正確率,它的loss都是趨近於0的。這邊這個圖是來自於to work principle method for training generation versus neural network這篇paper。
link |
這個paper要告訴我們的事情是說,現在有三個generator,一個generatortrain一個epa,一個generatortrain十個epa,一個generatortrain二十五個epa。根據作者在文字中的描述,train二十五個epa那個generator其實已經很強,它產生image其實是比較realistic的。
link |
但是你會發現說,當你有了這些generator,然後你有了這個好的generator產生一些generator的image,再去train一個discriminator的時候,discriminator它的accuracy幾乎都是100%。
link |
就算是那個已經train二十五個epa的generator,它產生出來的image,discriminator還是可以一眼就看出來說它就是錯的。
link |
discriminator的正確率幾乎都是100%,它的loss都趨近於0。這樣導致的壞處就是,事實上discriminator本來號稱是要量CS divergence,但是它告訴我們的事情其實非常的少。
link |
這個也是從同一篇篇裡面提出來的結果,它說它有兩個generator,一個是用一個fully connected的network當作generator,它現在做的就是產生image,就是產生那個房間,就是產生臥室的image。
link |
你有一個weak的generator,你有一個strong generator,它是dcgame的generator,它其實就是deep的convolutional的neural network。如果你今天橫軸代表training的iteration,隨著training的iteration越來越多,你會發現strong generator它generate出來的image已經非常的realistic。
link |
在這邊這個weak的generator它generate出來一些怪怪的東西,但是strong generator它generate出來這張圖已經很像是真的圖。但是如果我們看那個estimate出來的CS divergence,或者是看你的discriminator的loss的話,你會發現說loss幾乎是平的。
link |
從loss上面,你很難看出今天generate出來的image到底有沒有比較好。為什麼會這樣呢?為什麼discriminator的loss幾乎都是0呢?而discriminator的loss等於0,也就是說,或者是說,這個max找一個最大的D,帶進B of GD裡面算出來的值是0。
link |
意味著說,我們今天算出來的PData和PG的CS divergence等於log2,也就是說,PData跟PG,generator都覺得它們是完全沒有overlap的。
link |
這個有兩個原因,第一個原因是因為我們現在用的是sample,我們從來沒有辦法真的去算這個積分,而是從這個distribution裡面做一些sample出來。
link |
你可以想像說,假設我們現在有藍色跟紅色這兩個distribution,這兩個distribution是真的有重疊的,但是我們真的在算V的時候,我們是從紅色distribution裡面sample一些點出來,從藍色distribution裡面sample一些點出來。
link |
就算這兩個distribution它們真的有重疊,JAS divergence算出來不應該是log2,但是因為我們是用sample的方式得到我們的distribution,所以對generator來說,如果我們今天generator非常的powerful的話,
link |
那你其實可以找到一個boundary,硬是把這兩種positive example和negative example硬是分開,也就是說,你可以找得到方法硬是讓你的positive example它的d of x都是1,讓你的negative example它的d of x都是0,然後讓你的loss算出來就趨近於0。
link |
要解決這個問題,有一個方法就是綁住你的discriminator的手腳,要嘛就是update的次數少一點,要嘛就是讓它變得比較弱,比如說給它加個dropout,給它比較少的參數,讓它沒有辦法做這種overfitting的事情,讓它沒有辦法找一個奇怪的boundary,
link |
把兩個distribution的data point硬是分開。但是這樣的壞處就是,這件事很難做,就是你不知道你的discriminator應該要調到什麼地步,才能夠得到好的結果。
link |
而且我們今天,本來我們就是要用discriminator去量JS divergence,而discriminator可以量JS divergence的前提其實是,那個discriminator它的capacity是無限的,discriminator可以是任何function的時候量出來才是JS divergence,不是的話,其實你量出來也不是JS divergence。
link |
從這個角度來看,我們又很希望discriminator它其實是很powerful,所以這邊就造成了一些奇妙的矛盾。就實作上,理論上好像應該discriminator要很強,首先它要有infinity的capacity,它要update次數很多,update到真的找到maximum的值,
link |
因為實作上這樣做,你找出來的話,你JS divergence的算法永遠都是0,所以實作上變成你需要去綁住discriminator的手腳,卻又不知道要綁多少。這個是實作上的理由。
link |
另外一個理論上的理由是,從data的本質上來看,我們在考慮的data往往都是高微空間中的manifold。比如說,假設我們現在要產生的是image,我們之前就有說過說image其實是高微空間中的manifold。
link |
事實上,你的generator所產生出來的data也會是高微空間中的manifold。假設你一個generator,你input是一個10微的vector,那output的空間雖然是100微,但是你的generator的output會是100微的空間中的10微的manifold。
link |
也就是說,如果我們用圖式來表示的話,假設我們現在要generate的space是二微的空間,那你的pdata跟pg可能就是二微空間中的兩條直線。
link |
這兩條直線呢,它們交集的地方非常非常的小,幾乎可以說是趨近於零。所以在算JS divergence的時候,這兩個distribution,它們是幾乎沒有overlap的,所以它們算出來的divergence可能就是log2。
link |
這樣會造成什麼問題呢?我們不是有說過gain跟演化很像嗎?大家記得嗎?比如說我們看說在做演化的時候,眼睛是怎麼產生的呢?眼睛很複雜。
link |
有人覺得說,很難接受說,我們知道演化就是因為突變跟天擇的結果,有人很難接受說突變會突然從憑空突變出一隻眼睛,因為眼睛是一個非常複雜的器官。但是實際上在演化的時候並不是憑空出現眼睛的,而是先出現一個比較簡單的版本,比如說先出現感光細胞。
link |
對生物來說,要突變出一個細胞,它可以具有感光的能力,也許是做得到。先有感光細胞,然後後來再發現說,把感光細胞放在一個凹洞裡面,它就可以偵測來自不同方向的光線,就可以知道光源的方向,所以比較有好處,所以感光細胞就把它放在那個凹槽裡面。
link |
後來凹槽越來越深,因為凹槽很深就很容易掉髒東西進去,所以就把那個凹槽灌水,然後再把那個蓋子蓋起來,就變成眼睛。所以憑空從皮膚變成眼睛也許不行,但通過很多中間的步驟是可以的。
link |
但是要能夠有這些步驟的前提是,我們從左跨到右邊每一個步驟,都對這個生物的繁衍是有利的,這個天擇才能夠持續的演化下去。
link |
所以今天對GAME來說也是一樣,我們現在有一個P-DATA這個distribution,有一個P-G0這個distribution,一開始它們距離很遠,我們希望可以把P-G0跟P-DATA讓它們越近越好,比如說P-G100,希望它可以跟P-DATA是一模一樣的。
link |
但這中間一定有一個過渡的型態,因為我們是用歸根descent在調我們的generator,它中間有一個過渡的型態,你要從P0到變P1到變P50到變P-G100,它有一個過渡的型態。
link |
而對Machine來說,這過渡的型態必須每一次產生過渡的型態的時候,它必須比原來的更好,就P-G50必須要比P-G0更好,P-G1必須要比P-G0更好,P-G2必須要比P-G1更好,這樣子Machine才能夠一直update下去。
link |
如果對Machine來說,P-G0跟P-G50其實是一樣好或一樣壞的,那其實你就沒有辦法update你的generator。
link |
但實際上,如果今天是用JS divergence來計算你的divergence的時候,來量兩個distribution的差異的時候,你會發現說,在這個case,兩條線沒有交集,所以他們的JS divergence是log2。在這個case,兩條線沒有交集,所以JS divergence才是log2。在這個case,兩條線疊在一起,所以JS divergence是0。
link |
那這樣的問題就是,雖然說這個case確實JS divergence比較小,但其他caseJS divergence都是2。對Machine來說,這些case都是一樣糟的,所以在做update的時候,它根本沒有動力從這個case變成這個case。
link |
沒有動力從這個case變成這個case,它就沒有辦法從G0一下子跳到G100,它又沒有動力變成G0和G100之間的過渡型態,那你就train不起來了。
link |
然後怎麼解決這個問題呢?之後我們會講更好的方法,比如說WGAN。我就很surprise,就每個人都知道WGAN,那現在我還要講什麼呢?
link |
先講一些比較trivial的做法,比如說你可以add noise,你可以加noise,怎麼加noise呢?其實這邊有很多不同的做法,你可以說我在train discriminator的時候,我discriminator的input都加個noise。
link |
或我在train discriminator的時候,我把它的label加個noise,比如說有一張image它本來算是positive的,但我把positive image拿出來random有一部分的image被置換成negative的image。
link |
這種加noise的好處就是,本來你的distribution它都是,它可能是低微的manifold,但是現在加了一些noise以後,它們就漲寬了,這樣子它們可能就有overlap了。
link |
overlap的話,你就可以算它們的js divergence,而且如果它們有overlap的話,如果你有加一些noise的話,discriminator就沒有辦法得到zero的loss,它就沒有辦法硬是把positive和negative分開,這樣你就可以得到一些loss的值,你就可以算出一些js divergence。
link |
我會希望你的noise隨著時間越來越小,因為如果這個noise一直存在的話,假設紅色的線是真正的distribution,noise一直存在的話,noise會干擾你對真正distribution的判斷,所以實作上應該是noise隨著時間應該要越來越小。
link |
那還有另外一個問題呢,是mode的collapse,那mode的collapse是這樣子,你會發現,如果我們今天的data distribution是有很多個mode,所以很多個mode是說,假設你的data distribution其實是,比如說像這邊有兩個高前的分布,你generate出來的image,你generate出來的東西可能只有一個mode而已。
link |
比如說你generate出來的distribution就只有紅色的image,就只有紅色這個,你的generated distribution就像紅色的distribution一樣。
link |
舉例來說,剛才做那個動畫的case,我後來跑多一點epa以後就會變成這樣,你會發現它出現很多重複的臉,出現很多重複的臉,出現很多重複的臉,它們顏色有點不一樣。
link |
這個是粉紅色的頭髮,這個是棕色的頭髮,但它們是同一張臉,像Game的時候蠻常出現這種狀況。
link |
事實上這種狀況有時候不太容易發現,為什麼呢?因為你只會看到你有generate的東西,你不知道它沒有generate什麼。
link |
你懂我的意思嗎?舉例來說,你用一大堆image的圖片認出一個generator,然後它一直畫出很漂亮的狗,你就會覺得說,哇,好棒哦,畫出很漂亮的狗。
link |
也許它就只會畫狗,它完全畫不出別的動物,雖然AI沒有別的動物,它從來沒有畫出來,但你不會知道這件事情。所以有時候mockless不一定會被發現,但是這個case倒是比較明顯的一個mockless的狀況。
link |
這邊是另外一個toy的example,假設我們現在的data的distribution其實是長這個樣子,它是空間裡面的八個高選的分布。
link |
我們期待說今天,假設這邊的這些點是generator的分布,隨著training的過程,generator的distribution最後涵蓋了這八個點。
link |
在實作上,你比較容易觀察到以下這個現象,generator在產生這些data的時候,它變成它只有一個mode,它只會產生一個高選。
link |
比如說它在update實測的時候產生這個高選,discriminator就會發現說這個高選其實是fake的,然後discriminator就會針對這個高選去做調整,然後generator就會發現說這個高選呆不下去了,會被discriminator發現,然後就跳到下一個高選,然後又被discriminator發現,又再跳到下一個高選。
link |
進入一個貓抓老鼠的循環,然後就會沒有辦法停下來。
link |
這個原因是來自於哪裡呢?Bianca Fellow說,她原來以為可能是因為在做optimization的時候,diversion的設計有一些奇怪的地方。
link |
我們看看說,我們原來想要做的事情是maximum likelihood,maximum likelihood就是minimize KL divergence,這KL divergence是data放在左邊,然後generator的alpha放在右邊,那它的式子我們就寫在這個地方。
link |
這個KL divergence什麼時候有可能會產生無窮大的值呢?如果今天generator是0,而pdata有值的時候,你就會產生無窮大的KL divergence。
link |
所以我們今天在做KL divergence minimization的時候,我們會盡量避免這個情況發生。也就是說,如果你的pdata有值,那generator也應該要產生值。也就是說,對KL divergence說,如果你的pdata的distribution,它長得是這個樣子。
link |
如果你的generator,當然你的generator如果可以產生兩個高權的話,這樣是最好,這樣KL divergence最強。如果強過你的generator只能夠產生一個高權,因為你generator capacity不夠,它只能夠產生一個高權的時候,就是說generator它傾向於覆蓋住所有pdata存在的位置。
link |
有pdata在利用,pdata有的地方它都要有。就算機率不一樣也沒有關係,pdata有的地方它都要有,免得出現算出KL,KL divergence算出無窮大的原因。
link |
如果是這個狀況下,如果你的minimizer是KL divergence的話,你好像就比較不會出現mode collapse的情形,因為所有的mode,照理說你的pg都應該要cover到,免得產生無窮大的KL divergence。
link |
但是如果你今天minimizer不是KL divergence,而是reverse KL divergence,也就是你把pg跟pdata的順序調過來,本來是左邊pdata右邊pg下面,左邊pg右邊pdata,把pg和pdata順序調過來,那這個時候,什麼時候會產生無窮大的值呢?
link |
如果說今天怎麼都產生無窮大的值,如果pg有值,而pdata沒有值,也就是說今天只要pg它在某一個pdata機率是在某一個沒有data的地方它產生了某一筆data,那就會產生無窮大的divergence。
link |
或者說今天只要pg它產生,假設現在做的是image generation,只要pg產生的某一張image它不像是真正的image的話,那就會產生無窮大的reverse KL divergence,那這會造成你的pg在它分佈的時候是非常保守的,它寧可不斷的產生同一張realistic image,它也不要冒險產生一些不一樣的image。
link |
或者在這個圖的例子裡面,假設你pdata分佈是藍色distribution,那你pg它會想要固守在某一個distribution,如果它今天pg它只能有一個distribution,它會想要固守在某一個distribution,如果它今天只要在某一個pdata沒有的地方產生一些機率,它就會產生無窮大的reverse KL divergence。
link |
所以原來呢,原來人們以為說今天之所以會產生mulcollapse的狀況是因為我們在minimize的是reverse KL divergence,machine是看著reverse KL divergence在學習的。
link |
如果你看原來的game的話,它在調它的generator的時候,它的generator function裡面確實有reverse KL divergence這項,但是Ian Gunfellow在他的tutorial裡面有提到說,事實上你有辦法直接minimize likelihood,有辦法直接minimize KL divergence,因為你可以自己設那個v那個function嘛,所以你有辦法直接minimize KL divergence。
link |
就算直接minimize KL divergence,這個問題也沒有真的被解決。
link |
那其實呢,game的東西很多,我們就之後再慢慢講。我這邊胡亂列出一些例子,只是想告訴你說有很多,有各種game這樣子。然後比如說,有一些是只是改了那個optimization的方式,然後光改optimization的方式裡面就有兩個LS game,discrete game跟load sensitive game,它們都是LS game,有兩個LS game。
link |
然後有一些是改了那個structure,改了structure也有很多種。其實光那個by game啦,by game其實有兩個by game,而且都投在那個icare裡面。我發現比較多人讀其中一篇,那是因為那一篇呢,它的名字沒有game,另外一篇propose是一模一樣的方法,那propose的方法裡面名字沒有game這樣子。
link |
好,那我們講一下那個,我們很快很快的先講一下conditional game的概念,如果不清楚的地方我們可以下一次把它講得清楚一點。
link |
為什麼我們要講conditional game呢?因為我們的作業三就是要做一個conditional game啦,我們作業三就是要做一個image的generator,就是輸入文字產生image這樣子,然後細節就讓助教下周來講。
link |
我們知道說這個test其實有很多人做,有現成的corpus,那你在網路上就可以載到一些現成的corpus、現成的code,然後按下enter就可以得到結果。那我們用的不是現成的corpus,是助教花很多時間自己collect,下周我們就留給助教來講。
link |
反正我們要做的事情就是認一個generator,這個generator它不是憑空產生random的image,像我剛才講的那個動漫角色是憑空隨機產生的,你沒辦法控制它要產生什麼。這個conditional game就是要控制你的generator可以產生什麼。
link |
所以我們要做的事情是input一個文字敘述,然後希望generator可以產生對應的image。為什麼在這個test需要用到pair呢?你可能會想說,這不就是個supervised problem嗎?
link |
我們現在有一大堆的文字和image的pair,我們現在那個文字用c來表示,image用x來表示,因為這個文字是condition,所以我們用c來表示。我們有一大堆c跟x的pair,你們就一認一個supervised learning的network就好了嘛。
link |
input description output就是image,這有什麼不好認的呢?現在的問題是這樣,如果你只是一認一個supervised discriminator的話,一般的nn就是input一個東西,output一個東西嘛,input一個point,output一個point。
link |
但是今天如果你要做test to image的test的話,你可能會遇到一個問題,如果input的test是比如說火車,火車有好幾種樣,它可能有橫著看的火車,有可能有直著看的、迎面而來的火車,它們都是火車。
link |
在你的database裡面,你會label說,看到這個火車有這個image,看到這個火車有這個image,看到這個火車有這個image,看到這個火車有這三張image,這六張image。
link |
對nn來說,input同樣都是火車這個敘述,那它要找一個output去minimize,對這六張image同時做minimize,你找出來的其實就會是這六張image的平均,對不對?所以如果你直接把test to image這個test當作一個一般的supervised learning的problem,
link |
做下去的話,其實你的output往往就是會非常的模糊,等一下我們會看一些文獻上的例子,看到你產生的output就是會模糊,這個不是我們要的東西。
link |
所以我們要的是什麼呢?我們希望用一個gain的generator,這個gain的generator它的output,它這個gain的generator它有兩個input,一個input就是condition,如果它test to image的test裡面,input就是文字。
link |
另外一個就是prior的distribution,比如說從normal distribution裡面sample一個Z,丟到generator裡面去。因為這個g它吃的是C跟一個從distribution裡面sample出來的Z,所以它output的這個x也會是一個distribution,對不對?
link |
只是x這個distribution是dependent on C的,你input不同的C,output的distribution會是不一樣的,但它們output的都會是一個distribution。所以這個condition,ok,你的generator所output的x,它就是要去approximate一個distribution,這個distribution是p of x given C,給它不同的C,它的output distribution都不一樣,但它就是一個distribution。
link |
如果你看在文獻上的話,實作上這邊有一點小小小的問題,是其實那個generator有時候它會認到說無視那個prior distribution,因為prior distribution是一個noise,所以它就學一學就無視那個prior distribution,會變成說你input一個C,就算給它不同的prior distribution,output結果也是一模一樣。
link |
那要解決這個問題有一個方法是說,其實我們那個distribution不一定要是一個,你不一定要input一個distribution,你只要讓你的network的output有一些random的效果就好,所以一個解決的方法是在generator裡面加抓抱,你給generator加抓抱,它會沒有辦法無視那個抓抱,所以它的output還會是一個distribution。
link |
好,在這個conditional的git裡面,我們的discriminator有兩種版本,一個版本是它就吃一個image,然後output一個scanner,你就run一個binary,classify,input一個image,告訴你說這個image是不是realistic,那這麼做的performance會比較差,因為這麼做的壞處就是你的machine沒有認到說看到一個condition應該產生什麼樣的image,
link |
它只會認到產生realistic的image,但是它會產生無關的image,就是說它可能你輸入一個go,然後畫一隻貓子,畫出來是一個很像的貓,但是也不是你要的東西,所以我們要的不是這個第一版本的discriminator,
link |
我們要的是version 2的discriminator,這個discriminator吃一個c跟一個s,吃一段敘述跟一張圖片,然後它evaluate這個圖片加敘述的pair,這個圖片加敘述合起來的pair,它有多realistic。
link |
那真正在做training的時候,你會有description chat跟對應到description的真正的image xhat,在train這個discriminator的時候,你會有positive sample,這個discriminator看到training data裡有的chat跟xhat,
link |
它會output正值,它會output positive value,但是你要給它一些negative value,你要給它什麼樣的negative value呢?你把chat,把這個敘述丟到generator裡面去,讓generator產生一張image,你把這個真正的敘述加上generator產生的generated image跟discriminator去學,告訴它這個是錯。
link |
那同時呢,同時你也要input另外一種fake的example,另外一種fake的example是給它一張真的image,但是給它一個錯誤的敘述,給它一張真的狗,但是給它一個貓的敘述,然後告訴它說這個也是假的。
link |
所以你的next example可以有很多種。那generator它learn的目標就是希望它產生的pair,就是你input chat,output,把chat帶進generator的function裡面產生x,希望它產生的chat跟x可以騙過discriminator,讓discriminator覺得它是positive。
link |
其實這個text to image,我這個就是從文件上直接截下來的結果,我看有些結果都還做得蠻好,這個還驚人的好。
link |
比如這個是a picture is about to throw the ball to the batter,把這個敘述丟到generator裡面去,generator就output打棒球的場景出來,跟它說group of people on ski are standing in the snow,就產生滑雪的圖,所以有一群人在衝浪。
link |
假如說有一個人在衝浪,它就產生一堆衝浪的圖,或是讓它產生一些花,就說你要畫個白花,然後中間有黃色的花蕊,就畫一些花。
link |
然後說你要畫一些黃色花蕊的花,然後外面要有波浪狀的深紫色的花瓣,它就畫一些這樣。
link |
它就說你要畫粉紅色的花,然後還有小小的圓的花瓣畫出來,就是這樣子。這個程式網路上都有了,你直接載下來train其實就有了,所以我們不是直接拿這個Compass當作作業就是了,這Compass是助教自己蒐集的。
link |
助教試著跑了一下這些task,比如跑一下花的task,然後我說如果我們今天輸入一個比較怪異的description,會得到什麼樣的output呢?舉例來說,因為你知道其實有一個方法可以產生很realistic的image,怎麼做呢?
link |
我們現在已經有一大堆文字的敘述跟image的pair了,對不對?今天有輸入一個敘述進來,我就看說今天database裡面有沒有很類似的敘述,把它對照的image丟出來,我這樣產生就超像的。
link |
所以你輸入的敘述應該要是database裡面沒有的敘述,這樣才合理吧?比如說過去在做image generation的時候就要輸入一些荒唐的,比如說一輛公車在空中飛,看是不是真的可以畫一輛公車在空中飛,而且還真的畫得出來,就覺得說,欸,真的是有學到東西。
link |
我沒有check那個database啦,它輸入的是紅花,然後有黑色的花中心,然後我想說花應該是沒有黑色的中心吧,不過我沒有check database,它畫出來是這個樣子,所以確實有一個黑色的中心。
link |
然後,對,一模一樣的道理其實也可以用在image to image的translation上,這個我們就留著下次再講就好了。這個道理其實都非常簡單,剛才是input一段文字,output一張image,現在只是把input的文字換成另外一張image。
link |
input這種圖,output真正的街景,input衛星圖,output這樣子的圖,input幾何圖案,畫一棟建築,input黑白圖,畫橙色的圖,input白天的圖,畫黑夜的圖,input某個東西的邊,然後把那個東西畫出來等等,用conditional game來做。
link |
我們來看一下剛才那個lsgame到底有沒有跑起來啊。