back to index
Improved Generative Adversarial Network
link |
好,那趁同學一邊慢慢入座之前呢,我們就先很快的go over我們今天要上的內容,然後很快複習一下之前說過的東西。
link |
那今天呢,我們要繼續講Gan,然後上次呢,我們已經講了Gan的這個basic的idea。
link |
那今天呢,我們要更進一步講說Gan呢,它的unified framework是長什麼樣子。
link |
有一個unified framework呢,來統設Gan的這個process。
link |
那接下來呢,我們要講Gan的一個現在最知名的變化,就是WGAN。上次已經調查過了,隨便路邊sample一個人,通通都知道WGAN是什麼。
link |
然後接下來呢,在這個圖上的右半部,我們要講的是如何生成。
link |
也就是說,比如說,機器可以畫出圖,或者是合成出句子。
link |
那在這個outline的左半邊綠色的部分呢,我們要講的是轉換。
link |
給機器一個輸入,它把這個輸入轉換成另外一個東西。
link |
比如說像我們在座位裡面做的,給它一個句子,它把它合成一張圖片。
link |
或者是給它一張黑白的圖片,讓它合成出彩色的圖片等等。
link |
好,那等一下在講transformation的時候,又分成兩部分。
link |
一部分呢,是說假設我們有pair的data,另外一部分是更進一步假設我們是沒有pair的data。
link |
好,那我們先很快地複習一下我們上次說的內容。
link |
好,這個部分如果你覺得太快的話,你就舉手打斷。
link |
什麼意思呢?假設給機器看很多動畫的圖,它能不能夠自動畫出動畫的圖。
link |
我們上次已經示範過,畫出來就有這個樣子。
link |
如果擷取其中幾張的話,應該可以騙過87%的人。
link |
好,那這個要怎麼做呢?我們要用的技術就是generative adversarial的network。
link |
那我們知道說做這種生成的task其實有千千百百種的方法。
link |
舉例來說,如果你看B.M.Buffalo的教科書,它在第20章通通都是在講各式各樣的generative的model。
link |
但我們知道說,現在在做這種generative的model,最新的技術就是這個generative的adversarial network,也就是game。
link |
那其實今天他講的這些內容呢,並沒有在教科書上被cover。
link |
我相信你也沒有辦法在任何其他地方聽到,因為今天講的技術大部分都是在今年,甚至是一個月之前被develop出來。
link |
但我們這門課就是要這個,因為我們已經有另外一門機器學習的課,他講的是basic的技術。
link |
那我們這門課呢,就是要target在最前沿的技術,就是要與時俱進。
link |
好,那這個game呢,講的是什麼呢?
link |
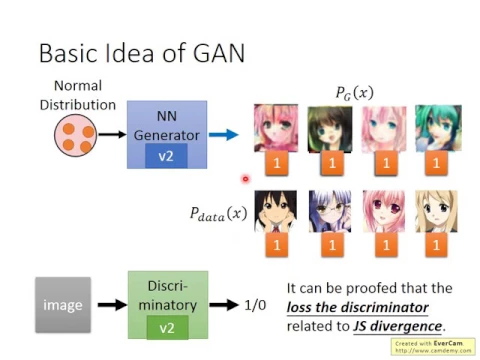
那basic idea是這樣,我們要做的事情是說,我們現在已經有一個target distribution。
link |
這個target distribution呢,我們寫作pθ的x,這個是我們希望machine可以生成的,可以找到的這個distribution。
link |
這邊的x可以是任何東西,在我們之前舉的例子裡面,x你就可以想成是一張圖片。
link |
好,在這個圖上呢,我們假設藍色的這個區域裡面,代表的是p of x的值是高的部分。
link |
而藍色區域以外的代表的是p of x的值是低的部分。
link |
而如果你從p of x的值是高的部分,去sample一個x出來,我們現在的x是image。
link |
所以你在藍色區域裡面sample出來的image呢,會是看起來像模像樣的image。
link |
如果是在藍色區域外面sample到的,就會是很模糊的圖。
link |
現在我們要機器做的事情就是找出這個pθ的x。
link |
這樣,你從這個pθ of x去sample出x的話,你就可以讓機器畫出以假亂真的圖了。
link |
那怎麼做呢?我們要找的是一個generator。
link |
這個generator呢,這邊用g來表示。
link |
generator就是一個neural network,我們知道neural network就是一個function。
link |
你丟一個東西進去,它就output一個東西出來。
link |
丟一個vector進去,它就output另外一個vector出來。
link |
所以現在如果你丟一個vector z進去,它就output一個vector x出來。
link |
如果x的dimension跟image一樣,你就可以把它看作是一張圖。
link |
那我們現在丟進去的x,其實不是一個point,而是一個normal distribution。
link |
如果我們丟進去的是一個normal distribution,那通過g這個function的轉換以後,
link |
那我們的輸出就是另外一個distribution。
link |
這個distribution是什麼,我們不知道。
link |
它可能不是你叫得出名字的distribution,比如說Gaussian mixture model等等。
link |
它不是你叫得出名字的東西,因為g是一個neural,它可能有很多個layer。
link |
所以經過這個轉換以後,你得到的distribution,
link |
你根本不知道是什麼,它是個異常複雜的東西。
link |
我們這邊就用Pg of x來描述它,來表示它。
link |
那麼這邊要做的事情就是,我們希望找到這個G,
link |
也就是調這個network裡面的參數,讓這個generator output的這個綠色的distribution
link |
跟藍色的distribution越接近越好,跟我們要找的這個distribution的越接近越好。
link |
這邊的難點是在於,我們沒有辦法直接去計算Pg of x,
link |
也就是說,給我們一個x,你沒有辦法算出Pg of x是多少。
link |
如果我們可以算Pg of x是多少,你可以maximum likelihood,
link |
但是我們現在沒有辦法算Pg of x是多少。
link |
所以給一筆data,我們根本不知道這個model產生這筆data的likelihood是多少。
link |
我們唯一能做的事情,只有sample。
link |
所以GaN的basic idea是這樣,有一個第一代的generator,
link |
一開始我們不知道generator的參數是多少,所以它幾乎是隨機的。
link |
然後呢,你給它從normal distribution裡面sample出一個橘色的點,
link |
丟到這個generator裡面,因為這個generator它是一個很弱的generator,
link |
它的參數幾乎是隨機的,所以它output的東西就是奇奇怪怪的圖,
link |
那你丟不同的點,你從GaN,你從normal distribution裡面sample多次,
link |
好,那接下來呢,我們要找一個discriminator。
link |
雖然我們要的東西只有generator,但是我們要另外訓練一個discriminator。
link |
這個discriminator它的作用呢,就是要來引導這個generator。
link |
我發現投影片上有一個錯誤,有人發現嗎?
link |
這個discriminator啊,就拼錯了這樣子。
link |
好,那我們丟一張,這個discriminator它做的事情就是你丟一張image進去,
link |
它會輸出一個0到1之間的值,那它代表的意思就是,
link |
這個輸入的image它看起來像不像是真的。
link |
如果輸入的這個image越像是真的,那這個discriminator輸出的值就越大。
link |
那同時我們會有另外一組真正的image,realistic的image,真正人化的image。
link |
那discriminator要做的事情就是,它要學習說這些generator所產生的image,
link |
它都是不好的,所以discriminator output的數值就要是0。
link |
那這個database裡面真正人手畫的image呢,那它輸出就要是1。
link |
那我們上次已經證明過說,這個discriminator它的loss跟
link |
這兩個distribution是有關係的。
link |
也就是說如果今天discriminator經過訓練以後,它的loss越大,
link |
代表這兩個distribution它們越接近,越沒有辦法被分開。
link |
那接下來呢,generator要做的事情呢,就是update它的參數。
link |
它希望update它的參數,使得它所generate的這些image會被discriminator label成1。
link |
就它希望update它的參數,使得它在產生image的時候,
link |
它產生的image會被discriminator誤認為是realistic的。
link |
那接下來呢,discriminator也會update它的參數,
link |
使得第二代的generator所generate出來的這些image被它判斷是0。
link |
然後呢,這些真正的image仍然被判斷是1。
link |
然後接下來呢,generator還會再update參數。
link |
這個process就反覆的進行,直到你覺得generator產生的image夠好為止。
link |
那這邊呢,有另外一個直觀的解釋來說明說,
link |
當我們有一個generator,有一個discriminator的時候,
link |
它們中間做的事情,到底是做了什麼樣的事情。
link |
這個藍色的,這個綠色的點啊,代表的是真正的data的distribution。
link |
也就是說,你可以想成每一個藍色的點代表的是人所畫的一張圖,
link |
如果你今天是要讓機器學會自動畫圖的話。
link |
那藍色的點代表的是機器現在的generator,它所畫出來的圖。
link |
那這個藍色的曲線,綠色的曲線跟藍色的曲線代表的是data的distribution,
link |
還有generator產的distribution。
link |
那discriminator做的事情呢,我們剛才說discriminator做的事情就是,
link |
它要讓綠色的那些點輸入discriminator以後,它的輸出就是接近1。
link |
藍色那些點輸入discriminator以後,它的輸出就是接近0。
link |
所以如果你訓練了一個discriminator,
link |
如果我們今天假設呢,是在一維的空間上,
link |
這個discriminator的輸入是一維的空間的話,
link |
那discriminator要讓綠色的這些點輸出是1,
link |
藍色的這些點輸出接近0,那它長的樣子可能就像是這個樣子。
link |
接下來呢,我們要調generator的參數,
link |
使得generator所產生的點,會讓discriminator覺得也是1。
link |
那如果我們要做這件事情的話,就會使得這些藍色的點,
link |
因為現在discriminator output1的地方是在這個區域,
link |
因為他們呢,也希望被discriminator認為是1,
link |
不過我們在調這個network的時候,
link |
你在調network的參數其實是很麻煩的。
link |
所以呢,你很難update一次參數以後,
link |
正好就落在你想要的distribution上面。
link |
所以有可能update參數以後,跑過頭了,
link |
那你現在generated藍色的distribution,
link |
跑到realistic的distribution的右邊。
link |
接下來呢,你就再訓練一個新的另外一個discriminator。
link |
這個discriminator看了這一組綠色和藍色的data,
link |
他要把藍色的dataassign值是0,
link |
這個時候,根據這個discriminator,
link |
因為藍色的點呢,會希望挪到讓discriminator的值呢,
link |
所以discriminator的值呢,就會,
link |
generator這些藍色點的值呢,就會往左移,
link |
那他們的process就反覆的在進行,
link |
你再產生一個discriminator,
link |
這個discriminator希望藍色的值是0,
link |
可能只能讓綠色的點的值比藍色的點稍微高一點而已。
link |
最後呢,當藍色點跟綠色點完全重合的時候,
link |
discriminator已經沒有辦法讓藍色點和綠色點有不同的值,
link |
這個時候discriminator會assign給藍色點和綠色點一模一樣的值,
link |
他會給這個空間上的每一個點一模一樣的值,
link |
這個時候呢,整個discriminator他就是平的,
link |
那這個時候呢,你的generator就沒有目標可以繼續去update,
link |
那這邊呢,其實有一個example,有一個toy example呢,
link |
就是告訴你說,實際上這整個process是怎麼運作的。
link |
在這個圖上呢,這是一個二維的平面啦,
link |
但實際上在真的要做realistic task的時候呢,
link |
你要產生的data point x是非常high dimensional的,
link |
那你要visualize就只能用二維而已。
link |
藍色的點代表real的data distribution,
link |
紅色的點呢,代表你現在的network generator的distribution,
link |
代表的是這個discriminator的value,
link |
那我們呢,實際來看一下這個generator跟discriminator呢,
link |
我發現說呢,我只要換回那個鍵號的時候呢,
link |
就是discriminator呢,不斷地改變他的方向,
link |
然後每次呢,都要把generator,
link |
那到最後當藍色點跟綠色點重合在一起的時候,
link |
discriminator沒有辦法給他們不同的值,
link |
他給這整個圖上每一個點呢,一樣的值。
link |
藍色的點是你的data generator的點,
link |
然後他會被你的discriminator呢,
link |
好,這整個game的process呢,就是這樣。
link |
那實際上我們在做game的時候,他是怎麼運作的呢?
link |
那這個algorithm我們上次是講過了,
link |
我們有一個discriminator,
link |
在每一個training的iteration裡面,
link |
我們都要sample m比data,
link |
我們要從我們的pdata裡面sample m比data,
link |
那pdata呢,就是你的影像的database,
link |
你就從你的影像的database裡面隨機抽取出m張圖片來。
link |
那接下來呢,你要讓你的discriminator也產生,
link |
呃,不是discriminator,說錯了,
link |
你要讓你的generator也產生m張圖片。
link |
那你的generator怎麼產生m張圖片呢?
link |
你要丟給他一個從normal distribution sample出來的vector,
link |
然後他從那個vector變成一張圖片。
link |
所以先從normal distribution,
link |
其實這個ppyalg不一定要是normal啦,
link |
呃,你只是通常都設成normal,其實他要是任何東西都可以的,
link |
好,我們一個ppyalg的distribution,
link |
大家從裡面sample出z1到zn,
link |
然後把z1到zn丟到generator裡面,
link |
我們用delta呢,來代表說這些x是machine generated出來的,
link |
好,那接下來我們要做的事情就是調整參數θD,
link |
調整discriminator的參數θD。
link |
這個discriminator的參數θD,
link |
他要做的事情是要maximize下面這個function。
link |
喔,呃,也許你已經忘了下面這個function是怎麼回事了,
link |
你會希望logD of x的值越大越好。
link |
一個realistic image discriminator要讓它的D越大越好。
link |
d log x delta是放在log1-D裡面,
link |
discriminator希望給real data比較大的value,
link |
然後呢,就用gradient descent去找一個θD,
link |
它可以maximize這邊這個式子,
link |
它可以maximize這邊這個式子的detail。
link |
我們就找到了我們的discriminatorVD。
link |
根據原來的GAMEPAPER的建議,
link |
我們應該repeat這個processK次。
link |
她說,嗯,她雖然建議repeatK次,
link |
但是她personal並不repeatK次。
link |
好,那接下來呢,要train generator。
link |
剛才找了一個discriminator,
link |
接下來要train這個generator。
link |
再去sample n個vector,
link |
從predistribution裡面sample n個vector出來。
link |
我們希望找generator的參數θG,
link |
剛才discriminator要使vθ的值越大越好,
link |
現在generator要使vθ的值越小越好。
link |
我們再update generator的參數,
link |
讓它能夠minimize上面這一個式子。
link |
那我們就完成training這個generator,
link |
上一次只是很specific的告訴大家說,
link |
這整個game的framework,
link |
什麼是franchise的conjugate,
link |
這邊是這篇paper的reference,
link |
它這個generalize的framework呢,
link |
fgame是f-diversions game的縮寫,
link |
NIST 2016是去年的11月舉辦的,
link |
如果我們要一句話來summarize它的話,
link |
一句話summarize這個paper就是,
link |
discriminator是跟js-diversions有關,
link |
其實那個discriminator,
link |
它可以跟任何f-diversions有關,
link |
你可以設計你的discriminator,
link |
讓它跟任何f-diversions有關,
link |
那至於要選哪個f-diversions呢,
link |
f-diversions在做的事情是說,
link |
假設我們現在有兩個distribution,
link |
那這個P of X和Q of X分別代表說,
link |
從P跟Q這兩個distribution裡面,
link |
那在我們要考驗的process裡面,
link |
P是我們要找的data distribution,
link |
Q是你的generator的distribution。
link |
這個f-diversions的式子呢,
link |
然後把Q of X乘上f of P of X,
link |
那這個f它可以是很多不同的function,
link |
只要滿足下面這個constraint,
link |
那為什麼我們說這個f-diversions
link |
假設P跟Q這樣的distribution
link |
代到上面這個f-diversions的式子裡面
link |
我們又已經限制說f of E等於0,
link |
前面的Q of X不管Q of X的值是多少,
link |
如果P跟Q是一模一樣的distribution,
link |
f-diversions衡量出來就是0。
link |
0是f-diversions可以得到的最小值。
link |
如果你對convex function熟悉的話,
link |
這邊變成對P of X這個distribution,
link |
一個distribution做積分,
link |
f-diversions它的值一定大於等於0。
link |
f-diversions之間的東西,
link |
當你要量這兩個distribution,
link |
如果兩個distribution有點不一樣,
link |
那f-diversions如果你不熟悉的話,
link |
KL-diversions你總是知道的吧?
link |
KL-diversions就是一種f-diversions。
link |
如果f of X我們代X log X,
link |
或者是如果今天f of X代負log X,
link |
那你得到reverse的KL-diversions。
link |
你也可以弄一些你可能沒有那麼熟悉的,
link |
所以這個f of X可以是X-1平方。
link |
這個其實就是high square。
link |
好,那講了這個f-diversions以後,
link |
franchise的conjugate。
link |
這franchise conjugate是什麼呢?
link |
franchise conjugate是說,
link |
每一個convex function f,
link |
max括號後面又有f不知道在做什麼。
link |
你可能很難一次想這個f-star t,
link |
但如果我們試著只算f-star t的其中一個值,
link |
帶某一個specific的值是t1,
link |
x必須要落在f of x的domain裡面,
link |
必修科室有講super-null的,
link |
那這個值就是f star of t1。
link |
這整個function到底長什麼樣子?
link |
這其實就只是一個linear的function而已,
link |
你得到的就是一個constant啊,
link |
那它是一個convex function,
link |
就是f star of t也是convex。
link |
如果f of x等於x log x,
link |
把這個f拿去當作f divergence的f的話,
link |
我們就得到KL divergence。
link |
如果f of x等於x log x的話,
link |
好像如果我們對這些直線取它的max的話,
link |
看起來像是一個exponential function。
link |
它的conjugate f star t,
link |
是一個跟exponential有關的function。
link |
那x要代多少可以讓g of x最大?
link |
x等於exponential t-1的時候,
link |
exponential t-1會有幾值?
link |
你就得到了exponential t-1。
link |
你得到的是exponential t-1。
link |
它的conjugate得到的是x log x,
link |
你只需要把x改成P of x除以Q of x,
link |
這邊本來放的是P of x除以Q of x,
link |
然後把P of x除以Q of x,
link |
置換成P of x除以Q of x,
link |
max xt-F star of D,
link |
所以P跟Q的F divergence,
link |
積分over所有的x,Q of x,
link |
先計算P of x除以Q of x,
link |
我們假設有一個function叫做D,
link |
就突然天外飛來一個function叫做D,
link |
F divergence可以等於這個樣子,
link |
F divergence有一個lower bound,
link |
這個lower bound是什麼呢,
link |
這個lower bound是積分over所有的xQ of x,
link |
它output的T不見得是可以讓中括號的值最大的那個T,
link |
所以如果我們把這個T用D of x取代掉,
link |
它會變成一個lower bound,
link |
它會變成一個lower bound,
link |
它變成了一個lower bound,
link |
接下來這個就沒有什麼匪夷所思的地方,
link |
這個Q跟Q可以消掉變成P of x乘D of x,
link |
這個Q乘進去變成Q of x乘上F star D of x,
link |
我們不管找哪一個function來,
link |
它都是DF的lower bound,
link |
它可以讓這個F divergence最大,
link |
它可以讓F divergence最大,
link |
我們就可以近似這個F divergence了嘛,
link |
那我們就可以去近似F divergence了嘛,
link |
它是積分over x P of x D of x,
link |
減掉積分over x Q of x F star of D of x,
link |
就可以去近似一個F divergence,
link |
F divergence可以寫成這個樣子,
link |
我們知道F divergence可以寫成這個樣子,
link |
那這邊是積分over所有的P of x,
link |
積分over所有的x乘上P of x,
link |
這邊是積分over所有的x乘上Q of x,
link |
是從P這個distribution裡面sample x出來,
link |
是從Q這個distribution裡面sample x出來,
link |
我們接下來取F star乘以D of x的期望值,
link |
因為我們沒有辦法真的對所有的x做積分,
link |
假如給你一個distribution P,
link |
給你一個distribution Q,
link |
你能夠做的事情是從P裡面sample出一些data,
link |
我們現在假設有一個P data這個distribution,
link |
是我們要讓model去target的那個distribution,
link |
然後我們有一個generator的distribution,
link |
那我們的目標是希望P data跟PG呢,
link |
現在假設給你一個generator G,
link |
它所generated出來的data distribution PG,
link |
跟真正的data distribution P data,
link |
它們的F divergence有多大,
link |
我們就可以直接套用這個式子來進行計算,
link |
那你說本來F divergence不是就已經有一個式子了嗎?
link |
本來F divergence不是就已經有一個,
link |
那是因為我們沒有辦法算P data跟PG,
link |
從P data跟PG做sample,
link |
所以如果我們今天要算P data跟PG,
link |
我們要算P data跟PG它們之間的F divergence,
link |
從P data裡面sample一堆x出來,
link |
給定一個PG它跟P data的某種F divergence,
link |
找一個G它可以minimize這個式子,
link |
找一個G它可以minimize這個式子,
link |
這個F divergence的這個式子,
link |
我們要找最好的一個generator,
link |
你看我們用D來表示這個function,
link |
我們剛才在game裡面看到的discriminator,
link |
這個game的那個function一模一樣呢?
link |
只是game之前我們在講game的時候,
link |
跟minimize這一個divergence有關的事情,
link |
這一整套F divergence game的想法,
link |
你想要minimize的F divergence是哪一個,
link |
你就可以找出我們的那個V of GD了,
link |
game就只是這個F divergence的game,
link |
原來的game就只是這個F divergence game的一個特例而已,
link |
這個在F divergence這個paper裡面,
link |
那首先我們先改一下我們的notation,
link |
然後找一個最好的generator,
link |
它們都是neural network,
link |
所以我現在把G跟D都換成θG跟θD,
link |
它是一個double loop的algorithm,
link |
double loop的algorithm,
link |
先給定一個初始化的generator,
link |
上標T就代表說是第七個iteration,
link |
初始的時候的generator的參數,
link |
接下來給定這個generator的參數,
link |
去maximize這個function B,
link |
找出來的這個最好的discriminator,
link |
那因為今天我們要解一個argmax的花紋,
link |
你要做gradient descent,
link |
我們的objective function是要最大,
link |
我們其實是做gradient ascent,
link |
不是gradient descent,
link |
我們要做gradient ascent,
link |
你要iterate的去找這個θD上標T,
link |
你要迭代你的discriminator的參數很多次,
link |
你才能夠找出你的這個θD上標T這個參數,
link |
你要update你的generator,
link |
你要update你的generator,
link |
你要update你的generator,
link |
使得它可以讓V的這個value function的值變大,
link |
你就有了這個新的generator,
link |
然後就過完了一個iteration,
link |
你就可以去找新的discriminator,
link |
我們要updateθD的參數好多次,
link |
我們才能夠maximize這個式子,
link |
然後再回頭去updateθG很多次,
link |
這個Nyx 2016 tutorial裡面,
link |
為什麼他只update一次是ok的呢?
link |
在這篇F Divergence Gain的paper裡面,
link |
如果我們今天要optimize這一個function,
link |
下面這個algorithm也是可行的,
link |
下面這個algorithm可以證明它會是收斂的,
link |
所以下面這個algorithm也是可行的,
link |
下面這個algorithm是一個single step algorithm,
link |
就是θD update一次,θG update一次,
link |
discriminator其實也只要update一次就好了,
link |
我們就各update θD跟θG一次,
link |
我們可以用一個backpropagation,
link |
我們可以用一個backpropagation,
link |
怎麼用一個backpropagation算出這件事情,
link |
我們就算θG對V這個function的歸點,
link |
我們就算θD對V這個function的歸點,
link |
我們就算θG對V這個function的歸點,
link |
但是他們update的方向是不一樣的,
link |
那現在我們有了這個F divergence gain以後,
link |
讓他minimize任何F divergence,
link |
他列出了各式各樣的F divergence,
link |
各式各樣的F divergence,
link |
每個F divergence裡面都有一個F對一個function F,
link |
我們說他是一個convex的function,
link |
每一個function有一個F star,
link |
假設你要minimize某一個F divergence,
link |
你其實就是找一個D去maximize,
link |
任何F divergence要找出他的F,
link |
可是如果我要minimize F divergence,
link |
最後minimize的值不都是零嗎?
link |
F divergence最小都是零,
link |
就是讓你的兩個distribution一模一樣,
link |
generator distribution跟你的目標distribution一模一樣,
link |
最後還是就是讓兩個distribution一模一樣而已,
link |
minimize不同的F divergence有差嗎?
link |
假設我們今天要去acrossiment的對象,
link |
是一個Gaussian的mixture model,
link |
而你的generator只有一個single的Gaussian,
link |
你現在的target distribution長的是這樣,
link |
那你要只用一個Gaussian的distribution,
link |
去調這個Gaussian distribution,
link |
他的mean跟variance等等,
link |
讓他可以跟這個Gaussian mixture越接近越好,
link |
如果你今天minimize的對象是不同的F divergence,
link |
換句話說,如果你minimize的KL divergence,
link |
如果你minimize的是JSD divergence,
link |
他提供了一個有趣的toy example,
link |
這個有趣的toy example是說,
link |
他試了五種不同的minimize的對象,
link |
可以是KL reverse,KLJS Jeffrey,還有Pearson divergence,
link |
你train的時候是想要minimize哪一種F divergence,
link |
都用不同的divergence來算一下,
link |
假設你今天是用KL divergence,
link |
當作你testing data的evaluation,
link |
minimizeKL divergence,
link |
假設你今天是用KL的reverse,
link |
來當作你的evaluation的話,
link |
你當然在training的時候去minimizeKL reverse,
link |
那這件事情聽起來好像也沒有什麼特別,
link |
但是他其實給了我們一個很重要的issue,
link |
過去大家相信game沒有辦法得到diverse的結果,
link |
就大家覺得說game在training的時候,
link |
你的distribution往往都很狹窄,
link |
你train出來的generator,
link |
generate image的時候,
link |
可能generate出來的image,
link |
是因為我們在minimize的是JS divergence,
link |
如果你minimize的是JS divergence,
link |
你可以去minimizeJS divergence的時候,
link |
你得到的這個single mixture,
link |
他的distribution是比較小,
link |
如果你換成minimizeKL divergence的話,
link |
他的distribution會是比較大,
link |
我們在train game的時候去minimizeKL divergence,
link |
就可以解決我們說的game他generate的image,
link |
換成KL divergence看起來沒有什麼不同,
link |
沒有辦法產生多樣的image的問題,
link |
可能不是來自於我們minimize的是哪一個divergence,
link |
那W game的第一篇paper呢,
link |
我記得是今年一月的時候放在archive上,
link |
我們本來就是用F divergence,
link |
我們要minimize兩個distribution的F divergence,
link |
現在改成是minimize兩個distribution的,
link |
Earth movers distance,
link |
而Earth movers distance呢,
link |
其實就是Vessel stand distance,
link |
因為Vessel stand distance的關係呢,
link |
叫做令人拍案教學的W game很有關係的,
link |
誒你真的看過W game那篇paper,
link |
有真的看過那篇paper的同學可以舉手一下,
link |
所以其實大家也不完全是看vlog文章,
link |
所以發的時候應該是Vessel stand,
link |
我還知道另外一個很有用的冷知識就是,
link |
Earth Movers Distance,
link |
Earth Movers Distance是什麼,
link |
那Earth Movers Distance就是說,
link |
某一個Distribution P,
link |
其中一個Distribution P是一堆土,
link |
另外一個Distribution Q,
link |
P這個Distribution的位置鏟到,
link |
這個呢,就是Earth Movers Distance,
link |
這邊有PQ這兩個Distribution,
link |
PQ這兩個Distribution,
link |
他們的分布呢,是在一維空間上的分布,
link |
我假設PQ這兩個Distribution,
link |
如果PQ這兩個Distribution距離是D,
link |
好,所以這兩個Distribution,
link |
Earth Mover的Distance,
link |
Earth Mover的Distance,
link |
好,那現在,如果兩個Distribution
link |
有一個P這個Distribution,有一個Q這個Distribution,
link |
那如果你今天講的課程沒有不懂的地方,
link |
有這兩個Distribution,P跟Q,
link |
我們就稱之為一個Moving Plan,
link |
所以從右邊移過來,然後再從這邊移過來。
link |
這個地方要墊高,你把這邊的圖移過來,
link |
移到Q的Distribution的話,
link |
你定義出來的Distance就會是不一樣。
link |
方法的話,感覺Distance比較小,
link |
右邊這個方法感覺Distance比較大,
link |
所以如果你用右邊這個Moving Plan
link |
Earth Movers Distance圖就有好幾個不同的定義了嘛。
link |
這邊的方法就是,雖然有很多個不同的Plan,
link |
算出來的Average Distance最小,
link |
今天這個例子裡面最好的Plan是這個樣子。
link |
那最好的Plan呢,是底下這個樣子的。
link |
放到這裡,有的放到這邊,有的放到這邊,等等等等。
link |
那我們要用最好的Moving Plan
link |
Distribution,一個是P,一個是Q。
link |
一個Moving Plan可以把它用一個矩陣來
link |
來表示這個Moving Plan。那這個Moving Plan
link |
其實是同一個位置。所以把圖從這個地方
link |
會等於它,我們把這個Rho的值和起來
link |
會等於它,我們把這個Rho的值和起來
link |
這個Column的值和起來會是這個Distribution
link |
對,會是這個值。我們把這個Column的
link |
那你想想看,這個Constant是很合理的。
link |
所以,Rho的這個Element的和
link |
這個Column的和呢,要等於Q的機率。
link |
一大Moving Plan,有很多很多
link |
Moving Plan。所有的Moving Plan合起來呢,
link |
今天如果給定了一個Moving Plan
link |
Moving Distance是多少呢?
link |
Average的Moving Distance。
link |
Xq。那就Summation over
link |
再Summation over所有的Xp
link |
Earth Movers Distance,也就是
link |
Versus Stand Distance的定義,WPQ
link |
Earth Movers Distance
link |
比如說F Divergence,你就算下去就好啦
link |
這個要算Earth Movers Distance
link |
你要先解一個Optimization
link |
Problem,你要先解一個Optimization
link |
這個Distance,你沒解這個Optimization Problem
link |
要改成用Earth Movers Distance
link |
來Evaluate兩個Distribution的差距
link |
我們要Minimize Earth Movers Distance
link |
為什麼要Minimize Earth Movers Distance呢?
link |
是藍色這條線,而Earth Movers Distance
link |
是藍色這條線,PData是紅色這條線
link |
因為我們Update參數的時候是用Gradient Descent
link |
如果你是用JS Divergence
link |
這個Case它的JS Divergence
link |
這個Case它的JS Divergence
link |
這個Case的JS Divergence是零
link |
如果你用JS Divergence來看的話
link |
Earth Movers Distance
link |
它們之間的Earth Movers Distance
link |
是D0的話,這兩個Distribution
link |
它們的Earth Movers Distance就是D0
link |
它們的Earth Movers Distance就是D50
link |
它們的Earth Movers Distance
link |
隨著Gradient Descent的Update
link |
它的這個Greater Send Distance
link |
它的Earth Movers Distance呢
link |
那這樣你在做Gradient Descent的時候
link |
所有的F Divergence都可以寫成
link |
可是這個Earth Movers Distance
link |
它們的Earth Movers Distance
link |
找一個Discriminator D
link |
從Data Sample出來的X它的值
link |
越大越好,從G Sample出來的X
link |
One Listed的Function
link |
就在One Listed Function的這個Set裡面
link |
就是Earth Movers Distance
link |
那你找出來的也不是Earth Movers Distance
link |
不像我們在前面做的時候,D,我們說D是個Network
link |
它Capacity無窮大的話,它要是誰就可以是誰
link |
但是在Earth Movers Distance
link |
它這個Function符合下面這個條件
link |
我們發現說F of S1跟F of S2
link |
的距離就是Function輸出的變化
link |
會小於等於Function輸入的變化的
link |
這個Function它不是一個很猛烈變化的Function
link |
One Listed Function
link |
K等於1就是One Listed Function
link |
如果今天你的Function是One Listed Function的話
link |
One Listed Function,哪一個
link |
不是One Listed Function呢?
link |
給大家三秒鐘的時間考慮一下,根據左邊的定義
link |
K代1的話,你就知道Listed Function
link |
綠色的Function是One Listed Function嗎?
link |
那藍色的呢?你覺得藍色的Function是One Listed Function
link |
所以它不是一個One Listed Function
link |
One Listed Function的限制呢?
link |
這個FastestStand Distance
link |
這個One Listed Function的限制的話
link |
如果沒有這個One Listed Function的限制的話
link |
pData的distribution和pGa distribution
link |
One Dimension的Space上面的
link |
One Dimension的Space
link |
One Dimension的Space上面的
link |
我們都假設它是One Dimension的Space上面的
link |
它們的這個EarthMoverDistance距離
link |
那我們都知道它是EarthMoverDistance距離
link |
那我們都知道它是EarthMoverDistance距離
link |
我們都知道它是EarthMoverDistance距離
link |
Best of Same Distance啊
link |
所以如果對Function沒有任何限制的話
link |
今天如果對Function沒有任何限制的話
link |
今天如果對Function沒有任何限制的話
link |
你的Pdata跟Pg沒有Overlap
link |
This One Listed Function這個限制
link |
One Listed Function這個限制告訴我們說
link |
那D這個function就不是One Listed Function了
link |
就不是One Listed Function了
link |
One Listed Function
link |
Vector Standard Distance
link |
它的Output是一個Sigmoid Function
link |
它的Output是一個Sigmoid Function
link |
然後你有藍色的Distribution
link |
那如果你要把藍色的Distribution
link |
要找的是一個Listed Function
link |
D of X跟這個位置的D of X
link |
符合這個One Listed Contract的話
link |
它可以讓這個地方Assign的值是K
link |
這個時候你會發現這兩個Distribution
link |
它們中間的Discriminator
link |
紅色這些點是Generator的Output
link |
你根本沒有辦法挪動Generator的Output
link |
讓它逼近這個Data Distribution
link |
所以這個時候,你的Distribution
link |
如果用Vector Static Distance的話
link |
就比較不會有這種歸電Vanishing的問題
link |
Optimization的Problem呢
link |
One Listed Function的限制
link |
歸電Descent或歸電Ascent來
link |
他說不然我們做Weight Clipping
link |
Weight Clipping是什麼意思呢
link |
我們學的這個Network它的參數的值
link |
因為你知道做歸電的時候你參數Update以後你根本沒有辦法控制它的Range在哪裡
link |
這個Clipping在另外一個地方也會做
link |
這個Gain在Trend Down的Gain的時候
link |
你會對這個Weight做Clipping
link |
做Weight Clipping這件事情
link |
是一個One-Lifted Function嗎
link |
是一個K-Lifted Function
link |
當我們對W的Weight做出限制的時候
link |
意味著說我們對Network的Input
link |
那這樣子如果Output的變化是有限的話
link |
就可以滿足K-Lifted Function
link |
可是不是要滿足One-Lifted Function嗎
link |
滿足K-Lifted Function行嗎
link |
會在Basis and Distance
link |
會在Error Mover Distance前面呢
link |
所以跟原來的Error Mover Distance呢
link |
放寬到找K-Lifted Function
link |
而不侷限於One-Lifted Function
link |
如果你對Weight做Clipping
link |
你可以保證它滿足這個Constraint
link |
但並不代表滿足這個Constraint
link |
都是符合這個Weight Clipping
link |
都是符合這個Weight Clipping
link |
如果做Weight Clipping的話
link |
我們Search Space其實只是
link |
這個限制的一個Search Space
link |
今天如果你有藍色橙色這兩個Distribution
link |
它們是沒有Overlay就長這個樣子
link |
歸間Decimal Maximize
link |
你會Assign給藍色這個地方的值無窮大
link |
假設你的Discriminator是一條直線的話
link |
你會得Sample一些Real的Object
link |
你會Sample一些Generated Object
link |
你的Discriminator的參數
link |
如果在實作上WGAN其實只要改幾個地方
link |
原來這邊這個V這個Function的第一項
link |
那個MessageStandDistance
link |
那個EarthMoveDistance式子的話
link |
從Generated的Model裡面Sample出來的X Delta
link |
就不需要Sigmoid Function
link |
我們D的Output就不需要Sigmoid Function
link |
因為原來你需要有Sigmoid Function
link |
原來沒Sigmoid Function
link |
如果你的Output是隨便都可以的值的話
link |
你要讓你的D of X介於0到1之間
link |
另外一件事情就是你要做Weight Clipping
link |
這個就是Weight Clipping
link |
把Log-E-D of G of Z
link |
然後在第一篇WGAN的Paper裡面
link |
用addon train WGAN的結果
link |
addon比較好 rmsplot比較差
link |
是你用CNN當作你的generator
link |
我們也是用CNN的generator
link |
第一個就是他沒有做fessionalization
link |
第二個就是他的structure是不好
link |
所謂structure不好的意思是說
link |
他每一個layer的filter的數目
link |
他告訴我們一個設計filter的準則
link |
就是每一層的filter都要是前一層的
link |
這種generative的model
link |
用你的baseline generate image
link |
然後自己再generate image
link |
那如果generator是NLP的話
link |
discriminator的output
link |
我們說discriminator的output
link |
你的discriminator的output
link |
你的model的performance
link |
你是在衡量JS divergence
link |
你每次都把JS divergence
link |
真的去量JS divergence的話
link |
你根本就不知道你的image generator
link |
你generate出來的output比較好
link |
不管output generator好或壞
link |
不管你generate的image好還是壞
link |
根本就不知道你generate的image
link |
你不要遵照原來衡量JS divergence
link |
這件事把你的discriminator train到底
link |
update是discriminator
link |
update discriminator
link |
這樣你的discriminator真正衡量的東西
link |
那他衡量的東西根本就不是divergence
link |
那你的discriminator output就變得沒有意義了
link |
這個時候discriminator衡量的是
link |
或是Earth movers distance
link |
他現在是真的在衡量這個distance
link |
而這個distance真的可以表示兩個
link |
distribution他們遠近的關係
link |
所以如果你看你的discriminator
link |
你從你的discriminator的loss
link |
是一個multilayer perceptron
link |
我們現在generate的image
link |
在vector distance很大的時候
link |
也就是你用deep convolution neural network
link |
我們如果量的是vector distance的話
link |
在vector distance很大的時候
link |
但vector distance下降得很快
link |
當vector distance一下降的時候
link |
所以如果你今天是train WGAN的時候
link |
也就是你的discriminator
link |
你可以看出你的image generate的好不好
link |
你的discriminator的loss大
link |
代表你的image generate的好
link |
他的loss小代表image generate的不好
link |
你就要generate a pinch image
link |
vector distance的變化
link |
這個時候有這種evaluation的
link |
你現在generate的image好或壞的
link |
vector distance一直都很大
link |
那你這時候generate出來的image
link |
這邊是你的generator跟discriminator
link |
那你generate出來的image都是爛
link |
這個時候measure set distance
link |
improve的wget它improve在哪裡呢
link |
我們要找一個one-axis function
link |
那我們之前是說就用weight clipping的方法
link |
one-axis function它有一個特性
link |
一個differentiable function
link |
如果它是one-axis function
link |
它是one-axis function
link |
improve的gradient的這個norm
link |
這個gradient並不是對d的參數
link |
d是一個neural network
link |
那個neural network裡面有一組參數
link |
就是neural wave跟bias
link |
這個gradient我們一般在做gradient descent的時候
link |
input對output的gradient
link |
對output d of x的gradient
link |
所以跟一般的gradient descent是不一樣的
link |
如果這是one-axis function的話
link |
如果它是one-axis function的話
link |
我們說一個function是one-axis function
link |
它就不是one-axis function
link |
如果它的gradient的norm大過1的話
link |
output的變化會比input還要大
link |
現在可以變成找所有可能的function
link |
但是我們在找這些function的時候
link |
max0 gradient的norm
link |
因為我們知道one-axis function
link |
因為這項只是像regularization一樣
link |
你找出來的function一定滿足這件事
link |
我們找一個distribution p penalty
link |
我們找一個distribution p penalty
link |
然後我們希望它所sample出來的這些x
link |
在計算對d of x的gradient的時候
link |
那這個p penalty到底應該是什麼呢
link |
uniform distribution
link |
是一個uniform distribution
link |
那你對p penalty做sample的時候
link |
一個uniform distribution
link |
他們選擇了一個特別的p penalty
link |
不是什麼uniform distribution
link |
這p penalty的distribution
link |
先從p data裡面sample一個點
link |
從p data裡面sample出來的點
link |
跟p generator裡面sample出來的點連起來
link |
所以你每次sample x的時候就用這個流程
link |
p penalty就是這個藍色的區域
link |
我們不要sample整個x的space
link |
有家癮號就是那篇paper裡面直接quote下來的句子
link |
enforcing this constraint everywhere is intractable
link |
enforcing this constraint everywhere is intractable
link |
enforcing this constraint everywhere is intractable
link |
enforcing it only along
link |
this straight line
link |
seems sufficient and experimental result
link |
in group performance
link |
discriminator目標就是要引導
link |
discriminator要做的事情就是要引導
link |
真正重要的其實只有generator
link |
the none of the gradient
link |
for differing from 1
link |
為什麼是penalize它不接近1這件事
link |
instead of just penalizing large gradient
link |
the optimal critic
link |
actually has gradient with none 1
link |
generator distribution
link |
better said this discriminator
link |
一個最好的discriminator
link |
discriminator值越大越好
link |
discriminator值越小越好
link |
one-listed function
link |
simply penalizing over large gradient
link |
also works in theory
link |
就這樣做也works in theory
link |
but experimentally
link |
we found that this approach converts faster
link |
and to better optima
link |
大家再自己check一下那個paper
link |
那我們來看一下paper裡面附的實驗結果
link |
如果你是用weight clipping
link |
跟gradient penalty的話
link |
如果你是用weight clipping
link |
跟gradient penalty的話
link |
你認出來的discriminator
link |
如果你是用weight clipping的話
link |
假設你clip在0.01和負0.01
link |
如果你是用gradient penalty的話
link |
你得到weight distribution感覺比較正常
link |
我們的true distribution
link |
如果你是用weight clipping的方法
link |
因為weight clipping的方法
link |
給了function的space很大的限制
link |
但是你在做weight clipping的時候
link |
但是如果是用gradient penalty的話
link |
discriminator跟generator
link |
其實還蠻早就被放到archive上面
link |
好再來第三個color是原來的WGAN
link |
generator跟discriminator都是定的convolution
link |
generator跟discriminator
link |
batch normalization的話
link |
如果今天是generator跟discriminator
link |
都用hyperbolic tangent的話
link |
但是這個時候WGAN還是有好的performance
link |
是multilayer perceptron
link |
而discriminator有用CNN的話
link |
然後看起來improved的WGAN
link |
而discriminator的structure是壞的
link |
就是說filter的數目沒有設好的話
link |
那improvedWGAN仍然有好的結果
link |
在不同的case就給他做不同的壓力測試
link |
還是會有比較好的performance
link |
他還可以拿來generate sentence
link |
怎麼generate一個sentence呢
link |
你可以把一個sentence這樣看待
link |
一個sentence比如說goodbye
link |
他其實就是character sequence
link |
第五個character是space
link |
表演符號你也可以把它都算成是character
link |
就我拿最後一個dimension表示space
link |
因為如果我們固定sentence的長度
link |
這個character的sequence當作
link |
如果你說寬就是一千個character
link |
如果今天產生的句子數目少於一千個character
link |
那但是你只要產生一百個character
link |
那剩下九百個character的位置
link |
但有沒有發現用game產生句子的test
link |
你想想看我之前想說要用game產生句子的時候
link |
你現在用neural network去產生
link |
你每一個color是一個distribution
link |
其他dimension的值很小0.000001
link |
所以這樣子對discriminator來說
link |
他要分辨real跟generator的image
link |
你的generator不管產生什麼東西
link |
discriminator都會覺得他是假的
link |
就是因為現在的real的sentence
link |
跟generated的sentence
link |
你可以generate出來的東西跟你真正的東西
link |
你永遠generate不出這樣子的結果
link |
如果你兩個distribution沒有overlap
link |
那這個是improvedWGAN的結果
link |
那他的WGAN輸出就是32個character
link |
如果你輸出32個character的話
link |
你可能會很擔心說WGAN可以產生一首好詩
link |
你想想看WGAN從來沒有看過真正的詩
link |
再產生七個character記得點一個句號
link |
我是產生五個character就點一個逗號
link |
我們現在不會講sequence game
link |
他比較像是actor creating
link |
但在sequence game裡面沒有這個process
link |
reinforcement learning
link |
這個我們之後講reinforcement learning的時候
link |
所以如果我們扣掉這種用reinforcement learning
link |
就是discriminator可以把它的歸點public給到generator的方法
link |
怎麼在兩類不同的action間的進行轉換
link |
就是conditional game
link |
他跟一般的supervised learning一樣
link |
你需要準備function的input
link |
舉例來說我們要做text to image
link |
你就要跟machine說看到a dog is running
link |
而bird is flying就產生這個鳥
link |
如果是用原來supervised learning的想法
link |
你輸入一個句子你會產生一個image
link |
舉例來說你輸入a dog is running
link |
你的machine的output你的urn的output
link |
不同的example之間的distance
link |
但是輸出的這個image你可以看成是
link |
所以x呢也是一個distribution
link |
來train這樣一個generator
link |
但他的output是一個distribution
link |
而你希望這個distribution呢
link |
像下面這樣子的distribution
link |
如果你是用game的方法來認你的generator的話
link |
你要用generator sample data的時候
link |
可以train discriminator
link |
我們作業也是text to image的test嘛
link |
這個generator input一張image output一個
link |
這個discriminator他要去maximize
link |
objective function
link |
你完全可以用wget的objective function
link |
你完全可以用wget的objective function
link |
就是discriminator對正確的東西分數越大越好
link |
然後你加一個weight clipping
link |
來train你的discriminator
link |
給他一些真的image當作positive example
link |
這些image丟到discriminator以後
link |
你要從generator裡面sample一些image
link |
當作negative example
link |
對discriminator來說這些image要越小越好
link |
那有另外一種discriminator
link |
這種discriminator他吃的
link |
他吃generator的input和output
link |
所以這個discriminator他會衡量兩件事
link |
所以對time2的discriminator來說
link |
你的positive example
link |
那你的positive example就是c的地方
link |
next example你要有兩種next example
link |
那因為discriminator要檢查
link |
是non-realistic是很奇怪的
link |
所以discriminator應該給他很小的值
link |
你的image是一個很正常的image
link |
如果你是用左邊那種discriminator的話
link |
好那這個conditional generator
link |
叫做image to image translation
link |
如果是原來supervised learning
link |
畫了這個幾何圖寫以後再去找下一個房子
link |
如果你是用一般的supervised learning
link |
的方法來train這樣子的network
link |
traditional的supervised learning的方法
link |
來learn一個network而不是learn一個
link |
gain train generator的話
link |
在testing的時候你輸入一個這樣子的房子
link |
同一個輸入在train data裡面可能對應到
link |
如果用gain train的話你要train一個generator
link |
distribution然後他output一張image
link |
discriminator去check說
link |
這個image他是不是realistic
link |
這個image他generator呢
link |
你其實還可以再加另外一個constraint
link |
跟你原來的target image越接近越好
link |
要讓你的generator的output滿足
link |
你在train這個discriminator的時候
link |
跟train這個generator的時候並沒有說不能加這個小閣樓
link |
那如果你有加這個constraint
link |
也有說generator的output還是要跟你的target image
link |
generator就比較不會亂加其他不存在的東西
link |
在我們剛才講的case裡面我們都假設有pair的data
link |
但是完全不要任何pair的data呢
link |
一個是disco game,那cycle game跟disco game
link |
cycle game這篇paper的結果
link |
這個generator可以把x domain的東西
link |
然後discriminator會去抓說
link |
所以他就是一個binary classifier
link |
因為你現在對他的要求只有產生泛古的畫
link |
他會失去轉回原來圖的information
link |
他原來保有原來的information
link |
把這個y到x動位的generator
link |
那我們也要產生一個generator
link |
然後這個generator跟這個generator
link |
這個generator跟這個generator參數
link |
但是它其實不是用cycle game
link |
那線上課程那個老色頭不是都會出現在右下角嗎