back to index
RL and GAN for Sentence Generation and Chat-bot
link |
繼續來講game這樣子。那我們今天要講的事情就是,怎麼用RL或者是game的技術來train一個sequence的generator,或者是train一個champion,那這個其實就是我們在作業室呢,要做的事情,所以呢,我們就先趕快來講說這個作業室要用到什麼樣的技術。
link |
那今天這個課呢,就算是你不熟悉RL,我相信呢,就算你不熟悉這個reinforcement learning,我覺得你應該也可以聽得懂。雖然我們說要用reinforcement learning來train一個champion,但我相信說就算你本來不知道reinforcement learning這個部分,你應該還是可以聽得懂的。如果你有問題呢,再問我,我會再發問。
link |
那我們先來複習一下,如果你想要做一個champion的話,你要怎麼做呢?其實這個我們之前已經講過了,那我們上週的作業室之一呢,也已經講過了這個部分。
link |
如果你要trainchampion,首先呢,你要在收集一大堆對話的data,這個網路上隨便載就有了,常用的有,比如說你拿電影的台詞當作這個對話的corpus,那就有A說了○○○,B說了○○○,A再說了△△△這樣。
link |
那你有一個encoder,你那整個champion呢,他有兩個部分,一個是一個encoder,另外一個是一個generator。那你就把B說的一句話,△△△這句話呢,丟到encoder裡面去,那encoder呢,就會把input呢,做encoder然後丟到generator裡面去,那這邊呢,你也可以用attention的技術呢,來讓你得到更好的performance。
link |
那generator呢,就丟一個句子出來,那generator跟encoder在學習的時候,他的目標就是希望呢,把B說△△△這句話丟到encoder裡面去,那generator output的sentence應該是A說的這句△△△△,因為△△△這個句子後面接△△△△,所以把這個句子丟進去encoder,希望透過generator以後,他的輸出呢,是接近△的這個句子。
link |
那你可能會說,那這樣machine不是就只記得前面,他只知道現在使用者輸入的句子,他不記得之前說過什麼話,或之前使用者說過什麼話嗎?
link |
如果你要考慮這個問題的話,你可以把之前發生的事情,當作額外的information,丟給encoder去學。假設你要讓checkbox記得說,他之前說過什麼句子,那你就把checkbox之前說過的句子,也丟到encoder裡面去,讓encoder呢,在學習的時候呢,也把過去的information考慮進來。
link |
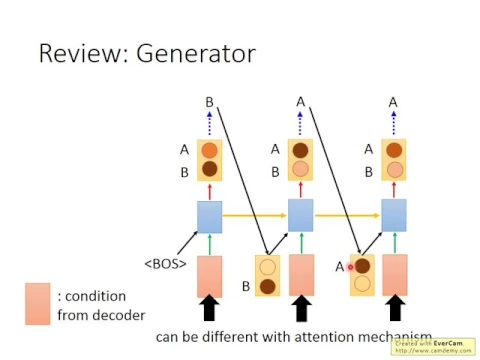
好,那我們來看一下encoder的架構。encoder的架構長什麼樣子呢?那假設你現在input的句子是,如果很好,那你就用一個RNN呢,把這個input的句子讀過一遍。
link |
那假設你的input同時有好幾個句子呢,為什麼input同時會有好幾個句子呢?因為我們說這個checkbox呢,要記得說他之前說過什麼話,或之前發生過什麼事。
link |
所以你的輸入呢,不一定是使用者現在輸入的句子,也包含了過去所有其他的information。我今天只用一個你好嗎這個句子來表示過去其他的information。那你要把過去什麼樣的information丟到這個encoder裡面,其實是看你自己決定。
link |
舉例來說,如果你今天想說你要考慮更複雜的test,你希望說checkbox不只是看使用者說的話,他還要看使用者的表情來決定他怎麼回應的話,那你其實就是把使用者的表情呢,假設你的checkbox是有攝影機的,那你就把那個攝影機所看到的那個圖呢,也丟到encoder裡面去。
link |
那這個checkbox在產生decode的時候,就可以考慮到video的information。總之encoder呢,可以吃各式各樣的information,depending on你現在要讓checkbox考慮這個多複雜的context。
link |
好,那如果今天input的information比較複雜的話,你可能就會需要一個hierarchical的這個encoder,也就是說,每一個不同來源的information呢,你可能都用一個encoder呢,把它們做encode。
link |
那你會有一個第二階的encoder,這邊用這邊畫成紅色的,你有這個紅色的encoder,他吃比較低階的兩個encoder的output,再把它再做一次encode,把它得到的結果呢,再去丟給generator。
link |
那generator長什麼樣子呢?我們之前在講sequence to sequence learning的時候呢,已經講過很多了。假設紅色的這個vector呢,是,這邊應該是encoder才對,不是嗎?
link |
這應該是encoder,紅色的vector應該是encoder。好,現在encoder呢,給了generator一個vector,然後呢,這個encoder給了generator一個vector,然後根據這個encoder的這個紅色的vector呢,
link |
那你的generator呢,就產生一個word distribution,代表generate出來的sentence的第一個詞彙。那你可能除了從encoder來的information以外,你還會丟一個特別symbol,這個特別symbol代表begin of sentence。
link |
OK,那現在呢,你的這個generator呢,它是一個RNN,它在第一個time step呢,先output一個word distribution。接下來呢,你會根據這個word distribution呢,做一遍sample。
link |
假設現在sample出來的是word B,那現在generator output的第一個詞彙呢,就是B。那接下來把這個B呢,變成一個code,往往可以用one-hot encoding呢,來描述B這個word。
link |
然後把B這個word的one-hot encoding,加上來自encoder的資訊,一起丟到這個RNN的generator裡面,在第二個time step,會產生另外一個distribution。
link |
那根據這個distribution,再做一次sample,假設這一次sample出來的是word A。接下來再把word A呢,接到再下一個time step。再下一個time step,RNN呢,會吃上一個time step output的word A,還有來自encoder的information,然後產生第三個step的output,然後再做一次sample。
link |
那這個紅色的vector啊,如果你今天有加attention的mechanism的話,這個紅色的vector呢,在每一個time step會是不一樣。
link |
在這個圖上有三個time step,如果你今天呢,有做attention的mechanism的話,那這三個紅色的vector呢,它的值呢,會是不一樣。
link |
好,再來呢,要怎麼train這個generator呢?在training的時候,你有標準答案。在training的時候,你有這個標準答案告訴machine說,現在應該要output什麼樣的sentence。
link |
那假設現在我們給machine標準答案是,應該output一個sentence,它有三個word,就是A,B,B。好,那machine呢,它呢,就會計算說,在第一個time step,它output的這個distribution跟這個reference的第一個time step的word,它們之間呢,有多大的差異性。
link |
你會算這個distribution和這個distribution,它們的cross entropy,這邊用C1呢,來表示第一個time step的distribution和標準答案算出來的cross entropy。
link |
好,接下來呢,在training的時候啊,會把reference,就是在testing的時候,會把這個network的output丟到下一個time step,但是在training的時候,會把reference丟到下一個time step。
link |
那我們之前其實也有討論過這個issue了,所以在training和testing的時候呢,有一些mismatch,那如果你要稍微處理一下這個問題的話,你可以用schedule sampling。
link |
那如果你不做schedule sampling的話呢,比較typical的做法就是,你現在的input呢,是這個reference的word,而不是你的network的output。
link |
好,那在第二個time step呢,你會產生第二個distribution,然後計算第二個distribution和正確答案之間的cross entropy。
link |
以此類推,你會得到第三個time step的distribution和第三個time step的正確答案算cross entropy。
link |
把每一個time step的cross entropy通通合起來,就是你要去minimize的對象,你就要調你的encoder和generator的參數,能夠minimize呢,在每一個time stepcross entropy的總和。
link |
那minimize這個cross entropy呢,其實就是maximize likelihood,怎麼說呢?
link |
好,那我們現在的training data是這個樣子,input h,應該output x hat,這邊h跟x hat呢,都是一個句子,都是一個word sequence。
link |
這個h呢,代表input的句子,或者是其他你想要缺乏考慮的history的information,或者是context的information。
link |
那x hat呢,代表說是正確的response,就是正確的,我們就應該輸出的word sequence。
link |
那xt hat呢,xt hat代表第七個word,x1t呢,代表x這個sentence的前七個word。
link |
好,那假設現在這個是generator的output,那上面這個是標準答案,那我們剛才已經講過說呢,我們現在要minimize的對象,就是每一個time step的cross entropy的總和。
link |
那每一個time step的cross entropy呢,舉例來說,第七個time step的cross entropy,ct其實可以寫成負的log pz,xt hat,given x,y到t-1,還有這個context,或者是historical information h。
link |
那這件事情呢,我想這個大家應該都知道,你只要把cross entropy的式子寫出來,就可以寫成這個樣子。
link |
所以呢,我們知道說cross entropy,其實就是在,minimize cross entropy,其實就是在maximize呢,log likelihood。那我們現在要把所有每一個time step的cross entropy統統合起來的話,那我們的整個loss function呢,就寫成負的summation over所有的time step,log p of xt hat,given x1t-1 hat,還有h。
link |
那如果我們把這個summation的項呢,把它展開的話,我們會有很多log項相加,那log項相加,我們可以把裡面的項呢,乘在一起。
link |
那所以我們得到的結果呢,就是負的log p of x1 hat,given h,乘上,這邊我本來想要寫2啦,真抱歉,這邊本來想要寫2,但大家知道我的意思了,我就是把這一整個sequence裡面的每一個機率呢,乘起來。
link |
那我們把這個sequence裡面所有的機率乘起來的話,那我們得到的就是p of x hat,given h。所以今天當我們實際上在training的時候,我們要我們去做的事情,就是maximize likelihood。
link |
我們要我們去做的事情是,假設我們給他一個總而言之,當我們給他training data是h跟x hat的時候,我們要我們去做的事情就是,給這個h,那我們希望說decoder output x hat的機率越大越好。
link |
所以傳統train這個generator的方法,我們又會叫做maximum likelihood的方法。那講正大家有問題嗎?沒有嗎?好。
link |
那接下來,這些你知道以後,我們就要進入怎麼用rl來做sentence generation,或者怎麼用rl來train一個chatbot。
link |
那怎麼用rl來train一個chatbot,啊我剛才忘了講一下,這第三堂課的時候呢,助教會來公告一下作業。怎麼用rl來train一個chatbot呢?
link |
我們今天假設在這個人和機器的互動的過程中呢,人呢,會給機器feedback,也就是說,舉例來說,今天人呢,跟機器說好阿姨。
link |
然後呢,機器就回說拜拜,然後人就很生氣,比如說他就給機器一巴掌,然後機器就拖著下巴嗚嗚嗚的哭。
link |
然後這個時候機器呢,就知道他得到一個negative的feedback。到底這個feedback怎麼來,其實就depend on你在實作的時候,你的系統怎麼設計。
link |
在作業裡面,你可能就會很直接的說,如果我們去回答這個句子,我就給他扣多少分數,或者是加多少分數。
link |
那在實作的時候,假設你今天做的其實是一個機器人,你可能可以有更豐富的方法呢,來讓機器知道說你要給他什麼樣的,什麼時候是positive,什麼時候他做的事情是positive,什麼時候他做的事情是negative。
link |
那實作上怎麼做就depend on你系統怎麼設計。舉例來說,你可以說你的機器他是有鏡頭,你的機器人他是有視覺的,他可以辨認人的表情,所以他可以知道說這個人不高興了,那他就得到negative的feedback。
link |
或者是他有觸覺的,他知道說你揪住他的領子,揍他幾拳肚子的時候,就代表說人在生氣了,等等。
link |
所以你有不同的方法可以給機器feedback。那這邊就是假設說,不管你有什麼方法給機器feedback,這些feedback都會被劃成一個分數,都會被劃成一個scalar,劃成一個real number。
link |
所以今天機器回答很差的時候,人就給他-10分。或者是在另外一個case,人說hello,機器說hi,然後人覺得這個回答是很好的,那可能給他摸摸頭。
link |
摸摸頭這件事情就被轉成正的分數,比如說是正的feedback,比如說是3分,等等。那現在機器要做的事情就是,他要學會根據這些過去的互動的資訊,他要maximize他未來預期可以得到的領悟。
link |
這件事要怎麼做呢?我們再把剛才,剛才是用比較圖像化的方式來說明機器和人之間的互動,那現在我們用更具體的方式來說明一下機器和人之間的互動是怎麼回事。
link |
現在假設有一個h當作你的check bar的input,check bar有一個encoder,有一個generator,ok,有一個h當作encoder的input,然後generator會output一個x。
link |
那他就是一個function,他是一個橙色的function,那這個function他做的事情就是,如果你給他看machine的output x,還有input,現在input給machine的history的information h,這個h是給machine的input,x是machine的output。
link |
那人要做的事情就是衡量說,當給這樣的h,machine有x這樣的output的時候,這樣做對不對。
link |
那這個做的到底好不好呢?就用R0hx來表示,那R0hx是一個數值,這個數值是我們把人想成一個function的時候,input h跟x的output就是R0hx。
link |
那今天machine要做的事情是什麼呢?當machine有了這個human會給他這個reward的時候,這個值叫做reward,當這個機器有這個人會給他reward的時候,機器要做的事情就是他要去調整他的參數。
link |
我們等一下把encoder加generator合起來的參數用theta來表示,那encoder跟generator都是RNN嘛,都是neural network,那他們合起來的參數我們用theta來表示。
link |
那我們現在要做的事情就是去update這個參數theta,使得說未來把h跟x丟到human這個function裡面,可以得到的output越大越好。
link |
那首先我們要定義一下什麼叫做expected reward,那我們可以把expected reward寫成下面這個式子,那我們用Rbar下標theta來表示它。
link |
所謂這個Rbar下標theta的意思是說,假設machine的參數就是theta,假設chipbar的參數就是theta,他未來都用theta這個參數來跟使用者互動,那他期待得到的reward有多大?
link |
那這個東西怎麼把它寫成一個式子呢?你可以寫成下面這個樣子,submission over所有的h,就submission over這個世界上所有可能可以給machine輸入的input。
link |
那當然這個input呢,每一個input有不同出現的機率嘛,所以這邊有一個p of h代表各個不同可能的input h呢,他出現的機率。
link |
好,窮取所有可能的h,然後呢,再submission over所有可能的response,給一個input的時候,給同一個input的時候呢,其實machine會有不同的response。
link |
為什麼呢?你想想看,我們這個Rn的generator,他本身是有隨機性的,對不對?Rn的generator在每一個time step,他要產生一個句子的時候,他在每一個time step,他會根據distribution做一次sample,對不對?
link |
那這個sample他本身是有隨機性的,所以給同樣一個h,通過encoder把code丟給generator,每一次得到的output不見得是一樣,但是這個雖然說有隨機性,但這個分布是固定的。
link |
所以我們可以寫出一個機率,p theta of x given h,就是給定這個h這個參數的時候,給定encoder跟generator的參數theta的時候,再給定h的時候,machine output x的機率有多少。
link |
然後我們再submission over所有可能的output x,然後我們再把所有的h跟x拿去這個human的function去做衡量,看看說這個h跟x的pair對人來說有多好,或者是多不好。
link |
那我們就得到了給定一個參數theta的時候,期望的reward。那接下來我們要做的事情是調整參數去最大化reward,調整參數去最大化這個期望的reward。
link |
找一個theta,它可以讓r把theta的值越大越好。這件事要怎麼做呢?這件事聽起來有點難,因為你不知道怎麼submission over所有的h,你不知道怎麼submission over所有的x,這件事情聽起來有點難。
link |
這個submission over所有的h跟submission over所有的x這件事情可以寫成,這邊我們要算一個期望值,我們從p of h去sample h出來,然後我們從這個p theta of x given h去sample x出來,再計算r of hx的期望值。
link |
這個第一個式子等於右邊這個式子,我想這對大家來說應該是沒什麼問題。那我們其實可以寫成這樣子,就根據p of h去sample一個h出來,給定h以後再根據p theta of x given h去sample一個x出來,然後計算r of hx的期望值。
link |
我想這個對大家來說應該也沒什麼問題。但是我們沒有辦法真的計算對所有的x和h做積分以後所得到的期望值,所以怎麼辦?實作的時候我們就是去做sample。
link |
你就是,如果你想要算出given某一個theta現在reward的期望值的話,那你要做的事情就是你現在給machine不同的輸入,給它大n的輸入,給它h1到h大n不同的輸入,然後看它會有什麼樣的response。
link |
假設它的response是x1 x2到x大n,接下來你就把hi跟xi的pair丟到這個reward function裡面,讓machine去計算一下它的reward,再把這n個可能,你sample到的這n組h跟x的pair拿去計算平均的reward,那你可以拿這個東西來近似reward的期望值。
link |
我們可以用sample來取代實際做summation這件事情。
link |
但是當你這麼做的時候呢,你就遇到一個麻煩,什麼樣的麻煩呢?我們現在如果要maximize這個式子,顯然你是用gradient asset,也就是你需要拿這個theta去圍rbar這一項,你要拿theta去圍rbar這一項。
link |
但是如果我們所謂的rbar其實是這一項的話,你會發現說現在做approximate,用sample得到的approximate這一項裡面是沒有theta,對不對?
link |
所以theta在哪裡?這個r是human的function,這裡面是沒有theta。那這個theta其實它是藏起來的,在這個式子裡面,theta它其實是隱含著的,因為在前面的式子裡面都有theta。
link |
在這個式子裡面,這個theta它是隱含著的,這個theta的值會影響到你得到什麼樣的training的example。
link |
這個theta的值會影響到你得到training的example,當然會影響到你最後加總的結果。
link |
但從式子裡面,你是看不到這個theta,theta影響的是sample,但是sample過後,那個theta就不見了。我們調整theta,我們可以影響sample到的結果,但是在這個式子裡面卻看不到theta,所以你根本沒有辦法算theta的偏微分。
link |
你沒有辦法算theta的偏微分,你就沒有辦法解這個optimization的problem。所以怎麼辦呢?這邊有一個trick,這個trick就是policy gradient。
link |
這個trick是這樣子,我們可以把這一項寫成這一項,那到底rtheta bar的gradient是什麼呢?
link |
如果我們把這一項取gradient的話,那對theta取gradient,對參數theta取gradient,那只有這個機率這一項,只有ptheta的x given h這一項,最後一項是跟theta有關的。
link |
所以做偏微分的時候,只需要為ptheta的x given h這一項,所以做偏微分以後你得到這樣的式子。
link |
那接下來呢,接下來做一件事情等於什麼都沒有做,把分子跟分母都乘上ptheta的x given h,分子分母都乘上一樣的值,所以完全不會影響最後的結果,等號仍然是成立。
link |
接下來呢,接下來重要的地方就是,這個式子,ptheta,對theta的偏微分除掉ptheta,ptheta的這個gradient除掉ptheta,會等於log ptheta的gradient。
link |
為什麼呢?式子就寫在右上角,你對log f of x,你有一個式function叫log f of x,你用x去微log f of x,你會得到什麼樣的結果呢?
link |
log裡面的項會放到分子,變成f of x分之一,然後x再去微f of x,所以你得到dx,d f of x。那我們這邊呢,只需要把f of x換成ptheta,那這個式子就是這個式子,那這個式子就是這個式子。
link |
那有了這些式子以後呢,我們看看前面這邊,我們有ptheta,有ptheta x given h,那我們可以把它寫成期望值的樣子,
link |
我們從p of h裡面sample一個h出來,我們從ptheta x given h裡面sample一個x出來,然後計算r of hx乘上這個log ptheta x given h的gradient的期望值。
link |
那所以呢,這一項,它的對這個機率分布的期望值,就是這個偏微分的結果,所以只要能夠計算這一項,你就可以計算偏微分,你如果可以計算這一項,你就可以計算這一項,你就可以做gradient of sample。
link |
那這一項實際上怎麼做的呢?實際上你還是做sample,你看到這個期望值呢,你就知道說,你應該要其實,你看到這個期望值你就知道說,實作上呢,我們其實是做sample。
link |
也就是說,你sample一堆的h跟x,然後你sample大n組的h跟x,然後計算r of hi xi乘上這個gradient log ptheta o,這邊應該要有xi given hi,這邊少了i,這邊應該要有xi given hi。
link |
那總之呢,現在gradient變成這個式子,你只要能夠寫,你只要能夠算這個式子,你就可以算gradient,你就可以update你的參數,你就可以maximize expected reward,就可以maximize reward的期望值。
link |
這邊是對的,你看,這邊是有加i的,不知道為什麼在上一頁裡面,i就不見了。那總之就是這麼回事。
link |
那這個式子呢,如果你要知道它的物理意義的話,那你看一下,它的物理意義是這個樣子的。現在如果說,r of hi xi是positive,也就是根據人給的feedback,根據人給的reward,輸入hi,machine回答xi,這件事情人覺得是很好的。
link |
那我們在調參數的時候,我們就希望update參數theta,使得machine在input hi,open xi的機率變大。
link |
如果今天r of hi xi是負的,也就是人覺得input hi,machine response xi這件事情是negative,是不好的,那我們就update參數theta,我們就調整參數theta,使得given hi,machine response xi的機率下降。
link |
所以這件事情非常非常的直覺,對不對?某一件事情如果是對的,某一個response如果是對的,之後我們就增加這件事情發生的機率。如果某一個response是錯的,我們就減少這件事情發生的機率。
link |
那實際上人跟機器在互動的時候,這中間會是有隨機性的,對不對?因為今天你的machine的response是有隨機性的,所以輸入同樣的input的時候,machine每一次的response會不一樣。
link |
那machine就會explode不同的response,如果某一個response是好的,是會得到高的reward,正向的reward,那machine之後就會多採取這種response,少採取那些會得到負向的response。
link |
那你可能會問說,好吧,那講到目前為止大家有問題嗎?好,沒有吼。那這個式子我想你都知道。
link |
實作的話,但問題是實作的話,要怎麼做呢?我們來看一下我們的gradient是這一項。我們要做的事情就是算出這一項,然後拿這一項去update data,來update name of all的參數。
link |
沒關係,我們可以把reinforcement learning跟maximum likelihood來做一下對比,你就會更發現說這個式子是非常有道理的。
link |
我們來看一下maximum likelihood,在maximum likelihood的train法裡面,我們有一筆training data,我們告訴machine說,machine根據那些training data知道說input h1叫output x1 hat, input hn叫output xn hat。
link |
那在training的時候,machine要做的事情是要maximize log likelihood,他要maximize given hi產生xi hat的機率。
link |
這是一般的training,這是maximum likelihood的training,這個大家都知道。在算gradient的時候,也沒有什麼特別的,我們對我們要maximize的objective function去做gradient的話,其實就是把log ptheta前面加一個gradient而已。
link |
好,那現在我們來看reinforcement learning,在做reinforcement learning的時候,我們已經知道他的gradient寫成右邊這個式子,如果我們知道gradient寫成右邊這個式子,你要反推他的objective function,其實很容易對不對,objective function就是長這個樣子。
link |
就是你把這個objective function做gradient的時候,你就得到下面這個式子。
link |
好,那在這個式子裡面我們看到xi跟hi,這個xi跟hi是怎麼來的呢?這個xi跟hi是sample來的,也就是說machine去跟人互動,他去互動n次,人給他h1跟hn的input,他response x1到xn,然後人會給他reward,人會給他說,每一個h跟xn的pair,每一個h跟x的pair,你做得有多好。
link |
每一個h跟x的pair,你做得有多好。
link |
然後呢,如果你看這個objective function,你會發現說他是非常有道理的。
link |
這邊我們sample到的這n筆data,就是training data,那每一筆training data,這n筆training data,每一筆都有一個weight,這個weight是這一筆training data,他的reward有多大。
link |
而reward值越大,這個training data,他的weight就越重。那有一些training data,他甚至是negative的,他是一個反面的例子,他的weight會是負的。
link |
那如果我們比較左邊跟右邊這個式子,比較maximum likelihood的式子和reinforcement learning的式子的話,你就會發現說,其實在做maximum likelihood的時候,我們等於也是sample了一堆的training data,但是這些training data,他們都有一樣的reward,而且他們的reward都是正的,都是設成1。
link |
這是很有道理的,因為這些training data就是正確的data,這些training data就是對的,懂了嗎?就是machine如果看到h1作為輸入,他最好的輸出,他的正確的輸出就是f1 hat。
link |
所以這邊每一筆h跟x hat的這些data,如果你要evaluate他有多好的話,你就會都給他一個正值,你會都給他一個正義的值。
link |
那如果你寫成objective function就是這個樣子。那現在我們這些data是sample出來的,是人跟機器互動的時候sample出來的,人也告訴機器說這邊每一筆data有多好。
link |
那你就拿這個evaluate reward去weight這邊的每一個log likelihood的小。所以如果今天有某一筆data,他越positive,今天在training的時候就會讓他的log likelihood越大。如果今天有一筆data,他的weight甚至是negative的,那就會讓他的log likelihood變小。
link |
剛講大家有問題嗎?我們作業就是要implement這個。那實際上到底要怎麼做呢?如果剛才講的東西你覺得沒有聽得很懂的話,事實太多了,而且又答錯好多地方,沒有聽得很懂,那怎麼辦呢?
link |
那實際上你要做的事情就是以下這個樣子。你有一個machine,你有一個chatbot,那這個chatbot裡面的參數我們先叫做setat,然後這個chatbot可能是一個sequence to sequence的level跟encoder跟decoder。
link |
那他跟人去做一下互動。跟人做互動的時候,他就會收集到一大堆互動的資訊,他知道說根據他現在的參數setat,他有一個初始化的參數。
link |
那根據這個參數setat,人輸入h1的時候,他就response x1。人會給他reward,告訴他說,如果我輸入h1,你去response x1的時候,你得到的reward是out of h1 x1。
link |
而如果今天人輸入h2,machine response x2,那人會告訴他說,你現在得到的reward是out of h2 x2,以此類推,你就sample個大N比data。
link |
接下來有這個大N比data以後,再來要做什麼?再來要根據這個大N比data去update你的參數。
link |
怎麼update你的參數呢?用的就是歸零的set。也就是說,你把setat加上某一個歸零的項,得到新的參數,setat加1。
link |
那這個歸零的項是什麼呢?這個歸零的項是這個樣子。submission over這N比training data,對每一筆training data都計算一下它的log likelihood的歸零。
link |
對這N比training data,每一筆都用setat算一下它的機率,然後取log,然後再取篇尾分,再取這個歸零,然後再乘上out of h1 x1,再乘上reward,那你就可以得到這項。
link |
如果是這樣子的話,這個程式大家會寫嗎?會寫的同學舉手一下。沒有人理我,不會寫的同學舉手一下。你是會寫的,是嗎?你不會寫,好,不會寫。
link |
好,沒關係,不會寫沒有關係。我們剛才說這個東西可以換成在objective的function上來看。現在我們的objective function是什麼樣子呢?objective function就是我們現在有一把training data,有N筆training data,
link |
那我們對每一筆training data,我們都要去maximize它的log likelihood,我們對每一筆training data,我們都去計算hi given xi的機率,然後前面會weighted by out of hi xi,然後再把它們全部上起來,然後你要去maximize這個objective function。
link |
這樣,大家會嗎?你想想看,我們今天本來在做training的時候,一般的training,我們沒有前面r這一項,不過這個r這一項就都是唯一。
link |
你今天唯一的差別只有,你在算你的objective function的時候,如果今天你用Piano或TensorFlow,你不是會定義你的objective function嗎?在objective function前面乘上一個weight而已,在你objective function的每一個example前面乘上一個不同的weight,這個weight是來自於reward。
link |
然後接下來說,這個怎麼算,你定好objective function,怎麼算微分,是TensorFlow的事情。這樣大家會嗎?會的同學舉手一下。
link |
有一些人會,太好了。不會的同學舉手一下。沒有人舉手,但還是有很多人沒有舉手,所以你可能是不會的。我再告訴你最後一招,假設你還是聽不懂的話,那實際上就是怎麼做的呢?
link |
假設這些reward都是正整數,有一些reward是1分,有一些是2分,有一些是3分,有一些是10分,它都是正整數,但實際上你可以不要是正整數,我們先假設它都是正整數。
link |
那你要做到讓machine根據這個objective function去maximize,你的方法就是,假設今天有一筆data,它得到的reward是譬如說正三分,你就把它duplicate三次。
link |
如果今天它得到的是正十分,就把它duplicate十次,如果它是正一分,就duplicate一次,如果它是零分,就不要把它放到training dataset裡面,然後再train下去,就跟原來的training的方法一樣,再train下去,就結束了。
link |
假設h1,x1它得到的reward是三分,你就把h1跟x1duplicate三次,h2,x2它得到兩分,你就把它duplicate兩次,然後就train下去。
link |
就用一般,你怎麼train,你之前怎麼train,你在作業2怎麼train,sequence to sequence,現在就怎麼train,sequence to sequence,作業2不是input每一個sequence to sequence,只是input是video而不是文字嘛,現在是把input video換成過sequence而已。那其他要怎麼做,其他該怎麼做的就怎麼做,只是現在training的data,有一些data被duplicate而已。
link |
如果這樣子,你覺得你還是不會的同學舉手一下。沒有人不會,所以大家都會了,對不對。就是這麼回事啦,好,假設你已經會了。
link |
接下來我們得到新的ht++1了,你就把ht++1取代掉,然後再去做sample就結束了,這個process要反覆很多次。
link |
好,那今天在實作上,這個機器一開始初始化的參數,你不一定要從random開始,從random開始機器一開始都回答一些完全是胡說八道的句子,那個train到什麼時候它才會有進步呢。
link |
所以通常你不會從random開始,你會先用一般的maximum likelihood的方法,先train一個初始的model,seda0,你會先用maximum likelihood的方法,根據你的training,先train一個seda0,然後再用seda0去跟人互動,再得到如果。
link |
好,那接下來呢,下一件要做的事情,這邊要做一個小小的修改,這個小小的修改是什麼呢?如果我們今天的reward永遠都是正的,可能會遇到一個小問題,什麼樣的小問題呢?
link |
本來在理論上reward都是正的,沒有什麼問題,因為假設我們現在就只有一個可能的h,然後有三個可能的output,x1,x2,x3。
link |
那這邊這個縱軸代表p,seda0,x,given,h的值。假設reward都是正的,那今天machine sample到h,x1得到正的reward,sample到h,x2也得到正的reward,sample到h,x3也得到正的reward。
link |
但是正的程度是不同的,你可不可以擔心說,這樣reward不就通通都上升了嗎?這樣reward不就這三個output,x的機率,因為這三個example,他們的reward都是正的。
link |
那你可不可以想說,這樣不是這三個pair,他們的機率都應該上升嗎?但事實上不會,因為這是一個機率,所以這三項的核要是1,最後train完以後,上升的reward較小的人,他的機率其實就下降。
link |
如果你的reward比其他人要小,比如中間這一項h,x2這件事情,他的reward比h,x1和h,x3小,在做完參數的update以後,之後machine就會減少h,x2的機率,轉而多採取x,x1和h,x3。
link |
所以就算是reward是正的,就算某一個pair,某一個example,他的reward是正的,但他的reward比其他example小,那他的機率也會下降。
link |
但是實際上的情況是不太一樣,因為實際上你沒有辦法把所有的h跟x的pair都sample過一次,你只能sample到部分,舉例來說你可能只能sample到h,x2跟h,x3,你沒有sample到h,x1。
link |
這個時候問題就來了,因為現在h,x2跟h,x3他的reward都是正的,那h,x1這個東西沒有被sample到,那做完參數的update以後是正向reward的機率都會上升,那沒被sample到的機率就下降。
link |
因為total機率的和要是1,所以如果這兩項的機率上升,那這一項的機率就下降,但是這一項是沒有sample到,我們根本不知道這一項到底是好還是不好。
link |
你說就算取期望值,你也應該取一個平均吧,他不好也不壞,你怎麼能夠在沒有sample過這個example的情況下就把他的機率下降呢?所以這件事不合理。
link |
假設今天reward都是positive的話,你得到的結果是,如果有某一筆data他沒有被sample到,某一個case他沒有被sample到,那這個case的機率就下降,有被sample到的case他的機率就上升了。
link |
如果你要deal with這個problem的話,有一個很簡單的solution就是把你的reward減掉一個baseline,就把你的reward減掉一個值b,假設你的reward都是正的話,你就減掉一個正值b。
link |
然後呢,讓這一項裡面的值是有正有負的。也就是說,原來根據reward,Hx2是正的,Hx3的reward也是正的,Hx1的reward不知道,因為沒有被sample到。
link |
但是如果我們加了一個baseline以後,可能Hx2減掉baseline以後,因為他的reward是正的比較小,所以他減掉這個baseline以後,他的reward就變負的。
link |
而Hx3減掉baseline以後,他的reward還是正的。那這樣就會變成說,Hx2的機率下降,Hx3的機率上升。那接下來會問的問題就是,怎麼找這個b呢?
link |
有很多不同的方法,等一下助教會講說,怎麼可以給大家找這個b的理念。你說哪一個方法比較好,其實我也不太確定,你就當作留言中間的題目來做做看。
link |
好,那我們講到這邊,我們先休息十分鐘,等一下再講,謝謝。
link |
那實際上在文件上有一個這樣的做法,這個做法看起來就像alphago一樣,雖然這個paper裡面沒有這麼說啦,但是我叫他alphago style的圈名。
link |
什麼意思呢?因為你要人一直去跟agent互動,要人一直去跟你的chatbot互動,很麻煩啦,人很忙。
link |
所以怎麼辦呢?任兩個chatbot讓他們互相互動,懂嗎?就是任兩個chatbot,現在藍色的機器人跟紅色的機器人都是chatbot,就讓他們互講。
link |
其中一個人講說,How old are you,另外一個人就講說,See you,然後藍色的人chatbot就說See you,然後紅色的chatbot就說See you,就陷入無窮迴圈。
link |
那你要設定一個停止的criteria,我記得在這篇paper的文獻裡面,他好像是說他定義了幾個句子,然後我們去講到那幾個句子,比如說I don't know, see you later,就結束這回合。
link |
或者是有機器人說How old are you,另外一個人說I'm 60,然後藍色機器人就說I saw you were 12,紅色機器人說What makes you think so,他們就可以自己去聊天。
link |
記得自己跟自己聊天,然後接下來你再自己define一個evaluation function,去計算在這個聊天的過程中,如果我拿一個H出來,拿一個X出來,這個reward有多大。
link |
那至於這個reward function,你要怎麼定,其實就是你自己定就是了,那paper上的做法不是最好,它只是一個例子告訴你說,我們可以定這個reward function去操控machine,回答的方式變得不一樣,或者可能是更好。
link |
至於怎麼定這個reward function在作業的時候,你就可以自己想一想,比如說你可以認一個不會說髒話的學霸,他只要說髒話就打他一巴掌,或者是認一個只會說髒話的學霸,他不說髒話就打他一巴掌。
link |
那在那個paper裡面是這樣定的,那detail我們就不要go through這個function的detail,因為這個是handcrafted的,你要怎麼定都行。
link |
就是說這個total的reward取決於三項,R1,R2,R3,那R1跟R2,R3中間有weight,量R1,量R2,量R3。那第一項R1叫ease of answer,等一下會解釋它是什麼。
link |
那第二項是information flow,第三項是semantic coherence,ease of answer就是要machine不要成為句點王,因為有一些回答是會讓整個dialogue句點,比如說有一些回答是比較無聊的,比如說I see, I don't know, see you later。
link |
那你講這句話以後下一個人就會接不下去,或者他也只能說I see, I don't know。所以第一項就是說希望machine它產生的response不要讓下一個句子,你今天產生的response不要讓下一個agent,另外一個agent要接下一句話的時候有困難。
link |
所以你希望你現在的agent說出這個句子的時候,另外一個agent它產生比如說I don't know的機率越低越好。
link |
那information flow意思是說希望machine不要反覆說同樣的話,所以這邊希望說machine現在說的句子跟它上一個回上一次說的句子差距越大越好。
link |
第三個是希望machine不要前言不對後語,就是說當agent A說一句話的時候,希望agent B說的話,它在語意上跟agent A問的句子是相近的,就不要前言不對後語。
link |
事實上我們人在對話的時候也常常會前言不對後語,舉例來說假設你跟一個外國人在聊天,但是其實你聽不懂他在說什麼的時候,有一個辦法可以讓這個conversation繼續下去,怎麼做呢?
link |
就是不斷轉換話題問他問題,就是你先問他一個問題,然後他就blah blah blah講一堆,但你其實沒有聽懂,然後你就再新開一個話題,然後再blah blah blah講一堆,可是每次都不斷的新開話題,你其實都沒有聽懂他在說什麼,那就可以讓conversation不斷的繼續下去。
link |
如果你有加這個semantic coherence,就會避免這件事發生,因為每一次你說的句子都必須要跟另外一個agent之前一次講的句子是有關的。
link |
總之這個東西reward怎麼定,就是看你自己可以定一些有用的reward。
link |
第七個方法就是還沒有用reinforcement learning的時候認出來的,那A跟B其實都是machine,A說where are you going,B說I'm going to the restaurant,然後A就說see you later,B就說see you later,然後A再說see you later,B再說see you later,就陷入無窮迴圈了。
link |
或者是A說how old are you,B說I'm 16,A說16,他不知道為什麼要懷疑一下,然後B說I don't know what you are talking about,A就說you don't know what you are talking about,B又說I don't know what you are talking about,然後就陷入無窮迴圈。
link |
那如果你有加前面那幾個reward的話,可能會讓對話稍微比較順一點。看那個實驗結果,感覺我加前面那幾個reward有一個很明顯的特徵是machine還比較擅長接話,他會希望這個dialogue繼續下去。
link |
比如說A說where are you going,就開頭是一樣,B說I'm going to the police station,那A並不是說see you later,他說I will come with you,他也要一起去,B就說no no no no no,A就說why,然後B就說I need you to stay here,然後這個句子就可以繼續下去,雖然這邊還是不小心做出I don't know what you are talking about,然後之後又會陷入無窮迴圈了。
link |
或者是A說how old are you,B說I'm 16,why are you asking,A說I saw you were tailed,然後B說what made you think so,A又說I don't know what you are talking about,B說you don't know what you are saying,然後又陷入無窮迴圈。
link |
但是他會比較晚陷入無窮迴圈,他可以撐比較久一點,然後我們去用了剛才那個reward以後,他比較喜歡反問,他感覺比較喜歡反問問題,然後他會產生比較長的句子。
link |
那我們今天講的東西啊,我都一直沒有提到reinforcement learning這個字眼,但用的技術就是reinforcement learning裡面的policy規定。
link |
那我不打算再重述說今天我們講的這個sequence to sequence learning跟reinforcement learning有什麼關係,因為這幾個投影片是我們之前上課就有的,是舊的投影片,我就跳過這一段。
link |
那唯一最後想要跟你說的事情是說,我們剛才使用reinforcement learning裡面的policy規定,它是重多技術裡面的其中一個。
link |
那還有別的advanced技術舉例來說,你可以用actor critic,那這邊我就列一個reference給大家參考,那等一下助教會來跟大家講一下說,如果要用actor critic產生句子的話呢,要怎麼做。
link |
好,那接下來我們講的就是怎麼用game來生成句子,或怎麼用game來train by alone,那這邊有一個很有名的技術呢,就叫做sequence game。
link |
那還記得說在sequence game發表在triple AI的那一周,我那一周在paper report的時候,聽了三個不同的人講sequence game,那時候聽了三次sequence game。
link |
好,那這個sequence,這個怎麼把game用在這個dialogue上面呢,或者是怎麼用在sentence generation上面呢,這個做法是很直覺的,就跟原來的game差不多。
link |
舉例來說,我們現在要做sentence的generation,那你就是有一個generator,那input呢,給他一個code,你先從predistribution,normal distribution裡面呢,先從一個code z,然後根據code z呢,generator就產生一個sentence x。
link |
好,接下來呢,你有一個discriminator,discriminator就看說呢,現在呢,discriminator呢,他會看說現在input的句子是generatorgenerate出來的句子,還是真正人寫的句子。
link |
假設你要做唐詩鍊成的話,那你就給discriminator呢,看唐詩三百首裡面的句子,然後判斷說,現在input的句子是唐詩三百首裡面的句子,還是generator所generate出來的句子。那我發現在實作上,不常看到,假設你現在要做的是output這個,一個句子的話,在sequence game裡面,他並不是從predistribution sample一個code來產生sentence。
link |
因為其實RNN他本身就已經有隨機性,所以其實你這邊就不再需要加一個predistribution來增加隨機性,因為RNN的generator本身就有隨機性,RNN的generator你把參數定好以後,
link |
他的output,你給他一組參數,他的output本來就是一個distribution,你每一次sample,你同一個generator你每次sample出來的句子,本來就不一樣,他本來就是一個distribution,所以當我們使用RNN到generator的時候,其實不需要input一個predistribution。
link |
那這個演算法就是這樣,這個很直覺,有一個generator,有一個discriminator,然後sample real的image x,然後叫generator generate fake的image x delta,那你希望任一個discriminator,他讓x的分數丟到discriminator裡面越大越好,讓x delta的分數丟到discriminator裡面是小的。
link |
那我這邊不把完整的式子寫出來,為什麼呢?因為這邊你可以用任何的game,你可以用原來的game,你也可以用大於game。
link |
那這邊是train,discriminator,接下來generator怎麼train呢?在直覺上想起來我們要做的事情就是,我們希望調generator的參數,我們要調generator的參數使得generator的output丟到discriminator以後,他的output的值是增加的。
link |
那等一下我們會發現說,做這件事情是有點麻煩,有一些問題,有一些tricky的地方,所以我們在這邊先打一個問號。
link |
那如果要認trainbar的話呢,其實也是一樣,如果要認trainbar的話,我們現在需要的就是conditional game,那我們作業3已經做過conditional game了,所以這個大家應該都懂懂懂,對不對?
link |
好,那現在我們有一個trainbar,trainbar裡面有encoder,有decoder,那trainbar的input就是你現在輸入的句子,或者是其他需要的information,output就是你的button的response。
link |
那在conditional game裡面你的discriminator的input是什麼呢?你的discriminator要吃trainbar的input,也要吃trainbar的output,他不能只吃trainbar的output,因為我們之前有講過說,在conditional game裡面你的discriminator,他要檢查的是這個h跟x有多匹配。
link |
你不能只檢查說x是不是realistic的,你還要檢查說這個h跟x有多匹配。那怎麼train這個discriminator呢?
link |
那你需要有真正的dialogue,你就需要去蒐集大量的真正的dialogue,那通常你都可以從電影或者從twitter上看說,人在給一個h的時候,他會有什麼樣的x。
link |
那discriminator要做的事情就判斷說,現在的這個h跟x的pair是來自於你自己train的trainbar,還是來自於真正人與人間的對話。
link |
這個都很直覺,這個演算法大家應該也是懂懂懂,就是有一個真正的historyh,然後根據data set,找一個generate一個sentence,就從data set裡面sample一個h跟一個x。
link |
然後再從data set裡面sample一個h,把這個h丟到generator裡面,也就是丟到你的trainbar裡面,得到response x.那h跟x是一個pair,h跟x是一個pair。
link |
那你要認一個discriminator,discriminator要給h跟x比較大的值,他要給h跟x比較小的值。
link |
而接下來train一個generator,這個generator要做的事情是,當我們把一個h丟到trainbar裡面,trainbar會有一個response x,把x丟到discriminator裡面,這個discriminator會給你的scatter。
link |
那我們希望調整這個trainbar內部的參數,調整encoder decoder的參數,去update encoder decoder的參數,讓scatter的output越大越好,讓這個discriminator的output越大越好。
link |
那到底我們現在把一個trainbar跟一個discriminator接起來的時候,會遇到什麼樣的問題呢?
link |
這個問題是這樣,在generator產生output的時候,其實這中間有一個sampling的過程。
link |
大家知道意思嗎?我們今天呢,generator它產生一個句子的時候,它在每一個timestamp,它是根據RNNoutput的distribution去做一個sample。
link |
它從這個distribution,sampleB,從第二個distribution,sampleA,從第三個distribution,sampleA。
link |
它在把,當我們把這個trainbar的output,trainbar的output是RNN的generator,sample的結果,把這個sample的結果再丟到discriminator裡面,discriminator可以output的scatter。
link |
那discriminator可能就是一個RNN,那你其實也可以用CNN,反正可以吃一個sequence,output一個scatter就行。
link |
那我們希望呢,調整這個trainbar,調整這個generator的參數,讓output的scatter的值越大越好。
link |
這件事情有辦法做嗎?如果在原來的game裡面,我們把generator跟discriminator接起來的時候,我們可以一路從discriminator,backpropagate到generator。
link |
但是今天在這個case,你沒有辦法,你沒有辦法,這個backpropagation通不過sample這一段,為什麼呢?
link |
你仔細想一想,什麼是gradient? gradient就是我們把參數小小的改變一下的時候,對它的output有什麼樣的影響,這個就是gradient。
link |
今天因為中間卡了一個sample,所以當我們把這個參數,就算你把這個sample改成,如果我們把這個sample改成argmax呢,也是一樣。
link |
如果我們把這個generator稍微改變一下,它的參數,對discriminator的output是完全沒有影響的。對不對?generator你稍微動一下它的值,如果你這邊是argmax的話,那output的sequence是不變的,discriminator的output是不變的。
link |
所以你沒有辦法計算這個generator,這個checkbox,對output的gradient,所以你沒有辦法用原來原始的game的方法去update參數。
link |
那你說不是可以用wgame嗎?之前在講wgame的時候,不是已經demo過用wgame產生sample產生參數了嗎?
link |
那wgame是怎麼做的呢?在wgame裡面,我們會把sample這個process,或者是argmax的process,就把它remove掉,當作沒看到。
link |
所以wgame的discriminator它吃的input就是distribution,它直接吃distribution當作input。那另外其實在wgame裡面呢,也沒有把這個sample的output當作下一個時間點的input。
link |
所以其實wgame裡面的handpaper,甚至它的generator不是一個RNN,它的generator其實不是RNN,只是CNN而已。
link |
所以我們等一下會講另外一個截然不同的方法,那到底另外一個方法跟wgame比起來,就c1game跟wgame比起來,performance有什麼樣的不同,也許可以把它當作留言終結者的問題來做一下。
link |
那現在CNN是怎麼做的呢?CNN的做法是這樣子,我們說我們要調這個缺乏的參數,讓discriminator的output越大越好。
link |
那我們可以把這件事情就想成是一個reinforcement learning的版本,我們把discriminator的output想成就是reward,我們把discriminator就想成是human。
link |
我們本來是用human,我們當然在講reinforcement learning的時候,我們在前一段的時候,我們是講說我們用human來evaluate缺乏的output。
link |
那現在我們改成用discriminator來evaluate缺乏的output,discriminator的output的值,discriminator判斷說現在缺乏的h跟x丟到discriminator的output的值有多大,這個就是reward。
link |
而我們要做的事情是說,我們要調整generator的參數去增加discriminator的值,這件事情就等同於是我們希望調整generator的參數,調整缺乏的參數去maximize reward。
link |
那這件事情,你會做嗎?我想你是會的,如果你上一堂課有聽懂的話,這件事情沒有什麼問題,我們只是把每個東西換個名字而已。
link |
我們只是把human換成discriminator而已,discriminator output的值就等同於是剛才human給的reward,所以什麼事情都沒有改變。
link |
所以在前一段我們講說,我們根據reward可以寫出這樣子的一個gradient的式子,那在sequence game裡面,我們唯一做的事情就是把這個reward換成,我發現一個錯,你們有發現嗎?
link |
我發現一個錯,什麼錯呢?就是這個h不應該是下標,在前面我都是把r寫成,我兩個input h跟s。
link |
我本來在做投影片的時候,到昨天晚上,比如說到凌晨四點為止,這個h都仍然是下標,後來我突然想要把它改成不是下標,那這個部分沒改到這樣子。
link |
所以這個h應該是在括號裡面,不過這不重要。那你就把這個reward換成discriminator的分數,就結束了。這樣大家聽得懂嗎?
link |
但是這邊,當你用game的時候,跟rl還是有一個不一樣的地方,在rl裡面,你用來evaluate的那個function就是人,它其實是固定的一個function。
link |
但是在game裡面,你的discriminator也會update,這個是唯一不一樣的地方,其他部分就是一樣的,你就把reward換成discriminator的output就好。
link |
所以現在呢,你在用sequence game來train一個checkbox的時候,它有兩個step。第一個step呢,它有兩步,有一個是g-step,g-step是要train你的checkbox。
link |
假設你已經有一個discriminator,discriminator也是另外一個network,discriminator已經認好了,discriminator你給它一個h跟x,它告訴你說,這個h跟x有多像realistic。
link |
所以呢,你現在就去sample一大堆的h跟x,你sample大N比的h跟x的pair,這個discriminator就會自動來evaluate說,每一個h跟x的pair,它的值有多好。
link |
這個d on h跟x,就代表說這個h跟x的pair有多好。原來在reinforcement learning裡面,這個d是人提供的,會用另外一個handcrafted rule提供的,但在這邊,這個d是由discriminator提供的。
link |
接下來呢,你在update參數的時候,你就把本來要放reward的地方,改成放discriminator的output,就結束了。
link |
那和剛才做reinforcement learning不一樣的地方就是,discriminator也是學出來的,那你要一個d-step,d-step它的作用就是在learn一個discriminator。那discriminator怎麼學呢?discriminator就是叫你的checkbox sample一堆fake的h跟x,然後再從real的data,再從human的dialogue,sample一堆對的、正確的h跟x。
link |
那discriminator要學著去分辨說哪些h跟x是人講的,哪些h跟x是checkbox講的,就可以認出這個discriminator。
link |
那這個g-step跟d-step,它們是反覆執行的。就是你先執行g-step,把generator認好,再執行d-step,把discriminator認好,那fix to discriminator,再回去g-step,再去train你的generator。
link |
但是在這個地方呢,在這個sequence game的paper裡面,這個sequence game有兩篇paper,一篇是原始的sequence game的paper,另外一篇是把sequence game用在dialogue上面,那我把這兩篇paper都剛才放在這個sequence game的標題下面。
link |
那今天有一件事情是我們可以improve這個sequence game,怎麼做呢?假設我們現在sample到一個h跟x的pair,這個h是why is your name,然後x是I don't know,那這顯然是一個不好的pair。
link |
所以你得到的這個discriminator的值減掉bias呢,會是negative的。因為discriminator值如果你今天是用原來的game的話,那這個discriminator值都是介於0到1之間嘛,原來的game有一個sigmoid,原來的game有一個sigmoid,所以這d的值都介於0到1之間。
link |
那所以你可能會想要減掉一個bias,讓他的值呢,有正有負。那我剛才已經解釋過原因了。好,那現在discriminator值減掉bias可能是負的。
link |
那machine在update參數theta的時候,他就會希望log ptheta的x given h,這個機率呢,越小越好,他就會希望這個機率呢,被減小。但是呢,這個p of x given h,他又是由以下三項呢,所組成。
link |
對不對,因為這個x啊,他是一個sequence,然後他裡面有三個word,i跟don't跟no,所以p of x given h,他可以拆成以下這三項相乘,就是p of x1 given h,跟p of x2 given x1,和p of x3 given x1到2。
link |
那如果我們要減小這個值,那減小右邊這三項機率的值,都可以讓p of x given h的值變小。所以今天我們在update參數的時候,update參數的方向要讓這一項變小。
link |
意思就是說,machine會讓這三項的機率變小。但這件事情可能有點怪怪的,因為想想看第一項,這個x1是i,x1是i放在巨首的機率。今天update以後的結果,machine會讓i放在巨首的機率下降。
link |
這樣不是很奇怪嗎?因為i放在巨首,並不是一個negative的事情。假設問說,what is your name? 那一個可以的回答是,比如說,I'm Joe,這樣Joe是一個可以的回答。
link |
那i放在巨首,並不一定是一個negative的事。negative是來自於don't跟no,而不是來自於i。但是如果根據這邊這個term法的話,machine沒有辦法判斷說今天xi的這個句子裡面,哪些word是造成negative的元兇。
link |
因為它還說每一個word都是有問題的。如果一個句子是壞的,那每一個裡面的word都是壞的。可以說這樣認不是會有問題嗎?理論上,如果sample的量夠大,就不會是問題。
link |
如果sample的量不夠大,就會是問題。假設sample的量夠大的話,那你在你的sample的data裡面,可能有另外一個pair是h是y是your name,然後x就是i am joe。
link |
那這個時候呢,因為這是一個好的pair,所以d of hx-b,它是正。那machine在update參數的時候,就會希望這個機率,p of x given h的值呢,上升。而這一項,這個機率呢,這個p of x given h,因為它裡面有三個word,所以它也是三項。
link |
那machine會希望這三項的值呢,都上升。而第一項是p of i given h。那如果你的sample裡面同時有這筆sample,同時也有這筆sample,那這兩項呢,就會抵消。
link |
讓p of i given h下降和上升的力量呢,就會抵消。這樣就不會造成問題。那i最後到底應該是上升還是下降,就看說在整個data裡面,以i為起手的句子是好的比較多,還是壞的比較多。
link |
如果好的比較多的話,那最後呢,i放在起手的機率,i放在起手given x h的機率就會上升,反之呢,就會下降。但是,實作上,如果我們的sample會是,因為我們sample data的量是有限的,
link |
所以實作上,你可能只sample到上面這個句子,沒sample到下面這個句子,這個時候就會造成問題。當然如果你今天update參數很多次,最後可能呢,讓i下降和上升的力量可以抵消。
link |
那這樣呢,很迂迴,你沒有辦法保證這件事情一定會發生。所以,我們能不能夠進一步做到說,machine知道說,在這個response裡面,哪些word是好,哪些word是不好。
link |
假設machine知道說,i放在句手是好,它應該把i放在句手的機率增加,把don't放在第二個詞彙的機率變少,把no放在第三個詞彙的機率下降。這件事情要怎麼做到呢?
link |
這件事情可以透過改寫gradient的式子來做到。我們本來是給說一整個句子一個分數,就是p of xi given hi,這件事情就是有一個分數,d of hi xi-b。
link |
但是我們現在可以猜成,每一個詞彙,每一項,就這個p of xi given hi,它其實是很多項相乘嘛,每一項都給它不同的分數。
link |
什麼意思呢?log p set of xi given hi,可以猜成summation over t等於1到大t,假設這個xi的長度有大t的word。
link |
然後呢,把它的這個大t項都寫出來,那裡面每一項就是xt given se-1。所以這一項可以猜解成summation over這些機率。
link |
然後每一項機率前面呢,我們都給它乘上一個分數,原來是一整個句子才一個分數,現在是每一個word都有一個分數。
link |
這個分數是什麼?這個分數是,如果我的history是,如果現在input是hi,我的output xi的前t個word,一冒號t就前t個word,output xi的前t個word是這t個word的話,它到底有多好?
link |
那有兩個方法,那這一項要怎麼算?有兩個方法可以估測這一項。第一個方法呢,是用multicolor的做法,第二個方法呢,叫做discriminator for partial decoded sequence。
link |
那現在看一下multicolor的方法,那這個multicolor的方法是這樣,那我們現在要怎麼算這一個呢?怎麼算這一項呢?舉例來說,怎麼算說,假設input是yi是your name,那現在response是句首,如果response的句首是i的話,平均而言這個句子有多好呢?
link |
這件事怎麼估呢?那這個估法就是,你就去sample一大堆以i為起始的response。那不光sample response,你也需要一個generator,你才能夠sample response。
link |
那在實作上啊,你可以把你現在的chatbot就當作那個generator,也就是說呢,你輸入your name給那個chatbot,然後強迫它第一個output的word一定要是i,然後接下來它要output什麼word就隨便它,然後讓chatbot產生好幾個不同的以i為起始的句子。
link |
比如說第一次sample,它sample到I'm Joe,第二次sample到I'm happy,第三次sample到I don't know,第四次sample到I'm superman。那接下來呢,你這樣discriminator對每一項呢,都去做evaluate。
link |
去evaluate說,現在response是I'm Joe有多好,可能很好,就是1.5,response是I'm happy,是不對,是0.1,responseI don't know,是不對,是0.1,responseI'm superman,其實也可以,因為它可能就是superman,所以就給它0.8這樣子。
link |
不同的sample呢,通通平均起來,那比如說得到的值是0.5,這四項平均是0.5,那這個值呢,這一項呢,就可以當作是以i起首的句子,平均的分數。
link |
這個是一個方法,那第二個方法呢,是讓machine直接去判斷說,如果,讓machine直接去判斷說,直接去判斷某一個generator一半的句子,它有多好。
link |
那這個概念是這樣,我們原來在train一個discriminator的時候,我們是把一個完整的h跟x的pair丟給discriminator,我們會告訴discriminator說,input y is your name, output I'm Joe,是positive sample,input y is your name, output I don't know,是negative sample。
link |
那現在我們要讓machine學會說,就算是只判斷到句子的一部分,你也要能夠評斷說,現在這一部分的句子,接下來如果把它完整的generate出來,那期望說這個句子,如果把這整個句子完整的generate出來,它的結果會有多好。
link |
那所以怎麼訓練呢?所以現在要給machine做訓練的時候,你要多加一些其他example,你要告訴machine說,y is your name,output,只output in,也是positive。
link |
你就把原來in Joe解一部分出來,只剩in,就告訴machine說,in可能是一個positive sample的其中一部分,句走放i,也是positive sample的其中一部分,那如果output I don't,是negative sample,只output i放在句走,它也有可能是negative sample。
link |
所以今天從這個example,它有可能是positive sample,也有可能是negative sample。那接下來呢,你就讓discriminator去學的時候,是看著這樣子有包含partial的response的example去做學習。
link |
那最後在做testing的時候,你就可以給你的discriminator只給它partial的response,只給它x的前7個word,然後問它說,如果現在input是x,那output的前7個word是x1,那你覺得它有多好?
link |
好,那在文件上還有一招叫teacher forcing,這個teacher forcing其實講起來也是頗直覺的,我們剛才有講說,不要讓check bar從random開始學起。
link |
要從random開始用sequence scan,或者用reinforced learning開始學習,都是很困難的,因為一開始machine很弱,所以它開始generate example,可能每一個都是negative。
link |
就好像說,你叫一個小學生去做大學的微積分的題目,他怎麼做都是錯的,然後他做錯你就打他一巴掌,他最後只有臉很腫,他永遠都回不來,回答不出正確的答案。
link |
所以永遠讓check bar從random開始學的就是這個樣子,一開始很弱,所以它所有output的東西都是negative,它根本不知道一個positive的東西是怎麼樣,它永遠都沒有辦法sample到一個正確的例子,所以它都沒有辦法從正確的方向走。
link |
那怎麼辦?有一個方法是這樣,我們在training的時候,原來的training是,我們會sample一大堆h跟s的pair,每一個pair都去算一個discriminator的分數,然後拿這些pair去做training。
link |
但如果一開始check bar很弱的話,這些pair裡面可能每一個pair它的d值都是很小。但你可以增加更多的data,你就把real的data,你就把你的real的data裡面的sample一些data出來,你sample一堆h跟s的pair,然後說這個h跟s的pair,discriminator的output就設為1。
link |
那這樣機器就至少會有一些positive的example告訴它說什麼樣是好的回答,就有一些example可以示範給機器看說什麼樣是好的回答,這樣它就會學得更好。
link |
那有關實驗的部分,這邊我們就不要細講了,這邊可以留給大家來試試看。那這個generator啊,就generate出來的sentence好不好,這件事情是非常主觀的,所以你很難去衡量。那在sequence game的第一篇paper裡面,它其實有一個用synthetic data來衡量的方法,至於這個衡量的方法你能不能接受,其實就是見仁見智,我可以接受。
link |
那這個synthetic data的方法是怎麼樣呢?它這個衡量的方法是這樣子的,它說一開始我們先假設我就是有一個LSTM,假設我們就是有一個LSTM的language model,我們用這個LSTM的language model去sample一大堆的sentence當作是正確的data,當作是real的data。
link |
那你說搞不好這個LSTM很爛啊,它sample出來的句子也很怪啊,不要管它好嗎,我們就當作是這個LSTMsample出來的句子就是好的。事實上在這個paper裡面,它的LSTM的參數就是random的,它並沒有train,它的LSTM的參數就是random的。
link |
所以它的LSTMgenerator出來的東西一定很怪,但是我們就當作是那些data就是好的,好嗎?然後呢,然後我們再去train一個generator,這個generator會去學著去output,去模仿這個LSTM的output。
link |
那你說這個LSTM是壞的,那沒有關係啊,就是看它能不能把那個特別的distribution學出來,它不一定要學說人產生的句子,它要學的就是這個LSTM產生的句子的distribution,看它能不能學得跟這個LSTM很像。
link |
然後你再用generator去產生一些句子,generator學好以後再讓它產生一些句子,再用這個LSTM,這樣一開始sample句子的LSTM去算說這些句子的negative log-likelihood,那你會希望說這個negative的log-likelihood越小越好,我覺得log-likelihood越大越好。
link |
我不知道你能不能接受這個方法,我覺得其實這個方法就是一個蠻客觀的方法,至少一個客觀的方法可以衡量你的generator做出來的sentence有多好,有沒有多像它的那個原來的source。
link |
那你又知道原來的source參數值是多少,你就可以拿原來source的model去衡量你的generator它產生出來的句子。
link |
那這是一些實驗的結果,那在那篇paper裡面呢,在sequence game原始的paper裡面除了這個synthetic data以外,它是有real data,而real data還做了三個test,在這三個test上看起來呢,sequence game都比NLE好,NLE就是我們講的那個原始的訓練方法。
link |
那如果sequence game看起來都performance呢,都比原始的訓練方法好,做了三個test,一個是唐詩的生成,一個是歐巴馬的演講的生成,看他講話像不像歐巴馬,然後一個是音樂的生成。
link |
那sequence game後來也可以被用在check bar上,那這是一些check bar的generate出來的open。那這個check bar到底有沒有答的比較好,這個也是見仁見智的問題。
link |
但是至少如果你看這個human evaluation的話,看起來用sequence game是有比較好的。那這邊是sequence game跟mutual information比啦,那sequence game呢,在single turn的時候有62%的機會,人是覺得他比較好。
link |
那在multi turn的時候有72%的機會,人是覺得他是比較好。那也可以看下面這些例子,看一下說前面兩個例子就是用原來的NLE trend,後面兩個例子呢,第一個是用,其實第二個這個也是用,第三個這個其實也是用sequence game trend啦,只是他沒有加那個每一個step給他不同的reward。
link |
第四個例子呢,是每一個step會給他不同的分數,每一個reward會給他不同的分數。比如我們看第一個例子,他說tell me, how long have you had this folding sickness? 那如果是NLE的response感覺很強,我又不是醫生,我怎麼會知道?
link |
那這個sequence game的response是a few months, I guess,會讓助教來講這個作業要怎麼用reforce and learning來做。那後面就只是列了一些其他跟產生sequence有關的參考文獻。
link |
比如這邊還有一個game叫做melee game這樣子,melee game就是一個沒有力氣的game。還有很多其他跟產生sequence有關的用game做的方法,就列在這邊給大家參考。
link |
那我們休息,我們就休息五分鐘就好了,就讓助教來講一下這個作業。