back to index
機械学習で美少女化 ~ あるいはNEW GAME! の世界
link |
知道它是怎麼做的。跟我猜的差不多了,有些小細節不一樣。所以我可以跟大家分享一下,這個是怎麼做的。
link |
好,那這個是introduction。introduction是說,這個部落格的靈感呢,來自一個叫做New Game的動畫。
link |
在這個動畫裡面呢,作者呢,是用他的,他講的是他自身的經驗。作者可能是一個做遊戲的設計師,然後講了一下他自己在遊戲公司的經驗。
link |
那唯一不同的只是他把他身邊的人都代換成這個萌妹子這樣子,都代換成二次元的角色,這樣可以讓他人生呢,比較開心一點。
link |
那我們知道說,現在在日本呢,如果你要promote一個東西,你就會畫一個那個東西的動畫。比如說,如果你要promote棋靈王,你就畫一個。
link |
你要promote圍棋,你就畫一個棋靈王。你要promote那個畫漫畫,你就畫一個盜漫王,這樣子。
link |
所以我們應該要,以後我們要promote什麼東西,就畫那個東西的動畫。可是現在都promote要唸博士,就畫一個唸博士的動畫,這樣子。
link |
這劇情我都想好了,我改天跟院長報告一下。劇情,這個我有講過嘛,這個劇情是這樣子的。
link |
有一個人他叫,也叫阿光好了,他在他爺爺的倉庫裡面,發現一個很舊的主機,486的。
link |
他把那個主機打開以後呢,就有一個千年的栓宅附在他身上。然後那個死後栓宅呢,他這一次的夢想就是拿一個博士學位,但是他還沒有拿到就死了。
link |
所以他就要逼迫阿光呢,也去唸一個博士。一開始阿光不想要唸博士,但那個鬼魂一直逼他唸博士,最後他就從唸博士中領悟到了很多事情,後來就拿到博士學位。
link |
那他到最後結尾的時候,人家問他說你為什麼要唸一個博士,他就說,唸博士是為了要連接遙遠的過去和未來,然後再結束它。
link |
不過,抽襲秦王的部分太多了,感覺不太OK,我來想新的故事好了。
link |
你有好的劇本再推薦給我好了。所以他這邊做的事情呢,就是要把真正的圖變成動畫的圖。
link |
他沒有用任何的pair data,理論上是用cycle game做的,但不是用cycle game做的。那個部落格沒有說這是每一個專宅的夢想,而不表示個人的立場。
link |
那這個步驟總共有三個,要做到這件事總共需要三個step。第一個step呢,就是用dc game先train一個generator,那這個呢,大家都知道,就是一般的dc game。
link |
你有一個generator,有一個discriminator,然後你就可以train一個image的generator。那他的data呢,用的是一個nicole的open data,這是他train出來的結果。
link |
那跟我們作業比起來,這個image應該是比較大張的,所以他不是只有人臉,還有人的上半身。
link |
那step2呢,step2呢,是train一個code的auto encoder。其實我們上週在講photo editing的時候呢,也講過類似的技術。
link |
你首先有一個generator,他會把code變成image,接下來呢,他有一個generator會把code變成image,接下來呢,你要認另外一個vectorizer,這個vectorizer做的事情是把image變成code。
link |
那在train的時候,就是要讓input跟output越接近越好。所以這是一個auto encoder,但是他特別的地方是,他沒有bottleneck的layer,那bottleneck的地方呢,是一個特別寬的layer,那特別寬的layer,他的output呢,就像是一個image一樣。
link |
那在train這個架構的時候,特別注意的地方就是,你要fix住你的generator的參數,只trainvectorizer的參數。
link |
如果你同時也traingenerator的參數的話,那整個結果就會壞掉,因為network一定可以學到說,因為現在中間這個layer是特別寬的,他一定完全可以把input的code就一路複製過去變成output。
link |
所以fix住generator是很重要。那有了這個以後,理論上呢,你就可以把vectorizer跟generator反過來接。
link |
你先train好這個auto encoder以後呢,你把vectorizer和generator反過來接,所以你丟一張動畫圖,他就會變成一個vector,再把這個vector丟到generator裡面去,理論上他就會產生跟input幾乎是一樣的動畫的,二次元的人物。
link |
但是問題就是,這個vectorizer啊,他從來沒有看過三次元的人物,所以有點擔心說,他丟三次元的圖片進去,那這個vectorizer呢,他的output會很奇怪。
link |
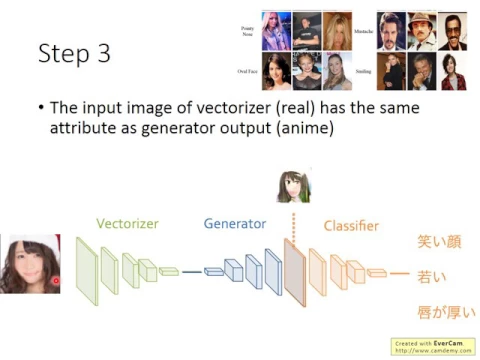
所以呢,最後有第三個步驟。第三個步驟是這樣,這邊需要用到那個select a這個corpus,那select a這個corpus裡面呢,就有一大堆名人的image,而且他有label。
link |
label說每張圖片裡面有哪些屬性。那接下來呢,你就是train下面這樣一個network,這個network呢,他的input是一個real的image,而這個real的image呢,通過一個vectorizer以後,把它變成一個code,再把這個code呢,通過generator變成一個image。
link |
然後再把這個image呢,丟到一個classifier裡面,然後他希望呢,這個classifier的output就是這一張image的attribute,也就是說你已經知道說,這一張image的attribute有笑臉,那你希望這個classifier的output呢,就有output笑臉。
link |
那這邊有一個值得討論的地方就是,據說根據那個部落格的內容,如果你有別的想法的話再來告訴我,因為我看不懂日文。據說根據那個部落格的內容,這三個network的架構是一起train的。
link |
這件事情有點奇怪這樣子。就是說,我們當然可以說,我們把vectorizer,generator跟classifier一起train,我們可以說,這個vectorizer,generator加classifier合起來就是一個非常deep的network,那你希望input一張image,output就是他的attribute。
link |
那你可以用這個selectA的這個corpus來train這樣一個classifier。但這樣做的話會有點奇怪,因為這樣子我們把這個classifiertrain完以後,雖然說我們的generator跟vectorizer有做pre-train,但並不保證我們這樣jointly train完以後,這個layer,他的output仍然是代表,仍然是這個二次元人物的頭像。
link |
但這也有可能可以解釋的說,如果你實際run這個code的話,他跑出來的圖片有一些雜訊,有一些奇怪奇妙的斑點,也許就是因為他沒有fit住這個generator的參數,所以才會讓他有奇怪的斑點。
link |
那事實上我認為呢,如果我們今天要做這個test的話,我認為首先generator的參數必須要fit住,這是第一件事情,我認為generator的參數必須要fit住。
link |
第二件事情是我認為classifier跟vectorizer沒有必要或者是不應該jointly train,我認為vectorizer跟classifierjointly train可能會有問題。為什麼會這麼說呢?
link |
因為你看喔,現在我們希望說把這個generator的output丟到classifier裡面去,classifier可以把它辨認成笑臉,然後classifier可能是跟vectorizer一起train。
link |
那你可能會得到的結果是,搞不好這是一張笑臉,然後呢,通過這個vectorizer,他變成的是一個哭臉的code,所以通過generator以後他output的image是一個哭臉。
link |
但是對classifier來說,如果他是跟vectorizer一起train的,他其實不知道說一個笑臉要長什麼樣,他搞不好會學到說那個哭臉就是笑臉,這樣大家了解我的意思嗎?
link |
所以我認為說這個classifier應該要先在另外一個corpus,比如說,我認為應該要有另外一個corpus,那corpus已經label好說這些image他有什麼樣的attribute,你可能可以直接用select a,
link |
or select a是real image,所以直接用在這邊也許怪怪,但是其實已經有很多的其他的data是動畫圖,然後又有label的,就像我們作業提供的那些data一樣。
link |
所以我認為classifier應該要先在別的data centertrain好,所以classifier也應該要fix住。
link |
那在這個task裡面,唯一要train的應該只有vectorizer,就是我們只trainvectorizer,然後讓vectorizer產生的code通過generator以後,會被classifier辨認成正確的attribute。
link |
所以這個是我的想法給大家參考,據說那個blog裡面寫的是說,這個vectorizer generator跟classifier應該要joint一起train。
link |
也許你可以把它當作留言終結者的專題,看看說,至少把generatorfix to performance會不會比較好。