back to index
Imitation Learning
link |
整理&字幕由Amara.org社区提供
link |
有時候在講apprenticeship learning的時候,有人會說apprenticeship learning是僅止於指inverse reinforcement learning,我們等一下會講到inverse reinforcement learning。
link |
你用inverse reinforcement learning的時候才叫做apprenticeship learning,也有人覺得apprenticeship learning就是imitation learning,這個都只是名詞定義的問題而已。
link |
從learning by demonstration這個字眼就可以看出我們現在要做的事情是什麼。我們要做的事情就是說,有一個expert,比如說人類,對machine做一些示範,然後machine根據這些示範就可以進行學習。
link |
這句話要講的就是,我們有一個expert,他會示範給machine看,他會對machine做一些示範,然後machine就可以學會他要做的事情。
link |
在這個task裡面,在這個imitation learning裡面,和reinforcement learning不同的地方是,machine也可以和環境做互動,但是它沒有辦法從環境得到reward。
link |
如果想要知道reward的話,machine必須要自己去猜出環境的reward是什麼。所以在這個task裡面,machine並不是在imitation learning裡面,machine並不是受到reward的驅動,然後才去做事。
link |
它是受到了expert的啟發,expert的demonstration的啟發,它才知道它要去做什麼事情。那你可能會問說,用reward來控制machine跟用demonstration來控制machine有什麼不同?
link |
你可以用reward來控制machine的行為,你可以用reward來教導machine,然後做一些你不喜歡的事情來打它一巴掌。但是你也可以用demonstration的方式來教導machine,告訴它什麼是好的行為,什麼是不好的行為。
link |
那用imitation learning有什麼好處呢?第一個就是,有時候reward是很難定義的。舉例來說,如果你是考慮的,比如說你現在要用reinforcement learning的方法,可以一部自駕車,那這個時候你就需要為這個task定一些reward。
link |
比如說如果車子撞到牆的話,那reward有多負?車子撞到人的話,reward有多負?車子撞到狗的話,reward有多負?那這個就很麻煩,因為你不知道要怎麼定比較好。
link |
那有時候你用handcrafted的方法定了一些reward,有可能反而造成很大的問題。因為舉例來說,假設我們今天machine要去考試,然後你給machine定的reward就是,你只要考一百分就好了,你沒有考一百分就打死你。
link |
然後他可能就會學到說,因為這個是reinforcement learning,只有reward可以操控agent的行為,那agent可能會學到說,他不如就考試作弊,這樣他就可以得到一百分。
link |
那這可能不是我們要的。那如果我們只是用handcrafted的reward的話,那我們對machine的控制是比較有限的。你只有設定目標,那machine可能會做出出乎你意料的行為。
link |
那今天要講的imitation的方法有三個方法,一個是behavior cloning,第二個是inverse reinforcement learning,第三個就是用gain來做imitation learning。
link |
那等一下發現說用gain來做imitation learning跟inverse reinforcement learning,其實是同一回事。好,那我就從behavior cloning開始說起。那behavior cloning顧名思義就是machine要去複製expert的行為。
link |
machine怎麼去複製expert的行為呢?舉例來說,假設你現在要坐自駕車,現在滿坑滿谷的人都在坐自駕車,在路上碰到的人不是在坐車霸,就是在坐自駕車。
link |
坐自駕車比較常見的是用GTA做的,我之前還看過用reinforcement learning認GTA的實況。而且這個滿坑滿谷,你就去youtube上googleGTA加reinforcement learning,滿坑滿谷的人在做這個,而且還有training的實況。
link |
很多人會說我在坐自駕車,你才會聽到路上有一個人說我在坐自駕車,然後想說你是在坐自駕車,坐自駕車你要先買一台車,你自己先找一台中古車來坐。你仔細問他,他就會告訴你其實他在GTA上坐的。
link |
今天如果是behavior cloning的話要怎麼做呢?首先我們要先收集expert的行為,比如說人類駕駛的行為,那你就去collect很多行車紀錄器。
link |
接下來你還要去collect說今天當一個駕駛看到這個畫面的時候,比如說行車紀錄器看到這個畫面的時候,人類會採取什麼行為?比如說行車紀錄器看到左邊這個畫面的時候,人類駕駛做的事情就是踩油門,然後車子就向前。
link |
這個時候我們要做的事情其實就很簡單,就是人類做什麼他就做什麼,人類踩油門他就跟著踩油門。所以在behavior cloning裡面首先你要收集一大堆的data,這些data就是一堆的observation,還有今天在這個observation之下這個expert採取的行為。
link |
這邊用ahead來代表說expert採取的行為。這邊的observation其實指的就是state,在今天這門課裡面state跟observation是混在一起用的,因為像現在如果你是在做自駕車的test的話,你的state其實直接就是你看到的畫面,並不會再handcrafted,並不會再用人手handcrafted一些state。
link |
所以現在有了leap learning以後,你的observation跟state幾乎就是同一件事情。
link |
你今天收集到這些training data以後,怎麼辦呢?你就認一個neural network,認一個actor,那這個actor的input就是state,就是observation,就是一個畫面,他的output就是現在要採取的行為,要採取哪一個action A,就結束了。
link |
他的training target就是,假設根據training data,人在看到OI這個畫面的時候,他會採取ahead,那machine就希望他的output的action跟ahead可能越接近越好,結束。
link |
想說這不就是supervised learning嗎?就好像只是把這些observation看作是function的input看作是x,然後這些action看作是function的output的target就是y,對,就是supervised learning,結束,跟一般的supervised learning沒有什麼不同。
link |
好,那behavior cloning有什麼問題呢?一個問題就是,今天expert可以sample到的observation是有限的。如果你今天只是clone這個expert的observation的話,假設今天是自駕車問題,expert是人類的駕駛,那人類駕駛做的事情可能都是比較正常的,比如說他從來沒有把車子開到河裡過,你可能從來沒有這種training data。
link |
對machine來說,如果他今天clone的對象,那個expert,他只有很有限的observation,很有限的state,那你認出來的actor在新的state上,他可能就不會表現得很好。
link |
這邊就只是一個簡單的示意圖,這個expert走的路線是紅色的,那對machine來說,他的observation就只有在這個條紅色的路線上面,他可以看到的景象。對machine來說,如果今天初始是在這個地方,他就會崩潰,就不知道要做什麼。
link |
對machine來說,如果你用behavior clone去玩瑪利歐,就是去讓machine複製人類玩瑪利歐的行為,就玩個一百場,然後讓machine去複製。
link |
那machine會遇到的狀況是,如果今天他沒有遇到什麼阻礙的話,他可以走得很順,但一旦他碰到阻礙,比如說陷到兩個方塊中間,他就會跳不出來。
link |
人不會犯這個錯誤,人從來沒有犯過這個錯誤,所以這個observation從來沒有出現過,就瑪利歐掉到兩個方塊中間,這也是從來沒有出現過。但是machine一旦碰到了,因為他training data從來沒有看到這種狀況,他就會不知道要怎麼解。
link |
所以怎麼辦呢?有一個方法就是增加更多的training data,增加更多的observation,你就強迫那些expert,你給他一些他平常不會看到的state或者是observation,然後問他說他要怎麼處理。
link |
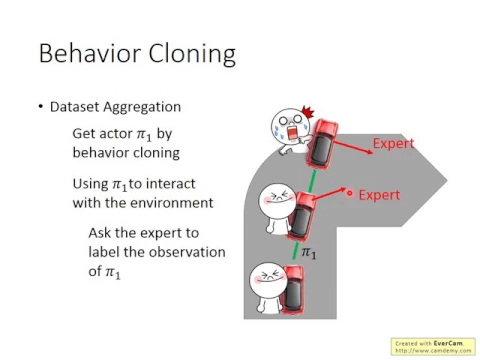
比如說你就去問expert說,如果遇到這個狀況,你要怎麼處理。這招叫做data set aggregate,這邊舉一個比較具體的例子。
link |
假設我們現在已經有一些training data,我們可以用behavior coding的方法,就train了你第一個actor,他叫做Py1。那接下來你就用Py1去對環境做互動。假如這邊,這台車如果根據Py1的actor的話,他會走綠色這個路線,然後最後就會撞到牆。
link |
這個時候這個車上有一個expert,他會不斷地告訴你說,今天在這個狀況下,他會採取什麼樣的行為。這樣就可以告訴machine說,今天一個expert如果在這些machine會經歷的state下面,他會採取什麼樣的行為。
link |
所以今天這個expert就會告訴machine說,今天在看到這個畫面的時候,雖然你要往直走,但是如果是人的話,會想要把方向盤向右。
link |
在這條線上的每一個observation,我們都請expert做label,說他要做什麼。舉例來說,最後車子撞到牆了,雖然expert努力地把方向盤往右,但是那個方向盤是假的,這個方向盤只要拿來做label用的,所以expert就會很慌張,最後車子就撞到牆。
link |
因為machine是按照他的policy走的,他其實不管expert做的label。expert的label只是告訴machine說,下次如果再看到同樣的state,你要把方向盤向右。
link |
那expert就跟著車子一起車毀人亡。所以每次做一次實驗,你都會損失一個expert。
link |
好,那你現在就有了剛才那個expert犧牲自己以後換到的data,然後你就可以去train一個新的policy。
link |
你就把這個expert犧牲自己以後換到的data跟之前的data全部都合在一起,然後你就可以train一個新的after pi 2。
link |
這個方法聽起來是比較……如果在自駕車上面可能是比較荒謬的,但是如果在其他有一些task,也許你還是可行的。
link |
比如說你今天要去打蘋果棋,假設今天某一種遊戲,你其實可以窮取所有的結果,知道說最好的state其實是哪一個。只是今天在實際下棋的時候,因為時間不夠,不能讓你窮取接下來所有的結果。
link |
窮取接下來所有的結果這件事情,就可以當做expert。也就是說,你今天讓machine學下某種比較簡單的棋,比如說蘋果棋。
link |
假設蘋果棋可以窮取接下來所有的結果。在每一個state,machine都按照它自己的policy下,都按照它自己的expert決定下子的位置。
link |
但是同時在每一個state,你都用窮取的方法窮取接下來所有的路數,看看說哪一步是最好的。那你就可以collect到expert的state跟action的pair,然後你就可以做training。
link |
好,那用這個data update的方法,你可以增加state。但是behavior clone,你還有另外一個本質上的問題。那這個本質上的問題呢,我就用下面這段影片呢,來描述這個本質上的問題。
link |
本質上的問題是說,你現在的agent,他會copy所有的expert所有的行為,不管那個行為呢,適不適合,他都會copy那個行為。
link |
我認為今天如果你的actor他的capacity夠強的話,也就是說他可以完全copy你的actor的行為,在不考慮overfitting的情況下,其實是沒有問題的。
link |
就假設你今天你的actor可以完全copyexpert的行為,今天在同一個state,你的actor的行為都跟expert完全一模一樣,他其實做的不會比actor還要差。
link |
但是真正害怕的情形是,今天你的actor他的capacity都是有限的,尤其是你其實會希望你的actor的capacity是有限的,因為如果他capacity是太大的話,你很容易overfitting,所以你會讓你的actor的capacity是有限的。
link |
在有限的capacity之下,expert哪些行為要被copy,哪些行為不要被copy,就會變成對結果有很大的影響。舉例來說,在剛才那個例子裡面,有人跟你說你叫什麼名字,你可以說我的名字是Sheldon,你也可以比這個手勢。
link |
但是因為Sheldon他是一個genius,所以他可以記得language跟手勢。但是假如actor他比較笨,他要嘛就記得語言,要嘛就記得language,要嘛就記得gesture的話,那就會變成他記哪一個就變成了關鍵。
link |
如果他說,那他選擇忘記gesture,只記得speech的話,那是好,沒差,雖然沒有完全複製expert的行為,但沒有關係,不會有什麼影響。但是如果他選擇的是,他要複製gesture,他只複製這樣,然後他把語音的部分就忘記了,那你就會得到一個差的結果。
link |
但是在behavior cloning裡面,我們其實沒有考慮到這個問題。Behavior cloning如果當作一個簡單的普通的supervised learning的問題做下去的話,對supervised learning來說,今天左右兩個case都是有一部分答對,有一部分答錯,所以對一般的supervised learning來說,做的是一樣好或者一樣不好。
link |
所以如果今天只是用一般的supervised learning來做behavior cloning的話,你就會有我這邊說的這個問題。所以要解決這個問題,理論上你應該要給予不同的錯誤不同的weight,你要給這個machine一個sensitive cost function,他犯不同錯誤的時候要給他不同的penalty,他犯不同錯誤的時候cost的大小是不一樣的,但是這件事情就不太容易知道要怎麼定。
link |
好,那接下來呢,我們再用不同的觀點來講一下為什麼behavior cloning可能會造成問題。那behavior cloning的一個問題就是,在training跟testing的時候,你很容易你的data distribution就是不一致的。
link |
怎麼說呢?在behavior cloning裡面,我們現在的supervised learning的problem就是input O output A嘛,但是今天這個input O output A這件事啊,就是你會看到什麼樣的observation其實取決於你的actor本身的參數。
link |
這句話我特別套一個黑色的出題,我等一下寫一集。這句話很重要,大家了解我的意思嗎?就是你今天會看到什麼樣的observation其實取決於你本身,其實取決於actor本身的參數。
link |
對不對?如果今天以自駕車的case為例,如果是一個很強的expert的話,你可能永遠不會看到車子往牆撞過去。除非你的policy很弱,你的actor很弱,是一個很爛的actor,你才會看到說現在車子往牆撞過去的state。
link |
所以今天在behavior cloning裡面,你會看到什麼樣的state,其實取決於你今天的actor的參數是什麼。所以如果你是跟你的actor跟expert一樣,如果是expert的話,他會sample到一個observation的distribution。
link |
但如果你是另外一個actor,他只是想要去cloningexpert的行為,但他沒有辦法完全複製expert的行為,他只能部分複製,沒有辦法完全複製的時候,這個時候opine的distribution就會跟owner是很不一樣。
link |
如果你今天這個pystar這個actor在testing的時候,就是你認好你的actor以後,你這個pystar你認出來的actor跟expert的actor正好是一模一樣的話,那你的training跟testing的data就有一模一樣的distribution。
link |
那你在training data上認的model就可以apply到testing data上面去。但是問題是,今天如果pyhead跟pystar不一樣的話,那你就會影響了你的observation。如果你今天你的cloning的結果跟expert的actor略有不同的話,這個時候你的observation可能就會變了。
link |
而當pystar跟pyhead有多大的不同,當pystar跟pyhead有不同,對這個observation有多大的影響,這件事是不知道的。
link |
有可能說兩個actor其實很不像,但是他們的observation差不多,有可能兩個actor差一點點就observation就天差地遠,這都是有可能的。
link |
所以變成在behavior cloning的時候,你要嘛你認出來的pystar跟pyhead一模一樣,只要有一些差距,你就有可能會得到很大的error。只要有一些差距,你就可能導致你的observation distribution很不一樣,那這個時候你的error就會被放大。
link |
所以這個是behavior cloning的問題。所以接下來就有下一個方法,這個方法叫做inverse reinforcement learning,IRL。
link |
Reinforcement learning已經很潮了,前面再加一個inverse就感覺更潮了。那這個inverse reinforcement learning也有人叫做inverse optimal control或inverse optimal planning,其實都是一樣的東西。
link |
那inverse reinforcement learning在做的事情是什麼呢?從顧名思義就知道說,它是reinforcement learning反過來。那原來的reinforcement learning在做什麼呢?在原來的reinforcement learning裡面,我們有一個environment,我們有一個環境,是agent可以去跟這個環境互動。
link |
那在這個互動的環境裡面,這個agent會知道兩件事。一件事情是reward function,也就是說,如果今天以這個Atari的遊戲為例,你有一個agent去,玩了一場遊戲以後,他會得到一個trajectory。
link |
這個trajectory寫成tau,所以trajectory的意思就是,他一開始先看到第一個畫面,他先看到第一個畫面O1,然後採取action A1,接下來看到畫面O2,再採取action A2。
link |
這個sequence一直到遊戲結束,把從遊戲開始到結尾的所有看到的畫面跟agent所採取的行為統統都記錄下來,這就是一個trajectory,那我們用tau來表示。
link |
遊戲結束以後,你會得到一個分數,那這個分數是哪來的?這個分數是遊戲告訴你的,是environment告訴你的,那我們用tau來代表這個trajectory我們會得到的reward。
link |
注意一下,這個不是我們定的,這個是環境給的,這個不是agent定的。然後還有另外一個東西是environment的dynamic,也就是說,你在某個state採取某個action的時候,接下來會跳到什麼樣的state。
link |
你在某個畫面採取開火這個動作,接下來敵人會有什麼樣的回應,這個也是由環境所告訴你的。
link |
那有了這些以後,你就可以找出一個最好的policy,這邊寫作hi-hat,這個最好的policy會去maximize他在玩一場遊戲的時候可以得到的期望的reward。
link |
那inverse reinforcement learning就是反過來,我們已經有了一個optimal的policy,你這個optimal的policy可能就是人,你找了一個expert去玩一個atari的遊戲,那個expert的policy,當我想policy的時候,他跟actor是一模一樣的東西,我想大家應該知道我的意思。
link |
今天有一個人去玩一個遊戲,有一個expert去玩一個atari的遊戲,那他的policy就是這個optimal,我們就當作是optimal的policy,假設人很會玩。
link |
但實際上我們並不真的知道這個policy的function,他的參數長什麼樣,因為這個參數在人的大腦裡面,你要把大腦剖開才知道他的參數長什麼樣,但實際上你不知道,那你知道的是什麼?你其實知道的是state跟action對應的關係。
link |
你找一個人來玩atari的遊戲,然後玩了很多場,就收集到一堆人類expert玩atari遊戲的trajectory,這邊寫成towhead,加一個head就代表說是玩得很好的,expert玩的。
link |
那你從這個towhead裡面你就會知道說,人在看到state S1的時候會採取action A1 head,然後在state S2的時候會採取action A2 head。那你有了這些資料以後,我們希望有了這些資料以後,去反推reward function。
link |
反推reward function這件事情就是inverse reinforcement learning,那這個環境的dynamic也是input,也就是說現在你的agent仍然可以去跟環境進行互動,只是他不知道說他現在採取的每一個行為會得到什麼樣的reward。
link |
他有的是,他可以去跟環境互動,然後他看過expert的trajectory,他知道expert會採取什麼樣的行為,然後想要反推reward function。那你可能會問說,為什麼是反推reward function,為什麼不是直接模仿expert的行為呢?
link |
剛才在behavior coding的時候是直接模仿expert的行為,但現在我要做的事情是反推reward function。反推reward function的時候還沒有結束,而你只是得到了reward function而已,你還沒有得到那個actor,你只有reward function而已,你還沒有這個policy,你還沒有那個actor。
link |
所以怎麼辦?你要先說,我先把reward function定出來以後,我先把reward function找到以後,接下來你再去做一次reinforcement learning,然後再去把最好的policy這邊寫作pi star,pi star就代表說是machine自己找出來的,再去根據inverse reinforcement learning反推出來的reward function,去找一個policy,pi star。
link |
好,那為什麼這邊是找reward function而不是直接找policy呢?在Andrew Ning的paper裡面,他有一個有趣的註腳,這個如果你有什麼更好的想法的話,就跟我分享。
link |
他想法是這樣,他有一個註腳是說,簡單的reward可能可以導致非常複雜的behavior,reward function有時候可能不一定是很複雜的function,它可能只是很簡單的function,但是就可以導致actor有非常複雜的行為,所以也許model reward function是比直接model actor還要容易的。
link |
舉例來說,人他的行為非常複雜,但人的reward function也許很簡單,人的reward function就只有活著而已,你每多活著一秒你就加一分,你可能就只有,你的reward function可能就只有這麼簡單而已,也許不是,我不知道,那假設只是這麼簡單而已,但是人就有非常複雜的behavior。
link |
也許你可以用inverse reinforcement learning來算一下人的reward function,看看是不是只要多活著一秒就多加一分。今天反正inverse reinforcement learning要做的事情就是先推出reward function,再根據推出來的reward function去推一個policy。
link |
我們現在很快地複習一下原來的RL怎麼做的,秒複習一下是不是統一一下那個notation。原來的RL是說,給你一個reward function R of tau,這個tau是一個trajectory,這個tau裡面就是一串state S跟A的sequence。
link |
在Akari遊戲裡面,S其實就是observation,就是遊戲的畫面,我想這個大家應該知道我的意思。這個R of tau,我們通常會寫成說,假設我們有一個function小R,這個function小R告訴我們說,在state S T採取action A T的時候,我們會得到什麼樣的reward。
link |
這個時間點,我採取這個action的時候,會得到什麼樣的reward。把整場遊戲每一個時間點得到的reward合起來,就是total的reward R of tau。
link |
接下來,我們有一個初始的actor pi,然後在每一個iteration裡面,我們會說,我們先拿pi去跟環境互動一下,互動N次,得到N的trajectory,tau1到tauN,每一個trajectory記錄成這個樣子。今天因為我們有這個reward function,所以我們可以量說,在state S採取A1的時候得到的reward是多少。
link |
今天把這個所有的R合起來,就是整個trajectory total的reward。接下來,我們可以算一個東西叫做expected total reward。
link |
expected total reward的意思就是說,假設我現在的actor就是pi,那in average得到的reward會是多少。因為每次玩遊戲的時候得到的reward都是不一樣的嘛,所以用pi這個actor得到reward的期望值是多少。
link |
你可以計算一下,其實很簡單,就是N個trajectory的total reward的平均而已。
link |
接下來,會去update你的actor pi,讓它可以去增加expected total reward,找一個新的pi,這個pi可以讓這個R bar的pi的值變大,比如說你會用policy gradient來做這件事情。
link |
你就反覆這個iteration很多次,最後你就得到一個可以讓expected reward很大的pi,這個pi就是最好的actor pi hat。
link |
那在reinforcement learning裡面它是反過來的,我們已經有pi hat了,已經有pi hat了,不知道從哪裡來的,但就是有一個。但是我們不知道reward function,所以我們要根據pi hat去反推reward function。
link |
怎麼做呢?基本的想法是這樣,我們沒有reward function,我們有pi hat,那實際上我們有的其實也不一定是pi hat的數字,因為pi hat可能根本是個人,讓它是一個真正的人。
link |
所以我們可能有的是,拿這個pi hat去玩遊戲的時候的trajectory,你讓expert玩N次遊戲,把它玩N次遊戲的結果記錄下來。那這邊inverse reinforcement learning它基本的假設是說,
link |
我們假設pi hat的這一個actor,它是可以在這個互動的過程中得到最大的expected reward的那一個policy。
link |
那大家了解嗎?就是說,如果我今天拿pi hat這個actor去跟環境做互動,它得到的expected reward一定是最大的,一定會大過所有其他的actor。
link |
也就是說,我們現在的目標變成說,我們要找一個reward function,找一個reward function,它是怎麼樣的reward function呢?
link |
它可以使得這個pi hat,用pi hat去跟環境互動得到的expected reward,大過於其他所有的pi跟環境互動的時候得到的expected reward。
link |
大家了解我的意思嗎?就好像說,這個pi hat是你的偶像,是一個偉人,所以它做的每一件事情你都覺得是最好的。
link |
我們不知道這個世界上真正的reward是什麼,但我們用pi hat去跟環境互動,它做完以後,它做出來的這些trajectory都是最好的,沒有人可以超越它。
link |
我們先做這個假設以後,再反推它的reward應該是什麼樣子。大家聽得懂我的意思嗎?
link |
就好像說,有一個偉人是大家很崇拜的,他先去做很多的事情,然後我們才定義人類的價值觀,然後告訴我們說,這個偉人做的事情都是對的。
link |
這樣大家有問題嗎?其實這件事情跟structured learning是非常像的,其實是一樣的東西。
link |
怎麼說呢?在inverse reinforcement learning裡面,我們要找我們的reward function。我們的reward function,找這個reward function的條件是,這個reward function會使得pi hat,就是這個expert的policy,這個optimal的actor,它的reward最大,大過其他的actor。
link |
然後接下來,我們有了這個reward function以後,我們要做什麼事?有了這個reward function以後,我們要去找出一個最好的policy pi star。
link |
有了這個reward function以後,我們再去說,現在用reinforcement learning的方法,我們去找一個policy pi,這個policy pi可以讓above pi的值最大。
link |
我們先找出這個reward function,這個reward function找的條件是這一條式子。接下來,我們有了這個reward function以後,再去找一個policy,它可以讓這個reward function的reward最大。
link |
那這跟structure learning,你沒有發現其實是同一件事嗎?在structure learning裡面,我們猜你的條件是什麼?我們要找一個evaluation的function,這邊寫的大F。這個大F就是input一個XY的pair。那我們希望說,X對上正確的Y hat,X跟Y hat這個pair,它的evaluation function,大過所有其他的XY組成的pair。
link |
然後今天在testing的時候,我們在structure learning的content下面的testing又叫做inference,inference的時候就是給另一個X,然後重複所有的Y,看哪一個Y可以讓f of XY最大,它就是答案。
link |
你沒發現左邊跟右邊其實就是同一件事,只是換了一個說法而已嗎?我們只要說這個pi就是Y,你可以想成說這個世界上只有一個X,假設現在training data裡面就只有一筆X,所以這個X你就可以忽略不計。
link |
那這個pi hat就是Y hat,pi就是Y,這個r bar就是f。我們有一個pi,我們把這個pi代進一個function裡面就可以算出expected reward,我們把Y代到evaluation function裡面就可以算出一個分數。
link |
我們希望Y hat只代其他的Y,我們希望pi hat代到r bar這個function裡面,它的值大過於其他的pi,我們其實只把r bar換成f而已。下面的式子也是一模一樣,找一個pi讓r bar這個function的值最大,找一個Y讓f of XY最大,其實是同一件事。
link |
如果是同一件事的話,接下來就沒什麼好講的了,你知道嗎?因為右邊這件事情你會做,對不對?如果右邊這件事情你會做的話,你就知道怎麼做inverse reinforcement learning了。
link |
我們來秒複習一下吧,這個我們看過太多次了,就舉例來說,在structure learning裡面,第一個我講的方法就是structure perceptron。那structure perceptron怎麼做?假設你現在的evaluation function f of XY是w這個vector跟fine of XY的email product。
link |
接下來你就follow下面這個process,每次sample一筆data出來,然後看哪一個y tilde可以讓f of XY最大,看哪一個y tilde可以讓w跟fine of XY的email product最大,把那個y tilde找出來。
link |
如果那個y tilde不是一個正確的y hat的話,那我們就update w,怎麼update w呢?w加上根據y hat抽出來的feature,減掉根據y tilde抽出來的feature,反覆這個process就結束了。
link |
那我們說,在這整個process裡面有兩個問題,第一個就是怎麼解argmax的problem,這邊會有一個問題就是怎麼解argmax的problem,下面這個update的式子要做的事情就是增加正確的y hat的evaluation function的值,減少錯誤的y tilde的evaluation function的值。
link |
接下來我們只需要把inverse reinforcement learning跟structured percentrum做一個對比,然後你就知道inverse reinforcement learning怎麼做了。
link |
怎麼做對比呢?首先我們先看一下,在structured percentrum裡面,我們強迫說f of XY它是一個linear的model,它是w這個vector跟另外一個feature vector的email product。在inverse reinforcement learning裡面,如果我們可以做同樣的限制,我們也可以用同樣的限制來定義我們的expected reward。
link |
如果我們可以用同樣的限制來定義expected reward,就可以完全套用structured percentrum的方法來解inverse reinforcement learning。
link |
這個怎麼定呢?怎麼把pi的total expected reward寫成一個feature vector,跟final pi的email product,怎麼寫成一個參數的vector跟feature vector的email product呢?
link |
我們就看看怎麼做呢?就這麼做。現在假設有一個trajectory。
link |
接下來呢,我們怎麼寫這個R bar of theta呢?我們說R bar of theta就是n個trajectory的reward的平均,那這個每一個trajectory呢,每一個trajectory的reward又可以寫成每一個time step的reward的總和。
link |
也就是R of tau可以寫成summation over t等於1到大t,R of t,代表在t這個step得到的reward。
link |
那其實每一個tau的長度不一定一樣,所以每一個tau的t的大t的大小不一定一樣,這邊為了簡單起見,所以把它省略。
link |
但是呢,我們現在要做的是inverse reinforcement learning,所以Rt的值我們是不知道,reward是我們要被找出來的東西,所以我們是不知道Rt的值應該是多少。
link |
Rt是由我們model的參數所決定的,它是要被找出來的。所以我們就定說,這個當然可以有不同的定法,今天之所以要這麼定,是為了希望把inverse reinforcement learning跟structure perceptron的式子寫成一樣,所以這麼定。
link |
好,那我們怎麼定這個Rt呢?我們說Rt等於一個參數的vector w跟一個feature vector f的inner product,這個參數的vector w是我們接下來要被求出來的,它是要被找出來的。
link |
這個feature vector f of st,at就是從現在的state跟action的pair,抽出一個vector。如果你看一些paper的話,很多paper是沒有把at放在這個f裡面的,就是現在的reward只跟state有關,跟你採取的action無關,這樣也可以。
link |
這些東西都是你自己定的,你要怎麼定就怎麼定。我們這邊就假設說,現在的reward是跟在哪一個state,還有在那個state採取什麼action有關。我們根據現在所在的state st,還有採取的action at,抽一個feature,把這個feature跟一個參數的vector w做inner product,我們就可以得到在t這個實驗鏈的reward。
link |
我們接下來要做的事情就是把w找出來,w是參數,f of st,at是feature vector。
link |
那知道蔣先生大家有問題嗎?你可以接受嗎?如果你可以接受的話,那就把rt換成w跟f of st,at的inner product,那你會得到什麼呢?你把這一下帶進去。那w對所有的n,對所有的trajectory,對所有的時間點都是一樣。
link |
所以你可以把w提出來,變成對所有的trajectory的所有的時間點的st跟at都抽一個feature,把這些feature統統平均起來,得到一個feature vector。
link |
這個平均的feature vector跟w做inner product以後,就會得到我們的expected reward。
link |
我這邊是不是犯了一個錯呢?也不算犯一個錯啦,這個θ我本來想把它改成π,但這邊忘記改了,反正式子的右邊也沒有θ也沒有π就是了。
link |
這個feature vector,這個f of st,at的平均,這個feature vector其實是depend on你的policy的,其實depend on你的actor的。你的actor不一樣,你得到的feature vector就是不一樣的。
link |
大家知道我的意思嗎?所以你可能會說,這個feature vector不是應該跟這個π有關係嗎?它確實跟π有關係,你的這個π不一樣,你當然會看到不同的state會採取不同的action,所以你的feature當然是不一樣的。
link |
所以你可以把這一串東西,就看作是對你現在的actor,就是對一個actorπ,抽一個feature,寫成finalπ,把這個finalπ乘以w,就會得到你的expected total reward。
link |
所以我們可以把r這個式子,我們可以把expected total reward的式子,寫得跟structure perceptron一模一樣。接下來有一個argmax的problem,我們說在做structure learning的時候,你會害怕遇到的問題就是解這個argmax的problem。
link |
如果這個argmax的problem解得出來的話,你就可以做得了structure perceptron,而且它的收斂的速度還是有保證的。那今天你能不能夠解arg,你能不能找到一個π讓你expected total reward最大呢?你是可以的,其實這件事情就是reinforcement learning。
link |
所以你原來reinforcement learning怎麼做,這邊就怎麼做。所以今天在inverse reinforcement learning裡面,如果要structure perceptron的方法來檢查,其實每一個iteration,你都要做一次reinforcement learning。
link |
所以它的運算量可以是很大。實際上怎麼做呢?首先先初始化一個random的reward function,根據這個random的reward function,你去找一個π,去找一個actor。
link |
這個actor可能很笨,因為它是從random的reward裡面找出來的。比如說這個random reward是說撞牆就得到10分,它是一個一直撞牆的actor。
link |
那用reinforcement learning就可以解這個東西,只是這個運算量可能會很大就是了。那你永遠可以想著有更好的方法來解它。那你就找到了一個actor,接下來你就用這個actor去跟環境做n次互動,得到了trajectory tau1跟taun。
link |
然後expert pi hat也去跟環境做n次互動,得到tau1 hat跟taun hat。那實際上這個expert可能是什麼樣的東西呢?舉例來說,如果在自駕車裡面,就是你對人類的駕駛記錄一下他在不同的情況下會做什麼樣的反應。
link |
如果今天是機器人的話,你要讓機器人自動學會做某些行為的話,那taun hat就是人去抓著那個機器人的手去做某一件事情,就是taun hat。
link |
好,那接下來呢,我們有了一大堆expert所製造的taun hat,有一大堆actor,現在你找出來的actor可能很弱的actor所製造出來的taun。那接下來呢,你就要去update你的reward function。
link |
update的準則是希望這個expert他的expected reward大過現在你的actor的expected reward。那假設你現在根據我們前一二頭影片定那個expected total reward的方式,你就定好說呢,根據我們前一二頭影片定expected total reward的方式,你就定好說呢,你的阿爸就是長這個樣子。
link |
你的阿爸就是根據pi呢,抽一個feature,其實這個feature就是把所有這邊的trajectory的state跟action的pair拿出來,都抽一個feature,把它平均起來,就得到這個final pi,總之不同的pi你會得到不同的feature。
link |
把這個feature呢,乘上一個weight parameter w,你就得到這個阿爸。好,所以我們現在呢,有了這個每一個policy的feature vector,我們有每一個policy的feature vector。
link |
那怎麼去update這個w呢?這個update的方法就跟structure perceptron是一模一樣的。我們說之前在update structure perceptron的時候,我們update的方式,這個箭頭應該從右指到左比較好,我忘了改了。
link |
我們update structure perceptron的方式就是,把原來的feature vector w,加上正確的東西抽出來的feature,減掉錯誤的東西抽出來的feature。就這邊是一模一樣的,每一個actor,每一個policy都可以抽一個feature,那個feature的定義就寫在這裡。
link |
你把正確的,你把expert的這個policy抽一個feature,加到w裡面,你把現在找出來的這個actor的feature,你把現在找出來的這個actor pi也抽一個feature,然後把w呢,減掉這個feature,那你就得到一個。
link |
你就update你的w,那你update的這個方向,是可以讓pi-hat的expected total reward大於pi-expected total reward的。這樣了解到什麼問題嗎?沒有嘛。
link |
好,那這個就是inverse reinforcement learning,那我們知道說,在structure learning裡面不是只有structure perceptron這個方法,還有很多其他方法,舉例來說,還有structure SVM,graphical model也是其中一種方法。
link |
可以用在這邊嗎?可以用在這邊,我們只是拿structure perceptron當作一個例子而已。如果你說你要用structure SVM在這裡面,當然也可以。
link |
那我們知道說,在做這個structure SVM的時候,一個特點就是,這邊這個argmax不只是找會讓reward最大,它還會找它會讓reward最大,但是同時loss也最大。
link |
它會考慮一個margin,那你當然可以把這個structure SVM的概念放到inverse reinforcement learning的framework裡面,這是沒有問題的。
link |
接下來呢,我們知道說,現在每件事情都一定要用game來做一遍才好。所以用game也可以做invitation的learning。
link |
那怎麼用game做invitation的learning呢?我們先想想看,本質上game要做的事情是什麼?
link |
本質上game要做的事情是找一個generator,這個generator產生一個distribution,這個distribution跟一個target的distribution越接近越好。
link |
那我們現在呢,可以把每,我們現在假設我們已經有一個hi-hat代表是expert的policy,那這個expert跟環境互動的時候,它會產生一大堆的trajectory tau hat。
link |
這些expert所產生的trajectory tau hat,它也是一個distribution。
link |
tau其實那個trajectory是一個sequence嘛,那我們可以把那個sequence想成是很高的空間中的一個點。
link |
那你把很多的tau hat,很多的expert去跟環境互動以後得到的sequence集合起來,那你就得到了一個distribution。
link |
那我們現在要做的事情就是認一個actor,這個actor呢,你每次去跟環境互動的時候,它會給你一個trajectory tau,這個actor跟環境互動一次的時候,它也會給你一堆state,它也會給你一個state跟action的sequence,它也會給你一個trajectory tau。
link |
那我們希望說這個actor output的distribution跟這個tau hat所形成的distribution越接近越好。來趕快問說,actor怎麼,它的這個tau hat怎麼形成distribution呢?當然可以形成distribution,因為當actor去跟環境互動的時候,環境本身它是有這個隨機性的。
link |
有時候actor本身也可以有隨機性,actor本身可能有隨機性,環境本身也可能有隨機性。你在玩Atari遊戲的時候,你在同一個畫面採取同一個action,敵人的反應不見得是一樣的,如果都是一樣的話,你閉著眼睛就可以玩了,所以不見得是一樣的。
link |
所以說我們有了這個環境的dynamic,所以我們也會得到一個tau的distribution,這邊用綠色的distribution來表示。那我們要做的事情就是,希望actor所產生的tau的distribution跟expert所產生的tau hat的distribution越接近越好。
link |
就是game可以做的事情了。實際上怎麼做呢?其實還頗直覺的。這個怎麼做呢?我們有一個expert,pi hat,它去跟環境互動,給我們一堆tau hat,這個tau hat就好像是說,我們現在如果是要用train game來畫image的話,那這個tau hat就是人手畫的image,是真正的image,從database裡面sample出來的image。
link |
那我們有一個expert,一開始expert它的參數是隨機的,然後這個expert也去跟環境做互動,那它也會得到一堆的tau。如果放到之前產生image的framework裡面,就好像說你一開始的generator很爛,你讓generator generate一大堆很爛的image,這邊只是改成不是generate image,是generate一大堆很爛的tau。
link |
那可能如果是要玩遊戲的時候,可能一開始就直接去給敵人的子彈撞一下,然後就死了這樣子的tau。
link |
接下來有一個discriminator,discriminator就是要鑑別說現在給它一個trajectory,給它一個玩遊戲的過程,然後去判斷說這個玩遊戲的過程是machine玩的,還是expert玩的。所以它要判斷說一個trajectory是,這邊有個錯,大家有發現嗎?這個是expert。
link |
寫錯了,好,沒關係。其實接下來就跟game一樣,你也可以用wgame,如果你想的話。
link |
好,這邊discriminator就是要給每個trajectory一個分數,discriminator希望說它給tau head的分數比較大,給tau的分數比較小,如果今天是wgame的話,你可能要強迫說你的d呢,是這個one mixed function等等,就是原來game怎麼做,你這邊就怎麼做。
link |
好,那接下來呢,actor就是我們原來的generator嘛,所以就是update這個generator的參數,希望它可以去騙過discriminator。update這個generator的參數,update這個actor的參數,希望現在actor新產生的這些trajectory,它放到discriminator以後,discriminator會給它比較高的分數。
link |
這整個process跟原來的game是沒有什麼不同的,所以相當的直覺。好,再來就是怎麼train這個discriminator呢?你可以說,因為一個trajectory,它這個trajectorytau,它就是一個sequence嘛,你就認個rn,把sequence讀過一遍,然後看說這個sequence要給它多少的分數。
link |
你可以這麼做,我們確認一下文件上有沒有這麼做,現在比較常看到的做法是,可能是因為tau的數目其實很少,就這個expert的demonstration其實不會太多,所以如果直接把每一個tau都當做一個example的話,可能太容易overfitting。
link |
所以我看到實作上的做法是說,我們知道說,我們把這個d of tau拆解成一大堆小的function d的和,那這個每一個小d呢,它也是一個function,它的input就是一個state跟一個action,它不是input整個trajectory,它只看trajectory的某一個時間點。
link |
它看說在這個trajectory的第一個時間點,你在看到state,看到畫面st的時候,你決定採取action at以後,你得到的值有多像expert的行為,或者是多不像expert的行為。
link |
所以d of st at就是說,今天在某一個state st採取某一個action at的時候,現在這個行為有多像expert的行為。所以我們有一個local的discriminator,它只判斷整個trajectory的某一個時間點。
link |
那把整個trajectory的所有的,把整個trajectory所有的這個state跟action的pair,通通都合起來,你就得到total的d of tau了。
link |
你得到total的d of tau,你就得到整個sequence是好的還是不好的。所以我們原來的目標是希望說,讓tau hat帶到大d以後分數越大越好,讓tau帶到大d以後分數越小越好。
link |
但現在大d是一大堆小d的和,所以這件事就變成說,我們現在有一個s跟a的pair,我們看看說它是不是expert做的。如果是expert做的話,那我們希望d of sa增加。如果不是expert做的話,是一個actor做的話,那我們希望d of sa的值要變小。
link |
那接下來呢,我們要講的是actor。actor怎麼讓d of tau的分數變大呢?那其實很簡單,就是理論上,今天你只要用這個gradient descent去調這個actor的參數,
link |
就可以說,你計算這個actor的參數,對d of tau的期望值的gradient,然後你就可以用這個gradient去update actor的參數,那actor就會讓d of tau的期望值變大。
link |
這就是我們現在要做的事情。但我們知道說呢,這一項在算gradient的時候是會有問題的,所以我們有一個policy gradient的trick,如果你不知道的話,你回去看一下policy gradient怎麼做的。
link |
我想這個大家應該知道,有一個policy gradient的trick,可以把這個update的式子轉成右邊這個樣子。而右邊這個式子是說,我們現在怎麼算這個gradient呢?
link |
這gradient的式子就是summation over我們現在sample到的n個trajectory,然後計算每一個trajectory的d of taui,我們現在已經有一個discriminator,我們可以拿這個discriminator計算這些trajectory的d of taui。
link |
然後把這些d of taui去乘上我們現在的參數,對log p of taui given pi的gradient,然後再把這些gradient做weighted上,然後去update這個actor的參數。
link |
這個p of taui given pi的意思,我想大家應該知道,就是你有一個actor,你有一個policy pi,你可以計算出這個policy pi產生這個trajectory的機率,然後再對這個機率去log,然後再去計算它的gradient。
link |
這個gradient會weighted by d of taui,然後去update actor的參數。如果這個東西有些數學式你聽不懂的話,那就不要管它,它的精神就是這樣子。
link |
它的精神就是說,現在你已經有一個discriminator,這個discriminator可以告訴你說,現在一個tau到底是好的還是不好,是expert做的還是不是expert做的,然後你就拿你的actor pi去跟環境互動n次,那互動n次的結果,你再把這n次的結果丟給discriminator。
link |
那如果discriminator說,你現在這次互動的結果感覺很像是expert做的,那我們就增加這個trajectory未來出現的機率,你就去調你的參數pi,你去調pi的參數,讓這個trajectory的機率上升。
link |
如果發現說,這個行為很不像是expert做的,就把它的參數調低。那如果這個你也沒聽懂的話,那我就告訴你說,其實啊,找這個actor,調這個actor參數的過程,就是一個reinforcement learning的發本。
link |
這個就是reinforcement learning,那只是這個reinforcement learning,它的reward就是d of taui。我們把d of taui視作reward,直接用reinforcement learning的alpha去update,去認你的actor,就是我們今天在做的事情,我們現在這一頁投影片在做的事情。
link |
那我們之前有講過說,這個d of taui啊,如果你把它只是換成d of stat的話,那你的machine就會失去planning這件事情,它就沒有做planning,那它做的行為可能就會和behavior coding很像。
link |
所以考慮整個trajectory的分數在這裡是需要的,但是你其實可以做得更好,如果你看那個sequence scan的那篇paper的話,你可以給每一個step不同的,你可以給一個trajectory的不同的step,都給它不同的value,這樣還可以做這件事情。
link |
好,那我們就summarize一下這整個algorithm。這整個algorithm是這樣,我們用game做imitation learning,你有一個expert的trajectory,tau1到taun,然後接下來你有一個初始化的discriminator和一個初始化的actor,然後在每一個iteration裡面,你都拿你現在的actor去玩n場遊戲,去跟環境互動,n次得到tau1跟taun。
link |
那這個tau1到taun呢,然後接下來你有了這個tau1到taun以後,你就可以去learn一個discriminator,discriminator會給tau1比較大的分數,給tau比較小的分數,那discriminator你可以定成這樣,你不想定成這樣也可以啦,這都是你自己決定的。
link |
然後接下來呢,你要update你的actor的參數,希望update以後呢,這個actor的trajectory丟到discriminator以後,它可以得到比較高的分數。
link |
那update的式子就是這樣,熟悉particle一點就知道我在說什麼,不熟悉你就,反正你知道它的精神在做什麼就是了。好,那事實上這件事情啊,你仔細想想,跟那個inverse reinforcement learning是不是其實在講同一件事呢?只是換個說法而已,對不對?
link |
我們就說這個D of STAT就是reward,我們剛才是說discriminator覺得它有多像actor做的,但是我們就只是換個名詞,說這個D of STAT就是假設agent在ST採取AT這個action的時候,它會得到的reward。
link |
那今天update discriminator這個式子,你其實根本可以把discriminator想成就是我們的reward function,你可以把這個discriminator根本就想成是我們的reward function,它會給正確的,它會給actor,它會給這個expert,它給expert執行的這些trajectory比較高的分數,給你的actor執行的這些trajectory比較低的reward。
link |
然後接下來這一步呢,接下來這一步我們說,我們要update actor的參數讓它可以得到比較高的D,那我們現在說D就是reward function,那update actor去得到比較大的reward function,不就是我們在講inverse reinforcement learning裡面,我們不是說在整個iteration裡面,每一次都要解一次這個reinforcement learning的法本,去maximize要得到的reward嗎?
link |
其實就是一模一樣的事情,對不對?這樣大家理解嗎?所以其實這個用game去玩imitation learning跟inverse reinforcement learning,其實指的是同一件事情,你只要說現在的discriminator,它的output就是reward。
link |
你只要說現在的discriminator,它的output就是reward。用game做imitation learning跟inverse reinforcement learning,其實就是同一回事。
link |
好,那我們之前有講過說,我們可以用這個game去做sentence generation,或者是去run一個chain bar。其實sentence generation跟run chain bar這個問題,它就是一個imitation learning的法本。
link |
雖然我們之前沒有這樣講,但事實上它就是一個imitation learning的法本。怎麼說呢?居然說在sentence generation這個task裡面,你expert的trajectory是什麼?expert trajectory就是人曾經說過的句子,人曾經產生的句子,就是expert的trajectory。
link |
所以其實要做的是,唐詩的生成,那expert的trajectory就是唐詩三百首裡面的句子。比如說《床前明月光》就是李白這個expert曾經產生的一個trajectory。李白這個expert他要去寫一首詩,那他產生的一個trajectory就是《床前明月光》。
link |
那在這個《床前明月光》的這個trajectory裡面,我們的state或者是observation,還有action到底是什麼呢?我們說一個trajectory就是一串的state,還有那一次在每一個state採取的action。我這邊用o來代表state,雖然前面是用s來代表state,但其實是一樣的意思。
link |
在這個case裡面,在這個trajectory裡面,你的o1就是beginner sentence,就是什麼都還沒有寫。然後a1就是我們採取一個action,寫了《床》這個字。那你說得到多少reward呢?不知道,因為現在是imitation learning嘛。
link |
imitation learning它的重點跟reinforcer類不一樣的地方就是,我不知道我每次採取一個action的時候,到底得到多少reward。我們只知道說expert做的事情就是對的而已。所以李白寫了《床》這個字以後,他到底得到多少reward,我們其實是不知道的。
link |
他寫了《床》之後,這個句子到底有多好,這個詩到底有多好,我們其實是不知道的。接下來,o2是什麼?o2就是已經寫了《床》這個word,然後接下來,a2就是寫了《前》這個word。那o3就是已經寫了《床前》這個word,然後a3就是寫了這個word。
link |
那每次寫一個word的時候,得到的reward有多少,其實不知道。每次寫一個word的時候,這個句子有多少,這首詩有多好,其實不知道。所以我們可以用inverse reinforcement learning的方法,用gain的方法,把這個reward把它找出來。
link |
那切法也是一樣,什麼是一個expert的trajectory,你就去錄一下人的對話,那其實就是expert的trajectory。你知道說,有一個人說,how are you,然後另外一個人就說,I'm fine,就是一個expert的trajectory。
link |
那在這邊的state和action是什麼呢?這邊的state就是現在的input加上beginner sentence,就是第一個state。那它的第一個action就是說出了i這個word。
link |
接下來第二個state就是input的sentence加上i這個word,然後第二個action就是說出了end這個word。那第三個state就是input加上in這兩個word,然後第三個action就是說出了fine這個word。
link |
這就是patient learning的problem,就是有expert在示範他在做什麼事情給你看,但是你不知道他的reward是什麼,然後你要去模仿這些expert的行為。如果你是用maximum likelihood的chain法來做sequence generation還有chain法的話,那你其實做的就是behavior coding。
link |
我們前面有講過有種種的問題,所以我們可以用game來做得更好,所以有了sequence game。講到這邊,大家有問題嗎?沒有問題的話,接下來我就舉幾個imitation learning的application,還有一些我覺得比較有趣的前瞻的研究。
link |
這個imitation learning,我們剛才有講過說你可以用它來訓練機器人,比如說你要讓機器人學會摺衣服,你就先拉著機器人的手摺一遍,然後之後他就學會摺衣服了。
link |
以下是一個真正的demo。這個paper的細節,大家再去check就好,裡面有提出幾個不同的方法,大家會demo不同的方法。
link |
demo二十次,自己做。這個是handcrafted的,做。這個是learn的,這裡沒有做好。這個就成功了。
link |
接下來是要倒查,先教他倒查。總共demo二十次,這是第三次demo。
link |
這要舉的另外一個例子是跟自駕車有關。
link |
我們知道說,你要認自駕車,用reinforcement learning的方法認是很困難的,因為你很難定你的reward function。
link |
這一個車子在路上可以遇到的事情太多了,你要怎麼把那個reward function定出來。
link |
舉例來說,你的reward function可能要考慮很多東西。舉例來說,如果今天倒車的話,是不是應該扣分?倒車很危險,所以是不是應該扣分?
link |
如果車子沒有走在該走的路上,沒貼著線走,是不是應該扣分?或者是說,如果今天車子有個急轉彎的話,會不會應該要扣分?
link |
這些東西合起來很複雜,因為根本不知道說,如果今天車子倒車的話,應該要扣多少分數,或者是說,如果他今天沒有走在路上的話,應該要扣他多少分數。
link |
那怎麼辦呢?就用imitation的方法來教這個machine,那就是去找一些真正的人,去真的開一下車,然後machine就根據人的駕駛真正的行為,來學習說他要怎麼控制這個自駕車。
link |
這邊是paper裡面的結果。這個paper裡面,他的自駕車是在一個停車場裡面運動,他要從停車場裡面的某一個位置,他會停到某一個停車格裡面。
link |
你可能會問說,他可以停到停車格裡面去嗎?這個問題不用擔心,因為如果是reinforcement learning的話,你說,我的初始位置在這裡,停車格在那裡,我一直用reinforcement learning的方法去學,遲早可以停進去的。
link |
就好像說,你就玩atari小遊戲,你只要把所有可能的狀況都試過一遍,最後總是會找到一個好。所以你不用擔心machine可不可以停得進停車格裡面去。這邊的重點是,machine可不可以學會不同駕駛的行為,因為不同的駕駛可能就有不同的,他心裡、內心深處可能有不同的reward function,他可不可以學到不同的行為。
link |
所以前面這一排是這個paper裡面叫做nice driver,就是他是一個循規蹈矩的driver。比如說他從這個地方開始開,目的在這邊,他就沿著這個路走走走走走,然後就走到停車格裡面去。
link |
我在這個paper裡面他的training data其實很少,他training data就是這個圖片上秀的這四筆,就只有這四筆training data,就只有四個example的expert trajectory。
link |
就像machine learn,machine就會知道說,現在如果在testing的時候叫他從這個地方開到這個地方,那他會循著這個道路,循規蹈矩地繞一圈,然後開進來。發現說其實好像沒有特別有效率,因為他其實可以從這個地方直接走走走走到這邊開進來。
link |
他走了一個其實是一個遠路,但他就是模仿這些expert的行為。然後這個第二排,這個expert他叫做sloppy的expert,這個expert會怎樣呢?他會超捷徑。
link |
舉例來說,現在他的初始位在這邊,他的終點在這邊,他會切過其他的車,就是說這邊其實是不能夠走,這邊不是路,但是他可以從這邊,反正中間也沒有車,他可以開得過去,他就直接從這個地方離開原來該走的道路,離開道路的,然後到另外一個地方。
link |
他是個懶惰的driver。如果是懶惰的driver的話,那machine就會學到懶惰driver的行為,他就知道說離開道路是沒有關係的。或者最後一個case是可以倒車的driver,就是driver可以倒車,那machine就會學到說倒車是沒有關係的。
link |
這邊還有另外一個例子是have training的例子,這邊是要教machine怎麼規劃你要走的道路。這邊的case是這樣子的,在training的時候你告訴machine說,如果你要從這一點走到這一點,那你就走這一條綠色的線。
link |
這個是一個空拍圖,你可以知道說這是一條道路,左右兩邊顯然是森林。告訴machine說,你要在道路上走,你要從這邊走到這邊。
link |
那machine接下來就會學到了一個reward function,這是用inverse reinforcement learning的方法,所以他會學到那個reward function,他會知道那個reward function長什麼樣子呢?如果我們把那個reward function套到這一張圖上的話,他會知道說黑色應該是代表reward大,然後白色代表reward小。
link |
他會知道說,如果走在道路上就是reward大,走在森林裡不走在道路上就是reward小,所以之後你只要從這個點走到這個點,他就會循著綠色這一條線走。
link |
但是如果你在training的時候,你給他不同的training data,上面跟下面這個圖是一樣的,初始的止,起點和終點也是一樣的,但是你告訴machine說,你今天在走的時候,你不要走馬路,你要故意走在森林裡面。
link |
所以你今天是有一個合理的application,比如說要躲避轟炸機的轟炸。所以你今天在從下面這個點到上面這個點的時候,你要盡量避開道路,你要盡量走在森林裡面。
link |
如果你給machine的training data是不一樣的話,他就會學到不同的reward function,所以他reward function就變了,今天上面這兩張圖是一模一樣的,但是因為imitation的對象,expert的policy不一樣,所以學到的reward就變成不一樣,就會變成說走在森林裡面的reward是大,走在路上的reward是小。
link |
那今天在同一個情況下,告訴machine說要從這點走到這邊,machine就會知道說,他要躲到森林裡面去,然後再走出來。
link |
這是一些應用,接下來舉幾個研究的例子。一個有趣的研究叫做third-person imitation learning。這個third-person imitation learning,你仔細想想,我覺得還蠻實用的。你看剛才我們怎麼教機器人做事情,我們是拉著機器人的手去做事情。
link |
舉例來說,你要讓機器人學會打高爾夫球,那你就是拉著機器人的手,讓他去打高爾夫球。但是實際上,machine在學習的時候,他其實不是用第一人稱的視角在學習的,對不對?
link |
你仔細想想看,真正的學習方法,如果machine要跟人一樣學習的話,也許他學習打高爾夫球的方式是,有人在打高爾夫球,然後他在旁邊看。但這樣會造成什麼問題?這樣會造成machine自己要去打高爾夫球的時候,他的視角跟他學習的時候的視角是完全不一樣的。
link |
你看,machine看到的expert的視角,都是第三人稱的視角。而他自己在做這些action的時候,他自己在打高爾夫球,如果是今天要做打高爾夫球case的話,machine打高爾夫球的case,他看到的是第一人稱的視角。
link |
如果你認一個discriminator,discriminator一定馬上發現說,現在expert的trajectory是這個樣子,machine的trajectory是這個樣子,完全不一樣,一秒就會被發現。machine不管怎麼努力,他可能都沒有辦法逼近expert的trajectory,因為他在觀察expert和他自己在跟環境互動的時候,他們的視角本來就是不一樣的,所以永遠弄不成一樣的東西,那怎麼辦?
link |
這邊還有一個蠻有趣的想法,在這個想法裡面他引入了domain adversarial training的概念。大家知道domain adversarial training嗎?不知道的同學去抽一下。
link |
不好意思,原來這麼多人不知道。domain adversarial training是這個樣子的,一個上學前machine的女友講,她是什麼意思呢?她是說,如果我們現在有data來自於兩個不同的domain,那我們有一個類似game的方法,可以把兩個不同domain的featuremap在一起。
link |
怎麼做?我們就是train一個feature extractor跟兩個discriminator,假設現在是手寫數字分類的問題,其中一個discriminator他的工作就是要辨識數字,根據feature extractor,extract出來的feature去辨識數字。
link |
然後接下來有另外一個domain的classification,他會決定說現在這個feature是來自於哪一個domain。那在learning的時候,feature的generator他的目標就是,他希望他產生的feature可以被正確的辨識出正確的數字,但沒辦法辨識出是哪一個domain。
link |
所以今天feature extractor他會想辦法產生feature去騙過domain的classification,他想辦法產生出來的feature是domain的classification,沒有辦法鑑別的。這樣大家了解這個意思嗎?
link |
如果有問題的話,歡迎舉手發問。好,大家都知道嗎?好,那其實今天的概念跟今天這個third-person imitation的概念,跟domain-adversarial training是一模一樣的。
link |
如果你有看過domain-adversarial training的paper,你就會覺得說這個圖很熟啊。好,那今天在這個test裡面,他的classifier,他的discriminator是input兩個observation,是input t時間點observation跟t加4這個時間點的observation。
link |
但是在今天為了簡單起見,你就把t加4想成是action好了,因為你今天採取的action會影響你接下來會看到的畫面,所以今天t加4是跟你的action有關的。
link |
講action可能比較容易。所以discriminator就是看一個observation跟看一個action,然後決定說這個observation跟這個action的pair,他們到底好不好,像不像是expert做的。
link |
好,但是我們今天說因為在third-person imitation learning這個problem,expert的observation跟machine的observation本來就很不一樣。所以怎麼辦?我們今天另外再learn一個neural network。
link |
這個neural network它的工作呢,今天再learn一個domain classifier,這個domain classifier的工作就是他要去判斷說現在這個observation,現在input的這個observation,它是machine的視角還是expert的視角。
link |
然後呢,今天這一個classifier,它的中間的某一個hidden layer會被丟到這個domain classifier裡面去。所以你可以想成說現在其實有三個network,一個network負責抽feature,它丟了feature,它的feature一方面會丟給domain classifier,
link |
決定說現在這個畫面是expert看到的畫面還是machine看到的畫面。然後今天會有一個discriminator,discriminator決定說在這個畫面下採取這個action,在這個畫面下採取這個action到底是expert採取的action還是machine採取的action。
link |
接下來在learning的時候呢,這個feature attractor目的就是希望可以一方面讓discriminator可以正確的判斷說現在這個action是machine採取的還是expert採取的,另外一方面同時這個feature attractor又希望可以騙過這個domain classifier,
link |
他希望說雖然原來expert和machine看到的視角不一樣,但通過這個feature attractor以後,兩個不同的視角會被align在一起,這個domain classifier會分辨不了說這個視角是來自於machine的視角還是expert的視角,
link |
這domain classifier會把兩個不同的視角放在一起,然後今天這個classifier是根據這個一樣的視角再去決定說是expert的行為還是machine的行為。
link |
那你可能期待說machine做的是比如說像我剛才講的打高爾夫那個例子,那其實在真的實驗裡面沒有做到那麼神奇,在真的實驗裡面這個視角的不同沒有那麼大。
link |
這個是比如說machine觀察到的視角,這個是machine實際在操作的時候的視角,是由轉一個角度加上改變顏色。那是不是真的可以做得起來呢?可以做得起來。
link |
這個上面跟下面就是玩兩個不同的遊戲,那橫坐標就是training的iteration,我就看上面就好了。
link |
那你會發現說今天有一個藍色的最高的線是RL,這個意思就是說我們就不要玩什麼imitation learning,我們假設說machine真的就可以去玩這個遊戲,它也可以得到reward,然後它是自己在玩的,然後又有reward function,然後它的視角training跟passing的視角沒有什麼不一樣的問題,所以這個是一個upper bound。
link |
那黑色的線呢?黑色的線是說假設machine跟expert的視角是一樣的,但是machine還是要自己把這個reward function推出來,那這個時候得到的是黑色這條線。
link |
那紅色這條線是說machine的視角跟expert的視角就是不一樣,那你也沒做什麼特別的處理,那就爛掉,學不起來。
link |
但是如果你今天說machine的視角雖然跟expert的視角不一樣,但你用了剛才前頁講的那個技術,你有一個domain classifier去強迫feature detector把expert的視角和machine的視角line在一起,讓expert的視角跟machine的視角可以是一樣的,那你得到的就是綠色的這條線。
link |
好,所以這個是一個還蠻有趣,而且我覺得未來可能會很實用的一個方向。那另外一個我要講的是one-shot的功能。