back to index
Energy-based GAN
link |
好,那什麼是Energy-Based Gain呢?
link |
Energy-Based Gain跟原來的Gain,它有不同的思維。
link |
那我們再很快地藐覆一下原來的Gain。
link |
那我們知道在原來的Gain裡面,這個Discriminator它扮演了一個引導者的角色。
link |
假設現在綠色的這個Data Point是Real的Data Distribution,藍色的是你的Generator的Distribution。
link |
那Discriminator認出來以後,可能像紅色這一條線,它會引導藍色的Distribution向右。
link |
因為藍色的Distribution,Generator Distribution,會試圖在這個DOM,在Discriminator的output上面得到比較大的值。
link |
那藍色的Distribution可能跑過頭,Discriminator會再把它拉回來,最後當藍色的Distribution跟綠色的Distribution重合的時候,
link |
Discriminator就會功成身退,它就變成平的。
link |
那我們上次也有看過這個Video了,在這個Video裡面,我們在很快地放一下,這個Video要強調,在這個Video裡面,我們之前已經看過了。
link |
那這邊有一件事情要強調的事情是,你看看這裡,它的這個Discriminator是一個Linear的東西。注意一下,你看它Discriminator的顏色,從它Discriminator的顏色你可以看出來說,它是Linear的。
link |
但是,雖然Discriminator是Linear,那Distribution呢,Distribution是中間的原點的地方,Distribution是原點的地方,但是Discriminator是Linear。
link |
那如果你今天要用一個Generator,產生落在,它的這個分布是落在原點附近的,那它可能不是一個Linear的Generator。你的Generator要產生這個Distribution,其實沒有辦法是Linear的,它要是比較複雜的。
link |
但是Discriminator它是比這個Distribution還要更簡單,因為它的目標只是要引導這個Distribution的移動,所以它不見得需要跟你的Distribution一樣複雜,它跟Distribution簡單沒有關係,它只要能夠引導這個Distribution就好了。
link |
但是這也許不是GAME唯一的想法,也許可以用另外一個想法。你知道我們之前在講這個Structure Learning的時候,我們有講說,我們今天在處理一個問題的時候,我們可以定一個Evaluation的Function。
link |
這個Evaluation的Function,它Input是一個ObjectX,它的Output是一個Scalar,Output f of x 是一個Scalar。
link |
那今天我們要做的事情是找一個Evaluation的Function,Input是一個ObjectX,Output就是一個Scalar,這個Output的ScalarEvaluate這個Input的ObjectX它有多好。
link |
它Evaluate這個Object它有多好。舉例來說,如果X代表的是Image,那今天Realistic的Image,也就是你Database裡面真正的Image,它帶到這個Evaluation的Function裡面,它應該要有很大的值。
link |
然後那些不Realistic的Image,看起來奇怪的Image,帶進這個Evaluation的Function,就要得到小的值。你有這個Evaluation的Function以後,這個Evaluation的Function可以就是一個Neural Network,Input一個X,Output一個Scalar。
link |
如果我們現在有了這個Evaluation的Function以後,我們就可以找一個X,我們就可以找一個X,這個X可以讓F of X產生很大的值。
link |
如果我們可以找一個X,這個X可以讓F of X產生很大的值的話,那我們就可以用這個F of X去產生Realistic的Image。所以我們只要找X,它可以讓F of X的值很大,我們就可以用F of X來產生Image。
link |
再來就是,要怎麼找這個F of X呢?在概念上是這個樣子。在概念上,我們要找的這個F of X,它要在有Real Data的地方,它的值是大的。
link |
所以就看說你的Database裡面,Real Data長什麼樣子。假設現在這個是,現在雖然在圖上,我們使得這個平面,我們是畫一個這個一維的Space。但實際上,這邊每一個點,比如說如果它代表一張Image的話,它是一個很高維的Vector。
link |
那總之呢,你就把你的Database裡面的Image都拿出來,然後你希望你的F of X在這些Database裡面的Image裡面的這個值呢,都越大越好。你希望把你的Image裡面,你的Database裡面的那些Image帶到F of X裡面,它的值呢,都越大越好。
link |
但是光這麼做,是不夠的。因為你可以說,我胡亂找一個Function F of X,它不管帶什麼Image進去,Output都是1億。那這樣子,一點用都沒有。
link |
所以光是讓Database裡面的Image,它帶進F of X,它的Output值越大越好,是不夠的。我們同時要讓不在Database裡面其他的東西,就是其他看起來不Realistic的Image,它帶到F of X裡面,它的值越小越好。
link |
但是在實作上,這樣子是有問題的。Real的Data就是你Database裡面的Data,你可以把它Sample出來。它就是,假設你Database有5萬筆Data的話,那綠色的點就是5萬個點。
link |
但是藍色的部分呢,不是Real Data的Data Point,不是Real Image的Data Point,太多了,無法窮取。那所以怎麼辦呢?理論上我們要做的事情是,窮取所有不是Real的Image,讓它帶到F of X裡面,都讓它的值越小越好。
link |
但是實際上,我們沒有辦法窮取所有不是Real的Image,所以我們要想其他辦法來處理這個問題。
link |
好,請問大家有沒有問題呢?這樣大家知道我們要做的事情嗎?好,那你回想一下,我們之前在講Structure Perceptron的時候,我們是怎麼說的?我們說Structure Perceptron是這樣,我們有一大堆的Training Data,每一筆Data都是一個X跟Y Head的Pair,然後我們說我們要找一個Weight Vector,其實所謂的我們要找一個Weight Vector的意思是說,
link |
我們要找一個Function,它代入的就是XY,然後這個Function呢,它是W跟一個Feature Vector,Find of XY的Inner Product,這個麥克風怪怪的,麥克風,喂喂喂,喂喂喂,好,喂,好,沒聲音啦,好,算了,那我們就不要麥克風好了。
link |
你看後面的都聽得清楚吧?好,那現在呢,這個F of X是W跟Find of XY的Inner Product,所以找W的意思就是,其實就是要找這個Function,F of XY,那這個Structure Perceptron要不然是這樣,你先Initialize一個W,接下來呢,對每一個Training Data裡面的X跟Y Head的Pair,
link |
我們都說,我們去找一個Y Delta,它可以讓現在我們要找的這個Function,F最大,OK,XR是給定的,但我們要找一個Y Delta,我們要找一個Y Delta,它可以讓這個F of XY的值最大,所以這邊我們要解一個ARG Max的Problem,
link |
我們要窮取所有可能的Y,看哪一個Y可以讓F of XY最大,好,如果今天我們找出來的Y Delta不是正確的答案Y Head,那我們就Update W,我們就把W加上Find of XY Head,減掉Find of XY Delta,這個式子的意思就是,
link |
我們希望呢,去增加F of XY Head,同時減少F of XY Delta,我們這邊不會只單純的增加F of XY Head,因為如果只單純增加F of XY Head,其實很容易的,你只要把W,比如說乘上一個,乘上兩倍,那F of XY Head直接就變兩倍,所以不是這樣,
link |
我們不只要增加F of XY Head,同時要減少F of XY Delta,好,那就跑這個Process,直到W不再改變,直到這個W的Update停止為止,好,那在這個Task裡面,我們的Evaluation Function就是F of XY,
link |
那我們每次呢,都要去找一個最Negative的Y Delta,然後呢,把XRY Delta的值壓低,把XRY Head的值提升,那今天呢,我們說,我們之前都有講說,在這整個Process裡面,有一個步驟是困難的,什麼步驟是困難的呢?
link |
找ARG Max的這個步驟是困難的,因為Y,如果Y是一個Structure的東西,它的Space太大了,你沒有辦法窮取所有的Y,去看說哪一個Y可以讓這個式子最大,所以這個步驟是有問題的,這個步驟導致我們的F of XY沒有辦法太複雜,如果是Linear的,在某些狀況下,你可以解這個問題,
link |
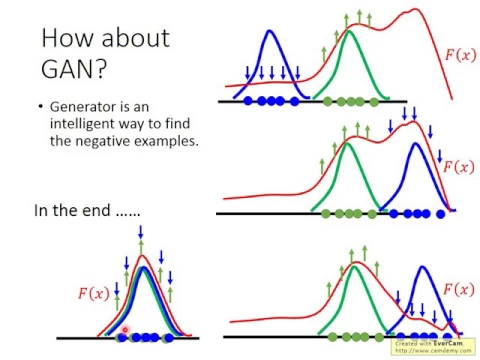
但如果不是Linear,你可能就不會有太多簡單的演算法可以讓你解這個問題,這個步驟感覺是困難的,那如果今天用Game的角度來看呢,如果用Game的角度來看,看Generator它在做的事情,其實它就是用了一個比較Intelligent的方法,去找Negative的Example,這樣大家了解這個意思嗎?
link |
怎麼說呢?現在假設這是Real的Distribution,這是Generator原來的Distribution,那我們有一個Evaluation Function,它長的是這個樣子,在Learn這個Evaluation Function的時候,我們讓Real的Data帶進Evaluation Function的值越大越好,就是這個部分,
link |
我們讓Generator Generate出來的Data帶進這個Evaluation Function的值越小越好,所以這個部分的F of X會被壓低,但是我們提升綠色這個部分,降低藍色這個部分,並不知道其他部分會發生什麼事,搞不好提升綠色部分,降低藍色部分,會讓右邊這個區塊值變得很大,也說不定,我們不知道。
link |
好,那接下來呢,在Game裡面我們不是要Update Generator嗎?Generator的參數會被Update,讓Generator Generate的Data Point是可以Maximize,讓F of X的值最大。假設你把這個F of X的值想成是Discriminator的Output的話,那我們今天要Update Generator,就是希望讓Generator產生新的值,可以讓F of X的值最大。
link |
所以你今天Update你的Generator以後呢,可能Generator的Output就跑到這個地方,而你Update你的Generator,那可能它就跑到這個地方,因為這個地方F of X的值最大嘛,所以Update Generator,然後Generator Generate出來的Data Point就在這個地方,那接下來呢,我們要讓Real Data帶到F of X裡面的值變大,讓Generator Generate的Data帶到F of X裡面它的值變小。
link |
於是就Update F,讓F變成這個樣子,那這個Process就一直反覆持續下去,最後,最後,當這個Generator產生出來的Data Distribution跟Real Data Distribution重合的時候,這個時候,把F of X往上拉,往上提升,跟把F of X往下壓的力量會抵消。
link |
最後Update就會停止,然後這個時候你找到了一個F of X,而我們說在Game裡面這個F of X其實就是Discriminator的Output,這個F of X其實就是Discriminator,但是這個DiscriminatorChained到最後的時候,它並沒有死掉,它並沒有Fat,而是這個Generator其實告訴我們說Real的Data出現在哪個地方。
link |
某些地方,Real的Data出現的Density越高,那這個F of X這個Discriminator Output的值就越大。
link |
實際上,到底在Chained Game的時候,是比較接近原始的Bianca Fellow的想法,還是比較接近這個Case呢?其實你可以自己做實驗study一下,其實有可能是接近現在這個投影片上所說的這個Case的。
link |
為什麼?因為在做Game的時候,有時候有人會做Experience Replay,也就是說我們有好幾代的Generator嘛,照理說你只要比較現在的Generator跟Discriminator之間的差異,但是有人會做說把過去的Generator所Generate出來的Data Point也都拿出來當做Negative Sample。
link |
意思就是說,你要告訴Machine說,雖然現在GeneratorGenerate出來的Data Point是在這個地方,但它之前也有Generate在這個地方,所以不只要把這個地方壓低,也要把這個地方壓低。
link |
有些人會,有些人呢,你會看到有些文獻是有這麼做的。另外一方面呢,我們今天在Chained Discriminator的時候,你想想看,在Chained Discriminator的時候,你並不是每一次都從頭Chained你的Discriminator,對不對?
link |
我們都會把Discriminator的參數,我們每一次要Update Discriminator的時候,我們並不是從頭Random開始Chained,我們會繼承過去的參數。
link |
如果按照原來的Gain的想法,原來的Gain的想法,Discriminator的作用是要Evaluate兩個Divergence之間的Difference,你其實感覺並不需要繼承它過去的參數,對不對?並不需要在每個Iteration,Discriminator都繼承過去的參數。
link |
但在實作上,你會繼承過去的參數。如果DiscriminatorChained到最後是要壞掉的話,那Discriminator其實會越來越差,那你繼承過去的參數其實沒有什麼太大的意義,但是我們會繼承過去的參數。
link |
所以也許Energy-based的想法也是有一些道理的,而且你會發現在文獻上,你Chained好一個Gain以後,Discriminator會被用在其他的Application上,所以代表那個Discriminator並不是Chained完Gain以後它就死掉了,而是它是有一些作用的,所以也許Energy-based的想法也是有道理的。
link |
也許你可以在留言終結者的Final裡面驗證一下這件事,就是你Chained了Gain以後,到底最後你的Discriminator長什麼樣子,你能不能真的Chained到讓Discriminator死掉變成Fed了,我感覺好像不見得那麼容易可以做到這件事情。
link |
但是如果我們今天要Energy-based的想法的話,Discriminator必須要可以Model這個True的Data Distribution,所以我們剛才看剛才的例子,我們剛才不是有一個YouTube的一個Video的例子嗎,在那個Video的例子裡面,我們的Discriminator是Linear,在那個Case裡面,那個Discriminator就沒有辦法Model Data的Distribution。
link |
所以如果我們今天要Energy-based的想法的話,我覺得Discriminator的Capacity要夠大,它的複雜度要夠大,大到它可以Model Data的Distribution,而不僅僅是引導Data所行進的方向。
link |
好,那這個是這個Young-Lakhan Proposed的Energy-based的Gate,然後縮寫的是EB Gate。那在Energy-based的Gate裡面呢,它把Discriminator的Output就當Discriminator當作是Energy Function,那什麼是Energy Function呢?
link |
我們剛才有講一個Evaluation Function嘛,其實Energy Function就是Evaluation Function取負號,就是Energy Function。在前面講那個,我之前講那個Structure Learning的時候,我都說了一個Evaluation Function,Evaluation Function Output的值越大,代表現在Data越Realistic。
link |
那Energy Function跟這個Structure Learning的Evaluation Function講的事情是一模一樣,是同一件事,只是當說我們用Energy Function的時候,意思是說Energy Function Output的值越小,代表這個Data越Realistic,所以只是Evaluation Function反過來而已。
link |
在這篇Paper裡面有一個特殊的地方是,他們用Autoencoder當作Discriminator,我們剛才說這個Discriminator就是Evaluation Function,就是Energy Function。
link |
那另外他在Loose Function上面做了一個小小的變化,他有加了一個Margin,那等一下會細講這篇Paper的他的式子長什麼樣。那現在看一下他得到的成果,那他有一個我印象很深刻的成果是,他可以在Image內上合出256x256的圖片,直接產生256x256的圖片,我們在作業裡面才做48x48,96x96而已,這麼小張,256x256的圖片很大張。
link |
而且他產生的結果其實還算蠻好,我這邊截取了幾個結果,比如說這是一個,你都可以看得懂這是什麼,這是海象,他是被斬首,然後這個是鍊成獸,他有很多的毛,看起來像是個猩猩之類的,這個顯然是個猴子在草原上,他鍊成的結果我覺得還蠻驚人的。
link |
那這個EBGAN是怎麼做的呢?在Generator的地方都跟其他人一樣,就是input一個Z,output一個X,那特別的地方是在Discriminator的地方,他的Discriminator裡面有一個Autoencoder,那我們知道Autoencoder就是有一個Encoder,有一個Decoder,你把一個X丟進去,通過Encoder變成一個Code,再把Code通過Discriminator,
link |
還原回來會得到另外一張Image,我們把Reconstruct還原回來的Image叫做Xtilt,那Discriminator是input一張Image,output是一個Scalar,如果你是放Autoencoder在這邊,你是input一張Image,output一張Image,他不是output一個Scalar,怎麼output一個Scalar?
link |
把X跟Xtilt相減,你就算說現在這個Autoencoder給他某一張ImageX的時候,他的Reconstruction error有多大,這個Reconstruction error就是這個Discriminator的output,或者說這個Reconstruction error就是現在Energy function的Energy,那這個Reconstruction error最小就是0。
link |
所以我們現在有一個Discriminator,他input是X,他的output是一個Scalar,那這個Discriminator他最小是0,最大可以到無窮大,然後如果是realistic的Image,我們希望他越接近0越好,跟之前講的都不一樣,之前講說realistic的東西,我們希望他越接近1,或者是越大越好,generated的東西越接近0,或者是越小越好,那這個EBGAN是反過來的,
link |
因為這個Discriminator他是一個Energy function,那Energy function希望給realistic data比較小的值,所以今天realistic data,這個Discriminator output值是小的,Reconstruction error是小的,如果是generated data,他的Reconstruction output值是大的,他Discriminator output值是大的。
link |
怎麼train這個EBGAN呢?就是首先sample一些real的exampleX,然後再從一個prior distribution sample一些Z,再把Z丟到generator裡面去產生一些Image。
link |
好,那這個Discriminator的loss function長的是這個樣子,這個Discriminator他要minimize下面這個function,這個function裡面有兩項,第一項是D of X,Discriminator要讓real data的D of X越小越好,這個跟我們之前講的是反過來的,大家了解吧,大家聽得懂吧。
link |
我這邊應該要換一個notation,也許不該用D,但是我已經寫下去就來不及改了。總之你要記得說這個跟之前講WGAN的時候是反過來的。
link |
好,所以今天real的image他的D of X要越小越好,然後理論上我們應該要讓generated的image他的D of G of X,就是我們要讓D of G of Z越大越好,不過這個我們等一下再講說後面這個max這項到底是什麼意思。
link |
好,那接下來在train generator的時候,就是sample一堆Z,然後我們希望generator可以minimize下面這一項,把Z帶到generator裡面產生一張image,然後這個image帶到D裡面,他的energy越小越好。
link |
好,那我接下來解釋說這個discriminator的這個loss到底代表了什麼意思。原來直覺上應該是這個樣子,應該就是要讓D of Xrealistic的image,他的energy越小越好,讓fake的image,generated的image,他的energy越大越好。
link |
也就是說,假設你現在有一堆real的image在這個地方,你有一堆fake的image,就是藍色這個點在這些地方,那你希望你的discriminator output應該要長得像紅色這一條線,在綠色的地方把它壓得越低越好,在藍色的地方把它拉得越高越好。
link |
那這樣做會是有問題的,為什麼?因為拉得越高越好,可以到多高呢?壓得越低越好,最低就到零而已,沒有辦法再更低,reconstruction error最低就到零,沒有辦法弄出一個負的reconstruction error。
link |
這個generated的data,你如果要讓它越高越好,可以高到多高?它可以高到無窮大。你知道,這個reconstruction是比較困難的,而destroy是比較容易的。就是你現在有一個autoencoder,你input一張image,你要讓output跟input一模一樣,這個需要花點功夫去train你的autoencoder。
link |
你要讓input一張image,output跟input差很多,這個是很容易的,它value random就好了。所以,如果我們今天只是拿上面這個式子來train的時候,那你可以猜想說這個discriminator最後會很高興地不斷地把generate這些image的error弄得很大。
link |
因為它很輕易地把error弄得很大,然後它就會懶得去管這個real的image,它懶得把real image的error變小,因為這件事情比較花力氣,而且它會花很多力氣去把generated的error都一直拉高。
link |
所以這邊才需要改一下這個式子,這個式子是長這個樣子,這個式子是max0跟m-d of g of z,這個m就是一個margin,它是一個你定好的值。
link |
所以這個max的意思就是說什麼時候會有loss,如果今天m-d of g of z大於0的話,會有loss,如果今天m-d of g of z小於0的話,就沒有loss。
link |
什麼意思?如果今天generator generate出來的image,它帶到這個discriminator,帶到這個energy function裡面,它的energy大於n的話,就不要給它penalty了。
link |
這邊這個max這一項的意思就是,如果generator generate出來的這些image,它的energy已經大於n的話,就沒有penalty了。這樣我們訊就會知道說,雖然把那些fake的image把它摧毀掉,感覺好像很爽很容易,但是當它讓fake的image的reconstruction error大於n以後,它就不再有任何的benefit了。
link |
所以它就只會讓generator的image,它的這個reconstruction error大於n。大於n以後,它就會focus在把real的image的這個reconstruction error壓小。
link |
那generator做的事情就比較直覺了,如果我們看generator的話,generator要做的事情就是,希望generate出來的image,它的energy是小的,希望generate出來的image,它的這個error是小的。
link |
所以呢,既然real的data所在的地方,energy是小的,那generated的data就會往real的data靠近。
link |
好,那現在我們要問的問題是,假設現在train到最後,real的data跟generator generate出來的data,它的distribution是一模一樣的,那會發生什麼事呢?假設real的data跟generator的output distribution是一模一樣的,那會發生什麼事呢?
link |
你可以想想看,如果今天,我們就假設我們只有一筆real的data,一筆generated data,我們只有一個x,一個z,那現在generator generate出來的distribution跟real distribution是一模一樣的,所以d of x的值會跟d of g of z的值一模一樣。
link |
因為x會等於g of z,所以d of x跟d of g of z的值是一模一樣的,我們假設這個一模一樣的值就叫做gamma。這樣大家可以接受嗎?有人有問題嗎?
link |
好,那你想想看,你覺得現在這個gamma的值落在哪裡,會讓這個discriminator loss最小?是不是gamma落在0到n中間的時候,discriminator loss最小?
link |
你懂我意思嗎?假設gamma在0的時候,你的loss是多少?你的loss是n。gamma在n的時候,你的loss還是n。gamma在0到n中間的任何值的時候,你的loss都是n。這樣大家了解我的意思嗎?
link |
所以現在的狀況就是,當generator所generate出來的data跟real的data distribution一模一樣的時候,這個時候,這個energy function算real data跟generated data的energy都會是一個gamma的值,而這個gamma的值會介於0到n中間。
link |
好,那我們知道說real data分布的地方,在check完以後,它的值會介於0到n中間。那其餘部分呢?其餘部分的值可能不會介於0到n中間,為什麼?
link |
因為我們現在做的是一個autoencoder。如果你train的是一個binary classifier,你可以想想看binary classifier,它在平面上的值是怎樣。假設你是linear的binary classifier,就畫一條線,一邊是接近1,一邊是接近0。
link |
但是如果是autoencoder呢?autoencoder它的recontraction error是d的區域,在input的空間上是有限的。假設你的autoencoder架構有設計好,中間有一個bottleneck的layer,那只有少部分的input可以被完全正確的recontract。
link |
因為你有那個bottleneck的關係,甚至你可能還有加上別的,比如說sparse coding或regularization等等的限制。一個autoencoder,通常在input的space上面,只有少量的區域,它是可以被完整的recontract回來的,只有少量的區域,它的energy是d的,只有少量的區域,它可以給它assignd的energy。
link |
那如果d的energy已經被real的data佔去的話,那其他地方,不是real data分布的地方,它可能就會有高的energy。所以如果我們用autoencoder來train的話,它並不會像一般的game一樣最後會死掉。這樣講大家有問題嗎?沒有嗎?
link |
我有一個問題。我們現在不要管real data以外的地方,如果我們考慮的是有real data分布的地方,但我們假設real data的分布是比如說是一個normal distribution,比如說它中間的分布比較大,兩邊的分布比較小。
link |
可是,如果按照現在這個想法的話,它應該還是沒有辦法給real的,就是這個autoencoder這個energy function的output,還是沒有辦法反映data的density啊,對不對?還是有人覺得可以。
link |
就是說,我們只知道說有real data分布的地方,它的值應該是gamma。但是我看不出來說,如果今天某個地方real data的值的density比較大的話,它會有比較低的值。還是大家有什麼不一樣的看法?
link |
如果你有什麼看法的話,你等一下下課來告訴我,我把你的名字寫在這一頁的投影片上面。
link |
好,所以好像跟原來energy的想法還是有點不一樣就是了,我也不知道為什麼。好,沒關係。好,那在這個EBGAN裡面,還有另外一個propose的東西是,它叫做pooling-away term。
link |
這個pooling-away term是希望churn出來的generator,它可以output比較多樣性的output。它希望這個generator可以output比較多樣性的,可以有比較多樣性的output。
link |
好,這件事情是怎麼做的呢?我們先讓generator輸出一個batch的generated data,那假設裡面有一筆data叫做xi,有另外一筆data叫做xa。
link |
好,那今天呢,本來generator要做的事情是要去minimize reconstruction error。現在除了minimize reconstruction error以外,除了讓它輸出的image可以minimize reconstruction error,除了讓它輸出的image可以讓energy function算出來的值比較小以外,還要有下面這一項。
link |
那下面這一項的意思是什麼呢?下面這一項的意思是說,我們會去計算我們generate出來的一個batch裡面的image,把一個batch裡面的image兩兩拿出來,然後丟到這個discriminator裡面去。
link |
那discriminator是一個autoencoder嘛,所以你丟進一個xi,你可以從encoder的output得到一個code的ei。那我們希望xi丟到encoder裡面的output ei,跟xj丟到encoder的output ej,它越不一樣越好。
link |
我們希望ei跟ej它們算出來的cosine similarity越小越好,它們越不一樣越好。那如果這樣做的話呢,我們就可以增加generator output的diversity,我們就可以讓generator output的這些image比較不一樣。至少generator output的這些image從encoder看起來,它的code是不一樣的。
link |
另外在那個EBGAN的paper裡面還提到說,你可以把它這個EBGAN視為是一種特別的、比較好的訓練autoencoder的方法,因為我們說我們的discriminator就是一個autoencoder。
link |
在原來的autoencoder裡面,這個autoencoder唯一做的事情就只有把real的data的reconstruction error變小。在GAN的情境下,把autoencoder當作discriminator的時候,autoencoder不只要讓real的data的reconstruction error變小,
link |
同時還有另外一項,它要讓generator generate出來的fake的data,它的reconstruction error變大。
link |
那這樣做的好處就是,你在認這個autoencoder的時候,它不能夠只是單純地把input的image背下來。就假設你今天autoencoder沒有設計好的話,它中間,假設你今天autoencoder沒有設計好的話,它可能只是把input的real的image都背下來,讓real的image的reconstruction error都是0。
link |
那它其實搞不好整體而言是一個identity function,其實你丟盡任何image的reconstruction error都是0。這件事情,如果你的autoencoder的bottleneck layer太大,你沒有加sparse coding,沒有加regularization的話,這件事情也許是有可能發生的。
link |
但是如果今天把這個autoencoder放在EBGAN的情況下去train的話,那你會增加它的限制,因為它必須要讓那些fake的image有比較大的reconstruction error,它就不能夠只是一個單純的接近identity的function。
link |
那這個EBGAN呢,它還有一個進階的版本,叫做margin adaptation game,它是馬game,沒有豬game,但其實有貓game,但沒有狗game。
link |
真的有貓game,有一個cat game。我看一下,這個margin應該是一個人名吧,對不對,就是margin可以當作一個人名用。
link |
那現在還沒有羅game跟梅game這樣子。好,那這邊這個要講的是什麼,它說我們先不要管那個megame的output,我們就先管那個EBGAN的output就好。
link |
EBGAN的output是紅色和綠色的線,然後紅色和綠色的線分別代表M的值射不一樣的時候的狀況,因為剛才我們講說有一個marginM值要首射嘛,你馬上就會問說,那M要射多少。
link |
好,那今天就要來講一下這個問題。那這個橫軸當然就是training的iteration,縱軸呢,上面這個圖是real data的energy,那我們當然希望real data的energy越小越好。
link |
下面呢,是generated data的energy,我們需要這個下面是generated data的energy。那底下這條線呢,是M等於30的時候,就M等於30取log就是底下黑色,黑色比較低的黑色這條線,70取log就是比較高的黑色這條線。
link |
好,那現在如果我們在一般的EBGAN的情況下在做訓練的時候,在原來一般EBGAN的情況下在做訓練的時候,我們會希望這些generated data它的energy要大過margin嘛。
link |
可是就發現說,確實EBGAN有做到這件事,這些generated data它的energy都是在margin的上下游走,如果margin射大一點的話,那這些generated data的energy就會稍微大一點。
link |
那最後呢,會感覺那個encoder有一點比generator強一點,所以後來的energy都超過margin,都比margin還要大。
link |
好,那你看這個real data的energy的部分,你會發現說在前面的幾個training的iteration裡面呢,real data的energy並沒有下降太多。
link |
感覺這個encoder花所有的力氣去讓這個fake的data,反正它花了很多力氣去讓fake的data的energy上升,但是它沒有花太多心力讓real data的energy下降,一直到很後面它才讓real data的energy下降。
link |
而事實上呢,而你會發現說,雖然說我們現在一直在update這個generator,照理說generator產生的image應該要越來越好,但generator的image越來越好這件事情並沒有反映在energy上面。
link |
照理說如果我們今天generator產生的image越來越好,直到最後它已經可以以假亂真了,這個時候那些可以以假亂真的image,它算出來的energy應該是低的。
link |
但是在這個以原來的evegame training的條件之下,這個discriminator會費盡所有的心力給那些next example,給那些generated image,至少大於end energy。所以你最後就會發現說呢,discriminator耗費很大的心力,要分開那些generator其實已經產生的很realistic的image。
link |
那這個margin adaptation gain呢,它的做法是,它想要有一個dynamic的margin,所以它的n呢,是一個浮動的值,它n是一個浮動的值,那詳細的式子呢,你再去看那個paper就好了。
link |
但是它整體而言的精神是這樣,它的n呢,會越來越小,就那個margin會越來越小。這件事其實也是make sense的,因為隨著generator training的次數越來越多,隨著generator參數不斷的update,generator所output的image應該越來越接近真的image。
link |
隨著generator output的image越來越接近真的image,我們應該要給這些真的image比較小的energy,我們應該調小margin,讓generator產生出來的image可以有比較小的energy。
link |
所以如果你今天用這個margin adaptation gain的話呢,你就會發現說,它的結果,不管是real的image還是fake的image,它們的energy都是在下降。
link |
那fake的image它的energy下降,也許就可以反映了說,現在generator產生出來的image是越來越好。
link |
那也許這個margin的概念是重要的。那有另外一個LS gain,它也提到了margin的概念,它也提到了adaptive margin的概念。
link |
我們之前有講過另外一個least square gain,它的縮寫也是LS gain,那這邊有另外一個loss sensitive gain,它也是LS gain。那這個LS gain它其實沒有提到跟energy base的model有關係的事情,但是它裡面也有一個adaptive margin。
link |
那這個LS gain是這樣子的,我們假設d of x是energy function的話,其實在LS gain裡面它沒有引入那個energy的概念,但我們今天就假設d of x是energy function的話。
link |
那我們希望discriminator minimize下面這一個式子,我們希望discriminator可以給real的image比較小的energy,而對於那些fake的image有另外一個特別的處理,寫在第二個式子。
link |
這個到底是什麼意思呢?如果圖示化的話,大家可能比較容易理解。我們要縱軸代表的是energy,或者是代表的是discriminator的output。
link |
那這個real的image,我們要讓它的energy越小越好,那fake的image,我們要讓它的energy增加,但是只要大過一個margin就好。
link |
那這個下面的這個式子告訴我們的是說,這個margin是一個adaptive的margin,對於不同的,對於g of z還有g of z'它們的margin是不一樣。
link |
如果今天這個g of z跟x已經很接近了,我們可以計算一個delta x g of z,這個代表x跟g of z它們有多像。
link |
那至於這個要怎麼量兩個image像不像,那這個就自己想個辦法。你可以說我算兩個image pixel間的相似度,這樣可能比較不reliable。
link |
我們之前已經有看過說,如果要算兩個image相似度的話,你可以拿一個現成的intranet的CNN,然後把它的某個hidden layer拿出來看,它們像不像,也許會得到比較好的performance。
link |
今天如果g of z產生出來的image跟real的image差異很大的話,那它們的margin就比較大,你就會把g of z頂得高一點。
link |
如果今天g of z'跟x它們已經很像了,那它們的差異比較小了,那你就不需要把g of z'頂得很高,因為g of z'已經跟x很接近了。
link |
也許這個圖大家都看得覺得很熟悉。我們之前在講structured SVM的時候,其實也有用到margin這樣子的概念。
link |
原來如果沒有考慮margin的話,我們會希望所有正確的data帶進evaluation function後,大過所有錯誤的data。
link |
但是如果引入margin的話,我們會希望正確的data跟錯誤的data相比,不只是大,而且大過一個margin,而這個margin可以是adaptive的,對每一筆data而言,對每一筆negative錯誤的data而言,這個margin可以是不一樣的。
link |
如果你今天得到的結果已經很接近正確的結果的話,那margin就比較小。如果今天離正確的結果還很遠的話,那margin就比較大。
link |
我們發現說,之前在講structured learning的時候,也有類似的概念。最後我要講的另外一個跟energy-based game有關係的東西,叫做boundary equilibrium game。它縮寫的就是began,就是開始的過去式。
link |
在這個began裡面,它的discriminator也是一個autoencoder,所以它的model的結構跟ebegan是一模一樣的。我們現在有了ebegan,也有vegan。
link |
這篇paper裡面一個讓人印象深刻的是,它generate的人臉非常realistic。這個是它paper裡面generate出來的人臉。我第一個看到的想法是,哇靠,這是我沒有見過最realistic的generate出來的人臉了吧。
link |
不過近一看發現說,它不是從那個slab Agenerate出來,它是有另外一個corpus,它是有一個in-house的corpus。所以我們不知道說,它可以產生這麼realistic的人臉,是因為began真的很強,還是因為它那個in-house的corpus比slab A大很多。
link |
也有可能是data的performance就好了,所以還沒有完全確定。但是這個結果真的很好,這個結果感覺也許可以用在真實的生活中了,比如說用來做真正的人臉的3D建模之類的。
link |
好,那這個began它的式子,它的model架構跟ebegan是一樣的。唯一不一樣的地方是在discriminator的loss有稍微改一下。原來我們說discriminator的loss裡面有一個margin,然後在began裡面它沒有那個margin,它是寫成這樣。
link |
它是寫成d of x減掉kt乘上d of g of z,那這個kt是浮動的。如果這個kt不是浮動的話,我們剛才講過,如果沒有這項kt,直接把d of x減d of g of z會是有問題的。
link |
所以這邊加了一個浮動的kt就是了。那這個浮動的kt是怎麼回事呢?一開始這個kt的值是0,比如說在一開始train這個discriminator的時候,我們只要求discriminator把real的energy壓得越小越好,不要管那些fake的image,因為一開始kt是0。
link |
那什麼時候kt的值會增加呢?你發現說,如果gamma d大於d of g of z的話,就kt的update式子寫在這邊,就是kt怎麼變成kt加1呢?就是把kt加上lambda。
link |
lambda就像learning rate一樣,它是個learning rate,它是正的。lambda乘上gamma d of x減d of g of z。那gamma d of x減d of g of z,什麼時候大於0?就是gamma d of x大於d of g of z的時候。
link |
也就是說,或者說,gamma是一個常數,你要自己設的,就跟margin一樣,這個你要自己手設的參數,設了一個gamma。好,那什麼時候kt會變成正的呢?什麼時候kt會增加呢?當d of g of z除以d of x小於gamma的時候,kt就會增加。
link |
所以什麼時候machine開始要考慮,就原來kt等於0,machine只想要把real data的energy下降。什麼時候machine會想要把fake的data,它的energy拉高呢?什麼時候會想要做這件事呢?當下面這個式子成立的時候。
link |
所以什麼時候下面這個式子會成立呢?什麼時候下面這個式子會小於gamma呢?當分子太小的時候。也就是說,今天這個式子想要做的事情是,當今天generator output的那些image reconstruction error已經太小的時候,甚至小過real的那些image的時候,我們再讓discriminator去把那些fake的image reconstruction error變大。
link |
所以它不會一直考慮fake的data reconstruction error,它只有在fake的data reconstruction error已經太小的時候,discriminator才考慮把那些fake的data的energy變大。
link |
而這個gamma是一個你手可以調的值,所以它調了一下這個gamma的值,會看到不同的結果。最下面是gamma等於0.3,中間的gamma等於0.5,上面是gamma等於0.7。
link |
你會發現說,如果gamma等於0.7,意思就是說,今天只要fake image的error小到一定程度,discriminator就會很緊張地把它的error變大。如果是這樣子的話,得到的結果是這樣子的。
link |
這個結果其實不太好,這個image是有點怪的,右邊這個有點像愛馬華森。如果今天測0.3的話,代表說今天discriminator,這個fake image的energy很小的時候,autoencoder才想辦法把它的error弄大。
link |
這個時候得到的image感覺是比較真實的,但是paper裡面有給一個comment是說,這些image是比較uniform的,比較一致,比較沒有那麼多的變化。
link |
我有點懷疑說,如果今天我們把這個gamma設成0.0的時候,到底會發生什麼事?如果我們把gamma設成0.0,意味著說autoencoder就做他自己的事就好了,他就不考慮negative sample,他就做他自己的事就好了。
link |
autoencoder在training的時候,他會想辦法把real image的energy通通都變成越接近0越好。
link |
如果你今天這個autoencoder設計得夠好的話,你讓generator去minimize這個autoencoder的reconstruction error,那你的generator的output應該就會是database裡面的image。這樣大家了解我的意思嗎?
link |
我猜把這個gamma設得很小的時候,你還是可以產生很realistic的image。而且gamma越小,你產生的image可能越realistic,只是那些image可能都是從database裡面直接sample出來的image,就很像database裡面直接sample出來的image。
link |
我們先是有一個陳柏文同學做了一下,用began做了一下,在select A上面做一下。因為在select A上做的,所以就可以跟其他paper的select A比較一下結果。
link |
下面這個顯然是真正的image,上面是machine generated出來的結果。這些machine generated出來的image,我真的覺得非常的realistic。如果你只從裡面sample一張跟下面的比,你八成會覺得上面的是realistic的image。
link |
但是如果你拿一打image出來看的話,你就會發現began generated出來的image,這邊顯然很單一,背景都不見。
link |
began那篇paper裡面也有提到說,他們都沒有觀察到generator產生任何有戴眼鏡的人。感覺現在如果用began的話,產生的image雖然說很好,但是好像是比較單一的,沒有select A原來的image那麼豐富。
link |
也做了一下interpolation,因為你知道都要做一下interpolation嘛。搞不好現在began就只是從image裡面直接sample一張image出來,所以你要做一下interpolation看看說,他能不能夠產生他沒有看過的image。
link |
所以左邊是began generated的一排image,右邊也是began generated出來的一排image,中間你就做interpolation。做出來的結果看起來像是這個樣子。
link |
這個還蠻驚人的。這個人是看右邊,然後這個人是看左邊。把他們interpolate起來以後,就從本來看左邊慢慢變成直視,然後再變成看右邊。
link |
比如說,本來這個人看起來很嚴肅,然後這個人看起來好像很爽的樣子,然後從左邊到右邊他嘴巴就慢慢張開了。或者這個人本來也很嚴肅,本來也很高興,然後從左邊到右邊他也慢慢張開了。
link |
這個人本來看左邊,然後看右邊,從左邊到右邊,他的臉就轉向了。所以這個結果看起來還蠻驚人的。