back to index
Video Generation by GAN
link |
有沒有用GetLiveGenerateVideo的。然後回想一下,我發現其實是有的。這是那個ICLR2016的paper。你知道ICLR2016那不是去年的事嗎?現在覺得去年的東西就好像很舊很舊很舊的樣子,想不太起來啊。
link |
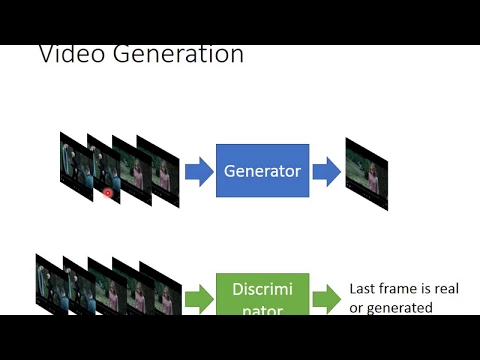
所以是有的。那怎麼做呢?它的概念其實就是conditional game的概念。你就弄一個generator,那這個generator它先吃一段video的前幾個fret,然後它會generate接下來的fret。
link |
那discriminator呢?discriminator就是吃一段video,然後判斷說這一段video裡面的最後一個fret是generated的還是real的。
link |
就是它input這一段video前面的fret都是真的,只有最後一個fret可能是fake的或者是real的。只有最後一個fret可能是fake的或者是real的。
link |
generator就會把它的input跟它的output丟給discriminator,然後希望它可以騙過discriminator,希望generator的input和output合起來可以讓discriminator給一個比較高的分數。
link |
我現在講已經有點confuse了,因為剛才在energy base game裡面d的分數是real的,但是通常在w game裡面高的分數是好的,所以這邊真的是有點confuse,但大家知道我的意思就好了。
link |
那另外一方面還要有另外一個criterion,就是讓generator output的image跟ground truth,因為你有ground truth嘛,因為你收集了很多video,所以你知道說這四個fret後面接的第五個fret是什麼,所以你會希望說generator output跟ground truth越接近越好。
link |
至於什麼叫最接近,你可以用不同的方法來evaluate什麼叫做最接近。那這跟我們講conditional game的時候是一模一樣的,是非常非常像的。
link |
然後為什麼需要用game來產生video呢?這邊有一個例子。為什麼用game來產生video呢?因為你可以想像說今天給同一段video,比如說一個人直直的走過來,接下來他可以往左轉也可以往右轉。
link |
對一般的training來說,如果你只是直接根據training data認一個generator,那對generator來說,往左轉是對的,往右轉也是對的,他最後就會產生一個video是往左轉的影像跟往右轉的影像合起來,結果就會壞掉。
link |
如果你用game的話,就可以避免這種情形。你可以往左轉也可以往右轉都是對的,但你只能選一個,兩個合起來結果就是差的。我把這個video的link放在投影片的第一頁,是一個GitHub的code,你可以直接載下來就可以玩。
link |
這個GitHub的code做的事情是train小精靈,generate小精靈的電丸,接下來會發生什麼事。這個結果是沒有用game的。如果你有simulator的話,你要sample多少video就可以sample多少video。
link |
但是現在呢,他可以往左走也可以往右走,這兩件事情是同時發生的,你就可以產生這種殘影。所以如果你沒有用game的話,你就容易產生殘影。所以你可以了解說,如果你要產生真正realistic的video的話,你是需要game。
link |
以下是GitHub的code所附的一些video。第一個column是光train,第二個column是用game train,第三個column是沒有用game train。仔細看,如果沒有用game train的話,你就很容易出現殘影,比如說這個地方。
link |
他就會很容易走一走就分解了。如果用game的話,就比較不會發生這種情況。雖然有些地方還是會壞掉,但是比如說遠看,有一些小精靈走一走就會憑空不見了,有一些怪走一走就會憑空不見了,不過至少不會出現太多的殘影。
link |
其實大家應該非常非常熟悉吧,每一個game的talk都有這張圖。這個圖就是做super resolution,你就給machine一張比較low resolution的image當作generator的input,generator output就是high resolution的image,你就用game train一下就行了。
link |
這篇paper裡面,如果我沒有記錯的話,他不是conditional game,也就是說discriminator只有看generator output的image,他沒有看fake的image,他只看generator的output而已。
link |
不只可以產生video image,也可以產生語音,也可以做語音合成。這樣相關的研究現在也是很多了。我在今年三月的icast看到兩篇,我相信馬上就會滿坑滿谷。
link |
在這些語音合成的paper裡面,他們其實都不是直接核語音。我覺得直接用game核語音可能還有難度,你直接run一個generator,input文字,output就是語音合成的結果,有點難。
link |
他們的做法其實都是拿一個現成的語音合成器。現成的語音合成model現在遇到最大的問題就是,語音合成出來的聲音都比較平板。你會發現現成的語音合成器,他合成出來的聲音都比較糊、比較平板。
link |
這就跟我們剛才看到的小精靈的例子一樣,你沒有game,你直接train下去,output東西就很容易糊掉,所以在語音上也是一樣。所以他們的做法就是有一個現成的generator,但是多加一個game的discriminator去finetune現成的generator,就可以得到更生動的聲音。