back to index
A3C
link |
那Deep Reinforcement Learning的方法其實非常多,那前面這個概要性的介紹呢,我們就把它跳過。
link |
好,那我們知道Deep Reinforcement Learning的方法呢,其實有兩大類,一個是model-based的方法,一個是model-free的方法。
link |
那如果是model-based的方法的話,代表你的agent對環境有理解,也就是你的agent呢,在採取一個動作以後,他可以預測接下來會發生什麼事。
link |
舉例來說,在AlphaGo裡面,他有用到model-based的方法,因為在AlphaGo裡面呢,他下一步棋以後,他會去預測說,接下來如果一直下下去,勝率是多少,這個東西是model-based的方法。
link |
那不是所有的情況你都可以用model-based的方法,model-based的限制比較多,至少你要用model-based的方法,你要對環境先建立模型,然後環境接下來會發生的事情,你是可以預測的。
link |
那如果是一些比較複雜的環境,舉例來說,你讓Machine去打電玩,比如說讓他玩星海爭霸,那玩星海爭霸就跟這個麥克風很爛,我們就不要用麥克風講,比如說你讓Machine玩星海爭霸,那相較於圍棋,圍棋你下一步以後,接下來會發生什麼事情,雖然變化很多,但他至少是可以窮局的。
link |
但如果是電玩,比如說星海爭霸的話,你把你的一個單位往前一步,對手會有什麼樣的回應,是無法窮局的,所以這個時候如果你用model-based的方法,就會有點麻煩,那這個時候你就會需要用到model-free的方法。
link |
那model-free的方法有兩大類,一個是policy-based的方法,一個是value-based的方法。那在policy-based的方法裡面,我們就是要認一個actor,他負責執行動作。
link |
那在value-based的方法裡面,我們認的是一個critic,這個critic會給予現在的狀況,給予評價,然後你也可以同時使用actor跟critic,這樣就是一個actor-critic的方法,你可以同時使用actor跟critic。
link |
好,那今天我們要講的方法呢,是首先我們會講一個最近很受到重視的方法,叫做A3C。那A3C這個方法呢,它是actor-critic方法的其中一個,它在那個Atari的遊戲上得到很好的成果。
link |
那我們知道說,過去在Atari上啊,這個DQN得到了很好的成果,但其實A3C的結果呢,是標大DQN的,所以發現說現在已經很少有人用DQN玩Atari的遊戲,現在更多看到的是用A3C在玩Atari的遊戲。
link |
而另外呢,我會再講另外一個actor-critic的方法,這個actor-critic的方法呢,其實也是一個大類,這個大類的方法叫做Pathwise Derivative Policy Gradient,那它其實跟這個game非常的像,等一下會講說它是怎麼回事。
link |
那Pathwise呢,又分成兩種,一種是onPathwise的方法,一種是offPathwise的方法。那所謂onPathwise的方法是說,我們現在,你知道在reinforcement learning裡面,agent怎麼學習呢?它是跟環境互動以後去學習。
link |
那onPathwise的方法是說,現在要學習的那個agent跟真正跟環境互動的agent是同一個人,是同一個agent。舉例來說,如果阿光跟佐維下棋,然後阿光有學到怎麼下棋的話,因為下棋的是阿光本人,所以這個是一個onPathwise的方法。
link |
那offPathwise的方法是說,現在有一個agent在跟環境互動,但是那個在跟環境互動的agent跟我們要認的那個agent並不是同一個agent。也就是說,你要認的那個agent是在旁邊觀看,看另外一個agent跟環境互動,那他看另外一個agent跟環境互動的狀況去進行學習。
link |
所以舉例來說,如果實際上是佐維在下棋,阿光在旁邊看。在這個圖上面,拿棋子的人是阿光,但實際上下棋的人是佐維。這個圖應該是來自於塔史形陽跟佐維在網路上下棋的那一回。如果是佐維在下棋,阿光在旁邊看,藉此學習的話,那這個是offPathwise的方法。
link |
在我們用offPathwise的方法的時候,你其實是要小心的,你必須要注意真正在跟環境互動的那個agent跟你現在學習的那個agent本身有多大的差距。如果他們兩個之間有很大的差距的話,你是需要做一些特殊的處理的。
link |
舉例來說,你想要學怎麼打籃球,你就在籃球場旁邊看其他人怎麼打籃球。這是一個offPathwise的方法,你沒有真的下場去玩,你就在籃球場旁邊看看其他人是怎麼玩的。
link |
但是你觀察的對象,比如說是劉川峰,他每一球都是灌籃。因為他很高,他每一球都是灌籃。比如說是我在旁邊看,我這麼矮,我沒有辦法灌籃,所以他的policy我就沒有辦法學起來,他的行為我就沒有辦法學起來。
link |
所以,如果你在用offPathwise的方法的時候,你要注意正在學習的那個agent跟真正跟環境互動的agent,他們之間的差距。接下來,我們要講這個A3C這個方法。
link |
這個A3C是A Synchronous Advantage Actor-Critic的縮寫,有三個A一個C,所以叫做A3C。我們等一下會一個一個解釋說這邊每一個名詞是什麼意思。我們會先解釋什麼是actor,然後解釋什麼是critic,然後解釋什麼是advantage,最後再說什麼是asynchronous。
link |
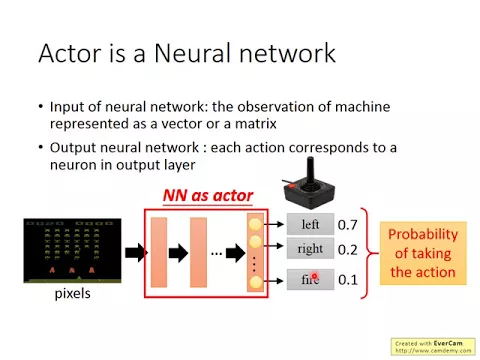
那actor是什麼呢?actor是一個neural network,而且這個部分,我們在上學期的N流其實有比較詳細的介紹過用actor做learning的方法。我們在用actor做learning的方法就是policy gradient。我們之前上學期其實有介紹過policy gradient的方法,那這邊我們就只是很快很快的複習一下。
link |
喂喂喂,喂喂喂,喔,太厲害了,太厲害了,欸,太厲害了,謝謝謝謝謝謝,感謝感謝。
link |
好,那我們說actor是一個neural network,那這個neural network的input是machine現在的observation,我們需要根據這個observation去決定它等一下要做什麼,那這個observation可以是vector,可以是matrix等等。
link |
那output呢,neural network的output就是決定了你有哪些可以被採取的action,所以舉例來說,現在這邊有一個NN所構成的actor,
link |
如果你拿這個actor去玩atari的遊戲的話,那這一個actor的output layer就是你現在,如果你控制那個玩atari遊戲的那個搖桿的話,你可以採取的行為,比如說你可以往左往右或者是fire。
link |
那這個actor的input就是你現在看到的遊戲畫面,那假設這個actor,這個neural network的參數我們已經知道的話,那input一個image,它的output就是每一個action會得到一個分數。
link |
那有了這個每一個action的分數以後,怎麼決定最後要採取哪一個action呢?你可以說,你根據這個每一個action的分數把它當作一個confidential distribution,從這個confidential distribution去做sample,然後actor就決定它要採取哪一個action。
link |
或者是你可以做一個argmax,看看哪一個action它的分數最高,那就採取哪一個action。好,那在這個例子裡面,machine所可以採取的action是discrete,就是要嘛向左,要嘛向右,要嘛開後。
link |
那其實呢,要讓machine採取continuous的action也是沒有問題的。什麼是continuous action呢?舉例來說,如果你現在actor要操控的是一個機器人,那你的actor要決定的是機器人的每一個,假設機器人有十個關節,那十個關節每一個關節要轉動的,比如說角度。
link |
好,那如果在這個case,你的actor的output可能就是一個十維的vector,每一維對應到一個關節,那那個十維的vector每一維的value就代表了現在那個關節轉動的角度,所以要output continuous的action也是沒有問題的。
link |
好,那有了這個actor以後,接下來呢,我們需要有一個方法去衡量一個actor它是不是一個好的actor。那能夠做到這件事以後,接下來我們才能夠歸類discrete的方法去調整actor的參數,調整neural network的參數,找出一個好的actor。
link |
所以首先呢,要能夠衡量一個actor是不是好的,它有多好,那怎麼做呢?那首先一個actor呢,它就是一個function,我們這邊就寫作pi of s,那這個function其實是一個neural network,這個neural network的參數我們用theta上標pi來表示,我們用theta上標pi來表示定義這個function的neural network的參數。
link |
好,那假設我們現在有了一個pi of s,有了一個actor以後,我們就拿這個actor去跟環境互動,比如說讓它打一個遊戲。
link |
那這個actor呢,起始的時候,假設這個actor看到s1,它就會根據s1去採取一個行為,舉例來說是a1,那採取一個行為以後就會得到一個reward r1,然後呢,machine會看到新的observation,會看到新的遊戲畫面s2,然後再採取action a2,然後得到reward r2,以此類推,直到這個遊戲的結束。
link |
那在這個遊戲裡面呢,machine會得到的total reward寫作R,這個R就是在玩遊戲從開始到結束的整個過程中得到的每一個時間點得到的reward加起來,就R1加R2,一直加到RT。
link |
那就算是我們現在有一模一樣的,就算是我們拿同一個actor去玩某一個遊戲,玩很多次,每一次machine得到的total reward也不見得是一樣,為什麼?有兩個理由。
link |
第一個理由是,有時候你的actor可能是sophistic,你的actor的output每次就算看到同一個畫面,它的output也不一定一樣,我們剛才說你可以把output當作是一個distribution,然後根據這個distribution去做sample,你可以把actor的output當作一個distribution,根據這個distribution去做sample。
link |
那這樣actor每次的output呢,就算看到同一個畫面,它的output也會不一樣。那另外一個可能是,就算是你的actor是deterministic,看到同一個畫面它就有一樣的反應,但是你的對手,你的環境,它也有可能是sophistic。
link |
比如說以下圍棋為例,就算你每次下圍棋你的出手都是天元,你的對手也會有不同的回應,你的policy就是,你的actor就是出手就一定要下天元,但是就算你每次都下出手天元,你的對手回應也不一樣,所以每次得到的reward也會不一樣。
link |
好,那我們現在呢,可以定義一個expected total reward,就拿你的agent去跟這個環境互動無數次以後,你就可以計算出現在如果我的agent參數是setup high,那得到的reward,total reward期望值是多少,這邊寫成above。
link |
那這個expected total reward就定義了一個actor有多好或者是多不好,有了這些以後呢,我們就可以做parsing gradient,parsing gradient的這個推導我們已經做過了,所以我們就不要再推導。
link |
假設你不知道這個是什麼的話,你就只要記得以下的這個結果就好了,你就記得這個以下的結果,它其實是過為直覺的。那它是怎麼說呢?它說,我們現在有一個參數叫做setup high,我們可以計算setup high對這個expected total reward的偏微分,我們可以計算出這個偏微分,然後我們拿這個gradient,我們可以計算出這個gradient,
link |
我們可以計算出這個total,我們可以計算出這個參數setup high對expected total reward的gradient,然後拿這個gradient去update setup high,然後得到新的參數,setup high,新的參數setup high,它的expected total reward會比setup high還要大。
link |
那這個gradient這項怎麼算呢?這個gradient這項怎麼算?它的式子就寫在下面這邊。簡單來說呢,如果我們不要看這個式,我們直接看這個下面它的這個直覺的結果的話,上面這個式做的事情,我們在update這個參數的時候,實際上我們去做的事情就是這樣。
link |
如果今天我們先去玩一次遊戲,然後呢,在這次遊戲裡面呢,他看到某一個state,s上標n下標t,那他在這個s上標n下標t的state裡面呢,他採取action,a上標n下標t。
link |
那玩完這次遊戲以後,他發現說,在這次遊戲裡面,他得到的reward是a到s上標n。好,那假設這個reward是真的,那machine呢,就希望去調整它的參數,使得p of a上標n下標t,given a上標n下標t的出現的機率呢,變大,出現的分數呢,變高。
link |
好,所以這個,這其實非常直覺,就是如果今天machine呢,他曾經在某一個state採取某一個action,最後eventually得到的結果是好的,那這一個action被採取的機會就會被提升,machine就調整它的參數,去增加採取這個action的機會。
link |
好,那如果不幸的是,今天machine呢,他在這個state採取這個action,但是最後玩完整場遊戲以後得到的reward是負的,之後machine就會避免在同樣的state採取同樣的action。
link |
那這邊要注意的事情是,我們考慮的並不是machine在state採取actiona以後馬上得到的reward,而是整場遊戲total的reward。
link |
整次互動total reward,整個actiontotal reward,這樣我們才能夠讓machine真的有這個對未來有規劃這樣的概念,他才能夠考慮這個長程的影響。
link |
好,這個是actor,再來critic呢,critic是這樣,critic他其實是不做事的,critic是沒有在做事的,那critic的任務是這樣子,給他一個actor,那他要去衡量說這個actor有多好或多不好。
link |
舉例來說,那critic有很多種,我們現在要介紹的critic是state value的function,這邊是寫成V上標,pi of S。
link |
那這個state value的function呢,他的意思就是說,今天先給定了一個actor pi,這個actor pi是已經被給定。
link |
然後呢,這個critic的作用就是告訴我們說,如果今天我們的actor固定是這個pi,那我們現在處在某一個state S,我們現在看到某一個state S。
link |
接下來,到這個互動結束為止,到遊戲結束為止,我們會得到的reward有多大?
link |
這個東西就是Vpi of S的output,也就是說,現在有一個function叫做Vpi,然後呢,我們告訴他說,那現在我們在某一個state S,我們現在我們的agent看到某一個observation S,那這個state如果在玩遊戲的時候,他可能是某一個畫面。
link |
那一直到這個遊戲結束的時候,我們可能得到的reward的期望值,一直到遊戲結束的時候,所有我們可以得到reward的和的期望值,就是Vpi of S,這個Vpi of S是一個數值。
link |
舉例來說,假設是在玩那個Space Invaders那個遊戲的話,那如果你看到這個畫面,你就會預期說,因為現在還有很多的敵人,所以你有很多的敵人可以殺,你每殺一個敵人就可以得到reward,還有很多的敵人可以殺,所以接下來你得到,你把這個畫面S輸入這個Vpi,那你得到的這個Vpi of S可能是一個大的證值。
link |
那如果在另外一個遊戲畫面,因為現在敵人已經比較少了,所以你可以得到的reward是,你可以殺的敵人是比較少的,所以到遊戲結束前你可以得到的分數是比較少的,那Vpi of S就會比較小。
link |
但是要注意一下這個state value的function,它是跟actor有關的,所以你要定義state value的function,你一定要先給定actor,才能夠定義state value的function。如果沒有告訴你actor是什麼,你是沒有辦法算state value的function。
link |
為什麼?因為給定同一個state,對不同的actor來說,因為不同的actor他的能力不一樣,他會採取的行為不一樣,所以就算是給在同一個state下,那不同的actor他接下來可以得到的期望的reward也是不一樣。
link |
所以這邊要注意,我們的critic其實是跟actor是有關的。這邊就舉一個例子,然後很用心的從奇異幻影裡面再剪了一個畫面出來。
link |
這一頁是發生在弱獅子戰之後,有一天阿光跟佐為在下棋,阿光是一個actor,阿光採取了某一個行為以後,
link |
然後佐為根據阿光現在所採取的行為和盤勢說,這個字有點小,不知道大家看不看得清楚,他說阿光這個時候不要下小馬步飛,然後阿光問為什麼。
link |
然後佐為說,之前下小馬步飛是對的,因為小馬步飛的後續預測比較不容易出錯,那如果下大馬步飛的話,接下來會比較容易出錯,但是因為阿光已經變得比較強了,所以他應該下大馬步飛而不是小馬步飛。
link |
你可問我說大馬步飛小馬步飛是什麼?這邊有一個很小很小的註解,不過我相信你看不到就是了,反正這個不重要。
link |
所以這邊的意思就是說,假設阿光是一個actor,然後佐為是一個critic,那這個V of以前的阿光,括號是下大馬步飛,這個時候得到的餘渥是少,因為以前的阿光比較弱,所以他下大馬步飛會出錯。
link |
但後來阿光比較強,所以如果是變強後的阿光,變強後的阿光是另外一個actor,他跟以前的阿光不是同一個actor,他是另外一個actor,那這個時候下大馬步飛的話就是好的。
link |
所以critic他會給某一個state多少分數,是取決於現在的actor是誰,所以會發現說這個critic的function他都有一個上標,π代表的是actor。那怎麼算,怎麼求找出這個function呢?怎麼找出一個V上標,π of S呢?
link |
這邊有兩個方法,一個是Monte Carlo的方法,那Monte Carlo的方法是這個樣子。你就讓critic去觀察現在我們要考慮的actorπ的行為,你就讓actorπ去跟環境互動。
link |
然後你就統計這個actorπ會得到的reward,比如說actorπ在看到state SA之後,他會得到的reward是GA。
link |
那這邊要注意一下我們算的是accumulated reward,也就是從看到state A以後一直到遊戲結束的時候,所有的reward的總和,你要考慮accumulated reward machine才能考慮長遠的規劃。
link |
然後在這個時候,我們知道說根據π的行為,他在看到SA之後,最後會得到的reward是GA。那Vπ要學到說,如果input SA這個state,那他的output Vπ of SA應該跟GA越靠近越好。
link |
接下來就再繼續觀察π的行為,發現說π有看到一個state SB,他在看到state SB之後,他得到的accumulated reward是GB,那我們把SB丟到Vπ,他的output Vπ of SB應該靠近GB,這是一個方法。
link |
那另外一個方法是temporal approach,所寫的是TD。那temporal approach是這個樣子的,我們現在只觀察到一個很長的互動的其中一小段。
link |
我們只觀察到說,今天某一個actor π在state ST採取某一個行為at,接下來他得到reward rt,然後state變成st-1,我們只觀察到一個很長的互動的其中一小段。
link |
那假設我們已經有Vπ的話,假設我們已經知道Vπ的話,我們可以算出這邊有一個地方我忘了改,我本來想要把,本來我這邊是寫SA跟SB,後來覺得改成T跟T加1比較好,到這邊忘了改,所以這個A應該是ST,這個B應該是T加1。
link |
假設我們已經知道Vπ的話,那這個Vπ of ST跟Vπ of ST加1,他們中間應該差一個rt,對不對,應該要差一個rt。
link |
所以呢,但是我們現在不知道Vπ,但是我們知道說Vπ of ST跟Vπ of ST加1中間,這邊就有改過來,這邊就有改過來,應該要差一個rt。
link |
所以我們就可以用另外一個不同方式來訓練Vπ,我們說這個Vπ他要滿足下面這件事情,我們把ST丟到Vπ裡面得到Vπ of ST,ST加1丟到Vπ裡面得到Vπ of ST加1,接下來把Vπ of ST減掉Vπ of ST加1,這個值應該跟rt越接近越好。
link |
講到這邊,大家有問題嗎?大家可以了解這個意思嗎?這個有點tricky,希望大家可以了解他的意思。
link |
那你的第一個問題可能是,為什麼要這樣做?為什麼我們不等到這個遊戲玩到底以後,這個互動一直玩到底以後,把整次互動的結果,把整場遊戲的結果通通記錄,通通收集起來,我就可以求total的突破?
link |
有些時候你沒有辦法這麼做,等一下會講其他的理由,一個很直覺的理由是有時候你沒有辦法這麼做。
link |
假設你現在有一個,你的actor其實是一個機器人,他在環境中不斷的互動,他永遠不停止,他就在環境中做他自己該做的事情,永遠沒有開始跟結束,就像人的人生一樣。
link |
其實人的人生有開始跟結束,這個例子不好,我要把它剪掉。就是有一個機器人,他沒有開始跟結束,他就不斷在環境中互動,他在環境中,他就採取at,就得到reward rt,就踏到state st-1,從來都沒有開始跟結束。
link |
這個時候你就沒有辦法用前面一張投影片講的multicolor的方法,因為你永遠不知道total的reward應該是多少,所以就只能夠用這個temporal difference的方法來估測它的d這個function。
link |
因為我們雖然不知道說,從st走到底的時候accumulated reward是多少,我們不知道st-1走到底的時候accumulated reward是多少,至少我們知道這兩個accumulated reward中間差了rt,有了這個constraint,我們還是可以想辦法把一拍的學出來。
link |
但是這邊就有一個問題了,這個nc跟td他們有不一樣的特性,如果我們今天考慮nc的這個方法,我們是要讓vpi跟accumulated reward越接近越好,我們要讓vpi跟accumulated reward越接近越好。
link |
這樣子做這件事情有什麼樣的特性呢?這個accumulated reward它的variance是比較大的,我們應該要把下面這個td的狀況也拿出來比較一下。
link |
在td的狀況的時候,我們是說現在input st得到v of st,input st加1得到vpi of st加1,然後我們希望這個vpi跟vpi of st加1中間差一個r。
link |
如果learning target的話,vpi的target是accumulated reward大G,現在vpi的target是小r,那大G跟小r比起來,大G的variance會比較大,小r的variance會比較小。這樣大家可以接受嗎?
link |
假設在每一個time step你得到的reward,它都有加上一個noise,那r是某一個step你得到的reward,所以它就只有加上那一個step的noise。
link |
但是G是很多的step的reward的總和,每一個step都加一個noise的話,那你當然variance是比較大。所以GA的variance比較大,r的variance比較小。如果你說sample的話,GA的variance比較大,r的variance比較小。
link |
好,但是這個GA跟r有另外,這邊這個tb跟mc有另外不一樣的地方是,mc的estimation是unbiased,意思就是說,假設我們sample很多很多的GA,
link |
我們讓mc看過很多次的state SA,然後每次都得到一個GA,把所有的GA平均起來的話,那我們把所有的GA平均起來,它就是我們要找的vpi of SA。
link |
所以今天這個estimation是unbiased,但是今天這個td的estimation,它可能是biased的。為什麼呢?因為看,我們是要讓vpi of ST去逼近r加上vpi of ST加1。
link |
那假設你今天的vpi of ST加1其實是沒有估測準的話,就算你這個rsample很多次,這個vpi如果沒有估測準的話,
link |
那這個vpi of ST加1如果沒有估測準的話,那這個vpi of ST它在近似的對象其實是biased的,其實並不是真的你會得到的expected accumulated reward。
link |
所以這樣大家了解我的意思嗎?所以這兩個方法,一個是variance啦,一個是可能會有biased。那下一頁投影片呢,會再從另外一個角度說明mc跟td的不同。
link |
現在假設你是一個critic,然後你看某一個actor在跟環境互動,現在你扮演一個critic,你要去預測說現在你觀察的actor在某一個state接下來會得到的reward有多少。
link |
那你觀察到的結果是這樣,我們在這頁投影片裡面就省略掉action,我們就只看state就好。現在有一個第一次互動的時候,你觀察那個actor先到state SA,然後得到reward 0,再到state SB,得到reward 0就結束了。
link |
然後接下來幾次呢,他有時候在state SB,得到reward 1,有時候在state SB,得到reward 0,然後就結束了。好,這個時候假設你扮演的是一個critic,那我問你說,SB的value的期望值應該是多少?
link |
Vvalue of SB是多少?這個我相信你可以秒回答我,因為SB我們總共看到了八次,對不對?其中有兩次的reward是0,其中有六次的reward是1,所以Vvalue of SB是0.75,對不對?
link |
因為如果我們看到,如果今天我們的actor走到state SB,他會得到reward的期望值,到遊戲結束為止,今天得到reward的期望值是0.75,我相信這個答案應該是沒有什麼問題。
link |
那問題就是,Vvalue of SA你覺得應該是多少呢?根據這八個episode的觀察,如果我們現在在state SA,如果現在actor在state SA,接下來他得到的reward的期望值應該是多少呢?
link |
給你十秒鐘的時間想一下。你覺得答案是0的同學舉手一下。
link |
好,有很多人覺得答案是0,手放下。你覺得答案不是0的同學舉手一下。大家都覺得答案是0,沒有人覺得答案不是0。為什麼你覺得答案是0呢?
link |
你今天這個Vvalue of SA到底是不是0,depends on你用什麼方法去做estimate。我們先考慮一下,用MC去做estimate的時候,我們會得到多少的expected reward。
link |
你可能想說,SA我這輩子只觀察到一次,那觀察到的那一次得到的reward,得到accumulated reward是0嘛,所以他的expected reward,所以這個Vvalue of SA當然是0。
link |
所以大家都是用MC的方法來做estimate。但是如果用TD的話,其實你會得到一個不一樣的結論。如果用TD的話,你得到的結論其實是四分之三。為什麼?
link |
我們說在做TD的時候,我們是先看到SA,接下來才看到SB嘛,那我們希望Vvalue of SA加上R會等於Vvalue of SB。
link |
那我們又已經知道說Vvalue of SB是四分之三,這件事情大家都同意,沒有人有懷疑嘛,所以他是四分之三。接下來,根據我們的觀察,我們知道說現在SA他得到reward R等於0以後會跳到SB,所以這個R是0。
link |
那這樣SA,這個Vvalue of SA不是應該是四分之三嗎?這樣大家知道我的意思嗎?所以如果用TD來算的話,reward應該是四分之三。
link |
所以用不同的方法,你得到的這個reward可能是不一樣。那到底是0對還是四分之三對呢?那這個就depend on你覺得你的環境其實應該是怎麼樣。
link |
如果你覺得你的環境有Markov的特性的話,那TD估的可能是比較準,如果沒有的話,可能NC估的是比較準的。因為你看,你現在SA在整個process裡面只經歷過一次。
link |
那經歷的那一次告訴你reward是0,但這個估測不見得是準的,因為我們知道說,SB他可以得到reward0,他也可能得到reward1。
link |
事實上SB得到reward1的次數是比較多的,所以平均而言,你走到state SB,你都應該得到0.75的reward。所以雖然這一次的sample得到reward是0,但是其實SB是會有reward的,所以你的reward其實應該是0.75。
link |
你可以從這個角度來看,他應該是0.7。那你會這樣看是因為你假設說,SB是不會受到SA影響的。但是如果你假設SB是會受到SA影響,也就是說,如果我們是從SA跳到SB的話,那SB就會得不到reward。
link |
SB要被放在整個互動的開頭的時候,他才有reward。如果今天實際的環境是這個樣子的話,那reward就應該是0。所以depending on你的假設是這樣。如果SB不會受他是從哪一個state跳進來影響的話,那reward應該是4分之3。
link |
如果SB會受到他是從哪一個state來得到不同reward的話,那reward應該是0。所以說0或4分之3其實都是對的,depending on你覺得這個環境應該是怎麼樣。
link |
好,那現在呢,接下來我們有了actor有了critic,接下來我們就要講actor critic。有了這個critic以後呢,我們可以用critic來幫助actor的estimation。怎麼做呢?這邊有一個process,這是一個循環。
link |
首先你有一個policy pi,然後呢,你用這個policy pi去跟環境做互動,收集到很多data。接下來用TD或MC的方法去學出Vpi of S。
link |
接下來呢,你可以根據Vpi of S去找到一個新的pi,你可以根據Vpi of S,根據你的critic去update你的actor得到新的actor。
link |
那這個步驟我們下一頁會講,先打一個問號。你有新的pi以後,你把pi當作你另一個pi的pi,然後再拿這個pi去跟環境做互動,再得到新的value function,然後再update你的actor,然後就反覆這個循環。
link |
接下來要講的就是這個問號的地方,怎麼做呢?然後呢,這電腦卡住了,我沒辦法跳下一頁。通常遇到這個狀況的時候,錄音設備都會失敗。
link |
糟糕,卡住了,好,就這樣。那我們剛才說這個policy gradient,就是要算一個setup,要算一下你的actor對你的expected total reward的gradient,這個式子寫成這個樣子。
link |
好,在這個式子裡面呢,有一項是out of tolerance,這個out of tolerance的意思就是說,現在我們讓actor跟環境做一次互動,那一次的互動呢,那一次的episode呢,是tolerance,那一次的episode呢,總共得到了多少的reward。
link |
那這個reward啊,我們可以改成用critic來算,我們本來是讓actor真的去跟環境互動,然後actor自己統計一下他得到在這次的互動裡面他得到多少reward,但是我們可以把這件事情改成用critic來算。
link |
那其實怎麼改成用critic來算,你可以有各種不同的做法,比如說如果你去看那個A3C那篇paper的話,他其實是嘗試了好幾種不同的做法的,那只是呢,其中某一種呢,就是A3C,A3C那個方法只是那篇paper裡面嘗試了眾多方法的其中一個,只是A3C那個方法performance最好。
link |
現在所以大家都比較知道A3C,那在A3C那個方法裡面,這個R他是怎麼定的呢?這個R他是怎麼定的呢?我們原來的R呢,是考慮了這個整個互動的,我們的R呢,原來是考慮了整個互動的情形。
link |
那現在如果你用這個advantage的acquitted的話呢,你的這個advantage的function呢,他的定義是這樣。
link |
首先呢,他第一個考慮的是R上標N下標T,意思就是說,現在呢,如果我們採取了,我們在這個state採取了這個action,我們會得到多少的reward?
link |
馬上會得到的reward是R上標N下標T。然後他還有後面這一項,後面這一項呢,是根據,後面這一項呢,是根據critic呢,estimate出來的。
link |
後面這一項是說,他去計算,根據critic呢,去計算說,現在如果我們採取的policy是pi,那S上標N下標T這個state的cumulative value,跟S上標N下標T加1的這個value,他們的差距呢,有多少?
link |
所以這個是我們實際上會看到的reward,實際上跟環境互動以後,actor得到的reward。
link |
這個後面,這個減到後面這一項啊,是根據critic會,根據criticestimate出來的reward。
link |
好,那所以現在呢,這個advantage action critic告訴我們的就是說,如果現在你的advantage function得到的值呢,是正的,那我們就應該要增加呢,採取這個action的機率。
link |
如果我們得到的advantage function的值呢,是負的,那我們就應該要減少呢,採取這個action的機率。
link |
那這邊呢,有一些advantage actor critic用的tip,那有一個tip是說,我們的critic跟actor啊,它的參數是可以share的。這個critic是一個neural network,actor也是一個neural network,那這樣的neural network有一些參數應該是可以共用的。
link |
因為我們input呢,都是一個image,都是一個遊戲的畫面,那要處理遊戲畫面,你前面幾個layer你可能用的是CNN,那你要對這個遊戲的畫面進行理解,那個CNN或許在actor和critic裡面用的CNN可以是同一組丟的。
link |
所以實際上呢,actor跟critic的關係可以是像下面這個樣子,state s進來以後,先通過綠色的這個network,它是actor和critic共用的,接下來再丟給藍色這個network,那它的output得到的是actor的值,再丟給紅色的network,它的output得到的是critic的值。
link |
好,另外一個在這個advantage、adequate這篇paper裡面有用到的技巧是,它希望它的actor output的entropy是大,它把actor的output用一個entropy來做regularization。
link |
它希望說呢,actor的output的distribution,它的entropy可以盡量大,也就是說actor output的distribution,它可以盡量不是集中的而是平滑的。
link |
這樣的好處是,你的actor在跟環境互動的時候,它可以增加探索的機會。如果今天你的actor是一個deterministic的actor,每次看到同一個state,它都會採取同一個action,除非你的環境有非常大的noise,有非常大的隨機性,
link |
不然呢,你的actor可能就只能夠經歷某幾個state而已。但是如果你今天增加了output的entropy,讓你的actor在採取action的時候,它的隨機性比較大的話,
link |
那它就可以在跟環境互動的過程中,經歷過比較多不同的state,那這樣可以給這個quotient更多的資料,讓quotient可以做更準確的預測。
link |
那最後,這邊只有兩個A,所以它是A2C。那最後A3C的最後一個A是什麼呢?這個A呢,是asynchronous。這個asynchronous的意思是說,我們現在呢,有一個共同的參數,有一個共同的參數呢,叫做θ1。
link |
那我們同時有好多個actor,這邊在這個圖上寫成walker,有好多個actor呢,在跟環境的互動。
link |
這邊每一個walker呢,其實包含了一個actor跟一個quotient,每一個walker呢,其實都包含了一個actor跟一個quotient。那這邊有很多的walker,那每一個walker呢,都去跟global的參數呢,去把它的參數複製過來,把它的參數複製過來,然後去跟環境做一下互動。
link |
那跟環境互動一下以後呢,它就可以計算出,如果我們要updateactor跟quotient的話,那這個actor跟quotient的參數要如何update。
link |
然後它就把這個資訊呢,送回去給global的network,那global的network的參數呢,就變了,global的network的參數呢,就變了。
link |
那其他的walker呢,也同時從global的network呢,要了一個參數過去,然後跟環境做互動,然後去估測說,他們要怎麼update呢,這個global的參數。
link |
所以實際上呢,當這個walker1它要updateglobal的network的參數的時候,它的參數已經不是senr1了,而其實呢,是senr2。那這樣子聽起來好像有點怪怪,但是實作上呢,沒有問題就是了。
link |
那這樣的做法就是,你可以加快訓練的速度,就同時有好多個這個actor跟quotient的pair,同時有好多的walker呢,在跟環境做互動,然後最後他們可以把他們全部的經驗呢,累積在一起。
link |
那其實有一個同學寄信給我,然後他說,當他看到actor query的時候,就讓他想到那個火影忍者。
link |
火影忍者大家知道嗎?就冥人不是有一次在練那個,讓樹葉裂掉的那個法術嗎?那個,好,其實我想起來了。就是,我記得是從那一集開始,那個不知道為什麼忍術有了屬性。
link |
然後冥人要練一個風屬性的忍術,那做的事情就是手上拿一個葉子,然後把葉子切成兩半。那他就用自己的影分身呢,複製了很多個影分身,然後每一個都在切葉子。然後最後把所有影分身都收回來的時候,就可以累積了很多的經驗。
link |
本來一個禮拜才練成的技巧,就可以一天就練成。那這個Asynchronous的概念,其實就是一模一樣的。好,那接下來我們要講的是這個Pathwise的Derivative的Policy規定。
link |
那這個Pathwise的Derivative的Policy規定,跟剛才講的那個Active規定有什麼不一樣呢?我們一樣要用這個,用這個棋魂的來做一下例子。那這個阿光是一個Active,他下了一紙,他下了一個,他落下一個紙以後,佐維說呢,他說,這邊應該不要下小馬不飛。
link |
這個是一般的Active規定在做的事。一般的Active規定他在做的事只有告訴你說,你現在採取的行動是好的還是不好,但他不會給你建議。他只告訴你說,好還是不好,他不會給你建議。
link |
但是佐維接下來他給了一個建議,他說,這邊應該要下大馬不飛。而給你建議這件事,就是Pathwise的Derivative Policy規定會做的事情。
link |
所以在我們現在要講的方法裡面呢,Machine不只這個規定呢,不只是告訴你說你做的好還是不好,他不只會告訴你說你做的好還是不好,他還會給你建議。
link |
那這邊呢,我們要先介紹另外一種規定。我們剛才介紹了這個V這個Function,我們現在要介紹另外一個Q這個Function。那這個Q這個Function呢,他的Input是一個State跟Action的Pair。
link |
那一樣呢,Depend on 一個Actor Pi。Q這個Function的意思是說呢,現在給我們一個Actor Pi。那如果現在給我們一個Actor Pi,然後接下來呢,你的Agent在某一個State S採取某一個Action A,接下來都Follow這個Actor Pi的這個Policy,那最後會得到的Accumulated Reward是多少?
link |
所以跟剛才B不一樣,剛才B只考慮說,現在如果我們走到某一個State的時候,接下來會得到多少Reward。而Q Function呢,他不只考慮哪一個State,他還要考慮Action。
link |
所以他說,我們在某一個State採取某一個Action的時候,接下來會得到多少Reward。而就算是同一個State,你採取不同的Action,接下來得到的Reward當然會是不一樣。
link |
所以Q Function像是這樣,現在有一個Function Q Pi,然後呢,給他一個State,給他一個Action,他的Output就是一個Scalar,告訴你說,在這個State採取這個Action,接下來得到的Accumulated Reward有多大。
link |
那這個Q Pi啊,如果你的Action是Discrete的話,有另外一個寫法,會寫成說呢,我們現在Q Pi的Input仍然只有S,但他的Output呢,不是一個Scalar,他的Output是一個Vector,Vector的每一個Dimension就對應到一個Action。
link |
這個只有在你的Action的數目是可以窮取的,所以才能這麼做。那這邊呢,每一個Dimension就對應到一個Action,比如說第一個Dimension對應到,假設你是玩Atari遊戲,代表向左,第二個對應到向右,第三個對應到開火。
link |
那每一個,這個Output一個Vector,這個Vector的每一個Dimension的值,就代表了這個Input某一個State和某一個Action的時候,你會得到的Accumulated Reward。
link |
好,那現在有了這個Q以後,我們可以怎麼用它呢?我們可以怎麼用它呢?
link |
在原來的Actor Query裡面,你的使用方式是這樣,我們現在呢,有一個Q這個Function,我們假設他的這個這個Q of SA的分布是這個樣子的,我們假設現在S被固定住,然後呢,A呢,我們可以採取不同的A,然後所以我們可以計算出不同的Q of SA的值。
link |
假設我們現在選擇的Action是A1的話,我們得到的值呢,是Qπ of SA1,它是一個比較差的Action。
link |
那如果我們選擇的這個A2的話呢,我們得到的值呢,是Qπ of SA2,它是一個比較好的Action。
link |
那接下來呢,Actor會做的事情就是,我們知道說,剛採取A1的時候得到的Reward比較少,所以我們就要降低A1採取的機會,那A2得到Reward比較多,所以我們就要增加A2採取的機會,這是原來的Actor規則告訴我們的。
link |
那這整個做法會有一個問題就是,對Machine來說,沒有Sample過的Action就永遠沒有辦法給予評價,沒有Sample過的Action,Actor就不知道說他應該要增加他的機率還是減少他的機率。
link |
就算是Mega Action是好的Action,Machine也不知道,舉例來說,假設採取了這個紅色的這條虛線所代表的Action,你會得到很高的Reward,但是Machine不知道這件事,那Actor不知道這件事,
link |
他要倒說,因為Actor本身有隨機性,他要一直倒說這個隨機這件事情,帶領你的Actor正巧採取了這個Action,他才會知道說,原來採取這個Action,我會得到很高的Reward,所以我要趕快增加這個Action的機率。
link |
但如果不幸的是你一直沒有恰好採取到這個Action,那你的Actor永遠不知道他是一個好的Action,這個在你的Action的Space很大的時候是會造成影響的,尤其是假設你的Action是Continuous的,
link |
如果是Continuous的Action,等一下Space是無窮大,那你很難把每一個Action通通都試過,那有很多好的Action也許你沒有試過,就白白的被放棄了。
link |
那所以呢,今天有另外一個方法,另外一個方法是這樣,這個Q這個Function,我們其實是知道,因為Q這個Function是我們Estimate出來的,它也是一個Neural Network,這個Neural Network的參數,我們是知道。
link |
既然我們知道這個Q這個Function的參數,那我們當然知道它的最高點在哪裡,我們當然知道它長什麼樣,前提是我們假設這個Q這個Function的Estimate是很準的,我們假設Q這個Function的Estimate是很準的。
link |
好,那接下來呢,那接下來呢,假設我們現在Sample了某一個Action A,我們知道說這個Action A只能夠給我們這樣子的Reward,但是我們又知道這個Q這個Function長什麼樣子,
link |
那我們其實知道說,如果我們把Action A往左移,等到另外一個Action A',其實我們會得到比較大的Reward,這樣子Machine就不需要等到說,它真的Sample到A'這個Action的時候,才知道它大的Reward。
link |
從Q拍這個Function的樣子,Actor其實就可以知道說,如果採取A',我們會得到比A更好的Reward。那這個方法呢,叫做Q Learning,從這個Q Function裡面,我們可以知道說A'其實是比A還要好。
link |
那整個Q Learning的Process呢,是這個樣子,跟剛才Actor Creating呢,其實很像,一樣是有三個Step。首先呢,你有一個Policy Pi,這個Policy Pi用環境互動收集到很多的Data,讓你可以去Estimate QPi.sa。
link |
這邊呢,我們要Estimate的是Q而不是V,因為在Q Learning這個Process裡面,我們可以藉由Q呢,產生一個Policy,但是如果是藉由V的話,我們其實沒有辦法產生一個Policy。
link |
等一下我們看說,怎麼藉由Q呢,來產生一個Policy,怎麼藉由Q,我講Policy的時候,我指的其實就是Actor,Actor有時候我們會叫它Policy。好,那這邊呢,我們要怎麼從Q呢,產生一個Actor呢?
link |
這邊有一個方法,我們可以找到一個新的ActorPiPi,就根據,假設我們已經有一個Function QPi,那我們就可以找到一個新的ActorPiPi,這個新的ActorPiPi,它是比Pi還要好的。
link |
這邊特別畫了一個雙引號,把好這個字呢,放在雙引號裡面,這個好到底是什麼意思呢?這個好呢,是有定義的,這個好的意思是這樣,一個ActorPiPi比一個ActorPi還要好的意思是說,
link |
對所有的State來說,對所有的State來說,VPiPi of S都大於等於VPi of S。
link |
VPi of S是什麼?VPi of S是說,假設我們的Actor是Pi,在State S,我們預期接下來會得到的餘額是多少?
link |
VPiPi of S是什麼意思?VPiPi of S是說,假設我們現在的Actor是PiPi,在State S,我們預期接下來會得到的餘額有多少?
link |
而既然VPiPi of S大於等於VPi of S對所有的State都是這個樣子,那意味著說,不管我們現在在哪一個State,我們用的Actor如果是PiPi的話,
link |
我們得到的期望的,接下來期望會得到的如果都比Pi還要大,那這樣PiPi就是一個比Pi還要好的Actor。
link |
那怎麼得到這個PiPi呢?現在呢,如果我們有了這個Q function,QPi of S,PiPi可以秒得到。
link |
如果我們有QPi of S,那PiPi就是下面這個式子,PiPi就是PiPi這個Actor,PiPi這個Actor就是,
link |
把那個Q function拿出來,然後看說哪一個Action A,State是已經給定了,State是這個Actor的input,State是已經給定了。
link |
給定一個State,給這個QPi的輸入一個State,它的output的Actor應該是什麼呢?就是把Q function拿來,看說哪一個Actor可以讓Q function的值最大。
link |
那它就是這個QPi,它就是這個PiPi的output。
link |
好,那這邊要注意的事情是,第一個,這個PiPi它其實沒有參數,它沒有額外的參數,對不對?因為我們只需要Q這個function就可以決定PiPi。
link |
Q可能是一個neural network,它本身有參數,但是我們除了這個Q的參數以外,這個PiPi不需要再額外的參數來決定它要採取哪一個Action。
link |
它光看Q就可以知道要採取哪一個Action。
link |
第二個問題我們等一下會解決的是說,這個方法它不適用於如果你的Action是continuous的時候。
link |
你想想看,你要解這個argmax的problem,就算已經把Q給你,但是A如果是continuous的話,意味著你可能要用gradient ascent去求說哪一個A它可以讓Q最大。
link |
那每一次你要決定要採取哪一個Action的時候,你都要做一次gradient ascent,花很長的時間才可以求出A,這感覺是不能接受的。
link |
如果你的A是discrete的話比較沒有問題,因為你可以求取各種不同的A,看哪一個A可以讓Q的值最大。
link |
比如說在Atari的遊戲,你可以採取的Action只有上下左右加開,或只有五個Action,你就把五個Action丟到Q function裡面去,看哪一個Action可以給我們的值最大。
link |
那它可以給我們Q的值最大,那它就是我們要採取的那個Action,它就是PiPi會採取的那個Action。
link |
好,那接下來就是要證明說這件事情是對的。講到這邊大家有問題嗎?
link |
如果我們找了這樣的一個Actor的話,它會滿足上面這個式子。那怎麼證明呢?首先我們先把VPiS拿出來,這個S可以是任何的state,那我們就是要證明說VPiS會小於等於VPiS,那PiPi就是長這個樣子。
link |
我們先看VPiS是什麼?我們先看VPiS跟Q的關係。VPiS等於QPiSPiS,這個大家可以接受嗎?
link |
因為我們在S這個state,因為這個VPiS的意思是說在S這個state,我們用Actor去跟環境,用ActorPi去跟環境做互動,那最後期望得到的reward是VPiS。
link |
那QPiSA的意思是說,我們在S採取這個action,我們會得到的reward。而今天如果我們的Actor是Pi的話,那我們採取的action就是PiS。所以今天VPiS跟QPiSPiS,它們的值會是一樣。
link |
好,那接下來呢,這一項一定會小於等於這一項,對不對?因為這一項是拿PiS放在A的位置。
link |
那現在如果我們窮取所有可能的A,窮取所有可能的A,Q function不變,那窮取所有可能的A,帶到QPiSA裡面去,那顯然這一項會是這一項的upper bound。
link |
好,那接下來呢,接下來呢,我們知道說什麼樣的Actor會採取這個actionA呢?什麼樣的Actor會採取一個actionA,讓QPiSA的值最大呢?
link |
那這個Actor其實就是PiPi,對不對?這個Actor其實就是PiPi,所以這一項又等於QPiSPiPiS。我想這件事情呢,應該是沒有什麼問題的。
link |
我們這邊呢,得到了一個式子,是VPiS小於等於QPiSPiPiS。這個式子其實也頗直覺的,它意思是說,假設我們現在在S這個state,
link |
假設我們現在在S這個state,用PiPi這個action來跟環境做互動一次,就我們現在只有在S這個state,用PiPi這個action來跟環境做互動,然後接下來都用Pi來跟環境做互動得到的reward,比我們從來沒有引入PiPi可以得到的reward還要大。
link |
好,那接下來有了這個式子以後,我們就可以把這個式子展開。我們來看一下QPiSPiPiS等於什麼呢?
link |
QPiSPiPiS是不是等於RT加1,假設現在這個S就是ST,那Q這一下就等於RT加1加上VPiST加1。
link |
好,那這個我們又知道說這個VPi的ST加1,它有一個upper bound,如果我們把這一下S換成ST加1,那它的upper bound就把這一下S換成ST加1,這一下S也換成T加1。
link |
所以VPi這一下有一個upper bound是這個樣子,有一個upper bound是這個樣子。好,那接下來你再把QPi這一下再換掉,把QPi這一下換成RT加2加上VPi的ST加2。
link |
然後VPi的ST加2,它一樣有一個upper bound是QPi的ST加2,PiPi的ST加2。那就把這件事不斷的做下去,不斷的做下去,不斷的做下去。
link |
最後你就會得到說這個VPi的S,它是小於等於VPiPi的S。如果你沒有辦法聽懂這個部分的話,其實你就記得說,現在假如給我一個Q function,假如給我們一個policy,假設給我們一個actor Pi,這個actor Pi我們可以計算出它的Q function,
link |
那我們就可以找到另外一個actor PiPi,它比原來的Pi還要更好,所謂的更好就是滿足這個需求。
link |
好,那所以現在假如有了Q,我們就可以找到一個更好的actor PiPi,那怎麼找這個Q呢?那你可以用MC的方法,你也可以用TD的方法。
link |
如果你用TD的方法看起來就像這樣,我們現在在某一個互動的過程中,我們看到了ST採取,在ST的時候actor Pi採取action AT得到reward RT,跳到state ST加1。
link |
那我們可以計算出QPi的STAT,因為這個Q這個function要吃S跟A嘛,所以我們可以計算出QPi的STAT。
link |
但是我們現在呢,如果只有給我們ST加1的話,我們不知道machine會採取哪一個action,但是我們可以預期machine會採取的action其實就是Pi到ST加1。
link |
對不對?就假設我們現在有一個action Pi,那machine在state ST加1的時候,它會採取的action就是Pi到ST加1。
link |
所以我們現在有兩項,一個是QPi的STAT,另外一項是QPi的ST加1,Pi的ST加1。
link |
那這兩項中間呢,會有一個差距呢,RT,因為我們在ST採取AT以後,得到reward RT,才跳到ST加1。
link |
所以這兩個Q中間呢,它們會有一個差距,這個差距呢,就是RT。
link |
那所以現在如果我們要求這個Q的話,我們就是對這個Q呢,用gradient descent的方法呢,去求這個Q的值。
link |
然後希望呢,今天如果把STAT帶進QPi得到的output,跟把ST加1還有Pi到ST加1,放到這個QPi裡面得到的output,它們中間有一個差距是R。
link |
那你可以用這個式子呢,把QPi找出來。但是在實作上呢,這邊有一個tip,就是如果我們同時認這兩個Q,
link |
這兩個Q其實是同一個function,所以它們參數是派在一起的,這兩個Q是同一個function,所以它們參數是一模一樣。
link |
那現在呢,如果我們同時認這兩個Q的話呢,會讓結果呢,變得比較不穩定。
link |
你可以想像說這個,你要同時認這兩個Q呢,它是比較困難的,它可以讓它的結果呢,可能會比較unstable。
link |
所以怎麼辦呢?在實作上啊,會把其中的Q呢,會把其中的Q呢,把它fix住。
link |
會把其中的Qfix住,把它當作是target,把它當作是target。
link |
把這個Q的outputfix住,然後只調這個Q的值,讓它的output呢,去fit這個已經被定住的Q呢,它的output。
link |
然後呢,update幾次以後,把這個Q認好以後呢,再把這個Q的參數呢,copy給另外一個Q。
link |
那如果說沒有做這件事情呢,做這個Q learning呢,當你用的這個Q function是一個neural network的時候,你其實很難把它認好。
link |
但是有加這個freeze這一項呢,你就比較容易呢,把這個Q learning做起來。
link |
再來要講的另外一個問題是,其實在做這個Q learning的時候啊,其實在做這個Q learning的時候,你很容易高估了Q的值。
link |
對不對?為什麼呢?為什麼很容易高估這個Q的值呢?
link |
你想想看,這個是你的target,你的target呢,是RT,加上重舉所有不同的action A,然後看哪一個action A,可以讓這個Q的值最大。
link |
那你把這兩項加起來,當作是Q的target。
link |
如果你是這樣estimate的話呢,會傾向於高估了Q的值。為什麼呢?我們假設說,現在呢,Q of SA長這個樣子。
link |
我們假設現在Q of SA長這個樣子。
link |
那我們現在呢,要挑出一個,這邊假設有四個action,那這四個action呢,會給我們四個不同的Q of SA的值。
link |
那我們挑出一個action呢,它可以讓Q of SA最大,然後把它的值呢,放在這裡。
link |
那因為現在這個Q of SA呢,它是估測出來的。
link |
因為它是估測出來的,所以它可能會有一些誤差。
link |
那麼假設說,這個誤差有時候大,有時候小。
link |
這個誤差並不是都會偏向大的,或者都是偏向小的,這個誤差並不是都是正的,或都是負的,而是有時候正,有時候負。
link |
那所以呢,今天,比如說這兩個action,它的Q值被高估了。
link |
這兩個action,它的Q值被低估了。
link |
那這個時候,你選一個這個Q值最大的action,你會選到這一個action。
link |
那如果今天在另外一個case,第一個和第三個action的值被低估了,第二個和第四個action的值被高估了。
link |
那你會選第四個action的Q值放在這邊。
link |
所以你會發現說,當你今天你的Q值的估測有一些誤差的時候,你其實比較容易選到高估的Q值當作你的target。
link |
因為你的target是高估的,所以你最後認出來的Q值呢,也會是高估的。
link |
這個巧妙的做法呢,叫做double的dqn。
link |
那在double的dqn裡面,我們需要兩個Q function。
link |
這邊一個是Q,另外一個呢,我們就寫作Q'。
link |
那這個Q跟Q'呢,他們其中一個人決定要採取哪一個action。
link |
另外一個人去計算Q的值,去計算這個Q value。
link |
在原來的Q value裡面,我們用同一個Q決定要選哪一個A。
link |
我們用同一個Q來決定說,把A選好以後,它的值有多少。
link |
但是今天在double Q裡面,我們用Q這個function來決定我們要選哪一個A。
link |
選定了A以後,我們用Q'來決定它的Q value。
link |
這個就是它可以防止overestimate的地方。
link |
為什麼這樣可以防止overestimate呢?
link |
它選出來的那個action,它的Q的值是overestimate。
link |
但沒有關係,只要Q'對Q選出來的那個A沒有overestimate的話。
link |
那你想說,那如果Q'對某一個Aoverestimate的話會怎樣呢?
link |
如果外面這個Q'對某一個Aoverestimate的話會怎樣呢?
link |
那沒有關係,因為雖然Q'overestimate,只要Q不要選那個action。
link |
只要Q對那個action沒有overestimate,Q沒有選到那個action就沒事了。
link |
所以這個還蠻有趣的,所以Q跟Q'它們是互相制衡的。
link |
譬如說行政院可以提預算案,但是不能夠審查。
link |
而立法院只能審預算案,它不能提預算案。
link |
所以Q可以提要用哪一個action,但它不能決定它的value。
link |
Q'它可以決定現在某一個action的value,但它不能夠決定要用哪一個action。
link |
那除非Q跟Q'同時對同一個action高估它的值,
link |
不然如果我們有同時有Q跟Q'的話,那這個Q的值就不會被高估了。
link |
還有另外一個會用在這個Q-learning的技巧叫做dueling Qn。
link |
這個dueling就是那個決鬥的意思。
link |
而這個dueling的DQn是什麼意思呢?
link |
原來的Q-network它長得像上面這個樣子,就input一個state,
link |
那output就是你的action,
link |
你的output dimension就等於你的action。
link |
然後就可以從output每一個dimension決定Q'的值。
link |
那如果是dueling的DQn呢,它唯一的改變是,
link |
它只有改了你的network的架構,所以training的地方都是一樣的。
link |
所以原來你用在Q-learning的技巧,
link |
在這邊都可以使用,比如說剛才的dueling DQn,
link |
或者是freezing target等等,都可以用在這邊。
link |
唯一不同的是它改了network的架構。
link |
它把network的架構改成什麼樣子呢?
link |
它說現在在得到output的Q-value之前,
link |
其中一條路只會output一個value,
link |
我這邊其實這個QRV上面都應該要上標Pi,
link |
它說我們的target是QofSA,
link |
就是network最後的output仍然是一個vector,
link |
這個vector的dimension跟我們可以採取的action的數目是一樣的。
link |
我們仍然把這個network的output當作是QofSA來看,
link |
但是我們對這個network中間的layer做了一些手腳,
link |
一條路就是output一個scale,
link |
接下來,另外一條路會output一個vector,
link |
這個vector的dimension跟action的數目是一樣的。
link |
你把這個structure定好以後,
link |
它說你得到的這個scale就會是V的值。
link |
那V的值加上這邊的output會得到Q的值,
link |
那個network難道不會說我就設VofS等於0,
link |
然後這個vector的output就直接等於這個vector的output嗎?
link |
所以它其實在training的時候,
link |
它其實對這個network還有偷偷做了一些手腳,
link |
那其他就跟原來的Q-learning沒有什麼不一樣,
link |
只是換了network的structure。
link |
好,那這邊的這個A這個function代表什麼意思呢?
link |
這個Afunction代表的意思是說,
link |
如果我現在在stateS採取actionA,
link |
它比其他的,比原來的policy還要好多少?
link |
所以這個A又叫做advantage的function。
link |
那這次這個Q-learning的DQN,
link |
它最後得到的performance是比一般的DQN好的,
link |
但是它最有趣的結果是它的visualization。
link |
如果現在玩的是那個Atari的遊戲,
link |
我們要怎麼改變input的image,
link |
我們要怎麼改變這個input的image,
link |
什麼樣的事情是跟action沒有關係的,
link |
什麼樣的事情是跟action有關係的。
link |
這個紅色的閃光不是原來遊戲裡面的東西。
link |
當現在的遊戲的畫面裡面的哪幾個pixel改變的時候,
link |
對value的function影響最大。
link |
對value的function影響最大。
link |
對advantage的function影響最大。
link |
那advantage的function是跟action有關的。
link |
它都沒有紅色了。我把它退到前面一點。
link |
你看右邊這個圖,什麼時候紅色才會出現?
link |
當有車子很靠近你的時候,紅色才會出現,對不對?
link |
當我車子很靠近的時候,這個紅色才會出現。
link |
你採取不足的action才會對你的結果有影響。
link |
所以當車子很靠近的時候,才會有紅色出現。
link |
那如果你看左邊,左邊考慮的是value。
link |
在這個遊戲裡面,每通過一輛車子你就會得到一分。
link |
你的value跟有沒有車子出現有關。
link |
所以你會發現說,如果你看value function的話,
link |
對value function比較有影響的,
link |
你會發現說,在地平線每次有車子過來的時候,
link |
這個是賽車的遊戲,這個是打磚塊的遊戲,
link |
你會發現說,如果看右邊的advantage function的話,
link |
這個advantage function才會受到影響。
link |
你採取不同的action才會影響你的value。
link |
而不是只有在球非常靠近板子的時候才有值。
link |
那我們剛才講說,我們要怎麼找pipeline呢?
link |
我們要找pipeline就是,只要給我們Q,
link |
只要給我們Q,我們就可以找出pipeline。
link |
這個時候呢,我們根本就不需要任何的actor,
link |
我們只需要有Q,就可以決定我們要採取哪一個action。
link |
但是現在,假如我們有一個actor,
link |
而這個actor的output就是我們要採取的action A的話,
link |
理論上我們要做的事情是,我們現在有一個actor pi,
link |
然後這個actor pi的input是state s,
link |
然後它的output就是action A。
link |
那我們要update這個state pi,
link |
把它的參數從pi變成pipeline,
link |
然後我們希望這個Q pi的值越大越好。
link |
有人發現說,今天這個actor的input是state,
link |
今天這個Q的input是state跟action,
link |
所以實際上,我們可以把這個actor跟這個Q的function把它接在一起,
link |
我們可以把這個actor的output就當作是Q function的input,
link |
就把它視為是一個比較大的network。
link |
那我們要update這個actor的參數的時候,
link |
實際上我們做的事情就是把Q function的值fix住,
link |
然後用gradient ascent去update這個actor的值。
link |
那我們actor也是一個neural network嘛,
link |
用gradient ascent去調actor的參數,
link |
讓這整個network的outputQ的值上升。
link |
好,如果你要把式子寫出來的話,就像是這個樣子。
link |
然後我們要計算theta pi對Q function的gradient,
link |
把theta pi加上Q function的gradient,
link |
你會發現說這個式子看起來好像很眼熟,對不對?
link |
它是不是就是很像GAMES的式子呢?
link |
在GAMES裡面,如果我們把actor想成是generator,
link |
把Q function想成是discriminator,
link |
在GAMES裡面我們會把generator跟discriminator接在一起,
link |
然後discriminator的參數是fix,
link |
去讓discriminator的值越大越好。
link |
我們可以把actor跟Q就接在一起,
link |
就叫做Pathwise Derivative Policy Gradient,
link |
那它其實是一系列的方法有種種的變形。
link |
跟Q-learning一樣呢,就一樣有三個步驟,
link |
我們在estimate Q function的時候呢,
link |
是當我們在estimate這個pipeline的時候,
link |
我們只有Q就可以直接得到pipeline。
link |
但現在呢,我們的pipeline呢,
link |
其實是一個neural network,
link |
我們的action呢,其實是需要有一個actor呢,
link |
所以我們做的事情,其實就是調這個actor的值,
link |
可以去maximize Q這個function的output。
link |
因為我們實際上在testing的時候,
link |
實際上這個actor pi在跟環境互動的時候,
link |
它並不需要接一個argmax的file。
link |
它在training的時候需要解一個argmax的file,
link |
它的output就是actionA,
link |
我們並不需要去解argmax的file。
link |
這邊還有另外一個需要用到的tip呢,
link |
你也需要用到replay buffer。
link |
這個replay buffer的意思就是說,
link |
你的actor pi跟環境互動的information,
link |
你的actor pi跟環境互動的information,
link |
然後今天你在認你的Q function的時候,
link |
然後今天你在認你的Q function的時候,
link |
它是從這個buffer裡面取值出來,
link |
跟環境互動以後得到的experience,
link |
都會存到replay buffer裡面。
link |
不只考慮了pi的experience,
link |
也考慮了其他actor的experience,
link |
你應該把你的actor的output呢,
link |
才能夠提供training data呢,
link |
那如果你把這個pi的output呢,
link |
看到更多不同的training data。
link |
它是這個deep deterministic policy gradient的縮寫。
link |
這個pathwise derivative policy gradient的
link |
那我們需要一個target的critic,
link |
這個target的critic跟target的actor,
link |
它是我們在estimateQ function的時候用的。
link |
好,這個target的critic呢,
link |
那我們initialize一個replay buffer。
link |
這個initialize的replay buffer呢,
link |
那在每一個iteration裡面呢,
link |
actor其實就是一個function,
link |
input,exit,output就是一個action。
link |
那我們會把它input,exit,output的action呢,
link |
那你會收集到一堆的training data,
link |
你的training data長什麼樣子呢?
link |
你的每一筆training data就是
link |
採取action at,得到reward rt,
link |
你的replay buffer裡面去。
link |
接下來你要認這個Q function,
link |
從你的replay buffer裡面
link |
sample出n筆的training data。
link |
n筆的training data以後,
link |
這個target y hat是什麼呢?
link |
這個target y hat呢,它是
link |
你先拿你的target actor pipeline出來,
link |
pipeline會採取哪一個action。
link |
pipeline會採取的action,還有
link |
認出一個Q function以後,接下來
link |
你要update你的actor pi
link |
可以讓這個Q function的值增加。
link |
做interpolation。把Q'乘三個位置
link |
做interpolation。這樣的好處是,
link |
跟pipeline的interpolation。
link |
它還會跟自己做interpolation。
link |
比較緩慢呢,可以讓你的training
link |
Pathwise Derivative的這個
link |
Pathwise Derivative的做一下連結。
link |
把actor critic還有game結合起來
link |
reinforcement learning跟
link |
那既然game跟actor critic你可以
link |
這個Connecting Generative
link |
Adversarial Network和Actor Critic
link |
把reference列在這邊給大家參考。
link |
game的技巧還有actor critic的技巧。
link |
這些這些技巧,actor critic呢
link |
試了有用,但還沒有被試在actor critic上。
link |
actor critic上試了有用,但還沒有
link |
你從別的領域借一個方法,比如說你原來在