back to index
Gated RNN and Sequence Generation (Recorded at Fall, 2017)
link |
好,那我們今天呢,要講的是有Gate的Recurrent Neural Network,有Gate的Gated的RNN,還有講怎麼用RNN這個技術呢,來Generate一個Sequence。
link |
那我們都知道說,作業二其實已經說到了,那作業要做的事情,就是Video Question Generation,也就是讓Machine看一段Video,然後它用一段話來描述說在Video裡面發生什麼事情。
link |
那如果你要做作業二這件事情,那你就需要今天我們這堂課講的技術。那今天這堂課內容如下,首先我們會複習一下RNN,那我想RNN其實大家應該也是熟熟熟,對不對?
link |
作業一,我看大家都已經有用LSTM,甚至是CTC來Solve作業一的Problem,所以這個部分呢,我們就稍微講得快一點,就當作是複習,那如果你有問題的話呢,你隨時可以打斷我。
link |
那第二部分就是講說,怎麼用RNN來Generate一個Sequence,那第三部分講說,怎麼用RNN在根據我們所給定的情境下,給定的條件下,比如說一段Video,Generate對應到我們給定的情境,比如說對應到我們輸入的那段Video的一段文字。
link |
那最後呢,我們會講一些做這個Generations的時候的小技巧,這些小技巧其實你自己如果讀文獻的話,其實是不太容易注意到的。
link |
那我們就先來複習一下RNN,那RNN我想大家應該都很熟悉了,你應該知道說RNN特別適合拿來處理Input是一個Sequence的狀況,舉例來說,在作業一裡面,我們要做的是Input一段聲音訊號,然後辨識這段聲音訊號裡面有什麼樣的Phoning。
link |
那一段聲音訊號,你在作業一裡面,知道說它是被表示成一個Vector的Sequence,舉例來說,現在這個就是你的Model的Input,它是一個Sequence,X1,X2,X3。
link |
那接下來呢,我們用RNN怎麼處理這個問題呢?一般我們在講RNN的時候,我們通常就會說,RNN就是有記憶的Recurrent Neural Network,有記憶力的類神經網路。
link |
那我們今天呢,在這邊,這個東西你在網路上大概已經聽了太多了,所以我們今天採取一個不一樣,比較不一樣的講法,RNN是什麼呢?RNN它的特色就是,它裡面有一個Basic的Function,然後這個Basic的Function,不管你現在輸的Sequence有多長,它都是不斷地被反覆地被使用的。
link |
那今天這個Basic的Function這邊呢,我們寫作F,這個Basic的Function F呢,它吃兩個Vector當作Input,一個是H,一個是外界的輸入X,它會吐出兩個Output,一個是H',一個是Y。
link |
好,那現在呢,假設Input一個Sequence,F呢,就會把Sequence的第一個Vector,X1呢,讀進來,那它會需要吃另外一個Vector,H0,那在整個Sequence的開頭的時候,你不知道H0是什麼,怎麼辦?
link |
通常你會自己給它Machine一個初始值,比如說你用一個Zero Vector來當作這個H0。好,那F呢,就吃X1跟H0以後,它就Output兩個Vector,它Output一個H1,它Output一個Y1。
link |
在作業1裡面,Y1呢,就是現在Input的這個X1,屬於哪每一個Form的機率,它是一個Form的Distribution。好,那X2呢,跟H1呢,會被丟到一個一模一樣的Function F裡面去,這兩個Function是一模一樣的Function。
link |
好,那這個,這邊要注意的地方呢,是這個H跟H',也就是這個Function F的輸入和輸出呢,它們必須要是同樣的Dimension,它們Dimension必須要是一模一樣的。
link |
這樣子呢,你看這個H1呢,是F的輸出,但是它又會被同一個Function吃進去,所以今天這個F的這個輸入和輸出的Dimension一定要是一樣的,這樣它等一下才可以把自己吐出來的東西呢,再吃進去。
link |
好,那現在Input X2跟H1以後呢,F呢,就Output這個,F呢,就Output H2呢,跟Y2。好,那接下來呢,接下來就讓,接下來呢,再把同一個Function拿出來,讓它吃X3跟H2,它就Output Y3跟H3。
link |
那同樣的Process呢,就反覆繼續下去,不管你的Sequence有多長。那Rn的特色就是,今天不管你Sequence有多長,你都是把同一個F一直反覆的使用,所以你的參數的量就不會受到你的Sequence所影響,這個就是Rn的好處。
link |
如果你今天是用別的Model來處理Sequence,舉例來說,假設你今天要用Fully Connected的Feedforward Network來處理,假設你要用別的方法來處理Sequence,假設你今天是用Fully Connected的Feedforward Network來處理Sequence,你有辦法處理嗎?其實你是有辦法,怎麼做?
link |
你可能會說,Fully Connected Feedforward Network不是要吃固定長度的Input嗎?那沒有關係,你就看你Database裡面最長的Sequence有多長,然後把所有比較短的Sequence統統補到一樣長,統統補0補到一樣長。
link |
那你就可以把Sequence呢,把不同長度的Sequence統統變成一樣長度的Vector,你就把整個Sequence裡面所有的Vector串起來變成一個很長的Vector丟到Fully Connected Feedforward Network裡面,你一樣可以處理Sequence的問題。
link |
但這麼做不是一個好方法,為什麼它不是一個好方法?因為你會發現說,如果你是用Fully Connected的Feedforward Network來處理Peg成一樣長度的Sequence,當你的Sequence越長的時候,你的Fully Connected Feedforward Network就會需要越多的參數。
link |
如果你稍微有點Machine Learning的概念的話,參數多意味著如果你的Training Data沒有辦法跟著增加的話,那你就容易Overfitting。所以RNN其實是一個當你在處理Sequence的時候對抗Overfitting的方法,因為我們只需要同一個Function就可以處理任意長度的Sequence。
link |
那當然RNN可以是Deep,但剛才舉的例子不是一個Deep的RNN,剛才只有一個Basic的Function在這邊寫作F1,那我們可以再多幾個Basic的Function。
link |
比如說如果我們要再疊另外一層,那我們其實就是多了另外一個Basic的Function,這邊寫作F2。F2它的Input是Y跟B,它的Output是B'跟C。
link |
那F2做的事情就是把F1的OutputY1吃進來,然後它再吃B0,然後吐出B1跟C1。然後F2也是一樣被反覆的使用,它吃Y2跟B1,吐出B2跟C2。它吃Y3和B2,吐出B3和C3。這個是Deep的Recurrent Neural Network。
link |
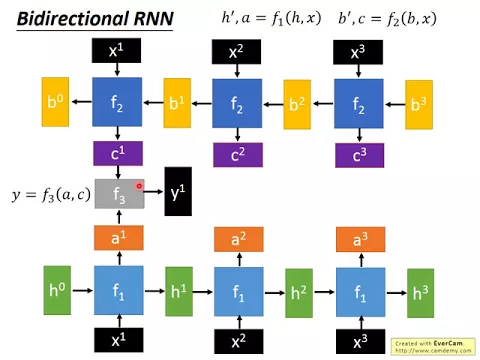
那Recurrent Neural Network也可以是雙向的,RNN也可以是雙向的。當我們說有一個雙向的RNN的時候,意思就是說我們不只是有原來的Basic Function F1,我們還有另外一個Basic Function F2。
link |
F1跟F2它們吃的Sequence是一樣的,在這個例子裡面都是X1,X2,X3,但是它們Process Sequence的方向是不一樣的。F1是先看X1,再看X2,再看X3。但F2是把X3吃進來,吐出東西,再吃X2,再吐出東西,再吃X1,再吐出東西。所以F2跟F1的方向是相反的。
link |
好,那在作業一裡面,我們知道說我們是要為每一個Input的Vector去決定它的Label是什麼。那如果今天使用的是Bidirectional的RNN,你怎麼得到一個最終的Output呢?
link |
因為現在Forward的Network,Forward的RNN正向的RNN給你的A1,逆向的RNN給你的C1,那你怎麼得到決定最終的結果呢?你需要有另外一個Function,這個Function我們這邊寫作F3。
link |
F3就吃Forward吐出來的A1,吃Backward吐出來的C1,然後得到一個最終的Output,而這個最終的Output我們這邊寫作Y1,就是你作業一裡面每一個Feature它對應的Label,它所對應的Form。
link |
好,所以這個Process呢,F3就Apply在每一個Input的Vector上面。好,那這個其實應該都是大家比較熟悉的東西,所以就只是當作複習而已。
link |
那接下來要講的是說,我們還沒有看一下這個Function F裡面呢,它長什麼樣子。它長什麼樣子呢?如果是在最簡單的,最馬藝夫的RNN裡面,它的長相是這個樣子的。
link |
我們知道說它吃一個H,吃一個X,它Output一個H', Output一個Y,怎麼把這個X跟H變成H'跟Y呢?它整個運作是這個樣子,你把這個X乘上Wi,Wi是一個Matrix,所以X乘上這個Matrix,它變成另外一個Vector。
link |
然後呢,把這個H乘上Wh,H乘上另外一個Vector,也變成這個Vector。把這個Vector和這個Vector呢,把它加起來,然後通過一個Activation Function,你就得到新的Output,H'.
link |
那怎麼得到Y呢?其實Y是根據H'所得到的,你把H'乘上一個MatrixWo,變成另外一個Matrix,然後Apply Activation Function,最後呢,你就得到Y。
link |
那假設Y是你最後的Output,你希望你最後的Output是一個Probability的Distribution,那你可能會Apply Softmax,那這個是比較容易的,我想大家其實也都很熟悉。
link |
接下來呢,我想要講的是LSTM,我有一個好奇就好奇問一下,我知道說大家在作業裡面都做LSTM,我不知道你是Call LSTM的那一人,然後其實不知道它是什麼,還是其實你已經非常了解它內部的結構。
link |
我們這樣問這個問題好了,假設有人叫你寫一下LSTM的式子,你其實是馬上可以寫出來的同學舉手一下,你其實不知道LSTM Layer裡面在做什麼的同學舉手一下。
link |
沒有人有回應,有一些同學舉手,所以其實講這個地方還是必要的啦,我們就來講一下,假設你其實只有Call了LSTM Layer,它就只是四個字母,但其實不知道裡面是什麼的話,我們就來講一下。
link |
好,那LSTM跟原來的RNN有什麼不同?其實它們是一樣的,我知道傳統的講法比較常講的是說,LSTM就是裡面有Memory Cell,然後Memory Cell有三個Gate,Input Gate、Forget Gate跟Output Gate,那這個東西你在很多不同的場合可能都已經聽到有人講過了,所以我們今天是用不一樣的講法。
link |
我們先說LSTM怎麼跟一般的RNN一模一樣呢?LSTM它的運作其實是這個樣子,你Input一個XT,然後它會Input這個HT-1跟CT-1,它會Output HT、CT、Output YT。
link |
如果你把這個CT-1跟HT-1這兩個Vector把它併在一起,你會發現說,右邊LSTM的Block其實跟RNN是一模一樣的,唯一不一樣的地方只有它們內部運作的式子不一樣。
link |
如果你把它們這個Block拿出來,它們的IO是一模一樣的。如果你不看內部構造,只看它們的IO的話,它們的IO是一模一樣的。既然IO是一模一樣的,為什麼我們要特別把Input分成C跟H呢?因為這是LSTM一個非常特別的設計。
link |
它的設計是C跟H它們的特色是不一樣的。怎麼個特色不一樣法呢?這個C這個Vector它的變化是比較慢的。所謂變化比較慢的意思是說,CT-1和CT其實不會差太多。
link |
就是今天LSTM的輸入CT-1跟它的輸出CT其實是很接近的,是不會差太多的。等下你會看到說,它的輸出CT其實只是輸入CT-1加上一個東西而已。
link |
但是呢,H它的變化是很快的。等下看到說,HT和HT-1這兩個Vector其實是會非常不像。那這帶給我們什麼好處?我們知道在文獻上常常會聽到有人說,LSTM厲害的地方在哪裡?
link |
它厲害的地方就是它可以記得非常久遠以前的事情。相較於一般傳統的RNN,它可以記得比較久遠以前的事情。那這個能力就來自於它有這個CT這個Path,有C這個Path。
link |
因為這個C這個Path呢,它的變化是比較慢的。所以就算是很久以前的CT跟現在的CT,其實長得其實是會很像。那意思就是說,今天LSTM可以把在Sequence開頭的時候讀到的Information就放在這個CT裡面,這個C這個變化是很慢的,所以它可以一直傳到Sequence接近結尾的地方。
link |
接下來我們就來看一下LSTM的內部實際上是怎麼運作的,這個Function裡面實際上是怎麼運作的。
link |
那你說這個LSTM它的Input就是有C這個Vector,有H這個Vector,有X這個Vector。那X是外界的Input啦,那H跟C來自於前一個Time Step,前一個時間點,LSTM自己的Output。
link |
那LSTM拿這些Input做什麼樣的處理?LSTM首先做的事情是,它會把X跟H併在一起,變成一個比較長的Vector。
link |
然後它會把這個比較長的Vector乘上一個Matrix W,做一個Linear的Transform。而這個Linear的Transform會再通過一個Application Function Hyperbolic Tangent,然後得到另外一個Vector Z。
link |
那這邊你可能會有問題說,為什麼這邊要取Hyperbolic Tangent?等一下我會引用文獻告訴大家說,LSTM裡面的每一步的設計都是古聖先賢的心血這樣子。
link |
所以它裡面的這些,你一下就不知道為什麼要這樣做的設計,其實拿掉以後的Performance都是有影響的。等一下我會引用文獻來告訴大家這件事情。
link |
那總之,現在把X跟H乘上一個Transform以後,得到Z。那在等一下的圖示裡面呢,今天這個比較粗的箭頭就代表一個Linear的Transform,就代表乘上一個Matrix,就代表一組參數。
link |
好,那現在把X跟H再乘上另外一個Transform,Wi,然後再把它通過一個Excavation Function。那這個Excavation Function這邊呢,我們通常選Sigmoid Function,然後得到另外一個Vector Zi。
link |
這個Zi跟Z呢,它當然是完全不一樣的,因為這邊不只Apply了不同的Excavation Function,也乘上了不同的Weight,但這個Weight我想大家都有訓練你的概念,它就是學出來的。
link |
但是這兩個Weight是不一樣的,所以Z跟Zi也是不一樣。
link |
好,所以根據X跟Ht-1,我們產生了另外一個Vector Zi。那我們接下來再反覆做同樣的事情,把X跟Ht-1乘上另外一個Matrix Wf,那這個都是從Data裡面認出來的,得到Zf。
link |
好,我現在得到另外一個Vector Zf,然後接下來呢,把這個X跟H的Containation呢,再乘上Wo,再得到另外一個Vector Zo,它又是另外一個Vector。
link |
我們把這個Input的這個Vector呢,乘上四個不同的Transform,得到四個不同的Vector。那在文件上呢,這個Zi我們叫它Input Gate,Zf它代表的是Forget Gate,Zo是Output Gate。
link |
那當我們實際看LSTM怎麼處理這四個Vector的時候,你就會了解說這四件事情,這個名字到底是什麼樣的含義。那現在你其實可以記起來說,Z有上標i,所以就是Input Gate,Z有上標f,所以是Forget Gate,Z上標o,就是Output Gate。
link |
好,接下來我們就來看一下,請說。你說這個,這邊都會用Sigmoid,那用Sigmoid的好處就是,它想要模擬一個閘門是打開還是關起來的狀況。
link |
我這邊通常都用Hyperbolic Tangent,為什麼不用ReLU這樣子,對不對?首先啊,在經驗上,如果在Recurrent Neural Network裡面Apply ReLU是蠻容易壞掉的啦,如果你自己有實作經驗的話,你可以比較Hyperbolic Tangent跟ReLU。
link |
Apply ReLU其實蠻容易壞掉的,除非你用Hitman Propose的那個特別的Indicialization,不然它還蠻容易壞掉的。所以這邊通常就用Hyperbolic Tangent。那你可能會問說,拿掉Hyperbolic Tangent行不行呢?等一下我們會引用一下文獻說,拿掉以後會有什麼樣的影響。
link |
好,希望我回答到你的問題。好,那接下來,有人就會說,為什麼只拿H跟X來產生這四個vector,C一起進來可不可以?C一起進來也可以。
link |
如果你要把C加進來的話,這個叫做用了Pinhole,Pinhole就是一個脫窺孔的意思。你也可以把C加進來,所以你可以把X、H跟C併在一起變成一個很長的vector,然後乘上一個比較寬的transform,得到Z。
link |
那一般我們在實作的時候呢,這一個部分啊,就是這個matrix跟C相乘的部分,我們通常會強制把它設成該功能。
link |
就在一開始的設計的時候,這個matrix就只有對角線有值,對角線以外的地方就把它設成0這樣。那其實有沒有加Pinhole本來就對performance的影響已經不大了,所以我們在加Pinhole的時候,我們會希望說不要再增加太多的參數。
link |
所以強制讓這個C、P-1跟這個matrix相乘的時候,這個matrix只有在該功能的地方是有值的。
link |
所謂該功能的地方有值的意思就是說,現在呢,C的第一維只會影響Z的第一維。這樣大家了解我的意思嗎?當這邊是該功能的時候,意思就是說,你只會把C、P-1的每一個element乘上一個scalar。
link |
你並不是對它做一個linear...你沒有對它做linear乘縫那麼複雜,你只是對每一個scalar乘上一個scale這樣。所以C、T-1的第一維只會影響Z的第一維,C、T-1的第二維只會影響Z的第二維。
link |
當然你也可以自己在實驗的時候,試試看說如果這邊不是該功能行不行,但這樣參數比較多,你可能會比較容易overfitting就是了。
link |
那ZO、ZF跟ZI也是用同樣的方法來處理。接下來我們就要看說好了,現在有了這四個vector,LSTM拿這四個vector來做什麼事情呢?
link |
第一個process是把Z跟ZI做elementwise的相乘。我們拿這個圈圈裡面的一個點代表的是elementwise的相乘。
link |
這個elementwise的相乘的意思是說,今天Z的information要通過ZI的檢查,看它要不要再去跟C、T-1這邊的information加在一起。
link |
所以這個ZI代表的是input gate,它決定說Z的information能不能夠被拿進來使用。然後這個ZF它會跟C、T-1做elementwise的相乘。
link |
它決定的就是C、T-1的information要不要在接下來的output被使用。所以它的概念像是,C、T-1我們通常把它當作是memory,把它當作是記憶。
link |
那要不要把記憶拿來用,就是代表說你要不要把過去的記憶遺忘掉。所以ZF它的意思它是forget gate,所以它代表的是forget.
link |
如果你沒有辦法聽懂這些也沒有關係,反正事實在這邊。事實就是說,把Z跟ZI做elementwise的相乘,把C、T-1跟ZF做elementwise的相乘把它加起來。
link |
加起來以後的結果就是新的C、T-1。所以這邊你會發現說,其實C、T-1和C、T,這個C的值在輸入和輸出端,它的差別是比較小的。
link |
所謂說它差別比較小的意思是說,從C、T-1到C、T,你只是做一個elementwise的相乘再加上一個東西而已。所以C、T-1通過這一條路到C、T,它們可能還是比較像。
link |
接下來我們會把C、T跟ZO做elementwise的相乘。當然在做elementwise的相乘之前,C、T其實會通過一個hyperbolic tangent。你可能會問說,為什麼要通過hyperbolic tangent?
link |
Apply hyperbolic tangent的用意就是希望C、T的值不要out of bound。在實作上,這件事情對影響是非常巨大的。如果你沒有加hyperbolic tangent的話,結果是很容易壞掉的。
link |
C、T會apply hyperbolic tangent,然後跟ZO做elementwise的相乘,得到H、T。我們如果把H、T視為output的話,ZO所做的事情就是決定這個output能不能夠出來。
link |
所以我們說ZO它是一個output gate。如果你沒有辦法聽懂,沒有關係,反正這個式子就是寫成這個樣子就是了。最後怎麼得到Y呢?我們現在已經有H、T了,H、T在這邊。
link |
H、T-1就會非常不像。為什麼非常不像?因為這個H、T-1它是經過一個linear transform以後,它是乘上一個matrix W以後變成Z,然後再經過一連串的operation才變成H、T。
link |
所以這個H、T-1它跟H、T已經非常不像,不像C、T-1跟C、T是比較像。H、T-1跟H、T它是非常不像。所以LC的特色就是它保留了兩個path,一個是變化很快的path,一個是變化很緩慢的path。
link |
最後怎麼得到最終的output呢?要得到最終的output就是把H、T乘上W'再通過我們excavation function得到最後的outputY、T。那我們知道說RNN的特色就是LSTM的輸出要再變成它自己的輸入,所以怎麼做呢?
link |
LSTM現在吃C跟H,output另外兩個C跟H,那同樣的operation就會被再反覆做一次,就是你把H、T-1加進來,然後apply四個transform變成四個不同的vector,再把這四個不同的vector做一模一樣的operation,你得到最後的outputC,你得到新的C、T加1,得到新的H、T。
link |
這邊notation有沒有錯呢?有錯!就是這個是H、T加1啦,這個應該是H、T加1,對不對?這邊是H、T,然後走過來這個應該是H、T加1,然後你可以得到Y、T加1。
link |
這個是LSTM,如果你聽不懂的話也沒有關係,反正在多數的framework裡面,你就是打LSTM layer,你就有這個東西了。那我們除了介紹LSTM以外,我們來講另外一個常用的block叫做GRU。
link |
我們知道說RN的精神就是它有一個block,這個block裡面有什麼設計其實都可以,都看你高興,你可以設計成LSTM的樣子,有別種的設計,比如說GRU就是另外一個現在非常常用的設計。
link |
GRU跟LSTM比起來的好處就是它的參數量比較少。我們先來介紹一下GRU的運作方式,然後我們再解釋說GRU和LSTM有什麼樣的關係。GRU它不像LSTM一樣有分成H跟C,它就是input一個H,output一個H。
link |
那它拿這個input的H跟X做什麼樣的事情呢?GRU就是把input的X跟H把它concatenate在一起,這個跟LSTM一開始做的事情是很像的。
link |
接下來apply兩個transform,所以你把X跟Hconcatenate在一起以後,apply兩個不同的transform,得到兩個不同的vector,一個寫做R,一個寫做Z。R的這個部分我們叫做reset gate,Z的部分我們叫做update gate。
link |
接下來我們把R跟H做element wise的相乘,然後把這個element wise相乘的結果跟XTconcatenate在一起,再apply一個transform,得到HT。
link |
這樣大家了解這個意思嗎?把這個element wise相乘的結果跟XT並在一起,apply一個transform,我們用一個黃色的箭頭代表transform,得到HT。
link |
這個圖有點難畫,我希望這個畫法是看得懂的。接下來我們要用Z來做一些什麼事,但是今天一個特別的地方就是,Z是一個人當作兩個人用,為了cost down,所以Z就是一個人當作兩個人用。
link |
他一個人做兩件事,他一個人當作兩個gate來用,所以Z他會去跟HT-1做element wise的相乘,但是他也會跟這邊這個HT,他也會跟這個HT也做另外一個element wise的相乘。
link |
但是這兩個element wise的相乘是不一樣的,我們直接把他的式子列出來比較清楚,我們是把這個HT-1跟Z這個vector做element wise的相乘,但是把HT-1跟,
link |
這邊這個是H',這個不是這個HT,我剛才好像都唸錯,我把它唸成HT,但它其實是H',其實從我這個角度來看這個mine是長得非常像體的。
link |
這個是H',它不是我們最後的output HT,最後的output HT在這邊,這個是H'.我們把這個H'跟Z做element wise的相乘,但它其實不是跟Z做element wise的相乘,
link |
它是跟E-Z做element wise的相乘,這個E-Z的意思是這樣,假設Z你是比如說0.1,0.9,這邊E-Z的意思其實就是0.9,0.1,希望大家知道我的意思。
link |
所以今天如果HT-1對最終的結果影響比較大,也就是說這個Z的值比較趨近1的話,那HT-1對結果影響比較大,那H'對結果的影響就比較小,
link |
它們是互相接抗的,一個多,另外一個就少。最後的HT如果比較像HT-1,它就比較不像H',比較像H'就比較不像HT-1。
link |
好,那我們來比較一下這個LSTM跟GRU,雖然在notation上我們把GRU的input和output寫成H,但是實際上如果你仔細想一下HT-1跟HT的關係,你會發現說HT-1和HT它是比較像的,
link |
意思就是說HT-1跟H中間它們只差了做element wise相乘和加上另外一個factor而已。所以其實在GRU裡面,它的H的角色比較像是LSTM裡面的C。
link |
那大家了解我的意思嗎?就是我們說LSTM裡面有兩個PAM,C跟H,C的變化是慢的,H的變化是快的。在GRU裡面它只有H,但它的H其實跟C做的事情比較像,它的H的變化是慢的。
link |
如果你從這個圖上可以很明顯的看出來,H跟HT之間它們是比較相像的。所以GRU可以做到跟LSTM比較類似的事情,它所儲存的資訊,它所傳遞給下一個step的資訊是可以保留的比較久的。
link |
如果我們看一下LSTM和GRU的參數,你會發現GRU裡面用了四組參數,有四個不同顏色的出熱箭頭,所以它用了四組參數。
link |
在GRU裡面它只用了三組參數,所以GRU的參數是比較少的,LSTM用的參數是比較多的。
link |
如果我們再看一下,比較一下GRU跟LSTM的話,請我們回到前面幾頁,我們先再給大家複習一下LSTM的式子,我們來看一下LSTM的式子。
link |
這個CT跟CT-1的關係是什麼?你會把CT-1乘上fork gate,再把它加上來自input和input gate相乘的資訊,得到最後的CT。
link |
對應到GRU裡面,應該就是這個式子。所以這個Z的角色,也就是update gate的角色,相對於LSTM而言,它的角色就是fork gate的角色。
link |
因為剛才在LSTM裡面是CT-1乘上fork gate gate,那這邊是HT-1乘上Z,所以Z的角色其實是fork gate的角色。其實我們有做,這個是我們實驗室自己做的實驗,就是比較一下GRU跟LSTM他們的gate的變化。
link |
你確實會發現說update gate的變化,比如說你在提名上train一個GRU,train一個LSTM,然後你看那個gate開關的變化,你會發現說fork gate的變化確實是比較接近update gate的變化。
link |
所以update gate的角色,它比較像是fork gate gate。那我們說後面這個部分,後面這個部分是由input gate所control,但是在這邊,它確實也是由update gate來用E-update gate來control這個結果。
link |
所以今天在這個GRU裡面,你就可以想成,它的input gate和fork gate gate是連動的,它們是互相連結在一起的。也就是說,你今天一定要有新的東西進來,你才會忘掉東西。
link |
如果沒有新的東西進來,你就不會忘掉東西。當你忘掉東西的時候,就會有新的東西進來。它是把input gate和fork gate gate連在一起,這件事情聽起來其實也是頗為合理的。
link |
這個是GRU的部分。接下來你可能會有的問題就是說,為什麼這些gate的network是這樣的設計?接下來就是要引用文獻來回答大家的這個問題。
link |
這邊要引用的文獻是LSTM的Search Space Odyssey這篇paper。所謂的Space Odyssey的意思,Odyssey就是河馬的史詩奧德賽。Space Odyssey其實是電影《太空漫遊》的那部電影的英文名字。
link |
所以這個篇paper的title的意思就是說,我們在這個LSTM可能的design的這個Search Space裡面進行漫遊。這個實驗其實在paper裡面做了好幾個不同的Compass。
link |
這邊只引用了做在Team力上的實驗,也就是跟大家在作業一的時候做的實驗是一模一樣的。你甚至可以在final的時候拿作業一出來,看看你能不能夠得到類似的結果。
link |
在這個圖上,每一個點都代表了一個LSTM。所以每一個點它的橫坐標代表的是這個LSTM的分類錯誤,縱坐標代表說這個LSTM需要訓練的時間。
link |
不同的顏色代表了不同的這種gated recurrent network的設計,比如說你拔掉一個input gate,拔掉forget gate,看看會有什麼樣的影響。
link |
那為什麼同樣顏色的點會有好多個呢?那是因為說,你知道在做那個network的時候,你要調參數嘛,你要調你的network的hidden layer的size。
link |
那不同hidden layer的size就對應到這個圖上的不同的點。那每一個network它都有用devalidation set去報收它的learning rate等等,把它調到最好。
link |
所以這邊有非常非常多的實驗,你可以想像說做這個實驗是非常花時間的。在Paver的expert裡面呢,他就很自豪的說,如果這些實驗用CPU跑的話,要跑15年這樣子。
link |
好啦,我們來看一下這個實驗結果。我們等一下會有比較好的整理的圖表,但我們先來看一下這個實驗結果,知道一下大致的趨勢。
link |
arrow rate越往右越大啦,所以它顯然是一個arrow rate特別差的東西。它是什麼呢?我們來看一下,青色的點是noaf。noaf是什麼?它是沒有output activation function。
link |
什麼叫做沒有output activation function?記得我們剛才講過那個CTR要乘上一個hyperbolic tangent,對不對?拿掉那個hyperbolic tangent,你就得到青色這個地方。所以拿掉那個hyperbolic tangent,它的performance是比較差的。
link |
你知道這個圖越往右上,就是代表結果越差啦,就代表越差的沒我。它就是訓練時間越長,它的performance越差。那我們來看一下,在上面這邊有一些黃色的XX。
link |
黃色的XX代表的是,雖然arrow rate你可以壓到比較低,但它訓練的時間是比較長的。黃色的XX是什麼?它是FGR。這個FGR是什麼呢?FGR是什麼?我看看。
link |
它是Fully Gating Recurrent。什麼意思呢?它的意思是說,我們每次在操控一個gate的時候,我們現在只有把H跟X,還有最多C併在一起,去產生不同的Z,對不對?
link |
它說,我們要把上一個時間點的Z也通通都拉進來,拼成一個很長的vector,然後去操控,去產生不同的Z跟去產生不同的Z,這樣大家聽得懂嗎?
link |
把一個時間點的Z通通拉到下一個時間點來使用,所以參數變多了,所以當然訓練的時間就變長了。好,這邊有一些右上角一些藍色的點,藍色顯然是不太好的,藍色是什麼?它是NFG。
link |
它是NFG是什麼?No Forget Gate這樣,所以把Forget Gate拔掉,performance會比較差。好,那這個圖有點難看,所以在這個paper裡面還是整理好的結果。
link |
每一個column就代表了一種不同的LSTM架構的變形,這個實驗是做在天上。
link |
那這個圖上,這邊不知道大家看不看得清楚,背後有一個長方形,這個長方形的高代表了這個network的參數,所以你會發現說,這一個架構,它的長方形是特別高的,參數量特別多,
link |
它就是我們剛才講的這個Fully Gated Recurrent,你把前一個時間點拉到下一個時間點來用,參數變多了,所以它的參數是比較多的。
link |
好,那如果我們看這個performance的話,你會發現說,首先最左邊這個VR代表的是standard的LSTM,就是我們現在所熟知的那個LSTM的型態,這個我們所熟知的LSTM的型態,它的performance其實是不錯的,相較於其他的方法而言,它並沒有特別差。
link |
另外有這三個變形,它們其實跟現在standard的LSTM performance差不多的,分別是哪三個變形呢?一個是CIGF,CIGF是什麼?
link |
喔,CIGF是把implicated跟plicatedcouple在一起,其實就是GRU了,對不對?所以GRU這個設計,至少在這個大量的實驗的explore上面發現說,這一個設計的精神是不會讓你的performance比較差,而且它的參數量呢,跟standard的LSTM比起來參數量是略少的,然後performance也沒有比較差。
link |
那fully recurrent,剛才講的就是增加參數量的那個方法,參數量變多了,performance沒有比較差,但是它參數量比較多,所以訓練時間比較長,所以大家也不會太喜歡這個方法。
link |
NP是什麼?NP就是把那個peak hold拿掉,就是不要讓C去影響你產生的Z,本來是只有H跟X會產生Z嘛,那我們說把C加進來叫做peak hold,那把peak hold拿掉,其實performance有稍微變差一點,但是影響也沒有很大。
link |
那接下來的這五個變化,會讓你的performance掉下來,一個是NOG,就是沒有output gate,會讓你的performance變差一些。
link |
然後NIAF是沒有input activation function,就我們說input的時候一個hyperbolic tangent,把它拿掉,performance也是差一點。NIG是把input gate拿掉,N就是not的意思,I就是input的意思,把input gate拿掉,performance就差了一點。
link |
那NFC,S代表forget gate,NS就是把forget gate拿掉,performance更差。NOAF就是把output activation function拿掉,以後它就不在那個圖上面了,它就飛到那個圖外面了。
link |
所以我們今天得到的結論是什麼呢?就是standard的LSTM其實還蠻好的,古聖先賢的智慧是不可思議的,所以他們設計出這個LSTM,它的效能是好的。
link |
只要有一些simplified LSTM的方法,對你的performance是不會有太大的影響的,一個是把input gate和forget gatecouple起來,這是GRU的精神,然後拿掉tweakpole,也沒有太大的影響。
link |
然後forget gate對你的結果是有很大的影響的,在這個實驗裡面你會發現說,拿掉forget gate的影響最嚴重,其次是拿掉input gate,最後是拿掉output gate,拿掉output gate的影響是最小的。
link |
所以你如果拿掉output的acclimation function,你不對你的c取一個hyperbolic tangent的話,整個結果是會壞掉的。這是某一篇paper的講法,那我們來看另外一篇paper,其實這篇paper裡面得到的結論跟上一篇search space odysseys得到的結論其實是還蠻接近的。
link |
在這篇paper裡面做的也是試了很多不同的cogos,我這邊也只引用一部分而已。這個結果是怎麼樣呢?我們先來看一下,這個三個不同的column代表三個不同的task,它的值是正確率,所以值是越大越好。
link |
那tangent h代表的就是原來的RNN,那LSTM整個大家都知道,LSTM比原來的RNN相比起來,它的performance是比較好的。
link |
LSTM-F的意思是說是把forget gate拿掉,-I是把input gate拿掉,-O是把output gate拿掉。如果我們比較這三個gate的影響的話,你會發現說拿掉forget gate的影響最嚴重,拿掉forget gate在這兩個task上面,結果都是整個爆爛。
link |
那如果拿掉input gate,影響稍微小一點,拿掉output gate,影響再小一點。所以這邊得到的結論也是forget gate最重要,大於input gate,大於output gate,跟前一篇paper得到的結論是一樣。
link |
然後這邊他做了另外一個study是說,我們把LSTM的bias,把這個forget gate的bias把它調大一點。什麼意思呢?forget gate的bias調大一點,你就想成說是LSTM傾向於記住過去的東西。
link |
L就是那個gate值的,假設你對那個式子不太熟悉的話,你就記得說今天所謂-b的意思是說,你在設定這個參數的initialization的時候,你希望forget gate可以盡量keep過去的information,盡量不要forget,盡量不要讓ct-1和ct差太多,盡量把原來ct-1保留到下一個時間點去使用。
link |
這個東西有沒有幫助呢?從這個實驗結果看起來是有幫助的。反正這篇paper其實就是驗證了這個都市傳說,其實這個都市傳說應該是有流傳非常多年了,或許有流傳數十年之久。
link |
這個都市傳說就是你在train那個forget gate的時候,你把bias調大一點,你的performance會比較好。你讓你的LSTM習慣讓forget gate是開啟的狀態,習慣把過去的information傳到下一個information,你的performance會比較好一點。
link |
那其實它就是驗證了這個都市傳說就是了。那這邊也做了一下GRU,有點難說GRU是不是有比LSTM好,它好像比傳統的LSTM好,但是如果你有比較大的bias的話,比較大的bias,至少在第一個test上又是贏過GRU的,所以有點難說,但至少GRU沒有比較差就是了。
link |
那最後這個μ1,μ2,μ3是什麼呢?它是這樣,它是用基因演算法去想辦法找出最好的recurrent block的架構。基因演算法不知道大家熟不熟悉,它基本的精神就是,我們就不要細講那個演算法的細節,基本的精神就是,你一開始有一些GRE,有一些recurrent neural network的設計,
link |
然後你把這些recurrent neural network的設計做雜交這樣子,把它們各自的特色拿出來做一下hybrid,然後再去做testing,然後testing的performance比較好的那幾個就留下來這樣,那可能還會做一些變異,以後再雜交,然後再去做testing,好的留下來再變異這樣。
link |
所以這個方法可以搜出一些比較好的RNN的structure,那找出來的比較好,這個performance比較好的這些RNN的structure長什麼樣子呢?它們長這樣,有點難看出什麼特別有趣的東西啦。
link |
如果你要比較這三個不同的用基因演算法找出來的network架構的話,你會發現說它們有一個共同的特色就是這個部分,就這個部分,就這個部分,那這個東西你會發現說它在原來的GRU裡面也是有的,對不對?
link |
因為原來的GRU就是把HT做elementwise的相乘,再加上另外一個東西得到HT加1嘛,對不對?所以原來的GRU裡面就有這樣子的設計,所以你可能會從這個圖裡面得到結論就是說GRU好像是比較強的。
link |
不過這個作者在最後conclusion的時候提醒你說,因為他今天在做基因演算法的時候,一開始不同的network最原始的祖先其實就是GRU,最後經過一番演化以後跟GRU長得很像也是有可能的,所以這樣的實驗還不足以說GRU就是一個最好的network的設計。
link |
但是反正學出來,用基因演算法找出來的比較好的recurrent neural network的block的設計是長這個樣子。好,那最近Google有一篇paper是用reinforcement learning的方法去印認recurrent neural network內部的架構。
link |
這邊左邊是傳統的LSTM,這邊用的notation跟我用的notation有點不一樣,但是這個在精神上超多的,你按input,X,HT-1跟CT-1,你就得到HT跟CT,中間operation有這個地方就是input gate,這個地方是forget gate,然後這個地方是output gate。
link |
你看到這邊有一個hyperbolic tangent,乘上一個sigmoid做LNY相乘,這個就是一個gate。
link |
你會發現CT-1到CT中間變化是比較少的,所以很明顯從這個圖上看CT-1和CT是比較像的,那這個HT-1跟HT是比較不像的。
link |
好,那如果用reinforcement learning的方法印找出來的recurrent neural network長什麼樣子呢?它長這樣,這個怎麼印找?這個是這樣子,你把每一個上面的這個圈圈當作是machine可以執行的一個action。
link |
reinforcement learning大家雖然,我們這門課還沒講過,你有一些類似的概念嘛,reinforcement learning你就拿它來玩那個atari的遊戲,那你有一個agent,agent就決定要做上下左右,然後會得到reward,然後會希望說它採取的action可以讓reward越大越好。
link |
今天這個network架構其實做的事情是一樣的啦,你就把machine決定說它現在要放什麼樣的operation到這個圖上去,當作是一個action這樣子,然後今天把network的架構決定好以後,拿去train,得到的正確率就是reward,然後agent就會想要用那種operation可以讓最後的reward最高這樣。
link |
然後想這個training的時間也是非常長的,你想想看,你玩這個遊戲,atari的遊戲可能數秒就結束了,但這個每一次你玩一次遊戲就等於是要train一個LSTM這樣子,所以這是一個非常暴力的實驗。
link |
總之,找出來的結果就是這樣子啦,有點難看出什麼東西啦,但是至少我們現在看到說它裡面也有這個gate的架構,那machine自己想要設計這個LSTM的block的時候,想要自己設計這個R的block的時候,它其實也自己找出了類似gate的架構。
link |
好,那這個部分其實就是複習一下recurrent neural network,大家有什麼問題,請說。
link |
【觀眾】那它那個initial frame call,它是一樣可以執行的嗎? 喔,就我所知不是,對,如果我說錯你再指正我,但是就我所知,它就是from scratch的硬學,硬學出來就是這樣。【觀眾】所以它有在其他的選單,比如說這個LSTM? 有,這個也是一個很厲害的地方,它說它裡面有怪怪的function,比如說sign這樣子,它自豪的一點就是machine沒選sign這樣子。
link |
好,如果大家沒有什麼其他問題的話,我們就進入到下一個階段。
link |
下一個階段就是,假設你會了LSTM以後,我們用LSTM怎麼產生一個sequence,或者我們舉比較具體的例子,在作業中我們要大家產生句子,我們怎麼用recurrent neural network來產生句子。
link |
那一個句子我們知道說它是由word或者是由character所組成的,對不對,如果是英文,我們通常把它當作是由一串word來組成,中文的話你可以看作是由一串word來組成,但是你也可以把它拆成是由一串character,一串字所組成。
link |
好,那怎麼用一個recurrent neural network來產生一個句子呢?等一下會有比較具體的例子,但它基本的概念是這樣,你把你的recurrent的unit拿出來,你把你這個basic function f拿出來,這個basic function的f它的input的這個x,就是你在上一個時間點generate出來的token,那我就用token來涵蓋word或者是character。
link |
那在不同的case,有時候你會想要用word,有時候會想要用character,怎麼用token來同時表示word和character。那通常一個token,我們會用關卡encoding來描述它。
link |
好,那這個f的output y是什麼呢?這個f的output y,它是所有token的,所有你可以產生的token的一個probability的distribution,那我們最後要讓我們去產生一個token,我們會從這個probability的distribution裡面去做sample,產生一個token。
link |
好,這樣講其實是有點抽象,我們來實際看一下,如果是x跟y的話,它們分別是長什麼樣子呢?如果是x的話,我們說它是一個one-time encoding的vector,也就是假設你在前一個time step,machine已經產生一個character,比如說它產生我這個character。
link |
那x你的表示方式就是,你在我這個dimension,它的值是1,而在其他的dimension,它的值是0。那y呢?y是一個over所有token的probability distribution,它是一個probability distribution,所以它的summation是1。
link |
通常會產生y字眼會通過一個submax,讓它的summation是1。然後呢,每一個character它都會給它一個機率,比如說,是的機率是0.7,但的機率是0.3,代表說,如果我現在看到我之後,接是的機率是0.7,接很的機率是0.3。
link |
好,那這樣子是比較抽象的,我們現在來講一個比較,我們現在來把它講得更具體一點。那假設我們已經train好一個recurrent neural network,等一下會講說怎麼把它train出來,假設它已經train好,我們怎麼拿它,怎麼拿這個basic function來產生一個句子呢?
link |
這個產生句子的process是這樣,首先呢,你在第一個typeset,你給它一個代表begin of sentence的token,代表begin of sentence的符號,你可能會加一個特殊的字元,代表句子開始。
link |
那接下來呢,f呢,就會output一個distribution y1,這個y1是什麼意思?這個y1代表說,假設現在輸入是begin of sentence,接下來第一個word,我們寫w這個token的機率,比如我們放,寫w這個字的機率就是y1。
link |
那舉例來說,假設你現在可能train的是一個寫詩的RNN,那你就從這個y1裡面去做sample,從這個distribution裡面去決定你要產生哪一個詞彙。
link |
那決定的方法有兩種,一個是用sample的方式,按照這個distribution去抽出一個詞彙,比如說你抽出來可能就是床這樣子。那或者是呢,你做argmax,看說哪一個詞彙的機率最高,選機率最高那個當作輸出也可以。
link |
所以用這兩種不同的方法,你會得到的結果是,如果你是argmax,那每次你產生的句子就都是同一句這樣子,那這depend on your application啦,你可能會希望他每次都產生的都是一樣的句子。
link |
或者是,如果是sample的話,他就會比較活潑,每一次你使用這個RNN的句子的時候,每次generate的都會是不一樣。好,那假設從這個y1裡面做sample,產生床以後,接下來呢,接下來你會把這個床呢,當作下一個時間點的輸入,再丟給這個basic function F。
link |
這basic function F就是床這個word的one of encoding跟前一個時間點basic function輸出h1產生y2跟h2。y2是什麼?y2就代表說,假設在這個network已經看到床作為輸入,還有過去已經看到picket of sentence作為輸入的前提之下,那接下來要產生哪一個詞彙的probability distribution。
link |
那你再從這個probability distribution裡面做sample,那你可能就sample出前這個字。好,這邊有兩個問題,一個是比較簡單的,有的同學可能會問說,這個F不是只有看床這個字嗎?為什麼這邊是寫成even床跟begin of sentence產生W的機率呢?
link |
但是你可以想想看,這個F它不只是看床的input,它還看前一個time state的output,前一個time state的output又depend on begin of sentence這個token,所以當我們產生y2的時候,我們其實同時考慮了input床這件事和input begin of sentence這件事,這個應該是大家對RMN都有的基本概念。
link |
另外一個同學可能會有的疑惑是說,為什麼需要把床當作下一個time state作為輸入呢?難道H裡面沒有保有y1的information嗎?為什麼我們需要把y1的資訊做一下sample或者是做一下argmax,再把它當作下一個time state的輸入呢?
link |
這個我們等一下再討論,當然你永遠可以在桌子裡面自己試試看,不要把x2當作輸入,把這個拿掉,把它補零,然後反正你相信H1它已經有包含y1的資訊,你可以試試看到底會怎樣,我覺得經驗上應該是會爛掉。
link |
那接下來呢,y2你做一下sample,sample出來的是錢,那把錢當作下一個time state的input,把它one open encoding再丟進去。
link |
那這個basic function f就是x3的h2,然後offer y3,y3就代表說machine已經產生了beginning of sentence,已經產生床,已經產生月,接下來要產生哪一個字呢?那它會產生一個distribution y3,從y3再去做sample,你可能就sample出你。
link |
那你就可以寫一個堂詩,這個process就反覆繼續下去,直到machine產生一個代表句子結束的token,你可能會用一個句號來代表句子結束的token,它產生句號的時候,這個產生的process就結束了。
link |
因為什麼時候產生句號是machine自己決定的,所以每一次產生句子的時候,它的長度都不見得會是一樣的,machine可以自己決定說它產生的句子要有多長。
link |
那這個講的是testing的部分,已經train好basic function以後,怎麼拿它來生成句子?那怎麼拿它來做訓練呢?假設你現在的training data裡面有一大堆的堂詩,比如說堂詩裡面的第一個句子是春眠不覺曉,那有了這個句子以後,怎麼拿來訓練這個RNN呢?
link |
訓練方法是這樣,你把begin of sentence丟到RNN裡面去,丟到這個basic function裡面去,假設第一個詩的第一個詞會是春的話,你就會希望說y1這個distribution和春的越接近越好。
link |
春你會用一個one of an encoding來表示它嘛,所以它也可以看作是一個distribution,那你要讓春的這個distribution跟y1它們的cross entropy越小越好。同理,在第二個詞彙的時候,在訓練的時候,你把春丟進來,那這個F看了春跟h1,你會希望它的distribution跟眠越接近越好。
link |
那你把眠丟進來,你會希望F這個眠跟h2的output y3跟不的這個cross entropy越接近越好。你就把這個cross entropy的和當作你的loss function去minimize它,你就可以把這個basic function把它勸出來了。
link |
那剛才講的是產生一個句子,那其實除了產生句子以外,同樣的技術,你也可以讓RNN去學著產生別的東西,舉例來說,產生圖片。
link |
怎麼讓RNN產生圖片呢?我們知道說圖片也是用pixel所構成的,對不對?一個句子是由character所構成的,圖片可以說是由一串的pixel所構成的。給我們一張圖片的時候,其實我們可以把它看作是一個非常特別的句子。
link |
怎麼樣特別的句子呢?給我們一張,舉例來說,這邊有一個3x3的圖片,我們就把每一個pixel的顏色用它對應的詞彙寫出來,比如說這張圖片的左上角是藍,我們把它轉成一個sentence的時候,它的第一個字就是藍,第二個字就是紅,第三個字就是黃,第四個字就是灰,然後黑藍,綠綠藍這樣。
link |
所以一張圖片,你可以把它變成一個句子,把它變成一個句子以後,你就可以任一個RNN去generate這種特別的句子,你even不用改你原來的code了,你就把圖片通通轉成這種很奇怪只有顏色的句子,然後用你原來產生句子的RNN的那個程式去任下去,你就可以產生圖片了,就這樣。
link |
所以怎麼做呢?假設你任好這個RNN以後,你就是給它一個begin of sentence,然後output一個distribution y1,然後從裡面的sample得到紅色,然後再把紅色丟進去,再做sample,你得到藍色,再把藍色丟進去,再做sample,你得到綠色,把這些顏色再轉回圖片,你就得到一張圖片了,這個方法是真的可行的,就這樣子。
link |
在文獻上也有人這麼做,這招叫做pixel RNN,那其實pixel RNN跟傳統RNN比起來還是有稍微做一下設計啦,其實你不用pixel RNN這個設計,直接拿你language model code來做,其實也做得起來,這個我試過,你們到時候自己試,你自己試試看,你even都不用改code,直接任下去就好。
link |
但是如果你要做到state-of-the-art的話,你要在RNN的架構再做一些特別的設計,pixel RNN裡面的設計是這個樣子的,原來的設計是這樣子的,我們產生藍色,再產生紅色,再產生黃色,假設你要它的寬只有三的話,接下來就換糖,產生灰色,產生黑色,產生藍色,再換糖。
link |
有人就會有個問題說,這個network架構的設計好像隱含著說,這個灰色的pixel和黃色這個特別有關係,但是實際上這個灰色的pixel應該是和這個藍色的pixel特別有關係,所以這個假設有點怪怪的。
link |
pixel RNN它的一個設計的概念,細節我們就不講了,它設計的概念是這樣,它說我們今天要產生這個灰色的pixel的時候,我們並不是看這個黃色的,我們是看左上角這個藍色的pixel,來決定我們這邊要產生灰色的pixel。
link |
我們要產生這個黑色的pixel的時候,我們不是只看左邊灰色的pixel,我們還要看上面紅色的pixel,看這兩個pixel來決定中間要放一個黑色的pixel,這個就是pixel RNN的基本設計的精神,它這個細節比較複雜,我們在這邊就先把它暫時挑過。
link |
接下來我們稍微先再講一下conditional sequence generation,我們剛才能夠讓machine產生一個句子,但是它產生的是一個隨機的句子,假設你從distribution裡面做的事情是,假設你產生句子的時候,你用sample這種方法來產生一個character的話,那你其實就只是讓machine隨機產生一些比較合理的句子。
link |
但我們要的不是只是machine隨便說一句話,我們要的是conditional generation,也就是說我們希望機器是根據我們所給它的情境產生合適的對應的句子。
link |
比如說像是我們作業二的時候,我們要大家做的是machine看一個video,比如說這個是星元節一直在跳舞,那它要產生一個句子去描述這個video的內容,那這個時候它必須要根據它的input的condition去決定它要offer什麼,而不是它愛說什麼就說什麼。
link |
所以我們會希望機器有這種conditional generation的能力。或再舉一個例子,比如說你想要做一個chatbot,那要做一個chatbot的時候,機器並不是只要說一句話就好了,這樣它就只是自言自語,沒有什麼好厲害的,你說一句話的時候,它根據你輸入的input給一個合理的對應的回應,這個時候你就會需要conditional generation的這個技術。
link |
好,那這件事情我們怎麼做到它呢?我們剛才已經看過怎麼產生一個隨機的句子,那我們把這個產生一個句子的network畫在右邊。
link |
那這邊我們會把前一個timestamp的輸出再接過來,放在下一個timestamp當作輸入,前一個timestamp的輸出會當作下一個timestamp的輸入。
link |
那我們現在要做的事情,假設我們要做的是image的conditional generation,那機器看一張圖片,之後我們實際上要做的是影像,看一張圖片比看一個影像還要更簡單一點,看一張圖片描述這張圖片的句子。
link |
那怎麼做?我們會希望說輸入的這張圖片對這個generation的process是有影響力的,所以我們希望把這個圖片的資訊也當作這個generator,generate sequence的時候的input。
link |
所以怎麼做呢?首先把這個圖片通過一個CNN,你把圖片通過CNN以後你可以得到一個代表這個圖片的vector,那你把這個vector當作generator的input。所以在generator在產生它的word的時候,產生它的probability distribution的時候,不是只有看前一個時間點已經產生的word。
link |
在原來的generator裡面,它的第一個time state就是看begin of sentence產生一個distribution。但是在conditional generation的時候,這一個RNN的basic function不是只有看前一個time state的東西,它還要看input的condition。
link |
你把input的condition變成一個vector,再當作這個RNN的輸入,它同時看這兩個輸入,決定最後要輸出多少。那在接下來的time state,你可以不要input這個condition,把這個condition的部分都補零。
link |
如果你想要做得比較好的話,你每一個time state都可以input這個condition,你的machine在第一個time state有看到這個condition之後就忘記它看過什麼,可以在每一個time state都把這個condition當作輸入,讓machine產生對應這個image的句子。
link |
那在training的時候,你就是給machineinput跟output,然後train下去就結束了。剛才舉的是image的conditional generation,那如果是input不是image,而是一個sequence的話怎麼辦呢?
link |
什麼時候input會是一個sequence?舉例來說,假設你現在要做翻譯,或者是你現在要做checkbox,你的輸入是一個句子,那一個句子比較自然的描述方法就是用一個character的sequence來描述一個句子,也就是用一個vector的sequence來描述一個句子。
link |
所以現在在這個conditional generation process裡面,在machine translation和checkbox裡面,machine要做的事情是given一個句子,產生一個對應的句子。
link |
那我們現在用translation當作例子,假設你要把機器學習翻成machine learning的話,那machine要怎麼做呢?
link |
首先我們剛才講說,我們有一個generator,這個generator只會隨機說奇奇怪怪的話,所以在前一個投影片裡面,我們把input的image變成一個vector,把這個vector接給generator,它就可以產生我們要它直接說的句子。
link |
那在machine translation或checkbox裡面也是一樣,我們只要能夠把input的這個句子描述成一個vector,接下來我們就可以把這個vector丟到generator裡面,當作generator的input,它就可以產生我們要它講的對應的句子。
link |
那怎麼把input的這個句子變成一個vector呢?那我們就需要一個RNN,我們把這個句子丟到RNN裡面,然後把這個RNN最後一個time step的output取出來,那最後一個time step的output就可以想成說,現在RNN已經把整個input的句子都讀過,所以最後一個time step的output理論上它就應該包含了input所有的information。
link |
那再把最後一個time step的output這個紅色的vector丟到generator裡面,希望它可以按照input的這個紅色的vector產生對應的句子。
link |
在文件上,前面這個把一個sequence變成一個vector的process,把一個前面這個sequence變成一個vector的network,我們叫做encoder,後半部就是decoder或者是叫做generator。那在training的時候,這個encoder和decoder,或encoder和generator,它們是jointly trained,所以encoder和generator並不是分開trained再把它接起來。
link |
你真的在trained的時候就是告訴machine說,看到機器學習,你就輸出machine learning。至於中間這個要output什麼樣紅色的vector,長什麼樣子,你不需要管它,你這個encoder和decoder是一起學的,machine自己想辦法pick out,怎麼在這個架構下input機器學習就產生machine learning。
link |
那這個架構又有另外一個名字,就是大家都知道的sequence-to-sequence learning,因為我們的input是一個sequence,那output也是一個sequence,所以這個架構又叫做sequence-to-sequence learning。
link |
好,剛才舉的例子是machine translation,那我們接下來舉的例子是chamfer的例子,但其實也沒有什麼太不一樣的地方,你就是run一個sequence-to-sequence的model,然後告訴machine說,假設使用者input是hi,你就把hi變成一個vector,把這個vector丟到decoder裡面,最後decoder也output hi。
link |
那有人會覺得說,這樣好像有一點問題,因為我們今天人和人對話的時候,我們並不是只看人的輸入,我們還會同時考慮過去對話的history。
link |
怎麼讓machine可以考慮過去對話的history呢?其實你可以透過更改你level的設計,把過去的history也當作information,也當作是你的condition,讓你的sequence-to-sequence的model可以考慮過去說過的話。
link |
舉例來說,假設有一個user說hi,那machine回答hi聽起來好像是一個很合理的答覆,但是假設在machine之前,其實他先發言了,他已經說了hello,然後人說hi,然後再回答hi,其實顯得就非常非常窄。
link |
這個讓我想到在Fifth Man Theory裡面,Leonard第一次遇到Penny的時候就是這個樣子。那怎麼辦呢?怎麼讓機器不會顯得那麼窄呢?你就要把過去的history當作input。
link |
所以今天machine在決定要講什麼的時候,它不是只看人現在的輸入派,你要告訴machine說,噢,你之前已經說過hello了,把machine之前說過的話也當作input。
link |
至於要怎麼同時處理這兩句話,你就可以自己設計你的network架構。舉例來說,在下面這篇論文裡面,他們提出了一個hierarchical的架構,先把input的兩個句子統統變成code,再用另外一個RNN把這兩個code讀進去,然後再產生decode出來的句子。
link |
假設你input已經有hello,那machine可能就會學到說,那現在offer high就是一個不合理的結果。講到這邊,我們就稍微休息十分鐘,等一下再回來。
link |
好,那我們接下來其實要講一個sequence-to-sequence learning的improvement。那你可能會有一個問題是說,在剛才的sequence-to-sequence learning的架構裡面,input要做的事情是把input的一整個sequence變成一個vector。
link |
但是你可以想像說,把input的一個sequence變成一個vector這件事情,其實很困難的。你很難把一整個sequence壓成一個vector,然後根據那個vector去做decode。你可能會把一個sequence壓成一個vector的時候,中間可能會lose掉很多資訊。
link |
所以呢,有一個conditional generation的進階版,叫dynamic conditional generation。那dynamic conditional generation怎麼回事呢?我們現在一樣把input的sequence通過一個RNN,但是我們現在不是只取最後一個time step的,比如說hidden layer的output出來,而是把每一個time step的h通通保留下來。
link |
那這邊就寫成h1到h4。那今天decoder在做decode的時候,decoder在決定他要產生哪一個詞彙的時候,他會去encoder的輸出的這個port裡面,這個encoder的輸出就想成是一個database,他會在這個database裡面去選擇他需要的資訊出來,再去做decode。
link |
舉例來說,他要寫出machine這個詞彙的時候,他可能就先去看第一個詞和第一個字,中文的input這個句的第一個字和第二個字,h1和h2。根據h1和h2,他產生一個vector c1,再根據這個c1寫出machine這個詞彙。
link |
那你可以想說,機器怎麼知道要選h1和h2呢?這個我們等一下再解釋。所以有一個intelligent的方法,讓decoder可以自己決定說,從這個input的sequence裡面,哪些部分是他現在要取出來使用的。
link |
然後有了h1以後,就寫出machine。接下來要寫第二個詞彙怎麼辦呢?machine自己決定說,他現在要看input的第三個字和第四個字,根據第三個字和第四個字,他抽出一個vector,這個vector用c2來表示,然後c2再丟到decoder裡面,讓他產生第二個詞彙,讓他產生learning這個詞彙。
link |
那接下來要講的就是,machine怎麼自己決定說,從input的sequence裡面的哪些部分去擷取出information,然後他怎麼把information也表示成一個vector呢?
link |
這個做法是這樣,其實剛才講的那個dynamic conditional generation,他又叫做attention-based model。這個attention-based model是怎麼運作的呢?我們現在以machine translation為例,現在input機器學習,機器怎麼把它翻成machine learning呢?
link |
現在input機器學習,現在每一個word我們都可以把它丟到rn裡面,用rn的output h來表示。這個h其實是rn的output,我這個圖沒有畫得很好,因為版面有限,所以我就直接把它畫在這個方塊上,讓大家知道我的意思就好。
link |
那現在有一個vector z0,這個z0是一個初始值,這個初始值你可以就handcrafted設一個初始值,或者是你可以把初始值當作參數,用learning的方式也把它認出來。
link |
接下來我們拿這個z0,我們有一個match function,這個match function做的事情就是input z0 input h,然後他會得到一個score alpha。
link |
這個score alpha的含義是什麼呢?這個score alpha的含義就是,今天如果我們要從這個database裡面取資訊出來,這個h他有多重要,他有多相關。
link |
所以可以想成說,這個z0好像是一把鑰匙,好像是一個關鍵字,好像是一個關鍵詞彙,他是一個keyword,然後他從這個database裡面去找出最相關的東西。
link |
那怎麼找出最相關的東西呢?你就找一個function match,這個match是z0跟h,然後決定他們有多相關,有多相關的這個程度,用一個數值,一個scale alpha來表示。
link |
那你可能會問說,match這個function長什麼樣子呢?這個就要問你自己,讓你可以用各種不同的方法來design這個match。
link |
最簡單的做法是,你就說,這個match這個function就是把input的h跟z做coefficient similarity,如果這樣做最簡單,你這個match完全沒有任何參數。
link |
那你也可以說,這個match其實就是一個neural network,這個neural network的input就是兩個vector h跟z,他的output就是一個scale alpha,這也可以,那你要認那個neural network的參數。
link |
或者是有人說,我可以做一些特別的設計,我認為呢,h、z和alpha中間的關係呢,是把h做transpose以後乘w再乘上z,你把h做transpose乘一個match w再乘上z,他會得到一個scale alpha。
link |
而這個w呢,是認出來的,他是認出來的,就像neural network的參數一樣,他是要被認出來一組參數,這樣也可以。那怎麼認,假設你的這個match function裡面有參數的話,怎麼認這些參數呢?
link |
其實就是你把這個match function當作是neural的一部分,你現在有一個encoder,有一個decoder,那再加上這個match function,一起joint裡面認出來,你只要給機器encoder的input,decoder的output,然後認下去,用back propagation認下去,就把match這個function裡面的參數也一併都認出來。
link |
好,總之,現在有了這個match的function以後呢,對input的每一個timestamp,我們都可以根據他的h,就算一個alpha。
link |
那接下來呢,你可以對alpha呢,做normalization,那這個normalization其實是可有可無啦,就看你的心情好啊,有的test需要我的test,不需要你自己試試看。
link |
好,那假設normalized以後,alpha的值呢,是alpha hat,那接下來根據這個alpha hat呢,我們會對h1到h4呢,做weighted sum,那就得到一個vector c0。
link |
那所以weighted sum的意思就是說,我們把這個alpha1乘h1,把alpha2乘h2加alpha3乘h3加alpha4乘h4得到c0,那就是我們的output。或者是我們舉一個比較具體的例子,假設alpha1是0.5,alpha2是0.5,alpha3,alpha4都是0,那接下來算出來的c0怎麼算呢?
link |
我們就是把0.5乘h1加0.5乘h2加上0乘h3加0乘h4得到0.5h1加0.5h2,那就是我們的c0。那這邊的意思就是,今天假設只有alpha1跟alpha2的值比較大,意思就是說我們訊今天在取information的時候,它只考慮了input sequence的第一個字跟第二個字而已。
link |
那這個alpha呢,我們又叫做attention的weight,因為它就表示了今天機器要選東西的時候,它看什麼樣的地方,代表它專注在什麼地方,代表它attent在什麼地方。所以這個alpha呢,我們又叫做attention的weight。
link |
所以這個model叫做attention的model。那我們現在有了c0以後,接下來呢,c0就當作你的decoder的input,產生第一個word machine。那同時呢,你的這個decoder的RNN啊,它除了產生word以外,它還要產生新的key,它還要產生新的關鍵字,這邊呢,寫做Z1。
link |
那這邊這個圖有一個比較不清楚的地方就是,Z1其實也是這個RNN的output這樣,它不是,這個希望大家了解我的意思啦,它不是那個RNN本身,它這個Z1寫在方塊上好像讓你覺得Z1是不知道什麼東西,它就是那個RNN的output。
link |
就RNN除了會output這個word以外,它還會output一個東西叫做Z1,然後我們會拿這個Z1去,這個動畫怪怪,好,沒關係,好,這邊沒有問題,我們會拿Z1呢,一樣跟H1到H4呢,去算出alpha的值。
link |
所以有了新的Z1以後,這個alpha的值算出來當然就不一樣了,但是每一個timestamp我們都還是會算這個alpha的值,一樣可以做normalization,一樣我們可以取出一個vectorC1。
link |
好,那因為這個Z1不一樣了,算出來的attention weight當然也不一樣,我們假設新的attention weight是在第一個時間點和第二個時間點是0,在第三和第四個時間點都是0.5,那你新得到的C1就是0.5倍的H3加上0.5倍的H4。
link |
好,那我們得到C1,那我們就把C1當作下一個時間點的輸入,然後呢,在下一個時間點呢,會輸入第二個詞彙machine,然後也會output新的key Z2。
link |
然後這個process呢,就反覆的繼續下去,直到有一天呢,machine最後取產生出來的詞彙是end of sentence或是句點,那這個整個產生句子的process就結束了。
link |
那這個attention的部分,啊,益勤說,這邊應該是這樣,這個是RNN嘛,他就input一些東西,output一些東西。
link |
那所以,今天在這個case裡面,他inputC0,然後呢,他會output下一個time step的這個distribution,我們這邊用y1來表示,但是他同時也會output另外一個vector。
link |
這個另外一個vector呢,呃,你可以,這邊其實有不同的做法,你可以說,本來RNN不是就會output,假設你今天input這個H0,他本來就會outputH1嘛,你可以說,這個H1就等於Z1,這是一個做法。
link |
另外一個做法是,你可以再多產生一個vector,這個vector就是Z1,這樣也可以。
link |
好,這樣大家聽懂我意思嗎?就本來的RNN,他是inputC跟H,他只會產生H'跟Y,那你現在再多產生一個vector,叫做Z1,然後這個Z1拿去做attention這件事。
link |
你現在多產那個vector,你現在多產多一些參數,你也可以說你H1就是Z1,欸你說,沒有。
link |
欸,他有一個,我也不瞭解說loop的意思,對不對,因為RNN其實本來就有loop,那我們可以把它展開,然後被跑遍圈下去就行了,這樣子。
link |
欸好,你請說。喔,attention的alpha怎麼產生的嗎?其實是這樣子的,這個東西啊,他就是一個function,那你其實他要怎麼產生你都可以自己設計。
link |
只要能夠input一個vectorH,input一個vectorZ,可以產生一個scalar,就行,怎麼樣都好,這樣子。
link |
因為這個alpha是不需要預先決定的,就是他隨便圈,然後他就大概可以自己做決定。
link |
對,沒錯,沒錯,所以這邊你可以說,假設match就是一個最簡單的function,比如說這兩個vector的cosine similarity,可以,你可以說H這個match這個function,他就是一個neural neural,兩個hidden layer,input兩個vector,output一個scalar,
link |
neural的參數跟其他部分一起學出來,這樣也可以,你自己在作業的時候可以explore各種不同的算法。
link |
欸你說,Z0怎麼定位比較好?其實最好的方法就是,把它當作neural參數的一部分,讓他跟著neural一起被學出來,這樣子。
link |
好,這樣大家還有問題嗎?有回答到大家的問題嗎?好齁,如果大家這部分可以接受的話,那application的部分其實就講得差不多,接下來就只是帶大家看一下各種application而已。
link |
好,那有什麼樣的application呢?現在啊,只要是你的task可以formulate成input一個sequence,output一個sequence,你就可以用我們今天教的這個dynamic conditional generation的技術,或是sequence to sequence learning的技術,來input一個sequence,產生一個sequence。
link |
什麼樣的task可以用呢?舉例來說,語音辨識,語音辨識input就是一段聲音訊號嘛,一段聲音訊號你用一個vector sequence來表示它嘛。
link |
那output,當然大家在作業裡面做的不是真正的語音辨識,你output的是full sequence,那真正的語音辨識output你可以想成就是一個character的sequence。
link |
所以語音辨識就是input一個vector sequence,output就是一個character sequence,那你就可以用sequence to sequence learning的方法,intrain一個語音辨識系統。
link |
其實怎麼做就跟剛才一模一樣,沒什麼好講的,這個只是引用一下文獻裡面的圖給大家看一下做起來是怎麼樣。
link |
因為你知道這種attention-based model,它的paper的開頭都一定要用三個動詞,沒有為什麼這樣來吵的,所以這篇paper的title就是Listen, Attend, and Spell。
link |
那就是input一句話,你用vector sequence來表示它,然後現在每次產生一個character的時候,machine就會決定說它要在這個vector sequence裡面attend在什麼位置。
link |
那在這個圖上,這個黑色就代表attention的weight,attention的值越大代表它的weight,值越黑就代表說attention的weight越大。
link |
所以在產生H這個character的時候,attend在這個地方,然後在產生O這個character的時候,attend在大概這個地方,產生W的時候,attend在這個地方,然後它也會產生space,產生空白,attend在這個地方,產生空白。
link |
那attend在這個地方產生N,然後attend在下面一點產生U,所以你會發現說這個attention的weight是不斷的由左向右的,就好像說它每次開一小段聲音訊號就產生一個character。
link |
那這個方法performance是怎麼樣呢?其實老實說這個方法performance還沒有辦法贏過傳統的deep learning的方法,我所謂的傳統方法也是用deep learning做的,不是用deep learning做的語音認識系統。
link |
傳統方法是用deep learning做的,但是因為傳統方法已經經過千錘百鍊,用DMNHA的方法用千錘百鍊,這個值是那個error rate,可能error rate是八點多,然後用這個LAS,就Listen and Expel的方法,它只能做到十點多。
link |
它還沒有辦法贏過傳統的方法,那你可能說既然沒有辦法贏為什麼還要做呢?因為潮,它的賣點就是潮,它的賣點就是哇靠這樣也行。
link |
那你也可以拿來做image的caption generation,怎麼說image的caption generation呢?在image的caption generation裡面input就是一張image,那我們需要採取一個句子,那我們剛才說一個image就可以用一個vector來表示它,但是如果你只有這樣做的話,你可能會lose很多比較detail的information。
link |
那你可以把一張圖把它切成小塊,那每一個小塊都用一個vector來表示它,那這樣你就可以用比較豐富的資訊來表示一張圖片。
link |
接下來怎麼產生一個句子呢?就你一開始有一個初始的Z0,然後用你的match function去對每一個vector算一個match的分數,假設左上角算算比較高是0.7,然後這邊是0.1,這邊0.1,其他是0,那意思就是說呢?
link |
Machine現在要產生第一個詞彙的時候,它要先看image的左上角,所以它對這些vector做weighting上,然後產生第一個詞彙,weight1。
link |
接下來呢,這個Z1會再去算一次這個attention的weight,決定說現在要attain在什麼地方,假設現在要attain在中間上面這個地方,那根據這個weight再產生一個vector,把這個vector丟到decoder裡面,產生weight2。
link |
那你只能這樣反覆繼續下去。這邊是引用一下文獻上的結果啦,它這邊的paper,它是show and attain and tell這樣子,跟你說一定要用三個動詞開頭。
link |
這個paper引用一下文獻裡面的結果,看一下在做image caption generation的時候,機器可以做到什麼樣的程度。這邊一個重點就是分析了attention的weight,在這個圖上這個亮點是說,亮點就代表attention的weight,越亮代表Machine attain在那個位置越多。
link |
那今天這個底線代表說Machine在產生這個weight的時候,它是attain在哪裡才產生這個weight。所以你會發現說Machine今天在產生這個caption的時候,它不是亂猜,猜對了。
link |
它attain在這個地方,然後它就說了freeskip,它attain在這個地方,它就說了don't,它attain在這個停止的告示牌上,它就產生了stop,然後attain在小女孩的頭上,它就產生girl,attain在這些人上,它就產生了people。
link |
attain在,你看這邊這個句子是a giraffe standing in the forest with trees,它不是attain在場景錄上的時候產生tree,它是attain在場景錄以外的地方,attain在這些綠色樹葉的時候,它才產生tree,顯然它不是隨便亂猜猜對。
link |
當然Machine也會犯錯,但是從attention上你會看到它說它犯的錯是有道理的,你可以了解它為什麼會犯錯。舉例來說,它這邊說看到a large white bird,你可能想說鳥在哪裡呢?它看到這個場景錄,它以為兩個脖子就是兩隻翅膀,所以它說它看到一隻鳥。
link |
這個圖它說a woman is holding a clock,你想說鐘在哪裡呢?鐘在那個人的衣服上。或者說這個是a man wearing a hat and a hat,這個Machine常常會這樣子,a hat and a hat,on a skateboard,它會覺得這個小提琴是一個skateboard。
link |
這個圖它說它看到一個surfboard,那它其實是把帆船的帆看成surfboard。或者這邊它說它看到一個很大的pizza,哪裡有pizza呢?它把這個小吃當作是pizza。
link |
或者它這邊說a man is talking on his cell phone,那這個人手上拿的其實不是cell phone,他拿的其實是一個類似潛艇堡的東西。雖然是機器會犯錯,但犯的錯看起來好像也是有那麼點道理。
link |
我們最要做的事情就是video的caption generation,就是讓機器能看一段video,然後它要講這一段文字。這邊也是引用一些文獻的例子,比如說Machine看到這一段video以後,它說它看到a man,這不是Machine看到,這個是人說a man and a woman ride a motorcycle。
link |
Machine產生的結果是a man and a woman talking on the road,跟人產生的沒有很像,但是為什麼Machine會看到road呢?如果你把那個attention的weight拿出來看的話,當它說road這個詞彙的時候,它attent在video的這一個frame上面。
link |
這個bar就代表說attention的weight,它attent在這個圖上,所以它說了road,那這邊確實是一個馬路的樣子。或者是說,這個圖是有一個人在煮菜,那人呢?人就是a woman is frying food,那Machine是說someone is frying a fish in a pot。
link |
你會發現說,這邊用不同顏色的attention的weight,來代表說它產生這些不同顏色的詞彙的時候,它attention的位置。你看,Machine看到這個人,所以它說someone。它看到這個圖,所以它說是在炸東西。
link |
它看到這個圖,所以它覺得是看到一個fish,它看到這個圖,所以它覺得它看到一個pot。在這個例子,我甚至覺得Machine其實做得是比人還要好。那其實在這種video caption generation上面,你是很難得到一個正確的答案的,所以你很難評估它的結果。
link |
所以其實在作業2裡面,等一下助教會講,我們是peer review這樣子,就其他同學來評估你的Machine output的結果。
link |
最後剩下的時間,我要講一個其實非常重要的部分,這些你可以在作業的時候可以派得上用場,就是一些在generate sequence的時候,你會用上的tips。
link |
首先呢,我們先來講說,我們剛才不是有看到一個例子,Machine在產生句子的時候,它做壞了,它說看到什麼a head and a head,為什麼會這樣子呢?
link |
因為我們現在用alpha來代表attention的位置,然後我們用上標來代表說attent在哪一個component上,我們用下標代表說是在產生第幾個word的時候的attention位。
link |
所以可以想像說,Machine的做法就是,我們產生一排attention的位置,然後產生word1,再對每一個frame產生attention的位置,再產生word2,再對每一個frame產生attention的位置,產生word3,接下來再產生word4。
link |
但是你會發現說有時候attention的位置,Machine認出認完以後attention的位置,是非常不平均的。
link |
舉例來說,假設它的attention位的分佈是長這個樣子,它在產生word2的時候,attent在第二張圖上,所以它說它看到woman。
link |
那在產生word4的時候,它又attent在同一張圖上,所以它又說它再看到一次woman。
link |
然後這個時候你認出來的結果可能會變成說什麼,a woman and a woman doing a woman這樣子,就會相當崩潰這樣。
link |
所以怎麼辦,一個好的attention應該是平均的,它應該要把這段video裡面的每一個frame通通都看過。
link |
所以我們會希望強迫Machine做到這件事,怎麼強迫它做到這件事呢?你可以加上一個regularization的term。
link |
Regularization我想大家都知道,我在Trend Network的時候會加regularization的term去限制你的參數的norm嘛,那這邊的regularization不是限制參數,它是限制attention的位置。
link |
舉例來說,你的regularization的term可以這樣設計,你說你希望每一個frame,所有每一個video的frame,它所有的attention的和呢,應該要都在某一個值淘上夾,淘就是一個你事先定好的參數。
link |
那你可以就把你的attention weight寫成這個樣子,submission over i是說對所有的component,對所有video的frame都做submission。
link |
然後呢,你希望說對同一個frame i,把所有timestamp t的值通通加起來,把這邊所有的值都加起來,把這邊所有的值都加起來,把這邊所有的值都加起來,把這邊所有的值都加起來。
link |
每一個frame的attention的weight通通加起來,它應該要接近淘這樣,所有每一個frame的值都應該要接近淘,這樣你就可以讓每一個frame它的attention都是在淘上下,都是比較平均的。
link |
當然這只是一個做法,你們可以design不一樣的做法就是了,只是告訴大家說有這樣的現象,你可以在attention上面加regularization,讓你的attention做得更好。
link |
好,接下來要講另外一個問題是,如果你仔細思量一下generation這件事情,你會發現說在training和testing的時候,這個generation的process是不一致的。
link |
怎麼說呢?想想看我們在training的時候,假設training的時候有一個句子,正確答案是abb。
link |
那machine怎麼training呢?machine說現在給我begin of sentence,給我condition,我要產生a。然後接下來呢,我們告訴machine說,在給定a的情況下,我們要產生b,然後給定b的情況下,我們要再產生一支b。
link |
然後我們會希望每一個timestamp的cross entropy的和要被minimize。所以發現說我們在training的時候,因為我們有正確答案,所以在每一個timestamp,machine看到的input,我們每一個timestamp不是都會給machine告訴它之前已經產生什麼東西嗎?
link |
那個之前產生什麼東西,其實是從光tube來的,從光tube裡面machine知道說前一個timestamp已經產生a,從光tube裡面machine知道前一個timestamp已經產生b。
link |
但是你想想看在generation的時候,generation的時候的process略有不同,在generation的時候,給定condition跟begin of sentence,machine產生一個distribution。從這個distribution,我們會比如說做argmax或做sample,產生一個word,比如說這時候sample出來的結果是b。
link |
因為我們不知道reference是什麼,所以在其他的timestamp,我們會告訴machine說,我們已經產生b了,但這個b是machine自己產生的對不對也不知道,所以已經產生b了。
link |
接下來根據已經產生b這件事,你要產生什麼,machine決定一個distribution,然後再去做sample,產生a,然後再把machinesample出來的結果當作下一個timestamp的input,然後產生a。
link |
所以你發現說在testing的時候,machine看到的前一個timestamp的input是來自於它自己的output,它是把自己sample出來的結果當作下一個timestamp的input,這是testing的時候,這是產生句子的時候。
link |
但在training的時候,我們用的不是前一個timestamp的output,我們用的不是machine自己的output,我們用的是正確答案。這邊可能會有兩個問題,第一個是,就這邊很明顯的一個問題,因為training和testing它們是不一致的。
link |
我們先來解釋一下這個不一致會造成什麼樣的問題,這個不一致的狀況叫做exposure bias。為什麼這個不一致是一個嚴重的問題呢?因為我們想想看,上面是training的process,在training的時候我們告訴machine說有一個正確答案叫做abb,但是machine是怎麼用這個abb這個sequence來學的呢?
link |
你仔細想想看,machine的學習方式是這樣子的。machine的學習方式是,現在給第一個beginner sentence的時候,你告訴machine說,你要判斷a跟b哪一個是對的。
link |
那它說,在一開始的時候,要知道判斷說a是對的。然後接下來告訴machine說,在已經產生a的前提之下,a跟b哪一個是對的。
link |
你讓machine學的是,在已經產生a的前提之下,b是對的。在已經產生a的前提之下,b是對的。然後接下來告訴machine說,在已經產生a跟b的前提之下,b是對的。
link |
machine在training的時候,理論上它今天假設我們世界上只有ab兩個詞彙而已,所有可能產生的sequence只有八個可能。但是machine並沒有把所有的可能性統統看過。
link |
在學的時候,它只在這整個可能產生的output所組成的tree structure上的非常一個小部分進行學習。它只學過說,今天在開頭的時候要選a,在看到a的情況下要選b,在看到ab的情況下要選b。
link |
你想想看在testing的時候會造成什麼問題。我們先講在training的時候,假設你說在一開頭它就犯了一個錯,它沒學到選a,它學到選b,那就只是一個錯而已,這輸出的sequence裡面就只有一個錯誤。
link |
這個問題在testing的時候就會很嚴重,因為在testing的時候,假設第一步犯錯,接下來就是一步錯步步錯。為什麼會一步錯步步錯?因為假設你一開始沒選到a,就有某些error導致你選了b,那在training的時候,對machine來說這件事不太重要。
link |
在training的時候,我們都是submission over每一個timestamp的cross entropy,反正你training的時候你也training不到error rate是100%,所以其實還是會有一些錯,但是假設犯的錯是在一開始的地方,接下來就很嚴重,因為會一步錯步步錯。
link |
當你選了b以後,machine就崩潰了,因為在下一個timestamp它的input是b,但它從來沒有看過說在第一個timestampinput是b的時候接下來要怎麼回應,它就會亂選。因為這種training的case,它在training的時候從來沒看過,所以它就崩潰,它就亂選,所以整個產生的句子就會壞掉。
link |
所以這個是training和testing的mismatch所造成的問題。有人就會想說,解決這個問題好像很簡單,就把training和testing弄成一致就好了,你為什麼在training的時候要拿reference當作input呢?你為什麼不直接拿machine自己的sample當作input呢?
link |
如果我們在training的時候,假設在training的時候,我們故意讓它跟testing是match的,這樣難道就不能解決training和testing不一致的問題嗎?但是你會發現說,假設我們在training的時候也是拿sample當作下一個timestamp的input,那你在train的時候會不容易train起來。
link |
怎麼說呢?我們舉這個例子,正確答案是abd,那machine一開始它很弱嘛,所以明明答案是a,但是b的機率比較高,所以sample出來是b,加一個timestamp的b丟進來,那machine很弱,它發現output的a的distribution比較高,所以正確答案是b,所以sample出來是a。
link |
machine一開始它很弱嘛,一開始參數是random的嘛,所以它都會犯很多錯。那machine會做的事情,我們到training的時候就要minimize, close, and so be,所以正確答案是a,它就會想辦法提升a的機率,正確答案是b,它就會想辦法提升b的機率。
link |
a的機率會提升,希望可以產生a,b的機率會提升,希望可以產生正確答案是b,但是你會發現說,這麼做會有一個問題,你會發現說當a和b,就第二個timestamp的b的機率很努力的提升,到b的機率壓過a,這邊第一個timestamp的a的機率很努力的提升,a的機率壓過b。
link |
a的機率一旦壓過b的時候,假設你現在sample變成a,這邊的training就白training了,對不對?因為剛才是在input是b的前提之下,machine學習應該要output b,應該要讓b的機率上升,但是training到一半突然發現,前面的人學好了,前面的人知道要generate a了,input整個變掉,那它不就output也整個變掉,它前面做的學的都白學了。
link |
那你會發現說,當你把training和testing用得一致的時候,當machine吃的是自己的sample的時候,因為machine是在一個學習的過程,所以它自己的sample會不斷地改變,它自己的sample distribution會不斷地改變,你會發現這樣的學習是比較困難的,你比較難用這個方法把它勸起來。
link |
所以怎麼辦?有一個方法叫做schedule sampling,我們現在就陷入一個糾結,因為我們陷入一個糾結就是說,在下一個time step,我們的input到底應該是正確答案還是前一個time stepmachine自己的output,我們不知道用正確答案還是machine自己的output,那怎麼辦?
link |
因為這兩個做法都有瑕疵,所以我們用硬幣的方式決定說要用哪一個當作input,有時候input正確答案,有時候input前一個time step的model。
link |
那今天在設計這個骰子的時候,在設計這個硬幣的時候,你一開始會讓machine都只吃reference,然後接下來呢,你這個機率是動態的,它本來機率比較大,然後慢慢會越來越小,本來從這邊sample的機率比較大,然後接下來會逐漸變小,變成由modelsample機率比較大。
link |
這樣的好處就是,machine一開始它還很弱的時候,它都看reference,reference是固定不會變的,它先看reference把它學好,它先學到好到一個地步以後,再看自己的output,那因為它現在已經好到一個地步了,所以可以相信說它的output可能不會很快的變化,它有時候還是會變化,但是變化是比較少出現的,這個時候training就會比較容易。
link |
這一招就叫schedule sampling,就是我們先只看reference,看reference做到好的一個地步以後,再改成看machine自己的output。
link |
在實作上,這是一個實務上的結果,在image caption generation上的文件上找來的結果,假設你總是看正確答案,那你得到的evaluation measure是這個樣子,如果你總是看machine自己的output,check不起來,結果爛掉。如果你今天用schedule sampling,那你可以得到比看正確答案和看reference output都還要好的結果。
link |
還有另外一個要跟大家提示的技術叫做bin search,bin search是什麼呢?我們剛才講說machine在產生一個sequence的時候,你可能是每一個timestamp都做sample,或者是每一個timestamp你都做argmax取機率最大。
link |
如果你每一個timestamp都取機率最大的,其實這只是一個greedy的search,對不對?你找出來的不見得是機率最大的path,什麼意思呢?
link |
假設在第一個timestamp,比如說A的機率是0.6,B的機率是0.4,如果你做argmax,那你可能就選先產生A。接下來,先產生A以後,可能A的機率是0.4,B的機率是0.6,選了argmax,你產生B。
link |
接下來,A的機率是0.4,B的機率是0.6,選了argmax,你產生B,你就輸出A、B、B。但有一個可能是,雖然在第一個timestamp,B的機率是比較小,但是接下來,假設第一個timestamp你選B,第二個timestamp也選B,第三個timestamp也選B,雖然一開始的機率比較小,但最後相乘以後,綠色的線頭所指的這個path,它的機率的分數可能還是比紅色這個線頭的分數高的。
link |
你一開始不是做greedy search,你一開始做一點犧牲,最後可能可以找到更好的path。但是如果我們每一個timestamp都做sample的話,其實你就只是greedy search,每一個timestamp都取max,你只是greedy search。所以怎麼辦?要窮取這個tree上面所有可能的path又是不practical的,所以我們會有一個概念叫做bin search。
link |
那bin search怎麼做呢?bin search的做法是這個樣子。那bin search在training的時候不用考慮它,這個是在testing的時候,你為了選最好的句子的時候,你會applybin search這個概念。所以bin search這個概念是這樣,我們今天就直接用舉例的方式來跟大家說明。
link |
第一個timestamp,你可以走A也可以走B,那我們通常會定一個bin的size,bin的size就是說在這個樹上面,在這個所有可能可以展開的path上面,保留幾條最好的路徑。我們假設bin的size是2,那就代表我們保留兩條最好的路徑。
link |
所以在第一個timestamp,有兩條路徑可以選擇,可以選A可以選B,那兩條都保留下來。接下來呢,你選A以後你可以選AB,選B以後你可以選AB,所以有四條路徑。
link |
你可以把這四條路徑的分數一一算出來,選最大的兩個保留下來,所以你保留了AB跟BB。接下來呢,有了AB以後後面可以接A,可以接B,有了BB以後後面可以接A,可以接B,所以總共有四條path,你四條path的分數都再去check一下,保留兩條最好的path。
link |
如果你用這個方法的話,你就可以得到可能是比Greedy Search還要更好的結果,這個方法就是放在這邊給大家參考。
link |
下一頁這個圖呢,是一個我覺得畫得很好的圖,這不是我自己畫的,但畫得很好,所以我還是把它留在這邊給大家參考。你就不要仔細講這個圖,你自己看這個圖就會知道說,實際上Big Search這個algorithm在sequence generation的時候是怎麼implement的。
link |
好,那接下來我們再講下一個問題。下一個問題是這樣,有人可能會問說,我們為什麼一定要取sample?
link |
為什麼我們要取了sample以後,把sample的結果當作下一個timestamp的input,而不是直接把前一個timestamp的output丟進來?或是我們為什麼不能直接只靠這個hidden layer給我們的information,直接當作下一個timestamp的input?
link |
為什麼一定要把sample以後的結果再丟進來呢?為什麼?這邊就試著跟大家解釋,用比較直觀的方法來跟大家解釋為什麼要這樣做。
link |
好,那你永遠可以當作一個final題目來驗證這個流言。那怎麼解釋呢?假設你現在training data裡面,大家的句子開頭都是in,所以大家開頭的句子都是ur,那in顯然是一個合理的句子,ur顯然是一個合理的句子,當然ir、um是不合理的句子。
link |
好,那今天因為愛常常出現在句首,u常常出現在句首,所以其實今天當Machine要generate一個詞彙的第一個詞彙的時候,其實愛跟u的機率恐怕是差不多的,恐怕是非常的接近。
link |
但是Machine會做一個sample,獲取argmax,決定現在到底要用i還是用u,它就決定一個,決定一個就是說我現在要選擇用u,然後u就當作下一個timestamp的input。
link |
那下一個timestamp如果input u的話,Machine就會非常明確的知道說input u,接下來我要接r而不是接n,所以r就會遠比n有更高的分數。
link |
但是假設你沒有用sample或argmax的方式,而是你說我現在就把第一個timestamp的distribution丟到下一個timestamp,我直接把distribution當作下一個timestamp的input,因為在這個distribution裡面,愛跟u的分數其實是非常接近的。
link |
那對Machine來說,它無法判斷說你一開始到底想要產生i還是u,你的input有i也有u,那training以後的結果就會變成說,它產生n跟r的機率可能是差不多的。
link |
那你當然說我最後,你最後的output當然不是一個distribution,你都會做sample,但你有可能在第一個timestampsample出u,在第二個timestamp就sample出r,因為在每一個timestamp你的distribution,這個u跟r的機率很接近,n跟r的機率很接近。
link |
如果你這邊你沒有把sample的結果接進來,而是直接給它distribution的話,它在下一個timestamp它無法決定說你今天已經產生的部分是什麼,它沒有辦法產生正確的結果,其實很容易做了就會壞掉。
link |
好,那最後一個想跟大家分享的問題是,我們今天generate的是一個sequence,sequence是由component,sequence是一個完整的object,它是由很多component所組成的。
link |
我們在train的時候,我們其實考慮的是component level的loss,但是實際上我們在evaluate一個句子的好壞的時候,你其實是看整個句子的語意文法對不對,而不是只單純看一個一個詞彙對不對。
link |
但在train的時候,我們只看一個一個詞彙對不對,你記得嗎?我們train的時候是minimize每一個詞彙的cross-entropy的總和,所以如果今天錯一個字就是有一個loss,錯兩個字就是有兩個loss。
link |
所以你會發現說,今天你在train的時候,其實一開始loss是掉得非常快的,比如一開始我們train很笨,他看到這個video,他就說a cat is 呃呃呃呃這樣子,然後接下來他loss掉得很快,他很快就直接知道說不要產生呃呃呃呃呃,還要產生比如說the dog is fat.
link |
然後接下來你就會發現說你的loss掉得變得非常慢了,因為假設正確答案是the dog is running fast,the dog is fat,他只差了一個word而已,這樣loss其實沒有很大,但是當然從人的角度來看,這個句子其實也是非常非常不合理的,對人來說他是一個很糟的句子。
link |
但是在learning的時候,他不是一個loss很大的case,因為我們evaluate的時候,我們是一個一個component去evaluate,但實際上人在看machine的performance的時候,我們看的是一整個句子。
link |
所以怎麼辦?如果你想要真的解決這個問題的話,也許你應該換一個loss,你可能會想要換一個loss,你的loss是一個function r,這個loss這個function r呢,它是會比較machine generate出來的sequence y 跟正確答案y hat的差異。
link |
它不是minimize cross entropy,你定義一個新的function,它去evaluate y 和y hat的差別,但這個要怎麼定就看你自己啦,比如說如果我們evaluate的時候,我們都用blue scope,那也許你這個r呢,你就可以定義成blue scope。
link |
等一下助教會講blue scope是什麼,反正就是input兩個sequence,它會比較兩個sequence的好壞,它會比較兩個sequence有多接近就是了,但它不是一個詞彙的比較,它是在object的level上做比較,當然你可以想想看它有沒有什麼其他的更好的evaluation的方法。
link |
但現在你馬上就遇到一個問題,r它可能是不能微分的,這個c cross entropy是可以微分的,這個r如果是怪怪的東西,其實你是不能微分的,你不能微分,你就沒有辦法train network,所以怎麼辦?
link |
你就記住以下的話,現在如果你發現你有一個objective function不能微分,把它當作reinforcement learning運作下去就行了。你懂嗎?你把你的network當成是reinforcement learning裡面的agent,把你要optimize的objective function,假設它不能微分也無妨,就當作是reward,當作是你那個agent去玩電玩的時候得到的分數,然後train那個agent,讓他去maximize reward。
link |
你就在maximize那個objective function,就結束了,好嗎?所以,假設你今天定了一個evaluation的measure,定了一個objective function,它是不能微分的,怎麼辦?當作reinforcement learning的partner運作。
link |
reinforcement learning大家都知道,路邊sample一個人都知道,他做的做法就是這樣,我真的覺得真的是路邊sample一個人都知道,就是machine開一個遊戲的畫面,然後他就決定他要做什麼事情,他決定做什麼事情,他會得到reward,會看到新的畫面,再決定做什麼事情,再得到新的reward,machine要做的事情就是去maximize他的reward。
link |
在sequence generation裡面,雖然我今天沒有細講怎麼做,但你可以參考一下這篇論文,看看別人是怎麼做的,把這個問題formulate成一個reinforcement learning的partner,運作下去。
link |
現在你的input,這可能包括你的condition,你在三個time state generate的word,就是observation,就是那個遊戲的畫面,好嗎?你可以產生的word,就是你可以產生的action。在原來的Atari遊戲裡面,你可能只能做上下左右跟開火。
link |
在generate sequence的時候,你的action的space很大,你可以採取的action就是所有的word,世界上有十萬個word,代表你有十萬個不同的action,可以去做抉擇。
link |
machine就是要決定他要採取哪一個action,假如他決定action B,然後就會看到新的畫面,然後再決定他要做什麼,然後再看到新的畫面。
link |
這個就是一個reinforcement learning的partner。在每一個time state,machine產生一個word的時候,他會得到一個reward。假設你現在要做sequence level的evaluation,machine在產生這個sequence的過程中,他產生的每一個word,得到的reward都是0。
link |
他產生第一個word,得到的reward都是0。產生第二個word,得到的reward都是0。直到他產生最後一個word的時候,你把你定義的objective function拿出來,你怎麼定都行,看你高興。
link |
你就可以evaluate說,現在已經產生的整個sequence BAA跟正確的答案比起來,他們差有多少。
link |
這個不能違規也沒有關係,當作reinforcement learning的partner,硬券下去,就結束了。今天要講的大概就是這個樣子,接下來這就是conclusion。
link |
我們就稍微暫停幾分鐘,讓助教進來觀察。