back to index
Structured Learning 1: Introduction
link |
好,什麼是Structured Learning呢?
link |
到目前為止,我們考慮的問題,它的Input其實都是一個Vector,Output都是另外一個Vector。
link |
不管我們是在做SVM,還是在做Deep Learning的時候,你們想過我們的Input跟Output都只是Vector而已。
link |
但是實際上我們真正要面對的問題,往往比這個更困難。
link |
我們可能Output是一個,我們可能需要Input,或者是Output是一個Sequence。
link |
我們可能會希望Output是一個List,我們可能希望Output是一個Tree,我們可能希望Output是一個Bounding Box等等。
link |
比如說像你在這個Final裡面,在那個Recommendation的Final裡面,你可能會希望你的Output直接就是一個List,而不是一個一個Element當作Output。
link |
我們就是要找一個Function,它的Input就是我們要的Object,比如說它是個Tree之類的,它的Output就是另外一種Object。
link |
比如說如果我們目前學過的Deep Learning的Neural Network架構,你可能不知道說,我要怎麼兜一個Network,它的Input才會是一個Tree Structure,Output才會是另外一個Tree Structure。
link |
那像這種Structured Learning的Task,它有非常多的應用,其實它的應用比比皆是。
link |
我知道一般Machine Learning的課程是不會講Structured Learning的,但其實Structured Learning它用的Application非常多,所以如果你不知道Structured Learning的話,其實很多時候你會非常的卡。
link |
比如說語音辨識,如果你只知道一般的Feed Forward Network,你根本無法想像語音辨識是怎麼做的,因為語音辨識它是Input一個Sequence,Output另外一個Sequence。
link |
或者是你根本無法想像Translation是怎麼做的,Translation是Input一個Sequence,Output另外一個Sequence。
link |
比如你要中翻英,中文是一個Sequence,英文是另外一個Sequence。
link |
或者是你要做Syntactic的Parsing,做文法剖析,就是Input一個Sentence,它是一個Sequence,Output是一個文法剖析的Tree Structure。
link |
或者你要做Object Detection,那你的Input是一張Image,你的Output是那個Object的位置,你會把那個Object用一個Bounding Box把它框出來,那個Bounding Box是你的Output,它也是一個Object。
link |
或者是你要做Summary,你的Input是一個Document,你的Output是你Summarize之後的結果,那你的Input跟Output都是Sequence。
link |
或者你要做Retrieval,你的Input是搜尋的關鍵詞,你的Output是搜尋的結果,搜尋的結果是一個List,它也是一個有Structure的東西。
link |
那Structure Learning怎麼做呢?雖然這個Structure Learning聽起來好像很困難,但實際上它有一個Unified的Framework。
link |
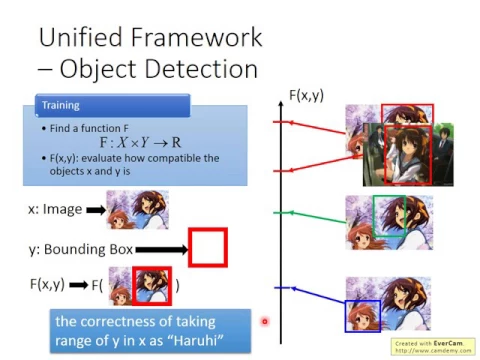
怎麼做呢?在Training的時候,我們就是找一個Function,這個Function我們這邊寫做大寫的F。
link |
這個大寫的F,它的Input跟Output,它的Input是X跟Y。我們之前是找一個小寫的Function,它的Input是X跟Output跟Y,現在不一樣,我們找一個大寫的F。
link |
它的Input就是X跟Y,它的Output就是一個Real Number。
link |
這個大寫的F它做的事情就是它想要衡量說,當我今天的Input是X跟Y的時候,它們兩個都是Structure的Object,這個X跟Y它們有多匹配。
link |
越匹配的話,大寫F它Output的值就越大。
link |
那Testing的時候,假設我們找出這個大寫的F,那Testing的時候我們要怎麼做呢?
link |
我們Testing的時候就是給一個新的X,我們去窮取所有可能的Y。
link |
窮取所有可能的Y,一一帶進大寫的F這個Function,看看哪一個Y它可以讓X的值最大。
link |
假設可以讓F的值最大,可以讓F的值最大的那個Y,我們叫做Y Delta,它就是最後你的辨識的結果,就是你的Model的Output。
link |
那你會說原來小寫的F呢,我們原來想要做的事情是找一個小寫的F,Input X Output Y。
link |
那這個小寫的F,Input X Output Y,你就可以把它想成呢,這個小寫的F其實就是ARG Max,窮取所有的Y,F of XY,這個東西就是小寫的F。
link |
這樣講你可能覺得有點抽象,所以我們來舉個實際的例子。
link |
假設我們現在要做的Task是,我們要給一張Image,然後現在Machine的任務呢,是要找出Image裡面我們要它找的Object。
link |
舉例來說,所以現在在我們的Task裡面,Input是一張Image,Output是一個Bounding Box。
link |
舉例來說,現在假設我們的Task呢,是要做一個這個良工春日的Detector,那Input呢是一張Image。
link |
那Output的Bounding Box就是良工春日在的位置。
link |
OK,不知道的人講一下,就是有綁黃絲帶的這個是良工春日。
link |
那這個東西有很多實際上,你可能問說偵測良工春日有什麼用,沒有什麼用這樣子。
link |
但是它有其他的作用,比如說偵測人臉,或者是無人駕駛要偵測有沒有車子等等。
link |
我知道說現在在做Bounding Box的Extraction,你可以有別的方法,你可以用Deep Learning的方法來做。
link |
有一個Language叫做Hybrid CNN,它可以直接OutputBounding Box。
link |
那事實上呢,Deep Learning跟Structured Learning是有關係的。
link |
這個我還沒有聽其他太多人講過,那這個是我個人的想法。
link |
我認為Gan其實就是,它跟Structured Learning是非常有關係的。
link |
Gan就是在實作我們剛才講的那個Framework的一個方法,這個我們講完Structured Learning以後再講。
link |
所以Deep Learning跟Structured Learning它們並不是Independent的,它們其實是,它們就即將要被Merge在一起。
link |
但是我還是想要舉Bounding Box的例子,因為我只是想要秀良工春日的圖而已。
link |
好,那如果是Object Detection的話,那是怎麼做的呢?
link |
那你的Image,你的Input的X就是一張Image,Y就是Bounding Box。
link |
那F of XY就是說,假設這張Image配上這個紅色的Bounding Box,這個位置的Bounding Box,它們有多匹配。
link |
如果是在Object Detection的例子的話,就是它有多正確,你有沒有真的把良工春日框出來。
link |
所以呢,你會期待說,你的Model可以做到的事情,你的這個大寫的F它可以做到的事情是這樣子。
link |
給這張圖,如果框在這邊,它的分數就很高,因為框得很對。
link |
框在這邊,綠色的框框有一點不對,框在19流頭上就很不對。
link |
那如果是另外一張圖,框在這個紅色框框,很對。
link |
框在這個地方,後面這個人,我也看不清楚他到底是誰,原來也是19流,也是不對。
link |
然後框在這個地方,這個人到底是誰呢?
link |
我現在看了,這個是谷泉,然後不是阿徐,左邊這個才是阿徐。
link |
接下來Testing的時候,給一張X,這個X是從來沒有看過的圖。
link |
你窮取所有可能的Bounding Box,這個Bounding Box可以畫在這個地方,可以畫在這個地方,可以畫在這個地方,可以畫在這個地方,可以畫在各個不同可能的地方。
link |
然後看說,哪一個Bounding Box得到的分數最高,可能紅色的得到10分,綠色的得到2分,藍色的得到3分,黃色的得到-1分等等。
link |
然後紅色的分數最高,所以紅色的就是你的Model的Output,紅色就是你的Model的Output。
link |
那在別的Task裡面呢,其實也是差不多的,假設我們今天要做Summarization,Summarization的Task就是Input一個Document,很長的,它有很多句子。
link |
那Output是一個Summary,你的Summary可以就只是從這個Document裡面取幾個句子出來,取一個Subset出來。
link |
那我們Training的時候呢,就是你的這個F of X啊,它的這個Document跟正確的Summary配成一對的時候,F的值就很大。
link |
如果Document跟不正確的Summary配成一對的時候,F的值就很小。
link |
那對,每一個Training Data都這麼做。
link |
Testing的時候,你就重舉所有可能的Summary,看哪一個Summary可以讓你的F最大,它就是一個正確的,它就是你的Model的Output。
link |
或者是Retrieval的時候呢,也是一樣,Retrieval的Task,Input是一個查詢詞,Output是一個搜尋的結果,是一個Webpage的List。
link |
那Training的時候,我們要一些Training Data知道說,Input這個Query的時候,Output哪一個List才是Perfect的。
link |
那Input歐巴馬的時候,Output這個List是Perfect,所以它們的分數最高,Output這個List是不對的,所以它的分數要比較低。
link |
那InputTrump的時候,Output這個List是對的,所以分數比較高,Output這個List是不對的,所以它的分數比較低,等等。
link |
那做搜尋的時候呢,比如說有人輸入一個良工春日,就重舉所有可能的List,看看哪一個List的分數最高。
link |
你可能覺得說,什麼重舉所有的List,聽起來多麼的荒謬啊。
link |
這個都是可以做的,這個都是可以做的。
link |
好,然後你只需要想一個好的演算法去解這個問題,那你就找出看哪一個List可以讓分數最高,它就是F of X Y。
link |
好,這個Unify的Framework,或許你聽了覺得很陌生,覺得很怪,第一次聽到的人都會覺得,這搞什麼東西,怎麼突然出現一個F這樣。
link |
那我換一個說法,看你有沒有比較接受。
link |
我這個說法是這樣,我們在Training的時候呢,我們是要Estimate X跟Y的Join probability,我要Estimate X跟Y一起出現的機率。
link |
那這個機率其實也是一個Function,這個機率的Input就是一個X跟一個Y,Output就是一個介於0到1之間的。
link |
那我在做Testing的時候,就是給我一個Object X,我去計算P of Y given X的機率,那哪一個Y的機率最高,它當然就是我的答案。
link |
那P of Y given X可以寫成P of X Y除以P of X,那P of X對你最後找出來的Y沒有影響,所以你真正做的事情就是看看哪一個Y跟哪一個X的Join probability最高,那個Y就是最後你的Output,就是你最後Model的Output。
link |
而這個Training就是這個Training,這個Inference就是這個Inference。我們剛才講的F of X Y,你或許覺得說Evaluate X跟Y有多相容,這個到底是在講什麼,其實不太懂。
link |
那如果我把它換成,我想要Evaluate X跟Y的Join probability,X跟Y一起出現的機率,然後在Testing的時候,根據這個機率,我要找最有可能的Y,這樣你會不會覺得比較能夠接受一點呢?
link |
我們來做一下民意調查,你比較喜歡直接用F of X Y你覺得比較容易理解的東西來評測嗎?沒有,有一些,請手放下。
link |
如果你覺得說這個機率P of X Y,你覺得你比較容易理解的東西來評測嗎?手放下,感覺稍微多一點。
link |
好,那其實這兩個東西都是可以的。如果你今天在讀的是這種Graphical Model的文獻的話,而Graphical Model的文獻你自己看可能都是看得一頭霧水啦,其實Graphical Model就是Structure Learning的其中一種。
link |
OK,所以如果你等一下你把我課之後的Structure Learning的部分聽完,你可以Map到Graphical Model的部分,你會發現我講的其實就是,其實Graphical Model就是一種Structure Learning,只是在Graphical Model裡面的時候,我們把F of X Y換成機率,但其實講的是一樣的事情。
link |
講的是一樣的事情,那些什麼Belief Network啊,Mark of Random Field啊,他們講的其實是一樣的事情,他們也都是去找一個Evaluation Function,只是他們Evaluation Function是個機率。
link |
那用機率有什麼壞處呢?有一些壞處啊,我個人其實比較喜歡用F of X Y勝過機率,因為用機率一個壞處就是,有時候東西說機率很怪,你說我們做搜尋,那X是查詢詞,然後Y是一個搜尋的結果,然後要衡量這個搜尋結果跟查詢詞,共同出現的機率,我覺得很怪,有時候不太能夠接受。
link |
然後再來就是,機率會有一個Constraint,就是Summation over 1,對,所有的X Y Summation over 1,但你現在是一個有Structure的東西,X Y都是一個很大的Space,你怎麼,要做這個Summation很難,你會搬著石頭砸自己的腳這樣子。
link |
就是你把機率的東西引進來,然後要Normalize,要把它變成一個機率,然後結果你花大部分的時間在想辦法把它做Normalization,那何不不要做Normalization呢?
link |
那做機率有一個好處,就是它是Meaningful的,機率你比較容易了解,想像它是什麼樣的東西。那其實還有另外一個東西叫做Energy Model,你可能有聽過Energy Model。
link |
Energy Model,這是那個Yann Larkin提出來的,我在下面有附一下Yann Larkin的Energy Model的一些說明給大家參考。其實Energy Model講的也是Structure Learning,那在差不多的時間點,世界上有很多不同的人都提出了類似的想法,提出了類似的Framework,他們合起來就是這邊這個Unified的Structure Learning的Framework。
link |
它們兩個其實是一樣的東西,什麼Graphical Model,Structure Learning,Structure SVM,Energy Based Model,它們的Framework都是一樣,就好像說同樣的東西,在獵人裡面叫做獵人,在海賊王裡面叫做霸氣,在Toy裡面叫做查克拉,它們其實是一樣的東西。
link |
好,那這個Framework聽起來好像很厲害,那其實要做這個Framework,你要解三個問題,我知道快下課了,所以我就很快的帶過這三個問題。
link |
第一個問題是F of X Y長什麼樣?你很難想像F of X Y到底應該長什麼樣,現在input是image,input是image加上一個bumping box,這F of X Y應該長什麼樣?input是一個keyword跟一個list,這F of X Y應該長什麼樣?
link |
再來就是荒唐的inference的問題,怎麼解argmax這個問題,這個Y它可是很大的,比如說你要做object detection,就窮取所狠的bumping box,這件事情做得到嗎?
link |
第三個問題是training,training的時候的principle就是我們希望正確的X跟Y的pair可以大過其他的,正確的XY的pair大過其他的,這個training是可以完成的,只要你解出這三個問題,你就可以做structured learning的發問,要獲得三張神之卡就可以成為新一代的法老王一樣。
link |
地震警報,現在有地震嗎?沒有喔!其實我覺得game可能就是解這三個問題的solution,所以你可能看不出來game跟這個有什麼關係,但他們是有關係的,我覺得game好像就是看到解這三個問題的曙光這樣子。
link |
其實這三個問題,你在別的地方是有聽過的,如果你有修過數位語音處理的時候,李明山老師在講HMM的時候,他有說HMM有三個問題,其實這三個問題就是general的structured learning的三個問題,他不是只用在HMM上,他可以用在任何structured learning的發問上。
link |
事實上這個東西,我們也可以把它跟DNNlink在一起,我們之前講的Feed Forward Network,你好像停著覺得說跟現在講的structured learning沒有關係,是有關係的,之前講的東西就是structured learning的一個special case,怎麼說呢?我們現在說我要做手寫數字辨識,input一個image,把它分成十類。
link |
那我的這個F長什麼樣子呢?我的F長這樣,我先把X丟進一個DNN,得到一個vector叫做N of X,接下來我在input Y,這個Y是一個vector,做手寫數字辨識的時候,Y是一個十維的vector,它只有一維是1,其他都是0,它分別代表十個不同的數字,然後把這個Y跟N of X算cross entropy。
link |
Negative的cross entropy就是F of XY,那你的整個F就是input X跟Y,output就是這一個字。
link |
然後接下來在testing的時候,在inference的時候,你就說我現在要做手寫數字辨識,我窮取十個所有可能的辨識結果,雖然說窮取所有可能的辨識結果,其實才十個,十個可能的辨識結果,每一個都帶進去這個function裡面,看哪一個辨識結果是可以讓F of XY最大的,它就是我的辨識結果。
link |
哪一個辨識結果可以讓F of XY最大的,其實如果你是用cross entropy來定義這兩個vector之間的差距的話,你就看說現在哪一個digit,它對應的dimension,它的值最大,它就是那個辨識的結果。
link |
所以這件事情跟我們之前在train neural network用cross entropy做loss function的時候做的事情其實是一模一樣,所以我們之前講的東西是structure learning的一個special case。
link |
你可以定出,其實事實上我們一直講說我們做的是F of括號X output Y,實際上那個問題也可以想成我們找了一個大F,input XY,output就是一個number,evaluate XY,有多compact,有多相容。
link |
那這個argmax這個問題,因為在classification裡面,我們的Y太少了,才看有幾個class就有幾個Y,這是可以窮取的,那找max其實就是窮取的那個行為,它是可以輕易做到。