back to index
Structured Learning 4: Sequence Labeling
link |
各位同學大家好,我們來上課吧。上上次我們講了Structured Learning的概念,然後說其實Learning都可以看作是只有兩個步驟,然後只要你能夠回答三個問題,你就可以解決所有Learning的Task。
link |
上一次我們講了Structure的SVM,是Structure Learning裡面的一種方法。今天我們要來study一個Structure Learning的problem,這個Structure Learning的problem是Sequence Labeling的問題。
link |
Sequence Labeling的問題是什麼呢?Sequence Labeling的問題是說,我現在Machine Learning要找的function,它的input是一個sequence,那它的output也是一個sequence,但是這兩個sequence的長度,我們先假設它是一樣的。
link |
也就是說我今天的input,我可以把它寫成一個vector sequence X,它的input就是X1,X2到X大L,那它的output希望是Y1,Y2,Y3一直到Y大L。
link |
那你可能會想說,這個問題有什麼難的呢?大家在作業2,你已經實作完了RNN,那其實這個問題,你其實是可以用RNN解的,對不對?所以其實你如果作業2做得出來的話,這個問題對你來說應該不是一個特別困難的問題。
link |
因為我們在作業2都已經知道說,input X是一串acoustic sequence,然後output是每一個acoustic sequence所對應的form,那大家已經會做這件事情了。
link |
那我們今天要講的方法,跟RNN有什麼不同呢?這個我們等一下會在最後再來告訴大家。我把前面的燈關一下好了,我找一下,在這裡嗎?在另外一邊。
link |
那我們今天就用POS tagging來當作講解的例子。POS tagging是什麼呢?POS tagging這個任務,是我們要去標記一個句子中每一個word它的詞性,那詞性有很多很多的類別。
link |
比如說光是名詞下面就可以分成proper noun,專有名詞,或者是common noun,一般的名詞,或者是動詞可以分成一般的動詞跟助動詞等等。
link |
那我現在要做的事情就是,今天input一個句子,比如說john sold a soul,那這個系統要自動標記說,第一個john它是一個proper noun,第二個word這個soul它是一個動詞,是一個貫詞,第二個soul它是一個名詞等等。
link |
那這個東西其實是natural language processing裡面非常basic但是重要的一個task,它其實是很多文字understanding方法的基石,比如說你要先有POS tagging以後,你可能才比較方便做文法的分析,或者是你要有POS tagging以後,你才比較容易做word sense的disambiguity。
link |
因為你可以假設說如果同一個word但是它今天的詞性不一樣的話,它可能就代表了不同的意思,或者是它可以用來抽keyword,因為一般keyword都是名詞,所以如果你能夠自動detect說哪些詞彙是名詞的話,你可以先filter掉一些不可能的詞彙等等。
link |
所以POS tagging有很多的應用。那你可不可以想說這個問題搞不好沒有很難,因為如果我今天找到一個dictionary,那dictionary會告訴我們說每一個詞彙它的詞性是什麼,那我們就自動解決這個POS tagging的問題了嗎?
link |
我只要寫一個hashtable,這個hashtable告訴我說的這個字,看到input的這個字,output就是另外一個字,那我不就已經解決這個POS tagging的問題了嗎?
link |
但是困難的點就是這個POS tagging的問題光靠查表是不夠的,你其實是要知道這一整個sequence的information,你才有可能完全正確的把每一個word的tagging,把每一個word詞彙的詞性把它找出來。
link |
比如說像受這個詞彙,它受這個詞可能有不止一個詞性,第一個受它是看到是一個動詞,第二個受不是看到,並不是就看一個看,第二個受其實是句子的意思,所以它是一個名詞。
link |
那我們怎麼知道一個詞彙它是動詞還是它的詞性是什麼呢?那受這個詞彙,它比較有可能是一個動詞,所以大多數的情況你可以猜它是一個動詞而不是一個名詞。
link |
但是因為我們今天又知道說一個慣詞的,它後面比較有可能是接名詞而不太可能是接動詞,所以如果今天這個受它前面出現的是慣詞的的話,那這個受它應該是名詞而不是動詞。
link |
所以如果我們要真的把PoS tagging做好的話,我們必須要考慮整個句子的information,我們才有可能真的把PoS tagging做好。
link |
不過因為現在我們等一下要講的這些machine learning的技術,這些structure learning的技術,它們都是可以考慮整個sequence,所以現在PoS tagging這個problem其實已經做得很成功了。
link |
在英文上,PoS tagging這個problem幾乎可以算是一個已經被解決的問題了。那我今天要介紹的技術呢,就先講一下,可能是大家都耳熟能詳的Hidden Mark of Model,HMM。
link |
我這邊要講的這個HMM,等一下你會發現它跟數位語音處理這門課上講的HMM非常的不一樣,等一下告訴你為什麼它不一樣。
link |
第三個呢,我們複習一下之前講過的structure perceptron和structure SVM,然後講一下如果我們把它用在sequence theory的花紋上的話,那是怎麼用的。最後呢,講一下怎麼把這些technique都變成deep的。
link |
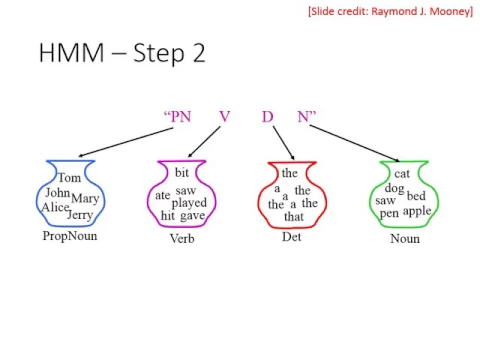
那我們就先從這個HMM開始。HMM的假設是這樣子,如果我們人要怎麼產生一個句子呢?我們人是用以下這兩個步驟產生句子的。
link |
首先當你想要說一句話的時候,你第一件在心裡做的事情呢,是先產生一個PoS的sequence。那這個PoS的sequence呢,是根據你腦中一個內建的grammar所產生的。
link |
你的大腦中有一個你對人類語言的grammar的理解,然後你根據這個grammar去產生一個合乎文法的PoS的sequence,那這個東西是你想在心裡的。
link |
然後接下來第二個步驟呢,是我們要根據每一個tag去找一個符合這個tag的詞彙,就是這邊有一個proper noun,你就找一個proper noun把它填出來。
link |
一個動詞,你就找一個動詞填出來。一個冠詞,你就找一個冠詞填上去。一個名詞,你就找一個名詞填上去。就把這個PoS的sequence變成一個word的sequence,然後你就把這個word的sequence說出來。
link |
那這個詞性跟文字之間的關係呢,你可以從一個詞典裡面去得到。那不管你同不同意這個假設,這個都不重要,這就是一個假設。
link |
H&M呢,就是假設說當你想要說一句話的時候,你是用這兩個步驟說的。先產生一個PoS的sequence,然後看說,given一個PoS的tag,given一個詞性,那你會填入哪一個詞彙。
link |
所以H&M呢,它說我們在講一個句子的時候有兩個步驟。第一個步驟是根據我們腦中所有的文法,建構一個PoS的sequence。那你腦中有的文法長什麼樣子呢?
link |
那你腦中有的文法呢,H&M假設它是一個markov chain,也就是說,當你填一個詞彙,舉例來說,這邊就是,這個看起來很複雜,連的非常的複雜,這是一個markov chain。
link |
你要開始說一句話的時候,放在據手的,在這個PoS tagging的sequence,它的據手的詞性有0.5%的機率是一個慣詞,0.4%的機率呢,不是0.4,50%的機率是一個慣詞,40%的機率是一個專用名詞,10%的機率是一個動詞。
link |
然後你就random做一下sample,假設今天你sample到說,你要講一個專有名詞,然後你就從專有名詞開始,如果你今天講了一個專有名詞以後,下一個你會用的詞性是什麼?
link |
那你有10%的機率專有名詞後面接慣詞,那這個其實是不太可能的。然後有80%的機率是專有名詞後面接動詞,10%的機率是這個句子就結束了。
link |
那你就再做一下sample,那假設sample出了,下一個詞彙要講的是動詞,那你就再繼續下去,動詞之後有可能就結束了,有可能再講一個專有名詞,有可能再講一個動詞。
link |
這個合起來不知道是不是1,我們要仔細的去check一下。
link |
綠色不是1,假設我從紫色出去,到這裡,然後這個出去他有0.5,他有0.05,那這個是1,綠色呢?
link |
哇,綠色不是1,等一下發現的時候可以來跟我講一下,每一個這個詞性後面接的,哪一個可能合要是1啊?
link |
我可能接一個名詞,然後名詞後面呢?我可能就結束了。那這個就是一個markup chain,所以你就可以算出根據這個process,假設你要產生一個句子,
link |
假設這個詞性是專有名詞、動詞、冠詞跟名詞的話,那他的機率就是這一路上我們選到這個詞性的機率的相乘的結果。
link |
產生這個詞性的sequence,接下來就要進入第二步驟。第二步驟是說,根據我手上的一個詞點,給我一個詞性,然後我看這個詞性應該填入哪一個詞彙。
link |
現在根據詞點,我們已經準備好說,有一大堆詞彙是屬於專有名詞,一大堆詞彙屬於動詞,一大堆詞彙屬於冠詞,一大堆詞彙屬於名詞。所以當我今天要選一個專有名詞的時候,
link |
我通通從專有名詞的這個集合裡面去sample出一個詞彙出來。這邊其實有五個詞彙,抽到中文的機率是五分之一,所以就是0.2。你可以仔細check看看,我等一下算的有沒有算錯。
link |
從動詞這個集合裡面,如果sample一個詞彙出來,sample出sole的機率是0.17,從冠詞這個集合裡面sample出一個詞彙出來,sample出the的機率是0.63,然後從名詞的集合裡面sample出sole的機率是0.17。
link |
所以今天如果given一個sequence,我今天最後說出來的,given一個POS tagging的sequence,我最後說出來的句子是中sole的機率,就是這四個機率把它乘起來。
link |
所以根據H&M它做的事情就是,它可以描述說,今天當有人說點什麼吧,然後你就說一句話,然後你用這個POS tagging的sequence說出這個句子的機率。
link |
H&M就是在描述這一件事情。所以根據H&M的描述,這個X跟Y,這個word sequence跟這個POS tagging的sequence,它一起出現的機率是我們產生這個POS tagging的sequence的機率P of Y乘上這個sequence產生這個sequence的機率P of X given Y。
link |
它們的機率都蠻單純的。P of Y的機率就是Pn放在句首的機率,Pn後面接動詞的機率,動詞後面接冠詞的機率,冠詞後面接名詞的機率,名詞放在句尾的機率。
link |
P of X given Y也很單純,它就是Pn產生就的機率,動詞產生受的機率,乘上冠詞產生得的機率,名詞產生受的機率。這些統統乘起來,就得到這一項,這一項乘這一項,就得到這一項。
link |
H&M在做的事情就是幫助我們描述說,我們是怎麼說出一句話來的。那有了這個模型以後,我們可以做什麼呢?
link |
這邊是要更一般化的用notation來講一下這個式子是怎麼描述的。P of Y它是Y1放在句首的機率,乘上YL後面接YL加1的機率,再乘上YL放在句尾的機率。
link |
而這個機率我們叫做transition的probability。那在step 2,我們會算一個P of X given Y。P of X given Y是整個sequence上面,given YL產生XL的機率,然後再把它全部連乘起來。
link |
那這個機率我們叫做emission的probability。那再來的問題就是,我們要怎麼算出這些機率呢?我們要怎麼算出這些機率呢?
link |
我們要怎麼算PN後面接N動詞的機率呢?我們要怎麼算我想要generate一個動詞,然後generate出來是sort的機率呢?這個我們就要從training data裡面來得到。
link |
也就是說我們現在先收集一大堆的training data,我們收集一大堆的sentence。那在這個sentence裡面的每一個詞彙呢,我們都找語言學家幫我們標注了它的詞性。
link |
那標完以後呢,這個問題就非常非常容易的被解決了。怎麼解決呢?假如你今天要算P of given YL下一個tag是YL加1的機率,你要算就是假設YL等於S,下一個tag是S'的機率的話,
link |
那很簡單啊,你就算一下在你現在的training data裡面S出現的次數,然後再算一下在你的training data裡面S這個tag後面接S'的次數,然後相除,就結束了。
link |
那如果你要算這個given某一個tag S,那我產生的word是T的機率的話,那也很簡單,你就統計一下tag S在這個corpus裡出現的次數,然後再統計一下某一個word T,它的POS tagging是tag成S的次數,
link |
再把這兩個值相乘,又得到這個機率,然後就結束了。這個東西呢,真的是簡單的不得了。
link |
你要算這一項跟這一項很簡單,就算y1某一個tag在句首出現的次數,跟某一個tag在句尾出現的次數,你就可以求出這兩個機率了。
link |
這個實在是太簡單了。那如果你修過數位語音處理的話,你可能會有一點困惑。有嗎?你看起來很困惑。
link |
你可能會發現說,這個跟數位語音處理求H&M的parameter的方式不一樣啊。
link |
在這個數位語音處理那門課裡面,當我們要求H&M的參數的時候,當然有一個不一樣的地方是,在數位語音處理那門課裡面,這個機率是一個Gaussian。
link |
這邊我講的東西跟用在語音處理上的H&M不一樣的地方並不是在這裡。你會發現說,在數位語音處理這門課裡面,如果你要找H&M的機率啊,你並不是直接用統計的方法這樣算出來的。
link |
如果你對這門課有印象的話,你需要用EM algorithm才能夠把那些參數求出來。為什麼會有這個不一樣的地方呢?這個就讓大家回去自己想看看。
link |
我這邊講的是沒有問題的,就是這麼算。我們統計出這個機率以後要做什麼呢?我們回到我們原來的問題。
link |
我們現在的任務是說,給一個句子X,給一個X,我要找Y,我要找Y。所以我們現在遇到的狀況是,這個X是我看得到的,它是observed的,而這個Y其實是我不知道的,它是我要去找出來的,它是我不知道的,所以它是hidden的。
link |
這就是為什麼這個東西叫做Hidden Mark of Model的原因,因為我們這個Y這個部分呢,它是hidden的。那要怎麼把這個Y找出來呢?我們現在做POX TAG的任務就是要把Y找出來啊,怎麼把它找出來呢?
link |
我們就是要靠我們知道怎麼算P of XY這個機率這件事情。那要怎麼把Y找出來呢?我們可以很自然的想說,如果我今天已經知道X,那最有可能的Y,就是那個P of Y given X最大的那個Y啊,P of Y given X最大的那個Y,就是最有可能的這個C分。
link |
那P of Y given X又可以寫成P of XY除以P of X,然後因為現在X是給定的,所以我求可以讓這一項最大的Y,跟可以求讓這一項最大的Y,那是同一個Y。
link |
所以呢,我們只要,我們要找P of Y given X最大的Y,其實就等於是要找一個P of XY最大的Y。而我們知道呢,P of XY怎麼算,就如果給我一個Y的話,我會算P of XY。
link |
所以我只要窮取所有的Y,一個一個帶進這個P of XY的式子裡面,算出P of XY,我就可以知道哪一個Y呢,可以讓這個機率最大,我就知道現在被hidden起來的Y呢,最有可能是哪一個sequence。
link |
所以呢,如果我們要運用HMM的話,我們要做的事情就是窮取所有的Y,然後算出它的機率,看哪一個Y最後得到的機率最大。那你可能會想說,窮取這件事情聽起來很沒辦法做。
link |
因為你可以想想看,有多少可能的Y呢?假設現在總共有S個,大S個可能的tag,而今天這個sequence的長度呢,假設是L。
link |
那有可能的Y是不是就是S的L次方個呢?那這個其實是非常非常大的。但是好在我們有Viterbi algorithm,那Viterbi algorithm呢,它在做的事情其實就是在做這一件事。
link |
所以如果你不知道Viterbi algorithm是什麼的話,沒有關係,你就想成說這就是一個function,你告訴它說P of XY怎麼算,然後你就call這個function以後,它就告訴你哪一個Y可以讓這個P of XY最大。
link |
那它的計算方法是很有效率的,所以它不用把每一個sequence都看過一次,它的complexity只有L,也就是句子的長度,sequence的長度,乘上可能的tag數目的平方,這樣子而已。
link |
它只要L乘以S平方的complexity,它就可以做到這一件事情。那我之前有說過說大家有空的話呢,要回去複習一下Viterbi algorithm,那假設你沒有,你還不知道Viterbi algorithm是什麼的話,那其實也沒有關係,因為第三堂課的時候,蕭老師會來稍微講一下Viterbi algorithm是什麼。
link |
那這個大家會在作業裡面是用得上的。好,那我們就來summarize一下這個HAM。那HAM它其實也是structure learning的一種方法,所以我們說structure learning的方法就要回答三個問題。
link |
HAM怎麼回答這三個問題呢?第一個就是,它的evaluation function f of x,y 就是x跟y的join probability,而這個join probability,我們剛才講過,它就寫成P of y 乘上P of x given y。
link |
然後呢,我們要解一個inference的花紋,也就是given一個x,然後我們要看哪一個y可以讓我們定義的這個大F的值最大,這件事情就是Viterbi algorithm。
link |
第三步呢,就是我們要找這個f of x,y,也就是我們要找P of y 跟P of x given y,這部分沒有什麼問題,我剛才講過,這個就是機率啊,你就去從你的training data那邊統計一下就好了。
link |
那HAM會有什麼樣的問題呢?HAM呢,它是這樣子,你想想看我們在做inference的時候,我們在求解得到output的時候,我們事實上可以讓P of x,y最大的那個y當作我們的output,對不對?
link |
所以今天如果說我們要讓HAM得到一個正確的結果的話,那我們會希望正確的y hat,假設我的training data是x跟y hat,y hat是正確的tagging sequence。
link |
我要讓P of x,y hat大於P of x,y,這樣我們最後用這個方法做inference的時候,我才能夠得到正確的tagging sequence,但是HAM可以做到這件事情嗎?
link |
HAM可能沒有辦法做到這件事情,在整個HAM的training裡面呢,你會發現說,它並沒有保證可以讓一個錯誤的y帶進去P of x,y的時候,它的機率一定是小的。
link |
怎麼說呢?我們就簡單的來舉一個例子。今天假設呢,我從我的corpus裡面呢,統計出來說,這個n後面接b的機率是0.9,n後面接d的機率是0.1。
link |
然後我從我的corpus裡面,從training data裡面統計出來說,b後面接,given b,b是一個磁性動詞,given b,我看到word a的機率是0.5,given d,我看到a的機率是1.0,given d,我就會看到a這個word。
link |
我這邊稍微圖示表示一下,word n後面接磁性n後面接磁性b的機率是0.9,接d的機率是0.1。
link |
那d產生word a的機率是1.2,產生word c的機率是1.2,word d產生word a的機率是1.
link |
今天呢,假設我們有一個problem,它是說,我已經知道前一個,在l-1這個時間點呢,我們的這個tagging是n。
link |
我知道呢,在l這個時間點呢,我看到的word是a。那請問yl,你覺得它最有可能是誰呢?
link |
那這個問題呢,應該難不倒大家,根據這邊的機率,你可以很輕易的反推說這邊的yl呢,最有可能是誰。
link |
因為我們已經知道這個yl given xl的機率,我們也知道yl-1given yl的機率。
link |
所以要知道,這邊放哪一個tag的機率最大這件事情呢,是很容易的。
link |
因為如果你今天呢,放b的話,這邊放b的話,n產生b的機率是0.9,b產生a的機率是0.5,0.9x0.5是0.45。
link |
那如果放d的話,那是0.1x1,那這樣是0.1,所以放d的機率呢,是比較大的。
link |
那根據這邊的機率呢,感覺這件事情是很合理的。
link |
可是如果我們今天觀察一下我們的training data,我們真的看一下我們的training data是怎麼得到這一個機率的話,那假設我的training data長的是這個樣子。
link |
n後面接b,b產生c出現9次,p後面接b,b產生a出現9次,n後面接d,d產生a出現一次。
link |
那從這個data裡面呢,我可以統計出,n後面可以接b或接d,那接b的機率是0.9,接d的機率是0.1。
link |
b可以產生c,也可以產生a,產生a的機率是0.5,產生c的機率是0.5,d產生a的機率是1。
link |
那我的training data就是長這個樣子。
link |
那根據training data得到的機率,會告訴我們說這邊應該是b。
link |
但是你不覺得這件事情不太對嗎?因為我們在training data裡面已經看過說,n後面要接d,然後d產生a。
link |
我們training data裡面exactly有這一筆training data,可是現在如果我的testing data裡面告訴你說,前面是n,產生的是a,中間你卻填b,
link |
而training data裡面明明就有一筆一模一樣的data,這樣不是不對嗎?這樣不是很奇怪嗎?
link |
所以你不覺得這個地方,你的training data都告訴你應該是d了,這邊應該填d,是比較合理的嗎?
link |
但是對HAM來說,它會給一些我們在training data裡面從來沒有出現過的example高的機率。
link |
如果我們按照HAM的算法,它會覺得n後面接b,b後面接a這個東西的機率是比這個東西還高的。
link |
所以HAM它有一個特色,就是它會腦補它沒有看過的東西。腦補大家知道是什麼意思嗎?腦補的意思就是說,假設你看了一個動畫,動畫裡面可能比如說男二跟女二後來沒有在一起,但是你覺得他們應該在一起,所以你就會在心裡覺得說他們應該在一起。
link |
所以HAM做的事情就是一樣,就是我沒有看過這一筆data,但是我覺得它的機率應該是很高的。
link |
這個就是HAM的一個問題。所以這邊這句話只是要講說,就算有一筆data,就算有一個xy的片,它在我們的training data裡面根本沒有出現過,對HAM來說它不見得會給它一個d的機率。
link |
這件事情是有好有壞的,其實大部分的人講到這邊都會覺得說,這件事情是壞的,這是一個HAM的缺點。但是其實不盡然是如此,因為當你的training data很少的時候,因為假設你的training data很少,搞不好在真實的世界真的這一筆data的機率就是很高啊,只是因為你的data很少而已,所以你沒有觀察到。
link |
所以HAM它其實是在training data少的時候,它的performance反而會比其他的方法還要好。
link |
所以如果你把HAM跟其他方法比較的話,如果你畫一個橫軸是不同的training data,在training data最少的時候,可能HAM的performance會超過其他方法。
link |
但是當你的data增加的時候,HAM的performance增加的幅度沒有其他的方法快,所以當data夠多的時候,HAM的表現就比較不好。
link |
那你可能會想說,HAM為什麼會產生這種腦補的現象呢?它會產生腦補的現象是因為對它來說,transition probability跟initial probability是分開model的,它假設這兩個機率是independent的。
link |
那你就會想說,所以有一個方法可以解決這個問題,就是用一個更複雜的model,用一個更複雜的模型來模擬這兩個sequence之間的probability。
link |
假設initial跟transition是independent,你可能會說,我不要只modelYL-XL的機率,我要modelYL-YL-1-X的機率。你可以這麼做,那可能可以解決這個問題。
link |
但是你要小心,如果你的model太複雜,參數太多的話,那我們會有overfitting的問題。
link |
但是在另外一方面來講,我們下一個要介紹的方法CRF,它其實就可以商號處理這個問題,而且它的model跟HAM是一模一樣。
link |
它可以在用跟HAM一模一樣的model的前提下,也假設initial跟transition probability是independent的前提下,卻可以克服HAM所遇到的問題。
link |
那我們接下來就來講一下CRF。那CRF是什麼呢?CRF它一樣也要描述P of XY,但是它描述P of XY的方法乍看之下,你會覺得很怪。
link |
它描述P of XY的方法是說,我知道說P of XY這個機率,它正比於exponential,一個weight w,跟一個根據XY所形成的feature vector,fine of XY,這兩個vector的因而發達,再去exponential以後,會正比於P of XY。
link |
CRF它的模型是長的這個樣子。這個fine of XY是一個feature vector,我們等一下會講說它長的是什麼樣子。
link |
那這個w呢,是一個weight vector,那這個w呢,是要從data裡面學出來的。那exponential w跟fine of XY的內積呢,我們只能夠知道說它一定是正的,因為我們取exponential嘛,所以一定是正的。
link |
但是我們沒有辦法保證它小於1,它是有可能大於1的,所以如果我們直接說這個東西是一個機率的話,也不太對,機率要小於1嘛,所以我們說它的機率是成正比的。
link |
那你可能就會想說,那我不就不知道這個真正的機率是什麼了嘛,怎麼辦呢?北灣市CRF它不care P of XY是什麼,它真正care的呢,是P of Y given X。
link |
那我們可以寫成呢,P of XY除掉這個summation over所有可能Y的P of XY,我們把P of XY除掉所有的Y的P of XY的summation,就得到P of Y given X。
link |
那P of XY呢,我們知道說它跟exponential這一項是成正比的,所以我可以說P of XY是exponential這一項除以R。
link |
那當你把這個東西帶進去,這個東西帶進去,因為R在上下都有出現,所以就可以直接把R消掉了,R就用不上了,對吧?
link |
所以呢,你就可以直接在CRF裡面呢,你就可以把P of Y given X寫成exponential W跟final XY的inner product,除掉呢,W跟所有的Y的final XY的inner product再去exponential。
link |
你把這一項帶進去,這一項帶進去,R上下都有出現,所以可以消掉,所以這一項你可以寫成這個樣子。
link |
因為下面這一項比較複雜,下面這一項比較複雜,下面這一項呢,它是summation over所有可能的Y,所以它跟Y其實是independent,它只跟X有關係。
link |
所以下面這一項呢,在簡化期間,我們可以直接把它寫成Z of X。那你可能會覺得說呢,這個CRF看起來,如果你是第一次看到它的話,你可能會就是一下子很難接受,為什麼機率會是一個exponential兩個factor做內積呢?
link |
這不是很奇怪嗎?感覺它跟H&M是完全不一樣的東西。其實不是,CRF跟H&M呢,它們想要model的,它們的model其實是一樣的,它們並沒有那麼多的不同,它們只是在training上面是不一樣。
link |
在過去大概在可能2006年到2008年那個時候呢,CRF曾經一度在語音界很熱門,然後那個時候大家其實沒有那麼懂CRF,因為H&M用了好多好多年了,用了二十年了,然後很少有方法能夠真的打敗它。
link |
然後就不知道有人去哪裡找了CRF,然後說你看這個東西,看起來完全跟H&M都不一樣啊,所以我們就找到救星了,它一定可以贏過H&M。但是後來在2008年的時候,有人寫了一個paper說,這其實是一樣的東西,然後大家就失望以後,就很少有人用CRF了。
link |
好,那其實它們為什麼是一樣的東西呢?你看看,在H&M裡面,我們說這個P of XY是一大堆的機率相乘。
link |
是Y1放在巨首的機率乘上YL given YL加1的機率乘上YL放在句尾的機率再乘上YL given XL的機率,它是一堆機率相乘。那我們現在把它取log,取log其實沒有什麼了不起的地方,就是原來的相乘通通都變成相加。
link |
然後呢,我們先來看看相加裡面的這一項。這一項它應該有,你的句子長度如果是大L的話,這一項應該是大L的log P of XL given YL的和。
link |
那我們可以把這一項稍微做一下整理,我們把它寫成下面這個樣子。下面這個樣子呢,這邊這個summation是summation over所有的tag S跟word T的,summation over所有的tag S跟word T。
link |
所以如果你有十個可能磁性的tag,這個世界上一萬個word的話,S總共有十個不同可能,T總共有一萬個不同可能的話,那這邊呢,你就是summation over十乘以一萬項,summation over十萬項。
link |
那裡面每一項是什麼呢?裡面每一項呢,是S跟T的這個pair,在這個tag S,這個word T它被標示成S這個tag這件事情,在XY這個pair裡面總共出現的次數。
link |
我再說一次,它是word T被標示成tag S這件事情,在XY這個pair總共出現的次數。
link |
第二項呢,就是根據我現在的model,P of word T given S,也就是說tag S,word T被tag成S的機率去log。這個看起來非常複雜,你可能一下子沒有辦法轉過來說,為什麼這個就是這個。
link |
等一下舉一個例子,你可能會比較清楚。這邊有一些文字說明,這邊是summation over所有可能的tag跟所有可能的word,這邊是機率,然後這邊是這個event這件事情,在XY這個pair裡面出現的次數。
link |
為什麼可以做這個轉化呢?我們來舉一個例子,現在有一個sentence,X the dog at the home word,每一個word我都有label它的tagging。
link |
那我們現在可以做一下計算,the這個word被標示成萬詞的次數,在這個XY的pair裡面出現幾次呢?假設我們不考慮大小寫的話,它出現一次兩次。
link |
the被標示成萬詞的次數是兩次,dog被標示成名詞的次數,dog被標示成名詞的次數是一次,at被標示成動詞的次數,at被標示成動詞的次數是一次,home word被標示成名詞的次數是一次,而其他的word標示成其他的tag,它的次數都是零次。
link |
接下來呢,我們來計算一下這邊所有的機率的相乘,這邊所有機率的相乘呢,就是D產生得的機率,加上N產生dog的機率,E產生at的機率,D產生得的機率,N產生home word的機率。
link |
然後我們會發現說呢,D產生得的機率出現過兩次,這一項跟這一項出現過兩次,它們的值是一樣的,所以我們可以把它加起來,加起來就變成說,P of the given D乘2,然後其他機率都乘1。
link |
從來都在這個裡面都沒有出現過的tag跟word的pair就都乘零,所以我們把它整理一下以後呢,就可以變成這樣子。
link |
這邊對所有機率的log的和,可以變成summation over所有的tag跟word,這個tag產生word的機率再乘上它們在這個句子裡面出現的次數。
link |
這樣大家有問題嗎?好,所以呢,對其他項呢,我們也可以做一模幾乎一樣的轉化。
link |
比如說,這一項機率,我們可以把它寫成說,summation over所有的tag,這個tag放在句首的機率,乘上在這個Sy pair裡面,這個tag S放在句首出現的次數。當然對所有可能的tag來說,只有其中一項是1,其他的都是0。
link |
或者是這個transition probability呢,我們可以把它寫成說,summation over所有的tag S跟S'的pair,然後呢,我們去計算一下S這個tag後面接S'這個tag在Sy裡面出現的次數,再乘上S後面接S'的機率之log。
link |
或者是最後一項呢,我們也可以如法炮製,把它寫成了兩項的相乘。把這個寫成相乘以後又怎麼樣呢?
link |
我們這邊呢,我們發現說,我們可以把log P of Sy寫成一大堆兩項的相乘,一大堆兩項的相乘。然後有的是summation over所有的tag跟word,這個summation所有的tag,這個summation所有的tag的pair,這邊也是summation over所有的tag。
link |
然後呢,我們就可以把它描述成兩個vector的inner product。大家可以轉著過來嗎?就是這邊是好多兩項兩項兩項東西乘起來再相加,這其實就等於是我今天有兩個vector在做inner product。
link |
我們把這兩個vector呢,他們animalize的相乘以後,然後再加起來,就變成這個樣子。然後在這邊這個紫色的vector裡面呢,它就是左邊這個第一項拿來拼在這邊,紅色的vector呢,就是右邊這個拿來拼在這邊。
link |
所以呢,我們用W來代表紫色的這個vector,用Phi of Sy來代表右邊紅色的這個vector。你會發現說紅色這個vector裡面呢,它每一個animal呢,它都是跟XY有關的。
link |
比如說這個是tag T,word T被標示成tag S,在XY pair裡面出現的次數。或這個是S'後面接S,在XY的pair裡面出現的次數。所以呢,這個vector呢,它是dependent on XY的。
link |
所以我們可以說這個vector呢,是一個XY所形成的feature,那我們寫成Phi of XY。那我們既然說log P of XY等於W跟Phi這個feature vector的inner product,那P of XY呢,其實就是W跟這個feature vector的inner product,再取exponential。
link |
但是這邊有一個地方呢,可能需要稍微注意一下。就是說呢,這個東西是這個,這個是這個,那這個東西啊,它可以跟HMM裡面的機率呢,做對應的。
link |
也就是說呢,這個W的ST呢,對應到這個,對應到這個維度的,對應到這個維度的weight呢,它其實呢,就是S,它的word T被標示成tag S的機率。
link |
或者是呢,對應到這一個維度的這個weight呢,它就是呢,S放在巨首的機率。或者是呢,對應到這個維度的weight呢,它就是YI-1等於F,後面接S'的機率。
link |
或者是對應到這個維度的weight呢,就是S放在句尾的機率。所以今天這個W這個vector裡面呢,它每一個weight呢,它都是對應到HMM裡面的某一個機率取log。
link |
所以,如果你想要把這個東西轉回成機率的話,你就把它取這個exponential,你就把它取exponential。你把這些weight呢,取exponential以後呢,你就可以把它轉回成機率。
link |
那這邊有一個問題就是,今天我們在做training的時候,這個weight裡面的value,它是可正可負的。這個weight vector裡面每一個element,它是可正可負的。那如果說這個weight是負的的話,取exponential以後我們得到的值是小於1,那也就罷了,你還可以把它解釋成一個機率。
link |
但是如果是大於1的話,那你就解釋成機率啊,就很奇怪。再來呢,就是givenS產生t對所有t的summation,我們也沒有辦法保證說它的和一定是1。
link |
所以呢,我們沒有辦法直接說P of x,y就等於這個exponential這一項,所以我們就把它稍微改一下,就說P of x,y是跟這個機率是成正比的。
link |
那我們在這邊先稍微休息一下,謝謝。好,我們來上課啦。假設剛才講的東西你沒有聽懂的話呢,就算了。
link |
我們接下來要講的就是,你就直接記得說,CRF,它說它的機率就是exponential,一個weight w,跟一個feature vector的inner product。
link |
再來就是,那個feature vector長什麼樣子呢?我以下就直接告訴你說那個feature長什麼樣子,那如果你沒有辦法理解它的話,沒有關係,你就硬背起來。
link |
你需要implement這樣的feature vector,那等一下小老師會來告訴大家說,在語音上這個feature vector應該要怎麼做,它也是跟語音的ham是有關係的,如果你這個地方理解不能的話,你就硬背起來就是了。
link |
好,那這個P of x,y它是長什麼樣子呢?這個P of x,y它有兩個部分,包含兩個部分。第一個部分呢,是有關這個tag和word之間的關係。
link |
第二個部分呢,是有關tag和peg之間的關係。那我們先來看第一個部分。右邊這個vector呢,是第一個部分的這個。
link |
那第二個部分呢,還沒有畫在這個投影片上面。好,那這個第一個部分,這個是什麼意思呢?第一個部分說,如果我今天假設有S個tag,然後呢,我們今天呢,有大L個可能的word的話,
link |
那這個第一個部分的feature vector呢,它的dimension呢,就是大S乘以大L。也就是說,假設世界上有十種可能的直性,有一萬個可能的word,那這個vector的長度呢,就是十萬維那麼長。
link |
那這個vector裡面有什麼呢?我這個動畫沒問題吧?OK,好,這個部分是沒有動畫,好,沒有關係。
link |
好,這個部分裡面是有什麼呢?它裡面呢,就是所有的直性跟所有的詞彙的pair。那今天呢,如果給一個XY的pair,給一個XY的pair,它裡面呢,這個的被標示成D出現兩次的話,
link |
那那個維度呢,就對應到2,或者是Dog被標示成N出現一次的話,那個維度呢,就被標成1。那其他呢,都沒有出現過的tag跟word的pair,我們就把它呢,標示成0。
link |
所以你可以想像說呢,這個vector呢,其實是一個非常fast的vector,它的dimension非常大,但是呢,有直的地方呢,可能沒有很多。那在第二個部分呢,我們要model tag和tag之間的關係,怎麼做呢?
link |
這個做法是這樣子,我們定義呢,這個N下標S',是這個tag S跟S'呢,在XY這個pair裡面連續出現的次數。
link |
所以呢,這個NDD of XY,就是D後面接D,在XY這個pair裡面出現的次數。不過呢,因為在這個example裡面,D和D從來沒有接在一起過,所以這個維度呢,就是0。
link |
那在這個example裡面呢,D後面接N這個event呢,它總共出現過兩次。D後面接N這邊一次,D後面接N這邊一次,所以這邊是兩次。D後面接B,D後面接B沒有出現過,所以是零次。
link |
或是N後面接B,N後面接B出現一次,所以這邊是1,那其他都是0。那所以你可以想像說呢,這個vector的dimension是多少呢?
link |
這個vector的dimension是,假設這個世界上的tag的數目有S種可能的tag,那這邊的dimension呢,就是S乘S,加上兩倍的S。因為對所有的tag的pair,我們都要有一個維度。
link |
然後每一個tag跟start所產生的pair也是一個維度,每一個tag跟end所產生的pair也是一個維度。所以所有tag的pair是S的平方,然後呢,start跟tag的pair是S,end跟tag的pair是S。
link |
所以第二個部分,我們有S平方加2S的dimension那麼多。那其實就是這樣。那你就可以把這個part2的vector跟part1的vector接起來,然後呢,就當作CRF裡面拿來算機率的這個vector。
link |
那這個vector呢,它有它的含義。它的含義呢,是它跟HAM想要model的東西呢,是一樣的。但是因為CRF把它的機率描述成一個weight跟一個feature vector的inner product,所以CRF比HAM呢,多了一個厲害的地方就是,你可以自己定這個vector。
link |
你可以說我不一定要這樣定啊,為什麼一定要這樣定?我可以自己提出一個我自己覺得好的定義的方式,那你就看你開心,然後就可以定一個自己的vector,希望它可以比原來一般人用的這個更厲害。
link |
那這就是CRF呢,一個厲害的地方,一個很flexible的呢,定義自己的vector。那再來CRF要怎麼train呢?那training的criteria是這樣,首先我們當然要收集training data,X1,Y1的head到X star,Y大的head。
link |
那接下來呢,我們要找一個weight vector W star,它要去maximize一個objective function O of W,那這個objective function要怎麼定呢?OK,我們要找一個W,去maximize O of W,那就我們的結果W star。
link |
這個O of W要怎麼定呢?我們把它定成說,我們已經有一堆的training data了,我要找一個W,它可以去maximize Xn,它可以去maximize given Xn產生正確的label sequence Yn head的機率。
link |
OK,我們要找一個W,去maximize given X產生Y的機率,然後我們把它取log,然後再把它subvention。
link |
那你會發現說呢,這一下,其實是不是就是很像那個cross entropy那一下呢?在做cross entropy的時候,我們不是要去maximize正確那個維度的機率,再取log,那個時候呢,我們是在一個frame上做考慮。
link |
那現在呢,我們是在一整個sequence上做考慮了,given一整個sequence X,我們要讓正確的那個sequence的機率的log越大越好。
link |
好,那這一項log這一項呢,我們可以把它做一下轉化,因為根據CRF的定義呢,這個P of Y given X可以寫成P of XY除掉一堆Y的P of XY的subvention。
link |
所以我對這個取log,對這個取log以後呢,就變成log P of XY,Yn head,減掉呢,log subvention over所有的Y,P of XY塊。
link |
OK,就是這一項取log,這一項取log,結果呢,就變成這個樣子。
link |
那你會發現說,因為我們現在要做的事情,是去找一個W去maximize這個equation,也是要去找一個W呢,去maximize這個equation。
link |
那當我們maximize這個equation的時候,我們會做到什麼事情呢?
link |
第一個是,第一項告訴我們的是,當我們maximize這個equation的時候,我們會maximize我們現在在training data裡面看到的片,X and Yn head的機率。
link |
這個東西在training data裡面有看到,所以我們maximize它的機率。但是同時呢,我們要minimize我們沒有看到的東西的機率。
link |
那這邊呢,是subvention over所有的Y塊。
link |
所以在這個subvention裡面,這個P of X and Y塊,通常都不會出現在這個training set裡面。那這些沒有出現在training set裡面的X,Y pair,我們希望minimize它的機率。
link |
所以CRF在做training的時候,它是希望找到一組weight,這一組weight同時可以讓我們有看到的pair,我們training data裡面有的pair機率大,但是又要讓我們在training data裡面沒看過的pair機率小。
link |
那這個,再來要怎麼去找W maximize這個呢?那其實就很簡單,其實就是用gradient descent,但是因為這邊呢,我們是要maximize一個function而不是minimize一個function。
link |
那所以呢,我們要做的方法呢,跟gradient descent有略略的差異,這個東西呢,叫gradient ascent,你知道在gradient descent的時候呢,我們有一個要去minimize a cost function C,然後呢,我們會去算這個C的gradient,然後把我們的parameter呢,在每一個iteration減掉C的gradient。
link |
那gradient ascent呢,它做的事情呢,非常的像,就是我們有一個objective function O要被maximize,那我們在每一個iteration呢,計算一下O的gradient,然後把O的gradient呢,加給我們要optimize的參數就好了。
link |
所以在gradient descent裡面我們是減的,在gradient ascent裡面呢,我們是加的。好,那接下來呢,我們要做的事情就是,這是我們要去optimize的function。
link |
那我們要計算呢,這個我們先定義log P of Yn given Xn是O上標Nw,那我們要去計算呢,這一項,這一項,對weight w的gradient。
link |
那我們w呢,有很多很多,有的w呢,是對應到一個tag跟一個word的pair,有的w呢,是對應到兩個tag之間的pair。
link |
那等一下呢,我會show一下說,partial w下標st,也就是對一個這個tag跟word的pair所對應的這個w,它對objective function做偏為分的結果。
link |
那其實呢,其他的weight算出來呢,也是非常非常類似的。那這個過程呢,這個計算的過程呢,當然這只是簡單的數學,你知道這個的定義,你把這個w拿去做偏為分,那你就可以得到那個結果了。
link |
那過程呢,我其實就放在appendix裡面,那你有興趣的話就自己去看。總之經過一串運算以後,我們最後得到說,這個partial w分之partial o啊,它有兩項。
link |
第一項,第一項是s跟t的這個pair,也就是word t被tag成s的event,在x跟y跟hab裡面出現的次數。
link |
第二項,這個比較複雜,它是summation over所有可能的y,然後在這個summation裡面呢,每一個turn呢,是這個word t被標示成tag s這個event,
link |
在xn跟任意一個y這個pair裡面出現的次數,乘上呢,given xn產生這個任意一個y的機率,那這個y呢,是sum任何y都有可能。
link |
所以有的y呢,可能這個機率大,然後這個出現的次數多,有的y呢,可能這個機率小,這個出現的次數小,都不一定。這個y呢,是所有可能的sequence,所以它非常非常的多。
link |
那這一項怎麼算呢?這一項的定義,我們就把它寫在這裡。你會發現說這個機率呢,其實是跟我現在做偏為分的那個參數w呢,是有關係的。
link |
所以呢,經過偏為分以後呢,我們得到的結果就是這個樣子。那這個結果的,這個推導的過程呢,有點繁瑣我們就不講,但是呢,它的物理的含義呢,其實是很清楚的,對吧?
link |
因為如果你看這個第一項,第一項是什麼意思?我們先提醒一下,就是說我們算出來這個東西啊,算出來這個偏為分的結果,我們是要把它跟我們原來的這個參數呢,做相加的。
link |
也就是說,如果這個東西算出來是正的,我的這個參數就會增加,反之這個東西算出來是負的,我這個參數就會減少。
link |
那這個參數呢,是對應到s跟t的這個pair的這個參數。那如果我們看第一項,第一項是s跟t的這個pair,在x跟y和h的這個正確的pair裡面出現的次數。
link |
所以這個式子告訴我們說,如果s跟t這個pair在正確的training data,在我們的training data裡面出現的次數越高,那它對應的weight w的值呢,就會越大。
link |
那這個是第一項呢,告訴我們的東西,這個是很直覺的。那第二項告訴我們什麼呢?第二項告訴我們說,第二項告訴我們說,因為它是減掉任意一個xy的pair裡面,s跟t出現的次數。
link |
所以如果今天s跟t這個pair出現的次數,在任意一個pair裡面出現的次數很大的話,在任意一個pair出現的次數很大的話,那我現在呢,就應該把w減小。
link |
所以這兩項呢,其實是互相解抗的,這樣嗎?我們老是用詞對不對?反正這兩項呢,是有一個tradeoff的。這一項就是說,如果你這一項是說,如果今天呢,這個st呢,在正確的答案裡面出現的次數很多,那它對應的weight就是增加。
link |
但如果它不只在正確的答案裡面出現的次數多,它在隨便拿一個y跟xpair起來的這個pair裡面出現的次數也多的話,那我就應該要把它減小。
link |
有沒有寫錯,我看看。你說這個嗎?哇,被發現了,寫錯了耶。這個,不好意思,不好意思,這個t才是過人,t是過人,所以這個應該是t,這個是t。
link |
所以這一項是說,如果wordt在training data裡面被label成tag s的話,那我們就要增加wst。如果wordt在任意一個pair裡面被label成s的話,我們應該減少wst。太棒了,這個應該是t,謝謝。
link |
然後剛才不是有一個同學發現了一個很神奇的錯誤嗎?請記得來跟我講一下,你的名字量來。好,那再來有一個問題就是,如果你今天要自己implement crf的話,有一個地方會讓你有點卡住就是,怎麼summation over所有可能的wifi?
link |
這聽起來是一個很困難的問題啊,但沒有關係,這個也可以用Viterbi algorithm來解,這個就留給大家自己來思考一下。
link |
所以呢,剛才我們只算了某一個w的片尾分,那對整個所有的w,它的歸點,我用這個w去對objective function over做歸點的話,這整個vector長什麼樣子呢?
link |
這整個vector就是正確的y hat所形成的vector,減掉任意一個wifi所形成的vector,再乘上那一個wifi的機率。
link |
這件事情有沒有非常的符合直覺呢?如果我們把gradient ascent的式子列出來的話,在做gradient ascent的時候呢,我們每次都去sample一筆data xn y hat,然後我們去計算xn y hat的vector,
link |
那我們把正確的y hat所形成的vector加給w,然後再去減掉任意一個y所形成的vector,但是每一個y的機率都不一樣,所以這邊是任意一個y的vector的weighted sum。
link |
講解大家有問題嗎?如果沒有的話呢,我們就繼續看下去。那有了這些以後呢,我們就用gradient descent的方法把w求出來,把w求出來以後呢,我們就可以做influence了。
link |
那怎麼做呢?我們知道說,我們現在要做的事情是given一個x,我們找一個y,讓P of y given x最大。那我們剛才在hn已經看到說,做這件事情等同於是找一個y,讓P of xy最大。
link |
那在CIF裡面,我們又知道說,P of xy它是正比於exponential w跟phi of xy的內積,這一項跟這一項成正比,所以你可以把這一項帶進去。
link |
那你因為exponential是一個monotonic的function,所以呢,你找讓這一項最大的y,等同於是找一個讓w跟phi of xy inner product以後呢,最大的y。
link |
那你會發現說這一項,我們其實在做這個,我們上週在講structured SVM或structured Perceptron的時候呢,其實看過一模一樣的事實。這一項呢,你其實也可以用Viterbi algorithm來做influence。
link |
再來我們要講的就是,CRF跟HNN有什麼樣不一樣的關係。那我們剛才在CRF的training process裡面呢,我們看到說CRF做的事情就是,它不只會increase P of xy hat的機率,
link |
它還會decrease任意一個y是跟x所形成的pair的機率,而HNN呢,並沒有做這一件事情。而我們知道說呢,如果我們要得到正確的答案,我們會希望y hat的機率大於y,
link |
而CRF它會increase y hat的機率,而decrease其他y的機率。所以跟HNN比起來,CRF更有可能得到正確的結果。
link |
舉例來說,我們剛才在HNN的example,我們說根據這筆training data,HNN給了我們一個這樣的結果,那這個是直接從統計來的。那根據統計的結果,HNN說這邊應該是n後面應該接b,b要產生a。
link |
這筆training data也就告訴你說,n後面要產生接d,d要產生a。那如果是CRF的話,因為它根本就不care這個機率,它並不是說我去data裡面去count一下說,n後面接b幾次,b產生c幾次。
link |
它不是,它完全不count這個。它就是去調那個參數,它要調到那個參數,使得說正確的這些xy的pair,它們的分數是比較大的。
link |
所以它可能就調來調去,調來調去,就說我把這一項從二分之一,不要是二分之一,我就把它改成是0.1,我把b產生a的機率變小,我把b產生a的機率變小。
link |
這樣子我就有可能在influence的時候覺得這邊應該是d,而不是b。你可能會想說,如果我把b產生a的機率變小,那搞不好這邊就會弄錯啦,那沒有關係,CRF它就是很神奇的,它就是會想辦法調整參數,讓正確的大,讓正確的大錯的小。
link |
所以可能如果b變成a的機率太小的話,可能就會調高p產生b的機率。
link |
然後這以下是一個Synthetic的實驗,這個實驗其實是出自於Proposed CRF的第一篇paper,那它是要比較CRF跟HNN有什麼不一樣的地方。然後在這個Synthetic的實驗裡面,它說我們的input是小寫的a到z,然後我們的output是大寫的a到e。
link |
然後我們要Generate一些Artificial的Data,我們Generate一些Artificial的Data,那這些Artificial的Data其實是用HNN Generate,但它用的不是一般的HNN,它又不是一般的HNN,它是用一個Mixed Order的HNN。
link |
它的Transition Probability是α乘上yi-1givenyi的機率,加上1-α乘上yi-1givenyi-2givenyi的機率。
link |
你可以想像說,如果今天α帶1,這一項是0的話,那這個就是我們剛才講的一般的HNN,但是因為今天這個α呢,它這個值是可以任意調整的,它可以任意調整說,今天這個HNN是要考慮一個order的情況比例比較大呢,還是考慮兩個order的比例比較大,它可以任意調整這個α的值。
link |
那在Emission Probability的部分呢,它是α乘上P of xi-yi,加上1-α乘上P of xi-yi,xi-1,那如果今天α剩1的話,只有這一下就是一般的HNN,但是因為加了這一下,所以它不是一般的HNN。
link |
接下來我們要做的事情就是,我們要比較HNN跟CRF的performance,那注意一下我們今天用的HNN跟CRF都是一般的HNN跟CRF,就是我們剛才講的HNN跟CRF,也就是說我們用的HNN呢,其實只有考慮一個order,也就是它是α等於1的狀況。
link |
那麼希望說,我們看能不能夠用α等於1的HNN或者是一般的CRF,就可以認出用這樣子比較複雜的process所產生的data。
link |
那當然,in general,一般而言,我今天在做實驗的時候,如果α調得越小,那它跟一般的HNN跟CRF的差距越大,我當然得到的performance會越差。它跟HNN跟CRF的假設差距越大,我當然得到的performance會越差。
link |
但是呢,我們想要知道在這個情況下,到底是HNN它壞得比較厲害,還是CRF壞得比較厲害呢?這個是實驗的結果。
link |
每一筆實驗,每一個圈圈,是不同的α所得到的結果。那由左下到右上呢,代表是α是由小到大。那每一個點呢,我們都用做一個HNN的實驗,都做一個CRF的實驗。
link |
那這個橫軸跟縱軸分別代表HNN犯錯的百分比跟CRF犯錯的百分比。那你可以想像說,如果今天一個點它在45度角的右側,代表說HNN犯的錯多,CRF犯的錯少。
link |
所以這個情況呢,代表說CRF的performance比較好。那如果它在左側呢,代表HNN的performance比較好。那這個實驗結果你可以發現說,今天這個框框非時薪的點,代表說α呢,是小大於二分之一。
link |
α大於二分之一代表說它比較接近我們一般的HNN或CRF的model。而在這個狀況你會發現說,其實HNN是比CRF還要好。我們傳統都會覺得說HNN就是很傳統,所以它很弱。
link |
但是在這個狀況下,其實HNN是比CRF還要好。那其實你也不用太疑問,因為其實這個data就是從HNN所產生的。所以今天在這個test裡面,HNN的假設其實是跟比CRF的更貼近我們data的產生方式。
link |
所以當我們α大於二分之一的時候,HNN可以比CRF得到更好的結果。但是當我們α小於二分之一,也就是說我們今天data的產生方式跟HNN還有CRF的假設都很不合的時候,這個時候你就會發現CRF還要比HNN還要好。
link |
因為今天如果在HNN跟CRF的假設都不合的情況下,HNN是只能夠完全按照機率,但是CRF會調整它的參數,讓它去fit你的data。
link |
所以雖然有些假設沒有被model在CRF裡面,但是藉由這些調整參數,CRF其實也可以認識,商號可以考慮把這些假設考慮進去。所以當你的模型和你的data背後的假設是比較不合的時候,這個時候CRF會得到比HNN還要好的結果。
link |
以下是CRF的summary,它也是一個structure blending的方法,它也滿足,它也解決了三個problem。第一個problem就是它的f of x,y是P of y given x,那我們說P of y given x可以寫成這個樣子。
link |
Inference就很簡單了,就是我們本來是要找一個y讓P of y given x最大,但是這件事等同於找一個y讓w跟f of x,y的inner product最大。
link |
最後呢,它的training,我這邊其實並沒有寫錯,你可能覺得說怎麼跟剛才投影片講的不一樣,但是那是因為剛才投影片是log相加,然後我這邊是沒有log相乘,所以它們是一樣的東西,並沒有寫錯。
link |
你可能會問說怎麼不一樣呢?怎麼會不一樣呢?其實我早上做投影片的時候,我就想說如果我寫相乘的話,等一下會不會有人來問我說為什麼是相乘而不是相加呢?
link |
所以我就想說把它改成相加好了,因為我想說我們在之前講那個cross entropy的時候,我們也是做log相加的,所以我就想說把它取成log相加,可以跟之前做cross entropy那個部分比較有連結。
link |
一般CRF的文獻都是這樣寫,寫成posterior probability的相乘,但事實上你可以把這邊直接改成相加而不取log,然後其實這樣子的performance還會比原來的好一點。
link |
這個是多講的,那這個就是它的parameter update的方式。最後複習一下structure percentile跟structure SVM,就我們上週講的東西怎麼又在secrets library發文上面。
link |
我們有講過structure percentile,它也是structure learning的技術,它也解了三個problem。第一個problem,它說f of x,y就是w跟phi of x,y的一個problem。
link |
你可能會問說,如果我今天x跟y都是secrets的話,這個phi of x,y應該定成什麼樣子呢?當然你可以想一個你自己喜歡的定法,但很簡單的方式就是,就拿CRF的那一個直接來做就好。
link |
如果你想到什麼好的定這個phi of x,y的方式的話,你就把剛才我們在講CRF的時候定的那個phi of x,y直接塞進來就好。那我們在做inference的時候,我們要去找一個y讓這個最大。
link |
一樣就是用Viterbi來解就好了。然後在training的地方,我們對所有的training data n,還有所有不是不等於y hat的y,我們希望讓w跟y hat所形成的vector的inner product大於w跟其他y所形成的vector的inner product。
link |
然後這件事要怎麼做呢?在structure perceptron裡面,在每個iteration,我們會找一個y tilde。這個y tilde是根據我目前的w,我去做inference這個problem,然後看哪一個y tilde可以讓這一項最大。
link |
接下來,我們把w加上y hat,正確的y hat所形成的vector,減掉y tilde所形成的vector。
link |
你有沒有覺得這一項很眼熟呢?我們好像剛才才看過。它是不是跟CRF在做gradient ascent的時候update的式子很像呢?這個structure perceptron,它是找一個會讓這個值最大的y tilde,然後它讓w加上y hat的feature減掉y tilde的feature。
link |
而CRF呢,如果你忽略掉這個lending rate這一項,你假設lending rate是1,你忽略掉lending rate這一項,它跟這個東西跟這個東西,它們一樣都有兩項,而它們前面這一項是一樣的。
link |
後面這一項呢,雖然表面上看起來不一樣,但是它們之間是很有關係的,因為你可以想,因為這邊是summation over所有的y,這邊是summation over所有的y的feature在這個位置上,這邊是只減掉某一個y。
link |
但它所減的那個y,它所減的那個y tilde的feature,是那一個可以讓這一個值最大的y tilde。那可以讓這個值最大的y tilde,其實就是機率最大的那個y。
link |
了解我意思嗎?也就是說,在CRF這一項裡面,它是把所有的y塊都用它的機率去做weighted sum,然後在structure percentile裡面,它只取機率最大的那個y出來減。
link |
所以這個structure percentile它是hard的,它只減一個,只減機率最大的那個y所形成的feature,而CRF它是soft的,它對所有的y可能形成的feature都按照它的機率去做weighted sum。
link |
你可以想像說,如果今天在這個y塊裡面,只有一項的機率是1,其他都是0的話,那這兩個東西其實就是等價。
link |
那如果是structure SVM的話,它的problem 1和problem 2都跟structure percentile是一樣的,唯一不同的地方是在它的training的方式。那在SVM裡面,我們會加上margin的概念,還會加上error的概念。
link |
這個是我們上週所講的內容,那我們要怎麼解這個problem呢?有兩個方法,第一個方法就是用weighted descent,第二個方法是把它formulate成很像SVM,解一個quadratic programming的problem。
link |
但是那個quadratic programming的problem太多parameter,沒辦法真的解,所以我們實際上在解它的時候,用的是cutting plane的algorithm。那structure SVM裡面,有一個特別的地方就是要consider error這件事情,要考慮error這件事情。
link |
那這個error的function呢,我們會把它寫成delta,那這個delta呢,它會計算兩個y,正確的y,y hat和另外一個y呢,它們之間的不一樣的程度。
link |
那這個delta呢,是在計算y和y hat它們之間的差異性。那我們上次有講過說呢,這個structure SVM它的cost function,structure SVM的cost function,其實就是這個difference的upper bound。
link |
所以如果你去minimize structure SVM的cost function,你就是在minimize你的error的upper bound。那theoretically,這個delta可以是任何你覺得適當的function,可以是任何你想要拿來衡量兩個y的差異的function。
link |
但是呢,你必須要考慮到說,我們今天在使用structure SVM的時候,不管是用gradient的方法,還是用quadratic programming的方法,我們都要面對一個problem 2.0。
link |
這個problem 2.0是說,我們要找窮取所有的y,看哪一個y,它的delta加上這個inner product值最大。我們剛才在problem 2裡面,我們只需要找一個y,讓這一項inner product值最大。
link |
但是在problem 2.1裡面,我們不只要讓這一項最大,我們還要讓delta加這一項最大。所以它是一個不一樣的問題。你可以解得出problem 2,代表你可以解得出problem 2.1,尤其是如果你的delta讓你覺得很難解的話。
link |
以下這個例子呢,是一個可以解的例子。如果你今天呢,把兩個sequence之間的delta定義成它的錯誤率的話,也就是說,假設y hat是正確的sequence,y是錯誤的sequence。
link |
那它們的長度一樣,你去看它們有幾個label不一樣。那我們把這個不一樣的label的數目,除掉這個sequence的長度,定義為它的delta。
link |
如果你把delta定義成這樣子的話,你就可以解problem 2.1。如果你胡亂定義一些很困難的,比如說我說delta是y和y hat的any distance的話,那這個可能就沒有efficient的解法。如果你用這個方法來定義delta的話,你可以用Viterbi來解,如果用其他方法的話,我就不敢保證。
link |
就這樣,如果你這樣子定義delta,你就用Viterbi algorithm來解。好,那我們來看一下一些不同的方法在文獻上的比較。
link |
首先是在PoS taking上的實驗。在這個實驗裡面,我們比較了HAN,CRW,Structure Percentron,Structure SEM。你會發現說這個橫軸是training data的size。
link |
你會發現說HAN的performance是最差的。有一些文獻會發現說如果training data更少的時候,其他方法會變得更差,然後HAN在這個情況下會比較好。
link |
這點在這張圖上沒有呈現出來。CRF是這一條橙色的線,它是贏過HAN的。Structure Percentron它是灰色這條線,它略勝,它勝過CRF。
link |
在文獻上,到底CRF跟Structure Percentron誰比較強,是沒有人定論的。你會發現他們其實很像,Structure Percentron是hard的,而CRF是soft的。到底是hard的好還是soft的好,我們不知道。
link |
但是Structure Percentron有一個好處,什麼好處呢?你記不記得在做CRF的時候,你要summation over所有的y'對不對?而這件事情你不一定知道要怎麼解。
link |
你不一定知道summation over所有的y'要怎麼解。如果你不知道怎麼解的話,我給你的建議就是不要用CRF,用Structure Percentron。因為Structure Percentron你只需要解problem2就好,而problem2我們是預設,它是有辦法解的。
link |
然後在這個實驗裡面,最後我們發現最後這個Structured SDN的performance是最好。這是另外一篇paper,這個是Proposed Structured SDN的那篇paper裡面的實驗,它做在Name Entity的recognition上面。
link |
這個test就是說我們必須要標註說,given a word sequence,哪些word是屬於人名,哪些word是地名,哪些word是組織的名稱,哪些word是其他。
link |
它跟POS tagging這個problem是非常非常類似的,只是我們把POS的tag換成公司名,地名,組織名,還有其他這樣子。我們發現在這個實驗結果上面,H&M的performance是最差的。
link |
然後CRF跟Percentron看起來在這個情況下,CRF還比Percentron好,但是最強的是Structured SDN。
link |
接下來呢,我們就要來回答一個問題,就是為什麼不用RNN?為什麼不用RNN?剛才講的這種Seven Sampling的問題,你可以用RNN或LSDN來解,你也可以用H&M的CRF跟Percentron的Structured SDN來解,到底哪一個比較好呢?
link |
RNN或LSDN它們有一個缺點,假設你今天用的是unidirection的單方向的RNN或LSDN的話,你在做決定的時候,你並沒有看完整個sequence。
link |
也就是說,在單方向的RNN裡面,你要產生第T的時間點的output的時候,你只考慮時間1到時間T的input,你沒有考慮時間T加1的input。
link |
也就是說,你在時間T的時候,你就已經把output丟出來了,如果你今天發現時間T加1的input會讓你想要改答案的話,已經覆水難收,已經來不及了,它output已經產生了。
link |
而產生output以後,你就不能再修改答案了,所以這是RNN的一個缺點。而這個是這些方法的一個優點,這些方法在做inference的時候,在產生結果的時候,它都是做determined algorithm。
link |
determined algorithm它做的事情是窮取所有的sequence,看哪一個sequence分數最大,而在計算那個分數的時候,它是看過一整個sequence的。所以跟單方向的RNN不一樣,單方向RNN只看了sequence的一部分,而這些方法在產生最終結果的時候,它都是看過整個sequence的。
link |
所以這個是它剩的地方。但是這個時候你可能會有一個問題了,那如果我用bi-directional的RNN或LSTM會怎樣呢?這個問題我不知道,我好像還沒有在文獻上看過說,bi-directional的RNN或LSTM跟這樣子用Viterbi解出來的方法,我們有可能得到什麼樣不一樣的結果。
link |
大家可能可以在之後的作業看看,你有沒有什麼心得。我在文獻上還沒有看過這兩個方法他們的機制的比較,研究說這兩個方法根據他們不同的機制到底會有什麼樣的優劣。
link |
所以這邊這個剩其實也是剩的有點牽強,所以我在這邊打一個問號。另外一個這些方法的優點是說,我們可以去明確的考慮output的sequence它的label和label之間的關係。
link |
什麼意思呢?假設你今天知道說在你的output sequence裡面,AA跟B這兩個elements是絕對不可能同時出現的,那你可以輕易地把這一件事情塞到Viterbi algorithm裡面去。
link |
舉例來說,在語音辨識裡面,中文都是initial接final,initial接final,就是生母接育母,生母接育母。所以生母後面就是要接育母啊,生母後面不能再接生母了。
link |
有這麼強的constraint,你可以把這個constraint直接塞到Viterbi algorithm裡面去。怎麼做呢?因為你可以說,我在做Viterbi algorithm的時候,我一面窮取所有的sequence,一面filter掉所有我覺得一定就是不可能的sequence。
link |
我在窮取所有sequence的時候,我只窮取那些符合我給它的constraint的sequence。比如說我做中文語音辨識的話,我只窮取那些initial後面接final,initial後面接final的句子。
link |
如果有一個sequence它是生母後面接生母的話,我就直接把它丟掉。這樣子的話,我們就可以把sequence裡面dependency的關係,explicitly地描述在我們的model裡面。
link |
當然RNN或LSDA如果你給它足夠的training data,或許它也可以把這項dependency的關係認進來,但是這樣dependency的關係如果它很明確的話,直接放到Viterbi algorithm裡面去,會不會直接比認得還要更容易一點呢?
link |
所以在這個地方我們可以說,或許這一系列的方法是勝的。好,那RNN跟LSDA還有一個問題,就是它的cost跟你要的arrow不見得是有關係的。
link |
已經有不只一個同學講過說,我們現在上課的evaluation,我們這個作業2的evaluation是any distance,然後你在training RNN的時候,你minimize的對象是cost function。
link |
你minimize cost function,不見得代表你會minimize any distance,而且甚至你minimize cost function,也不見得保證你一定會minimize你的每一個frame的accuracy。
link |
所以很多同學都已經觀察到這個現象,那確實這件事情並不是你的程式有寫錯,或者是你的training有什麼問題,RNN本質上就有這個問題,這個問題可能不是你在短時間之內可以解決的。
link |
而structured learning這一套方法,這一系列的方法,如果你使用structured SVM,那你的cost function就會是你的arrow的upper bound,這樣你是不是會讓你覺得在training的時候比較安心呢?
link |
當你的cost逐漸減小的時候,你的arrow很有可能是跟著cost一起減小,這樣可能讓你training的時候是比較安心的,所以這是它勝的地方。
link |
RNN到現在為止,都是這邊贏這邊輸。但是RNN或LSTM,有一個這邊沒有辦法比擬的優點就是它可以頂了,你可以疊很多層RNN或LSTM,這是它勝的地方。
link |
所以這邊有三個勝,這邊有一個勝。如果我們比較這兩個方法,最後誰比較強呢?其實都是左邊這個方法比較強,因為地盤太強了,這邊這些優點最後搞一搞就飛水車薪。
link |
你可能聽到這個就火大,就覺得說我們今天花了兩快兩個小時的時間在講這個其實會輸給RNN或LSTM的東西,早知道我今天就不來上課了。
link |
今天其實都跑跑完了,你應該是要出去玩了,你今天居然還來上課,我應該要感激涕零,但今天講一個沒有用的東西,你可能都要火大了。沒有關係,我們可以把剛才左邊的這些方法跟右邊的方法加起來。
link |
怎麼加起來呢?你的model現在就像是一個蘿蔔,它在地底下是很深的,然後上面露出一點葉子讓你扒。
link |
就是我們的model的底層是RNN或LSTM,它們可以deep,它們就像是埋在這個土裡的蘿蔔一樣,它們很深很深。然後在葉子的地方,我們都HANFCI Structure Percentile或者是STM。
link |
你就可以讓它們發揮它們的優勢,因為它們可以去明確地描述dependency的關係,而且如果你是直接去使用Structured SVM的話,你的cost function還是你的arrow的upper bound。
link |
所以當你去minimize這個Structured SVM的cost function的時候,你其實是minimize你的arrow的upper bound,那你可以讓這個東西跟這個東西一起trap,那這樣你就可能可以得到比較好的結果。
link |
也就是說這個蘿蔔它的主體是RNN或LSTM是deep,那最後它有一個把手,這個把手就是這些東西,然後讓你可以把這個deep的部分把它拔出來。
link |
所以現在大部分state-of-the-art的系統,就你想要在這種secret laboring的test上面得到state-of-the-art最好的performance的話,光用這個是不夠的,你都要用這個蘿蔔的架構才可以得到最state-of-the-art的結果。
link |
舉例來說,我們以語音辨識為例,那做語音辨識的人呢,現在都會很自豪地講說我們用deep learning,我們不用HNN,其實那是騙你的,我們都還是有用HNN,怎麼用的呢?
link |
就是我們都是把不管你是用CNN、RNN或LSTM,或者是DNN,或者是你把這些東西通通接起來以後,我們最後都還是會把它接給HNN,只是我們最後apply了這一段而已。
link |
事實上那些commercial system,比如說Google的voice search,他們也都是用這種架構來真正實作語音辨識這一件事情的。那你可能會想說這個東西要怎麼做呢?其實很簡單。
link |
我們剛才說呢,根據HNN的model,P of X,Y就是這樣子,對不對?就是有transition probability跟emission probability。那我們把HNN的emission probability,也就是P of X given Y用DNN、RNN或者是LSTM得到的結果呢,去取代掉。
link |
那大家在作業一或作業二裡面,你可以做到什麼事情呢?你可以說我用RNN或DNN把一個input的acoustic feature XL變成一個機率的分布嘛,對不對?
link |
這是大家在作業一或作業二所做的事情。那你可以把這個機率的分布就直接塞在這邊,當作HNN的機率,然後再做HNN就結束了。那這樣子你可能會有一個讓你覺得不安的地方就是,這邊是P of X given Y,這邊是P of X given Y,這邊是P of Y given X,他們的方向不一樣啊。
link |
大家有發現嗎?有沒有讓你覺得很不安?那沒有關係,我們就做一個小小的改變。我們要的是P of X given Y嘛,我們要的是P of X given Y。
link |
那P of X given Y呢,我們可以把它寫成P of XY除掉P of Y。然後呢,P of XY呢,又可以寫成P of Y given X乘上P of X。有沒有發現說,我們剛才從DNN、RNN所算出來的P of Y given X就出現在這邊。
link |
所以我們就把RNN塞到這裡。然後呢,這個P of Y怎麼辦呢?P of Y就是你的那個Label,比如說你的某一個Form、某一個State,它出現的機率。
link |
那你就直接從你的training data去count一下,某一個Form或某一個State出現的機率比較好的嗎?所以P of Y也難倒你。再來最卡的地方就是,P of X怎麼辦呢?這邊的每一個feature,我們要怎麼算它出現的機率呢?
link |
同樣的feature根本不可能出現兩次啊,我們要怎麼算P of X的機率呢?這個方法很簡單,就是不要管它。為什麼不管它呢?因為你可以想想看,我們正正在用HNN做Inference的時候,我們是given X看哪一個Y可以讓這個機率最大。
link |
所以X是給定的,不管這個P of X的值是多少,它都不會影響你最後得到的Y是誰了。所以這個X呢,你是不用理它的。
link |
第一次聽到這整個架構,你可能心裡覺得怪怪的,但說不出來哪裡怪怪的。我可以跟你講,現在commercial system,比如說voice search,都是用這樣子的架構做的。這樣的架構或許讓你心裡聽起來有點不安,但它是work的。
link |
很多人會想一些別的方法,想說我怎麼去improve這個想法,但那個improvement都非常的有限,所以現在state of the art system還是使用這樣子的架構做的。
link |
或者是呢,你可以把Bidirectional的RNLSTM加上CIF或Structured LSTM。這樣的方法現在在這種tagging的方法,比如說POS tagging,或者是Semantic tagging,或是soft filtering這種test裡面呢,是非常常見的。
link |
也就是如果你要得到state of the art的方法的話呢,你要把RNLSTM加上structured learning的方法。那怎麼做呢?你可以說,OK,我現在把我的input feature通過底盤的RNLSTM,那它可能是Bidirectional,我這邊沒有畫出Bidirectional,然後得到一組新的feature。
link |
然後我背上我這組新的feature去抽出final XY,我現在的X不是這個input的X,而是這組新的feature,從RN、DNN的output的X。然後呢,我把這個W跟final XY去相乘,當作我的evaluation function。
link |
所以呢,在inference的時候,在testing的時候呢,我是去找一個Y可以讓W跟final XY的E發達最大,而這個X呢,是來自於RN的output。
link |
而在training的時候呢,我可以用braided descent,讓W跟這邊所有的RN的參數一起train。那最後呢,就是我們今天的結論。
link |
我們今天的結論是這樣啦,我們講了好幾種不同的可以處理sequence lagging的方法,那他們呢,都解了三個問題。那在problem 1裡面,我們要定一個evaluation function,三個方法定evaluation function的方式都不一樣。
link |
H&AN說是P of XY,CRF說是P of Y given X,然後percentron的SBN,他們都跟機率沒有關係。那在problem 2呢,大家都用Viterbi algorithm。
link |
那在problem 3呢,H&AN就是統計,CRF呢,要去maximize這個機率,而structure percentron呢,要讓正確的分數大過錯誤的分數。
link |
而且要大過一個margin。那最後呢,我們都可以把這些方法加上deep learning,然後讓他們變得更powerful。那我在這邊呢,休息一下。