back to index
Deep Learning Theory 1-1: Can shallow network fit any function?
link |
今天要講說為什麼我們要用deep的structure。
link |
相較於shallow的structure,deep的structure到底好在哪裡。
link |
所以今天這份投影片的開頭,如果翻成中文的話,它就是深度學習是不是過於了。
link |
好,那我們來複習一個大家也許都知道的東西,讓大家可以比較很快的進入狀況。
link |
之前在machine learning的課程裡面,我們有講過說,其實每一個network都是一個function。
link |
給你一個network的structure,這個network裡面,如果每一個參數,也就是每一個neuron的weight跟bias你都知道的話,那這一個network代表了一個function。
link |
同樣的structure,填入不同的參數,它的neuron填入不同的weight跟bias,那我們就得到不同的function。
link |
那如果你現在給定一個structure,你可以填入不同的參數,那你其實得到的就是一個function的set。
link |
或者是講得更精確一點,因為今天我們可以填的參數其實是連續的,你可以填各式各樣不同的參數,這些參數的數量是無法窮舉的。
link |
所以你其實得到的是一個function的space。
link |
所以今天給我們一個network的structure,當我今天在這個課程裡面,我講到network的structure的時候,我指的就是一個network的架構。
link |
你決定了neuron怎麼連接,但是你沒有決定neuron的參數。
link |
當我們給一個network的架構的時候,我們其實就是在所有可能的function裡面畫一個範圍,畫一個function的space,我們用一個network的架構就定義了一個function的space。
link |
那deep為什麼比較好呢?如果假設有人告訴你說,deep比較好就是因為參數比較多、資料量比較大等等,那個其實是一個外行的講法。
link |
那在文獻上你常常可以看到這樣子的結果,給定一個固定的function,假設給定這個function叫做f of x等於兩倍的cos x-1-1,其實我們在作業一之一裡面就是要各位同學做類似的事情。
link |
好,那給定一個固定的function,接下來我們自己兜不同架構的network,然後去train這個network,想辦法讓這個network跟你現在目標的function越接近越好。
link |
你就從這個目標的function裡面sample一些值當作training data,然後去train一個network,然後希望這個network跟這個目標的function越接近越好。
link |
那你會兜不同的network架構,比如說一個hidden layer的network、兩個hidden layer的network、三個hidden layer的network。
link |
但是在比較這些network的時候,注意,不同架構的network,你會希望它們有同樣的參數。
link |
而你會調整不同的架構,讓它們有不同的參數,但是你今天在比較的時候,你會希望拿同樣參數量的network來進行比較。
link |
舉例來說,左邊這個圖是說用不同的unit來表示你的架構,右邊這個圖是用不同的參數量來表示你的架構。
link |
等一下在課程裡面,我們通常在討論的時候,我們都用unit的數目,所謂unit的數目指的就是neuron的數目,用neuron的數目來表示一個network的架構。
link |
只不過neuron的數目跟參數的量是正相關的,所以你用neuron的數目來表示一個network structure,跟拿參數的數目來表示一個network structure,所以得到的分析的結果會是大同小異。
link |
你今天其實可以觀察到這樣的結果,在作為easy裡面就希望大家驗證一下這件事情。今天在同樣的參數量下,去fit同樣參數的時候,你會發現比較深的network,它是可以fit的比較好。
link |
或者是假設你橫著看,你希望你今天的networkfit你的目標的function到某一個精確度,這個時候deep的network需要的參數量是比較少的。
link |
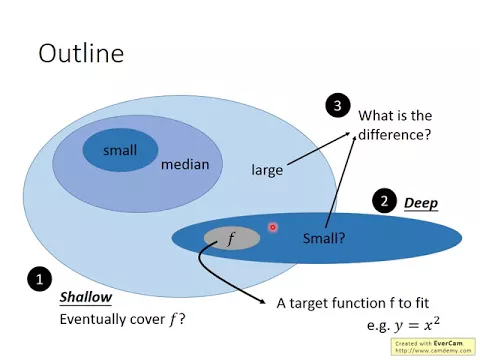
所以接下來我們就是要討論為什麼會這個樣子。今天講的這個課程的outline大概是這個樣子,首先我們會告訴大家說,其實shallow的network就可以fit任何的function。
link |
但是接下來告訴大家說,雖然shallow的network可以fit任何function,但是deep的network它有什麼樣的優勢。然後接下來告訴大家說,假設我們用deep的network想辦法去fit一個function的時候,看起來像是什麼樣子。
link |
就拿shallow的network去fit一個function,跟用deep的network去fit一個function有什麼不同。最後再告訴大家說,deep會是比shallow還要好的。最後很快地告訴大家,現在在deep learning的community,一些有關network的structure,有關已經有的理論。
link |
在以下的討論裡面,為了讓等一下的說明比較方便,所以如果沒有特別強調的話,我就假設我們今天討論的是一個relu的network,就我們的network裡面它的activation function都是relu。
link |
用relu來討論其實是非常合理的,因為現在大部分的network都是用relu來train的,其實已經很少用sigmoid了。然後今天為了簡化等一下的討論,我假設輸入只有一個scatter,輸出也是一個scatter,當然中間可以有很多個hidden layer。
link |
然後為了討論方便起見,我假設輸入的input domain就一定落在0到1之間。我們假設這個network輸入的數值是0到1之間一個數值,輸出是另外一個數值。
link |
好,那等一下我們要回答三個問題。第一個要回答的問題是說,假設我們現在有一個目標的target function f,我們希望network去fit這個f,也就是說我們可以用network去製造出一個function。
link |
我們希望我們找到一組參數,使得network製造出來的function跟我們目標的target function f越接近越好。好,那這個目標的target function等一下在討論的時候,我們常常會用y等於x平方,當然你也可以選擇更複雜的function。
link |
好,那第一件我們要說明的事情是,當然如果今天有一個shallow的network,這個shallow的network它非常的小,也它非常小,所以它cover的function的space是比較小的。它沒有cover到這個target function,所以你用這個在這個shallow的structure裡面去找尋一個最好的參數,你找不到任何方法可以讓一個小的小又shallow的network它可以fit這個target function。
link |
那等一下要告訴大家的是,假設這個shallow的network它很大,它越來越大,就增加它的參數量,或者是說增加它的neuron的數量,讓它的neuron的數量越來越多,最終它一定可以去fit我們給它的一個target function。這是第一個要跟大家說明的事情。
link |
好,那第二個要跟大家說明的事情是說,假設現在換成deep的structure,那用deep的structure去fit這個target function會有什麼不一樣?第三個就是最關鍵的,假設我們用shallow的structure去fit這個function,跟我們用deep的structure去fit這個target function有什麼不同?
link |
當然我們希望的結果是deepfit同樣的function,deep需要的參數量是比較少的,而shallow的參數量是比較多的。但這個少跟多中間的差距到底差多少,等一下是要跟大家說明的。
link |
那最後有一件事情在今天的討論中要先跟大家提醒的就是,我們今天只討論能不能夠fit target function。有兩件事情我們是不討論的,第一個就是optimization,我們是不討論的。
link |
我們不討論說今天給你這個function的space,你要怎麼找到這個app。我們知道說你在train level的時候你用的都是gradient descent,那所以今天在train level的時候,就算你的這個function set有function的space有包含這個target function,用gradient descent也不保證你一定可以找到這個function。
link |
所以我們今天不討論這件事,我們假設只要function的space可以包含target function,那麼一定就可以找到這個最佳的solution,我們就可以在這個space裡面找到一個function,它是跟這個target function最接近的,所以我們不討論如何做optimization這件事。
link |
我們也不討論general,這邊寫錯了,為什麼寫成generation呢?我想要講的是generalization,所謂generalization的意思是說,我們知道在train這個做,做machine learning的時候我們分成training set跟testing set,那這邊這個所謂的function,這個target function是根據你的training set定出來的,它不見得能夠apply在testing set上,那麼現在我們也不討論這件事。
link |
好,那我們就進入今天的第一個主題,是不是shallow的network就可以fit任何的function?那大家可能都知道shallow的network可以fit任何的function,因為有一個理論叫做universality的theory,它就告訴我們說,其實任何continuous的function,我們都可以用一個只有一個hidden layer的network來fit它。
link |
我們過去在machine learning的課程裡面也已經強調過這件事情,但是過去沒有講過的事情是怎麼證明這件事,我們只有用講的直接告訴大家,這件事情是可以做到的,但卻沒有證明給大家看說這件事情是如何辦到的。
link |
所以你可能想說,也許我是騙你了,這個shallow的network其實沒有辦法fit任何continuous的function,而且我們今天就是要真的來講一下shallow的network如何fit任何continuous的function。
link |
那我們今天shallow的network它用的activation function是relu,一個由relu的activation function所組成的network,它的定義出來的function,它的長相都會是piecewise linear,為什麼呢?
link |
因為我們知道說,今天你input一個數值x,通過第一個relu的activation function,那你得到的output可能就是長這個樣子,那只是隨著你這邊的參數的bias的不同,這個轉折的地方可能會不一樣,這個斜線可能會有不同的斜率,所以這個relu它的output可能是這個樣子。
link |
那在output layer,我們現在講是output layer就沒有activation function,output layer就是把唯一的這個hidden layer的每一個neuron的output把它weighted上起來,那因為每一個neuron的output長得都像是這個樣子,那做weighted上以後呢,它就是一個piecewise linear的function。
link |
反正它就是由,如果你不知道piecewise linear指的是什麼的話,反正就是由relu所組成的function,由relu的neuron所組成的function,它都是由一個一個線段所構成的。
link |
好,那我們接下來要講的就是說,給一個alolysis的function,然後這邊寫做f star,等一下告訴大家alolysis的function指的是什麼意思。好,給了某一個alolysis的function f star,我們需要多少的neuron才能夠用network製造出一個function,這個function能夠approximate我們目標的function f star。
link |
等一下會告訴大家說,這邊所謂的approximate指的是什麼意思。好,那我們先來看什麼是alolysis的function,也許很多人都知道,那我們就是很快地複習一下。
link |
alolysis的function指的是說,在講定義之前,它的觀念上就是這是一個比較smooth的function。alolysis的function的定義是這個樣子的。假設給兩個x,x1跟x2。
link |
alolysis的function的output,f of x1跟f of x2,它們之間的distance會小於等於x1和x2之間的distance乘於L倍。
link |
這意味著說,你的output的變化會被bound在某一個範圍之內,就你input從x1移到x2的時候,它output的變化一定會小於L倍的x1減x2,代表它output的變化是沒有辦法太大的。
link |
所以它是一個比較smooth的function。假設今天L等於1的話,就是alolysis的function,L等於2就是qolysis的function,以此類推。
link |
所以今天假設一個function是alolysis的function,就是這邊L代1,意思就是說,你input有一個變化的時候,output的變化不可以大過input的變化,output的變化一定要小於等於input的變化。
link |
所以像今天這種,像藍色這條曲線是一個變化非常快的曲線,它可能就不是一個one-lysis的function。
link |
那綠色這條直線呢,它的變化是比較慢的,input的輸出的變化小於輸入的變化,那它是一個one-lysis的function。
link |
好,那今天講了我們的target function長什麼樣子以後,接下來要告訴大家的是所謂的approximation,approximation這邊指的是什麼意思?
link |
這邊的approximation指的意思是說,首先我們先定了一個network的架構,今天在講一個shallow的network的時候,在以下課程裡面當我說一個shallow的network的時候,我指的是指我這種一個hidden layer叫做shallow的network。
link |
好,那今天我們先定一個network的架構,今天用N of K來表示一個network的架構,這個K指的就是這個shallow的network它的neuron的數目。
link |
那我們知道說,一個network的架構其實定義了一個function的space,然後F是這個function space裡面的其中一個function。
link |
好,那所謂的拿這個network去approximate F star的意思就是說,給一個很小的number,這個很小的number是一個epsilon,這個epsilon大於0,就給一個epsilon。
link |
那我們這個K需要設多大,我們需要設什麼樣的network的架構,才能使得在這個function space裡面存在某一個F。
link |
這一個F這個function跟F star這個function,它們之間的差距小於等於epsilon,那我們只考慮X在0到1之間的情況。
link |
也就是說,我們希望說,今天找到某一個K,然後這個K就定義了一個function的space,在這個space裡面,我們找得到某一個function,這一個function它和我們目標的那個function,它們之間的差距不會超過epsilon。
link |
也就是說,假設F star是下面的這條藍色的曲線,然後你希望在你的function space裡面找到一個K,然後它決定了一個function space,然後在這個function space裡面,你找得到某一個function,這一個function和我們的目標F star之間的差距,
link |
最大的差距就是這個綠色的這個曲線,它一定要小於等於某一個給定的epsilon。
link |
那epsilon是給定的,就給你epsilon,然後接下來問你說這個K應該要有多大,才能夠讓下面這件事情發生,這個是我們這邊講的approximation的意思。
link |
那有同學可能會想說,這邊取的是maximum,那有人可能會覺得說,maximum只有討論一個點會不會不太夠,也許他比較喜歡算這個L2-norm,也許他比較喜歡算L2-norm或者這個Euclidean norm。
link |
他可能比較喜歡,他可能想要做的事情是說,他希望找到某一個function f of x,它跟F star of x之間的距離的平方,然後從積分從0到1再開根號,會小於等於epsilon。
link |
但是如果上面這一個條件被滿足的話,其實下面這一個條件也等於是自動被滿足了,對不對?這件事情其實非常的直覺。
link |
假設現在這個f-f of star,我們把它寫作一個function,f of x-f star of x,我們把它的絕對值,我們把它寫作一個function,長得是這個樣子。
link |
我們在下面這邊的說明,是希望說這個function的最高點小於等於epsilon,那如果你今天算的是L2-norm的話,其實你想要做的事情是希望你從0到1之間的積分小於等於epsilon,
link |
也就是你希望這個面積是小於等於epsilon,那如果今天maximum的地方都小於等於epsilon,那你今天這個又是0到1,那你的面積其實就自動小於等於epsilon了。
link |
所以我們並不需要特別討論下面這個case,只要上面這個case做到,下面這個case自動也可以做到了,所以我們就只討論上面這個case就好。
link |
好,那這件事情要怎麼辦到呢?我們知道說今天不管這個k我們設多少,我們得到的都是一個piecewise linear的function,我們得到的那個function,我們在這個function space裡面的function,它都是由很多線段所構成的。
link |
那所以今天我們要用某一個function F去approximate F star,意味著說我們要找到一個piecewise linear的function,它可以去approximate F star。
link |
那所以等一下我的講法是說,我們先看看怎麼使用piecewise linear的function去approximate某一個function F star,我們怎麼用piecewise linear的function去approximate某一個function F star。
link |
再回頭過來看說,如果要製造這樣的piecewise linear function,這個k應該要設多大才能夠製造這樣子的piecewise linear function。
link |
好,那要怎麼用piecewise linear function來approximate某一個function F star呢?我們假設我們F star就是圖上的這一條線,那怎麼用piecewise linear function來fit它呢?你就在這個F star上面點一些點,就點很多綠色的點,然後再把這些綠色的點連起來,你就得到一個piecewise linear的function。
link |
接下來我們希望這個piecewise linear function它的arrow是小於等於epsilon。
link |
因為我們剛才有說,所謂的approximate就是我們給一個epsilon,那你得到的這個piecewise linear的function,它跟你的target function之間的差距要小於等於epsilon。
link |
那這件事情要怎麼計算呢?就假設我們今天有一個piecewise linear的function,我們就是在這個F star上面點一些綠色的點。
link |
當然我們今天點了一些綠色的點,得到一個piecewise linear的function以後,這個piecewise linear的function跟我們的target function中間一定是有一些差距的,尤其假設你的target function它不是piecewise linear,它是continuous,你的piecewise linear function不可能跟你的target function長得完全一模一樣。
link |
它們中間會有一些arrow,但是這些arrow到底有多大呢?我們先算一下這些arrow到底有多大,然後再想辦法安排這個綠色點的位置,讓這些arrow可以小於等於epsilon。
link |
那這些arrow到底有多大呢?假設我們現在有兩個點之間的距離,我們寫作L,那其實這個arrow一定會小於等於小L乘上大L。
link |
這個小L是這兩個點之間的距離,這個大L是什麼?這個大L是L-listed function的這個大L,因為我們的F star還是有一些限制的,它是一個比較smooth的function。
link |
有了這個限制以後,我們就可以知道說它的這個arrow一定小於等於小L乘上大L。那為什麼會這樣呢?其實這件事情也是蠻直覺的,我相信你坐下來想一想,三秒鐘後你其實就已經知道了。
link |
那我們其實還是可以跟大家說明一下。你看,今天假設我們就考慮這個L的這個區間,它可能長的是這樣之類的,像是這個樣子。
link |
好,那這個線段之間的距離是L,那我們今天如果找出這個區間的最高點跟這個區間的最低點,那它們的距離一定是比L還要小,對不對?它們的距離一定是比L還要小。
link |
那這個區間的最高點跟這個區間的最低點,它們的差距,這個差距到底會有多大呢?這個差距到底會有多大呢?因為它們兩個之間的距離小於,它們兩個之間的距離是小於L的。
link |
那我們知道說這是一個alysis的function,如果input的變化是小於L的,output的變化一定要小於這個小L乘上大L,對不對?因為它是一個alysis的function。
link |
所以input的變化有小L,output的這個變化一定要小於小L乘上大L。所以今天在這個區間裡面的最高點跟最低點的差距是小於小L乘上大L。
link |
那今天我們把這個區間的頭跟尾連起來,要算說今天這個線段,這個線段也許我畫個綠色的,要算這個線段跟藍色這條實線最大的差距,一定會比這個綠色的線段的最高點跟最低點之間的差距還要更小。
link |
所以今天你的error它一定會小於小L乘上大L。這個大家可以接受嗎?有人不能接受嗎?那這是一個upper bound,在實際的情況下你的差距可能是小於小L乘上大L的,但是最大你不會大過小L乘上大L,對嗎?
link |
假設你可以接受這件事的話,那其實就結束了,對不對?其實就結束了。我們只要讓小L乘上大L,它比給定的這個epsilon還要小,就結束了。
link |
那怎麼讓這一項小於epsilon呢?大L是你不能夠操控的,但小L是你可以操控的。你要做的事情,因為大L是給定的,這個就是給定的某一個L list的方向,它是給定的,它是你不能夠操控的東西。
link |
但是小L是你可以操控的,其實是你可以操控的東西。我們只要讓小L越來越小,那這個error就會越來越小。我們希望這個小L越來越小,小到可以讓這個error一定小於等於epsilon。
link |
所以我們只需要列這樣一個式子,我們希望小L乘上大L小於等於epsilon。那意思就是說,我們希望我們的小L,也就是我們的這個點和點之間的距離,一定要小於等於epsilon除以大L。
link |
所以今天假設我們要用一個piecewise linear的function去fit一個L list的function,只要這個點和點之間的距離小於等於給定的epsilon除以L。epsilon是我們要求要多fit的那個限制,那個error。
link |
然後L是代表list this function的這個,我們給定的target function的複雜的程度。只要這個L小於等於這個數值,那我們就可以滿足上面這一個條件。
link |
所以我們知道說,我們希望我們的L一定要小於等於epsilon除以大L。所以今天隨便給你一個list this function,L list this function,F star,你要找一個piecewise linear的function,讓它的error小於等於epsilon,就給你epsilon。
link |
那你希望你得到error小於等於epsilon,怎麼做?你其實完全不用任何複雜的數學秒做,因為你只需要在取這個線段的時候,它們之間的距離你都設epsilon除以L。這樣你就可以滿足它的條件,你就可以讓你的error是小於等於epsilon。
link |
好,那今天假設我們的每一個這個區間的這個寬都是epsilon除以大L的話,那在0到1的區間之內,我們會有多少個segment呢?會有多少個,它是一個piecewise linear的function嘛,會有多少個piece呢?會有大L除以epsilon的piece。
link |
好,那我們現在知道說,我們只要做出這樣的一個piecewise linear的function,我們就可以fit我們的target function,讓它的error小於等於epsilon。
link |
接下來問題就是,有沒有辦法製造出一個network,就用一個heaven layer,它的excavation function都是reduce,就製造出這樣子的piecewise linear的function。是,可以的,因為非常的trivial這樣,這個也是,秒想一下你就知道了。
link |
怎麼做?怎麼做?就這個,這個不見得是最好的方法,就只是一個方法而已。怎麼做呢?好,現在有大L除以epsilon的片段。
link |
好,然後呢,我們今天呢,看一下這樣子的piecewise linear的function,我們可以拿另外一堆function呢,去加起來,就變成上面這個綠色的線段。
link |
怎麼做?我們看這個第一個點有多高,然後呢,根據第一個點的高度呢,畫一條橫線。
link |
接下來呢,我們再把這個線段拿來把它擺在這邊,然後前面呢,就把這個線段拿來擺在這裡,那開頭的地方就都放零,然後結尾的地方呢,就看它有多高就放多少的值。
link |
接下來呢,我們就畫一個這個,其實我也不太確定這樣的function應該叫什麼,它也不是一個梯形,就畫一個三坡的function。
link |
好,那同樣的道理,就你可能覺得這個很無聊了,就把這個線段拿到這邊,然後再製造一個三坡的function。
link |
你只需要把這些藍色的function通通疊起來,就可以產生這個綠色的function。
link |
那接下來呢,就是要告訴你說,其實這邊每一個藍色的function,都可以輕易地用兩個relue的neural,就可以組成這邊每一個藍色的function。
link |
那這個橫線呢,其實更簡單就不用理它,它就是在output的地方最後用一個bias,就可以製造這條藍色的線。
link |
所以,你可以輕易地找到一個relue的組成的network,然後呢,它bias的地方呢,去產生這條藍色的線,然後呢,在這個relue的那個hidden layer裡面,每兩個neural,它就產生一個這樣子的三坡的function。
link |
每兩個neural就產生一個三坡的function,那所有的neural最後全部加起來,你就得到這個piecewise linear的function,你就可以去fit你的target的function,然後就結束了。
link |
你就證明了說,我們今天一定可以拿relue的function去fit你的那個alysis的target function。
link |
好,那接下來就是要講說,怎麼用兩個relue就製造出這樣的function呢?其實這個也沒有很難。
link |
我們這邊就舉個例子來跟大家說明,假設我們要製造的三坡的function呢,第一個轉折點就在開始上坡的時候是三分之一,走到三頂的地方是三分之二,然後三頂的高度是二。
link |
好,那怎麼用兩個relue就達到這件事情呢?怎麼兩個relue就達到這件事情呢?這個非常的簡單。
link |
我們需要有第一個relue,我們需要第一個relue的function,它的output就是長這個樣子,ok?就是長這個樣子。
link |
我們今天需要的就是兩個這種,這種function其實就叫ramp function啦,我們需要兩個這種ramp function,然後呢,第一個ramp function它的轉折點在三分之一的地方。
link |
第二個ramp function它的轉折點在三分之二的地方,然後把第二個ramp function把它倒過來,乘上一個符號。
link |
好,所以第一個ramp function叫做function1,倒過來的ramp function我們叫做function2,我們把function1跟function2加在一起,我們其實就可以得到左邊的這一個三坡的function了。
link |
所以我們接下來的任務只是說,有兩個neuron,其中一個去負責產生1,另外一個負責產生2,然後再把它們的結果加起來,就結束了。或者其實是相減啦,那相減就只乘著符號加起來,就結束了。
link |
好,那怎麼讓第一個neuron產生這個東西呢?那你就湊一下數字這樣,國小數學,你可以check一下我有沒有算錯這樣。如果你發現錯影片上有錯的話,就跟我講,把你的名字加在錯影片的旁邊。
link |
好,你們看一下哦,我們只要x進來的時候乘上9,然後bias設-3,然後output就會是這個ramp function,因為它轉折的地方在三分之一嘛,我們今天把三分之一帶進來,三分之一乘9等於得到3,再減掉bias-3得到0,所以是在轉折的地方。
link |
在三分之二的地方應該要升到2這個數字,好,把三分之二帶進來,哦,會不會算錯了?
link |
誒,真的算錯了誒,我看看哦,因為走到三分之二的地方,它的值應該要是2,但我可能本來想要寫的是3,但不知道怎麼回事,它就變成2了這樣子。
link |
好,我們再看看這邊有沒有算錯,如果我今天帶三分之二進來,帶三分之一二進來,它是0,但是今天我帶三分之二的時候,這邊的輸出應該要是2,但是它今天帶三分之二進來的時候,它的輸出其實是3,我只要把這邊的這個2把它改成3就可以了這樣子。
link |
可能我本來是想要寫3的,不知道為什麼它就變成2了,好,這個應該是3啦,抱歉抱歉抱歉,這個應該是3,好,那沒關係,這個大家都聽得懂就好了。
link |
好,所以第一個這個ramp function由上面這個redu生成,第二個這個ramp function由下面這個redu生成,那你只要把它的輸出代成-1,它就倒過來變成這個樣子,好,那把1跟2加起來,輸出就是這一個function了,就這樣,就是這麼簡單。
link |
好,那接下來要做的事情是,這邊有好多個像山坡形狀一樣的function,所以你就把x丟進去,用兩個redu產生y1,再用另外兩個redu產生y2,再用另外兩個redu產生y2,然後再用另外兩個redu產生y3。
link |
那你再把y1、y2、y3通通都加起來,y0的部分你用一個bias來處理就可以了,那最後你就得到最終的輸出y,你就得到這一個piecewise linear的function。
link |
有人可能會說,這個算不算是多加了一層啊?這個當然不算是多加了一層,因為我們雖然是說,我把這兩個加起來變y1,這兩個加起來變y2,再把y1跟y2加起來變y,但是意思跟我們直接把這些東西通通加起來變成y,其實講的是同一件事。
link |
所以並沒有,希望大家可以了解我的意思,我並沒有多加一層,它還是只有一個neat layer加一個output layer而已,這邊通通合起來就是output layer。
link |
好,那所以今天講到這邊,大家學到的東西是說,現在有一個L-Lysis function,那我們要如何approximate這個L-Lysis function,讓它的error小於ε呢?
link |
我們需要大L除以ε的segment,每一個segment我們需要兩個neural,所以我們總共需要兩倍的大L除以ε的radial neural就可以approximate一個L-Lysis function。
link |
但這邊要強調的事情是,這邊只是說可以做到,沒有說這個是最有效率的方式,你永遠可以想想看有沒有更有效率的方式。而這個結果看起來是非常合理的,因為L-Lysis的這個L越大代表那個function它的變化越快,它是一個越複雜的function。
link |
它是一個比較複雜的function,你可能本來就需要比較多的neural才能夠fit它。而ε代表說你今天fit的那個accuracy有多大,ε越小代表說你今天要求的精準度越高,ε越小,你需要的neural越多,就是你需要的精準度越高,你當然需要越多的neural才可以達成你要求的精準度。
link |
好,那講到這邊只是告訴大家說,反正我們任何的L-Lysis的function,我們都可以用一個hidden layer的ReLU就可以去approximate它。