back to index
Deep Learning Theory 1-3: Is Deep better than Shallow?
link |
所以接下來就是要看的就是shallow的network潔淨權利的狀態。
link |
好,那我們剛才反覆講過很多遍了,一個relue的network就是一個piecewise的linear的function。
link |
我們現在要討論的就是,因為我們知道說,如果是一個shallow的network,每一個piece我們都需要至少一個neuron才能夠製造出一個piece。
link |
所以今天piece的數目越少,需要的neuron就越少。如果我們要想辦法fit y等於x平方的時候,到底最少要多少的piece才能做到這件事情呢?
link |
好,那我們剛才在討論的時候,我們在製造這個piecewise的linear function的時候,我們都是把我們的目標的function,是紅色這一條,目標嗎?紅色這一條拿出來,然後在上面取幾個點,然後把這些點連起來,就說這個是我們要去fit target function的piecewise linear的function。
link |
那能不能做得更好呢?我們假設,其實是可以做得更好的,怎麼樣做得更好?我們不要讓這些線段呢,它的頭還有尾跟紅色的線相接,對不對?
link |
因為這邊這個黑色的線段,我們之前在做的時候,我們都強迫它的頭跟尾一定要跟我們目標的線,假設我們現在目標的線是y等於x平方,我們就假設它的頭跟尾一定要跟目標的線接在一起。
link |
那我們現在能不能夠把這一條線把它往下挪一點,不要讓它們的頭接在一起,不要讓它們的尾接在一起,因為如果你這樣做的話,你從這張圖上直覺一看就知道說,這個error比較大,這麼做其實error是比較小的。
link |
當然你可能會問說,左邊這個狀態是確實可以用ReLU產生這樣子的network的結構,但右邊這個狀態,這邊有一個非連續的東西,ReLU能夠產生非連續的output嗎?
link |
你仔細想想,應該是沒有辦法的。沒有關係,這個就是它的夢幻狀態,就是它在夢中可以使出彗星的一擊。雖然實際上它只能這樣搞,它一定要每一個線段都接在一起,因為它必須要是連續的,但是我們就假設夢幻的狀態是不需要連續的。
link |
反正就先看看,如果在不需要連續的狀況下到底需要多少個片段,在不連續的狀況下到底需要多少個片段,我們才能夠去fitX平方這個function。所以這是夢幻的狀態。在夢幻的狀態,我們可以有比較小的error。
link |
另外,我們之前有講過說,今天滿足上面這個條件,就自動滿足了下面這件事情。滿足下面這件事情,不見得滿足上面這件事情。
link |
因為你這邊是,它們兩個最大的差距小於等於ε,所以平均這個積分可以看作平均,平均會小於等於ε。但是平均小於等於ε並不代表它們最大的差距小於等於ε。
link |
好,那沒有關係,我們現在不要管這一項,不要管最大的差距,我們只看平均能不能小於ε。跟剛才我們狀態不一樣,不太能比,沒關係,這個就是再給Shadow的內部一些benefit這樣子,就好像說他的裁判通通都是自己人這樣,就給他各種不同的優勢,各種不同的不可能達成的夢幻的狀態,看說在這種給他這麼多的優勢的情況下,他到底可以做到多好。
link |
好,所以我們現在呢,我們不考慮max,我們不考慮max,我們只考慮這個積分的結果,我們只考慮他的這個Euclidean的null,好,這個就是Euclidean的null。
link |
好,那接下來呢,接下來我們現在要問的問題是,假設這個紅色的線就是y等於x²,然後在上面呢,取一個線,取一個片段,這個片段的長度是L,它的起始是x0,它的終止的位置是x0加L,而它的長度呢是L,然後我要用某一條直線去fit紅色的這個y等於x²,我到底可以fit多好呢?
link |
這條直線就如我剛才講的,是一個夢幻的狀態,不需要頭對頭,不需要尾對尾,這個直線可以是任何一條直線,到底在給定L的狀態下,可以fit到多好呢?
link |
那你可以想像說,我們其實就是解這樣一個問題嘛,我們就算說,積分從x0到x0加L,積分從x0到x0加L,好,然後呢,我們要算x²,就是紅色這條線,跟ax加b,也就是某一條直線,a跟b的值是多少,我們還不知道。
link |
x²跟x加b這條直線,它們的差距的平方和,就得到了它的這個arrow的平方,好,那你就想,我們就是要算這一項,然後找出一個a跟b,可以讓1的平方的值呢,最小,然後接下來啊,你就是怒算一波,你可以回去check一下,我有沒有算錯,算出來是,我的5次方除以180這樣子。
link |
如果這個是不對的,你再告訴我這樣子,好,我就不要把計算過程寫出來了,不然你會聽了,你等一下就生氣了這樣子,那個是,我的5次方除以180這樣,這個也就是說今天在,這個結果其實還蠻神奇的,就是給一個線段,它的長度是L,
link |
在,如果我們今天考慮的是,y等於x²,在任何區間裡面,它的誤差都只跟L有關,它的誤差最小就是L5次方除以180,大概是怎麼做的呢,這邊給大家一些方向,那如果這一段你沒有聽懂的話,就沒有關係,我扭的map就是你沒有聽懂就算了的意思。
link |
大家記不記得我們在線性代數的時候,我們這樣學,我們學說,有兩個function叫做w跟u,然後我們希望把w跟u做linear combination,找一個w跟u的linear combination,結果aw加b,然後希望這個新的linear combination出來的vector跟v的距離越近越好,那怎麼找呢?
link |
我們就是找出w跟u它們展開的那個space嘛,你要找,就假設u跟w就是,它們是orthogonal basis的話,你就可以直接展開這樣子,那如果不是你就另外想辦法,反正就是把u跟w展開成一個basis,展開成一個basis,然後把vproject到那個basis上面,你就可以知道aw加bu是哪一個了,就這樣,我們在線性代數學。
link |
那其實在線性代數課本的最後一章有說,每一個function都是一個vector,對不對,我們都可以用線性代數學到的operation來處理這些function,所以我們假設呢,某一個function,就是x平方是一個function叫做fv,然後x是一個function叫做fw,然後長數項是一個function叫做fu,
link |
我們現在要做的事情是希望,找到一組a跟b,把fw跟fu做linear combination,讓它跟fv的距離越接近越好,那我們要定義什麼叫做兩個function間的距離嘛,那我們定義兩個function間的距離就是這個樣子,就是計算從積分x0到x0加L,這兩個function的差的平方和,就是它們之間的距離。
link |
然後接下來呢,你就可以說,我們找出a fw加b fu的這個展開的那個space,然後把fvproject到那一個space上面,然後你就可以找出a跟b,然後怒算一波,然後就結束了這樣子,對,好,就這樣子,那總之,無論如何,這邊反正就跳過去,好。
link |
好,然後算出來的結果啊,就是總之arrow是L五方除以180,好,那接下來的狀況是這個樣子,我們假設呢,我們可以放n個線段,那n個線段放上去的時候,我們得到了arrow的最小值,
link |
就我們要如何分配這n個線段,使得它的arrow的值越小越好呢,如果可以小的話,可以小到什麼樣的地步,我們如何分配這n個線段,使得arrow的值最小,所以我們在0到1之間,就給它切n個線段,這n個線段不用是一樣長的,反正就想辦法分配這個n個線段的位置,想辦法分配L1到Ln的長度,我們希望最後算出來的arrow是最小的。
link |
好,那L1加到Ln的合啊,會等於1,這是唯一的constraint,因為我們要考慮的就是0到1的區間嘛,我們把它分成n個區間,把0到1之間切n份,那每一份的長度就是L1L2一直到Ln,所以L1加L2加Ln合起來,應該它的值呢,要是1。
link |
好,那假設這邊的長度是L1的話,那它的arrowE1就是L1的5次方乘以80,E2就是L2的5次方除以80,E3就是L3的5次方除以80,以此類推。
link |
所以total的arrow啊,total的arrow,我們用E平方代表total arrow的平方,就是每一項E1E2一直到En,每一項E的平方合,那每一項EEi是Li的5次方除以180,所以E的平方是summationn等於1到nLi的5次方除以180這樣。
link |
好,那接下來的問題就是,怎麼分配L1到Ln使得這個值最小這樣子,對不對?就假設我們現在只能夠用n個片段來fit這個function,那我們要fit的function是y等於x平方,我們怎麼分配L1到Ln使得total的arrow的值最小?
link |
我們只要total的arrow的值寫成這樣,summationi等於1到nLi的5次方除以180,Li唯一的限制是這樣子。講到這邊,大家有問題想要問的嗎?其實就算沒有證明,你直覺知道這一題的答案是什麼呢?應該是平均分配吧,對不對?
link |
你可能會問為什麼?沒有為什麼,平均分配。其實等一下我告訴你為什麼,但我猜你大概也不想知道。你直覺想要知道平均分配一定可以讓它的E平方最小這樣子,我直覺就覺得應該是平均分配會讓E平方最小。
link |
如果平均分配的話,那Li就等於n分之1,那Li等於n分之1,把n分之1帶進去,所以E的平方就是summationi等於1到n,n分之1的5次方除以180,然後這邊這個重複n次嘛,對不對?
link |
這項重複n次,所以乘個n,所以180分之n的四方分之1。講到這邊,大家有問題要問的嗎?你可能會問說為什麼要平均分配?這邊有一個Warning of Math告訴你為什麼要平均分配。怎麼平均分配呢?
link |
這邊要用一個Hodler's Inequality,怎麼說呢?我們現在的前面這邊有一個180,我們不要管那個180,因為這個不重要,它不會影響你的結果,我們只要知道summationi等於1到n,Li的五方要怎麼讓它的值最小這樣子。
link |
怎麼做呢?有一個Inequality是這樣說的,我們現在有n個值a1到an,有n個值b1到bn,有兩個數值p跟q,然後p分之1加q分之1的值會等於1。
link |
這個時候有一個Inequality告訴我們說,ai乘上bi的絕對值從i等於1加到n,會小於等於ai的p次方從i等於1加到n,再乘以,再開p次方,然後bi的q次方summationi等於1到n,再開q次方。
link |
接下來我們只需要把a1跟an還有b1跟bn換成我們想要的東西,把a1跟an換成l1到ln,b1到bn通通換成1,我們就可以簡化上面這個式子,ai乘bi,li乘1就是li。
link |
那l一定是正的啦,所以絕對值也不用了,因為l一定是正的嘛,它是線段的長度,所以它一定是正的,所以絕對值也不用了。那ai就是l,把它放到這邊,bi就是1,把它放到這邊,所以我們得到了這一個不等式。
link |
那這個不等式可以輕易的簡化它,因為根據我們對l的限制,summationi等於1到n,li,它的值就是1,所有線段的total的和是1。1的q次方,summationi等於1到n就是n。
link |
所以說這邊這一項是1,這一項是n的1-q次方,把n的1-q次方拿到左邊去,變成n的-1除以q次方,這邊是n的1除以q次方,拿到左邊去,變成n的-1除以q次方,小於等於summationi等於1到n,li的p次方,再取1除以p次方。
link |
然後呢,然後呢,這邊是1除以p次方嘛,然後兩邊都取p次方,所以這邊1除以p次方拿到左邊,變成n的-1除以q次方,小於等於summationi等於1到n,li的p次方。
link |
然後呢,然後這個p除以q是多少呢?你就知道說p分之1加q分之1等於1,我們要把p除以q製造出來,所以左右同乘於p,所以p除以p是1,p除以q這邊是p除以q,然後把p乘過來,乘過來,p也乘在右邊,左右都乘p,所以1加p除以q就等於p。
link |
所以那負的p除以q就是這一下,等於多少呢?把p除以q拿到右邊去,變成1減p,所以這一下是1減p。
link |
好,這邊呢,p就等,然後p代5,p代5,p代5,這邊就有summationli的5次方了,這是我們要minimize的這一下。
link |
我們知道說,它的最小值就是n的1減p次方,也就是n的負4次方,跟我直覺想的是一樣的這樣子。
link |
好,這沒什麼好笑的真的,就是說你直覺也覺得是每一個片段一樣應該會最小,果然怒倒一發以後,事實是這個樣子。
link |
好,這個不重要,你還在那邊沒有聽懂的話,真的就算了。好,那現在得到的結果是這個樣子的。
link |
1的最小值,我的滑鼠還在嗎?1的,1平方的最小值是180分之1除以n的4次方,所以1的最小值啊,所以1啊,它的最小值啊,就是1除以180,然後1除以n平方。
link |
好,這是它的error,它的error的lower bound是這個樣子。好,那我們希望這個lower bound呢,它小於等於我們給定的誤差ε,那我們希望這個1這一項小於等於我們給定的誤差ε的話,那我們需要多大的n呢?
link |
我們根號1除以180,1除以n平方要小於等於ε的話,那我們會希望把n平方項拿上來,ε項拿下去,我們希望n平方大於等於根號1除以180,1除以ε。
link |
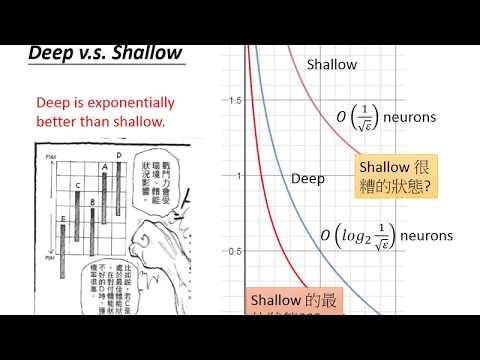
我們希望n大於等於,就再開一次根號,變成根號1除以180開四方,根號1除以ε。所以我們需要這麼多的n,這麼多的linear的piece,才能夠讓error小於等於ε。
link |
那我們知道說,每一個piece都需要一個,在shallow的狀況下都需要一個neural來製造,所以呢,我們這邊仍然需要big of the piece除以根號xn的neural,才能夠去fit y等於x平方。
link |
所以現在我們剛才疑慮就消失了,我們本來不知道shallow的最佳的狀態是什麼,但我們現在說就算是給它一些不公平的狀態,給它一個夢幻的狀態,其實它就只能夠做到這樣。
link |
所以我們剛才看到那個不知道是好還是壞的狀態,已經是shallow的最佳的狀態了。而另外一方面,deep這個狀態,我們不知道它是最好還是沒有很好這樣子。
link |
我們只是可以這樣做到,我們有一個方法可以用這麼多的neural,就去fit y等於x平方,接下來就可以fit polynomial。
link |
只需要這麼多的neural就可以fit y等於x平方,能不能更少呢?不知道,但我們至少只要隨便找一個方法就這樣子了,那shallow的方法竭盡全力,也就只能夠做到這樣而已。
link |
所以這邊就是告訴我們說deep是比shallow好的。
link |
後面有一些現在有的理論,我今天講的是現在有的理論的異常簡化版,你可以自己去看看那些paper裡面講的都還蠻複雜的。
link |
這邊就是用流水帳的方式帶過去,那些理論是長什麼樣子的。
link |
這邊都是簡化的版本,實際上更詳盡的說明,你再自己去看看那些文章。
link |
在最早的時候,我剛才找到最早的跟這些deep fit function的power有關的文獻,是從2016年開始的。
link |
文獻是發表在COLT,我找到最早的文獻,它證出來的理論是這樣,這個是比較早的結果。
link |
它證出來的理論是這樣,它是說有某一個function,它是由三個layer的free-forward network所組成的,那這個function沒有辦法被兩個layer的network所逼近。
link |
但是它只是說有存在這樣的function,並不是說所有function都是這樣子。
link |
你隨便找一個很簡單的function,比如說linear的function,就是一條水平線的function。
link |
這樣比起來,deep跟shallow比起來,在fit的那種function上是沒有任何優勢的。
link |
所以這邊的理論只是告訴我們存在某一個function,它可以用三個layer的network來表示,但卻沒有辦法被兩個layer的network來表示,除非那個兩個layer的network非常的巨大。
link |
那它的證明是一個general的證明,我們剛才討論的都是在review的case上面,它不限於review,它可以apply在其他的activation function上面。
link |
它告訴我們說,假設三個layer的network,它的每一層寬度是k,那兩個layer的network要怎麼樣才能夠逼近三個layer的network所構成出來的function呢?
link |
你要把它的寬度,你要把那個k取4除以19次方,然後放在指數,然後這邊有兩個常數項A跟B,然後你需要這麼多的neural,你的兩個layer的network需要這麼多的neural,才可以去approximate這個三個layer的network。
link |
發現說,這個三個layer的寬度,居然在兩個layer這邊是放在指數項的,雖然它這邊有取一個4除以19次方,會讓這個k的值變小,但是它是被放在指數項。
link |
這邊這個是只有正三個layer跟兩個layer,所以它可能是比較limit,這邊有一個更general的,看一次,我在COLT的2016,它說,存在著一個function,它可以被deep network所表達,但是沒有辦法被shallow的network所表達。
link |
跟剛才講一樣,除非那個shallow的network非常的大,它的證明一樣也不限於review的function。證明是這個樣子,它說,假設你有一個很deep的network,它的layer的數目是theta of k三方,然後它的每一個layer的node的數目是theta of 1,它的參數是theta of 1。
link |
你可能說,怎麼突然討論參數?這邊它還討論了參數的量,因為這邊指的是不同的參數,也就是說你的不同的layer是可以share參數的,你可以不需要那麼多的參數,就構築出一個非常複雜的deep network。
link |
那shallow的network呢?如果它的layer的數目是theta of k,那它至少要2的k次方的node才可以逼近這個deep的network。但是這些paper裡面,他們討論的都只有一直說存在這樣子的一個function。
link |
接下來有人就會問說,那雖然說存在這樣的function,那個function會不會非常的奇怪,然後在真實的case上完全派不上用場呢?所以接下來,有人就證了說,那存在的那個function,它不見得是一個很奇怪的function,至少我們舉一個例子,它是一個球狀的function。
link |
就你做一個球,然後這個球裡面的值啊,就你做一個function,它在這個球裡面都是1,在球外面都是0,它就是前述的那幾個理論裡面講的function的其中一個。
link |
那這種球狀的function你看就很有用啊,因為你可以做一個,你做分類的時候可以用上嘛,就某一個類別都落在球裡面,某一個類別都落在球外面。
link |
那這篇paper還做了實驗的證明,它說,假設我們現在要去fit這個function,我們用兩個layer的network跟用三個layer的network來比較看看。
link |
那你會發現說,兩個layer的network,你不管怎麼開它的寬度100、200、400到800,都沒有辦法去fit那個球。
link |
那一弄到三層,寬度只有100,你得到的error馬上就有很大的降降,那它只是用這個實驗來驗證這個理論而已。
link |
那剛才講的都是比較specific的case,其實現在還有很多的證明,我就沒有把他們的理論寫上來,你可以自己check一下這幾篇paper。
link |
那其實在這些paper裡面啊,你要證明所有的function都是deep比較好,shallow比較差是不可能的,也不合理的,因為你隨便拿一個function出來,比如說它是一個linear function,deep就不見得會佔到優勢。
link |
所以deep要比較好的前提通常是,你對那個function還是要做一些限制的,就是你不能夠證說任何function都是deep好shallow差,你沒辦法證這件事,而且實際上也不是這個樣子。
link |
你只能是說,假設你的function有某種程度的複雜度,比如說它的coverture是多少,那每一篇paper證的就不太一樣這樣子。
link |
就是每一個function,你要考慮的那個function,它在有某種複雜程度的前提之下,我們通常可以得到類似以下這樣的結論。
link |
就假設你有一個network,你希望它的這個L2node的accuracy小於epsilon,那它是一個radial的network,它的深度是固定的,那你需要的這個neuron的數目可能是1除以epsilon的某一個polynomial下,1除以epsilon放到某一個polynomial的function裡面。
link |
但是如果你今天的network可以很深,深到它的深度是跟epsilon有關係的,那這個時候你的寬度只需要log1除以epsilon帶到polynomial裡面去。
link |
本來需要1除以epsilon帶到polynomial裡面去,現在是log1除以epsilon帶到polynomial裡面去,所以它們的差別是差了一個exponential,跟我們剛才在前面講的比較簡單的推導,其實得到的結果是一致的。
link |
這一頁投影片想要講的是,其實還有別的說法,這個細節大家再check那個paper,什麼情況下deeper會比較好呢?如果那個function有一個compositional的structure,那deeper會比shallow還要好。
link |
那我今天要講的差不多就是這個樣子,等一下我們就請助教來講一下作業。在請助教來講作業之前,我還是為今天的課程下一個結論。假設剛才講了那麼多東西,你覺得很煩躁都沒有聽下去的話,那今天得到的結論就是這樣。
link |
假設你想要fit某一個function,那deeper會比shallow還要好,然後它的好是exponential的那麼好,那要fit那個function,結論就是這樣子。
link |
那這個function,我們今天證了y等於x平方是那樣子的function,那你可以很直覺的覺得說,也許比y等於x平方還要簡單的,比如說一次的,不符合剛才的說法,但是比y等於x平方複雜的,就會符合剛才那一個說法。
link |
我們要考慮要fit的function,一定都比y等於x平方複雜,所以deep learning是很有用的,就是這樣子。好,那接下來我們就請助教來講一下作業。