back to index
Deep Learning Theory 2-1: When Gradient is Zero
link |
講Deep Learning的Optimization
link |
為什麼Deep Network的這個Deep的Structure
link |
那用Deep的Structure是比較有效率的
link |
假設我們定出了一個Deep的Network
link |
那我們上週講過說Deep的Network
link |
它代表了一個Function的Space
link |
那怎麼在這個Function的Space裡面
link |
找出那個我們要找的最好的Function
link |
就我們要找那個最好的Function
link |
那Deep的Network它定義了一個Function的Space
link |
怎麼在這個Function的Space裡面
link |
那這個從Function的Space裡面
link |
那這邊更正式的用Formulation來講一下
link |
我這邊指的Optimization是什麼
link |
也就是Neural的Weight跟Bias
link |
接下來我們有一些收集好的TrainingData
link |
我們希望Network所Output的Target
link |
這邊從X1 Y1 hat到Xr Yr hat
link |
接下來我們會定義一個LossFunction
link |
那這其實都是我們過去機器學習講過的東西
link |
這個LossFunction長什麼樣子呢
link |
你現在Summation over你所有的TrainingData
link |
把這個Output跟Yr hat去計算一下
link |
如果是Regression的Problem
link |
你會用Mean Square Error
link |
你可能會用這個Cross Entropy
link |
那總之你會定義不同的LossFunction
link |
然後你要Minimize這個Total Loss大L
link |
這個Theta代表Network的參數
link |
它可以讓Total Loss大L的值
link |
那這個可以讓Total Loss大L的值
link |
這個Evolution of Theta
link |
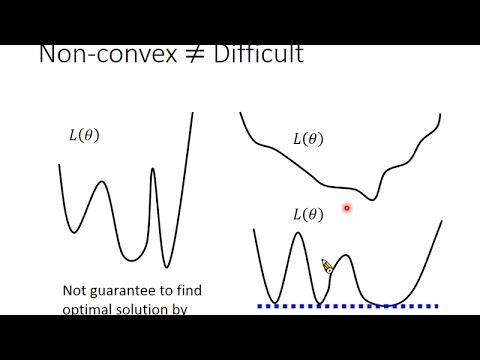
所以我們這邊不會強調Convex是什麼
link |
Deep Learning所定義出來的Loss Function
link |
那如果一個Loss Function是Convex的
link |
你可以保證你一定可以找到Global Minima
link |
然後Convergence的Rate一定有多大等等
link |
並不是屬於Deep Learning的
link |
這些機會並不是屬於Deep Learning的
link |
因為它不是一個Convex的Problem
link |
假設一個Optimization Problem
link |
那個Loss Function是Non-Convex
link |
那這個問題是一個NP-Hard的問題
link |
Deep Learning它的Loss Function不是Convex的
link |
In General Non-Convex是一個非常困難的問題
link |
但是Deep Learning沒有我們想像的那麼困難
link |
通常我們今天要Optimize Deep Learning的Network的時候
link |
我們其實只要用Gradient Descent這種方法
link |
通常就可以得到不錯的Solution
link |
為什麼我們能夠用Gradient Descent
link |
就得在一個顯然不是Convex的Optimization Problem下
link |
對Deep Learning是非常有幫助的
link |
Deep Learning它是一個非常強大的方法
link |
但是假如沒有一個很好的Optimization方法
link |
可以讓我們從那個Function的Space裡面
link |
就算是Deep Network所定義出來的Function Space
link |
我可以想到最Typical的例子就是八門盾甲
link |
然後你就會瞬間得到跟火影一樣強的力量
link |
沒有尾獸跟血輪也都不好意思出去跟別人打招呼
link |
Deep Learning它的Optimization
link |
還是是像血輪也那種每個人都有的一樣呢
link |
Optimization其實不等於Learning
link |
Optimization和Learning是有差別的
link |
不管你是Deep Learning還是其他Learning的方法
link |
找出了最好的這個參數Theta Star以後
link |
那你希望你找出來的Theta Star
link |
它Optimize在你看過的Training Data上
link |
但是在Testing Data上也要有好的結果
link |
Train出來的Model可以Apply在Testing Data上
link |
我們只專注在Optimization這件事情上
link |
今天Loss Function給我們了
link |
你能不能夠找到一個Theta Star
link |
讓Loss Function的值最小
link |
讓Loss Function的值最小的Theta Star
link |
為什麼Deep Learning所定義出來的Loss Function
link |
那假設你不知道什麼是Convex的話
link |
所謂的Convex的Function
link |
那怎麼檢查一個Function是不是Convex的呢
link |
都大過於這個Function本身的值
link |
今天根據這個Deep的Network
link |
所定出來的Loss Function
link |
它很有可能沒有辦法滿足這個Convex的特性
link |
所定義出來的Loss Function
link |
它有非常非常多的Global Minima
link |
因為其實我們今天把一個Network裡面的
link |
我們就產生一組新的Network的參數
link |
我們找到一個Global Minima
link |
我們找到一個Global Minima
link |
我們把黑色的這個Neuron擺到中間
link |
它已經是一個Global Minima
link |
它也是一個Global Minima
link |
但是它們都是Global Minima
link |
而且它們都是Global Minima
link |
直接做Linear Interpolation
link |
那因為它的Global Minima
link |
因為Network本身是Non-Linear的
link |
這個Global Minima得到的Loss還要高
link |
今天Deep The Network所定義出來的
link |
它不是一個Convex的Function
link |
Deep The Network是Non-Convex的
link |
In General Non-Convex Optimization
link |
In General而言Non-Convex Optimization是困難的
link |
但也許Deep The Network所製造出來的
link |
讓我們可以用Gradient Descent的方法
link |
Non-Convex Optimization可能很困難
link |
你沒有辦法用Gradient Descent的方法
link |
Deep Learning定義出來的
link |
Non-Convex的這個Function
link |
但是你用Gradient Descent的方法
link |
都可以走到Global Minimum
link |
所以Gradient Descent可以Optimize這一個
link |
Deep Learning不太可能是這樣吧
link |
Deep Learning它顯然有好多個
link |
這個Non-Convex的Function
link |
不是它沒有任何的Local Minimum
link |
它通通都是Global Minimum
link |
Deep的Network所定義出來的
link |
從哪邊開始做Gradient Descent
link |
但是我們在Machine Learning那一堂課
link |
講完了這個Background的知識以後
link |
會分析一下Deep的Linear的Network
link |
再拓展到Non-Linear的Network
link |
對這個Deep Learning的Aero Surface的想像
link |
講一些Empirical的Observation
link |
好,那我們就先從Hessian的Matrix開始講起
link |
什麼時候我們會需要用到Hessian的Matrix呢
link |
當你今天做Gradient Descent
link |
然後發現今天Gradient非常趨近於0的時候
link |
也就是你走到了一個Critical Point
link |
這個時候你就會用這個Hessian來進行分析
link |
那我們知道在Trend Network的時候
link |
我們就是用Gradient Descent
link |
那通常我們相信Trend使用Gradient Descent
link |
那當Gradient非常接近於0的時候
link |
Gradient Descent這個方法就會停下來
link |
那那些Gradient非常接近於0的點
link |
我們叫它Critical Point
link |
所以我們今天用Gradient Descent的時候呢
link |
這個是你在做Gradient Descent的時候
link |
你可以觀察到說隨著Empirical越來越多
link |
那個地方的Gradient非常趨近於0
link |
如果比較或者是Double Minima
link |
噢我到了一個Local Minima
link |
你一定就會被做Deep Learning的人嗆到爆炸這樣子
link |
因為其實當你Trend發現停下來的時候
link |
Settle Point就是它不是極值
link |
怎麼分辨說現在在Gradient是0的地方
link |
它是Settle Point還是一個Minima或者是Maxima呢
link |
這個時候你就需要用到Hessian Matrix這個東西
link |
什麼是Hessian Matrix呢
link |
之前我們在講Gradient Descent的時候
link |
我們在Machine Learning那一課有跟大家推導過Gradient Descent
link |
那Gradient Descent是怎麼推導出來的呢
link |
任何的Function f of Theta
link |
就這個不限於Deep Learning
link |
任何的Function假設它的參數是Theta的話
link |
任何的Function f of Theta
link |
Theta0就是某一個Specific的參數
link |
這個f of Theta0加上Theta-Theta0的Transpose乘上G
link |
再加上1 2 Theta-Theta0的Transpose乘上h
link |
這個Gradient它是一個Vector
link |
每一維就是我們拿Theta的某一個Dimension
link |
那就得到G這個Vector的第i為GI
link |
Theta-Theta0也是一個Vector
link |
我們把這個Vector做Transpose乘上G以後
link |
就把這個倒三角形放在FunctionF前面
link |
那Gradient其實就是一個Vector
link |
這個h就是我們今天要介紹的Hesitant
link |
那Hesitant它是一個Matrix
link |
那假設現在這個Theta它是一個n維的向量
link |
它的二次微分是continuous的
link |
我們其實可以來描述一個Function
link |
但這個描述其實是一個approximate
link |
今天如果Theta跟Theta0非常接近的時候
link |
我們現在這個Function F的coverture
link |
今天如果我們沒有考慮後面這個h這一項
link |
那如果我們現在的F of Theta呢
link |
你的參數其實是在一個非常高危的空間中
link |
而這個Newton's Method
link |
這個Newton's Method是說
link |
Gradient Descent的時候
link |
在做Gradient Descent的時候
link |
Gradient Descent是怎麼來的
link |
Machine Learning的話
link |
在做Gradient Descent的時候
link |
Theta-Theta0的Transpose
link |
這Gradient是一個vector
link |
所以θ-θ0等於-H的inverse
link |
它是一個symmetry的metric
link |
並不是所有symmetry的metric
link |
所以沒有辦法找到inverse怎麼辦
link |
Gradient descent做的事情是說
link |
G會乘上一個learning rate
link |
常數啊一個learning rate
link |
就是這個是Newton's method
link |
這個是Gradient descent
link |
Gradient descent是乘上一個常數
link |
所以就不用再調什麼step size了
link |
但是Gradient descent
link |
Gradient descent在走的時候
link |
theta跟theta0非常接近的時候
link |
所以跟gradient descent不一樣
link |
gradient descent每次
link |
但是如果你用Newton's method
link |
quadratic的function
link |
這個optimization的process呢
link |
其實在做deep learning的時候
link |
你要去maximize的function
link |
所以你用這個Newton's method
link |
怎麼不用Newton's method
link |
gradient descent的時候
link |
在做gradient descent的時候
link |
它是一個critical point
link |
今天當一個critical point
link |
metric A的eigenvector
link |
就是metric A的eigenvalue
link |
你得到的還是zero vector啊
link |
zero vector對應一個eigenvalue
link |
positive跟negative的definite
link |
這個是symmetric matrix的
link |
就叫做positive definite
link |
就這個symmetric matrix
link |
它是一個positive definite的symmetric matrix
link |
negative definite的metric
link |
它是positive definite的
link |
如果它是negative definite的
link |
是那個positive的semi definite
link |
那這個semi definite跟definite
link |
x transpose乘上a再乘上x
link |
那是positive semi definite
link |
那是positive definite
link |
positive semi definite呢
link |
如果是positive definite
link |
positive semi definite
link |
就是negative semi definite
link |
就是negative semi definite
link |
在走到了某一個critical point
link |
critical point歸零等於0
link |
1的theta-theta0的transpose
link |
乘上Hatrian matrix H
link |
是positive definite
link |
它是positive definite的
link |
它是positive definite
link |
如果F of theta一定會大於F of theta0
link |
它就走到一個critical point
link |
是positive definite的
link |
我們現在的這個critical point
link |
positive definite的時候
link |
F of theta大於F of theta0
link |
是negative definite
link |
是positive semi definite呢
link |
有可能是一個local minima
link |
但是它一定是local minima嗎
link |
仍然一定是local minima嗎
link |
有可能就不是local minima嗎
link |
有可能就不是local minima的同學
link |
它有可能不是local minima
link |
如果f of theta總是大於等於theta0
link |
它仍然是一個local minima
link |
f of theta跟f of theta0
link |
H是semi-definite的時候
link |
它到底是不是local minima了
link |
今天positive semi-definite
link |
如果是negative definite
link |
那我們把這個eigenvalue V
link |
這邊我就記得要加一個transpose
link |
不過這邊我就記得要加transpose
link |
用H的某一個eigenvector來代換的話
link |
因為根據eigenvector的定義
link |
等於λ乘上V的transpose跟V
link |
就是我們eigenvector和eigenvalue
link |
就是H的eigenvector跟eigenvalue
link |
就你剛才講一些什麼positive definite
link |
把eigenvector跟eigenvalue
link |
根據某一個eigenvector的方向
link |
V這個eigenvector的eigenvalue
link |
那現在假設我們找了兩個eigenvalue
link |
那往V2這個eigenvector方向移動
link |
這個linear combination的方向去走的話
link |
X是V1跟V2的linear combination
link |
你覺得假設V1V2是orthogonal
link |
你翻到symmetric matrix那一章
link |
是一個orthonormal的basis
link |
orthonormal basis是什麼
link |
假設一個symmetric matrix
link |
因為這個是eigenvalue的定義
link |
因為V1V2是orthogonal的
link |
它是V1跟V2的linear combination
link |
Eigenvector的linear combination
link |
H的Eigenvector就是V1V2到Vn
link |
U可以寫成A1V1加A2V2加到AnVn
link |
V1到Vn的linear combination嗎
link |
因為symmetry matrix就是這樣
link |
一定是Eigenvalue的linear combination
link |
Eigenvector的linear combination
link |
用Eigenvalue和Eigenvector
link |
用Hatian的Eigenvalue和Eigenvector
link |
分析critical point這件事情
link |
所謂的Hatian的Eigenvalue和Eigenvector
link |
往Eigenvector的方向走過去
link |
我們會增加Eigenvalue那麼多的值
link |
然後往某一個不是Eigenvector的方向走過去
link |
因為那個方向會是Eigenvector的linear combination
link |
它是各個不同Eigenvector增加的量的和
link |
假設所有的Eigenvalue通通都是正的
link |
所以它是一個local minima
link |
所以它是一個local maxima
link |
所以剛才Eigenvalue、Eigenvector
link |
跟是不是local minima的關係
link |
所以它是一個saddle point
link |
它的Eigenvector和Eigenvalue
link |
這個function只有兩個參數x跟y
link |
它的有哪些critical point
link |
那它的critical point是local minima
link |
它唯一的critical point
link |
用Hessian matrix來分析一下
link |
Hessian gradient會是零
link |
也就是走到一個critical point
link |
我們的Hessian matrix是2006
link |
那2006這個Hessian matrix
link |
它是positive definite
link |
還是negative definite
link |
它到底應該是local minima
link |
是不是positive definite
link |
所以是不考慮zero vector的
link |
所以H是positive definite的
link |
因為它是positive definite的
link |
所以它是一個local minima
link |
它不是positive definite的
link |
也不是negative definite的
link |
所以它是一個saddle point
link |
至少有一個eigenvalue是0的意思
link |
我們要考慮的那個preview point
link |
我們說eigenvalue的意思就是說
link |
往那個eigenvector的方向走過去
link |
它有一個critical point
link |
它是local minima,local maxima
link |
覺得它是local minima的同學
link |
覺得它是saddle point的同學
link |
覺得它是local maxima的同學
link |
the critical point
link |
linear combination
link |
linear combination
link |
所以它是一個local minima
link |
覺得它是local minima的同學
link |
覺得它是local maxima的同學
link |
覺得它是single point的同學
link |
所以多數同學覺得它是single point
link |
所以它是一個single point
link |
那剛才那個Hadrian matrix
link |
一模一樣的Hadrian matrix
link |
Hg of xy它其實是一個single point
link |
在那個zero eigenvalue的方向
link |
從H這個Hadrian matrix看起來
link |
這只是一個approximation而已
link |
其實只是一個approximation而已
link |
但是今天既然連Hadrian那一項是0
link |
它有是0的eigenvalue的時候
link |
用Hadrian matrix來判斷它是
link |
local minima還是zero point
link |
但是它顯然是一個local maxima
link |
Gradient跟Hadrian的話
link |
它是一個奇妙的saddle point
link |
為什麼它叫做monkey saddle
link |
一個猴子坐在這個function上面
link |
所以它叫做monkey saddle
link |
走到一個critical point
link |
critical point規定是0的情況下
link |
那個deep learning的教科書
link |
他自己training了一個network
link |
它根本就不是走到saddle point
link |
它根本就不是走到saddle point
link |
Ian Goodfellow做的事情
link |
training某一個network
link |
現在逐漸靠近一個saddle point
link |
看看Ian Goodfellow跟Benjo