back to index
Deep Learning Theory 2-3: Does Deep Network have Local Minima?
link |
一般的nonlinear deep network,它到底有沒有local minima?
link |
你要證沒有local minima很難,但你要證有local minima太容易了,
link |
找個local minima來,就證它有local minima了,對不對?
link |
所以,這個就好像說你要證明一個東西不存在很難,
link |
但是要證明事情存在呢,是相對比較容易的。
link |
好,那怎麼做?這邊的說法呢,是這個樣子的。
link |
首先就算是非常簡單的task,比如說XOR的task,
link |
我們今天在講machine learning的時候,
link |
從non-deep的network跨到deep network的時候,
link |
說如果今天有一個data point,它是這樣的分布,
link |
然後呢,這兩個point是delay,linear network沒有辦法分,
link |
所以一定要non-linear的network。
link |
但如果你實際上去認一下這種XOR的problem,
link |
你會發現說,如果你用一個network它只有一個hidden layer,
link |
它的neural的速度是2,3,4,5,6到7,
link |
就算是增加到7個neural那麼多,
link |
你使用addend這種optimization,
link |
都沒有辦法保證你一定可以得到100%的正確率,
link |
找到一個global的optimal。
link |
那如果是這個sigmoid,在network比較大的時候倒是可以。
link |
接下來這篇payment裡面呢,它想了一個更複雜的問題,
link |
這個複雜的問題叫做jellyfish的問題,
link |
它說它現在有四個點,這四個點的分布呢,
link |
就分布在這四個位置,然後這兩個黑點是delay,
link |
那如果是sigmoid,它還可以解SO的problem,
link |
如果是jellyfish,不管是relu還是sigmoid,
link |
以及是我們現在覺得最state-of-the-art的optimization方法,
link |
用addend,你都找不到global的optimal。
link |
這個是第一個比較不直接的證據告訴你說,
link |
就算是很簡單的network,有時候你也認不起來。
link |
再來呢,我們今天假設要證明說relu的network有local minima,
link |
找一個來就證明說relu的network有local minima了嘛。
link |
所以怎麼辦呢,在文件上有人就找了一個,
link |
他就隨便找一個,這個其實你要找十個八個也是有的,
link |
他就說我們現在有一個case,我們有五筆data,
link |
這五筆data分別就是,這邊要畫一個點,
link |
這邊要畫一個逗點,不知道為什麼畫成一個小數點,
link |
我畫錯了,有五個點,-1,3,1,-3,3,0,4,1,5,2,有五個點。
link |
接下來呢,我們有一個全世界最簡單的relu network,
link |
它只有一個neural,那把x放進去,
link |
它會乘上一個weight,加上一個bias,
link |
再通過relu這個activation function,
link |
再乘上一個weight,再加上一個bias,得到最終的y。
link |
那現在在這一排,這五個這個pair裡面,
link |
每一個數字都代表x,output就是,第二個數字就是target。
link |
好,今天假設你有一個relu的network是1,-3,1,0,
link |
它的曲線畫出來,它x跟y的關係畫起來是這個樣子,
link |
它正好可以fit後面三個點,但它fit不了前面這兩個點,
link |
那它的loss算出來是18,那你可以輕易的證明它是一個local minimum,
link |
怎麼輕易的證明呢?你可以證說這個1,-3,1,0,
link |
如果你都把它們加一個小小的delta,
link |
不管加的delta是什麼,它的loss一定都會增加,
link |
所以它是一個local minimum。
link |
那接下來你只要找到另外一個minimum,它的值,
link |
你只要能夠找到另外一組參數,它的loss比18還要低,
link |
那你就知道說這一組參數是一個local minimum,就結束了對不對?
link |
那找不找得到呢?就胡亂找就一組這樣子。
link |
這個-7,-4,1,0這個network,它音部跟output的關係長這個樣子,
link |
它算出來的loss是14,比它還要低,它是一個minimum,
link |
然後又發現說有其他的參數loss更低,
link |
它就不是global minimum了,所以就結束了,
link |
所以ReLU的network是有local minimum的,
link |
有不是global minimum的local minimum的。
link |
那剛才舉的是一個非常specific的case,
link |
也許你覺得這個case太過specific,
link |
其實in general而言,ReLU的network都可以找到local minimum,
link |
怎麼說呢?因為ReLU這種network有一個狀況叫做它的盲點,
link |
你可以為ReLU這個network製造盲點,
link |
我們知道ReLU這個network,它的每一個neuron有兩種operation region,
link |
一種region是input等於output,一種是output等於0,
link |
今天我們假設一個case是所有的neuron它通通是output等於0,
link |
這個就是代表這種狀況叫做ReLU的network陷入盲點,
link |
就是今天input一個x進來,所有的neuron它的output通通都是0,
link |
如果所有的neuron都作用在output是0的region上,
link |
那整個network最終的output當然也是0,
link |
那你會發現說在這個case,你的歸點算出來就是0,對不對?
link |
因為你想想看,你今天假設在這個盲點的這個區域裡面,
link |
假設你不改變這些neuron的operation region,
link |
所以今天所有的參數,它的歸點通通都是0,
link |
所以你今天你就找到一個critical point,
link |
那這個critical point它其實是一個local minima,
link |
怎麼說它是local minima呢?
link |
因為這個critical point它在它的,
link |
它其實是這樣子的,就假設橫軸是你的參數的變化,
link |
假設橫軸是你的參數的變化,我寫做theta好了,
link |
在某一個區間內啊,你的network的output呢,
link |
那今天在這個output是0的這個區間裡面選一個點,
link |
它其實都是local minima,
link |
所以它是一個local minima,
link |
但它會不會是global minima?
link |
它一定不是global minima啊,
link |
你只要你最後的那個target它不是0就好了,
link |
你只要你最好的那個target它不是0,
link |
你只要有別的case它可以找到的loss小於output是0的case,
link |
那它就不是global minima了,
link |
所以對reduce這個network來說,
link |
就所有的neuron通通output是0的狀態,
link |
它很有可能就是local minima,
link |
你給它比如說每一個neuron的bias設很大,
link |
它train了很多的reduce的network,
link |
然後參數update一百萬次這樣子,
link |
就update到覺得已經不可能再有任何變化,
link |
今天它做了不同的initialization的case,
link |
首先上面這個row跟下面這個row,
link |
上面這個row是用一般的unlist training set train的,
link |
下面這個row是用奇怪的unlist train,
link |
今天假設你用一個正常的initialization的方式,
link |
你用一個normal distribution,
link |
有時候代表說它們有不同的hidden unit,
link |
那也不同的顏色代表兩個hidden layer,
link |
或者是五個hidden layer,
link |
那發現說不管是多少hidden layer,
link |
不管是多少的hidden unit,
link |
只要用這種正常的initialization的方式,
link |
用這種正常的initialization的方式,
link |
你accuracy都可以train到1,
link |
accuracy都可以train到1,
link |
試圖讓network進入盲點的區域,
link |
故意讓它是從mean是-10的random variable sample起,
link |
故意讓它是從mean是-10的random variable sample起,
link |
或者是故意讓bias的mean是-10,
link |
weight跟bias的mean都是-1,
link |
也就是故意讓network在一開始的時候,
link |
就掉入local minima的區域,
link |
它的accuracy就一直在趨近於0的地方,
link |
relu的network是有local minima的,
link |
那會不會撞到local minima,
link |
跟你怎麼做initialization是有關係的。
link |
不只是initialization會影響你有沒有local minima,
link |
會不會碰到local minima,
link |
會不會容易遇到local minima這件事。
link |
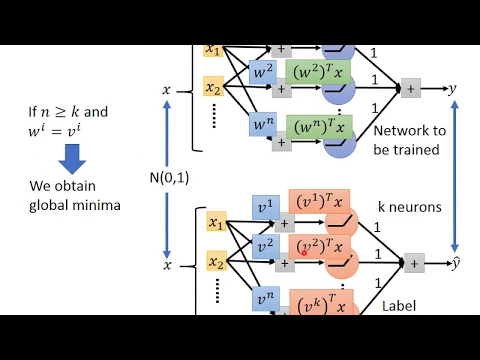
這個network只有一個hidden layer,
link |
假設每個neural它的參數分別就是w1, w2到wn,
link |
那每個neural的input就是x跟w1做inner product,
link |
就是你把w1的transpose成x當作activation function input,
link |
w2的transpose成x當作activation function input,
link |
wn的transpose成x當activation function input,
link |
通過relu以後再乘上1得到最終的y,
link |
我們都沒有假設我們的data應該長什麼樣子,
link |
現在假設data是從一個generator生出來的,
link |
這個generator怎麼生data呢?
link |
這個generator是一個network,
link |
但這個network的參數是給定的,
link |
假設我們知道這是一個有k個neural的hidden layer的network,
link |
它的參數也就是每個neural的weight分別是v1, v2到vn,
link |
然後最後把它通通加起來,得到你的label,
link |
從一個normal distribution做sample,
link |
丟到這個label generator產生你的label y hat,
link |
它要做的事情是想盡辦法去fit這個x跟y hat之間的關係,
link |
假設今天這兩個network他們的neural的數目,
link |
下面這個network的neural的數目比較多,
link |
或上面這個network它的neural的數目大於等於下面這個networkneural的數目,
link |
我們只要這邊的第一個neural等於這邊的第一個neural,
link |
這邊的第二個neural等於這邊的第二個neural,
link |
這邊的dk的neural等於這邊的dk的neural,
link |
也就是這邊的di的neural等於這邊的di的neural,
link |
你就可以找到global minima,
link |
我們就知道global minima長什麼樣子,
link |
然後假設現在n的數目跟k的數目是一樣的,
link |
也就是你要train的networkneural的數目,
link |
跟你的label generator neural的數目是一樣的,
link |
這邊就是說你真的去train那個network,
link |
然後再檢查說他是不是一個local minima,
link |
你是停在一個local minima,
link |
今天有很大的機率會停在local minima,
link |
就假設他找到一個critical point,
link |
把他的eigenvalue都找出來,
link |
eigenvalue的平均的最小值呢,
link |
找到那個critical point,
link |
你從這個critical point往四周走,
link |
代表他是一個local minima,
link |
也就是label generator,
link |
跟你要train那個network,
link |
假設現在network的neural,
link |
你就很少遇到local minima,
link |
有點那種over parameterized的情況,
link |
遇到local minima的機會,
link |
你的label generator,
link |
你的network有9個neural,
link |
你的label generator有8個neural,
link |
你的network給他10個neural,
link |
你就完全找不到local minima,
link |
當然並不代表local minima,
link |
然後都不會卡在local minima,
link |
都可以找到global minima,
link |
或是non-linear的deep的network,
link |
deep learning是不work,
link |
deep learning是沒有辦法train的,
link |
找出什麼樣的狀況有local minima,
link |
什麼樣的狀況沒有local minima,
link |
那你把有local minima的狀況都記掉,
link |
什麼情況下會沒有local minima,
link |
有沒有local minima的理論出現的話,
link |
那個理論的statement會是講,
link |
relu的network就沒有local minima,
link |
你不太可能做這種statement,
link |
因為它就是有local minima的這樣子,
link |
它就是沒有local minima,
link |
應該要考慮initialization,
link |
你故意initialize在relu network的盲點,
link |
但你不能故意initialize在盲點的地方,
link |
所以在某種initialization的情況下,
link |
在某種data的distribution的情況下,
link |
如果你現在的data相對於network是比較簡單的,
link |
你就在實驗上找不到local minima,
link |
今天你的data跟你的network之間的關係,
link |
我們一定能夠找到global optimal。