back to index
Deep Learning Theory 2-5: Geometry of Loss Surfaces (Empirical)
link |
上次講的是比較有關理論的部分,那這邊要講的是在實驗上真正的觀察,那這個也是作業一至二的其中一題,就是我們試著用一些你想得到的方法來visualize這個training的時候,這個loss surface長什麼樣子,還有training的process長什麼樣子。
link |
那這邊這個圖當然不是一個network真正的error surface,它只是一個示意圖,希望大家可以想辦法看能不能visualize network的參數還有它的loss之間的關係。
link |
但是怎麼visualize呢?network的參數有成千上萬個,它並不是二維的空間,並不是只有兩個參數,那要怎麼visualize network的參數跟它的loss之間的關係呢?
link |
那以下是Ian Goodfellow用的一個方法,那這個其實是我看到比較早的一篇跟network的error surface visualization有關係的文章,應該是在14年還是15年的時候就發表了,這是Ian Goodfellow做的。
link |
他這邊怎麼說呢?他說,我們沒有辦法visualize network的所有參數跟loss之間的關係,但是我們可以visualize參數在某一個方向上的變化跟loss之間的關係。
link |
我們把參數往某一個方向改變的時候,我們去觀察它對loss的影響,但是要選擇哪一個方向呢?今天在一個network的參數所組成的space裡面,你可以選擇的方向有無窮多個。
link |
那今天在visualize的時候呢,Ian Goodfellow他選擇的方向是從training的initial的參數到最後你train到停止的時候,你找出來的那一組參數中間的這個方向。
link |
也就是說,我們一開始training的時候呢,有一組initialize的參數這個寫作θ0,train到最後,你的network停下來了,你training的process停下來了,你得到θ stop。
link |
接下來呢,我們在θ0跟θ start之間連一條線,當然實際上在training的時候,network並不是從θ0直接跑到θ start,它從θ0跑到θ start中間可能有一大堆曲曲折折的關係。
link |
當然這件事情是發生在一個非常高維的空間上,只是現在我們把它畫在二維平面上,這個θ0跟θ start都是高維空間中的一個point,我們只是把它放畫在二維的空間上而已。
link |
好了,有了θ0,有了θ start,有了高維空間中的兩個點,我們就把高維空間中的這兩個點連在一起,接下來我們visualize這一條連線上面loss的變化,所以就得到了右上角這個圖。
link |
0這邊呢,代表θ0這個參數它的loss,那這個1.0這邊呢,代表θ start,就是你最後train出來的solution它的loss。
link |
那你還可以再順著這個方向繼續向右,把這邊這一條連線上面的每一個點它的loss都算出來,又放在這邊,放在這邊就得到這個曲線。
link |
然後你從這個方向還可以繼續,再順著這個方向繼續往右走,你走到θ0加上兩倍的θ start減θ0,那你就得到右邊的這個部分。
link |
好,那上面這邊有三條曲線,這三條曲線分別是三個不同的network,mixout network,redu,還有sigmoid這三種不同的network,它們的arrow surface。
link |
那這個圖告訴我們什麼呢?這個圖告訴我們的事情呢,其實是從這個地方,從training的起始,一直到training的結束,其實這個arrow surface看起來是頗為平坦的。
link |
其實只有非常少的例外,舉例來說,我們最後training的時候停在,比如我們看藍色這條線,藍色這條線是一個mixout network。
link |
比如training的時候是停在這個地方,但實際上有一個更低的地方是在這裡。
link |
所以顯然這個地方在用gradient descent並沒有真的找到一個local minima,因為這個點它的這個loss是更低的,它比較更像是一個local minima。
link |
那你光看這個圖,你並不能確定說這邊是不是一個local minima,因為它只是某一個方向上面的loss的變化。
link |
比如在這個螢幕上這個方向上看起來它是local minima,但是也許垂直這個螢幕輸入輸出的地方,它原來loss還可以再下降,其實它是一個saddle point,也是有可能的,我們不知道,因為我們只看了某一個方向上loss的變化而已。
link |
那這個圖告訴我們什麼?這個圖告訴我們說,其實local minima好像沒有我們想像的那麼容易出現。
link |
從這個地方到這個地方,我們從這個地方到這個地方,我們本來預期中間有很多的坑坑洞洞,它會讓network走到那些坑洞以後就陷進去了。
link |
但事實並不是這樣,從theta0到thetaX大中間,它是非常平坦的,network從這邊直接走走走,如果你用gradient descent從這邊滑下來,你even可以直接從起始的地方就滑到終點。
link |
你可能在training的時候,你根本就不需要像我們想像的一樣,是繞了遠路,順著gradient的方向才從theta0走到thetaX大,這是B.M.Buffalo給我們的一個觀察。
link |
好,那剛才看的是一個一般的Fully Connected Forward Network,那如果沒記錯的話,實驗是做在NIST的上面,今天有另外一個實驗是看CNN,它是做在SciFar 10上面。
link |
然後呢,一樣我們看CNN的時候會發現說,最左邊這個,這邊是training起始的地方,中間這個是training停止的地方,就是你最後training停止的時候你得到network的參數。
link |
要注意,你最後training停止的時候你得到network參數,它不見得是local minima,它甚至不見得是critical point。
link |
所以如果你讀Ian Goodfellow paper的話,你會發現他寫的時候他是很小心的,他都沒有告訴你說這個地方叫做local minima或者是critical point,他都只說那是我的algorithm的solution。
link |
因為首先你要確定它是不是local minima,你要檢查hesion才知道它是不是local minima,你沒有檢查你怎麼能夠說它是一個local minima的。
link |
再來假設你要確定它是不是一個critical point,你至少要確定你的微分是0,如果你不確定微分是0,你的歸點是0,你其實也不能夠說它是critical point。
link |
所以Ian Goodfellow他從來沒有說過這個點叫做critical point,他只說它就是他的algorithm的solution。
link |
所以從initial的地方到最後algorithm的solution,中間的變化也是頗為平坦的,然後再往更右邊去,再往更右邊去會發現說loss就急遽的上升。
link |
所以確實這個最後找到的solution看起來有點像是一個local minima,雖然不能百分之百保證它是,但是看起來有點像。
link |
那有人會說會不會是因為我們的解析度不夠,如果解析度高一點也許就會看到很多的local minima。
link |
這邊Ian Goodfellow提供了一個解析度比較高的圖,他把這個位置放很大,然後來觀察,發現說確實有一點點高低起伏,這個點好像是比旁邊還要低的。
link |
所以如果你用gradient descent,因為這個地方稍微高一點,因為gradient descent就是順著那個坡度走嘛,除非你有momentum,不然你沒有辦法逆勢而為走過這個地方。
link |
所以我們現在走的時候,它應該還是有繞路,它並不是完全順著這條線走,它應該還是有繞路避開這個山坡的地方,最後才能夠走到solution。
link |
不過助教上週也有講說,如果他把解析度放得非常非常大,他其實是有看到一些高低起伏的,那這個就留給大家作業的時候觀察,看看Ian Goodfellow是不是也在騙我們這樣子。
link |
也有可能就是比如說他的network太shallow了,所以他才沒有觀察到那些高低起伏,也許當network非常深的時候,你就可以觀察到一些崎嶇的變化,也說不定。
link |
這個是更多的實驗嘛,因為我們剛才發現說很難找到local minima,非常難找到local minima,他說今天如果隨便找兩個點,然後把它們連在一起,你會發現它的曲線看起來的變化像是這個樣子,非常平坦,你很難找到一些高低起伏的地方。
link |
那這邊是另外一個case,他說他的0.0跟1.0分別是兩個solution,所以從兩個不同的initialization圈下去,得到兩個不同的最終的參數的solution,然後在這兩個參數solution中間連線的這個地形,這邊我們就可以看到一個高起來的地方。
link |
所以看起來像是說,這個solution有點像是一個local minima,這另外一個solution看起來也有點像是一個local minima,然後中間有一個高起來的小山丘,把它們分開在兩邊,這個就是一些觀察。
link |
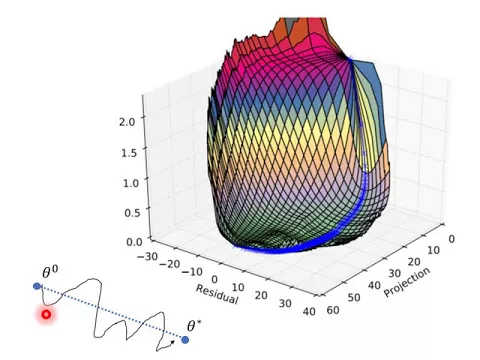
那剛才觀察的是只有一個維度而已,那如果觀察兩個維度呢?怎麼觀察兩個維度呢?這邊的做法是說,一個維度是從θ0到θstart,這個代表的是projection這一維。
link |
那另外一個維度是限在你的參數跟這一條藍色的線中間的距離,這個叫做residual,所以你今天實際上在train的時候,你是從θ0走到θstart,這一條藍色的線的座標是projection這一維的座標。
link |
然後這個residual這一維的座標,代表的是現在走的這一條線,它跟藍線中間的距離,那要注意一下,因為今天在走的時候,舉例來說在這個點,你的residual是這個點和藍線的距離,這邊是這個點和這一條線的距離,它們的方向是不一樣的。
link |
但是它們都是正的值,我不知道大家知不知道我的意思。
link |
所以這個residual這個方向,並不是高維空間中的某一個固定的方向,它其實不斷地在旋轉,我不知道大家知不知道我的意思,假設這個是起始的地方,這個是終止的地方,其實要終止的地方是這一條線。
link |
那你在train level的參數的時候,在高維空間中,從這一點走到這一點,它並不是這樣走直線過去的,它是歪歪曲曲的走,它可能有時候往上偏一點,然後再下來,然後有時候又往右邊偏一點,再進來,然後再往左邊偏一點。
link |
那在算residual的時候,你算的是現在你的參數偏離這一條連線中間的距離,所以如果在這個地方,假設一開始先往上走,在這個地方,你所謂的偏離的距離是指往上的這個方向,然後接下來如果往右偏,它指往右這個方向,現在往左邊,它指的是往左這個方向,所以這個所謂的residual,它並不是一個固定的方向。
link |
你可能會說,那怎麼不設一個固定的方向?舉例來說,也許為什麼不說我們就看這個方向跟這個方向,這樣就好,等一下會講為什麼。在Ian Goodfellow的paper裡面,他不是這麼做的,他的另外這個residual方向是不斷地改變的。
link |
那如果觀察了它,有了這個現象,有了這個東西以後,你就可以把剛才在一維上的觀察拓展到在二維上的觀察。所以他觀察的時候是在二維上的,一開始在這個地方,然後慢慢地滑下來、滑下來、滑下來、滑下來,然後很快就滑到一個比較像是谷地的地方,然後最後走到終點。
link |
但是你如果觀察,我們剛才只看了這個方向而已,但如果你觀察這個方向的話,會發現說machine並不是從這一點直接就走直線下來,它中間也是有繞了一些遠路,也就是它有偏離這兩點中間的連線,繞了一些遠路,才慢慢地從起點走到終點。
link |
當然,這條線,這個surface看起來非常平滑,這條線也看起來非常平滑,但是也有可能是因為這個visualization的關係,不見得真實的情況就是如此。
link |
假設Network一開始往上走的時候,那這個方向就是正的,反方向就是負的,所以你會發現說這個residual它總是正的,就是Network的這個藍色這條曲線,它的residual的值總是正的。
link |
為什麼?因為這個residual的值其實就是你現在的參數跟中間這個連線,中間的距離,就是那個residual的值。
link |
但是反向,就假設現在這個是你的θ0,這個是你的θstar,這是它中間的連線,這是實際上走的距離,然後這個東西是residual,反向就是負的,所以它是這麼畫的,這個就是它的visualization的方式。
link |
好,那有人就會說,為什麼這個感覺沒有非常的自然,有沒有比較自然一點的方法?他說,好吧,如果你要比較自然的話,那我們就固定住另外一個,我們現在有一個方向是這樣子,跟這個方向,跟這個θ0跟θstar中間連線的這個orthogonal的座標,其實有無窮多格啊,對不對?
link |
就隨便選一個。他說,隨便選一個,你會遇到什麼問題?隨便選一個,你會發現說,那個方向對你的loss的值幾乎是沒有影響的。
link |
這邊可能是從這裡到這裡是原來的這一條線,但是現在如果隨便選一個跟這兩點的連線orthogonal的方向,你會發現說它的loss幾乎是沒有影響,你就觀察不到任何有用的東西。
link |
然後他說,那如果我們再更進一步,不是選這一條線還有和它orthogonal連線,而是隨便地在參數的這個base上面隨便選兩個座標,參數就是一個非常高微的空間嘛,隨便選兩個座標,你會發現說,隨便選兩個座標,然後再把它的lossprint出來,會發現說,這兩個座標的變化對loss幾乎是沒有影響的。
link |
這個結果其實你仔細想想看也是合理的,因為假設你現在random pick兩個座標,那現在你的network假設是一萬維,那你的參數就是一萬維,它就是一個一萬維的空間的space嘛,假設你選的其中一個座標就是改變某一個參數,
link |
選的另外一個座標是,假設你選的某一個座標要改變第一個參數,選的另外一個座標要改變第二個維的參數,通常你只改變一個參數,你對結果幾乎是沒有什麼影響的,對不對?
link |
你要改變一大堆的參數,而且改變的方向要正好是對的,你對結果才會有影響,你只改變某一個參數,你對結果其實是沒有什麼影響的,所以你得到的結果就會這樣。
link |
你如果隨便在那個參數的space上面選兩個座標,visualize出來,你其實是看不到什麼有趣的結果的。
link |
講到這邊,大家有針對這個答案的問題想要問嗎?
link |
好,如果沒有的話呢,這邊有人會問說,剛才只看了C4的network跟CNN,也許更複雜的network會觀察到更複雜的error surface。
link |
Ian Goodfellow告訴我們說,他visualize了LSTM,看起來跟剛才的CNN或者是C4的network看起來差不多,這邊這是一個LSTM,他是train在patriot bank上,這個test是什麼就不太重要,他是train了一個language model,那這個是初始的地方,這是他的solution,在初始的地方跟solution中間的連線,看起來也是頗為平滑的。
link |
如果你visualize,用二維的方法,看那個residual跟projection的話,其實這個flow surface也是頗為平滑的,就沒有看到什麼特別的現象。
link |
這個實驗其實是想要告訴我們說,也許network的optimization,deep learning的optimization,也許比我們想像的還要簡單。
link |
這邊這個是另外一個visualization的方式,大家在座位裡面就選自己想要的visualization的方式來做,比如說像用Ian Goodfellow那個也可以,這個是另外一個可能的visualization的方式。
link |
這個方法是怎麼做的呢?這個方法是說,我們先train network很多次,你就每次都random initialize不同的值,然後就train下去,train一大堆的network。你random initialize一個值,然後train的過程中你就會每次update參數的時候,你就把那個network把它記錄下來,把那個network的參數把它記錄下來,那就會收集到一大把的network,那每一個network其實它的參數就是一個vector。
link |
接下來,你把那一大把的network用PCA或者是其他的方法降到二維,所以現在每一個network的參數,你可以在二維的平面上去visualize它。
link |
從這個實驗結果裡面發現什麼現象呢?這個是一個在Cypher 10上的六層的CNN得到的結果,會發現說,今天這邊每一條線代表某一個training的process,其實今天這邊的每一個數字代表了一個network,就代表一個network,那只是把它做降維,把它降到二維。
link |
每一個數字代表一個network的參數,它本來是一個上百萬維的vector,做降維,把它降到二維,所以你可以visualize到二維的平面上,每一個不同的顏色代表一個training的process。
link |
你就會發現說,每一個每一次training的process,最後得到的solution其實是非常不一樣的。這跟傳統的想像是不太一樣的,因為在傳統的想像裡面,我們覺得說整個network,也許我們用不同的方法做optimization的時候,最後可能收斂在差不多的地方,只是速度有所差別而已。
link |
我記得我曾經在某一年的上課的時候講說,如果你用Adam,用SGD,這樣不同的algorithm來train你的network的時候,他們可能只是速度有差,但是最後可能走到的local minima,或者走到的critical point,或者你找出來的solution可能是差不多的。
link |
仔細想想,我這樣講並沒有非常的精確,因為我之所以會這樣想像是因為說,我們用這些方法train出來的,不管是用SGD還是用Adam,往往train出來的network最後的performance差不多,所以我們覺得說它好像是同一個network,但是事實上未必是如此。
link |
從這個實驗裡面看起來,當我們今天每一次不同的training的process,給我們train出來的參數其實是非常不一樣的。雖然參數實際上是高微空間中的一個點,但我們把它project到二維,仍然保留了高微空間中的某些特性,如果它們距離越遠,就代表說它們在高微空間中越不像。
link |
所以這個實驗告訴我們,今天你不同的initialization,不同的training algorithm,最後雖然可能你得到的正確率都差不多,得到的model performance差不多,但是那些model可能是非常不一樣的model。
link |
這邊是另外一個例子告訴你說,那些model其實是不太一樣的model。在這個實驗裡面,這些reference我等一下都列在最後一頁了,在這個實驗裡面是跑說,現在有四個不同的optimization的algorithm,有SGD,還有大家都熟悉的Adam,還有一些大家比較不知道的,比如說RK2還有RK2加Adam,這個細節是什麼,對今天的這門課來說沒有那麼重要,反正就是另外一個algorithm就是了。
link |
他說,現在假設我們用了四個不同的algorithm,找到了四個不同的solution,這四個不同的solution到底其實是非常像的,只是不同的algorithm收斂的速度有差別,還是這四個algorithm會給我們非常不一樣的solution呢?
link |
他得到的答案是,這四個algorithm給我們的solution其實是非常不同的。他這邊就把這四個algorithm得到的solution把它拿出來,然後他做這兩個solution之間的interpolation,畫一下它們的變化,做這兩個solution之間的interpolation,它們的interpolation,還有它們四個的interpolation放在中間這個區域。
link |
你就會發現說,根據這個visualization,好像是說不同的這些algorithm,它們各自有一個不同的流域,就好像說這個是一個山丘,然後一個雨下下來的時候,當你用不同的algorithm,你就進入了不同的河川的流域,就進入了不同的集水區,就進入了不同的河川的流域。
link |
所以不同的algorithm最後給我們的solution其實是不太一樣的,那在不同的network架構上都得到了非常類似的結果。
link |
這個作者做了一個比較多的實驗,把各種不同的training algorithm通通都拿出來,然後每次三個三個拿來做visualization。這個圖其實有點小啦,你再自己回去check一下paper的細節,總之他得到的結論是,我們現在如果拿某三個algorithm出來做visualization,
link |
你會發現說這三個algorithm給我們的solution都是非常不同的。
link |
但是這個時候就會有同學問一個問題,這個所謂的不同是看起來參數非常不同,但有沒有可能看起來參數非常不同卻是同一個network呢?
link |
這句話是什麼意思?你記不記得我們今天在這份同學裡面的開頭我們就講過說,今天你有一個network,你把中間的hidden layer的兩個neural的參數調換,它其實還是同一個network啊,只是它們的參數非常的不一樣。
link |
對不對?如果你把那些參數排成一個vector,顯然是兩個不同的vector,但是它們其實是同樣的network,只是從參數上也不容易看出來而已。
link |
有沒有可能這邊所謂看起來不同的solution其實是同樣的network,只是它們的那個neural被調換的順序而已?
link |
所以他就做了另外一個實驗,這個實驗是說,要檢測這件事就看說,如果我們把同樣的data餵給不同的algorithm所串出來的network,它們有百分之多少是不一樣的。
link |
所以今天就如果要比較ADAM跟SGD這兩個方法的話,你就比較ADAM這個network它得出來的結果跟SGD得出來的結果,它們之間的差異。
link |
那你就會發現說,它們大概有,這個圖我們就不要詳加解釋好了,總之得到的結果是大概有8%左右的disagreement,可能會覺得8%聽起來好像還蠻小的。
link |
但是你仔細想想看,這邊可是坐在Cypher10上面哦,Cypher10現在隨便坐一坐,錯誤率都是10%左右的,所以8%的不一樣其實是非常大的不同。
link |
所以顯示說,現在不同的algorithm,它們找到不同的參數,而這些參數並不是equivalent的,我們並不是只是找到看起來不一樣,但是其實一樣的network,我們找到的就是本質上做的事情不太一樣的network,所以它們中間的disagreement其實是蠻大的。
link |
接下來另外一個要探討的問題是說,我們知道說不同的algorithm,它會帶給我們不同的training的結果,那為什麼會有不同的training的結果呢?在想像中啊,這個情況是,也許不同的algorithm走到這種比如說saddle point的時候,它們會選擇不同的岔路,所以從此它們的人生就不一樣了。
link |
在這個點,假設有某一個algorithm選擇往這邊走,另外一個algorithm選擇往另外一個方向走,往螢幕內部走過去的話,它們最後可能就會找到非常不一樣的solution。
link |
但是是什麼時候開始分道揚鑣的呢?在過去人們的想像裡面覺得說,也許這一個分道揚鑣是來自於training的起始,也就是一開始你在initialize的時候,你是initialize在某一個分水嶺上,然後這個不同的algorithm就會帶你到不同的河川的流域。
link |
所以今天的分別是在起始的時候,在這個分水嶺上發生的,也就是在training的一開始,你使用不同的algorithm,決定了你最後會走到哪一個流域。
link |
但是一旦流域已經被決定以後,不同的algorithm也許就沒有什麼影響了。
link |
就是你今天不同的algorithm只是在分水嶺的時候會決定你進去哪個流域,一旦決定了流域,也許不同的algorithm,也許差別就不大,這個是過去的想像。
link |
但是你可以做實驗來驗證這件事情,這個怎麼驗證呢?今天這個實驗是說,我們先拿某一個algorithm出來做training,然後training一陣子以後再把它換掉,換成新的algorithm。
link |
舉例來說,在這個實驗裡面,這個字有點小,希望大家看得清楚,這一條線是兩百個APA通通用SGD的結果,然後這一條線就是前一百五十個APA用SGD,最後五十個用ADDON。
link |
這邊是前一百個用SGD,後一百個用ADDON,這邊是前五十個用SGD,後一百五十個用ADDON。從這個結果就會發現說,你不管在什麼時候轉換成ADDON,最後你得到的正確率其實是差不多的。
link |
也就是說,跟我們過去直覺的想像不太一樣,過去覺得說,一開始決定用哪個algorithm才有差別,也許已經training一陣子以後,選哪個algorithm也許就沒差了。
link |
但是從這個實驗的結果來看,其實這個paper不只這個實驗,它做了很多很多的實驗,但是結果顯示都是這個樣子,你回去再去check一下。
link |
也許今天很神奇的地方是,就算是在training的末尾選擇了不同的algorithm,最後得到的結果仍然有可能是非常不同的。
link |
然後每個algorithm就有一個它自己非常特別的特性,雖然我們現在還不清楚那是什麼,但每個algorithm好像就有自己的特性,比如說你只要把SGD換成ADDON,它就很執著地會有一個跳上來,不管在training的哪一個stage都會發生這樣子的情形。
link |
這個圖是要說,不同的algorithm,它最後走到的區域仍然是非常不同的。
link |
舉例來說,它這邊說我們隨便畫找一條線,比如說這邊,我們看紅色這一條線,紅色這一條線是這一條,它說一開始用兩百個SGD,所以接下來從一百五十個SGD換成五十個ADDON。
link |
那這兩個Solution到底不一樣呢?從這邊的Loss看起來非常不一樣,但實際上會發現說這兩個Solution中間有一個非常高的山丘,所以代表說這兩個Solution它們其實是在兩個不同的集水區,它們中間有山丘把它們隔起來,而用不同的algorithm帶我們走到不同的集水區。
link |
雖然說我們在非常接近結束的時候才換algorithm,但是最後的結果就變了。這個實驗講的也是非常類似的事情,它是說,比如說看這個圖,本來是用ADDON,然後這邊有個折線,就是說training半就突然換SGD。
link |
而今天這個縱軸不是accuracy,縱軸是跟出發點,跟initial的那個參數之間的距離,然後發現說現在的距離是越來越遠了。
link |
所以一旦換成SGD,不知道怎麼回事,它非常執著要往回走,而且不管在什麼地方換成SGD,它都想要往回走。
link |
這個演算法就有一個這樣的特性,雖然我們不知道它是什麼,但是觀察到這樣的現象。這件實驗就是要告訴你說,不同的演算法,不同的training,optimization,algorithm,其實它本身是有不同的特性的,雖然我們現在還不確定那個東西到底是什麼。
link |
那這邊是另外一個演算法的特性,你會發現說這邊有四種不同顏色的線,每一種顏色代表我們使用某一個演算法得到的結果。舉例來說,這邊藍色的這條線是用ADDON得到的結果。
link |
那淺藍色的也是ADDON的結果,只是是有加RK2,總之你就當作是一個ADDON的變形就是了。這個淺藍色的線也是ADDON的變形,就是ADDON跟它的變形。
link |
好,那現在呢,假設我們這邊是0的地方,這個是起始的位置,這個1.0的地方是你的solution,然後呢,你把這兩點之間連線,然後再繼續往右走,你就可以知道說,現在你找到的那個solution,它周遭看起來像是什麼樣。
link |
那你發現說,如果用ADDON的話,它找到的那個solution感覺是在一個比較平坦的谷地裡面。如果你不是用ADDON,用SGD的話,它找到的solution感覺是在一個比較尖銳的峽谷裡面,代表說它們找到的這個solution的特性是不太一樣。
link |
那這件事情等一下我會再提到,這其實對你的結果可能是有,對generalization這件事可能是有很大的影響。那它這邊有畫很多條線,代表說,同樣的實驗,不同的initialization,做很多次,得到的結果都一樣,SGD就是有這個特性,ADDON就是有這個特性。
link |
那這個實驗是什麼?這個實驗是想要講batch normalization對結果的影響。我們還沒有講到batch normalization,那之後會講。如果你不知道batch normalization是什麼,沒有關係,你就知道它是一個很屌的方法就是了,這個之後會講。
link |
然後這個很屌的方法就是用這個結果來呈現它到底有多屌,它的屌是怎麼樣?它的屌是說,這個有這麼好笑嗎?它的厲害之處在於,假設沒有batch normalization,它結果沒看到長這個樣子。
link |
上面是有用batch normalization,所以剛才看到的都是有用batch normalization的結果,你會發現說不同的solution,不同的solution間有一個很尖銳的分水嶺,但是假設你沒有用batch normalization的話,你會發現什麼現象?
link |
你會發現說不同的solution間有一個非常平坦的高原。那這個高原意味著什麼?這個高原意味著,假設你initialize的時候initialize在這個高原上,你可能會逃不出去,因為那高原很平,你在initialize這個地方,你最後會找不到路下去,你就找不到路下去。
link |
如果今天是在這個case,你initialize在這個分水嶺的地方,那反正你總是找得到一條路下去,你隨便走一走都找不到一條路下去,但initialize在高原的地方,你找不到路下去,但是這是沒有batch normalization,如果batch normalization就不會這樣。
link |
那這個意味著什麼?如果換另外一個角度來看,不是從Aerosurface的角度來看,高原的地方很平的地方意味著歸零點很小,那什麼時候歸零點很小?其實就是歸零點vanishing。如果你熟悉batch normalization這個技術的話,它可以善後對抗歸零點vanishing這個問題。
link |
你有時候圈圈圈圈到某個地方,歸零點很小,你就無法再update參數了,那其實中間這個高原的地方就意味著說這個地方的歸零點很小,你要是落在這個地方,你就無法update參數,就逃不出去了,那batch normalization可以解決這個問題。
link |
還有一個更精彩的,它做的事情是visualize有沒有做skip connection的network。skip connection是什麼?就是像receiver network就是有做skip connection。如果你不知道這個是什麼,沒關係,就是一種比較強的network架構,我們以後會講到。
link |
它發現說,它在做visualize的時候也會做一個特別的normalization,我們之前這篇paper沒有講到,它對不同的參數有做不一樣的normalization,它說沒做這個normalization是看不到這個結果的,要做它那個normalization才看得到這個結果。
link |
這個結果非常厲害,非常驚人。它這個厲害的地方是說,一般的network,如果沒有skip connection,你疊五十層,你試圖在二維的空間中去visualize它的參數,這邊就是選兩個dimension,然後visualize參數在那兩個dimension上面,後來發現說它的高低起伏是非常劇烈的。
link |
這跟剛才Ian Goodfellow做的實驗看起來有點不一樣,因為剛才看Ian Goodfellow的實驗結果好像是,結果都非常的平坦這樣子。
link |
這邊有兩個可能,但是沒有人做實驗去比較就是了,你可以有興趣你自己做做看。
link |
有兩個可能,一個是這篇paper裡面有做特別的normalization,是那個特別的normalization導致這種高低起伏的狀況,另外一個可能就是Ian Goodfellow visualize的network不夠深,要五十層才看得出這種結果。
link |
其實後面這篇paper有比較不同的層數,那可能我第二個理由是比較有可能的,因為當它visualize一個很淺的network,比如說只有十層的時候,它也看不到這種非常驚人的山水畫的那種感覺,要五十層的時候才有這個山水畫的感覺。
link |
但是他說,如果我們今天用了residual network這種架構,這個沒有用residual network的架構,一用residual network這個架構,這個架構太強了,馬上就變得很平這樣子,馬上就變得很平,就變得只有中間一個坑洞,然後你只要調到中間這個坑洞就沒事了,光是外面都是很平的。
link |
這就是一個比較安全的結果,就從某個角度告訴我們說它是怎麼做的。你問這個是怎麼畫的嗎?你如果是問軟體的話,我不知道這樣子。如果問實際上怎麼畫的,就我所知可能是現在找到的optimal solution當作原點,然後接下來它會去找兩個dimension,找兩個方向。
link |
我看Ian Goodfell的結果,那兩個方向你要好好選,不然你畫不出不同的高低起伏的變化。但我看這篇paper,如果我弄錯的話,之後你再糾正我,我如果沒記錯的話,它兩個方向是random選的,它隨便random選兩個方向,就會看到這樣的結果。有可能是它的特別的nomization方法所造成的影響就是了。
link |
這個就是那些paper,第一篇做visualization是Ian Goodfell的篇,原來是ICOR2015,然後不同的algorithm的是第二篇,第三篇是用PCA把它project到二維的,第四篇就是我剛才講的,看speed connection的。
link |
最後就是optimization方面的conclusion,首先我們學到了什麼是Hessian,然後我們知道所謂的linear的network,它雖然不是convex的,但是一個deep的linear network,它的所有的local minima都是global minima。
link |
我們有點期待nonlinear的network也是這個樣子,但是看起來好像不是nonlinear的一般的deep network,它終究是有local minima的。但是有一些推論告訴我們說,也許在一個很大的network裡面,雖然有local minima,但是local minima非常的罕見。
link |
所有的local minima,它的loss都比較低,今天loss比較高的critical point通通都是saddle point,假設這個假設是真的的話,我們只要能夠找到任何一個local minima,只要能夠避開那些saddle point,找到任何一個local minima,它的loss其實都在使用上可能都是足夠低的,這個是一個推測。