back to index
Deep Learning Theory 3-1: Generalization Capability of Deep Learning
link |
而接下來呢,我們就要來講一下在learning裡面最重要的generalization的這個問題。
link |
那我們都知道說,你今天把你的level train在你的training data上,得到training data上的error,並不是結束。
link |
今天真正重要的是,你在testing的data上得到的error有多少。
link |
所以你在training data上得到100%的正確率,得到0%的error,也不用太得意,因為搞不好在testing set上,你完全就是overfitting。
link |
那我們知道說,training data的error總是會比testing data的error還要大的,但問題是到底大多少呢?
link |
那machine learning的theory其實告訴我們說,無論你的data distribution長什麼樣子,有1減delta的機率,delta是你自己定的一個值,
link |
有1減delta的機率,你的testing的error會小於等於training的error,加上這一項我們寫作大寫的omega。
link |
我們等一下會再講說這一項到底是什麼東西。
link |
那這個式子告訴我們什麼?這個式子想要告訴我們的是說,假設你現在得到的training error有這麼高,
link |
那testing error一定小於等於training error再加上另外一項,這個是training error加上後面那一項。
link |
那testing error會落在這兩者中間,那這件事發生的機率是1減delta,但delta會影響你後面這一項。
link |
那至於實際上這個證明怎麼來的,就請參見田神的機器學習基石,我們就不要講田神有講過的東西,反正他的結果是這個樣子。
link |
那其實這個結果雖然我們在機器學習這門課沒有講過,但是他的得到的結論其實是非常直覺而合理的,首先這個delta對這一項的影響當然是delta越小,這項就越大。
link |
假設你要你的這件事發生,你越肯定這件事會發生的話,那這一項就會越大。
link |
就假設說你希望發生這件事的機率是0.99999,非常可能會發生,那這個training error跟testing error,它們中間的差距就會非常大。
link |
因為為了要保證這件事一定會發生嘛,所以他就要把差距拉得非常大,這件事情才能夠一定會發生,才會一定落在這個range裡面。
link |
那當然這個是一個upper bound,就是說這是你的training error,這是training error加某一項,那你說你testing error落在中間這個範圍內到底是落在哪裡,是很接近training error還是離很遠,我們不知道,這個理論沒告訴我們這麼多。
link |
這個理論有時候一算出來啊,不小心後面這一項都是大於1的這樣子,你知道training error最大就是1啊,它這個很容易算出來就大於1的,所以不見得特別有用。
link |
你等一下會告訴你說,我有99%的機率,我知道說我的error一定會小於200%這樣子,那就沒有什麼用這樣子,但它就是一個upper bound就是了,到底最後11個error是跟training很近,還是其實很遠,那這個你不知道。
link |
好,那在這一項後裡面到底有什麼呢?它有一個r,r是什麼?r是training data量,training data越多,後面這一項就越小,那這個很合理嘛,training data越多,training data的error跟testing data的error就越接近,這個你不會有太多的問題。
link |
好,再來就是,它還跟另外一項有關,這項我們這邊寫做m,m代表什麼?m代表你現在要train的那個model它的capacity有多大,所謂一個model的capacity到底是什麼意思呢?
link |
我們其實講過很多次capacity這件事,但我們都沒有正式的定義它,所謂capacity這個東西從直觀上來講,你可以當成是你現在的model定出來的function set的大小,我們說每一個model或者是我們講的都是network,每一個network其實它都定義了一個function的set,這個function set的大小就代表這個network的capacity,這個function的set越大代表這個network的capacity越強。
link |
capacity就是能力的意思,所以function的set越大代表它的能力越強。
link |
但是今天在machine learning裡面,能力強並不是一件好事,當你的m越大的時候,你的後面這一項就會越大,當你的m越大,當你的model capacity越大的時候,training跟testing的error的差距就會越大。
link |
這個其實也是很直覺的,因為我們知道model越大,越容易overfitting,所謂overfitting的意思就是training跟testing的error差距很大,叫做overfitting。
link |
model越大,越容易overfitting,就代表說當你的model越大,也就是m越大的時候,e-train跟e-test它們的差距是越多的,這個是model的capacity告訴我們的。
link |
但這邊是一個非常vague的講法,實際上怎麼evaluatemodel的capacity呢?我們說這個capacity是function set的size,但function set裡面有幾個element呢?
link |
實際上如果我們看一個neural network的話,它的element是無窮多的,因為它的參數配置continuous,所以network是無窮多的。
link |
隨便拿一個function set出來,隨便拿一個network出來,它可能定義出來的function都是無窮多的,所以兩個無窮多的東西根本沒有辦法比它們之間能力的差異。
link |
所以我們必須要定出某一個數值化的東西來衡量每一個model的能力,你就知道在王道漫畫裡面都要定一個數值來evaluate每一個人物的能力,
link |
就像海賊王裡面會用倒立來evaluate一個人的能力一樣,已經沒有人知道倒立是什麼了,倒立並不是手撐在地上的那個倒立,倒立在水之祈禱那邊有出現過,後來就再也沒有人記得這件事了。
link |
那怎麼樣evaluate一個model的能力呢?一個model的能力,用一個叫做VC dimension,這邊寫做DVC的東西來衡量它,VC dimension越大就代表這個model的能力越強,在machine learning裡面能力強是一件壞事。
link |
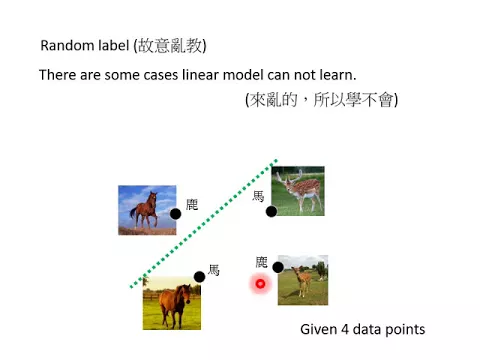
那VC dimension是什麼呢?我們用一個很簡單的方法來講,所謂的VC dimension意思是說,假設我們今天要教一個machine,假設我們有三筆data,假設我們現在要教machine分類的問題,
link |
那我們假設說,當然每張圖片其實是高維空間中的一個點,但我們現在假設說三號有某個方法,把每張圖片project到二維的平面上,就把它畫在投影片上,每張圖片都是一個二維的點,有三個二維的點在這張投影片上,我們有三個點,我們接下來要教machine。
link |
但是呢,我們今天在算VC dimension的時候,我們就是故意亂教,故意亂教的意思就是隨便給它label,今天在這三個點裡面,如果隨便給它label的話,有幾種可能呢?
link |
因為現在假設這是一個分類問題,我們是給一張圖片,分類它是鹿還是馬這樣子,那現在是一個分類的問題,總共有三個圖是二元分類的問題,總共有八個可能。
link |
但是在某些可能裡面就是完全亂教,就是指鹿為馬的意思,我們可能教它說這個是一個馬,這個也是一個馬,但是這是一個鹿這樣,我們就把所有各種不同可能label,通通分開每一個都拿去勸你的model,去勸勸看。
link |
假設在所有亂教的可能裡面,model都可以得到0%的錯誤率,你不管用哪一種label去教它,make sense的也好,只有這個是馬,這兩個是鹿,假設藍色代表馬的話,只有這個是正確的,剩下七個都是錯的,都是亂教。
link |
但是你不管用什麼樣的data去教machine,它都全部都學得會,它的錯誤率都是0,它都可以完全在training set上得到100%正確的答案,有亂教它都學得會。
link |
假設存在三個點亂教都學得會的話,這一個model它的VC dimension就大於等於三,所以今天它可以學得會的亂教的點越多,它的VC dimension就越大。
link |
今天假設我們的model是一個linear的model,linear的model在做分類的問題就是在平面上劃一條線,把兩個case分成兩邊,今天在這個case裡面,這八個case,不管你是怎麼樣的label,linear的model通通都可以學得起來。
link |
所以我們知道說,linear的model它的VC dimension是大於等於三的,當然deep的network它的VC dimension也是大於等於三的,但是實際上到底有多大呢?
link |
如果我們再繼續增加我們的data的數目,如果我們現在有四個點,那一樣我們窮取所有各種不同的亂教的方法去教machine,如果四個點的話,我們可能的label有二的四次方,也就總共有十六個可能。
link |
那你會發現說,某一些可能是linear的model學不會的,舉例來說,如果你告訴它說,這個是路,這個是馬,這個是馬,那linear的model它只能劃一條線,把兩個case分成兩邊,今天這個馬分在兩邊,路分在兩邊的case,linear的model它發現它怎麼學都學不會,
link |
而學不會的意思是說,你怎麼調linear model參數,你怎麼train,train這個linear的model,你怎麼train它,它都沒有辦法得到0%的錯誤率,它都沒有辦法完全答對training set上所有的問題。
link |
這個時候我們就知道說,linear的model,它的VC dimension是小於四的,因為今天如果只要有四個點,這四個點不管怎麼排,然後我們不管怎麼排,都存在一些亂教的情形是linear的model學不起來的,那這樣子就叫做linear model的VC dimension小於四。
link |
那我們知道說,如果對一個deep的network來說,它可以解這種問題,我們今天每次在從不是deep的network跨過deep的network的時候,我們都會舉XO的花紋嘛,它就告訴你說,這種問題linear model解不了,但是deep的network是可以解的,所以deep的network的model,它的VC dimension是大於等於四的,那你其實可以找到一些文獻估測這個network的VC dimension。
link |
那實際上,network的VC dimension到底有多大呢?在理論上,你可以找到一些理論的文獻,但是你不妨直接做個實驗來驗證。
link |
怎麼做實驗來驗證?拿出一個image的classification dataset,然後把那些image通通都random label,裡面如果是貓就標個狗,如果是狗就標個貓,故意亂標,隨機標。或者是說,如果你是拿at least的data,每一張圖片你就隨機assign給它一個數字,隨便標,然後讓model去train,看它是不是可以得到100%的正確率。
link |
如果你不管怎麼隨便random,model都可以得到100%的正確率,你有五萬筆data,那就意味著說你至少知道network它現在的VC dimension是大於等於五萬。
link |
那實際上怎麼樣呢?實際上你會發現說,一個deep的model,它的capacity是大的一呼尋常的。
link |
這個實驗是做在SciFar 10上,這個就是ICLR Base Paper Award那篇paper,這個實驗告訴我們說,它在SciFar 10上,首先先train一個正常的SciFar 10的network,橫軸是training的step,縱軸是average的loss,當然很快的,loss就下降到零,這個沒有什麼特別的地方。
link |
接下來它說,如果現在把所有的image的label隨機亂標,那你得到的training的curve是紅色這一條線,最後其實也可以走到正確率,error是零,也就是正確率是100,所有的data,training set上的data都可以分對的,當然在training set上一定是壞掉嘛,因為那是完全不相干的東西嘛,但是network可以硬背五萬張的image。
link |
今天還有一些別的實驗,它說紅色是random label,綠色這條線是shuffle pixel,就是說它把image的input的pixel故意打亂,反正network還是學得起來,另外random就是說每一張image的pixel都是隨機打亂的,那這個shuffle是有固定的pattern打亂,粉紅色這條線是隨機打亂,反正也學得起來。
link |
那Gaussian就是說input的pixel根本就不是給它image,就是給它Gaussian的noise,反正通通都學得起來,非常強,你給它什麼data,network就是印記這樣子,所以代表它的capacity非常非常的巨大,然後從typical的machine learning的理論上告訴我們說,這是一個capacity很大的model,它非常容易overfitting。
link |
但是實際上,如果有了這個理論,你其實就會知道說,假設今天有兩個model,它們的training error都是零,那你要選哪一個model會讓你的testing error比較小呢?是不是要選capacity比較小的那一個model?
link |
通常capacity是跟你的network的參數有關,它們當然不是成正比的,但是參數越多,顯然capacity就是越大。所以今天,假設兩個network,它們都可以讓你的training error等於零,你顯然會選參數比較小的那個network,你顯然會選capacity比較小的那個network,以避免在testing上overfitting。
link |
但是我們看看實際上的,這邊想要做什麼?這邊就是train一個at least,沒有什麼特別的,我們就是train一個at least的。那我們多的是一個很typical的network,有三個hidden layer,每個hidden layer有100個unit,那我們用的是add-on。
link |
然後我們現在的training data,我記得我用多少,我故意用少一點,我只有一千筆training data,那為了要讓overfitting的狀況比較容易發生,所以故意用比較少的training data,training data少比較容易overfitting。
link |
好,train一個100個unit的network。好,train一下,train一下。好,這邊有,其實剛才那個參數量,你會發現說,有9萬個,只有10萬個參數,其實也比我們的training data還要多了。
link |
好,我們現在得到的testing accuracy是88.78,可能也沒什麼特別的這樣子,88.78。好,這個要調還真的是調不出來,這只是in case是這樣。
link |
好,那現在呢,如果是正常,有任何有學過機器學習的人都知道說,我們看一下training data的error,training data的正確率已經是100%,所以你今天training data的error是0,你今天要做的事情,如果你要讓你的performance變好,
link |
你要做的事情應該是減少你model的capacity,希望他在testing的時候可以得到比較好的performance,因為training error上面,你沒東西可以弄了,他覺得error已經到0了,他已經封頂了,所以就是說testing error它是小於等於兩項嘛,
link |
一項是training error,一項是後面的omega,你現在要弄的就是選一個capacity比較小的network,讓omega值比較小。但是現在假設我們很無腦地反其道而行,故意把它的unit變多,這個很難用,故意弄成1000個neuron,所以現在參數大概是100倍了。
link |
好,再確認一下,你覺得在training set上就不要管,training set正確率一定是100,因為現在network更大了,training set上正確率只會更高,training set上你覺得會比88.7%高還是比88.7%低呢,你覺得是一樣?
link |
好,那我們來問一下大家的想法好了,你覺得現在network的參數大概是100倍,會比88.7%高的同學舉手一下,有一些,會比88.7%低的同學舉手一下,多數同學都覺得會比88.7%低,你覺得會有87%這樣子,你覺得應該是季中季對不對,因為你如果變高比較surprise。
link |
好,確認看看,它只要90.3%,所以參數比較多的時候performance比較好的,你覺得會不會運氣好,再指一次,會不會賽到的,再指一次,還是比較好這樣子,所以神不神奇?
link |
有沒有很意外,正常有學過三天機器學習的人,都不覺得說在training error等於零的時候增加model的參數,performance會比較好,但是deep learning就是這麼神奇這樣子,你可能會覺得說這是一個很偶然意外的現象,但是其實不是這樣,已經有非常多人都report過一樣的結果。
link |
那我就把文獻列在,來源列在右下角,比如這個人說,他在at least上train一下,然後橫軸是hidden unit的數目,然後所以參數量是越來越多的,在training set上只要有32個neuron,其實你就可以得到100%的正確率,你的error就壓到零了,但是testing set上,隨著neuron的數目越來越多,你的error居然還會下降,這是一個結果。
link |
這是另外一個結果,另外一篇papers,他說,現在我們來做一下,at least跟sidebar tag,黑色這條線是training set上的loss,發現說training set上的loss大概在64個neuron以後,他的loss就是零了,紅色的線跟藍色的線都是testing set上的結果,唯一的差別是,紅色的線有做early stopping,early stopping有一點點那種regularization的效果嘛,
link |
你會看你的validation set決定什麼時候會停,所以有一點這個regularization的效果。那藍色這條線是說,不顧一切的就硬train下去,不做regularization,硬train下去,train到不能再train,一直train一直train這樣子,overfitting也不害怕這樣,就一直train下去,然後他說發現說,就算是藍色這條線隨著neuron參數越來越多的時候,他的error居然也是下降的,雖然training已經是零了。
link |
3810上這個現象比較不顯著,但還是可以看到一點這樣子的現象。
link |
然後這個是又是在另外一篇paper,那這篇paper沒有,他在testing set上的performance沒有變好,他只是說隨著參數越來越多,那testing set上的performance紅色這一條線,那training set上藍色這條線的error已經可以壓到零,紅色這條線並沒有隨著model capacity越來越大而error變大,他並沒有發生overfitting的狀況。
link |
那當然有可能會想說,你知道三人成虎,已經有三個人告訴你這件事了,所以他很有可能是真的,但有可能會覺得說也許是因為你調了參數這樣,你的network有很多參數可以調,會不會剛才那個demo什麼一百個neuron,一千個neuron是你故意千挑萬選,挑了某一組參數,讓大的network performance就是比較好,然後來騙騙大家這樣子。
link |
這邊呢,就有一個google的paper,暴做所有各種不同的參數的組合這樣子,他想在每一種不同的network的weight的情況下,就network的參數從左邊由少到多,在各種不同network的參數量下面,暴搜所有可能的各種不同的參數,running rate啊什麼之類的,暴搜所有參數,然後勸上千個network。
link |
然後這些network通通在CyberTank的training set上,train到在training set上的正確率是一百,就是錯誤率是零。
link |
接下來呢,他們說,那evaluate在testing set上,那這個縱軸是什麼?這個縱軸是generation gap,也就是training set跟testing set中間的差值,error的差值,那這個差值呢,越小代表越沒有overfitting。
link |
那你會發現說,最大的這些network,我們本來預期說最大的這些network應該是最overfitting的,但最大的這些network也有一些參數是可以讓它overfitting的,但整體來說,最大的那些network反而是最不overfitting的那些network。
link |
那為什麼呢?這其實是一個謎這樣子,真的,然後在實作上其實也是看到這樣的趨勢,你看看哦,這邊這個圖是那個image net上面的各式各樣不同的network,縱軸是top1的accuracy,那每一個球的大小代表那個network的參數量。
link |
你會發現說,當然有很多的例外,但整體來說它的趨勢是隨著球越來越大,那它的正確率就越來越高,那早年的時候用的network都比較小,比如說google net、residual net是比較小的,後來inception net,三板四板就越來越大,那它的正確率也越來越高。
link |
這邊還有另外一個實驗是說,neural network是自帶regularization的,這個實驗是這樣,它給你五個紅色的點,它是一個regularization的problem,input是x,output是y,給你五個紅色的點,要你把它們串在一起。
link |
那如果你今天是用一個polynomial function去fit那五個的點,當你的polynomial function的order很高,但你用九四方的function去fit這五個點的時候,你會發現那個九四方的function可能是震動得非常的劇烈,我們在第一堂課講寶可夢cp值的預測的時候就講過這些事情了。
link |
但是神奇的是,當你用一個network去fit這五個點的時候,從兩層一直到十二層,network它得到的結果其實是非常平滑的,就好像它自帶了regularization一樣。
link |
這些network train的時候並沒有做regularization,就是train下去,但是train出來的結果,它好像自帶regularization。
link |
有人就會說,也許是因為這些network的capacity不夠大,也許是因為它沒有九四方的polynomial function的capacity那麼大,所以才會看起來很平滑,好像自帶regularization。
link |
但是實際上,今天如果你畫一條藍色的折線,要network去fit這條藍色的折線,它完全可以fit這條藍色的虛線,它只是不想這麼做而已。
link |
也不知道為什麼,它明明有一個很大的capacity,它的力量很大,但那個力量卻是被regularize起來,卻是被封印起來的,它並不會把那個力量釋放出來。
link |
這個其實就是一個謎這樣子,就是告訴你說,network的capacity很大,但是在實作上卻發現它沒有那麼容易overfit。
link |
但我並不是說它一定不會overfit,但你永遠可以找到一些case,是你train一個很大的network,它overfit,但是它沒有你想像的那麼容易overfit。
link |
哦,沒有關係,反正訪問剛才沒有什麼要錄的,是按for,對不對?
link |
好,那原因不清楚這樣子,那有一些可能的猜測,有無聊的,還沒有看到特別有趣的,但比較無聊的是說,
link |
有人是說,之所以沒有overfit,是因為你用validation set挑好的參數,挑了一組不會overfit,這個答案好像沒有特別有趣。
link |
還有另外一個答案是說,有人說是因為SGD的關係,他說如果用gradient-based的方法來train你的model的時候,會有自帶regularization的效果。
link |
一個很簡單的解釋是,你可能就說,為什麼會這樣?一個很簡單的解釋是,你今天在train你的network的時候,你一開始不是random initialize嗎?
link |
那你random initialize的時候,你initialize的那個參數都很小,對不對?很接近原點。
link |
好,那接下來是從那個接近原點的地方開始去做update,那所以最後train出來的那個model應該跟距離原點的地方很近。
link |
那我們知道說做regularization的時候,你就是希望你的model的參數距離原點越近越好嘛,
link |
那也許用gradient descent,它這一個process就有點自帶regularization這樣子。