back to index
DRL Lecture 1: Policy Gradient (Review)
link |
好,各位同學大家好,那我們來上課吧。等一下我們大約講到四點四十的時候,助教會來講一下這個作業四之一。
link |
作業四之一就是做reinforcement learning,reinforcement learning policy gradient的部分其實在NL那門課有講過了,但是在NL那門課沒有reinforcement learning的作業,所以我們現在那個作業四之一是要做policy gradient。
link |
那今天這一堂課我們要講什麼呢?我們要講一個policy gradient的進階版,這個技術叫做proximal policy optimization,縮寫就是PPO。
link |
那這個技術有多屌呢?這個技術它是default reinforcement learning algorithm and open AI,open AI把這個方法當作他們default reinforcement learning的algorithm,所以今天假設你要implement reinforcement learning,也許這是第一個你可以嘗試的方法,就是PPO。
link |
那今天這一門課我們還是先幫大家複習一下policy gradient,這個部分也許有點快,所以如果你有問題的話,你就直接舉手打斷我。
link |
那接下來我們會講說,原來的policy gradient是on policy的方法,那怎麼從on policy的方法變到off policy的方法,那等一下會講on policy是什麼off policy是什麼。
link |
最後從on policy變成off policy以後再加一些constraint就變成了PPO,但是講這個技術之前,我們先看一下這個DeepMind跟open AI試出來的demo。
link |
那其實這個DeepMind跟open AI各有一篇PPO的paper,那是DeepMind先發了這個,如果我沒有記錯時間的話,應該是在去年七月的月初就發了這個PPO的paper。
link |
他們有說PPO不是他們propose的,他們site了一個reference,這個reference是什麼呢?這個reference是open AI的某一個人,我記得是Jones Goldman,他在Nips的tutorial裡面有提到PPO,但他還沒有寫paper。
link |
然後DeepMind就先寫了paper,然後propose了PPO這個方法,然後在裡面是siteNips那個tutorial影片的連結,然後過了數日之後,可能open AI就發現說被DeepMind搶先發走了,所以他們也迅速地發了另外一篇他們自己的PPO的paper。
link |
好,那我們來看一下這個DeepMind的demo,我這個滑鼠不太work耶,我覺得它可以讓這個機器人學會跑步。
link |
好,那我們來看一下這個DeepMind的demo,我這個滑鼠不太work耶,我覺得它可以讓這個機器人學會跑步。
link |
好,那我們來看一下這個DeepMind的demo,我這個滑鼠不太work耶,我覺得它可以讓這個機器人學會跑步。
link |
好,那我們來看一下這個DeepMind的demo,我這個滑鼠不太work耶,我覺得它可以讓這個機器人學會跑步。
link |
好,它就可以讓機器人學會走路,這種問題其實還蠻難的,所以能學起來其實是蠻厲害的。
link |
好,這個是OpenAI的demo,在它這個demo裡面它也一樣是控制一個機器人,然後這個機器人會在球場上去找紅色的球,它會吃紅色的球,然後會有白色的球一直攻擊它。
link |
好,那機器人被打倒以後,它就會自己學著站起來,然後它會去找紅色的球。我覺得這個demodemo的不只是PPO,它demo其實是人生,你知道嗎?
link |
就是說,在人生裡面你有很多的目標,就告訴你說,你念完國中、念完高中以後你就輕鬆了,然後念高中以後告訴你說,念大學你就輕鬆了,念大學告訴你說,拿個博士你就輕鬆了,拿個博士告訴你說,當個教授你就輕鬆了。
link |
但其實結果一直都沒有很輕鬆,然後念高一直在前面,然後會有生命中無情的打擊,它居然沒有把它站起來。但是你還是要掙扎的站起來,就是這樣子。
link |
好,所以這個demo是人生,好,那我們就來先複習一下Policy規點,PPO是Policy的規點一個變形,所以我們先講Policy規點。
link |
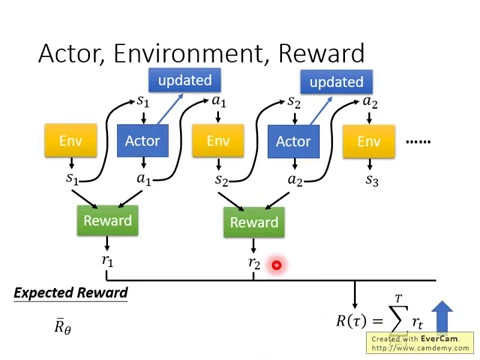
好,那在reinforcement learning裡面有三個component,一個actor,一個environment,一個reward function,在我們作業四之一裡面就是要讓機器玩video game,那這個時候你的actor做的事情就是去操控遊戲的搖桿,比如說向左、向右、開國等等。
link |
那你的environment就是遊戲的主機負責控制遊戲的畫面,負責控制怪物要怎麼移動,你現在要看到什麼畫面等等。那最後所謂的reward function就是決定當你做什麼事情發生什麼狀況的時候,你可以得到多少分數,比如說殺一次怪就得到20分等等。
link |
那同樣的概念用在圍棋上也是一樣,actor就是alphaGo,它要決定下哪一個位置,那你的environment就是對手,那你的reward function就是按照圍棋的規則,贏就是得一分,輸就是得負一分等等。
link |
那在reinforcement learning裡面,你要記得說environment跟reward function不是你可以控制的,environment跟reward function是在開始學習之前就已經事先給定的,你唯一能夠做的事情是調整你的actor,調整你的actor裡面的policy,使得它可以得到最大的reward。
link |
你可以調整這個actor,environment跟reward function是事先給定,你是不能夠去動它的。好,那這個actor裡面會有一個東西,會有一個policy,這個policy決定了actor的行為。
link |
那所謂的policy就是給一個外界的輸入,然後它會輸出actor現在應該要執行的行為。那今天假設你是用deep learning的技術來做reinforcement learning的話,那你的policy就是一個network,那我們知道說network裡面就有一堆參數,我們用theta來代表pi的參數。
link |
好,那今天你的policy它是一個network,這個network的input它就是現在machine看到的東西,如果讓machine打電玩的話,那machine看到的東西就是遊戲的畫面。
link |
當然讓machine看到什麼東西會影響你現在training到底好不好training。舉例來說,在玩遊戲的時候,也許你覺得遊戲的畫面前後是相關的,也許你覺得說你應該讓你的policy看從遊戲起初始到現在這個時間點所有畫面的總和,你可能會覺得你要用一個RN來處理它,不過這樣子你會比較難處理就是了。
link |
那要讓你的machine你的policy看到什麼樣的畫面,這個是你自己決定的。那等一下在講作業四之一的時候,助教會給你一些tips,給你參考,讓你知道說給機器看到什麼樣的遊戲畫面可能是比較有效的。
link |
好,那在output的部分,output的部分輸出的就是今天機器要採取什麼樣的行為。這邊這個是具體的例子,你的policy就是一個network,input就是遊戲的畫面,那它通常就是由pixel所組成的。
link |
那output就是看看說現在有哪些選項是你可以去執行的,那你的output layer就有幾個neuron,假設你現在可以做的行為就是有三個,那你的output layer就是有三個neuron,每個neuron對應到一個可以採取的行為。
link |
那input一個東西以後,你的network就會給每一個可以採取的行為一個分數,接下來你把這個分數當作是機率,那你的actor就是看這個機率的分布,根據這個機率的分布決定他要採取的行為。
link |
比如說70%會走left,20%走right,10%開火等等,機率分布不同,你的actor採取的行為就會不一樣。這個是policy的部分,它就是一個network。
link |
那接下來用一個例子具體的很快的說一下說,今天你的actor是怎麼跟環境互動的。首先你的actor會看到一個遊戲的畫面,這個遊戲的畫面我們就用S1來表示它代表遊戲初始的畫面。
link |
接下來你的actor看到這個遊戲的初始畫面以後,根據它內部的network,根據它內部的那個policy,它就會決定一個action,表示它現在決定的action是向右。
link |
那它決定完action以後,它就會得到一個reward,代表它採取這個action以後,它會得到多少的分數。
link |
那這邊我們把一開始的初始畫面寫作S1,我們把第一次執行的動作叫做A1,我們把第一次執行動作以後得到的reward叫做R1。那不同的文獻其實有不同的定義,有人會覺得說這邊應該要叫做R2,這個都可以,這個都可以,你自己看得懂就好了。
link |
那接下來就看到新的遊戲畫面,你的actor決定一個行為以後就會看到新的遊戲畫面,這邊是S2,然後把這個S2輸入給actor,然後這個actor決定要開火,然後他可能殺了一隻怪就得到5分,然後這個process就反覆的持續下去。
link |
直到今天走到某一個time step,執行某一個action,得到reward之後,這個environment決定這個遊戲結束了,比如說如果在這個遊戲裡面你是控制綠色的船去殺怪,如果你被殺死的話,遊戲就結束了,或者你把所有的怪都清空,遊戲就結束了。
link |
一場遊戲叫做一個episode,把這個遊戲裡面所有得到的reward統統總合起來就是total reward,這邊用R來表示它。
link |
今天這個actor存在的目的就是想辦法去maximize它可以得到的reward,這邊是用圖像化的方式來再跟大家說明一下你的environment actor和reward之間的關係。
link |
你可以把它看作是一個function,雖然它裡面不見得是neural network,可能是rule based的規則,但你可以把它看作是一個function。這個function一開始就先吐出一個step,接下來也就是遊戲的畫面。
link |
接下來你的actor看到這個遊戲畫面的S1以後,他吐出A1,然後接下來environment把這個A1當作他的輸入,然後他再吐出S2,吐出新的遊戲畫面。
link |
actor看到新的遊戲畫面,又再決定新的行為A2,然後environment看到A2再吐出S3,這個process就一直下去,直到environment覺得說應該要停止為止。
link |
在一場遊戲裡面,我們把environment輸出的S跟actor輸出的行為A,把這個S跟A全部串起來,叫作一個trajectory。每一個trajectory,你可以計算它發生的機率。假設現在actor的參數已經被給定的話,就是setup,根據這個setup,你其實可以計算某一個trajectory發生的機率。
link |
你可以計算某一個回合、某一個episode裡面發生這樣子的狀況的機率。怎麼算呢?某一個trajectory,在假設你的actor的參數就是θ的情況下,某一個trajectory它的機率就是這樣算的。
link |
你先算說environment輸出S1的機率,再計算根據S1執行A1的機率,根據S1執行A1的機率是由你的policy裡面的network的參數θ所決定的。
link |
它是一個機率,因為我們之前有講過說,你的policy的network它的output其實是一個distribution,你的actor是根據這個distribution去做setup,決定說現在實際上要採取的action是哪一個。
link |
接下來,你這個environment,這邊是畫寫說是根據A1產生S2,其實它是根據A1跟S1產生S2,因為你想說S2跟S1還是有關係的,下一個遊戲畫面跟前一個遊戲畫面通常還是有關係的,至少是連續的。
link |
所以這邊是給定前一個遊戲畫面S1跟你現在你的actor採取的行為A1,然後會產生S2。那這件事情它可能是機率也可能不是機率,這個是就取決於那個environment,就是那個主機它內部的設定是怎樣。
link |
看這個主機在決定要輸出什麼樣遊戲畫面的時候有沒有機率,因為如果沒有機率的話,那這個遊戲每次的行為都一樣,你只要找到一條path就可以過關了,這樣感覺是蠻無聊的。
link |
所以遊戲裡面通常是還是有一些機率的,你做同樣的行為,給同樣的前一個畫面的下一次產生的畫面,其實不見得是一樣的。
link |
那這個process就反覆繼續下去,你就可以計算說一個trajectory S1、A1、S2、A2它出現的機率有多大。
link |
在這邊只是把這個機率把它寫出來而已。那這個機率取決於兩件事,一部分是environment本身的行為,就environment的這個function,它內部的參數或內部的規則長什麼樣子。
link |
那這個部分就最像P of S T加1 given S T A T,代表的是environment,這個environment最像通常你是無法控制它的,因為那個是人家要寫好的,你不能控制它。你能夠控制的是這個,你能控制的是P set of A T given S T。
link |
你的actor要採取什麼樣的行為,A T這件事會取決於你actor的參數,你的pass的參數,所以這個部分是actor可以自己控制的。隨著actor的行為不同,每一個同樣的trajectory,它就會有不同的出現的機率。
link |
好,那我們說在這個reforce learning裡面,除了environment跟actor以外,還有第三個角色叫做reward function。reward function做的事情就是根據在某一個state採取的某一個action決定說現在這個行為可以得到多少的分數,它是一個function,給它S1 A1,它告訴你得到R1,給它S2 A2,它告訴你得到R2。
link |
我們把所有的小R統統加起來,我們就得到了大R。我們這邊寫做大R的頭,代表說是某一個trajectory頭,在某一個trajectory頭,在某一場遊戲裡面,某一個episode裡面,我們會得到的大R。
link |
好,那今天我們要做的事情就是調整actor內部的參數setup,使得大R的值越大越好。但是實際上,reward它並不只是一個scanner,reward它其實是一個random variable,這個大R其實是一個random variable。為什麼呢?
link |
因為你的actor本身在給定同樣的state會做什麼樣的行為,這件事情是有隨機性的。你的environment在給定同樣的action,要採取什麼樣的observation,要產生什麼樣的observation,本身也是有隨機性的。
link |
所以這個大R其實是一個random variable,你能夠計算的是它的期望值,你能夠計算的是說,在給定某一組參數setup的情況下,我們會得到的這個大R的期望值是多少。
link |
那這個期望值是怎麼算的呢?這個期望值的算法就是窮取所有可能的trajectory,每一個trajectory它都有一個機率,比如說,如果你今天你的setup是一個很強的model,那它都不會死,如果今天有一個episode是很快就死掉了,它的機率就很小,如果一個episode是都一直沒有死,那它的機率就很大。
link |
那根據你的setup,你可以算出某一個trajectory的tau出現的機率,接下來你計算這個tau的total reward是多少,把total rewardweighted by這個tau出現的機率,summation over all的tau顯然就是這個期望值,顯然就是given某一個參數你會得到的期望值。
link |
或者你會寫成這樣,從psetoutoftau這個distribution,從psetoutoftau這個distribution,sample一個trajectory tau,然後呢,計算outoftau的期望值,就是你的expected reward。
link |
好,那我們要做的事情就是maximize the expected reward,怎麼maximize the expected reward呢?我們用的就是Gradient Asset,因為我們是要讓它越大越好,所以不是Gradient Descent,是Gradient Asset,所以跟Gradient Descent,唯一不同的地方就是本來在update參數的時候要減,現在變成加,是Gradient Asset。
link |
然後做Gradient Asset,你就必須去計算Rbar,這個expected reward它的Gradient,Rbar的Gradient怎麼計算呢?這個跟我們上週講那個GAMES產生做sequence generation的式子其實是一模一樣的,所以這個部分我們就是很快把它走過去,我們說Rbar我們取一個Gradient,這裡面只有psetout是跟setout有關的,所以Gradient就放在psetout這個地方。
link |
那R這個reward function它不需要是differentiable,不需要是可為的,我們也可以解接下來的問題,舉例來說如果是在那個game裡面,你的這個R其實是一個discriminator,它就算是沒有辦法為分也無所謂,你還是可以做接下來的運算。
link |
那接下來要做的事情,這個大家可能都看過很多次了,分子分母上下同成psetout of tau,接下來我就會告訴你說,後面這一下,psetout of tau的Gradient除以psetout of tau,其實就是log psetout of tau的Gradient,或者是你之後就可以直接背一個公式,就某一個function f of x,如果你對它做Gradient的話,就等於f of x乘上Gradient log f of x。
link |
所以今天這邊有一個Gradient psetout of tau,代進這個公式裡面,這邊應該變成psetout of tau,乘上Gradient log psetout of tau。
link |
然後接下來這邊有summation over tau,然後又有把這個R跟這個log這兩項weighted by psetout of tau,那既然有weighted by psetout of tau,它們就可以被寫成這個expected的形式,也就是你從psetout of tau這個distribution裡面sample tau出來,去計算R of tau乘上這個Gradient log psetout of tau,然後把它對所有可能的tau做summation。
link |
就是這個expected的value,然後接下來這個expected的value實際上你沒有辦法算,所以你是用sample的方式來sample一大堆的tau,你sample大N筆tau,然後每一筆你都去計算它的這些value,然後把它全部加起來,最後你就得到你的Gradient,你就可以去update你的參數,你就可以去update你的agent。
link |
那這邊我們跳了一大步,這邊這個psetout of tau,我們前面有講過說psetout of tau是可以算的,那psetout of tau裡面有兩項,一項是來自於environment,一項是來自於你的agent,來自environment那一項其實你根本就不能夠算它,你對它做這個Gradient是沒有用的,因為它跟那個setup是完全沒有任何關係的,所以你不需要對它做Gradient。
link |
你真的會對它做Gradient的,只有log psetout,at,even,st而已。
link |
好,那這個部分其實你可以非常直觀的來理解它,也就是在你sample到的data裡面,你sample到在某一個state,st要執行某一個action,at,那如果在某一個state,st執行某一個action,at,最後導致整個trajectory,tau,就是這個st跟at它是在整個trajectory,tau裡面的某一個state跟action的配置。
link |
假設你在st執行的at,最後發現tau的reward是正的,那你就要增加這一項的機率,你要增加在st執行的at的機率,反之在st執行的at會導致整個trajectory的reward變成負的,你就要減少這一項的機率,那這個概念就是這麼簡單。
link |
那因為我們在作業裡面要實作嘛,那這個怎麼實作呢?你實作的方法就是這個樣子,你用gradient asset的方法來update你的參數,所以你原來有一個參數set啊,你把這個set啊,加上你的gradient這一項,然後當然前面要有一個learning rate,learning rate其實也是要調的,而且你要用andon,nsprop等等,還是要調一下。
link |
那這個gradient這一項怎麼來呢?就要套下面這個公式把它算出來,那在實際上做的時候,要套下面這個公式,首先你要先收集一大堆的s跟a的pair,你還要知道說這些s跟a,如果實際上在跟環境互動的時候,你會得到多少的reward,所以這些資料你要去收集起來,這些資料怎麼收集呢?
link |
你要拿你的agent,它的參數是set啊,你要拿你的agent去跟環境做互動,也就是你拿你現在已經train好的agent先去跟環境玩一下,先去跟那個遊戲互動一下,那互動完以後你就會得到一大堆的遊戲的記錄,你會記錄說今天先玩了第一場,在第一場遊戲裡面,我們在state s1採取action a1,在state s2採取action a2。
link |
那要記得說其實今天在玩遊戲的時候是有隨機性的,所以你的agent本身是有隨機性的,所以在同樣的state s1不是每次都會採取a1,所以你要記錄下來,在state s1採取a1,在state s2採取a2,然後最後呢,整場遊戲結束以後得到的分數是r1,那你會sample到另外一筆data,也就是在另外一場遊戲裡面,你在第一個state採取這個action,在第二個state採取這個action,在第二個遊戲畫面採取這個action,
link |
然後你得到的reward是r2,你有了這些東西以後,你就去把這邊你sample到的東西,帶到這個gradient的式子裡面,把gradient算出來,也就是說你會做的事情是把這邊的每一個s跟n的pair拿進來,算一下它的probability,算一下它的low probability,
link |
你計算一下在某一個state採取某一個action的low probability,然後對它取gradient,然後這個gradient前面會呈一個weight,這個weight是什麼,這個weight就是這場遊戲的reward。
link |
你有了這些以後呢,你就會去update你的model,那你update完你的model以後,你回過頭來要重新再去收集你的data,不是收集reward,收集你的data,然後再收集新的data以後,再update model,然後再收集新的data,再update model,這個就是大家在作業裡面要implement的東西。
link |
這邊要注意一下,就是一般parsigrenia,你sample的data就只會用一次,你把這些datasample起來,然後拿去update參數,這些data就丟掉了,你要重新再sampledata才能夠再重新update參數,等一下我們會解決這個問題。
link |
接下來就是實作的時候你會遇到的一些細節,實際上這個東西到底是怎麼實作的呢?因為到時候你要真的實作嘛,所以我們還是講一下,這個東西到底實際上在用這個deep learning的framework在implement的時候,它是怎麼實作的呢?
link |
其實你的實作方法是這個樣子,你要把它想成你就是在做一個分類的問題,分類問題大家都會嘛,對不對?現在我們電機營都已經教大家用cancel flow implement and list classification,所以這個理論上每個人都會做classification。
link |
它在classification裡面就是input一個image,就是做input一個image,然後output就是要決定說是十個class裡面的哪一個。那怎麼做classification,你當然要蒐集一些training data,你要有input跟output的pair。
link |
那今天在reinforcement learning裡面,在實作的時候,你就把你的state當作是classifier的input,你就當作你是要做image classification的problem,只是現在的class不是說image裡面有什麼object,現在的class是說看到這張image,我們要採取什麼樣的行為,每一個行為就叫一個class。
link |
比如說第一個class叫做向左,第二個class叫做向右,第三個class叫做開伏。好,那這些訓練的資料是從哪裡來的呢?
link |
就我們說你要做分類的問題,你要有classifier的input跟它正確的output嘛,這些訓練資料哪來呢?這些訓練資料就是從這個sampling的process來的。
link |
假設在sampling的process裡面,你sample到某在某一個state,你sample到你要採取action A,你就把這個action A當作是你的property,你在這個state,你sample到要向左,本來向左這件事的機率不一定是最高,因為你是sample,它不一定機率最高,反正就sample到向左,假設你sample到向左。
link |
那接下來在training的時候,你就告訴machine說,調整level的參數如果看到這個state,你就向左。好,那在一般的classification的problem裡面,其實你在implement classification的時候,你的objective function你都會寫成這個minimize cross entropy,對不對,你都會寫成minimize cross entropy。
link |
那其實minimize cross entropy就是maximize log likelihood,所以你今天在做classification的時候,你的objective function,你要去maximize或minimize的對象,因為我們現在是maximum likelihood,所以其實是maximize,你要maximize的對象,其實就長這個樣子。
link |
那像這種loss function,你在tensorflow裡面,你一本不用手刻,它都有現成的function就是,你就call個function,它就會自動幫你算這樣子的東西。
link |
然後接下來,你就apply計算gradient這件事,那你就可以把gradient計算出來,這是一般的分類的問題。那如果今天是RL的話,唯一不同的地方只是,你要記得在你原來的這個loss前面,你要記得在你原來的這個loss前面,乘上一個weight。
link |
這個weight是什麼?這個weight是今天在這個state採取這個action的時候,你會得到reward,在這個state採取這個action的時候,你會得到reward。
link |
這個reward不是當場得到reward,而是整場遊戲的時候得到reward,它並不是在state S採取action A的時候得到reward,而是說今天在state S採取action A的這整場遊戲裡面,你最後得到的total reward這個。
link |
那你要把你的每一筆的training data都weighting來這個大R,然後接下來你就交給Tensorflow或Python去幫你算gradient,然後就結束了,就結束了,知道嗎?
link |
所以實作上就是這樣implement的,跟一般classification其實也沒太大的差別。
link |
那這邊有一些通常實作的時候你也許用得上的tip,一個就是你要add一個東西叫做baseline,所謂的add baseline是什麼意思呢?
link |
今天我們會遇到一個狀況是,我們說這個式子它直覺上的含義就是,假設在state S採取action A,會給你整場遊戲正面的reward,那你就要增加它的機率。
link |
如果說今天在state S執行action A,整場遊戲得到負的reward,你就要減少這一項的機率。但是我們今天很容易遇到一個問題是,很多遊戲裡面它的reward總是正的,最高就是零。
link |
譬如說打乒乓球,我們等一下是要作業四之一,是玩很簡單的,其實就是碰的遊戲。碰的遊戲,你的分數就是介於零分到二十一分間,所以你根本就不會得到負的分數,所以這個reward總是正的。
link |
所以假設你直接採用這個式子,你會發現說,在training的時候,你告訴model說,今天不管是什麼action,其實你都應該要把它的機率提升,這樣聽起來好像有點怪怪的。
link |
但理想上,這麼做並不一定會有問題,為什麼呢?因為今天雖然說R總是正的,但它正的量總是有大有小。
link |
你在玩乒乓球那個遊戲裡面,得到的reward總是正的,但是它是介於零分到二十一分之間,所以有時候你是得到二十分,有時你採取某些action可能是得到零分,你採取某些action可能是得到二十分。
link |
所以雖然說,假設你現在有三個action ABC可以執行,在某一個state你有三個action ABC可以執行,雖然現在根據這個式子,你要把這三項的分數都拉高,你要把這三項的機率都拉高,你要把這三項的log probability都拉高,但是它們前面weight的這個R是不一樣的。
link |
它們前面weight的這個R是有大有小的,所以weight小的,它上升的就少,weight多的,它上升的就大一點。因為今天這個log probability它是一個機率,所以這三項的和要是零,所以上升的少的,在做完normalize以後,它其實就是下降,上升的多的才會上升。
link |
這個是一個理想上的狀況,但是在實際上,你千萬不要忘了,我們是在做sampling。本來這邊應該是一個expectation,submission over所有可能的S跟A的pair,但是實際上你這次在學的時候,當然不可能是這麼做的,你只是sample了少量的S跟A的pair而已。
link |
所以今天因為我們做的是sampling,所以有一些action你可能從來都沒有sample到,在某一個state,雖然可以直接action有ABC三個,但你可能只sample到action B,你可能只sample到action C,你沒有sample到action A。
link |
現在所有action的reward都是正的,所以根據這個式子,今天每一項它的機率都應該要上升。現在你會遇到的問題是,因為A沒有被sample到,其他人的機率如果都要上升,那A的機率就下降。
link |
所以A可能不是一個不好的action,它只是沒被sample到,一個運氣不好,沒有被sample到。它不是一個不好的action,它只是沒被sample到而已,但是只是因為它沒被sample到,它的機率就會下降,那這個顯然是有問題的。
link |
要解決這個問題要怎麼辦呢?你會希望你的reward不要總是正的。為了解決你的reward不要總是正的這個問題,你可以做一個非常簡單的改變,就是把你的reward減掉一項叫做B,這一項B叫做baseline。
link |
你減掉這一項B以後,就可以讓R減B,就是這個小發號裡面這一項,有正有負。所以今天如果你得到的reward,這個RnotN,這個total reward大於B的話,就讓它的機率上升。
link |
如果這個total reward小於B,就算它是正的,因為遊戲裡面不可能有負的,所以如果正的很小,其實也是不好的,所以你就要讓這一項的機率下降。如果今天RnotN它小於B的話,你就要讓這個state採取這個action的分數下降。
link |
反正這個B怎麼設呢?你就隨便設,你就自己想個方法來設。一個最簡單的做法就是,你把那個total的值取絕對值,你把total的值取expectation,算一下total的平均值,你就可以把它當作B來用,你可以把total的平均值當作B來用,這是其中一個做法,你們可以想想看有沒有其他的做法。
link |
所以在實作上,你就是在implement的時候,在training的時候,你會不斷地把total的這個分數把它記錄下來,然後你會不斷地去計算total的平均值,然後你會把這個平均值當作你的B來用。
link |
這樣就可以讓你在training的時候,你今天這個log probability,乘上歸零這一項前面是有正有負的,這個是第一個tip。
link |
第二個tip,這個我們在machine learning的那一門課沒有講到,前面那個東西我們在machine learning的那一門課講過了,今天我們要講一個在machine learning那一門課沒有講過的tip,這個tip是這樣子的,今天你應該要給每一個action合適的credit,什麼意思呢?
link |
如果我們看今天下面這個式子的話,我們原來會做的事情是,今天在某一個state,假設你執行了某一個action A,它得到的reward,它前面乘上的這一項就是r of t-b。
link |
今天只要在同一個episode裡面,在同一場遊戲裡面,所有的state跟A的pair,它都會weighted by同樣的reward,它都會weighted by同樣的term。
link |
這件事情顯然是不公平的,因為在同一場遊戲裡面,也許有一些action是好的,也許有一些action是不好的,假設最後最終的結果,整場遊戲的結果是好的,並不代表這個遊戲裡面每一個行為都是對的,或是整場遊戲結果不好,但並不代表這場遊戲裡面每一個行為都是錯的。
link |
所以我們其實希望可以給每一個不同的action,前面都乘上不同的weight,這個每一個action的不同的weight,它真正的反映了每一個action,它到底是好還是不好。
link |
這邊就是舉了一個例子說,假設現在這個遊戲都很短,只會有三次互動,在SA這個state執行A1這件事得到5分,在SB這個state執行A2這件事得到0分,在SC這個state執行A3你得到-2分,整場遊戲下來你得到正三分。
link |
那今天你得到正三分,代表在state SB執行action A2是好的嗎?並不見得代表state SB執行A2是好的,因為這個正的分數主要是來自於在一開始的時候在state SA執行的A1,也許跟在state SB執行A2是沒有關係的,也許在state SB執行A2反而是不好的,因為它導致你接下來會進入state SC,然後執行的A3會扣分。
link |
所以今天整場遊戲得到的結果是好的,並不代表每一個行為都是對的。如果按照我們剛才的講法,今天整場遊戲得到的分數是三分,那到時候在training的時候,每一個state跟action的pair,它們都會被乘上正三。
link |
在理想的狀況下,這個問題如果你sample夠多,就可以被解決。為什麼?因為假設你今天sample夠多,在state SB執行A2的這件事情被sample到很多次,某一場遊戲在state SB執行A2,你會得到正三分,但是在另外一場遊戲在state SB執行A2,你卻得到了負七分。
link |
為什麼會得到負七分呢?因為在state SB執行A2之前,你在state SA執行A2得到扣五分。
link |
但這扣五分可能也不是中間這一項的錯,這扣五分這件事可能也不是在state SB執行A2的錯,因為兩件事情可能是沒有關係的,因為它先發生了這件事才發生,所以它們是沒有關係的。
link |
在state SB執行A2,它可能造成的問題只有會在接下來扣兩分,而跟前面的扣五分是沒有關係的。
link |
但是假設我們今天sample到的這項的次數夠多,把所有有發生這件事情的情況的分數統統都集合起來,那可能不是一個問題。
link |
現在的問題就是,我們sample的次數是不夠多的,在sample的次數不夠多的情況下,你就需要想辦法給每一個state跟action pair合理的credit,你要讓大家知道它合理的contribution,它實際上對這些分數的貢獻到底有多大。
link |
那怎麼給它一個合理的contribution呢?一個做法是,我們今天在計算這一個pair它真正的reward的時候,不把整場遊戲得到的reward全部加起來,我們只計算從這一個action執行以後所得到的reward。
link |
因為這個場遊戲在執行這個action之前發生的事情跟執行這個action是沒有關係的,前面的事情都已經發生了,那跟執行這個action是沒有關係的。
link |
所以在執行這個action之前得到多少reward都不能夠算是這個action的功勞,跟這個action有關的東西只有在執行這個action之後發生的所有reward把它總合起來,才是這個action它真正的contribution。
link |
才比較可能是這個action它真正的contribution。
link |
所以在這個例子裡面,在state SB執行A2這件事情,也許它真正會導致你得到的分數應該是負二分而不是正三分,因為前面的加五分並不是執行A2的功勞,實際上執行A2以後到遊戲結束前你只有被扣兩分而已,所以它應該是負二。
link |
同樣的道理就是,今天執行A2實際上並不應該是扣七分,因為前面的扣五分跟執行A2跟在state SB執行A2是沒有關係的,在state SB執行A2真正導致的問題只有你接下來被扣兩分而已,所以也許在state SB執行A2你真正會導致的結果只有扣兩分而已。
link |
好,那如果要把它寫成市值的話是什麼樣子呢?你本來你前面的weight是out of tau,是整場遊戲的reward總和,那現在改一下,怎麼改呢?改成從某個時間t開始,就假設這個action是在t這個時間點所執行的,
link |
從t這個時間點一直到遊戲結束,所有的reward R的總和才真的代表這個action是好的還是不好的。這樣大家了解我的意思嗎?
link |
好,那這邊大家有問題要問嗎?如果ok的話,如果你可以接受這個講法,接下來再更進一步,我們會把比較未來的reward做一個discount,為什麼我要把比較未來的reward做一個discount呢?
link |
因為今天雖然我們說在某一個時間點執行某一個action會影響接下來所有的結果,有可能在某一個時間點執行的action,接下來得到的reward都是這個action的功勞,但是在比較真實的情況下,如果時間拖得越長,影響力就越小。
link |
就是今天我在第二個時間點執行某一個action,那我在第三個時間點得到reward,那可能是在第二個時間點執行某一個action的功勞,但是獲了一百個tie state之後又得到reward,那可能就不是在第二個時間點執行某一個action得到的功勞。
link |
所以我們實際上在做的時候,你會在你的r前面乘上一個term叫做gamma,這個gamma它是小於1的,它會設個0.9或者是0.99,那如果你今天的r它是月之後的tie state,這個t term越大,這個r是月之後的tie state,它前面就乘上月多次的gamma,
link |
就代表說現在在某一個時間,在某一個state st執行某一個state at的時候,真正它的credit其實是它之後在執行這個action之後所有的reward的總和,而且你還要乘上gamma,這樣大家可以了解我的意思嗎?
link |
或是如果要舉一個很具體的例子的話,你就想像說現在這是遊戲的第一回合、第二回合、第三回合、第四回合,那你在遊戲的第二回合的某一個state執行at,它真正的credit到底是得到多少分數呢?
link |
它真正的credit得到的分數應該是,假設你這邊得到正一分,這邊得到正三分,這邊得到負五分,你真正得到的,它的真正的credit應該是1加上有一個decomp的pattern叫做gamma乘上3,再加上gamma的平方乘上負五分,這樣。
link |
所以雖然在某一個state執行這個action,你會影響接下來是我的結果,所以它所導致的它的credit是接下來是我的reward總和,但是離它越遠,它的責任就越小,離它越遠,gamma乘得越多,gamma是小一滴的,所以離它越遠,離它越遠,就是跟它的關係就越少了。
link |
好,如果大家可以接受這樣子的話,實際上你implement的時候就是這麼implement的,好,那這個b呢?b這個我們之後再講,它可以是state dependent的,事實上b它通常是一個network estimate出來的,這還蠻複雜的,它是一個network的output,這個我們之後再講。
link |
好,那把這個r減掉b這一項,這一項我們可以把它合起來,我們統稱為advantage function,我們這邊用a來代表advantage function,那這個advantage function它是dependent on s跟a,我們就是要計算的是說在某一個state s採取某一個action a的時候,你的advantage function有多大,然後這個advantage它一個上標,它這個上標是state,這個上標state是什麼意思呢?
link |
因為你實際上在算這一項的時候,你實際上在算這個submission的時候,你會需要有一個interaction的結果嘛,對不對?你會需要有一個model去跟環境做interaction,你才知道你接下來得到的reward會有多少。
link |
而這個sa就是代表說現在是用sa這個model跟環境去做interaction,然後你才計算出這一項,你才計算出這一項,從時間t開始到遊戲結束為止,所有的r的submission。
link |
這項減掉b,然後這個就叫advantage function,它的意義就是現在假設我們在某一個state st,質詢某一個action at,相較於其他可能的action,它有多好,它真正在意的不是一個絕對的好,而是說在同樣的state的時候,
link |
是採取某一個action at,相較於其他的action,它有多好,它是相對的好,不是絕對的好,那麼今天會減掉一個b嘛,減掉一個baseline,所以這個東西是相對的好,不是絕對的好。
link |
那這個a啊,這個我們之後再講,它通常是可以是有一個network estimate出來的,那這個network叫做critic,我們講到execritic的方法的時候,再講這件事情。