back to index
DRL Lecture 2: Proximal Policy Optimization (PPO)
link |
好,各位同學大家好,那我們開始上課吧。
link |
今天的規劃是這樣,我們先講PPO,這個是作業四之一用得到的東西,然後接下來講Q-learning,這是作業四之二用得到的東西,最後副教會來講一下作業四之二。
link |
上週我們做的事情是複習了一下Policy Gradient,我們今天要講的事情是Policy Gradient的一個變形,就是PPO。
link |
上週已經講過PPO是現在OpenAI default reinforcement learning的algorithm。在講PPO之前,我們要講on policy和off policy這兩種training方法的區別。
link |
那什麼是on policy,什麼是off policy呢?我們知道在reinforcement learning裡面,我們要learn的就是一個agent。如果我們今天拿去跟環境互動的那個agent,跟我們要learn的agent是同一個的話,這個叫做on policy。
link |
如果我們今天要learn的agent跟和環境互動的agent不是同一個的話,那這個叫做off policy。所以如果比較擬人化一點的講法的話,就是如果今天要學習的那個agent,他是一邊跟環境互動一邊做學習,這個叫on policy。
link |
如果他是在旁邊看別人玩,透過看別人玩來學習的話,這個叫做off policy。底下這個是麒麟王的比喻,如果阿光在下棋的話,他自己下自己學,這個是on policy。如果他在旁邊看走為下的話,這個是off policy。
link |
好,那為什麼我們會想要考慮off policy這樣子的選項呢?那我們來想想看我們今天講過的policy gradient。其實我們之前講的policy gradient,它是on policy還是off policy的做法呢?它是on policy的做法,為什麼?
link |
我們之前講說在做這個policy gradient的時候,我們會需要有一個agent,我們會需要有一個policy,我們會需要有一個actor,這個actor先去跟環境互動去收集資料,收集很多的淘。
link |
那根據他收集到的資料,會按照這個policy gradient式子去update你的policy的參數,這個就是我們之前講過的policy gradient。所以它是一個on policy的algorithm,你拿去跟環境做互動的那個policy跟你要認的那個policy是同一個。
link |
好,那今天的問題是這個樣子,我們之前有講過說,因為在這個update的式子裡面,其中有一項你的這個expectation應該是對你現在的policy setup所sample出來的trajectory做expectation。
link |
所以當你今天update參數以後,一旦你update的參數從setup變成setupline,那這一個機率就不對了,你之前sample出來的data就變得不能用了。
link |
所以我們之前就有講過說,policy gradient是一個會花很多時間來sample data的algorithm,你會發現大多數的時間都在sample data,那你的agent去跟環境互動以後,接下來就要update參數。
link |
你只能update參數一次,你只能update參數一次,你只能做一次gradient descent,你只能update參數一次,接下來你就要重新再去collect data,然後才能再次update參數,這顯然是非常花時間的。
link |
所以現在我們想要從onpolicy變成offpolicy的好處就是,我們希望說現在我們可以用另外一個policy,另外一個actor,setupline,去跟環境做互動,用setupline collect到的data去訓練setup。
link |
我們可以用setupline collect到的data去訓練setup,意味著說我們可以把setupline collect到的data用非常多次。你在做gradient descent的時候,其實gradient ascent是optimize某個數值,所以是gradient ascent。
link |
但是gradient ascent的時候,我們可以執行那個gradient ascent好幾次,我們可以update參數好幾次,都只要用同一筆data就好了。
link |
因為假設現在SEDA有能力從另外一個actor,setupline,它所sample出來的data來學習的話,那setupline就只要sample一次,也許sample多一點的data,讓SEDA去update很多次,這樣子就會比較有效率。
link |
所以怎麼做呢?這邊就需要介紹一個叫做importance sampling的概念,那這個importance sampling的概念不是只能用在RL上,它是一個general的想法,可以用在很多其他地方。
link |
我們先介紹這個general的想法。假設現在你有一個function f of x,那你要計算從p這個distribution,sample x,再把x帶到s裡面得到f of x,你要計算這個f of x的期望值。
link |
那怎麼做呢?假設你今天沒有辦法對p這個distribution做積分的話,那你可以從p這個distribution去sample一些data xi,那這個期望值,這個f of x的期望值就等同於是你sample到的xi,把xi帶到f of xi裡面,把xi帶到f of x裡面,然後取它的平均值就可以拿來近似這個期望值。
link |
假設你知道怎麼從p這個distribution做sample的話,你要算這個期望值,你只需要從p這個distribution做sample就好。
link |
但是我們現在有另外一個問題,那等一下我們會更清楚知道說為什麼會有這樣的問題。我們現在的問題是這樣,我們沒有辦法從p這個distribution裡面sample data,那等一下你可能說,怎麼不能從p這個distribution sample data,等一下會更清楚說為什麼不能從p裡面sample data。
link |
假設我們不能從p sample data,我們只能從另外一個distribution q去sample data,q這個distribution可以是任何distribution,不管它是什麼樣的distribution,在多數情況下等一下討論的東西都成立。
link |
我們不能夠從p去sample data,但我們可以從q去sample xi,但我們從q去sample xi,我們不能夠直接套這個式子,因為這邊是假設說你的xi都是從p sample出來的,你才能夠套這個式子,從q sample出來的xi套這個式子,你也不會等於左邊這一項期望值。
link |
所以怎麼辦?做一個修正,這個修正是這樣子的,期望值這一項其實就是積分f of x乘上p of x的x,然後我們現在上下都同乘q of x,上下同乘q of x不會改變任何式,
link |
但是我們可以把這個式子寫成對q裡面所sample出來的x取期望值,我們從q裡面sample x,然後再去計算f of x乘上p of x除以q of x再去取期望值,左邊這一項會等於右邊這一項。
link |
要算左邊這一項,你要從p這個distribution sample x,但是要算右邊這一項,你不是從p這個distribution去sample x,你是從q這個distribution去sample x。
link |
你從q這個distribution去sample x,sample出來以後再代入f of x乘上p of x,q of x,接下來你就可以計算左邊這一項你想要算的期望值。
link |
所以就算是我們不能夠從p裡面sample data,你想要計算這一項的期望值也是沒有問題的,你只要能夠從q裡面去sample data,可以帶這個式子,你就一樣可以計算從p這個distribution sample x代入f以後所算出來的期望值。
link |
這兩個式子唯一不同的地方是說,這邊是從x做sample,這邊是從q做sample,因為它是從q裡面做sample,所以sample出來的每一筆data,你需要乘上一個weight,修正這兩個distribution之間的差異,而這個weight就是p of x的值除以q of x的值。
link |
所以q of x其實它是任何distribution都可以,這邊唯一的限制就是你不能夠說q的機率是零的時候,p的機率不為零,不然這樣會沒有定義。
link |
假設q的機率是零的時候,p的機率也都是零的話,那這樣p除以q是有定義的,所以這個時候你就可以apply important sampling這個技巧,所以你就可以本來是從p做sample換成從q做sample。
link |
好,那這個跟我們剛才講的有什麼關係呢?剛才講的從on policy變成off policy有什麼關係呢?在繼續講之前,我們來看一下important sampling的issue,雖然理論上你可以把p換成任何的q,但是在實作上並沒有那麼容易,實作上p跟q還是不能夠差太多,如果差太多的話會有一些問題,什麼樣的問題呢?
link |
雖然我們知道說左邊這個式子等於右邊這個式子,那你要不要想想看,如果今天左邊這個是Applemax,它的期望值distribution是p,這邊是Applemax乘以p除以q的期望值,它的distribution是q,我們現在如果不是算期望值而是算variance的話,這兩個variance你覺得它會一樣嗎?
link |
給你三秒鐘的時間想一下,你覺得它會一樣的同學舉手一下,你覺得它不會一樣的同學舉手一下,好,多數同學都覺得它們不會一樣,沒錯,它們確實是不一樣的,兩個random variable,它的mean一樣,並不代表它的variance一樣,對不對?
link |
所以今天你可以實際算一下,Applemax這個random variable跟Applemax乘以p除以q這兩個random variable,它們的variance是不是一樣的,可以計算一下,那我們知道variance of x,就是這個公式,variance of x,是x平方的expansion減掉e of x的平方。
link |
好,你就帶一下這個式子,所以今天這一項的variance是這個樣子,這一項的variance就套一下這個公式,寫成這樣,然後今天這一項你其實是可以做一些整理的,這邊有一個s平方,這邊有一個p平方,這邊有一個q平方,這邊又有一個q,
link |
所以這邊有一個這個,這邊有一個f of x的平方,然後有一個p of x的平方,有一個q of x的平方,它在前面是對q取expectation,對q的distribution取expectation,
link |
所以如果你要算積分的話,你就會把這個q把它乘到前面去,算期望值,其實是這樣算的,然後這個q就可以消掉了,然後你可以把這個p拆成兩項,然後就會變成是對p取期望值。
link |
好,那這個是左邊這一項,那右邊這一項呢?那右邊這一項啊,這一項其實就寫在這邊,所以這一項其實就是這一項,然後你把它平方就變成這樣。
link |
所以如果你比較這一項跟這一項的話,它們差別在哪?它們差別在第一項是不同的,第一項這邊多成了p除以q,這邊沒有成p除以q,這邊多成了p除以q,所以如果p除以q差距很大的話,這個時候這一項的variance就會很大。
link |
所以雖然理論上它的expectation一樣,也就是說你只要對p這個distribution sample夠多次,q這個distribution sample夠多次,你得到的結果會是一樣的,但是假設你sample的次數不夠多,因為它們的variance差距是很大的,所以你就有可能得到非常大的差別。
link |
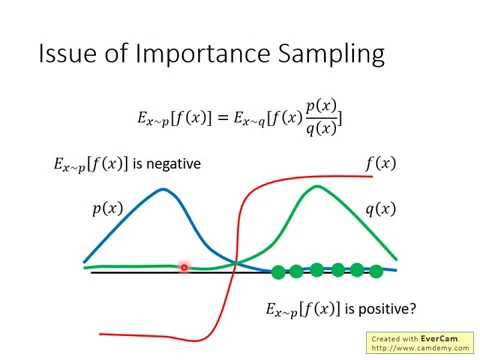
如果這個地方你聽得不是很懂的話,那沒有關係,這邊就是舉一個具體的例子告訴你說,當p跟q的差距很大的時候會發生什麼樣的問題。假設這個是p的distribution,這個是q的distribution,這個是f of x,這是f of x。
link |
如果我們要計算f of x的期望值,它的distribution是從p這個distribution做sample,顯然這一項是負的,因為f of x在這個區域,這個區域p of x的機率很高,所以要sample的話都會sample到這個地方,而f of x在這個區域是負的,所以理論上這一項算出來會是負的。
link |
接下來我們改成從q這邊做sample,因為q在右邊這邊的機率比較高,所以如果你sample的點不夠的話,那你可能都只sample到右側,如果你都只sample到右側的話,你會發現說,如果只sample到右側的話,算起來右邊這一項搞不好還應該是正的。
link |
對不對?因為你這邊sample到這些點,然後你去計算它們的f of x,p除以q,都是正的啊,所以你sample到這些點,它們都是正的,所以你取期望值以後,也都是正的。
link |
那為什麼會這樣?那是因為你sample的次數不夠多,因為假設你sample的次數很少,你只能sample到右邊這邊,但左邊這邊機率雖然很低,但也不是沒有可能被sample到,就假設你今天好不容易終於sample到左邊的點,
link |
因為左邊的點,p跟q是差很多的,這邊q很小,p很大,所以今天f of x好不容易sample到一個負的,這個負的就會變成一個非常巨大的位,就可以平衡掉剛才那邊一直sample到positive value的情況,
link |
最後eventually,你就可以算出說,這個期望值,這一項的期望值終究還是負的。但問題就是,這個前提是你要sample夠多次,這件事情才會發生,但有可能sample的次數不夠,那左勢跟右勢就有可能有很大的差距,所以這是important sampling的問題。
link |
那現在要做的事情就是把incentive這件事用在off policy的case,把on policy的training algorithm改成off policy的training algorithm,那怎麼改呢?
link |
之前我們是拿SEDA這個policy去跟環境做互動,sample出trajectory out,然後計算中括號裡面這一項,現在我們不根據SEDA,我們不用SEDA去跟環境做互動,
link |
我們假設有另外一個policy,另外一個policy它的參數是SEDAPoint,它就是另外一個actor,它的工作是它要去做demonstration,它要去示範給你看。
link |
這個SEDAPoint它的工作是要去示範給SEDA看,它去跟環境做互動,告訴SEDA說它跟環境做互動的時候會發生什麼事,然後藉此來訓練SEDA。
link |
我們要訓練的是SEDA這個model,SEDAPoint只是負責做demo的,負責跟環境做互動。
link |
所以我們現在的Cow它是從SEDAPoint sample出來的,不是從SEDA sample出來的,但我們本來要求的事實是這樣,但是我們實際上做的時候是拿SEDAPoint去跟環境做互動,
link |
所以sample出來的Cow是從SEDAPoint sample出來的,這兩個distribution不一樣,但沒有關係,我們之前說過說,假設你本來是從P做sample,
link |
但你發現你不能夠從P做sample,就現在我們說我們不拿SEDA去跟環境做互動,所以不能做跟P做sample,你永遠可以把P換成另外一個Q,然後在前面,在後面這邊,補上一個important的位。
link |
所以現在的狀況就是一樣,把SEDA換成SEDAPoint以後,要在中括號裏面補上一個important的位,
link |
這個important的位就是某一個trajectoryCow它用SEDA算出來的機率,除以這個trajectoryCow用SEDAPoint算出來的機率,那這一項是很重要的,因為今天你要認的XSEDA跟SEDAPoint是不太一樣的,
link |
所以SEDAPoint會遇到的狀況,會見到的情形,跟SEDA見到的情形不見得是一樣的,所以中間要做一個修正的項目。
link |
就像你在電影裏面,你會看到說,男女主角一遇到的時候,他們可能就一臉都潛到自己,在互相接吻,但是這個只透出來的日常生活中是不能學的,你只會吃巴掌而已,
link |
所以並不是所有的demonstration你都可以做到,你要看一下說這個demonstration是不是你可以做的,然後做一下修正這樣子。
link |
所以我們做了一下修正,因為我們現在data不是從SEDAPointsample出來的,是從SEDASample出來的,那我們從SEDAPoint換成SEDAPoint有什麼好處呢?
link |
我們剛才就講過說,因為現在跟環境互動的是SEDAPoint而不是SEDA,所以今天你sample出來的東西跟SEDA本身是沒有關係的,
link |
所以你就可以讓SEDAPoint去跟環境做幾次互動,sample一大堆data以後,SEDA可以update參數很多次,然後一直到SEDA可能change到一定的程度,update很多次以後,SEDAPoint再重新去做sample,這就是onPolicy換成offPolicy的妙用。
link |
好,那我們其實上週有講過說,實際上我們在做這個policy gradient的時候,我們並不是給一整個trajectory一套都一樣的分數,而是每一個state action的pair,我們會分開來計算。
link |
所以我們上週其實有講過說,我們實際上update我們的gradient的時候,我們的式子是長這個樣子的。我們用SEDA這個actor去sample出st跟at,sample出state跟action的pair,我們會計算state跟action的pair它的advantage,就是它有多好。
link |
那我們上週有講過說,這一項就是accumulated reward減掉bias,如果你忘記的話也沒有關係,反正這一項就是估測出來的,它要估測的是,現在在state ST採取action AT,它是好的還是不好的。
link |
好,那接下來後面會呈上這個log pset AT given ST,也就是說如果這一項是正的,就要增加機率,這一項是負的,就要減少機率。
link |
好,那我們現在就用了important sampling的技術,把on policy變成off policy,那我就把on policy變成off policy,就從SEDA變成SEDA prime。
link |
所以現在ST AT,它不是SEDA跟環境互動以後所sample到的data,它是SEDA prime,另外一個actor跟環境互動以後所sample到的data,但是拿來訓練我們要調整參數的model SEDA。
link |
但是我們有說過說,因為SEDA prime跟SEDA是不同的model,所以你要做一個修正的項,那這一項修正的項就是用important sampling的技術,把ST AT用SEDA sample出來的機率,除掉ST AT用SEDA prime sample出來的機率。
link |
那這邊其實有一件事情我們需要稍微注意一下,這邊A有一個上標SEDA,代表說這個是ST AT SEDA跟環境互動的時候所計算出來的A,但是實際上當我們今天從SEDA換到SEDA prime的時候,這一項其實你應該改成SEDA prime而不是SEDA,為什麼?
link |
這個A這一項是怎麼來的?這一項A這一項是想要估測說,現在在某一個state採取某一個action,接下來會得到的accumulated reward的值減掉baseline嘛,對不對,我們上週有講過。
link |
你怎麼估這項advantage?你就看在這個state ST採取這個action AT,接下來會得到的reward的總和,再減掉baseline,就是這一項嘛,對不對,這上週有講過。
link |
而之前是SEDA在跟環境做互動,所以你觀察到的是SEDA可以得到的reward,那現在不是SEDA跟環境做互動,現在是SEDA prime在跟環境做互動,所以你得到的這個advantage其實是根據SEDA prime所estimate出來的advantage,但我們現在先不要管那麼多,我們就假設這兩項可能是差不多的,我們就假設他們是差不多的。
link |
好,那接下來呢,這個STAT這一件事情,你可以拆解成ST的機率乘上AT given ST的機率,然後接下來這邊需要做一件事情是,我們假設當你的model是SEDA的時候,你看到ST的機率,跟你model是SEDA prime的時候,你看到ST的機率是差不多的,你把它刪掉,因為它們是一樣的,你可以把它刪掉。
link |
為什麼可以假設它是差不多的?當然你可以找一些理由,舉例來說,會看到什麼STAT往往跟你會採取什麼樣的action是沒什麼太大的關係的,比如說你玩不同的Atari的遊戲,那其實你看到的遊戲畫面都是差不多的,所以也許不同的SEDA對ST是沒有什麼影響的。
link |
但是有一個更直覺的理由就是,這一項到時候真的要你算,你會算嗎?你不覺得這一項其實你不太能算嗎?因為你想想看,這項要怎麼算?這項你還要說我一個參數SEDA,然後我拿SEDA去弄環境,或說我互動算ST出現的機率,這個你根本很難算,尤其是你如果input是image的話,通常ST根本就不會出現過第二次,所以根本沒辦法複製一下,所以乾脆就無視這個問題。
link |
但是Demon ST接下來產生AT這個機率,你是會算的,對不對?這個很好算,因為你有SEDA,手上有SEDA這個參數,它就是一個network,你就把ST帶進去,ST就是遊戲畫面,你把遊戲畫面帶進去,它就會告訴你說某一個state AT的機率是多少,對不對?
link |
我們說我們其實有一個policy的network,把ST帶進去,它會告訴我們說每一個AT的機率是多少。所以這一項,你只要知道SEDA的參數,知道SEDA的換算項,這個就可以算,但這一項其實不太好算,所以就說服自己說這一項其實不太會有影響,我們只管前面這個部分就好了。
link |
好,所以現在我們得到了一個新的objective function,這一項是gradient,其實我們可以從gradient去反推原來的objective function,怎麼從gradient去反推原來的objective function呢?
link |
這邊有一個公式你可以,我們就背一下吧,F of X的gradient等於F of X乘上log F of X乘上F of X,這一項是這個樣子的啦。
link |
前面有P SEDA,對不對?然後下面有一個P SEDA time,然後這邊有一個function A,然後這邊有一個gradient log P SEDA,好,然後我們看一下這邊,我們說這個F of X乘以gradient log的F of X,
link |
這個F of X就是P SEDA就當作是F of X,好,這個是F of X,這個是gradient log的F of X,這兩項合起來,就可以變成gradient F of X,所以變成gradient P SEDA這樣子。
link |
好,然後接下來我們要做的事情就是,這個是gradient的項目,我們要還原說原來沒有去gradient之前的樣子,那是怎麼樣子呢?其實就是把這個gradient拿掉,所以就變成下面這個式子,就變成下面這個式子。
link |
所以實際上,當我們apply importance sampling的時候,我們要去optimize的那一個objective function,長什麼樣子呢?我們要去optimize的那個objective function就長這樣,我們把它寫作這一SEDA time SEDA,為什麼要這麼麻煩寫這一SEDA time,這個括號裡面的SEDA代表是我們要去optimize的那個參數。
link |
SEDA time代表什麼?SEDA time是說我們拿SEDA time去做demonstration,就是現在真正在跟環境互動的是SEDA time,因為SEDA是跟環境互動,不是SEDA time在跟環境互動。
link |
然後呢,你用SEDA time去跟環境互動sample出st、at以後,你要去計算st跟at的advantage,然後你再去把它乘上pSEDA at given st,再除掉pSEDA time at given st,這兩項都是好算的,這一項你是可以從data裡面,你可以從這個sample的結果裡面去估測出來的,所以這一整項你是可以算的,那我們實際上在update參數的時候,就是按照上面這個式子update參數。
link |
所以我們現在做的事情就是我們可以把of policy換成of policy,但是我們會遇到的問題是,我們在前面講important sampling的時候,我們說important sampling有一個issue,這個issue是什麼呢?
link |
這個issue是,其實你的pSEDA跟pSEDA time不能差太多,差太多的話你就important sampling結果就會不好,如果pSEDA跟pSEDA time差太多的話,你的這兩個distribution差太多的話,important sampling的結果就會不好,所以怎麼避免它差太多呢?
link |
這個就是PPO在做的事情,所以PPO雖然如果你看它原始的paper,或者你看PPO的前身,TRPO原始的paper的話,它裡面寫了很多的數學式,但它實際上做的事情是怎樣呢?
link |
它實際上做的事情就是這樣,它說我們原來在of policy的方法裡面說我們要optimize的是這個objective function,但是我們又說因為這個objective function牽涉到important sampling,
link |
在做important sampling的時候,pSEDA不能跟SEDA time差太多,你做demonstration model跟那個真正的model不能夠差太多,差太多的話important sampling的結果就會不好,所以我們在training的時候多加一個constraint,這個constraint是什麼?
link |
這個constraint是SEDA跟SEDA time這兩個model他們output的action的KL divergence,就是簡單來說這一項的意思就是要衡量說SEDA跟SEDA time有多像,然後我們希望在training的過程中我們認出來的SEDA跟SEDA time越像越好,因為SEDA如果跟SEDA time不像的話,最後你做出來的結果就會不好。
link |
所以在PPO裡面有兩個式子,一方面就是optimize你要得到的,你本來要optimize的東西,但是再加一個constraint,這個constraint就好像那個regularization的time一樣,在我們在做machine learning的時候不是有L1跟L2的regularization嗎,這一項也很像regularization,這樣regularization做的事情就是希望最後認出來的SEDA不要跟SEDA time太不一樣。
link |
那PPO有一個全身叫做TRPO,TRPO寫的式子是這個樣子的,這一項跟前面這一項是一樣的,它唯一不一樣的地方是說這個constraint擺的位置不一樣,這邊是直接把那個constraint放到你要optimize的那個式子裡面,然後接下來你就可以用gradient ascent的方法去maximize這個式子。
link |
但是如果是在TRPO的話,它是把KL divergence當作constraint,它希望SEDA跟SEDA point的KL divergence小於一個delta,你知道你在做那種optimization,如果你是用gradient descent based optimization的時候,有constraint是很難處理的。
link |
所以你會發現PPO上次助教有講很多,我相信大家應該都沒有聽懂,那個是很難處理的,就是因為它是把這個KL divergence的constraint當作一個額外的constraint,沒有放objective裡面,所以它很難算。
link |
所以如果你不想搬石頭砸自己的腳的話,你就用PPO,不要用TRPO這樣。看文獻上的結果是PPO跟TRPO可能performance差不多,但是PPO在實作上比TRPO容易得多。
link |
那這邊要注意一下,就是這邊所謂的KL divergence到底指的是什麼?這邊我是直接把KL divergence當作一個function,它吃的input是SEDA跟SEDA point,但我的意思並不是說把SEDA當作一個distribution,把SEDA point當作一個distribution,算這兩個distribution之間的距離,我不是這個意思。
link |
今天這個所謂的SEDA跟SEDA point的距離,並不是參數上的距離,而是它們的behavior上的距離。我不知道大家可不可以了解這中間的差異。
link |
就是假設你現在有一個actor,它是SEDA,你有另外一個actor,它的參數是SEDA point,所謂的參數上的距離就是,你算這兩個參數,這兩組參數有多像,它們兩個都是mode裡面的位置跟byline,它們有多像,可是這不是我今天這邊所講的這個距離,我這邊所講的不是參數上的距離,我這邊所講的是它們的行為上的距離。
link |
就是你先帶進去一個state S,你先帶進去一個state S,然後今天它不是會output一個distribution嗎,它會output一個distribution,它會output一個,它會對這個action的space,output一個distribution,假設你有三個action,三個可能action就output三個值,三個可能action就output三個值。
link |
那我們今天所指的是behavior distance,也就是說給同樣的state的時候,它們output的這個action,這個action之間的差距,這兩個action的distribution,它們都是一個機率分佈,因為你這個output通常都,你這個output通常都output,所以這是一個機率分佈,這是一個機率分佈,所以就可以計算這兩個機率分佈之間的KL divergence。
link |
把不同的state,它們的output的這兩個distribution的KL divergence平均起來,才是我這邊所指的這兩個actor間的KL divergence,然後大家聽不聽得懂我的意思。
link |
你可能說,那怎麼不直接算這個theta和theta prime之間的距離,比如說甚至不用KL divergence算,有one跟有two node,也許更能夠,也可以保證theta跟theta prime很接近。在做reversal learning的時候,之所以我們考慮的不是參數上的距離,而是action上的距離,
link |
是因為很有可能對actor來說,參數的變化跟action的變化不是,不一定是完全一致的,就有時候你參數小小變了一下,它可能output的那個行為就差很多,或是參數變很多,但output的行為可能沒什麼差距,所以我們真正在意的是,這個actor它的行為上的差距,而不是它們參數上的差距。
link |
所以這裡要注意一下,在做PPO的時候,所謂的KL divergence並不是參數的距離,而是action的距離。
link |
那假設這個你沒有聽得很懂的話,我們等一下還有一個PPO2,這個是PPO1,它還是略微複雜的。
link |
我們來看一下這個PPO1的algorithm,它就這樣,它說initial一個policy的參數set0,然後在每一個iteration裡面,你要用參數setk,setk怎麼來的?
link |
那setk就是你在前一個training的iteration得到的actor的參數,你用setk去跟環境做互動,sample到一大堆的state action的片。
link |
然後根據setk互動的結果,你也要估測一下,st跟at,這個state跟action pair它的advantage。
link |
然後接下來,你就applyPPO的optimization function,但是跟optimization的formulation,但是跟原來的policy規則不一樣,原來的policy規則你只能update一次參數,update完以後,你就要重新sample data。
link |
現在不用,你拿setk去跟環境做互動,sample到這組data以後,你就努力去測setk,你可以讓setkupdate很多次,想辦法去maximize你的objective function,你讓setkupdate很多次。
link |
這邊setkupdate很多次沒有關係,因為我們已經有做imported sampling,所以這些experience,這些state action的pair是從setksample出來的沒有關係,setkupdate很多次,它跟setk變得不太一樣,也沒有關係,你還是可以照樣訓練setk。
link |
那其實就說完了,在PPO的pair裡面,這邊還有一個adaptive KL divergence,因為這邊會遇到一個問題就是,這個beta要設多少,它就跟那個regularization一樣,是一個regularization time前面也要乘一個weight,所以這個KL divergence前面也要乘一個weight,那beta要設多少呢?
link |
所以有一個動態調整beta的方法,那這個調整的方法其實也是蠻直觀的,在這個直觀的方法裡面,你先設一個KL divergence你可以接受的最大值,然後假設你發現說,你optimize完這個式子以後,KL divergence的項太大,那就代表說後面這個panelize的term沒有發揮作用,那就把beta調大。
link |
那另外你定一個KL divergence的最小值,那你發現說optimize完上面這個式子以後,你得到KL divergence比最小值還要小,那代表說後面這一項它的效果太強了,那你怕它都只弄後面這一項,那seda跟sedaK就一樣,這不是你要的,所以你這個時候你就要減少beta,所以這個beta是可以動態調整的,這個叫做adaptive的KL penalty。
link |
所以實際上你在算這個KL的時候,也是有點麻煩的,怎麼有點麻煩呢?因為這個KL,理論上你應該sample一大堆不同的set,然後每一個set都丟進去,然後再算不同的set一下,出現KL的感覺,再把它複製起來嘛,對不對?
link |
那這個不同的set哪裏來呢?從你的sample data來,因為在這邊會用sedaK去做sample嘛,所以它也sample了很多不同的set,那就把這些不同的set統統帶進去這個KL divergence去算它的不同的set,output的action之間的KL divergence,那這是你實際上的要做法。
link |
假設大家有問題要問嗎?如果你覺得這個很複雜,為什麼還要算KL divergence很複雜?有一個PPO2,PPO2它的式子我們就寫在這邊,它要去maximize這個objective function寫成這樣,它的式子它裏面就沒有什麼KL了。
link |
這個式子看起來有點複雜,但是我們就實際implement,就很簡單,我們來實際看一下說這個式子到底是什麼意思,這個式子很複雜哦,這邊是summation over state action的pair,那沒有問題,這個是minimize,就是說這邊有個大括號,這邊有個大括號,這邊有個括號,這邊有個括號,這個括號裏面有兩項,這是第一項,這個是第二項。
link |
然後nin這個operator它要做的事情是第一項跟第二項裏面選比較小的那個,然後第一項比較單純,第二項也比較複雜,第二項前面有一個pip這個function,pip這個function是什麼意思呢?
link |
pip這個function的意思是說在括號裏面有三項,如果第一項小於第二項的話,那就output1-f0,第一項如果大於第三項的話,就output1-f0。
link |
那f0是一個type of parameter,你要tune的,比如說你就設0.1啊,設0.2啊,也就是說這個值假如這邊設0.2的話,就是說這個值如果算出來小於0.8,那就當作0.8,這個值如果算出來大於1.2,那就當作是1.2。
link |
好,那這個式子到底是什麼意思呢?我們先來解析一下,我們來看一下這個第二項這個就好,我們先來看第二項這個算出來到底是什麼樣的東西。第二項這一項算出來的意思是這個樣子。
link |
假設這個橫軸是pθ除以pθk,橫軸是第一項,pθ除以pθk,縱軸是這個pip這個function它實際上的輸出,那我們剛才講過說,如果pθ除以pθk大於1-f0,它輸出就是1-f0,如果小於1-f0,輸出就是1-f0,如果介於1-f0之間就是輸入等於輸出。
link |
所以,pθ除以pθk跟pip function的輸出的關係是這樣的一個關係。
link |
好,那接下來呢,我們就加入前面這一項,來看看前面這一項到底在做什麼?前面這一項呢,其實就是綠色的這一條線,對不對,前面這一項就是綠色的這一條線,pθ除以pθk就是綠色的這一條線。
link |
但是,這兩項裡面的第一項跟第二項,也就是綠色的線跟藍色的線中間,我們要取一個最小的,我們要取一個最小的。
link |
假設今天前面乘上的這個term a,它是大於0的話,取最小的結果就是紅色的這一條線。反之,如果a小於0的話,那取最小的以後,就得到紅色的這一條線。
link |
那這個結果其實非常的直觀,所以這個式子雖然看起來有點複雜,但是implement起來是蠻簡單的,然後想法也非常的直觀,因為今天這個式子想要做的事情就是希望pθ跟pθk,也就是你拿來做demonstration的model,對,實際上認的model,最後在optimize以後不要差距太大。
link |
那這個式子是怎麼讓它做到不要差距太大的呢?你要怎麼讓它做到不要差距太大的呢?再複習一下這個橫軸的意思,就是pθ除以pθk,這個橫軸是pθ除以pθk。
link |
如果今天a大於0,也就是某一個state跟action的pair是好的,那我們想要做的事情當然是希望增加這個state跟action的pair的機率,也就是說我們想要讓pθ越大越好。
link |
但是我們覺得pθ越大越好沒有問題,但是它跟這個θk的比值不可以超過1加ε,如果超過1加ε的話就沒有benefit了,就是我們要,我們這次紅色的線是我們的objective function,我們希望我們的objective越大越好。
link |
當pθ比pθk的比值,我們希望pθ越大越好,但是pθ比pθk的比值只要大過1加ε就沒有benefit了,所以今天在train的時候,pθ只會被train到比pθk它們相除大1加ε,它就會停止。
link |
那假設今天不幸的是pθ比pθk還要小,因為我們的目標是要讓pθ越大越好,因為假設這個advantage是正的,我們當然希望pθ越大越好,假設這個action是好的,我們當然希望這個action被採取的機率越大越好。
link |
所以假設是pθ還比pθk小,那就盡量把它挪大,但是只要達到1加ε就好。那負的時候也是一樣,如果今天某一個state action pair是不好的,我們當然希望pθ把它減小,假設今天pθ比pθk還要大,那你就要趕快把它盡量壓小。
link |
那壓到什麼樣就停止呢?壓到pθ除以pθk是1減ε的時候就停了,就算了,就不要再壓得更小,那這樣的好處就是你不會讓pθ跟pθk差距太大,那要implement這個東西其實對你來說可能不是一個太困難的事情。
link |
最後這頁投影片只是想要秀一下在文獻上PPO跟其他方法的比較。今天這邊有秀的有actor critic的方法,這邊有AQC,AQC加transmission,它們都是actor critic base的方法,那actor critic我們之後會講到。
link |
然後還有這邊有個PPO,PPO是紫色的線的方法,然後還有TRPO,PPO就是紫色的線,那你會發現說在多數的task裡面,這張每張圖就是某一個RL的任務,你會發現說在多數的case裡面,PPO都是不錯的,不是最好的,就是第二好的。