back to index
DRL Lecture 3: Q-learning (Basic Idea)
link |
沒有的話,我們就來講一下Q-Learning,這個Q-Learning是什麼呢?我們等一下會簡單的介紹一下Q-Learning,其實在Machine Learning那門課裡面其實也簡單的介紹過Q-Learning了,不過今天就算是在很快的複習一下,那接下來會講一些Q-Learning的Tips,可能是之前沒有講過的,然後會講說Q-Learning怎麼樣用在Continuous的Action上。
link |
我們就先從Q-Learning的簡介開始說起。我們說Q-Learning這種方法,它是Value-Based的方法,在Value-Based的方法裡面,我們認的並不是Policy,我們並不是直接認Policy,我們要認的是一個Critic,Critic並不直接採取行為,他想要做的事情是評價現在的行為有多好或者是多不好。
link |
Critic並不直接採取行為,他是說假設我們已經有一個Actor Pi,那Critic的工作就是來評價這個Actor Pi他做的有多好或者是多不好。
link |
舉例來說,有一種Actor叫做State Value的Function,這個State Value的Function意思就是說,假設現在的Actor叫做Pi,拿這個Pi跟環境去做互動,拿Pi跟環境去做互動的時候,現在假設Pi這個Actor他看到了某一個State S,那如果在玩Atari遊戲的話,State S等於是某一個畫面,看到某一個畫面,某一個State S的時候,接下來一直玩到遊戲結束,累積的Reward的期望值有多大。
link |
所以VPi它是一個Function,這個Function它是吃一個State當作Input,然後它會offer一個Scalar,這個Scalar代表說,現在Pi這個Actor他看到State S的時候,接下來預期到遊戲結束的時候,他可以得到多大的Value。
link |
我這邊就舉一個例子,假設你是玩Space Invader的話,也許這個State S這個遊戲畫面,你的VPi的S會很大,因為接下來還有很多的怪可以殺,所以你會得到很大的分數,在遊戲結束的時候你仍然有很多的分數可以吃。
link |
那在這個Case,也許你得到的VPi就很小,因為一方面剩下的怪也不多了,再來就是現在因為那個防護罩,這個紅色的東西防護罩已經消失了,所以可能很快就會死掉,所以接下來得到的預期的Reward就不會太大。
link |
那這邊需要強調的一個點是說,當你在講這個Critic的時候,你一定要注意Critic都是綁一個Actor的,就Critic他並沒有辦法憑空去evaluate一個State的好壞,而是他所evaluate的東西是,在given某一個State的時候,假設我接下來互動的Actor是Pi,那我會得到多少Reward。
link |
因為就算是給同樣的State,你接下來的Pi不一樣,你得到的Reward也是不一樣的。
link |
舉例來說,在這個Case,雖然假設是一個正常的Pi,他可以殺很多怪,但假設他是一個很弱的Pi,他就站在原地不動,然後馬上就被射死了,那你得到的V還是很小。
link |
所以今天這個Critic的Output值有多大,其實是取決於兩件事,一個是State,另外一個其實是Actor,所以今天你的Critic其實都綁一個Actor,他是在衡量某一個Actor的好壞,而不是general的衡量一個State的好壞。
link |
這邊有強調一下,你這個Critic的Output跟Actor是有關的。這邊就是舉一個例子,這個例子是阿光跟佐維的互動,這件事發生在什麼時候呢?
link |
這件事發生在下完弱獅子戰的時候,佐維跟阿光說,這個時候不要下小馬不飛,而是要下大馬不飛。
link |
這邊有一個註釋告訴你說小馬不飛是什麼,我們就不要管它。阿光說,他覺得為什麼一定要下大馬不飛,下小馬不飛也不錯。
link |
佐維說,因為之前你沒有很強,所以下小馬不飛是對的,但是現在因為你已經變得比較強了,所以應該下大馬不飛,才能夠有比較好的發展。
link |
所以今天,假設佐維是一個Critic的話,他的Evaluation是dependent on他的Actor,也就是阿光的能力。如果是以前的阿光,因為他比較弱,所以下大馬不飛接下來可能會犯錯。
link |
所以以前的阿光是Actor,假設你的State是下大馬不飛的話,你得到的Value是小的。假設現在Evaluation的Actor其實是一個變強的阿光的話,那下大馬不飛反而是好的。
link |
這個例子想要強調的就是,你的State Value其實是dependent on你的Actor,當你的Actor變的時候,你的State Value Function的Output其實也是會跟著改變的。
link |
好,那再來的問題就是,怎麼衡量這個State Value的Function呢?怎麼衡量這個Pi of S呢?有兩種不同的做法。
link |
那等一下會講說,像這種Critic,它是怎麼演變成可以真的拿來採取Action,那這個是等一下要講的,我們現在先問的是,怎麼Estimate這些Critic?
link |
好,那怎麼Estimate這個Pi of S呢?有兩個方向,一個是用這個Multicolumn,MC-based的方法。
link |
如果是MC-based的方法,它非常的直覺,它怎麼直覺呢?它就是說,你就讓Actor去跟環境做互動,你要量Actor好不好,你就讓Actor去跟環境互動給Critic看。
link |
然後接下來Critic就統計說,這個Actor如果看到State S,A,他接下來Accumulated Reward會有多大?如果他看到State S,B,他接下來Accumulated Reward會有多大?
link |
但是因為實際上,你當然不可能把所有的State統統都掃過,不要忘了如果你是玩Atari遊戲的話,你的State可是沒有辦法把所有的State統統掃過。
link |
所以實際上,我們的這個Pi of S,它是一個Network,對一個Network來說,就算是Input的State是從來沒有看過的,它也可以想辦法估測一個Value的值。
link |
但是怎麼訓練這個Network呢?因為我們現在已經知道說,如果在State S,A,接下來Accumulated Reward就是GA,也就是說,今天對這個Value Function來說,如果Input是State S,A,正確的Output應該是GA,如果Input是State S,B,正確的Output應該是Value GB。
link |
所以在Training的時候,其實它就是一個Regression的Problem,Regression的Problem大家應該都知道,這個胡亂call一下就有,它是個Regression的Problem,你的Network的Output就是一個Value,你希望在Input S,A的時候,Output的Value跟GA越近越好,Input S,B的時候,Output的Value跟GB越近越好。
link |
接下來連我串下去,就結束了。這是第一個方法,這是NC-Base的方法,還有第二個方法是Temporal Difference的方法,這個是TD-Base的方法。那TD-Base的方法是什麼意思呢?
link |
在剛才那個NC-Base的方法,每次我們都要算Accumulated Reward,也就是從某一個State S,A一直玩遊戲,玩到遊戲結束的時候,你會得到的所有Reward的總和,我在前一個投影片裡面把它寫成GA或GB。
link |
所以今天你要Apply NC-Base Approach,你必須至少把這個遊戲玩到結束,你才能夠估測NC-Base Approach,但是有些遊戲非常的長,你要玩到遊戲結束才能夠Update Network,你可能根本收集不到太多的資料,它花的時間太長了。
link |
所以怎麼辦?有另外一種TD-Base的方法,TD-Base的方法不需要把遊戲玩到底,只要在遊戲的某一個情況,某一個State S,T的時候,採取Action A,T,得到Reward R,T,跳到State S,T加1,就可以Apply TD的方法。
link |
怎麼Apply TD的方法呢?這邊是基於以下這個式子,以下這個式子是說,我們知道說在State S,T採取某一個Action,就是說我們現在有某一個Policy Pi,假設我們現在用的是某一個Policy Pi在State S,T以後,在State S,T它會採取Action A,T,給我們Reward R,T,接下來進入State S,T加1。
link |
這就告訴我們說,State S,T加1的Value跟State S,T的Value它們中間差了一下R,T,因為你把State S,T加1得到的Value加上這邊得到的Reward R,T,就會等於State S,T得到的Value,State S,T得到的Value就是R,T的Value加上State S,T加1的Value,State S,T的Value就是R,T加上State S,T加1的Value。
link |
有了這個式子以後,你在Training的時候,你要做的事情並不是真的直接去估測V,而是希望你得到的結果,你得到的這個V可以滿足這個式子。
link |
也就是說你Training的時候會是這樣Training的,你把St丟到Network裡面,我看看我這邊有沒有寫錯,沒有寫錯,你把St丟到Network裡面會得到V of St,你把St加1丟到你的Value Network裡面會得到V of St加1。
link |
這個式子告訴我們,V of St減V of St加1,它應該值是R,T,V of St減V of St加1,它得到的值應該是R,T,然後按照這一樣子的Loss,希望它們兩個相減,跟R,T越接近越好的Loss,Train下去,對V的參數,你就可以把V這個function認出來。
link |
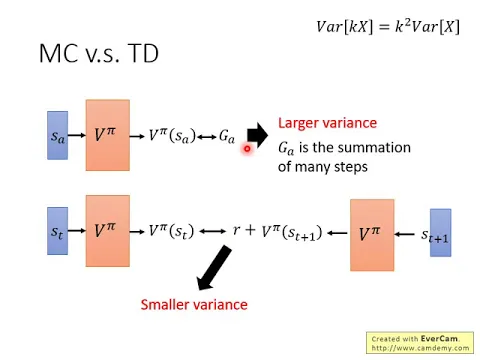
這邊是比較一下NC跟TD之間的差別,那NC跟TD它們有什麼樣的差別呢?
link |
這個NC它最大的問題就是它的Variance很大,因為今天我們在玩遊戲的時候,它本身是有隨機性的,所以GA本身你可以想成它其實是一個Random的Variable,
link |
因為你每次同樣走到SA的時候,最後你得到的GA其實是不一樣的,你最後玩到遊戲結束的時候,因為遊戲本身是有隨機性的,你的玩遊戲的Model本身搞不好也有隨機性,所以你每次得到的GA是不一樣的。
link |
那每一次得到GA的差別其實會很大,為什麼它會很大呢?因為GA其實是很多個不同的Step的Reward核,假設你每個Step都會得到一個Reward,GA是從SA開始一直玩到遊戲結束,每一個Time Step的Reward核。
link |
舉例來說,我在右上角就列一個式子是說,假設本來只有X,它的Variance是VAR of X,但是你把某一個Variable乘上K倍的時候,它的Variance就會變成原來的K平方。
link |
所以現在這個GA的Variance相較於某一個Step的Reward,它會是比較大的,所以GA的Reward,不是Reward說錯了,GA的Variance是比較大的。
link |
GA的Variance相較於某一個Step你會得到的Reward的Variance,它是比較大的。反正我們來看一下說如果用TD的話呢,用TD的話你是要去minimize這樣子的一個式子,在這中間會有隨機性的是R,因為在ST就算你採取同一個Action,你得到的Reward也不見得是一樣,所以R其實也是一個Random Variable。
link |
你看這個Random Variable,它的Variance會比GA還要小,因為GA是很多R合起來,這邊只是某一個R而已,所以GA的Variance會比較大,R的Variance會比較小。
link |
但是這邊你會遇到的一個問題是,你這個V不見得估得準,假設你的這個V估得是不準的,那你apply這個式子,認出來的結果其實也會是不準的。
link |
所以今天NC跟TD,它們是各有優劣,等一下其實會講一個NC跟TD綜合的版本,今天其實TD的方法是比較常見的,NC的方法其實是比較少用的。
link |
這個圖是想要講一下TD跟NC的差異,這個圖想要說的是什麼呢?這個圖想要說的是說,假設現在我們有某一個critic,他去觀察某一個policy pie跟環境互動八個episode的結果。
link |
有一個actor pie他去跟環境互動了八次,得到了八次玩遊戲的結果是這個樣子。接下來,我們要這個critic去估測state的value。
link |
如果我們看SB這個state,它的value是多少?SB這個state在八場遊戲裡面都有經歷過,然後在這八場遊戲裡面,其中有六場得到reward1,再有兩場得到reward0。所以如果你是要算期望值的話,看到state SB以後得到的reward,一直到遊戲結束的時候得到的accumulated reward期望值是四分之三,這個非常直覺。
link |
但是不直覺的地方是說,SA的期望的reward到底應該是多少呢?這邊其實有兩個可能的答案,一個是0,一個是四分之三。為什麼有兩個可能的答案呢?這取決於你用NC還是TD。
link |
你用NC跟用TD,你算出來的結果是不一樣的。假如你用NC的話,你用NC的話,你會發現說這個SA就出現一次嘛,它就出現一次。看到SA這個state,接下來的accumulated reward是多少?就是0啊,就是0啊,所以今天SA它的expected reward就是0。
link |
但是如果你今天去看TD的話,TD在計算的時候,它是要update下面這個式子。下面這個式子想要說的事情是,因為我們在state SA得到rewardR等於0以後,跳到state SB,所以state SB的reward會等於state SB的reward。
link |
加上在state SA,它跳到state SB的時候,可能得到的rewardR。而這個可能得到的rewardR呢,它的值是多少?它的值是0。而SB的expected reward是多少呢?它的reward是四分之三。那SA呢,它的reward應該是四分之三。
link |
所以有趣的地方是,用NC跟TD你估出來的結果,其實很有可能是不一樣的。就算今天你的credit observe到一樣的training data,它最後估出來的結果也不見得會是一樣的。
link |
那為什麼會是這樣呢?那你可能問說,哪一個比較對呢?其實就都對,對不對?因為今天在SA這邊,今天在第一個trajectory,SA它得到reward0以後,再跳到SB也得到reward0。
link |
這邊有兩個可能,一個可能是SA它就是一個待賽的state,所以只要有看到SA以後,SB就會拿不到reward,有可能SA其實影響了SB。
link |
如果是用蒙地卡羅的算法的話,他就會考慮這件事,他會把SA影響SB這件事考慮進去,所以看到SA以後,接下來SB就得不到reward,所以看到SA以後期望的reward是0。
link |
但是今天看到SA以後SB的reward是0這件事有可能只是一個巧合,就並不是SA所造成,並不是因為SA它是一個待賽的reward,而是因為說SB有時候就是會得到reward0嘛,這只是單純運氣的問題。
link |
其實平常SB它會得到reward的期望值是四分之三,跟SA是完全沒有關係的。
link |
所以SA假設之後會跳到SB,那其實得到reward按照TD來算應該是四分之三,所以不同的方法它有著,它考慮了不同的假設,最後你其實是會得到不同的運算的結果的。
link |
那接下來我們要講的是另外一種critic,這種critic叫做Q-function,它又叫做state action的value function,那我們剛才看到的那個state function它的input就是一個state,它是根據state去計算出,看到這個state以後的expected cumulative reward是多少。
link |
那這個state action的value function,它input不是state,它是一個state跟action的pair,它的意思是說在某一個state採取某一個action,接下來假設我們都使用actor pi,得到的accumulated reward它的期望值有多大。
link |
那在講這個Q-function的時候,有一個會需要非常注意的問題是,今天這個actor pi在看到state s的時候,它採取的action不一定是a。
link |
大家了解我的意思嗎?Q-function的假設是說,假設在state s強制採取action a,不管你現在考慮的這個actor pi它會不會採取action a,這個不重要,只要在state s強制採取action a,接下來都用actor pi繼續玩下去。
link |
只有在state s我們才強制一定要採取action a,接下來就進入自動模式,讓actor pi繼續玩下去,得到的expected reward才是Q的sa。那假設你讓pi看到這個state的時候,它不見得要去採取a,我們只是強制手動讓它一定要去採取action a。
link |
好,那Q-function有兩種寫法,一種寫法是你input就是state跟action,那output就是一個scalar,就跟那個value function是一樣的。但還有另外一種寫法,其實也許是比較常見的寫法,是這樣,你input一個state s,接下來你會output好幾個value,假設你的actor是discrete的,
link |
假設你的action是discrete的,你的action就只有三個可能,往左、往右或者是開火。那今天你的這個Q-functionoutput的三個value就分別代表,假設a是向左的時候的Q-value,a是向右的時候的Q-value,還有a是開火的時候的Q-value。
link |
所以你要注意的事情是,像這樣子的function,只有discrete的action才能夠使用,如果你的action是無法窮舉的,那你只能夠用左邊這個式子,不能夠用右邊這個式子。
link |
這個是文件上的結果,在作業4-1裡面,其實作業4-2不是要玩這個,作業4-2是玩打磚塊,但如果是作業4-1的Pong的這個遊戲,你去estimateQ-function的話,那你看到結果可能會像是這個樣子,這個樣子,這是什麼意思呢?
link |
它說,假設現在在這個state,上面這個畫面就是state,在這個state,我們有三個action,三個action就是原地不動、向上還有向下。
link |
那假設是在這個state,不管是採取這個action、這個action還是這個action,最後到遊戲結束的時候得到的expected reward其實都差不了多少。
link |
因為球在這個地方,就算是你向下,接下來你其實應該還來得及救,所以今天不管是採取哪一個action就差不了太多。
link |
但假設現在這個球,這個乒乓球它已經反彈到很接近邊緣的地方,這個時候你採取向上,你才能夠得到positive reward,才接得到球。
link |
如果是站在原地不動或向下的話,接下來你都會miss掉這個球,你得到的reward就會是負的,這個case也是一樣,球很近了,所以就要向上,接下來你的球被反彈回去,這個時候採取哪一個action就都沒有差了。
link |
這個是state action value的一個例子,是在文件上截下來的,是那個,大家都應該知道說deep reinforcement learning最早的受到大家重視注意的一篇paper就是這個DeepMind發表在Natural上的那個paper,
link |
就是用DQN可以玩Atari遊戲,可以痛電人類,那個是那篇paper上的一個圖就是了。
link |
那今天要講的是說,雖然表面上我們認一個Q-function,它只能夠拿來評估某一個action,好壞,但是實際上只要有了這個Q-function,我們就可以做reinforcement learning,
link |
其實有這個Q-function,我們就可以決定要採取哪一個action,它的大原則是這樣,假設你有一個初始的actor,也許一開始很爛,隨機的也沒有關係,初始的actor叫做pi,
link |
那這個pi跟環境互動會collect data,接下來你認一個pi這個actor的Q-value,你去衡量一下pi這個actor,它在某一個state強制採取某一個action,接下來用pi這個policy會得到expected reward,那你可以用PD也可以用MC都是可以的。
link |
你認出一個Q-function以後,等一下我們接下來會細講的一個神奇的地方就是,只要認得出某一個policypi的Q-function,就保證你可以找到一個新的policy,這個policy叫做pi-pi,這個policypi-pi它一定會比原來的policypi還要好,那等一下會定義說什麼叫做好。
link |
所以這邊神奇的地方是,假設你只要有一個Q-function,你有某一個policypi,你根據那個policypi,認出那個policypi的Q-function,接下來就保證你可以找到一個新的policy叫做pi-pi,它一定會比pi還要好,你今天找到一個新的pi-pi,它一定會比pi還要好以後,你把原來的pi用pi-pi取代掉,再去找它的Q,然後再去,得到新的Q以後,再去找一個更好的policy。
link |
然後這個循環一直下去,你的policy就會越來越好。
link |
那今天這邊呢,我們講完這一頁我們就下課,這一頁要講的是什麼呢?這一頁就是要講說我們剛才講的到底是什麼,首先第一個要定義的是什麼叫做比較好,我們說pi-pi一定會比pi還要好,什麼叫做好呢?
link |
這邊所謂的好的意思是說,對所有可能的state S而言,對同一個state S而言,pi的value function一定會小於pi-pi的value function,也就是說我們走到同一個state S的時候,如果拿pi繼續跟環境互動下去,我們得到的reward一定會小於用pi-pi跟環境互動下去得到的reward。
link |
所以今天不管在哪一個state,你用pi-pi去做interaction,你得到的expected reward一定會比較大,所以pi-pi是比pi還要好的一個policy。
link |
好,那有了這個Q以後,怎麼找這個pi-pi呢?這邊的構想非常簡單,事實上這個pi-pi是什麼?這個pi-pi就是如果你根據以下的這個式子去決定你的action,把根據以下式子去決定的action的這個步驟叫做pi-pi的話,那這個pi-pi它一定會比pi還要好,而在下一頁會有證明。
link |
好,那這個是什麼意思呢?這個意思就是說,假設你已經認出pi的Q function,你已經認出pi的Q function,今天在某一個state S,你把所有可能的action A都一一帶入這個Q function,看看說哪一個A可以讓Q function的value最大,那這一個action就是pi-pi會採取的action。
link |
那這邊要注意一下,今天在given這個state S,我們剛才有講過Q function的定義,given這個state S,你的pi-pi並不一定會採取action A,今天是given某一個state S,強制採取action A,用pi去互動下去,得到的expected reward才是這個Q function的定義。
link |
所以在state S裡面不一定會採取action A,我們強調在state S裡面不一定會採取action A,所以今天呢,今天假設我們用這個pi-pi,它在state S採取action A跟pi所會採取action是不一定會一樣的,然後pi-pi所採取action會讓它得到比較大的reward。
link |
所以實際上啊,根本就沒有一個所謂的policy叫做pi-pi,這個pi-pi其實就是用Q function推出來的,所以並沒有另外一個network決定pi-pi怎麼interaction,我們只要Q就好,有Q就可以走出pi-pi。
link |
那這邊有另外一個問題是我們等一下會解決的,就是在這邊要解一個argmaxofvolume,所以A如果是continuous就會有問題,如果是discrete,A只有三個選項一個一個帶進去,看誰的Q最大沒有問題,但如果是continuous,只要解argmaxofvolume,你就會有問題了,但這個是之後才會解決的。
link |
好,那接下來啊,下一頁投影片想要跟大家講的是說,為什麼用這個Q set啊,這個Q function所決定出來的pi-pi一定會比pi還要好,所以下一頁是要證這件事,那下一頁的證明,假設你覺得你沒有辦法follow的話,其實就算了這樣,你就只要記得這個結果就可以了。
link |
好,下一頁投影片是要證的就是這樣,假設現在呢,我們有一個part叫pi-pi,它是由Q-pi決定的,我們要證說,對所有的state s而言,dpi-pi一定會比dpi還要大,這件事怎麼證呢?
link |
事實是這樣,我們先把dpi寫出來,那dpi這個式子啊,會等於Qpi log s pi log s,假設你在state s這個地方,你follow pi這個actor,它會採取的action也就是pi log s,那你算出來的Qpi會等於dpi。
link |
之所以Qpi之前in general而言Qpi不見得等於dpi,是因為這一個action不見得是pi log s,那這個action如果是pi log s的話,Qpi是等於dpi的。
link |
好,然後呢,今天的Qpi log s pi log s一定會小於等於Qpi log s a,a取最大的那個,對不對,因為這邊是某一個action,這邊是所有action裡面可以讓Q最大的那個action,所以今天這一項一定會比它大。
link |
那我們知道說這一項是什麼,這一項就是這個Qpi log s a,然後a是什麼,a就是pi log s,因為今天pi log s它output的a就是可以讓Qpi log s最大的那個,所以今天這個式子可以寫成Qpi log s pi log s。
link |
好,那這邊我們就知道說Vpi log s它一定小於等於Qpi log s pi pi log s,也就是說你在某一個state,如果你按照policy pi一直做下去,你得到的reward一定會小於等於你在現在這個state s,你故意不按照pi所給你指示的方向,你故意按照pi pi的方向走一步。
link |
但只有第一步是按照pi pi的方向走,只有在state s這個地方你才按照pi pi的方向走,pi pi的指示走,但接下來你都會按照pi的指示走,雖然只有一步之差,但是我們可以按照上面這個式子知道說這個時候你得到的reward,只有一步之差,你得到的reward一定會比完全follow pi得到的reward還要大。
link |
那接下來eventually你想要證的東西就是,這個Qpi of s pi pi log s會小於等於Vpi pi log s,也就是說只有一步之差,你會得到比較大的reward,那假設每步都是不一樣的,每步通通是follow pi pi而不是pi的話,那你得到的reward一定會更大,就這樣。
link |
那直覺上想起來是這樣子的,那如果你要用數學式把它寫出來的話,略嫌麻煩,但是也沒有很難,只是比較繁瑣而已,怎麼寫呢?你可以這樣寫,我們現在在這個Qpi這個式子,怎麼寫啊?
link |
Qpi這個式子它的意思就是說,我們在state st,我們會採取action at,接下來我們會得到reward rt加1,然後跳到state st加1。
link |
這邊有一個地方啊,我覺得我寫得不太好,我覺得這邊應該要寫成rt,跟我之前的那個notation感覺比較像字啊,反正這邊寫成了rt加1,因為我們這個其實都是可以的,在文獻上有時候有人會說在state st採取action at得到reward叫rt加1,有人會寫成rt,但意思其實都是一樣的。
link |
好,在state st採取按照Pipeline採取某一個action at得到reward rt加1,然後接下來跳到state st加1,然後我們這邊是state st加1根據Pi這個actor所估出來的value,上面這個式子等於下面這個式子。
link |
這邊要取一個期望值,因為在同樣的state採取同樣的action,你得到的reward還有會跳到的state不見得是一樣,所以這邊需要取一個期望值。這一項啊,會小於等於下面這個式子,為什麼這一項要等於小於等於下面這個式子呢?
link |
因為我們上面已經講過說vPi一定小於等於qPi of sPiPi,也就是這邊vPi的st加1一定會小於等於qPi的st加1PiPi的st加1,也就是說現在你一直followPi跟某一步followPiPi接下來都followPi比起來,某一步followPiPi得到的reward是比較大的。
link |
那這一個式子啊,就可以寫成下面這個式子,因為qPi這個東西可以寫成rt加2加上st加2的value,然後接下來呢,你再把這個式子,你再把vPi小於等於qPi sPiPi of s這件事情再帶進去,然後一直算算算算到底,算到episode結束。
link |
那你就知道說vPi of s會小於等於vPiPi,反正這邊假設你沒有辦法follow的話,總之想要告訴你的事情是說,你可以estimate某一個policy的q function,接下來你就一定可以找得到另外一個policy,叫做PiPi,PiPi比原來的policy還要更好。
link |
好,那我們講一下那個target,我們講一下接下來呢,在q learning裡面typical,你一定會用到的tip,還有幾個tip,第一個是,你會用一個東西叫做target network,什麼意思呢,我們在learn q function的時候,你也會用到td的概念,那怎麼用td的概念呢?
link |
就是說你現在收集到一個data是說在state st,你採取action at以後,你得到reward rt,然後跳到state st加1,然後呢,今天根據這個q function,你會知道說qPi of st at跟qPi of st加1,Pi of st加1,他們中間差了一下,就是rt。
link |
所以你在learn的時候,你會說我們有這個q function,input st at得到的value,跟input st加1,Pi of st加1得到的value中間,我們希望它差了一個rt,這跟剛才講的td的概念是一樣。
link |
但是實際上在learn的時候,你會發現說,in general而言,這樣的一個function並不好learn,為什麼?因為假設你說這是一個regression的problem,這是你內窩的output,這是你的target,你會發現你的target是會動的,但是你要implement這樣的training其實也沒有問題,對不對?
link |
就是你在做backpropagation的時候,這個model它的參數會被update,這個model的參數也會被update,但它們同一個model,所以你會把兩個update的結果加在一起,它們是同一個model,所以兩個update的結果會加在一起。
link |
但是實際上在做的時候,你的training會變得不太穩定,因為假設你把這個當作你的model的output,這個當作target的話,你會變成說你要去fit一個target,它是一直在變的,這種一直在變target的training其實是不太好training的。
link |
所以實際上怎麼做呢?實際上你會把其中一個Q,通常是你就選擇下面這個Q把它固定住,也就是在training的時候,你並不update這個Q的參數,你只update左邊這個Q的參數,而右邊這個Q的參數它會被固定住,那我們叫它target level,它負責產生target,所以叫做target level。
link |
因為target level是固定的,所以你現在得到的target,也就是RT加上QπlobST加1πlobST加1的值也會是固定的,那我們只調左邊這個network的參數,假設因為target level是固定的,我們只調左邊的network的參數,它就變成是一個regression的problem。
link |
我們希望我們的model的output,它的值跟你的目標越接近越好,你會minimize它的mean square error,你會minimize它們的L2的distance,那這個東西就是regression。
link |
然後在實作上,你會把這個Qupdate好幾次以後,再去把這個target level用update過的Q去把它替換掉,在training的時候先update它好幾次,然後再把它替換掉,但它們兩個不要一起動,它們兩個一起動的話,你的結果會很容易壞掉。
link |
這樣大家聽得懂我的意思嗎?這個地方大家有問題要問的嗎?所以今天一開始這兩個network是一樣的,然後接下來在train的時候,你會把它fix住,然後你在做gradient descent的時候只調左邊這個network的參數,
link |
那你可能update比如說一百次以後,才把這一個參數複製到右邊去把它蓋過去,把它蓋過去以後,你這個target的value就變了,就好像說你今天本來在做一個regression的problem,
link |
那你train train train把這個regression的problem的notes壓下去以後,接下來你把這邊的參數把它copy過去以後,你的target就會變掉了,你output的target就變掉了,那你接下來你就要重新再train這樣子。
link |
好,這樣大家有問題嗎?一起做,一起做。
link |
同樣的function,在這邊input是st跟at,這邊input是st加1,在st加1會採取的action pileup st加1,因為input不一樣,所以它output的值是會不一樣,所以光這一下跟這一下的值就會不一樣。
link |
那今天再加上at,所以它們的值就會更不一樣,但是你希望說你會把這兩項的值把它拉近這樣子,要把它拉近。
link |
好,這樣大家還有問題要問嗎?如果大家OK的話,這個是第一個你會用到的tip啦。
link |
好,第二個你會用到的tip是exploration,我們剛才講說當我們使用q function的時候,我們的policy是怎樣,我們policy完全depend on那個q function,
link |
換說given某一個state,你就窮取所有的a,看哪個a可以讓q value最大,它就是你採取的policy,它就是採取的action。
link |
而且這個跟policy gradient不一樣,在做policy gradient的時候,我們的output其實是stochastic的,對不對,我們output一個action的distribution,根據這個action的distribution去做sample,所以在policy gradient裡面,你每次採取的action是不一樣的,是用水晶形式。
link |
那像這種q function,如果你採取的action總是固定的,會有什麼問題呢?你會遇到的問題就是,這不是一個好的收集data的方式。
link |
為什麼這不是一個好的收集data的方式呢?因為假設我們今天真的要估某一個,我這邊應該要,某一個state可以採取action a1, a2, a3,我這邊應該要寫a1, a2, a3,但我忘了加了,我忘了加了。
link |
好,今天你要估測在某一個state採取某一個action會得到的q value,你一定要在那一個state採取過那一個action,你才估得出它的value,對不對?
link |
如果你沒有在那個state採取過那個action,你其實估不出那個value的。當然如果是用deep的network,就你的q function其實是一個network的話,這種情形可能會比較沒有那麼嚴重。
link |
但是in general而言,假設你的q function是一個table,沒有看過的state action pair,它就是估不出值來,當然network也會有一樣的問題就是了,只是沒有那麼嚴重,但也會有一樣的問題。
link |
所以今天假設你在某一個state,action a1, a2, a3,你都沒有採取過,那你估出來的a1, a2, a3的q value可能就都是一樣的,就都是一個初始值,比如說0。
link |
但是今天假設你在state x,你sample過某一個action a2了,那sample到某一個action a2,它得到的值是positive的reward,那現在q的a2就會比其他的action都要好。
link |
那我們說今天在採取action的時候,就看誰的q value最大就採取誰,所以之後你永遠都只會sample到a2,其他的action就再也不會被做了,所以今天就會有問題。
link |
就好像說你進去一個餐廳吃飯,反正餐廳都有一個菜單,那些你都很難選,你選到某一個,你今天點了某一個東西以後,接下來你可能就不會,今天下次你來去吃的時候,你就會再點一樣的東西,
link |
你今天點了某一個東西,比如說椒麻雞,你覺得還可以,接下來你每次去,就都會點椒麻雞,又再也不會點別的東西了,但你就不知道說別的東西是不是會比椒麻雞還要好吃就是了,這個是一樣的問題。
link |
那如果你今天沒有好的exploration的話,你在training的時候,你就會遇到這種問題。
link |
舉一個實際的例子,假設你今天是用Q-learning來玩Sleeper IO,在玩Sleeper IO的時候你會有一個蛇,牠在環境裡面就走來走去,吃到星星牠就加分。
link |
今天假設這個遊戲一開始,牠採取往上走,然後就吃到那個星星,牠就得到分數,牠就知道說往上走是positive,接下來牠就再也不會採取往上走以外的action了,所以接下來就會變成每次遊戲一開始牠就往上衝,然後就死掉,然後再也做不了別的事。
link |
所以今天需要有exploration的機制,需要讓machine知道說,雖然A2根據之前sample的結果好像是不錯,但你至少偶爾也試一下A1跟A3,搞不好牠們更好也說不定。
link |
有兩個方法來解這個問題,一個是Epsilon規定,Epsilon規定的意思是說,我們有E-Epsilon的機率,通常Epsilon就設一個很小的值,
link |
所以E-Epsilon可能是90%,你有90%的機率,完全按照Q-function來決定action,但是你有10%的機率,你是隨機的。
link |
通常在實作上,Epsilon會隨著時間遞減,也就是在最開始的時候,因為還不知道哪個action是比較好的,所以你會花比較大的力氣在做explore。
link |
那接下來隨著training的次數越來越多,已經比較確定說哪一個Q是比較好的,你就會減少你的exploration,你會把Epsilon的值變小,主要根據Q-function來決定你的action,比較少做random。
link |
那還有另外一個方法叫Boltzmann exploration,這個方法就比較像是Parsigradient,在Parsigradient裏面,我們說neighborhood output是根據action space上面的一個probability distribution,再根據probability distribution去做sample。
link |
那其實你也可以根據Q-value去定一個probability distribution,你可以說,假設某一個action它的Q-value越大代表它越好,那我們採取這個action的機率就越高。
link |
但是某一個action它的Q-value小,也不代表我們不能夠try try看說它好不好用,所以有時候我們也要try try看那些Q-value比較好的action。
link |
那怎麼做呢?因為Q-value它是有正有負的,所以你要把它弄成一個機率,你可能就先取exponential,然後再做normalize。
link |
然後把Q-value的exponential再做normalize以後的這個機率,就當作是你在決定action的時候sample的機率,這樣你就可以達到exponential的效果。
link |
請說,Q一開始嗎?其實在實作上,你那個Q是一個paywall,所以你有點難知道說,今天在一開始的時候,neighborhood output到底會長什麼樣。
link |
但是你其實可以猜測說,假設一開始沒有任何的training data,你的參數是隨機的,那given某一個state s,你的不同的a的output值可能就是差不多的,所以一開始Q of sa應該是會傾向於是uniform的,也就是在一開始的時候,你這個probability值沒有算出來,它可能是比較uniform的。
link |
你是說他實際上的直算不會不會就是假設你今天你的直通通比如說通通都是一你的直通通都是二你的直通通都是一百套這個式子以後算出來的結果會是一樣的對不對
link |
那還有第三個你會用的這個叫做replay buffer意思是說現在我們會有某一個policy去跟環境做互動,然後他會去收集data,我們會把所有的data放到一個buffer裡面,那buffer裡面就排了很多的data,那你buffer他會設比如說五萬,這樣他裡面可以存五萬筆資料,每一筆資料是什麼?
link |
每一筆資料就是記得說啊,我們之前在某一個state ST採取某一個action AT,接下來我們得到了reward RT,然後接下來跳到state ST加1,就每一筆資料就是這樣,好,那你用排序跟環境互動很多次,把所有收集到的資料通通都放到這個replay buffer裡面,都放到replay buffer裡面。
link |
好,那這邊要注意的事情是,這個replay buffer啊,他裡面的experience可能是來自於不同的policy,就是你每次你拿排序跟環境互動的時候,你可能只互動一萬次,然後接下來就更新你的排了,但是你的這個buffer裡面你可以放五萬筆資料,所以那五萬筆資料,他們可能是來自於不同的policy。
link |
而這個buffer只有在他裝滿的時候,才會把舊的資料丟掉,所以這個buffer裡面,他其實裝了很多不同的policy,所計算出來的,不同的policy的experience。
link |
好,那接下來啊,你有了這個buffer以後,你做的事情,你是怎麼train這個Q的model的呢?你是怎麼估這個Q的function的呢?你的做法是這樣,你會iteratively train這個Q function,在每個iteration裡面,你從這個buffer裡面隨機挑一個batch出來,就跟一般的network training一樣,你從training dataset裡面去挑一個batch出來,你去sample一個batch出來,裡面有一把的experience,再根據這把experience去update你的Q function。
link |
就跟我們剛才講的那個TD learning,要有一個targeting network什麼是一樣的,你去sample一個batch,sample一個batch的data,sample一堆experience,然後再去update你的Q function。
link |
好,這邊其實有一個東西你可以稍微想一下,你會發現說,實際上當我們這麼做的時候,它變成了一個of policy的做法,對不對?因為現在本來我們的Q是要觀察拍這個action它的value,但實際上存在你的replay buffer裡面的這些experience,不是通通來自於拍,對不對?
link |
有一些是過去的其他的拍所遺留下來的experience,因為你不會拿某一個拍就把整個buffer裝滿,然後拿去train Q function,這個拍只是sample一些data塞到那個buffer裡面去,然後接下來就讓Q去train。
link |
所以Q在sample的時候,它會sample到過去的一些資料,但是這麼做到底有什麼好處呢?這麼做有兩個好處,第一個好處是,其實在做reinforcement learning的時候,往往最花時間的step是在跟環境做互動,train level反而是比較快的,因為你GPU train其實很快,真的花時間往往是在跟環境做互動。
link |
今天用replay buffer,你可以減少跟環境做互動的次數,因為今天你在做training的時候,你的experience不需要通通來自於某一個policy,一些過去的policy它所得到的experience可以放在buffer裡面,被使用很多次,被反覆的再利用,這樣讓你的sample到experience的利用是比較efficient。
link |
還有另外一個理由是,你記不記得我們說在train level的時候,其實我們希望一個batch裡面的data越diverse越好,如果你的batch裡面的data通通都是同樣性質的,你train下去其實是容易壞掉的,對不對?
link |
不知道大家有沒有這樣的經驗,如果你batch裡面都是一樣的data,train的時候performance會比較差的,我們希望batch裡面的data越diverse越好。
link |
如果你今天你的buffer裡面的那些experience,它通通來自於不同的policy的話,你得到的結果,你sample到的一個batch裡面的data會是比較diverse的。
link |
但是接下來你會問的一個問題是,我們明明是要觀察pi的value,我們要量的明明是pi的value,你們又混雜了一些不是pi的experience,到底有沒有關係?
link |
一個很簡單的解釋是說,也許這些不同的pi也沒差那麼多,所以也沒有關係。但是你仔細想一想,這一件事情其實是沒有關係的。
link |
這並不是因為過去的pi跟現在的pi很像,就算過去的pi沒有很像,其實也是沒有關係的。這個就留給大家回去想一下,說為什麼會這個樣子。
link |
今天主要的原因是因為我們並不是去sample一個trajectory,我們只sample了一筆experience,所以跟我們是不是of policy這件事是沒有關係的。
link |
就算是of policy,就算是這些experience不是來自於pi,我們其實還是可以拿這些experience來估測Qpi of SA。
link |
這件事有點難解釋,不過你就記得說replay buffer這招,其實在理論上也是沒有問題的。
link |
好,那這個就是typical的一般的正常的Q-learning的演算法。這個演算法是這樣,我們說我們需要一個target network嘛,所以一開始initialize的時候,你需要兩個network,一個是Q,一個是Q-head,那其實Q-head就等於Q啦,一開始這個target network跟你target的Q-network跟原來的Q-network是一樣的。
link |
好,那在每一個episode,就你拿你的agent,你拿你的actor去跟環境做互動,那每一次在每一次互動的過程中,你都會得到一個state st,一個遊戲的畫面,那你會採取某一個action at,那怎麼知道採取哪一個action at呢,你就根據你現在的Q-function,但是要記得你要有exploration的機制,比如說你用Boltzmann exploration或Epsilon greedy的exploration,有一點exploration的機制。
link |
好,那接下來你得到reward rt,然後跳到state st加1,那你現在collect到一筆data,這筆data是stacrt st加1,你把這筆data就塞到你的buffer裡面去,那如果buffer滿的話,你就把一些舊的資料再把它丟掉。
link |
好,那接下來你就從你的buffer裡面去sample data,那你sample到的是sairi si加1,這筆data跟你剛放進去的不見得是同一筆,懂嗎?你把這筆data塞到buffer裡面,塞到buffer裡面去抽data,抽出來並不是同一筆,你可能抽到一個舊的也是有可能的。
link |
那這邊另外要注意的事情就是,我覺得notation不太好寫,其實你sample出來不是一筆data,你sample出來的是一個batch的data,你sample一個batch出來,sample一把experience出來。
link |
好,你sample這一把experience之後,接下來你要做的事情就是計算你的target,根據你sample出來的data,假設你sample出這麼一筆data,根據這筆data去算你的target。
link |
你的target是什麼呢?target要記得要用target network,也就是Q-head來算,我們用Q-head來代表target network。好,那target是多少呢?target就是ri加上Q-head of si加1a,a是什麼?
link |
a就是看說現在哪一個a可以讓Q-head的值最大,你就選那一個a,因為我們在這邊,在state si加1會採取的action a,其實就是那個可以讓Q-value的值最大的那一個a。
link |
好,那接下來呢,我們要update那個Q的值,那他就把它當這個regression function,希望Q的siai跟你的target越接近越好。
link |
然後今天假設這個update已經update了某一個數目的字,比如說C次,比如說你就設一個100,C等於100,那你就把Q-head設成Q,然後就這樣。