back to index
DRL Lecture 4: Q-learning (Advanced Tips)
link |
哪裡有錯?我看看,哦,這裡,太厲害了,太厲害了,好,等一下告訴我你叫什麼名字,這樣子,好,等一下告訴我你叫什麼名字。
link |
好,那接下來我們要講的是Train Q-learning的一些Tip,那在作業裡面當然是會要求你implement某一個Tip,那你等一下就看看說哪一個Tip是你覺得最簡單的。
link |
那第一個要介紹的Tip叫做Double DQN,那為什麼要有Double DQN呢?因為在實作上你會發現說Q-value往往是被高估的,那下面這幾張圖是來自於Double DQN的原始的paper,那想要顯示的結果就是Q-value往往是被高估的。
link |
那這邊就是有四個不同的小遊戲,那橫軸呢是那個training的時間,然後這個紅色的這個句子中一直在變的線就是這個Q-function所estimate出來的,對不同的stateestimate出來的平均的Q-value,就有很多不同的state,每個state你都sample一下,然後算他們的Q-value把它平均起來,就是紅色這一條線。
link |
那在training的過程中會改變,但它是不斷上升的,為什麼它會不斷上升?因為很直覺,不要忘了Q-function是depend on你的policy的,你今天在learn的過程中你的policy越來越強,所以你得到的Q-value會越來越大,你得到的在某個state,同一個state,你得到的expected reward會越來越大,所以general而言這個值都是上升的。
link |
好,但是他說這個是Q-network估測出來的值,接下來你真的去算它,那怎麼真的去算?很容易啊,你有那個policy,然後真的去玩那個遊戲,你就可以真的去算說,就玩很多次,玩個一百萬次,然後就真的估說在某一個state,你會得到的Q-value到底有多少,你會得到說在某一個state,你接下來採取某一個action,你接下來會得到的reward,cumulative reward的總和是多少。
link |
那你會發現說,實際的值跟估測出來的值,估測出來的值是遠比實際的值大,在每一個遊戲都是這樣,都大很多。
link |
所以他今天要propose的這個double DQN方法就是,它可以讓估測的值跟實際的值是比較接近的,那我們還沒有講double DQN的方法,但我們先看它的結果。藍色的,彙聚子狀的線是double DQN的Q-network所估測出來的Q-value,那藍色的是真正的Q-value,你會發現說它們是比較接近。
link |
還有另外一個有趣可以觀察的點是說,你會發現用double DQN所估測出來的Q-value都比,就是說估測出來的就不用管它,用network估測出來的就不用管它,那比較沒有參考價值。
link |
但是如果是真正的cumulative reward,用double DQN得出來的真正的cumulative reward,在這三個case都是比原來的DQN高的,代表double DQN認出來的那個policy比較強,所以它實際上得到的reward是比較大。
link |
雖然說看那個Q-network的話,一般的DQN的Q-network虛張聲勢,高估了自己會得到的reward,但是實際上它得到的reward是比較多的。
link |
接下來就要講的第一個問題就是,為什麼Q-value總是被高估了呢?這個是有道理的,因為想想看我們實際上在做的時候,我們是要讓左邊這個式子跟右邊我們這個target越接近越好。
link |
那你會發現說target的值很容易一不小心就被設得太高。為什麼target的值很容易一不小心就被設得太高呢?
link |
因為你想想看,在算這個target的時候,我們實際上在做的事情是說,看哪一個A它可以得到最大的Q-value,就把它加上去,就變成我們的target。
link |
所以今天假設有某一個action,它得到的值是被高估的。舉例來說,我們現在有四個action,本來其實它們得到的值都是差不多的,它們得到的reward都是差不多的,但是在estimate的時候,畢竟是個network,所以estimate的時候是有誤差的。
link |
所以假設今天是第一個action,它被高估了,就假設綠色的東西代表是被高估的量,它被高估了,那這個target就會選這個action,然後就會選這個高估的Q-value來加上RT當作你的target。
link |
如果第四個action被高估了,那就會選第四個action來加上RT,來當作你的target value。所以你總是會選那個Q-value被高估的,你總會選那個reward被高估的action,當作這個max的結果,去加上RT當作你的target。
link |
所以你的target總是太大,對不對?那怎麼解決這個target總是太大的問題呢?在double TQM它的設計是這個樣子的。在double TQM裡面,選action的Q-function跟算value的Q-function不是同一個。
link |
今天在原來的DQM裡面,你窮取所有的A,把每一個A都帶進去,看哪一個A可以給你的Q-value最高,那你就把那個Q-value加上RT。
link |
但是在double TQM裡面,你有兩個Q-network,第一個Q-network決定哪一個action的Q-value最大,你用第一個Q-network去帶入所有的A,去看看哪一個Q-value最大。
link |
那你決定你的action以後,實際上你的Q-value是用Q-prime所算出來的。這樣子有什麼好處呢?為什麼這樣就可以避免overestimate的問題呢?
link |
因為今天假設我們有兩個Q-function,假設第一個Q-function它高估了它現在選出來的action A,那沒關係,只要第二個Q-function Q-prime它沒有高估這個action A的值,那你算出來的就還是正常的。
link |
那今天假設反過來是Q-prime高估了某一個action的值,那也沒差,因為反正只要前面這個Q不要選那個action出來,就沒事了。這個就跟行政跟立法是分立的概念是一樣的。
link |
大家了解嗎?就是這一個Q它只能夠提案,它不能夠執行,Q負責提案,它負責選A,Q-prime負責執行,它負責算出Q-value的值。
link |
所以今天就算是前面這個Q做了不好的提案,它選的A是被高估的,只要後面Q-prime不要高估這個值就好了,那就算Q-prime會高估某一個A的值,只要前面這個Q不提案那個A,就算出來的值就不會被高估了,所以這個就是double DQN神奇的地方。
link |
然後你可能會說,那哪來兩個Q跟Q-prime呢?哪來兩個network呢?其實在實作上,你確實是有兩個Q-value的,因為一個就是你真正在update的Q,另外一個就是target的Q-network。
link |
所以你其實有兩個Q-network,一個是target的Q-network,一個是真正你會update的Q-network。
link |
所以在double DQN裡面,你的實作方法會是,你拿真正的Q-network,你會update參數的那個Q-network,去選action,然後你拿target的network,固定住不動的network,去算value。
link |
而那double DQN相較於原來的DQN的更動是最少的,它幾乎沒有增加任何的運算量,你看連新的network都不用用,因為你原來就有兩個Q-network了。
link |
你唯一要做的事情只有,本來你在找最大的A的時候,你在決定這個A要放哪一個的時候,你是用Q-prime來算,你是用freeze的network來算,你是用target的network來算,現在改成用另外一個會update的Q-network來算,這個應該是改一行code就可以解決了。
link |
所以假設今天等一下會講好幾個tip,假設你今天只選一個tip的話,正常人都是implement double DQN這樣,所以這個就是輕易的就可以implement,這是第一個你可以嘗試的tip。
link |
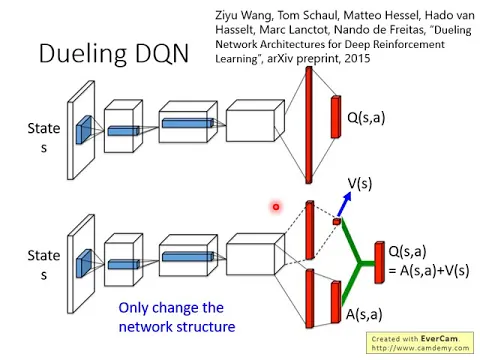
第二個tip叫做during的DQN,during的DQN是什麼呢?其實during的DQN也蠻好做的,相較於原來的DQN,它唯一的差別是改了network的架構,等下你聽了如果覺得聽了有點沒有辦法跟上的話,你就要記住一件事,during DQN它唯一做的事情是改network的架構,也就是改了那個,我們說Q-network就是input state,output就是每一個action的Q-value。
link |
during DQN唯一做的事情是改了network的架構,其他的演算法你都不要去動它,那during DQN它是怎麼改了network的架構呢?它是這樣說的,現在本來的DQN就是直接output Q-value的值,現在這個during的DQN就是下面這個network的架構它不直接output Q-value的值。
link |
它是怎麼做的?它在做的時候它分成兩條path去運算,第一個path它算出一個scalar,那這個scalar我們叫做d of s,因為它跟input s是有關係的,所以叫做d of s,d of s是一個scalar。
link |
那下面這個呢,它會output另外一個vector,這個vector叫做a of sa,那下面這個vector它是每一個action都有一個value,然後你再把這兩個東西加起來就得到你的Q-value。
link |
如果你覺得這樣不夠具體的話,實際上做的事情就是這樣,你有一個Q-network,input state進來,那首先會output兩個東西,一個東西叫做b of s,它就是一個scalar,我們就假設它是1.0好了。
link |
然後接下來我們會output另外一個vector,這個vector它是每一個,它跟那個dimension跟你action的數目是一樣的,就是它的action,a1,a2,a3,那你這邊就是output三個值,比如說這邊叫output,這邊是1.0,這邊output比如說-2,-2,0好了,就隨便取個。
link |
然後接下來你要做的事情是把這兩個值加起來,所謂加起來的意思就是說把1.0加到第一維,加到第二維,加到第三維,加起來,加起來,變成這個是3-1,這個東西就是你的Q of sa,這個是a1的Q-value,a2的Q-value,a3的Q-value,就這樣。
link |
大家有問題要問嗎?這個很簡單,這個就是改network的架構,其他的training就是一模一樣的,這個就是你的Q-value,跟你之前怎麼用Q-value,現在你就怎麼用這個network。
link |
好,但是接下來你要問的問題就是,這麼改有什麼好?所以接下來就是想要講一下說,這麼改有什麼好呢?好,那我們假設說原來的Q of sa,它其實就是一個table,對不對,我們假設state是discrete的,但實際上state不是discrete的,那為了說明方便,我們假設就是只有四個不同的state,只有三個不同的action,所以Q of sa你可以看作是一個table。
link |
好,那我們說Q of sa等於V of s加上a of sa,那V of s是對不同的state它都有一個值,a of sa它是對不同的state,不同的action都有一個值,那你把這個V的值加到a的每一個column,V的值加到a的每一個column,就會得到Q的值,2加1,2加-1,2加0,就得到312,以此類推。
link |
所以你就把這一個東西給它加上去,加上去,加上去,就得到上面這個,你把V加上a,就得到Q。
link |
好,那今天假設說你在train內握的時候,你現在的target是希望這個值變成4,這個值變成0,但是你實際上能更動的並不是Q的值,你的內握更動的是V跟a的值,根據內握的參數,V跟a的值output以後是直接把它們加起來的,所以其實不是更動Q的值。
link |
然後在練內握的時候,假設你希望這邊的值,這個3增加1變成4,這個-1增加1變成0,最後你在train內握的時候,內握可能會選擇說,我們就不要動這個a的值,我們就動V的值,把V的值從0變成1。
link |
那你把從0變成1有什麼好處呢?這個時候你會發現說,本來你只想動這兩個東西的值,那你會發現說,這個第三個值也動了。
link |
所以有可能說你在某一個state,你明明只sample到這兩個action,你沒sample到第三個action,但是你其實也可以更動到第三個action的Q value,那這樣的好處就是,你就變成你不需要把所有的state action pair都sample過,你可以用比較efficient的方式去estimate Q value出來。
link |
因為有時候你update的時候,不一定是update下面這個table,而是只update了V of S,但update V of S的時候,只要一改,所有的值就會跟著改,所以這是一個比較有效率的方法去使用你的data,所以這個是dueling DQN可以帶給我們的好處。
link |
可是接下來有人就會問說,真的會這麼容易嗎?會不會最後認出來的結果是,反正Machine就學到說,我們也不要管什麼V的,V就永遠都是0,然後反正A就等於Q,那就沒有得到任何dueling DQN可以帶給的好處,就變成原來的DQN一模一樣。
link |
所以為了避免這個問題,實際上你會對下面這個A下一些constraint,你要給A一些constraint,讓update A其實比較麻煩,讓network傾向於會想要去用V來解的問題。
link |
舉例來說,你可以看原始的文件,它有不同的constraint,一個最直覺的constraint是,你必須要讓這個A的每一個column的和都是0,每一個column的值的和都是0,你可以看我這邊舉的例子,我的column的和都是0。
link |
那如果這邊的column的和都是0,這邊這個V的值,你就可以想成是上面Q的每一個column的平均值,這個平均值加上這些值才會變成是Q的value。
link |
所以今天假設你發現說你在update參數的時候,你是要讓整個row一起被update,你就不會想要update這邊,你就不會想要updateA這個matrix,因為A這個matrix的每一個column的和都是要是0。
link |
所以你沒有辦法說,讓這邊的值通通都加1,這件事做不到,因為它的constraint就是你的和永遠都是要0,所以你不可以都加1,這時候就會強迫network去updateV的值,然後讓你可以用比較有效率的方法去使用你的data。
link |
那實作上怎麼做呢?所以實作上我們剛才說,你要給這個A一個constraint,所以在實際implement的時候你會這樣implement,假設現在你的network的output是732,就舉個例子。
link |
假設你有三個action,然後在這邊output的vector是732,你在把這個A跟這個V加起來之前,先加一個normalization,就好像做那個layer normalization一樣,加一個normalization。
link |
這個normalization做的事情就是把7加3加2加起來等於12,12除以3等於4,然後把這邊通通減掉4,變成3-1-2,再把3-1-2加上一點0,得到最後的Q value。
link |
然後這個東西就是network的一部分,這樣你聽得懂嗎?這個normalization的step就是network的其中一部分。
link |
在train的時候,你從這邊也是一路被publicate回來的,只是normalization這個地方是沒有參數的,它就是一個normalization的operation,
link |
讓它可以放到network裡面,跟network的其他部分,就一個retrain,這樣A就會有比較大的,到大的constraint,這樣network就會給它一些benefit,傾向於去updateV的值。
link |
這個是dueling DQN,這個也算是容易。
link |
其實還有很多技巧可以用,這邊我們就比較快的帶過去,有一個技巧叫做priority replace,priority replace是什麼意思呢?
link |
我們原來在sample data去train你的Q-network的時候,你是uniform的從experience buffer裡面,這邊沒有拼錯,是buffer,
link |
從buffer裡面去sample data,你就是uniform的去sample每一筆data,這樣不見得是最好的,因為也許有一些data比較重要,你做不好的那些data。
link |
假設有一些data,你之前有sample過,你發現說那一筆data的td error,所謂td error就是你的network的output跟target之間的差距,你的td error特別大。
link |
這些data代表說你在train network的時候,你是比較train不好的,那既然比較train不好,那你就應該給它比較大的機率被sample到,
link |
所以這樣在training的時候,才會考慮那些train不好的training data多次一點,這個非常的直覺。
link |
詳細的事實,你再去看一下paper,其實等一下助教在講priority replay的時候會講更多東西,因為實際上在做priority replay的時候,你還不只會更改sampling的process,
link |
你還會因為更改了sampling的process,你會更改update參數的方法,這個我們就留給助教講就好。
link |
所以priority replay其實並不只是改變了sample data的distribution那麼簡單,你也會改training的process。
link |
另外一個可以做的方法是你可以balance Monte Carlo跟td,我們剛才講說Monte Carlo跟td的方法,它們各自有各自的優劣,
link |
那我們怎麼在mc跟td裡面取得一個平衡呢?我們的做法是這樣,在std裡面,你只需要存在某一個state st,
link |
採取某一個action at,得到reward rt,還有接下來跳到下哪一個state st加1,但是我們現在可以不要只存一個step的data,
link |
我們存大n個step的data,我們記錄在st採取at,得到rt,會跳到什麼樣的st,一直記錄到在第n個step以後,
link |
在st加大n,採取at加大n,得到reward rt加大n,得到跳到state st加大n加1的經驗,通通把它存下來。
link |
實際上你今天在做update的時候,在做你的Q-Network的learning的時候,你的learning的方法會是這樣,
link |
你learning的時候,你是要讓這個Q的stat跟你的target value越接近越好,而你的target value是什麼呢?
link |
你的target value是會把從時間t一直到t加大n的n個reward通通都加起來,然後你現在的Q-Net所計算的不是st加1,而是st加n加1,
link |
你會把大n個step以後的state丟進來,去計算大n個step以後你會得到的reward,再加上multiple step的reward,然後希望你的target value跟這個multiple step的reward越接近越好。
link |
那你會發現說這個方法它就是mc跟td的結合,因為它就有mc的好處跟壞處,也有td的好處跟壞處。那如果看它的這個好處的話,
link |
因為我們現在sample了比較多的step,之前是只sample了一個step,只有某一個step得到的data是real的,接下來都是Q-value估測出來的。
link |
現在sample比較多step,sample大n個step才估測value,所以估測的部分所造成的影響就會比較輕微,當然它的壞處就跟mc的壞處一樣,
link |
因為你的r比較多項,你把大n項的r加起來,你的variance就會比較大,但是你可以去調這個n的值,去在variance跟不精確的Q之間取得一個平衡。
link |
那這個就是一個hyperparameter,你要調這個大n到底是多少,你是要多sample三步,還是多sample五步,這個就跟network structure是一樣,是一個你需要自己調一下的值。
link |
好,那還有其他的技術,有一個技術是要improve exploration這件事,我們之前講的hepstone greedy這樣的exploration,它是在action的space上面加nodes。
link |
但是有另外一個更好的方法叫做noisy net,它是在參數的space上面加nodes,什麼意思?
link |
noisy net的意思是說,每一次在一個episode開始的時候,你要跟環境互動的時候,你就把你的Q function拿出來,那Q function裡面其實就是一個network嘛,
link |
就是你把那個network拿出來,在network的每一個參數上面加上一個Gaussian noise,那就把原來的Q function變成Q delta,因為Q hat已經用過,Q hat是那個target network,我們用Q delta來代表一個noisy的Q function。
link |
那我們把每一個參數都可能都加上一個Gaussian noise,你就得到一個新的network叫做Q delta。那這邊要注意的事情是,我們每次在sample noise的時候,要注意在每一個episode開始的時候,我們才sample network。
link |
這樣大家了解我的意思嗎?在每個episode開始的時候,在跟環境互動之前,我們就sample network,接下來你就會用這個固定住的noisy的network去玩這個遊戲,直到遊戲結束,你才重新再去sample新的noise。
link |
那這個方法神奇的地方就是,這個OpenAI跟DeepMind又在同時間propose了一模一樣的方法,通通都publish在IQ2018,然後兩篇paper的方法就是一樣的,不一樣的地方是他們用不同的方法去加noise。
link |
那我記得那個OpenAI加的方法好像比較簡單,它就直接加一個Gaussian noise就結束了,就是你把每一個參數、每一個weight都加一個Gaussian noise就結束了。
link |
然後DeepMind他們做的比較複雜,他們的noise是由一組參數控制的,也就是說network可以自己決定說它那個noise要加多大,但是概念就是一樣的,總之你就是把你的Q function裡面的network加上一些noise,把它變得有點不一樣,跟原來的Q function不一樣。
link |
那兩篇paper裡面都有強調說,你這個參數雖然會加noise,但是在同一個episode裡面,你的參數就是固定的,你是在換episode,玩第二場新的遊戲的時候,你才會重新sample noise。
link |
在同一場遊戲裡面,就是同一個noisy的Q network在玩那一場遊戲。
link |
這件事非常重要,為什麼這件事非常重要呢?因為這是導致了為什麼在network這個方法,noisy net跟原來的axiom greedy或是其他在action上做sample的方法本質上的差異。
link |
在原來的sample的方法,比如說axiom greedy裡面,就算是給同樣的state,你的agent採取的action也不一定是一樣的,對不對?
link |
因為你是用sample決定的啊,given同一個state,你如果sample到說要根據Q function的network,你會得到一個action,你sample到random,你會採取另外一個action。
link |
所以given同一個state,如果你接受axiom greedy的方法,它得到的action是不一樣的。
link |
但是你想想看,實際上你的policy並不是這樣運作的啊,在一個真實世界的policy,給同樣的state,它應該會有同樣的回應,而不是給同樣的state,它其實有時候是Q function,然後有時候又是隨機的。
link |
所以這個是一個比較奇怪的、不正常的action,是在真實的情況下不會出現的action。但是如果你是在Q function上面去加noise的話,就不會有這個情形。
link |
因為如果你今天在Q function上加noise,在Q function的network的參數上加noise,那在整個互動的過程中,在同一個episode裡面,它的network的參數總是固定的。
link |
所以看到同樣的state或是相似的state,就會採取同樣的action,這個是比較正常的。
link |
那在paper裡面有說這個叫做state-dependent exploration,也就是說你雖然會做explore這件事,但你的explore是跟state有關係的,看到同樣的state,你就會採取同樣的exploration的方式。
link |
也就是說你在explore你的環境的時候,你是用一個比較consistent、一致的方式去測試這個環境。
link |
也就是上面如果你是noise的action,你只是隨機亂試,但是如果你是在參數下加noise,在同一個episode裡面,裡面的你的參數是固定的,那你就是有系統的在嘗試。
link |
就每次會試說在某一個state,我都向左試試看,然後在下一次在玩這個同樣的遊戲的時候,看到同樣的state,你就說我再向右試試看,你是有系統的在explore這個環境。
link |
主持人說那這邊這個實驗,我記得是openai的實驗,他們就是想要告訴你說,用noise類的方法是真的好,左邊這個是episode規定的方法,右邊這個是noise類的方法,然後希望訓練這個狗開始奔跑。
link |
主持人說那左邊這個方法,雖然這個狗最後也可以學會奔跑,但是因為可能exploration的方法不太對,所以他沒真的到學到一個好的奔跑的方式,他是用一個沒有效率的方法在奔跑。
link |
你會發現右邊的跑比較快,因為他已經跑到黑色的區域了,左邊那個還沒有跑到黑色的區域,他跑得比較慢。右邊的是用比較有效率的方法在奔跑。
link |
還有另外一個東西,叫做distributional Q-function,我們就不講它的細節,只告訴你它的大概念。distributional Q-function我覺得還蠻有道理的,但是它沒有紅起來,就發現說沒有太多人真的在實作的時候用這個技術,可能一個原因就是因為它不好實作。
link |
它的意思是什麼?我們說Q-function到底是什麼意思?我們說Q-function是accumulated reward的期望值,所以我們算出來的這個Q-value它其實是一個期望值,也就是說實際上我在某一個state採取某一個action的時候,因為環境是有隨機性,在某一個state採取某一個action的時候,實際上我們把所有的reward玩到遊戲結束的時候所有的reward進行一個統計,你其實得到的是一個distribution。
link |
也許在reward得到零的機率很高,在-10的機率比較低,在-10的機率比較低,但是它是一個distribution,這個Q-value代表只是說我們對這個distribution算它的mean,才是這個Q-value,我們算出來是expected accumulated reward。
link |
真正的accumulated reward是一個distribution,對押起expectation,對押起mean,你得到了Q-value。但是有趣的地方是,不同的distribution它們其實可以有同樣的mean,也許真正的distribution是這個樣子,它算出來的mean跟這個distribution算出來的mean其實是一樣的,但它們背後所代表的distribution其實是不一樣的。
link |
所以今天假設我們只用一個expected的Q-value來代表整個reward的話,其實可能是有一些information是lost的,你沒有辦法modelreward的distribution。
link |
所以今天distributional的Q-function它想要做的事情是modeldistribution,所以怎麼做?在原來的Q-function裡面,假設你只能夠採取A1、A2、A3三個action,那你就是input一個set,output三個value,三個value分別代表三個action的Q-value,但這個Q-value是一個distribution的期望值。
link |
所以今天distributional的Q-function它的idea就是,何不直接output那個distribution,但是要實際output一個distribution你不知道怎麼做嘛,對不對?實際上的做法是說,假設distribution的值就分佈在某一個range裡面,比如說-10到10,要把-10到10中間拆成一個一個的bit,拆成一個一個的長條圖,拆成一個一個的bit。
link |
舉例來說,在這個例子裡面,每一個action等於我們把reward的space就拆成五個bit,拆成五個bit,拆成五個bit。
link |
這邊的做法就是,假設reward可以拆成五個bit的話,今天你的Q-function的output是要預測說,在某一個bit裡面,你在某一個state採取某一個action,你得到的reward落在某一個bit裡面的機率。
link |
所以其實這邊的機率的核,這些綠色的bar的核應該是1,它的核應該是1,它的核應該是1。
link |
它的高度代表說,在某一個state採取某一個action的時候,它落在某一個bit的機率。
link |
這邊綠色的代表action1,紅色代表action2,藍色的代表了action3。
link |
所以今天你就可以真的用Q-function去estimateA1的distribution,A2的distribution,A3的distribution。
link |
實際上在做testing的時候,我們還是要選某一個action去執行,那選哪一個action呢?實際上在做的時候,它還是選命最大的那個action去執行。
link |
但是假設我們今天可以model distribution的話,除了選命最大的以外,也許在未來你可以有更多其他的應用。
link |
舉例來說,你可以考慮它的distribution長什麼樣子,如果distribution variance很大,代表說採取這個action,雖然命平均而言可能不錯,但也許風險很高。
link |
你可以train一個network它是可以規避風險的,就在兩個action命都差不多的情況下,也許它可以選一個風險比較小的action來執行,這是distribution和Q-function的好處。
link |
那細節怎麼train這樣的Q-network我們就不講,你只要記得說反正Q-network有辦法output一個distribution就對了,我們可以不只是估測命的值,我們不只是估測得到的期望reward的命的值,我們其實是可以估測一個distribution的。
link |
好,那下一頁呢,這個是一個demo,就是要告訴你說,用這個技術真的可以估測distribution,那這是在文獻上找到的結果。
link |
也就是說今天呢,這個demo想要顯示的是說,左邊是機器看到的遊戲畫面是set,右邊就是reward的distribution。
link |
你要注意一下,其實每一個action都有一個自己的distribution,那只是因為現在不同的action,它們的distribution其實可能也沒差那麼多,所以它們是蓋在一起。
link |
但你還是可以看到一些不一樣的顏色,不同的action,每一個action都有一個自己的distribution。
link |
那你看這個distribution就會發現說,它其實也是蠻有道理的,我們來看一下,看它的distribution是怎麼樣的狀況。
link |
反正在遊戲開始的時候啊,通常in general而言,你的distribution是比較偏右邊的,因為你得到的reward是比較大的,因為你接下來還有很多怪可以殺,但隨著怪越殺越多,你發現distribution逐漸向左邊。
link |
橘色,你說這個是什麼東西是不是?這個是防護罩,怎麼會突然從頭開始了是不是?橘色是防護罩,對,它很笨,它設計了防護罩。
link |
你可以看到右邊的distribution就逐漸地往左邊。
link |
那你發現現在防護罩不見了以後會發生什麼事呢?你會發現在reward是零的地方,有時候會暴增,為什麼?
link |
因為它現在就是,因為防護罩不見了,所以它很容易就死掉,只要一死,reward就是零,下一個時間點就結束,reward就是零。
link |
所以你仔細觀察一下,有時候在reward是零,那邊會突然有一個暴增,會有一個peak,會有一個peak,會有一個peak,它很厲害,它清怪清完了,但可以打第二場。
link |
帶風船,你說上面嗎?他們應該會攻擊啊,可是他們沒有攻擊哦,應該會攻擊吧?
link |
而且向左,你看現在怪越來越少,distribution就向左。
link |
上面怎麼不射子彈,但它摸越來越下來,不知道為什麼它還清自己的防護罩呢?現在防護罩不見了以後就很危險,所以現在reward都會變向左邊,很危險,快死了,最後就死了。
link |
那最後要跟大家講的是一個叫做Rainbow的技術,Rainbow這個技術是什麼呢?Rainbow這個技術就是把剛才所有的方法統統綜合起來就變成Rainbow啊,因為剛才每一個方法就是有一種自己的顏色,把所有的顏色統統合起來就變成Rainbow。
link |
我們來算算看是不是真的有所有的方法,就我仔細算一下,不是才六種方法而已嗎?為什麼會變成是七色,也許它本來的TQ也算是一種方法。
link |
好,那我們來看看這些不同的方法,這個灰色這一條,這個縱軸就是你玩,這個橫軸是你這個training的process,那縱軸呢,縱軸是玩了十幾個apiary小遊戲的平均分數的盒這樣子,它取的是median的分數。
link |
為什麼是取median,不是直接取平均呢?因為它說每一個小遊戲的分數其實差很多,如果取平均的話,到時候某幾個遊戲就dominate你的結果,取median的結果。
link |
好,那這個,如果你是一般的DQN,就灰色這一條線,就沒有很強,那如果是你換noisy的DQN,就強很多。
link |
然後如果這邊每一個單一顏色的線是代表說只用某一個方法,那紫色這一條線是DDQN,double DQN,double DQN還蠻有效,你換double DQN就從灰色這條線跳成紫色這一條線。
link |
然後prioritize DQN during DQN,還有distributional DQN都蠻強的,都蠻強的,差不多都蠻強的。
link |
那這邊有個A3C,A3C其實是extra critical的方法,這個我們下週會講,那單純的A3C看起來是比DQN強的。
link |
所以發現這邊怎麼沒有multi-step的方法,他們講的multi-step的方法就balance TD跟NC,我猜是因為A3C本身內部就有做multi-step的方法,
link |
所以他可能覺得有implement A3C就算是有implement multi-step的方法,所以可以把這個A3C的結果講成是multi-step的方法。
link |
最後,其實這些方法他們本身之間是沒有衝突的,所以全部都用上去,就變成七彩的一個方法,就叫做Rainbow,然後他很高這樣,他很高。
link |
這是Rainbow的第一張圖,這是下一張圖,這張圖要說的是什麼呢?這張圖要說的事情是說,在Rainbow這個方法裡面,如果我們每次拿掉其中一個技術,到底差多少?
link |
因為現在是把所有的方法通通倒在一起,發現說進步很多,但後面有些方法其實是沒用的,所以看看說哪些方法特別有用,哪些方法特別沒用。
link |
所以這邊的虛線就是拿掉某一種方法後的結果,可以發現說黃色拿掉multi-step掉很多,Rainbow是彩色這一條,拿掉multi-step馬上就掉到這裡,然後拿掉priority-replay也馬上就掉下來,拿掉distribution他也就掉下來。
link |
而且有趣的地方是說在開始的時候,distribution訓練的方法跟其他方法速度差不多,但是如果你拿掉distribution的時候,你的訓練不會變慢,但是最後performance會收斂在比較差的地方。
link |
然後拿掉noisy-made performance差一點,拿掉dualling也是差一點,反而拿掉double沒什麼用,拿掉double沒什麼差,所以看來全部倒在一起的時候,double是比較沒有影響。
link |
其實在payload裡面有給一個make sense的解釋,他說其實當你有用distributional的DQN的時候,本質上就不會overestimate你的reward,因為我們之所以用double的理由是因為害怕會overestimate reward,因為避免overestimate reward才加了double DQN。
link |
那在payload裡面有講說,如果有做distributional的DQN就比較不會有overestimate的結果,事實上他有真的算了一下發現說,他其實多數的狀況是underestimate reward,所以會變成double DQN沒有用。
link |
那為什麼做distributional的DQN不會overestimate reward反而會underestimate reward呢?
link |
因為可能是說,現在那個distributional的DQN,我們不是說他output的是一個distribution的range嗎?所以你output的那個range不可能是無限寬的,你一定是設一個range,比如說我的output的這個range就是從負十到十,那假設今天得到的reward超過十怎麼辦,是一百怎麼辦,就當作我沒看到這件事,所以會變成說reward很極端的值,很大的值,其實是會被丟掉的。
link |
所以變成說,你今天用distributional的DQN的時候,你不會有overestimate的現象,反而有underestimate的現象就是了。
link |
主持人:"好,那我就講到這邊,現在是五點了,接下來就請助教來講一下作業示範。