back to index
DRL Lecture 5: Q-learning (Continuous Action)
link |
Q-learning 跟 policy gradient based 的方法比起來,Q-learning 其實是比較穩的,policy gradient 其實沒有太多遊戲是玩得起來的。
link |
你看看我們作業四之一是要做 break-in,為什麼四之一不用 break-in 呢?因為 policy gradient 在 break-in 上是走不太起來的。
link |
所以 policy gradient 其實比較不穩,尤其在沒有 PTO 之前,你很難用 policy gradient 做什麼事情。
link |
Q-learning 相對而言是比較穩的,所以你看最早 deep reinforcement learning 開始受到大家注意,最早的 DeepMind 的 paper 拿 deep reinforcement learning 來玩 Atari 的遊戲,用的就是 Q-learning。
link |
我覺得 Q-learning 比較容易圈的一個理由是,我們說在 Q-learning 裡面,你只要能夠 estimate 出 Q-function,就保證你一定可以找到一個比較好的 policy。
link |
你只要能夠 estimate 出 Q-function,就保證你可以 improve 你的 policy,而 estimate Q-function 這件事情並不是比較容易的,為什麼?
link |
因為它就是一個 regression 的 problem,在這個 regression problem 裡面,你可以輕易的知道說,你現在的 model learn 的是不是越來越好。
link |
你只要看那個 regression loss 有沒有下降,你就知道說你的 model learn 的好不好。
link |
所以 estimate Q-function 相較於 learn 的 policy 是比較容易的,然後你只要 estimate Q-function,就可以保證說你現在一定會得到比較好的 policy。
link |
所以一般而言, Q-learning 是比較容易操作。
link |
那 Q-learning 有什麼問題呢?它一個最大的問題就是,它沒辦法處理,也不能說沒有辦法,但它不太容易處理 continuous 的 action。
link |
很多時候你的 action 是 continuous 的,什麼時候你的 action 會是 continuous 的呢?
link |
在作業裡面,我們都只玩 Atari 的遊戲,你的 action 只需要決定比如說上下左右,這種 action 是 discrete 的。
link |
但很多時候你的 action 是 continuous 的。
link |
舉例來說,假設你的 agent 要做的事情是開自駕車,他要決定說他方向盤要左轉幾度、右轉幾度,這個是 continuous。
link |
假設你的 agent 是一個機器人,他的每一個 action 對應到的就是,假設他身上有五十個關節,他的每一個 action 就對應到他身上的這五十個關節的角度,而那些角度也是 continuous 的。
link |
所以很多時候你的 action 並不是一個 discrete 的東西,它是一個 vector,然後這個 vector 裡面,它的每一個 dimension 對應的 value 都是 real number,它是 continuous 的。
link |
假設你的 action 是 continuous 的時候,做 Q-learning 就會有困難,為什麼呢?因為我們說在做 Q-learning 裡面,一個很重要的一步是,你要能夠解這個 optimization problem。
link |
你 estimate 出 Q-function, Q of S, A 以後,你必須要找到一個 A,它可以讓 Q of S, A 的值最大。
link |
假設 A 是 discrete 的,那 A 的可能性都是有限的,舉例來說在 Atari 的小遊戲裡面,A 就是上下左右跟開火。
link |
它是有限的,你可以把每一個可能的 action 都帶到 Q 裡面,算它的 Q-value。
link |
但是假如 A 是 continuous 的,你就很麻煩,這個 continuous 的 action,你無法窮取所有 continuous action,試試看哪一個 continuous action 可以讓 Q 的 value 最大。
link |
所以怎麼辦呢?怎麼辦呢?在概念上,反正我們就是要能夠解這個問題,但是怎麼解這個問題呢?就有各種不同的 solution。
link |
第一個 solution 是,假設你不知道怎麼解這個問題,因為 A 是很多的,A 是沒有辦法窮取的,那怎麼辦?用 sample 的。
link |
Sample 出大 N 的可能的 A,一個一個帶到 Q-function 裡面,那看誰最快。
link |
那這個方法其實也不會太不 efficient,因為其實你真的在運算的時候,你會用 GPU,所以你一次會把 N 個 continuous action 都丟到 Q-function 裡面,一次得到 N 個 Q-value,然後看誰最大。
link |
當然這不是一個非常精確的做法,因為你真的沒有辦法做太多的 sample,所以你 estimate 出來的 Q-value,你最後決定的 action 可能不是非常的精確,這是第一個 solution。
link |
那第二個 solution 是什麼呢?今天既然我們要解的是一個 optimization 的 problem,你會不會解這種 optimization 的 problem 呢?
link |
你其實是會的,因為你其實可以用 gradient descent 的方法來解這個 optimization problem。
link |
我們現在其實是要 maximize 我們的 objective function,我們是要 maximize 一個東西,所以這不是 gradient descent,這是 gradient ascent,不過這意思是一樣的,我相信大家都很清楚。
link |
你就把 A 當作是你的 parameter,然後你要找一組 A 去 maximize 你的 Q-function,那你就用 gradient ascent 去 update A 的 value,最後看看你能不能夠找到一個 A 去 maximize 你的 Q-function,也就是你的 objective function。
link |
當然這樣子你會遇到的問題就是 global maxima 的問題,你不見得能夠真的找到最 optimal 的結果。
link |
而且這個運算量顯然很大,因為你要 iterative 的去 update 你的 A,我們 train 的 network 就很花時間了嘛。
link |
今天這個,如果你是用這樣子 gradient ascent 的方法來處理這個 continuous 的 problem,等於是你每次要決定要 take 哪一個 action 的時候,你都還要做一次 train network 的 process。
link |
這個顯然運算量是很大的,這是第二個 solution。
link |
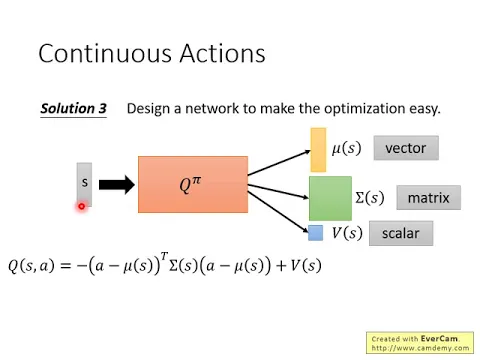
那第三個 solution 呢,就是有點神奇,第三個 solution 是特別 design 一個 network 的架構,特別 design 你的 Q-function,使得解那個 argmax 的 problem 變得非常容易。
link |
有時候這邊的 Q-function 不是一個 general Q-function,特別設計一下它的樣子,讓你要找哪一個 A 可以讓這個 Q-function 最大的時候非常容易。
link |
那這邊是一個例子,這邊有我們的 Q-function,這個 Q-function 它的做法是這樣,input 一個 S,input 你的 state S,它就是一個 image,它可以用一個向量或者是用一個 matrix 來表示。
link |
input 這個 S,這個 Q-function 會 output 三個東西,它會 output mu of S,這是一個 vector,它會 output sigma of S,sigma of S 是一個 matrix,它會 output V of S,這邊 V of S 是一個 scalar。
link |
output 這三個東西以後,我們知道說 Q-function 其實是吃一個 S 跟 A,然後決定一個 value,對不對?
link |
Q-function 意思是說在某一個 state,某一個 action 的時候,你 expect 的 reward 多大?到目前為止,這個 Q-function 只吃 S,它還沒有吃 A 進來。
link |
A 在哪裡呢?當這個 Q-function 吐出 mu, sigma 跟 V 的時候,我們才把 S 引入,用 A 跟這三個東西互相作用一下,你才算出最終的 Q-value。
link |
A 怎麼和這三個東西互相作用呢?它的作用方法就寫在下面這個地方。所以實際上 Q-function 的運作方式是先 input S,讓你得到 mu, sigma 跟 V,然後再 input A,然後接下來的計算方法是把 A 跟 mu 相減。
link |
注意一下,A 現在是 continuous action,所以它也是一個 vector,假設你這樣當作機器人的話,這個 vector 的每一個 dimension 可能就對應到機器人的某一個關節,它的數值就是那個關節的角度,所以 A 是一個 vector。
link |
你把 A 的這個 vector 減掉 mu 的這個 vector 去 transpose,所以它是一個橫的 vector,它是倒下來的 vector,然後 sigma 是一個 matrix,然後 A 減掉 mu,這兩個都是 vector,減掉以後還是一個數的 vector。
link |
接下來,你把這個 vector 乘上這個 matrix 再乘上這個 vector,你得到的是什麼?你得到的是一個 scalar 對不對?你得到的是一個 scalar 對不對?有學過線性代數的人都知道。把這個 scalar 再加上 P of S 得到另外一個 scalar,這個數值就是你的 Q of S A,就是你的 Q-value。
link |
接下來,假設我們的 Q of S A 定義成這個樣子,我們要怎麼找到一個 A 去 maximize 這個 Q-value 呢?其實這個 solution 非常簡單,因為我們把 formulation 寫成這樣。
link |
那什麼樣的 A 可以讓這個 Q-function 最終的值最大呢?什麼樣的 A 可以讓這個 Q-function 最終的值最大呢?因為這邊這一項,這個 A 減 mu 乘 sigma,再乘上 A 減 mu 這一項,一定是正的,前面乘上一個負號。
link |
所以第一項,就假設我們不要看這個負號的話,第一項這個值越小,你的最終的 Q-value 就越大。因為我們是把 V 減掉第一項,所以第一項,假設不要看這個負號的話,第一項的值越小,最後的 Q-value 就越大。
link |
怎麼讓第一項的值最小呢?你直接把 A 代 mu 讓它變零,就會讓第一項的值最小。這樣大家有問題嗎?你寫錯,怎麼寫錯啊?它是一個 matrix。
link |
哦,你這個問題問得很好,假設它不是正定的,比如說如果它不是正定的話,它有可能會出現 negative 的 value。對,其實有假設它是正定的。
link |
這邊少講一個東西,因為你知道這個東西就像是那個 Gaussian 的 distribution,所以 mu 就是 Gaussian 的 mean, sigma 就是 Gaussian 的 variance,但是 variance 是一個 positive definite 的 matrix。
link |
所以其實怎麼樣讓這個 sigma 一定是 positive definite 的 matrix 呢?其實在 Qπ 裡面,它不是直接 output sigma,如果直接 output 一個 sigma,它可能不見得是 positive definite 的 matrix。
link |
它其實是 output 一個 matrix,然後再把那個 matrix 跟另外一個 matrix 做 transpose 相乘,然後可以確保它是 positive definite 的,就是這樣。所以這邊確實是漏講了一塊。
link |
感謝你有特別提出來,等一下問一下你叫什麼名字。所以這樣大家聽得懂嗎?大家還有什麼問題嗎?所以這邊要強調一點就是說,實際上它不是直接 output 一個 matrix,它其實不是 output 一個 matrix。
link |
你再去那個 paper 裡面 check 一下它的 tree,它可以保證說 sigma 是 positive definite 的。所以今天前面這一項,因為 sigma 是 positive definite,所以它一定是正的。
link |
所以現在怎麼讓它值最小呢?你就把 a 代 mu of s,今天把 a 代 mu of s,而你把 a 代 mu of s 以後,你可以讓 Q 的值最大,所以這個 problem 就解了。
link |
ARQmax 這個東西,雖然 in general 而言,如果 Q 是一個 general function 你很難算,但是我們這邊 specifically design 了這個 Q 的 function,所以 a 只要設 mu of s,那我們就得到 maximum 的 value,你在解這個 ARQmax 的 problem 的時候就變得非常的容易。
link |
所以其實 Q learning 也不是不能夠用在 continuous case,是可以用的,只是有一些局限,你的 function 就不能夠隨便亂設,它必須有一些限制。
link |
剛才那個方法其實用在 robotics 上面看起來是可以得到一些不錯的結果,這個是文獻上的例子,就是用 Q learning 來 learn 這個機械手臂。
link |
後面有另外一個機器人,兩個人一起學。
link |
我們知道雖然有個 buffer,但是兩個人一起學 buffer 就比較快。
link |
我們知道雖然有個 buffer,但是兩個人一起學 buffer 就比較快。
link |
我們知道雖然有個 buffer,但是兩個人一起學 buffer 就比較快。
link |
我們知道雖然有個 buffer,但是兩個人一起學 buffer 就比較快。
link |
我們知道雖然有個 buffer,但是兩個人一起學 buffer 就比較快。
link |
第四招就是不要用 Q learning,用 Q learning 處理 continuous 的 action 還是比較麻煩的。
link |
到目前為止,我們講了 policy based 的方法,我們講了 PTO,這是上上週講的。
link |
上週講了 value based 的方法,也就是 Q learning。
link |
但是這兩者其實是可以結合在一起的,也就是 activated 的方法。