back to index
DRL Lecture 7: Sparse Reward
link |
我們稍微講一下Sparks reward的problem,然後再下課。Sparks reward是什麼意思呢?實際上,當我們在認agent的時候,多數的時候,agent都是沒有辦法得到reward的。
link |
在沒有辦法得到reward的情況下,對agent來說,他的訓練是非常困難的。舉例來說,假設你今天要訓練一個機器手臂,桌上有一個螺絲釘跟螺絲起子,你要訓練他用螺絲起子把螺絲釘栓進去。
link |
這個很難,為什麼?因為你知道,一開始你的agent是什麼都不知道的,他唯一能夠做不同的action的原因是因為exploration。舉例來說,你在做Q-learning的時候,你會有一些隨機性,讓他去採取一些過去沒有採取過的action。
link |
你要隨機到說,他把螺絲起子撿起來,再把螺絲栓進去,然後就會得到reward1,這件事情是永遠不可能發生的。所以你會發現說,不管今天你的agent他做了什麼事情,他得到的reward永遠都是零。
link |
對他來說,不管採取什麼樣的action,都是一樣糟或者是一樣好的,所以他最後什麼都不會學到。所以,今天如果你環境中的reward非常的Sparks,那這個reinforcement learning的問題就會變得非常的困難。
link |
但是對人類來說,人類很厲害,人類可以在非常Sparks的reward上面去學習,就我們的人生通常多數的時候我們就只是活在那裡,都沒有得到什麼reward或者是penalty,但是人還是可以採取各種各式各樣的行為。
link |
所以一個真正厲害的人工智慧,他應該能夠在Sparks reward的情況下也學到要怎麼跟這個環境互動。所以接下來我想要跟大家很快地、非常簡單地介紹的,就是一些handleSparks reward的方法。
link |
在這個作業四之三裡面,除了要做equity以外,你就會要求大家做equity,然後比較一下說,你現在的equity如果做在四之二上有沒有比較好,如果做在四之一上有沒有比較好,當然希望應該是要有比較好啦。
link |
然後接下來會希望你implement某一個方法來再improve你的model。那這個方法是什麼呢?你就自己決定,你不一定要implement很難的方法,你就看你自己想要做什麼。
link |
HandleSparks reward的方法,你就看看說裡面有沒有是你用得上的。我們會講imitation learning的方法,看你要不要做一下imitation learning,你可以給你的agent一些示範,看看他能不能夠學得比較好等等。你就想一個你喜歡的方法來improve你的model。
link |
好,那怎麼解決Sparks reward的這件事情呢?我們等一下會講三個方向。我們先講第一個方向,第一個方向是非常容易理解的,第一個方向叫做reward shaping。
link |
reward shaping是什麼意思呢?reward shaping的意思是說,環境有一個固定的reward,它是真正的reward,但是我們為了引導machine,為了引導agent,讓它學出來的結果是我們要的樣子,這個developer,就是我們人類,刻意地去設計了一些reward來引導我們的agent。
link |
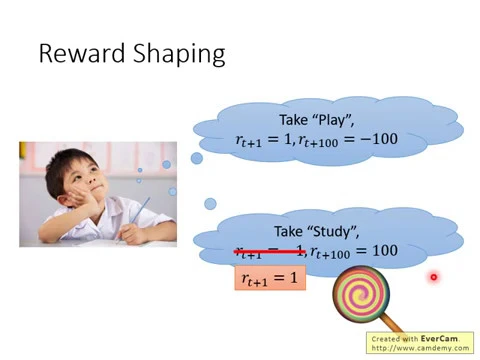
舉例來說,如果是把人類當作agent,把小孩當作一個agent的話,就一個小孩,他現在可以take兩個action,一個action是他可以出去玩,他出去玩的話,在下一秒鐘他會得到reward1,但是他可能在月考的時候成績會很差,所以在一百個小時之後他會得到reward-100,然後他也可以決定他要念書,然後在下一個時間,因為他沒有出去玩,所以他覺得很不爽,所以他得到reward-1,但是在一百個小時之後他可以得到reward-100。
link |
但是對一個小孩來說,他可能就會想要take a play,而不是take a study,因為今天雖然說我們計算的是accumulated reward,但是也許對小孩來說,他的discounting factor的值很大,所以未來的reward,他是覺得不太在意未來的reward,而且也許因為他是個小孩,他還沒有很多experience,所以他的q-function的estimate是非常不精準的,
link |
所以要他去estimate很遙遠以後會得到的accumulated reward,他其實是預測不出來的,所以怎麼辦呢?這個時候大人就要引導他,怎麼引導他?就騙他說,如果你坐下來念書,我就給你吃一個棒棒糖。
link |
所以對他來說,下一個時間點會得到的reward就變成是positive的,他就覺得說,也許take這個study是比play好的,雖然實際上這並不是真正的reward,而是其他人去騙他的reward,告訴他說,你採取這個action是好的,所以我給你一個reward,雖然這個不是環境真正的reward。
link |
所以reward shaping的概念是一樣的,簡單來說就是你自己想辦法design一些reward,所以它不是環境真正的reward,比如在玩atari遊戲裡面,真正的reward是那個遊戲的主機給你的reward,但是你自己去設一些reward,好引導你的machine做你想要它做的事情。
link |
舉例來說,這個例子是Facebook玩Viston的agent,Viston是一個第一人稱射擊遊戲,在這個射擊遊戲裡面,基本上你殺了敵人就得到positive reward,你被殺就得到negative reward,但是如果你看一下他們的paper的話,他們其實小心地在設計了一些新的reward,用這些新的reward來引導他們的agent去做得更好,所以這個並不是遊戲中真正的reward。
link |
舉例來說,我們先不要看第一個,比如說你掉血你就扣0.05的分數,這個很正常,為什麼會加這個reward呢?因為假如說要死了才會得到negative reward,這時間太久了,你可能玩很久才會死,但如果掉血就扣分,那agent就會學到說盡量不要掉血。
link |
而這個是什麼呢?這個是如果彈藥減少就扣分,而這個是說如果撿到補給包就可以加分,因為假設今天只有活著才有加分的話,撿到補給包這件事情對agent來說是不一定可以得到reward,就是他撿到補給包,他可能很久以後才會發現說這個補給包跟他接下來的存活有沒有關係,所以你就直接告訴agent說撿到補給包是有加分的,撿到彈藥是有加分的。
link |
而這個是說這個是扣分,這是什麼?如果agent一直待在原地他就會扣分,因為他就不做事嘛,因為其實待在原地就短程來說還是有用,因為隨便走走很容易被敵人殺死,你躲在角落反而做一個邊緣人海比較不會那麼容易被殺死。
link |
所以今天為了讓agent能自動去尋找敵人,所以如果他一直待在原地的話是扣分的。這邊也有一個是說如果agent動的話他也是加分的,給他一個很小的分數。
link |
第一個有一個有趣的是說,他其實活著是會被扣一個很小的分數的。為什麼活著會被扣一個很小的分數呢?我猜疆這個的原因可能是因為,假設Machine現在只想活著,他就不去殺敵人,他會一直躲避敵人,他就在這個環境裡面胡亂一直躲在角落,都不出去迎戰,這個遊戲就會玩不下去。
link |
所以如果他一直活著,不出去決戰的話,反而是會被扣分的,所以故意把這個reward加上去,強迫Machine變得比較好戰一點。
link |
所以你說為什麼這個是0.05,為什麼不是0.053呢?這顯然是調出來的,懂嗎?這個你就是要去調它,讓你的agent做出來的事情是你想要的樣子。
link |
另外一個例子是OpenAI舉的一個例子,這個例子是想要表達說,reward shaping有時候是會有問題的,因為你需要domain knowledge。
link |
舉例來說,他們現在想要機器人學會的事情是,把這個藍色的板子從這個柱子穿過去,機器人怎麼學都學不會,這個很難。
link |
那你接下來可能會做一些reward shaping,一個乍聽之下很合理的reward shaping的方式是說,只要那個藍色的板子越靠近中間的柱子,那得到的reward就越大。
link |
但是你的問題是,今天機器人可能確實可以學到說,把藍色的板子靠近柱子,但是他是這樣靠近的,他拿藍色板子去打那個柱子。
link |
但是要把藍色板子拿到柱子上面去,才能夠把這個藍色的板子從上面滑下來。所以,今天光是設定說讓藍色板子越接近柱子而言,這種reward shaping的方法是沒有幫助的。
link |
至於什麼樣reward shaping有幫助,什麼樣reward shaping沒有幫助,就變成是一個domain knowledge,是你要去調的。
link |
所以接下來就是介紹各種你可以自己加進去,然後in general看起來是有用的reward。
link |
舉例來說,一個技術是給你機器人加上curiosity,給他加上好奇心,這叫curiosity-fever的reward。
link |
這個是我們之前講anticipated的時候看過的圖,我們有一個reward function,他給你某一個state,給你某一個action,他就會評斷說在這個state還比這個action得到多少reward,那我們當然是希望total reward越大越好。
link |
在curiosity-driven的這種技術裡面,你會加上一個新的reward function,這個新的reward function叫做ICM,intrinsic curiosity module,他就是要給機器人加上好奇心。
link |
而這個ICM他會吃三個東西,他會吃state S1,他會吃action A1跟state S2,根據S1、A1跟A2,他會output另外一個reward,我們這邊叫做R1i。
link |
那最後你的total reward對機器人來說,total reward並不是只有R而已,還有Ri,他不是只有把所有的R都加起來,他還把所有的Ri加起來當作total reward。
link |
所以他在跟環境互動的時候,他不是只希望R越大越好,他還同時希望Ri越大越好,他希望從ICM的module裡面得到的reward越大越好。
link |
那這個ICM他就代表了一種curiosity,那怎麼設計這個ICM讓他有類似這種好奇心的功能呢?這個是最原始的設計,這個設計是這樣。
link |
我們說curiosity的module就是input三個東西,input現在的state,input在這個state採取的action,然後接下來input下一個state,Sti,然後接下來會output一個reward,Ri。
link |
那這個Ri怎麼算出來的呢?在ICM裡面你有一個network,這個network會take at跟St,然後去outputSti,也就是這個network做的事情是根據at跟Sti去predict接下來我們會看到的Sti,也就是根據現在的state跟在現在這個state採取的action,我們有另外一個network去預測接下來會發生什麼事。
link |
接下來再看說machine自己的預測,這個network自己的預測跟真實的情況像不像,越不像,那越不像,那得到的reward就越大。
link |
所以今天這個reward它的意思是說,如果今天未來的state越能被預測的話,那得到的reward就越大,這就是鼓勵machine去冒險。現在採取這個action,未來發生什麼事,越沒有辦法預測的話,那採取這個action的reward就越大。
link |
所以machine如果有這樣子的intrinsic curiosity的module,它就會傾向於採取一些它風險比較大的action,它想要去探索未知的世界,它想要去看看說,假設某一個state是它沒有辦法預測,假設它沒有辦法預測未來會發生什麼事,它會特別去想要採取那種state,可以增加machine exploration的能力。
link |
那這邊這個network 1其實是另外train出來的,大家了解我的意思嗎?這個training的時候,你這個network 1它就是在training的時候,你會給它at、st跟st加1,然後讓這個network 1去學說,given at跟st怎麼predict,st加1,
link |
apply到action互動的時候,這一個intrinsic curiosity的module,其實會把它fix住。
link |
好,如果大家知道我的意思的話,其實這一整個想法裡面是有一個問題的,這個問題是什麼呢?這個問題是,某一些state它很難被預測,並不代表它就是好的,它就應該要去被嘗試的。舉例來說,俄羅斯輪盤的結果也是沒有辦法預測的,並不代表說人應該要每天去玩俄羅斯輪盤這樣。
link |
所以今天光是告訴machine、鼓勵machine去冒險是不夠的,因為如果光是只有這個network架構,machine只知道說什麼東西它無法預測,如果在某一個state採取某一個action,它無法預測接下來的結果,它就會採取那個action。
link |
但並不代表這樣的結果一定是好的。舉例來說,可能在某個遊戲裡面,背景會有風吹草動,會有樹葉飄動,也許樹葉飄動這件事情是很難被預測的。
link |
對machine來說,它在某一個state什麼都不做,看著樹葉飄動,然後發現這個樹葉飄動是沒有辦法預測的,接下來它就一直站在那邊看樹葉飄動。
link |
所以說光是有好奇心是不夠的,還要讓它知道說什麼事情是真正重要的。那怎麼讓machine真的知道說什麼事情是真正重要,而不是讓它只是一直看樹葉飄動呢?
link |
你要加上另外一個module,我們要認一個feature的attractor,這個黃色的格子代表feature的attractor,它是input一個state,然後output一個feature vector代表這個state。
link |
我們現在期待的是,這個feature的attractor可以做的事情是把那種沒有意義的state裡面沒有意義的東西把它濾掉,比如說風吹草動、白雲的飄動、樹葉的飄動這種沒有意義的東西直接把它濾掉。
link |
我們希望這個feature的attractor可以做到這個功能,我們等一下再講說這件事情是怎麼做到的。
link |
假設這個feature的attractor真的可以把無關緊要的東西濾掉以後,那我們的network1實際上做的事情是給它一個attractor,給它一個state s1的feature representation,讓它預測state s7加1的feature representation。
link |
然後接下來我們再看說這個預測的結果跟真正的state s7加1的feature representation像不像,越不像reward就越大。
link |
接下來的問題就是,怎麼認這個feature的attractor呢?怎麼認這個feature的attractor讓這個feature的attractor它可以把無關緊要的事情濾掉呢?
link |
這邊的認法就是認另外一個network2,這個network2它是吃這兩個vector當作input,然後接下來它要predict action a是什麼。
link |
然後它希望這個action a跟真正的action a越接近越好,我突然發現我的地方寫的其實沒有很對,你有發現嗎?
link |
不對,這個a跟a hat我應該要反過來吧,預測出來的東西我們用hat來表示,真正的東西沒有hat,應該是這樣感覺比較對啦,所以at跟at hat應該是反過來的。
link |
所以這個network2它會output一個action,就根據state s7的feature跟state s7加1的feature,它output說從state s7跳到state s7加1要採取哪一個action才能做到,希望這個action跟真正的action越接近越好。
link |
那加上這個network的好處就是,因為這兩個東西要拿去預測action,所以今天我們抽出來的feature就會變成是跟預測action這件事情是有關的。
link |
所以假設是一些無聊的東西,是跟machine本身採取的action無關的東西,風吹草動或者是白雲飄過去,是跟machine自己要採取的action無關的東西,那就會被濾掉,就不會被放在這個抽出來的feature的representation裡面。
link |
好,那我們就先休息一下,我們十分鐘以後再回來,我們來上課吧。
link |
第二,剛才講的是reward shaping的方法,接下來我們要講curricular learning這件事情。
link |
curricular learning不是reinforcement learning所獨有的概念,其實在很多machine learning,尤其是deep learning裡面,你都會用到curricular learning的概念。
link |
舉例來說,curricular learning的意思是說,你為機器的學習做規劃,你給它weight training data的時候是有順序的。
link |
通常都是由簡單到難,就好比說,假設你今天要教一個小朋友做微積分,然後他做錯就打他一巴掌,可是他其實永遠都不會做對,因為太難了,你要先教他久久懲罰,然後再教他微積分,所以他打死他,他都學不起來,所以很難。
link |
curricular learning的意思就是,在教機器的時候,從簡單的題目教到難的題目。那如果不是reinforcement learning,一般在training deep network的時候,你有時候也會這麼做。
link |
舉例來說,在training R&N的時候,已經有很多的文獻都report說,你給機器先看短的sequence,再慢慢給它越來越長的sequence,通常可以學得比較好。
link |
而那用在reinforcement learning裡面,你就是要幫機器規劃一下它的課程,從最簡單的到最難的。舉例來說,在Facebook的Viston那個遊戲,在Facebook玩Viston的agent裡面,
link |
Facebook那個Viston的agent據說蠻強的,他們在參加這個Viston的比賽,機器Viston的比賽是得了第一名的。他們是有為機器規劃課程的,先從課程0一直上到課程7。
link |
在那個課程裡面,那些怪就是有不同的speed跟health,就怪物的速度跟血量是不一樣的。所以在越進階的課程裡面,怪物的速度越快,然後它的血量越多。
link |
在Payment裡面也有講說,如果直接上課程7,Machine是學不起來的,你就是要從課程0一路往上去,這樣Machine才學得起來。
link |
所以在拿剛才把藍色的板子放到柱子上的實驗,那怎麼讓機器由簡單一直學到難呢?
link |
也許一開始你讓機器初始的時候,它的板子就已經在柱子上了,這個時候你要做的事情只有把這時候機器要做的事情圍繞做的事情之後把藍色的板子壓下去,就結束了。
link |
這個比較簡單,它應該很快就可以學得會,因為它從往上跟往下這兩個選擇,往下就得到reward,就結束了,它比較學得起來。
link |
這邊是把板子挪高一點,所以有時候它會很笨的往上拉,然後板子反而拿出來了,如果它這個學得會的話,那這個也比較有機會學得會。
link |
那假設它現在學得到說,只要板子接近柱子,它就可以把這個板子壓下去的話,接下來你再讓它學更general的case,先讓它一開始板子離柱子遠一點,然後等板子放到柱子上面的時候,它就會知道把板子壓下去。
link |
這個就是curriculum learning的概念,當然curriculum learning這邊有點A-hart,就是你需要人當作老師去為機器設計它的課程,一個比較general的方法叫做reversed curriculum generation,你可以用一個比較通用的方法來幫機器設計課程。
link |
這個比較通用的方法是怎麼樣呢?假設你現在一開始有一個state,SG,這是你的goal state,也就是最後最理想的結果,如果是拿剛才板子和柱子的例子的話,就把板子放到柱子裡面,這樣子叫做goal state。
link |
已經完成了,讓機器去抓東西,你訓練一個機械手臂抓東西,抓到東西以後叫做goal state。接下來,你根據你的goal state去找其他的state,這些其他的state跟goal state是比較接近的。
link |
舉例來說,如果是機器抓東西的例子裡面,你的機器手臂可能還沒有抓到東西,假設這些跟goal state很近的state我們叫做S1,你的機械手臂還沒有抓到東西,但是它離goal state很近,這個叫做S1。
link |
至於什麼叫做近,這個就麻煩,就是case dependent,你要根據你的test來design說怎麼從SGsample出S1,如果是機械手臂的例子可能比較好想,其他例子可能就比較難想。
link |
接下來,你再從這些state 1開始做互動,看它能不能夠達到goal state SG,每一個state你跟環境做互動的時候,你都會得到一個reward R。接下來,我們把reward特別極端的case去掉。
link |
reward特別極端的case的意思就是說,那些case太簡單或者太難,reward如果很大,代表說這個case太簡單了,就不用學了,因為機器已經會了,可以得到很大的reward。
link |
而reward如果太小,代表這個case太難了,依照機器現在的能力,這個課程太難了,它學不會,所以就不要學這個。
link |
所以只找一些reward適中的case,那當然什麼叫做適中,這個就是你要調個參數嘛,找一些reward適中的case。
link |
而接下來,再根據這些reward適中的case,再去sample出更多的state。假設你一開始,你的東西在這裡,你機器的手臂在這邊,可以抓得到以後,那接下來就再離遠一點,看看能不能夠抓得到。
link |
又抓得到以後,再離遠一點,看看能不能抓得到。這個方法很直覺,但是它是一個有用的方法就是了,這個叫做reverse curriculum learning。
link |
當然講的是curriculum learning,就是你要為機器規劃它學習的順序。
link |
最後一個要跟大家講的tip,叫做hierarchical reinforcement learning,有階層式的reinforcement learning。
link |
請說,請說。沒有,因為他說從goal state去反推,就是說你原來的目標是長這個樣子,我們從我們的目標去反推,所以這個叫做reverse。
link |
接下來要講階層式的reinforcement learning,所謂階層式的reinforcement learning是說,我們有好幾個agent,有一些agent負責比較high level的東西,他負責定目標,他定完目標以後,再分配給其他的agent去把它執行完成。
link |
這樣的想法其實也是很合理的,因為我們知道說,我們的人在一生之中並不是時時刻刻都在做決定。
link |
舉例來說,假設你想要寫一篇paper,那你會先想說,我要寫一篇paper的時候,我要做哪些process,比如說先想個梗,先想完梗以後,你還要跑個實驗,跑完實驗以後你還要寫,寫完以後你還要去發表。
link |
那每一個動作下面又還會再細分,比如說怎麼跑實驗呢?你要先collect data,collect完data以後,你要再label,你要弄個network,然後又勸不起來,要勸很多次,然後重新定在network架構好幾次,最後才把network勸起來。
link |
所以其實我們要完成很大的task的時候,我們並不是從非常底層的那些action開始想起,我們其實是有一個plan,我們先想說,如果要完成這個最大的任務,那接下來要拆解成哪些小任務,每一個小任務要再怎麼拆解成小小的任務,這個是我們人類做事情的方法。
link |
舉例來說,叫你直接寫一本書可能很困難,但叫你先把一本書拆成好幾個章節,每個章節拆成好幾段,每段又拆成好幾個句子,每個句子拆成好幾個詞彙,那你可能就比較寫得出來。
link |
那這個就是階層式的reimbursement learning的概念,這邊是隨便舉一個好像很不恰當的例子,就是說假設校長跟教授跟研究生通通都是agent,那今天假設我們的reward就是只要進入百大就可以得到reward。
link |
那假設校長進入百大的話,校長就要提出願景,告訴其他的agent說,現在你要達到什麼樣的目標,那校長的願景可能就是說,教授每年都要發三篇期刊。
link |
然後接下來,這些agent就是有階層式的,所以上面的agent,他的action,他所提出的動作,他不真的做事,他的動作就是提出願景,然後他把他的願景傳給下一層的agent,下一層的agent就把這個願景吃下去。
link |
如果他下面還有其他人的話,他就會提出新的願景,比如說校長要教授發期刊,但是其實教授自己也是不做實驗的,所以教授也只能夠叫下面的研究生做實驗。
link |
所以教授就提出願景,做出實驗的規劃,而研究生才是真的去執行這個實驗的人,然後真的把實驗做出來,然後最後大家就可以得到reward。
link |
這個例子其實有點差,為什麼說這個例子有點差呢?因為真實的情況是,校長其實是不會管這些事情的,我說校長會不會管教授發期刊,而且發期刊跟進入百大其實關係也不大。
link |
而且更退一步說好,我們現在是沒有校長的,所以現在根本就不是指臺大。所以這是虛構的故事,我隨便亂編的,沒有很恰當。
link |
現在是這樣子的,在認的時候,其實每一個agent都會認,他們整體的目標就是要達到最後的reward。
link |
前面的這些agent,他提出來的action就是願景,比如說如果是玩遊戲的話,他提出來的就是我現在想要產生這樣的遊戲畫面,下面的人能不能夠做到這件事情,上面的人就是提出願景。
link |
但是假設他提出來的願景是下面的agent達不到的,那就會被討厭,比如說如果教授對研究生都一直逼迫研究生做一些很困難的實驗,研究生都做不出來的話,研究生就會跑掉,所以他就會得到一個penalty。
link |
所以如果今天下層的agent沒有辦法達到上層的agent所提出來的goal的話,那上層的agent就會被討厭,他就會得到一個negative的reward,所以他要避免提出那些願景是底下的agent所做不到的。
link |
每一個agent都是吃上層的agent所提出來的願景當作輸入,然後決定他自己要產生什麼輸出。但是你知道說,就算你看到了上面的願景說叫你做這件事情,你最後也不見得做得到這件事情,對不對?
link |
假設本來教授的目標是要寫期刊,但不知道怎麼回事,他就變成一個YouTuber這樣子。至於這個黑盆裡面的solution,我覺得真的非常有趣,這給大家人生做一下參考。
link |
就是其實本來的目標是要寫期刊,但是卻變成YouTuber,那怎麼辦呢?把原來的願景就改成變成YouTuber,就結束了,在黑盆裡面就是這麼做的。
link |
為什麼要這麼做呢?因為現在雖然本來的願景是要寫期刊,但後來變成YouTuber,那難道這些動作就浪費了嗎?不是,這些動作是沒有被浪費的。
link |
我們就假設說本來的願景其實就是要成為YouTuber,這樣你就知道說成為YouTuber要怎麼做了。
link |
這個是細節我們就不講,你自己去研究一下黑盆,這個是階層式IL可以做得起來的一個tip。
link |
這個是真實的例子,真實的例子就是給大家參考一下,實際上在裡面就做了一些比較簡單的遊戲,比如說這個是走迷宮,藍色的是agent,藍色的agent要走走走,走到黃色的目標。
link |
這邊也是,你的agent是單白,單白要碰到黃色的球。願景是什麼呢?在這個task裡面它只有兩個agent,只有下面的一個最底層的agent負責執行決定說要怎麼走,然後還有一個上層的agent負責提出願景。
link |
雖然實際上以general而言可以有很多層,但黑盆我看那個實驗主要就是兩層。今天這個例子是說,粉紅色的這個點代表的就是願景,上面那個agent告訴藍色的agent說,你現在的第一個目標是先走到這個地方,藍色的agent走到以後再說你的新的目標是走到這裡,藍色的agent再走到以後,新的目標在這裡,接下來要跑到這邊,最後希望藍色的agent就可以走到黃色的位置。
link |
這邊也是一樣,粉紅色的這個點代表的是目標,代表的是上層的agent所提出來的願景,所以這個agent先擺到這邊,接下來新的願景就跑到這邊,所以它要擺到這裡,新的願景就跑到上面,然後擺到上面,最後就走到黃色的位置。
link |
這個就是Hierarchical的reinforcement learning。