back to index
DRL Lecture 8: Imitation Learning
link |
我們接下來要講的是假設學習。假設學習又更進一步要討論的問題是,假設我們今天連獎勵都沒有,那要怎麼辦才好呢?
link |
假設學習又叫做learning by demonstration,或者叫做apprenticeship learning,apprenticeship這個字是學徒的意思。
link |
在這個imitation learning裡面,你的setup是這樣子的,你有一些expert的demonstration,那machine也可以跟環境互動,但它沒有辦法從環境裡面得到任何的reward,它只能夠看著expert的demonstration來學習什麼是好,什麼是不好。
link |
為什麼有時候我們會沒有辦法從環境得到reward呢?其實多數的情況,我們都沒有辦法真的從環境裡面得到非常明確的reward。
link |
舉例來說,如果今天是棋類遊戲或者是電玩,你有非常明確的reward,那其實多數的任務都是沒有reward的。
link |
舉例來說,你說開自駕車,雖然說自駕車我們都知道撞死人不好,但是撞死人應該扣多少分數,這個你沒有辦法定出來,而撞死人的分數跟撞死一個動物的分數顯然是不一樣的,但你也不知道要怎麼定。
link |
所以這個問題很難,你根本不知道怎麼定reward。
link |
或者是chatbot也是一樣,今天機器跟人聊天,聊得怎麼樣算是好,聊得怎麼樣算是不好,你也無法決定。
link |
所以很多task,你是根本就沒有辦法定出reward的。但是雖然沒有辦法定出reward,但是收集expert的demonstration是可能可以做到的。
link |
舉例來說,在自駕車裡面,雖然你沒有辦法定出自駕車的reward,但收集很多人類開車的記錄,這件事情是可行的。
link |
在chatbot裡面,你可能沒有辦法收集到太多,你可能沒有辦法真的定義什麼叫做好的對話,什麼叫做不好的對話,但是收集很多人的對話當作範例,這件事情也是可行的。
link |
所以今天imitation learning其實它的實用性非常高,假設你今天有一個狀況是你不知道該怎麼定reward,但是你可以收集到expert的demonstration,
link |
你可以收集到一些範例的話,你可以收集到一些很厲害的agent,比如說人,跟環境實際上的互動的話,那你就可以考慮用imitation learning這個技術。
link |
好,那這個在imitation learning裡面,我們等一下就是介紹兩個方法,第一個叫做behavioral cloning,第二個叫做inverse reinforcement learning,或者又叫做inverse optimal control。
link |
我們先來講behavioral cloning。其實behavioral cloning跟supervised learning是一模一樣的。舉例來說,我們以自駕車為例,今天你可以收集到人開自駕車的時候的資料,
link |
比如說人類的駕駛就是收集人的行車記錄器,在看到這樣子的observation的時候,人會決定向前,那機器就採取跟人一樣的行為,也採取向前,也踩個油門,就結束了。
link |
這個就叫做behavioral cloning,expert做什麼,人就做一模一樣的事。不是人做一模一樣的事,機器就做一模一樣的事,expert做什麼,機器就做一模一樣的事。
link |
那怎麼讓機器學會跟expert一模一樣的行為呢?你就把它當作一個supervised learning的問題,你去收集很多自駕車,你去收集很多行車記錄器,然後再收集人在那個情境下會採取什麼樣的行為。
link |
你知道說,人在state S1會採取action A1,人在state S2會採取action A2,人在state S3會採取action A3,接下來你就learn一個network,這個network就是你的expert,他input SI的時候,你就希望他的output是AI,就這樣結束,他就是一個非常單純的supervised learning的product。
link |
那behavior cloning雖然非常簡單,但是它有什麼樣的問題呢?它的問題是,今天如果你只收集expert的資料,你可能看過的observation會是非常limited的。
link |
舉例來說,假設你要看另一部自駕車,自駕車就是要過這個彎道,如果是expert的話,你找人來,不管是找多少人來,他就是把車順著這個紅色線就開過去了。
link |
但是今天假設你的agent很笨,他今天開著開著不知道怎麼回事,就快要撞牆了,他會永遠不知道撞牆的這種狀況會怎麼處理,為什麼?
link |
因為training data裡面從來沒有撞過牆啊,所以他根本就不知道撞牆這種case要怎麼處理。
link |
或者是打電玩也是一樣,假設你讓機器看著人去玩mario,那可能expert非常的強,他從來不會跳不上水管,所以機器根本不知道跳不上水管的時候要怎麼處理。
link |
但是機器,就是人從來不會跳不上水管,但機器他今天如果跳不上水管的時候,他就不知道要怎麼處理,所以今天光是做behavior cloning是不夠的,光是只觀察expert的行為是不夠的。
link |
需要一個招數,這個招數叫做data的application,我們會希望收集更多樣性的data,而不是只有收集expert所看到的observation。
link |
我們會希望能夠收集expert在各種極端的情況下,他會採取什麼樣的行為。
link |
如果以自駕車為例的話,那就是這樣,假設一開始你的actor叫做policy pi1,接下來你讓policy pi1真的去開這個車,但是車上做了一個expert。
link |
這個expert會不斷地做記錄說,如果今天在這個情境裡面,我會怎麼樣開。所以今天policy pi1,machine自己開自己的,但是expert會不斷地表示他的想法。
link |
比如說在這個時候,expert可能說那就往前走,這個時候expert可能就會說那往右轉,但是pi1是不管expert的指令的,所以他會繼續去撞牆。
link |
然後expert雖然說要一直往右轉,但他不管怎麼下指令都是沒有用的,pi1會自己做自己的事情。
link |
因為我們要記錄的是說,今天expert在pi1所會看到的這種observation的情況下,他會做什麼樣的反應。
link |
這個方法顯然是有些問題的,因為每次你開一次自駕車,都會犧牲一個人,但你用這個方法,你犧牲了一個expert以後,
link |
你就會得到說人類在這樣子的state下,在快要撞牆的時候,會採取什麼樣的反應。
link |
然後你再把這個data拿去train新的policy pi2,然後這個process就反覆繼續下去。
link |
而這個方法叫做data的aggregation。
link |
那behavior cloning這件事情會有什麼樣的issue呢?
link |
還有一個issue是說,今天機器會完全copyexpert的行為,不管今天expert的行為有沒有道理,就算沒有道理,也沒有什麼用的,只是expert本身的習慣,機器也會硬把它記下來。
link |
這個跟那個是沒有半毛錢的關係,我怎麼會沒有辦法放呢?我看一下,我可以幫我查一下嗎?
link |
请不吝点赞 订阅 转发 打赏支持明镜与点点栏目
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
整理&字幕由Amara.org社区提供
link |
就是你有一个跟你互动的环境,然后你有一个reward function,然后根据环境的reward function,透过reinforcement learning这个技术,你会找到一个actor,你会认出一个optimal的actor。
link |
那inverse reinforcement learning刚好是相反的,你今天没有reward function,你只有一堆expert的demonstration,但你还是有环境。
link |
那inverse reinforcement learning的做法是说,假设我们现在有一堆expert的demonstration,那这边我们用这个towhead来代表expert的demonstration。
link |
如果今天是在玩电玩的话,每一个tow就是一个很会玩电玩的人,他玩一场游戏的记录,如果是自驾车的话,那就是人开自驾车的记录,如果只有人开车的记录,这些就是expert的demonstration。
link |
每一个tow是一个trajectory,你现在把所有的trajectory,expert的demonstration的trajectory收集起来,然后使用inverse reinforcement learning这个技术。
link |
在使用inverse reinforcement learning这个技术的时候,机器是可以跟环境互动的,但是它得不到reward,它的reward必须要从expert那边推了出来。
link |
现在有了环境,有了expert的demonstration以后,去反推出reward function长什么样子?之前reinforcement learning是有reward function,反推出什么样的action,actor是最好的。
link |
inverse reinforcement learning是反过来,我们有expert的demonstration,我们相信它是不错的,然后去反推expert既然做这样的行为,那实际的reward function到底长什么样子?
link |
我就反推说expert是因为什么样的reward function才会采取这些行为,你今天有了reward function以后,接下来你就可以套用一般的reinforcement learning的方法去找出optimal的actor。
link |
所以今天inverse reinforcement learning里面,你是先找出reward function,找出reward function以后,再去实际上用reinforcement learning去找出optimal的actor。
link |
有人可能就会问说,把reward function认出来,到底相较于原来的reinforcement learning有什么样的好处?
link |
一个可能的好处是,也许reward function是比较简单的,也许虽然这个expert的行为非常复杂,但也许简单的reward function就可以导致非常复杂的行为。
link |
一个例子就是,也许人类本身的reward function就只有活着这样,每多活一秒你就加一分,但是人类有非常复杂的行为,但也许这些复杂的行为都只是围绕着要从reward function里面得到分数而已。
link |
所以有时候很简单的reward function也许可以推导出非常复杂的行为。
link |
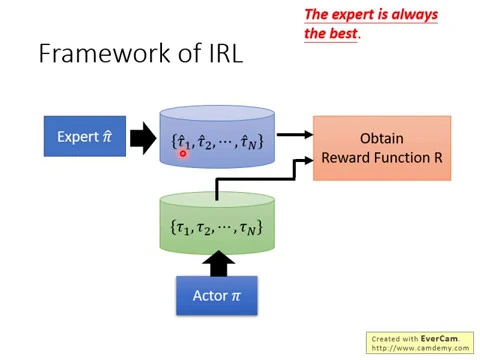
Inverse reinforcement learning实际上是怎么做的呢?首先,我们有一个expert,叫做PyHead,这个expert去跟环境互动,给我们很多Towerhead到Towerhead。
link |
如果是玩游戏的话,就让有一个电玩高手去玩N场游戏,把N场游戏的state跟action的sequence统统都记录下来。
link |
接下来,你有一个actor,一开始actor很烂,他叫做Py,这个actor也去跟环境互动,他也去玩了N场游戏,他也有N场游戏的记录。
link |
接下来,我们要反推出reward function,怎么推出reward function呢?这边的原则就是expert永远是最棒的,今天是先射箭再画靶的概念,expert他去玩一玩游戏,得到这些游戏的记录。
link |
你的actor也去玩一玩游戏,得到这些游戏的记录。
link |
接下来,你要定一个reward function,这个reward function的原则就是expert得到的分数要比actor得到的分数高,先射箭再画靶。
link |
所以我们今天就认出一个reward function,你要用什么样的方法都可以,你就找出一个reward function,这个reward function会使得expert所得到的reward大过于actor所得到的reward。
link |
你有了新的reward function以后,你就可以去认一个actor,你有reward function,你就可以套用一般的reinforcer learning的方法去认一个actor,这个actor会对这个reward function去maximize它的reward,它也会采取一大堆的action。
link |
但是今天这个actor虽然可以maximize这个reward function,采取一大堆的行为,得到一大堆游戏的记录,但接下来我们就改reward function了,先射箭再画靶的概念。
link |
这个actor就会很生气,它已经可以在这个reward function得到高分,但它得到高分以后,我们就改reward function了,仍然要让expert比我们的actor可以得到更高的分数,这个就是inverse reinforcement learning。
link |
你有新的reward function以后,你就有根据这个新的reward function,你就可以得到新的actor,那新的actor再去跟环境做一下互动,但它跟环境做互动以后,你又会重新定义你的reward function,要让expert得到reward function,大过,诶,你请问,这边其实就没有讲演算法的细节。
link |
那你至于说要怎么让它大于它,其实你在learning的时候,你可以很简单地做一件事情,就是我们的reward function也许就是一个neural network,这个neural network它就是吃一个凹,然后input output就是这个凹应该要给它多少的分数。
link |
或者是说你假设觉得input整个凹太难了,因为凹是S跟A一个很长的sequence嘛,那你也许就说它就是inputS跟A,它吃一个S跟A的pair,然后output一个real number,那把整个sequence,整个凹会得到real number,加起来就得到total的R。
link |
那在training的时候你就说,今天这组数字,我们希望它output的R越大越好,然后今天这个,我们就希望它R的值越小越好,就这样。然后这边对inverse reinforcement learning的framework,大家有没有什么问题要问的呢?
link |
对,我们假设说expert就是最好的,最好,所以最后什么叫做一个最好的reward function呢?最后你认出来的reward function应该就是,这个actor跟这个expert,他们在这个reward function都会得到一样高的分数。
link |
可是最后你可能会,最终你就会reward function没有办法分辨出谁应该会得到比较高的分数。
link |
这样大家还有问题要问的吗?诶,请说,通常在这个training的时候,你当然是会iterative的去做的,那今天的状况是这样,
link |
最早的inverse reinforcement learning,它对R的那个function有一些限制,它是假设它是linear的。如果在linear的话,你可以prove说这个algorithm会converge,但是如果不是linear的,你就没有办法prove说它会converge。
link |
大家还有问题要问的吗?你有没有觉得这个东西其实看起来还颇熟悉的呢?其实你只要把它换个名字说,actor就是generator,然后reward function就是discriminator,其实它就是gain。
link |
所以你说它会不会收敛这个问题就等于是问说gain会不会收敛,那你今天已经有做过作业三,你应该知道说也是很麻烦,不见得会收敛,但是除非你对R下一个非常严格的限制,那如果R是一个general的network的话,你就会有很大的麻烦就是了。
link |
那怎么说它像是一个gain呢?我们把它跟gain来比较一下。在gain里面,你有一堆很好的图,然后另一个generator,一开始它根本不知道会产生什么样的图,所以它就乱画。
link |
然后另一个discriminator,discriminator的工作就是这个expert画的图就是高分,generator画的图就是低分,然后你有了discriminator以后,generator会想办法去骗过discriminator,也就是generator会希望它产生的图discriminator也会给它高分。
link |
这整个process跟inverse reinforcement learning是一模一样的,我们只是把同样的东西换个名字而已。今天这些人画的图在这边就是expert的demonstration,你的generator就是actor,今天generator要画很多图,就是actor会去跟环境互动产生很多trajectory。
link |
这些trajectory跟环境互动的记录,游戏的记录,其实就是等于是gain里面的这些游戏画面,不是游戏画面,就等于是gain里面的这些图,然后你认一个reward function,这个reward function其实就是discriminator,这个reward function要给expert的demonstration高分,跟actor的互动的结果低分。
link |
然后接下来actor会想办法从这个已经认出来的reward function里面得到高分,然后接下来iterative的去循环,跟gain其实是一模一样的,我们只是换个说法来讲同样的事情而已。
link |
Inverse reinforcement learning其实有很多的application,举例来说,当然可以用来开自驾车,然后有人用这个技术来学开自驾车的不同的风格。
link |
今天每个人在开车的时候,其实你会有不同的风格,举例来说,能不能够压到线,能不能够倒退,要不要遵守交通规则等等,每个人的风格是不同的,然后用inverse reinforcement learning就可以让自驾车学会各种不同的开车风格。
link |
这个是文献上真实的例子,在这个例子里面,其实inverse reinforcement learning有一个有趣的地方,通常你不需要太多的training data,因为training data往往就是个位数而已,因为inverse reinforcement learning它只是一种demonstration,它只是一种范例,今天机器它仍然实际上可以去跟环境互动非常多次。
link |
所以inverse reinforcement learning的文献往往会看到说,只用几笔data就训练出一些有趣的结果,比如在这个例子里面,是要让自驾车学会在停车场里面停车。
link |
这边的demonstration是这样,这个蓝色的圈圈,蓝色的方形是一部车,蓝色是终点,车从这边开始开,开到这边停车,然后从这边开,开到这边停车,然后从这边开,开到这边停车。
link |
好,那就是给机器只看一个row的四个demonstration,然后让它去学怎么样开车,最后它就可以学出说,在这个位置,如果它要停车的话,它会这样子开,这样子开。
link |
今天给机器看不同的demonstration,它最后学出来的开车的风格就会不太一样。举例来说,这个是不守规矩的开车方式,因为它会开到道路之外,比如说这边,它会穿过其他的车,然后从这边开进去。
link |
所以机器就会学到说,不一定要走在道路上,它可以走非道路的地方。或者是这个例子是,机器是可以倒退的,它可以倒退路一下,在这边它也会学会说它可以倒退。
link |
这种技术也可以拿来训练机器人,你可以让机器人做一些你想要它做的动作。过去,如果你要训练机器人做你想要它做的动作,其实是比较麻烦的。
link |
怎么麻烦呢?这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
这边有一个例子,这个没有字幕啊,我开大声一点,希望你听得懂。
link |
人做一下示范,然后机器人就跟着人的示范来进行学习。
link |
或者是学会摆盘子,人拉着机器的手去教他摆盘子。
link |
或者是学会倒水,他只教他二十次的样子,跟杯子每次放的位置不太一样。
link |
或者是学会倒水,他只教他二十次的样子,跟杯子每次放的位置不太一样。
link |
或者是学会倒水,他只教他二十次的样子,跟杯子每次放的位置不太一样。
link |
在刚才那个例子里面,我们人跟机器的动作是一样的,但是在未来的世界里面,也许机器是看着人的行为学的。
link |
在刚才那个例子里面,我们人跟机器的动作是一样的,但是在未来的世界里面,也许机器是看着人的行为学的。
link |
有没有可能机器就是看着人打高尔夫球,他自己就学会打高尔夫球了呢?这个时候要注意的事情是,机器的视野跟他真正去采取这个行为的时候的视野是不一样的。
link |
机器必须了解到,当它是作为第三人称的时候,当它是第三人的视角的时候,看到另外一个人在打高尔夫球,跟他实际上自己去打高尔夫球的时候,看到的视野显然是不一样的。
link |
但它怎么把它是第三人的时候所观察到的经验,把它generalize到它是第一人称视角的时候所采取的行为呢?这就需要用到一个叫做three-person imitation learning的技术。
link |
那这个怎么做呢?细节其实我们就不细讲。它的技术其实不只是用到imitation learning,它用到了domain-adversarial training。
link |
因为我们在讲domain-adversarial training的时候,我们有讲说,这个也是一个game的技术,那我们希望今天有一个extractor,有两个不同domain的image,通过这个extractor以后没有办法分辨它是来自于哪一个domain。
link |
其实第一人称视角和第三人称视角imitation learning用的技术也是一样的,希望对一个future extractor,当机器在第三人称的时候跟在他第一人称的时候看到的视野其实是一样的,就只把最重要的东西抽出来就好。
link |
好,那其实我们在这个讲sequence game的时候,我们有讲过sentence generation跟缺乏,那其实啊,sentence generation或缺乏这件事情也可以想成是imitation learning,就是机器在imitate人写的句子。
link |
你可以把写句子这件事情,你在写句子的时候你写下去的每一个word,你都想成是一个action,那整个所有的word合起来就是一个episode。
link |
那这个sentence generation,举例来说,在sentence generation里面,你会给机器看很多人类写的文字,那这个人类写的文字,你要让机器学会写诗,那你就要给它看《唐诗三百首》,这个人类写的文字啊,其实就是这个expert的demonstration,那每一个词汇其实就是一个action。
link |
那今天你让机器做sentence generation的时候,其实就是在imitate expert的trajectory,或者是缺乏也是一样,在缺乏里面你会收集到很多人互动对话的记录,那些就是expert的demonstration。
link |
那如果我们今天单纯的用maximum likelihood这个技术来maximize,我们会得到的likelihood,这个其实就是behavioral cloning,对不对?我们今天说behavioral cloning就是看到一个state,接下来预测我们会得到什么样的action,看到一个state,然后有一个ground truth告诉机器说什么样的action是最好的。
link |
在做likelihood的时候也是一样,given sentence已经产生的部分,接下来我们需要predict说,接下来要写哪一个word才是最好的。所以其实maximum likelihood在做这种sequence generation的时候,maximum likelihood其实对应到imitation learning里面就是behavioral cloning。
link |
那我们说光maximum likelihood是不够的,我们想要用sequence gap,其实sequence gap就是对应到inverse reinforcement learning,我们刚才也有讲过,其实inverse reinforcement learning就是一种gap的技术。
link |
那你今天你把inverse reinforcement learning的技术放到sentence generation里面,其实就是sequence gap跟它的种种的变形。好,那其实差不多就是讲到这里。