back to index
Linear Algebra Lecture 28: PageRank
link |
所以我們剛才就聽到說,PageRank首先它是很長一段時間才update一次。等一下你就會知道說為什麼不能夠天天都算PageRank。
link |
接下來,PageRank跟你的網頁本身的內容是沒有關係的,它看的是有哪些其他的網頁link到你的網頁。所以它看的不是網頁的內容,你可以想成它看的是這個webpage在整個網絡平臺上它的評價有多大。
link |
這個就是有關PageRank的一些特性。首先,有比較高的PageRank的網頁,當然Google就會把它排在比較前面的地方。
link |
再來,PageRank它依靠的並非是網頁本身的內容,而是整個網絡的結構。也就是說,看有哪些人有把他的網頁放一個超連結連到你的網頁,你的網頁被超連結連到的越多,代表說這個網頁的PageRank算出來就會越大。
link |
當某一個PageA把它放一個超連結連到PageB的時候,就代表說PageA投一個信任票給PageB,就代表說PageB就會得到比較高的PageRank。
link |
這個也是網絡上找到一個示意圖,這邊的每一個笑臉就代表了一個網頁。我們知道,網頁和網頁之間有很多的超連結,這個圖上的箭頭代表的是網頁之間的超連結。
link |
像藍色的這個網頁跟黃色的這個網頁,就代表說它們是比較知名的網頁,它們被很多其他的網頁用超連結連到。這些被很多其他網頁用超連結連到的網頁,它算出來的PageRank就會值得大。
link |
那也有另外一個可能,你可以得到很高的PageRank。什麼樣的可能呢?如果你被一個重要的網頁,被一個本身PageRank算出來很高的網頁用超連結連到的話,比如說這個紅色的網頁,雖然沒有很多人連到它,但是黃色的這個網頁,它有指向紅色的這個網頁。
link |
黃色的這個網頁本身被很多其他的Webpage用超連結連到,所以這個黃色的網頁本身的PageRank很高。一旦這個黃色的網頁它放了一個PageRank去指向右上方這個紅色的網頁的話,那紅色的網頁本身就會水漲船高。
link |
所以這個跟真實的人類世界也是非常像的,如果你被很多人認識的話,那你就是一個名人,然後如果有某個名人特別推薦你的話,那你也會變成一個名人,所以差不多就是這個樣子。
link |
實際上PageRank是怎麼運作的呢?這其實是來自於Google的一篇文章,我們知道說Google就是由兩個Stanford的學生所創立的,其中一個人就是Laurence Page。
link |
那PageRank的那個Page據說就是來自於Page它的姓。我本來以為說PageRank的Page可能指的就是網頁,所以是PageRank,但據說其實是來自於創辦人的姓,但也有可能就是一語雙關就是了。
link |
這個是Google背後的技術的那篇文章,據說是投到第一屆的WWW,如果沒記錯的話,應該是1999年的時候發表,大約是二十年前發表。
link |
那你看這篇文章的Title它就說,在這篇文章裡面我們Present了一個東西叫做Google,它是一個Search Engine的Prototype,那它使用了什麼呢?它使用了這個網絡上的Hypertext的Structure來排序它的搜尋的結果。
link |
那這邊有一個勵志的故事,據說這篇文章一開始是想要投到SIGIR,投到SIGIR以後就被拒絕,後來它就改投WWW,WWW那個時候是第一屆,據說是因為有這篇文章才捧紅了WWW。
link |
我不知道這個事情是不是真的,也許WWW本來就會變得很紅,跟這篇文章也沒有什麼關係,不過很多人都傳說說,是這篇文章捧紅了WWW,這就是一個勵志的故事。
link |
PageRank的由來,那接下來要講說PageRank實際上是怎麼計算的呢?假設我們現在有一個非常簡單的網絡,這個網絡上只有四篇Webpage,但實際上網絡上有多少Webpage,它是一個天文數字,那我們這邊就簡單地用四個網頁來代表整個網絡。
link |
在這個網絡上,Webpage和Webpage之間是有連結的,第一個Webpage,Webpage編號1,它指向Webpage編號2,Webpage編號4和Webpage編號3,以此類推。
link |
那PageRank怎麼計算呢?PageRank的定義是這樣,每一個網頁都有一個分數,這個分數我們就用x1到x4來表示,這個分數要符合下面這個equation,x1的分數要等於有指向它的網頁分數的總和。
link |
那有誰指向x1呢?x3有指向x1,x4也有指向x1,那x1的分數本身x1就等於x3的分數加上x4的分數,但是這邊你發現說x4的分數我們要把它乘上二分之一,為什麼x4的分數要乘上二分之一呢?
link |
因為x4這個Webpage,它有Support Page3,它也有Support Page1,所以它本身的PageRank,它本身的分數就要分成兩半,有一半要給3號,有一半要給1號,所以今天x1的分數等於x3的分數加上一半的x4的分數。
link |
x3它只有0到x1,所以它全部的分數都會給x1,x4它有一半連到x1,一半連到x3,所以x4只有二分之一的分數會給x1,所以x1的分數會等於x3加二分之一的x4。
link |
以此類推,每一個Webpage的分數都可以列出這樣一個式子,x2它只有誰連到它呢?只有x1連到它,但x1又連到三個不同的網頁,所以x2的分數會等於三分之一x1的分數。
link |
那x3呢?x3它被x1、x2跟x4連到,那x3的分數就等於三分之一的x1加上,x2有連到兩個人,所以x3只能分到一半的x2的分數,x4也連到兩個人,所以x3只能得到x4一半的分數,所以x3等於三分之一x1加二分之一x2加二分之一x4。
link |
那x4呢?x4等於有誰連到它呢?1跟2都有連到它,1把它的力量分成三部分,所以x4只有三分之一x1,加x2分成兩部分,所以加二分之一x2。
link |
所以今天PageRank的這個分數它要符合右邊這個式子所下的限制。那這件事情你可以怎麼來理解它呢?就是這個分數你可以怎麼理解它呢?你可以把這些分數想成是一個在網絡上的流量,什麼意思呢?
link |
你想像說有一個random的server,就是有一個無聊的人,他在網絡上胡亂瀏覽網頁。那他瀏覽網頁的方式就是,現在他假設一開始在看網頁二,那下一分鐘他會看哪一個網頁呢?
link |
取決於網頁二它的hyperlink。有網頁二,如果連到網頁三跟網頁四的話,接下來下一分鐘他就有二分之一的機率去看網頁三,有二分之一的機率去看網頁四。
link |
那你可以把右邊這個式子就想成是,等號右邊是前一分鐘每一個網頁瀏覽的人數,你可以把x想成是瀏覽的人數,那左邊就是下一分鐘每一個網頁瀏覽的人數。
link |
也就是說,本來有x3的人在看網頁三,本來有x4的人在看網頁四,那下一分鐘x1會有多少人在看呢?就是從x3瀏覽過來的人跟從x4瀏覽過來的人。
link |
就假設說,當然這是一個很粗糙的假設,假設說每個人在網路上就是順著hyperlink到處去點網頁,所以x1瀏覽的人數就會是x3瀏覽的人數加上二分之一x4瀏覽的人數。
link |
那假設你現在把一大群人就放到網路上,讓他們在網路上隨便點來點去,點來點去,那最後當這些人,當這個人口的網頁流量的分布最後收斂的時候,就會變成右邊這個式子。
link |
講到這邊大家有沒有問題要問呢?沒有啊,那再來就是怎麼把x1到x4解出來呢?怎麼把x1到x4解出來呢?這個就變成一個線性代數的問題,那我們把式子寫出來以後,接下來就是要把x1、x4解出來。
link |
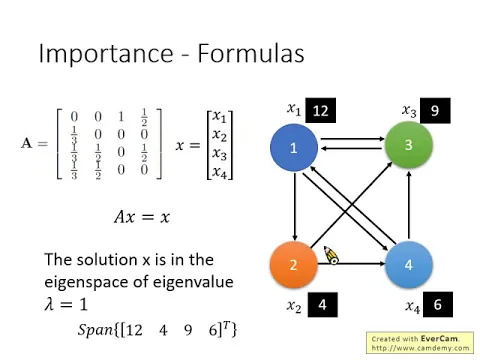
那你可以想像說有一個matrix是A,有一個vector是x1到x4,那事實上右邊那個式子就等同於寫成A乘上x等於x。
link |
那這個就很直覺,就不太需要多做解釋啦,我們就是把x1到x4乘上A的第一個row就得到了一倍的x3,二分之一倍的x4,那乘上第一個row就是三分之一倍的x1,然後其他都乘零。
link |
這個row就是三分之一倍的x1,二分之一倍的x2,跟二分之一倍的x4,以此類推。所以你可以把右邊這個式子寫成某一個矩陣A乘上x以後仍然等於x它自己。
link |
那就會發現說x是A的什麼?x就是A的eigenvector,那這個eigenvector它對應的eigenvalue就是1。所以解這個formulation,解Ax等於x這個formulation,
link |
其實等同於是說我們要去找matrix A的對應到eigenvalue等於1的eigenvector,那就是我們要找的solution,就是page rank的分數。
link |
所以今天要怎麼算page rank呢?其實就是把整個網頁,整個互聯網這個世界想成是一個巨大的matrix A,這個matrix A裡面的這些數值就代表了這兩個網頁之間有沒有hyperlink相連。
link |
就如果這兩個網頁間沒有hyperlink相連,那就是0。那如果有的話,就看說連到幾個網頁,那寫出來的數值就是不一樣。
link |
那就把整個網絡的架構用一個matrix A來表示,然後接下來找這個matrix A,它eigenvalue等於1的那個eigenvector,就是page rank的數值。
link |
舉例來說,今天用我們圖上這個四個網頁的例子,這一個matrix A,它eigenvalue等於1的時候有一個eigenvector,是什麼呢?
link |
有一個eigenvector是x1等於12,x2等於4,x3等於9,x4等於6,那可以自己帶到左邊這個式子驗算一下看看對不對。
link |
或者是說,這一個vector12,9,4,6,它們的n倍都是,它們用這個vector做spam,把它乘上任意一個k倍,都是你的solution,都可以是合理的solution。
link |
好,那接下來有人會問的問題就是說,這一個formulation,它一定有解嗎?這個matrix A,你一定找得到,它一定有eigenvalue等於1嗎,它一定有eigenvalue是等於1的嗎?
link |
這個我們今天就先不證明,之後我們有空再證明,我們先趕個課,先把考試會考的東西講完,這個是可以證明的。
link |
就是如果今天一個矩陣,它的column的核都是1,如果一個矩陣,它的column的核呢,它的column的這個數值的核都是1,比如說你看這個矩陣,它每一個column裡面數值的核都是1,那它就會有lambda等於1的eigenvalue,就這樣子。
link |
好,那為什麼今天這個matrix A,它的每一個column都會是1呢?因為你想想看,今天矩陣上面的每一個數值代表什麼?比如說這個row是2,column是1的index代表什麼?
link |
它代表的是網頁1對網頁2的投票,那網頁1它會有三分之一分到網頁2,每一個網頁就想像它的分數是1,它看它有幾個link,比如說網頁1有三個link,它就會把三分之一的分數分到網頁2,有三分之一的分數分到網頁上,有三分之一的分數分到網頁1。
link |
那不管它怎麼分,它的核總是1,不管它怎麼分,它的核總是1,不管它怎麼分,它的核總是1,不管它怎麼分,它的核總是1,所以你總是會有lambda等於,所以你算出來的這個matrix,它的column的核總是1,所以它的這個eigenvalue它一定會有lambda等於1的eigenvalue。
link |
但這邊可能會有一個問題,就是假設有一個webpage它完全沒有hyperlink,它完全不會連出去的話,它完全沒有hyperlink連到其他地方的話,如果你把那個webpage也考慮進去的話,會變成說這個matrix有的column全部都是0,如果是有出現這樣子的狀況,那就會有問題,所以我們就不考慮這種狀況。
link |
因為你想想看,如果你從剛才講的那個random server的直觀的想法來看,如果有某一個webpage它是只進不出的,只有別人用hyperlink連到它,它沒有任何hyperlink連到別人的話,那最後所有的人其實都會堆積在那個沒有辦法出去的webpage裡面,所以這樣子是有問題的,所以你就要假設這樣子的狀況是不存在的。
link |
是講說我們一定找得到讓eigenvalue等於1,就今天我們列出來的這個matrix,它的eigenvalue一定會等於1。講到這邊,大家有問題嗎?
link |
如果沒有的話,接下來下一個問題是,這個解會是唯一的嗎?假設我們今天要用page rank的這個分數來對所有的網頁做排序,這個排序會是唯一的嗎?
link |
還是說,不同的情況,用不同的解法,我們可能就會找出不同的排序的結果?
link |
假設今天這個eigenvalue lambda等於1所對應的eigenspace,它的dimension等於1的話,你會發現說今天這個排序就是唯一的。因為假設今天這個eigenvalue它的dimension等於1,那它的dimension等於1它就只會有一個basis,對不對?
link |
dimension等於1,就只會有一個basis,比如說B1。那其他eigenspace裡面的成員,都是這個basisB1直接乘上k倍,直接乘上k倍。
link |
那如果你今天拿B1的分數來做排序,假設B1的值就是12、4、9跟6,拿它來做排序,跟把B1的值乘上k倍,你現在把12、4、9、6這些值通通乘個k,通通乘個k,通通乘個k,其實也不會影響排序的結果。
link |
所以我們今天就學到說,假設今天你找出來的這個matrix A,它lambda等於1的eigenvalue,它對應的dimension等於1的話,它對應的dimension正好等於1的話,那今天這個page rank它的ranking就是unique。
link |
你拿page rank的分數,拿這個eigenvector給我們的分數來做排序的話,就是唯一的。不管你找出來的這個solution是哪一個,這個排序的方法、排序的結果都是唯一的。
link |
甚至你可以下一個constraint說,我今天找出來的那個eigenvector,舉例來說,這個vector裡面所有element的核要是1,那你找出來的solution就是唯一的,就只有一個可能的solution而已,那你這樣網頁的排序就只有一種分數來排序而已。
link |
但是真的會是這樣嗎?lambda等於1的eigenspace的dimension真的一定會等於1嗎?事實上你可以輕易的舉出反例來說,有可能它的dimension是大於1的。
link |
舉例來說,我這邊有一個matrix A,這個matrix A它也定義了網路的某個架構,但是這個matrix A,我算了一下,它lambda等於1的eigenspace的dimension就是2。
link |
這一個matrix它所定義的網路架構長什麼樣子呢?它長的是這個樣子,我們總共有五個網頁,在這個網頁裡面,1指向2,2也指向1,然後3指向4,4指向3,然後5指向3跟4,5指向3跟4。
link |
今天你可以把這五個網頁用一個矩陣來表示,這個矩陣,我們剛才說如果一個矩陣它的每一個column的和都是1,那它就會有lambda等於1的eigenvalue。
link |
這個矩陣,它確實有lambda等於1的eigenvalue,但它的問題是什麼?它問題是lambda等於1的eigenvalue,它所對的eigenspace的dimension是2。
link |
所以如果今天這個網路你用page rank的方法來計算的話,找出lambda等於1的eigenvector,你有兩個不同的ranking,其實不是兩個不同的ranking,你有很多不同的ranking,你有無限多,你有各式各樣不同的ranking,它的ranking就不是唯一的。
link |
那這邊就是舉一個例子,舉例來說,在這個有五個webpage的網頁裡面,有哪些lambda等於1的eigenvector呢?
link |
舉例來說,你可以把第一個網頁跟第二個網頁的數值都填1,第三、第四、第五個網頁的數值都填0,你也可以把第一、第二個網頁的數值填0,三、四的數值填1,二分之一、五的數值填0。
link |
這兩個solution的這個二分之一、二分之一、零、零、零跟零、零、二分之一、二分之一、零,它們都是matrix A的eigenvector,而這兩個vector它們是independent。
link |
那我們知道說,所以有兩個independent的lambda等於1所對應的eigenvector,有兩個independent eigenvector,它的dimension你實際上算一下會發現它的dimension其實是2。
link |
但是你用左邊這種分數跟用右邊這種分數去做排序,排出來的結果會是不一樣的,它的排序並不是唯一的。
link |
那要怎麼避免這個狀況發生呢?因為我們希望說今天那個分數就是唯一的,你並不希望說你用不同的solution解出來的分數是不一樣的。
link |
所以PageRank怎麼讓它的分數是唯一的呢?其實PageRank的分數真正的寫法,真正完整的寫法是這個樣子的,真正完整的寫法是這個樣子的。
link |
除了matrix A以外,會把matrix A乘上e-n再加上n倍的另外一個matrix,它叫做S,那等一下我們會講它是什麼。
link |
舉例來說,n這邊就可能就設成0.15,它就是一個比較接近0的值。
link |
那這個S是什麼呢?S是一個matrix,這個matrix裡面所有的值都是n分之1,什麼意思呢?
link |
假設你是一個2乘以,比如說3乘以3的matrix好了,它的所有的值都是1 3分之1,都是1 3分之1,所有值都是1 3分之1。
link |
那這一個新的式子代表什麼意思呢?這個新的式子的意思是說,假設現在每一個人在使用網絡的時候,它有兩個模式。
link |
它的第一個模式是按照網頁和網頁間的hyperlink來搜尋這個網絡,來在網絡上瀏覽這些網頁。
link |
那我們剛才有講過說,我們假設說每一個人他就是順著hyperlink去看下一個網頁,那這個部分是matrix A。
link |
但是人呢,其實還有另外一種type,這個另外一種type就是每個人他都可以有一定的機率,他突然之間覺得他不想要follow hyperlink給你的搜尋的順序,
link |
他突然想要隨機的跳到某一個網頁上面去,他想要突然隨機的跳到某一個網頁上面去,那這個部分就是S。
link |
如果我們這邊用圖示的方法來表示的話,你就想像是說,有一個人他現在在看網頁3,那他有1-n的機率,也就是有85%的機率,他會順著hyperlink來瀏覽下一個網頁。
link |
但是他也有15%的機率,他會隨機的跳到任何其他的網頁,那順著hyperlink的部分就用A來表示,隨機跳到任何網頁的部分就用S來表示。
link |
那S裡面呢,每一個所有的element值都是n分之一,意思就是說,現在每一個人跳到其他網頁的機率都是n分之一。每一個人跳到其他網頁的機率,就有n個網頁,假設100個網頁,你今天不按照hyperlink走,那你隨便看到一個網頁的機率就是1%。
link |
但實際上這個數值可能不是uniform的,可能在Google的model裡面,這個S可能不是uniform的。
link |
舉例來說,如果你有付錢打廣告的話,那你的S的這個值可能就比較高。就比如說,page1有付錢打廣告的話,那到時候在這個模型裡面,當進入這個隨機搜尋的模式的時候,那這個使用者假設他跳到page1的機率就會比較高。
link |
如果你有付錢打廣告的話,那他的數值在這個matrix S裡面就會比較大。好,那根據A跟這個S的weighted sum,你就得到一個新的matrix,這個新的matrix叫做n。
link |
那同樣的,我們現在要找n的ln等於1的eigenvalue,我們一樣要找nx等於x的solution,我們一樣要找nx等於x的solution。
link |
那首先n這個matrix,我們剛才有講過說,如果某一個matrix它的column的數值的和等於1的話,那它就一定就有ln等於1的eigenvalue。matrixn它的column的值都會等於1嗎?它的column的數值的和是等於1嗎?是,所以它有ln等於1的solution。
link |
但是同時呢,它有unique的ranking,因為這個matrixn它的ln等於1的eigenvalue,eigenspace的dimension一定是1,這個證明就是之後再講。
link |
反正今天如果你把一個matrix寫成這個樣子,它ln等於1的eigenvalue的eigenspace的dimension是1,所以今天如果你用n這個matrix來找eigenvector來算page rank的分數的話,
link |
算出來的page rank,根據page rank的分數來做排序的話,這個排序會變成是唯一的。接下來問題就是怎麼找matrixn的eigenvector呢?
link |
你也可以想像說,我們之前要找eigenvector的時候,你要做一個reduce raw hreform,那如果今天這個n它代表的是整個網頁的架構,假設現在整個網絡的架構,
link |
假設現在世界上有一億個網頁,那n就是一億乘一億的一個非常非常巨大的矩陣,那你要為這麼巨大的矩陣做什麼reduce raw hreform,根本就是不可能的。
link |
所以怎麼辦呢?實際上在解的時候,要用一個解法叫做power method,這個power method是這樣做的,假設你今天要找一個vector x star,
link |
這x star它是lambda等於1的eigenvalue的eigenvector,也就是說x star乘上matrixn要等於x star,那今天對x star的長度你要做一個限制,我們假設說x star的長度就是1,
link |
我突然發現說我們還沒有講過這個雙引號是什麼意思,雙引號代表的就是這一個vector它的長度這樣,而下標1就代表說這個長度是用one-norm來算的。
link |
那接下來怎麼找出這個x star呢?這個方法是這樣子的,因為n很大,所以你絕對不要想說做什麼matrix inverse或reduce raw hreform之類的,所以實際上怎麼做呢?
link |
實際上就是你先隨機的random一個vector x0,然後這個x0它只要裡面的每一個element的和是1就好,那實際上值是多少?不用在意,隨機一個vector,它裡面只要所有的值和是1就好了,你就隨便隨機一個vector。
link |
接下來把x0乘上n變x1,把x1乘上n變x2,把xk-1乘上n變到xk,最後它會收斂,也就是k等於無窮大的時候,xk就會等於k star,就這樣子,然後我們就是省略這邊的證明。
link |
那這個收斂其實是非常快的,也就是說你並不需要真的跑比如說上百萬個iteration才會收斂,它可能是跑數十個iteration就收斂了,所以收斂的意思就是說,xk跟xk-1的值就沒有差很多,你就可以把你的計算停下來了。
link |
也就是說,實際上Google是怎麼找出這個eigenvector的呢?隨機有一個初始的值x0,那初始的值不會影響結果,到時候你作業的時候你可以自己試一下,你不管選什麼樣的初始的值,最後收斂的結果都是一樣的。
link |
你就隨便random一個vector x0,每個網頁都有一個分數,然後把它乘上n,當然這個n想必也是非常非常地巨大,所以這個運算可能還是需要花些時間的,你把x0乘上n得到x1,但這個一定是比GDSOM的reduce,如果H2O還要快,那把x1再乘上n變x2,一直到把n乘上xk-1變成xk,那這個xk,你知道這個k夠大,它就是k rank的數值,就這樣。
link |
所以PageRank就是這樣子來的,那這邊最後呢,有一件要告訴大家的事情,就是據說Google已經逐漸不會再使用PageRank,據說PageRank的數值最後一次的update是在2013年的12月,所以Google就說PageRank是我們已經至少一年,
link |
沒有update它了,之後可能也就不會再update它了。
link |
好,那後面呢,是一些reference給大家參考,那我們在這邊呢,還是休息十分鐘,那等一下是四十分的時候助教會來講作業啦,不過我們大概就是十二點半回來,我們接下來繼續講後面的部分。