back to index
GAN Lecture 1 (2017): Introduction of Generative Adversarial Network (GAN)
link |
整理&字幕由Amara.org社區提供
link |
我想,多數同學,如果你對deep learning有興趣的話,那你一定聽過Generative Adversarial Network,這是現在非常熱門的一個主題。假如你還沒有聽過的話,以下是一些台教的話,讓你覺得這個主題是很重要的。
link |
之前有人在Quorum上問,有沒有什麼在unsupervised learning的領域,有沒有什麼技術,最近有沒有什麼特別的突破。
link |
Younglak親自來回答了,他說他覺得adversarial training is the coolest thing since sliced bread。這邊教大家一個片語,什麼是since sliced bread呢?since sliced bread如果你翻成中文的話,你可以翻成由始以來。假設有一個好東西出現了,那這個英文的片語就since sliced bread。
link |
我還特別google了一下,since sliced bread是什麼意思呢?過去麵包店在賣吐司麵包的時候是沒有切片的,它是賣一整條,買回去以後要自己切,很麻煩。
link |
後來有人發明了應該要把麵包先切片以後,再賣給家庭主婦,就省了家庭主婦很多的時間。所以since sliced bread就是有一個好東西出現的意思。
link |
今天我們先學了一個片語。後來又有人問說,最近在deep learning的領域有沒有什麼特別的breakthrough。Younglak又親自來回答了,他說game跟它的種種變形是the most interesting idea in the last ten years。他覺得這是近十年來最有趣的技術。
link |
接下來我們就進入今天的主題,來講一下GN。第一個問題就是,GN怎麼pronounce呢?我試著用google小姐pronounce一下。
link |
Google小姐pronouncingGN就是這麼發音的,它就是發成擱暗四聲。所以在臺灣的路上常常聽到有人大聲地在說擱暗四聲,其實他們就是在討論這個技術。
link |
接下來進入今天的outline。首先講一下game的base,到底GN是什麼。我想大家都知道,這個比較像是農場文的講法。
link |
接下來要講說什麼時候我們會需要用到GN。大家通常看到GN現在的應用都是拿來生成影像,那你就會覺得說,如果我今天其實也沒有要做影像處理相關的技術,好像沒有要用到GN。
link |
接下來就是要告訴大家說,GN可以用在什麼樣的地方。接下來會告訴大家說,GN我認為它可以看作是一種structure learning的技術。最後會告訴大家怎麼做conditional的generation。
link |
今天大概計劃就是講到這邊,然後就請助教來講一下作業。那我們這個第四個作業就是跟GN有關的。
link |
先來介紹一下GN。GN通常是拿來做什麼呢?我們就是要拿它來生成東西。拿GN來生成東西,我們就需要一個生成器,我們就需要一個generator。
link |
這個generator你不用把它想得太複雜,它就是一個function。我們知道說NN是一個function,所以這個generator它可以是一個NN。至於這個NN的架構長什麼樣子,當然就是取決於你現在要生成什麼樣的東西。
link |
我們現在還沒有講到conditional generation,我們先講生成這件事,要機器生成一個東西。如果要機器生成一個東西,這個generator是怎麼運作的呢?我們會給generator吃一個input,這個input是一個vector。
link |
那這個generator會根據input的這個vector產生出一個你要的object。那產生出來是什麼東西,當然是取決於你希望machine生成什麼。假設我們現在希望machine產生的是圖片,你給它一個random的數字,給它一個random的vector,它就產生一張圖片。
link |
那這個輸出就是一個matrix,就讓機器輸入一個vector,吐出一個matrix,把這個matrix排起來,它就變成一張image。當然你可以想像說,我們今天如果要讓machine產生一個matrix,那你這個generator的最後幾個layer可能是用decomposition來生成的。
link |
那如果你現在要產生的不是image,而是一個sequence,比如說一個word sequence,你要讓機器說一句話,寫一首詩,那你可能就會在這個generator的輸出的地方用RNN,讓機器可以產生一個sequence。
link |
總之現在的大原則就是,generator就是吃一個vector當作input,輸出你要的object。至於要怎麼輸出object,怎麼design那個network,那是你要自己去想的,根據不同的case,有不同的做法。
link |
這邊是舉比較具體的例子。大家在作業裡面要做的事情就是二次元人物的人臉生成,所以我們就用二次元人物的人臉生成來當作例子。以下的圖片其實是從右上角這個github的程式弄出來的,你可以自己跑跑看,它的結果其實還蠻驚人的。
link |
舉例來說,有一個generator,那你輸一個vector進去,它就輸出一張圖片,這個圖片是機器自己生成的。而輸入的這個vector,每一個dimension,會代表了輸出的圖片的某一種特徵。
link |
所以你只要跟動輸入的這個vector的某一個維度,或某幾個維度,你就可以讓輸出的這個圖片有不同的變化。舉例來說,我們假設這個第一個維度代表了頭髮的長度,所以你增大了第一個維度,你就可以讓你輸出的人物的頭髮變長。
link |
舉例來說,我們現在把第一個維度的值變大,那你就產生一個長髮的角色。或者是我們假設說,某一個維度是跟頭髮是不是藍色的有關係。我們假設說倒數第二維跟頭髮是不是藍色的有關係。
link |
這邊有點講錯了,我這個兩個數字是一樣的,我忘了改了。那這邊如果你跟動一下倒數第二維,你就可以把頭髮從本來沒有顏色變成藍色。所以這個人物就從白頭髮變成藍頭髮,那其他地方幾乎是不變的。
link |
或者是有某一個維度,它其實代表了嘴巴是關起來的還是張開的。假設最後一個維度代表嘴巴是關起來的還是張開的。那你把最後一個維度的值變大,這個人物就笑了。
link |
它本來是像長門一樣是無口的,但是把最後一個維度變大以後,它就笑了。我們今天要的就是generator,我們要生成的時候,我們需要的就是generator。
link |
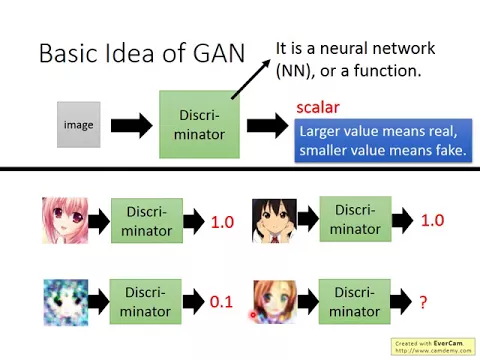
但是gain那個有趣的地方就是它引入了另外一個東西,這個東西是一個discriminator,那等一下會告訴大家說這個discriminator帶來了什麼樣的幫助。這個discriminator它一樣也是一個function,這個function一樣也可以用neural network來表示。
link |
那它的輸入是一張圖片,它的輸出是一個數值,這個數值代表說輸入的這張圖片它有多像是人畫的。如果輸入這張圖片非常像是人畫的,它就會得到比較高的分數。如果它不像是人畫的,它就會得到比較差的分數。
link |
舉例來說,現在有一張圖片,這個是畫得很好的,所以把它當作discriminator的input,discriminator的輸出就是1.0,再給discriminator看另外一張圖片也是好的,那discriminator的輸出就是1.0。
link |
但是如果給discriminator看一個畫得很差的圖片,這個可能是機器生成的,那discriminator就給它0.1的分數。或者是說,當然discriminator也是一個network,所以它也是會犯錯的。
link |
一張圖片到底像不像是人畫的,discriminator能不能夠正確判斷說它是不是人畫的這件事情,取決於你在訓練的時候這個discriminator訓練得有多好。舉例來說,像下面這個角色,其實你乍看之下會覺得說畫得其實也不錯了。
link |
如果你仔細看這個人物的眼睛,會發現說他兩隻眼睛的顏色是不一樣的,只有機器才會犯這樣的錯誤。如果今天這個discriminator很笨的話,他可能就會覺得說這張圖片畫得也已經很像是人畫的,所以會給他很高的分數。
link |
但是事實上,如果這個discriminator夠強的話,他可以偵測出發現說兩隻眼睛的顏色是不一樣的,而他知道說人在畫角色的時候通常不會畫兩隻眼睛的顏色是不一樣的,除非你是一眼開白眼、一眼開血輪眼,兩隻眼睛的顏色才會是不一樣的。
link |
所以,很少有角色兩隻眼睛的顏色是不一樣的,所以他就應該要學到給他比較低的分數。能不能做到這件事,要看discriminator學得好不好。那等一下會講discriminator是怎麼學的。
link |
有一個generator,有一個discriminator,為什麼我們會需要兩個東西呢?在生成的時候只需要generator就好了,為什麼會需要discriminator呢?那如果你看Ian Goofalo原始的paper的話,當然那邊有一連串的證明,但是他給了一個intuitive的比喻,這個比喻後人都一直引用,或者是略微改造那個比喻來說明gap。
link |
那這邊就是仿造原來Ian Goofalo的講法。他舉的例子是做假鈔和警察的故事,今天只是改成被掠食者和他的天敵的故事。
link |
這個是枯葉蝶,枯葉蝶的祖先並不是長這個樣子,枯葉蝶的祖先可能跟一般的蝴蝶一樣,他也是五彩斑斕。但是為什麼枯葉蝶會從五彩斑斕變成像是一個枯葉一樣呢?因為他有天敵,他的天敵是麻雀,麻雀會吃枯葉蝶。
link |
他怎麼判斷說,一個東西是不是可以吃的呢?他就看它的顏色。他看到棕色的,他就覺得是枯葉,他不會去吃它,看到彩色的就會去吃它。在天擇的壓力之下,枯葉蝶就淨化了。在天擇的壓力之下,枯葉蝶就從原來的彩色變成棕色的。
link |
但是他的天敵同樣也會淨化。麻雀淨化以後,這個就是大鼻鳥,或者又翻譯成鼻雕。不同年代的翻譯是不太一樣的。
link |
麻雀淨化以後,他就知道說,蝴蝶其實有可能是棕色的。所以怎麼判斷一個東西能不能吃,不是看它的顏色,而是看它有沒有葉脈。有葉脈的就是枯葉,沒有葉脈的可能是枯葉蝶,還是可以吃它的。
link |
所以在天擇的壓力之下,枯葉蝶又在淨化,他就產生了葉脈,希望可以騙過他的天敵。淨化是有很多層次的。像《數碼寶貝》裡面可以淨化、超淨化、究極淨化、究極超淨化,我說的對嗎?我其實已經不太記得了。
link |
所以,淨化本來就是有很多階的。雖然枯葉蝶淨化了,但是他的天敵也會跟著在淨化。這個淨化就會不斷持續下去,有很多階的淨化。
link |
像水賤龜可以淨化成傑尼龜,傑尼龜在淨化,到底是什麼呢?我說反了,傑尼龜淨化會變成卡咪龜,卡咪龜淨化會變成水賤龜,然後在用mega淨化時可以淨化成別的東西。我其實也不是很清楚。
link |
這個被掠食者就是generator,這個掠食者就是discriminator。所以,今天有這個generator和discriminator,他們是怎麼互動,讓generator學會產生以假亂真的圖片呢?
link |
他們的互動是這樣子的。一開始generator的參數幾乎是隨機的,所以他什麼都不會。一開始他的參數是隨機的,所以你輸入一個vector,要他產生一個圖片的時候,他產生出來就是一堆noise,譬如說像是這個樣子。
link |
但是我們有一個discriminator,discriminator他看過真實的圖片,你會收集很多人畫的圖片餵給discriminator,告訴discriminator說,這些就是人畫的圖片,人畫的圖片長這個樣子。
link |
discriminator他要做的事情就是學習分辨這個generator產生的圖片和人畫的圖片之間的差異,他要能夠知道真正的人畫的圖片和generator產生的人物之間的差異。
link |
當然對第一代discriminator來說,這個工作是非常簡單的,因為第一代generator很笨,他產生出來的東西是黑白的,所以第一代discriminator也許他只要能夠判斷一張圖片是彩色的還是黑白的,看到黑白的就說是generator生成的,看到彩色的就說是真實的。
link |
接下來generator就會進化,進化到第二代,第二代的generator進化的方向就是為了要騙過第一代discriminator,如果第一代discriminator是用顏色來判斷說,現在你產生出來的人物是不是人畫的,
link |
那第二代的generator為了要騙過第一代discriminator,他產生出來的圖片就會變成是彩色的。
link |
第一代discriminator會被這些彩色的圖片騙過,他會覺得這些彩色的圖片就是真的,但是discriminator也會再進化,他進化的方向就是他要去分辨這種圖片和這種圖片的差異。也許他發現說,這些人物都沒有嘴巴,他們是有嘴巴的,所以他就會知道說,沒有嘴巴的就是generator產生出來的圖片。
link |
但generator也會跟著再進化,畫得更好,但discriminator也會跟著再進化,他會變得更嚴格。所以,這兩者之間就不斷地互相砥礪,不斷地互相砥礪,然後讓彼此都能夠做得更好。
link |
Adversarial字眼的意思就是對抗的意思。在generator和discriminator的互動裡面,你可以想成是generator和discriminator在互相對抗,所以在這個技術的名字裡面有adversarial這個字眼。
link |
有人可能會問說,為什麼是要讓兩個network互相對抗呢?為什麼不能互相合作呢?為什麼這個世界不能夠充滿愛與和平呢?
link |
這個其實只是比喻而已。這兩個network是不是互相對抗,其實看你心裡是怎麼想的。你要怎麼想,其實都是可以的,這只是一個比喻而已。所以其實你也可以舉不同的例子,說這兩個network是合作的關係。
link |
舉例來說,我們這邊就換一個比喻的方式。我們把generator想成是學生,而我們把discriminator想成是指導教授。
link |
指導教授看過很多真人化、大師化的人物的圖片,所以他知道什麼是好的,什麼是不好的。學生就是要去跟老師學習。
link |
那怎麼學習呢?一開始一年級的學生,他什麼都不會,所以他畫出來的東西是很差的。老師就會給他feedback,告訴他說,我覺得你畫得不好,為什麼你沒有畫眼睛。
link |
等一下會更具體的講說到底老師也就是discriminator是怎麼給generatorfeedback的。
link |
discriminator就說,這個generator是沒有眼睛的。這個generator升上二年級以後,他就記得一年級的老師教他的東西,所以他就知道說,畫人物的時候要把眼睛點上去。
link |
他就會把這個畫的結果拿給二年級的老師看。他本來以為二年級的老師會說他好棒,但其實二年級的老師只會說他好棒棒而已。二年級的老師說,你其實沒有畫得很好,你沒有把嘴巴畫上去。
link |
所以generator升上三年級以後,他就知道要把嘴巴畫上去。在這個互動的過程中,學生會畫得越來越好,老師會變得越來越嚴格。
link |
在這個過程中,其實我們有很多的問題,等一下我們就試著來回答這些問題。第一個問題是,為什麼generator不能自己學呢?
link |
這些圖片就在這邊,為什麼會需要一個老師,為什麼generator不自己看著這些圖片學呢?還有另外一個,學生都會有的問題就是,為什麼老師都不自己做呢?為什麼老師要受到一直批評都不coding呢?我相信大家都有這個問題,所以我們等一下要來回答這個問題。
link |
以下是一些實際上產生的結果。我做出來的其實不是特別好,你隨便google一下會發現,現在已經有滿坑滿谷的人在做二次元人物的生存。我今天demo是比較差的,很多人都可以生成遠比這個好的結果。
link |
這個是network update一百次以後的結果,那個時候產生的圖片都還是黑白的。但是update一千次以後,generator就知道說應該要產生眼睛,update兩千次以後,generator就會知道說,現在不只要產生眼睛,還應該要產生嘴巴。
link |
那update五千次以後,你會發現說,network學到說動漫人物就是要有水汪汪的大眼睛,你會發現這些人物的眼睛都很大。這些人物的眼睛都有反白,反白就代表是水汪汪的大眼睛。
link |
那update一千次以後,這個時候外型看起來就有點像了。你會發現說,這些角色外型雖然看起來像,但是是有點模糊的,有點像是水彩畫畫的不好暈開的那種感覺。
link |
接下來是兩萬次的結果。如果看右上角的話,剛才說兩隻眼睛顏色不一樣的圖片就是來自這個地方。最後就停在update五萬次的結果。
link |
有些角色其實已經畫得不錯了,但有一些其實也還頗失敗的,比如說這個我就不太清楚在畫什麼。這些角色一眼大一眼小,感覺有點奇怪。但是其實也有一些是畫得不錯的,比如說我覺得這個就畫得不錯,這個就畫得不錯。說是我畫的,你大概也信就是了。
link |
除了讓機器產生二次元人物的頭像以外,還可以讓它產生真人的頭像。有一個code叫做SLAB-A,裡面就是很多名人的頭像。你拿那些頭像給generator和discriminator讓他們去學,機器就可以產生真人的頭像。
link |
這邊這些頭像都是機器產生的,他們並不是某張名單,並不是某個真實人物的頭像,都是機器產生的。你們會問的問題是說,讓機器產生這些頭像有什麼用呢?基本上沒有什麼用。
link |
你想想看,你要真人的頭像,我去路邊拍不是更快嗎?讓機器產生有什麼意義呢?但是這邊一個有趣的地方是,機器其實可以產生你沒有見過的人物的頭像。
link |
而且今天光讓機器產生人物的頭像其實並沒有什麼特別厲害的地方,因為generator做的事情很有可能只是背了training data裡面某一張圖,你叫它產生一張圖的時候,它背了training data裡面某一張圖,再把它丟出來而已。
link |
那我直接寫一個程式去database裡面隨機產生一張圖,這樣做起來不是更快嗎?所以我們為了要考驗generator是不是背圖,你會叫它做一件事,叫它產生兩張圖片的interpolation。
link |
怎麼讓機器產生兩張圖片的interpolation呢?舉例來說,這上面的圖片是真實的例子,下面這個input就是隨便亂取的toy example,假設你輸入0.0的時候產生這張圖片,假設你輸入0.9、0.9的時候產生這張圖片。
link |
接下來你輸入0.0和0.9、0.9中間的各種不同的值的變化,你輸入0.0到0.9之間的interpolation,你就可以產生這兩張臉之間連續的變化的型態。
link |
本來這個人的嘴巴本來是很嚴肅的樣子,然後慢慢地他就笑了。或者是說,這個人本來他朝左邊看,這個人本來他朝右邊看,把他們做interpolate以後產生出來的圖片就是這樣。
link |
機器自己學到說,本來這個是向右邊看,那跟左邊看的圖片他們中間的連續變化形態是什麼樣子呢?是從右邊慢慢轉正,然後再慢慢轉左。機器並不是說,哦,有一個人臉朝左,有一個人臉朝右,他們把這兩張圖片interpolate起來,就把這兩張臉疊起來,像同時向左看向右看,像起伏一樣,就不是這個樣子。
link |
它自己知道說,人的臉,如果是向右看的臉和向左看的臉在做中間的interpolate的時候,其實是向前面看的。機器自動地學到了這件事情。你並不需要用handcrafted rule去告訴他這件事情,他很聰明地在看了很多圖片以後,generator就自己學到說,人臉的連續變化是什麼樣子。
link |
舉例來說,這個人是朝右看,這個人是正面,那就可以從朝右看慢慢地轉正。
link |
講到這邊,通常大家接下來要問的問題就是,GAN可以拿來做什麼?剛才舉的例子都是影像生成。好像除了影像生成以外,沒有太多其他的例子可以舉了。而且有人說,那GAN可以做什麼?也許可以用在擴增實境或者虛擬實境裡面吧。
link |
現在GAN產生的圖片又沒有那麼真實,還是很容易有擴增,所以用在擴增實境或虛擬實境裡面,好像還不夠好。
link |
有人會想說,我們用GAN來生成更多的training data,看看今天performance會不會比較好。我其實並沒有非常認同這個方向,因為本來你的training data就是這麼一點。
link |
假設我們現在要訓練一個分類器,分類碼和不是碼的圖片好了。你覺得你的碼的圖片很少,你的training data裡面所有的碼通通都是朝左邊看,那你訓練一個generator讓它產生更多的碼,它也只能產生向左看的碼。
link |
你給它的training data裡面的碼都是向左看的,那你用generator學出來以後,你也只能夠學到一樣的distribution而已,generator並不會產生非常完全不一樣的東西。
link |
與其用generator去生,你還不如自己去收集更多的image,也許還比較有效率一點。
link |
我覺得說用GAN來生成額外的圖片會有用的前提是,你必須加入額外的資訊。如果你只是拿一些training data,然後再生出更多的data,我並不覺得這一招會有用。
link |
我認為你要讓GAN產生更多的data有用的前提是,你要加入額外的資訊。舉例來說,舉剛才那個碼的例子,假設你training data裡面所有的碼都是朝左看的,但是你有另外一堆data,你有另外一堆,比如說斑馬的圖。
link |
斑馬有一些是朝右看的,然後你用之後我們會介紹的cycle GAN的技術,把那些斑馬的圖片轉成一般的碼的圖片,你有向左看的碼,你有向右看的碼,這個時候拿去做training,我就相信是有幫助的。
link |
但是這邊我們又會引入額外的資訊,就是斑馬的資訊,告訴機器說,哦,碼跟斑馬其實長得非常像,只是顏色不一樣,那我多了這些斑馬的外型,然後讓機器去學得更多。這樣我就相信是會有用的。
link |
另外一個可能會有用的case是,你今天的classifier,它是那種不具有generalize能力的classifier,比如說它是那種nearest neighbor base的classifier,那nearest neighbor base的classifier它沒有generalize的能力,它會希望說所有的各式各樣的example它都必須要看過。
link |
如果在這個case的話,你用這個generator產生更多的圖片,可能會是有用的。如果你今天的classifier是nearest neighbor,那你用generator生成更多的圖片可能是沒有用的,因為generator雖然它可能也有generalize的能力,但是你的classifier它其實也有generalize的能力,那你用generator來產生更多不同的圖片不見得有什麼樣的好處。
link |
因為訓練generator其實是比訓練classifier更困難的,你還不如直接訓練一個deep learning base的classifier。但假設你今天因為某種原因,你的classifier它不是一個deep learning base的,它是比如說nearest neighbor base的,那用generator產生更多的example也許就會是有幫助的。
link |
那我今天要講一下,我認為這個GAN可以用在什麼樣的地方。那我認為GAN其實是一種新的structure learning的方法。那structure learning是什麼呢?我們知道說在machine learning裡面,我們要machine做的事情就是找一個function,那input是x domain的東西,output是y domain的東西。
link |
那隨著output的這個domain不同,我們把machine learning的問題分成不同的path。舉例來說,當我們說regression的時候,我們的意思是說machine的output是一個數值,這個叫做regression,比如說預測某段時間以後的pm2.5,這個是一個regression的問題。
link |
那還有分類的問題。那在分類的問題裡面,機器要輸出的就是一個類別,假設現在世界上就有三個類別,機器就是要從三個類別裡面選出它覺得正確的那一個。
link |
但是在除了regression和classification之外,還有另外一系列的問題,我們稱之為structure learning或structure prediction的問題。在這類問題裡面,我們要機器輸出的東西是一個有複雜結構的object。
link |
舉例來說,我們要機器輸出一個sequence,當然sequence就是由一個component排起來變成一個sequence,或者是我們要機器輸出一個metric,或者是我們要機器輸出一個graph,或者是我們要機器輸出一個tree。
link |
那我們要機器輸出的是一個很複雜的object,這個object是由很多component組合而成的,有很多component用正確的方式組合而成的,那這個東西,這種任務叫做structure learning或者是structure prediction。
link |
那通常在一般的machine learning的課程裡面,通常我們只會教regression跟classification,甚至有的machine learning的教科書告訴你說,machine learning的問題就分成兩種,regression的問題跟classification的問題。
link |
這就好像告訴你說,這個世界其實就是五大洲,但是我們知道這個世界不是只有五大洲而已,在五大洲之外還有一個很大的黑暗大陸,這個就是structure learning。
link |
那gain是一種structure learning的新的演算法,它就像是打開新世界的大門一樣,就像是新世界的引路人一樣,雖然我現在也還不知道引路人是什麼,你們也不知道引路人是什麼對不對,它是一種雅人種,我現在知道的情報只有這麼多。
link |
所以gain就是一個新的,我把它看作是一個新的structure learning的algorithm。
link |
那structure learning可以用在什麼樣的地方呢?講到structure learning,它的應用就滿坑滿谷了,就不會只侷限在以下的生成上,它的應用是滿坑滿谷的。舉例來說,機器翻譯是一種structure learning的問題,你的輸出是一個sequence,已經有人用gain來做出更好的翻譯,這個已經有了。
link |
語音辨識輸入一段時間訊號,輸出就是語音辨識的結果,它也是一串文字,我倒是還沒有看過有人把gain用在語音辨識上面。
link |
那chatbot也是一個structure learning的問題,輸入是使用者的說的話,輸出是使用者的回應,這個當然也是一個structure learning的問題,把gain用在chatbot上面,其實已經不是一個特別新的事情了。
link |
那剛才講的都是輸出一個sequence,輸出一段文字,那也可以讓機器輸出一個matrix,也就是輸出一張影像。那什麼時候我們會用到讓機器輸出一張影像呢?
link |
舉例來說,你可以設計一個系統,這個系統的輸入是簡單的幾何圖案,輸出就是真實的照片。那假設你就胡亂把這些幾何圖案排一排就可以產生這棟房子的話,這個應該對房屋的設計師是很有幫助的。
link |
或者是你可以讓機器幫你上色,本來是黑白的圖片,那機器自動幫你把顏色塗上去,這個是機器塗上去的結果,這個圖片都是來自於以下這個文件。
link |
雖然實際上真實的世界長得是這個樣子,這些瓶子其實是綠的而不是紅的,但是告訴你說這張圖片就是真實的世界,你其實也相信就是了。
link |
或者是可以讓機器根據文字的敘述產生圖片,你告訴機器說畫一些白色的花,它就畫出一堆白色的花,這個就是我們作業要大家做的事情,就是根據文字敘述產生二次元人物的頭像。
link |
這個也都是文件上有的結果。甚至這個decision的making或者是machine的control也是跟structure learning有關係的。
link |
舉例來說,在作業三裡面,我們都知道說在作業三裡面要做的事情就是讓機器玩一個遊戲。
link |
機器要做的事情簡單來說就是看到一張圖片,然後看到一個畫面,它決定它要做什麼事情,比如說向右,看到下一張圖片,它決定要開火,再看到下一張圖片,它決定要向左等等。
link |
這一連串的action,它們並不是獨立的,所有的action之間是環環相扣的。之所以在這邊要向右,是為了要瞄準在下一個階段才能夠開火。所以每一個action,它們並不是獨立的,它們是環環相扣的。
link |
你可以把所有的action接起來,就當作是一個整體來看待。如果把所有的action接起來,它其實就是一個sequence。
link |
所以今天這個decision making這樣的problem也可以視作是一個structured learning的problem。我們之前有講說,這一類的問題,你是用reinforcement learning來解。既然這類的問題又是structured learning的problem,你可以把game的概念引入進去。所以其實game跟reinforcement learning是非常有關係的,這個我們之後再繼續跟大家詳談。
link |
那為什麼structured learning是一個有趣或者是有挑戰性的問題呢?我覺得第一個理由是,它是一個one-shot或者是zero-shot learning的problem。我們知道說在分類的問題裡面,我們會給每一個class一些example。
link |
你要分類貓和狗,就給機器看一百張貓、一百張狗,然後希望它可以分類。但是在structured learning的這樣的問題裡面,如果我們把每一個機器可能的輸出當作是一個類別的話,今天在structured learning的問題裡面,你的類別是無法窮舉的。
link |
假設我們今天要做的問題是翻譯,你把所有機器可能的翻譯的結果,通通都視為是一個class。你把所有的詞彙的各種排列的組合,通通都視為是一個class。那這個class是無窮無盡的,你根本沒有辦法數出這些class有多少。
link |
所以在training的時候,你根本沒有辦法給機器每一個class都有一些example,多數的class都是沒有example的。你在testing裡面會出現的class,在training的時候,機器是從來沒有看過這些class的。
link |
如果講得更具體一點,舉例來說,假設我們現在要做的是語音辨識的問題,我們把所有機器可能的輸出都當作是一個class。比如說,你好是一個class,大家好是一個class,今天天氣很好也是一個class。那這個class是無窮無盡的。
link |
在testing的時候,你可能遇到一句話是,今天天氣其實很好。我們今天假設在testing的時候出現一個句子是,今天天氣很不好。然後在training裡面,只有今天天氣很好,沒有今天天氣很不好。那等於是在testing的時候出現一個你從來沒有看過的class。對機器來說,它是從來沒有看過這個class的,所以這是一個one-shot或zero-shot learning的問題。
link |
one-shot或zero-shot learning的意思就是說,某一些class,它的training data很少,只有一個,或者甚至是沒有。所以structured learning,它可以看作是一種one-shot或zero-shot learning的problem。
link |
那如果要講得比較用農場文的風格來講的話,你就會說,在分類的問題裡面,機器做的事情就是歸納。每一個class都給你一些example,然後機器去學習歸納出它們中間的共通性。
link |
那在structured learning裡面,機器就不只是做歸納了,它做的事情是創造。因為今天機器要面對的class是它從來沒有看過的,所以它顯然是有比較高的智慧,它不是只有歸納,它還能夠學會創造,它才能夠解structured learning的problem。
link |
另外一個structured learning比較有挑戰性的地方就是,在做structured learning的時候,機器必須學會有規劃的概念,它必須學會有大局觀。為什麼呢?
link |
因為今天如果你要讓機器產生一個句子或者是產生一張圖片,機器在生成的時候,它是component by component生成的。你要機器產生一個句子,它就是一個一個詞彙的產生。你要機器產生一張image,它就是一個一個pixel的把顏色塗上去。
link |
但是機器雖然說它在做的時候,一次只做一件事,一次只產生一個word,一次只產生一個pixel,但是它最後的目標是要產生一個完整的人看得懂的句子,產生一張完整的人看得懂的圖片。
link |
所以機器在產生每一個component的時候,它必須在心裡有一個整體的佈局,我到底total要畫什麼,當我點下這個顏色的時候,整張圖片我到底希望它看起來是什麼樣子。機器必須要有這樣的能力,它才能夠解structured learning的問題。
link |
舉例來說,以影像生成為例,現在機器叫它寫一個數字,這個是一個空白的畫布,然後機器一開始在上面就點了一點。那你說機器點一點到底做得好還是不好呢?只點一點的時候,你是看不出來的。
link |
如果今天機器最後畫出來的數字是這個樣子,那是好的結果。如果最後畫出來的數字是這樣子,那就是一個失敗的結果。所以並不是點一個點在這邊,並沒有好壞的區別,而是最後整體看起來它是好的還是不好的。
link |
這邊再舉另外一個例子,這個例子我們就當作是季小蘭的故事好了。有一次季小蘭要去為上書的老婆祝壽,然後大家叫她寫一首詩,她就提筆寫下第一句是,這個婆娘不是人,旁邊的人就發火了,要把她打死。
link |
然後她說,我還沒有寫完,下一句是,九天玄女下凡塵,然後大家就高興了。所以今天當我們看一首詩的時候,只看這個詩的某一個詞彙或者是某一句,我們並不會知道說它是不是一首好詩。要把整首詩都產生完以後,我們才知道說它是不是一首好詩。
link |
所以季小蘭雖然可能一開始只寫第一句,但她心裡已經計劃好說,她其實要寫第二句。
link |
過去在structured learning的領域有兩套不同的解法。一套解法是bottom-up的,也就是機器每次都學習去產生,它的工作就是每次產生一個object。但是這樣子的壞處就是機器會失去大局觀,它每次都只點一個顏色,等一下會忘記整張圖片要產生出來是什麼樣子了。
link |
這樣就可能會產生出很模糊的圖片,或者是好幾隻眼睛的圖片等等。
link |
有另外一個系列的方法是top-down的方法。在top-down的方法裡面,機器是看一個完整的object,然後去評估說這個object到底是好還是不好。光看top-down的方法,你可能很難想像說怎麼使用top-down的方法去產生一個object,因為機器在top-down的方法裡面,它好像只學會了評估一個東西。
link |
就好像說,你畫一張圖給它,它可以評估說這張圖好不好,但它不知道要怎麼畫一張圖。這個等一下我會講說,在top-down的方法裡面,機器是怎麼產生一張圖片的。
link |
在game裡面,其實generator就是bottom-up的方法,discriminator就是top-down的方法。兩者合起來,結成不斷以後,它就是generative adversarial network。 接下來我就要講說,為什麼generative adversarial network可以被視為是一個structured learning的問題。
link |
我知道說,如果你看原始的Ian Goodfell的paper,我相信大家都已經看了滿坑滿谷的game的paper了。我知道說有另一套講法,另外一套講法我們會在下一堂課的時候跟大家說明。
link |
下一堂課的規劃,大家知道嗎?現在狀況是這個樣子的,因為我禮拜一不在,所以禮拜一就是請作業一和作業二前幾名的同學來分享他們的成果。
link |
剩下的時間會播放上學期的錄影,那就是講game的理論的部分,然後跟今天講的東西是完全不一樣的,另外一套講法。我也要讓禮拜一的內容跟禮拜四的內容一樣,所以禮拜四雖然我會來,但我們就做一模一樣的事情,然後我就坐在最後面聽自己講。
link |
好,那今天要講的就是跟下週你要聽到的是一個截然不同的講法,就是我要告訴大家說,我覺得game就是一種structured learning的algorithm。
link |
好,那現在到目前為止,我們都只會講生成,那所謂的生成的意思是說,這邊只是複習一下我剛才講過的東西,給generator一個input,一個vector,然後它就產生一張圖片,如果你是要做圖片生成的話。
link |
那通常這個vector會是從一個比如說normal distribution裡面做sample,sample出一個vector,sample一個vector就產生一張圖片,sample一個vector就產生一張圖片。那如果你要產生句子的話,也是一模一樣的,只是這個當然你的generator架構可能會不太一樣,但是大方向來說是一樣的,都是輸入一個vector,輸出一個句子,輸入一個vector,輸出一個句子,輸入一個vector,輸出一個句子。
link |
那你可能會說這個隨機產生一些句子,隨機產生一些圖片有什麼用呢?基本上沒有什麼用,光做generation這件事我覺得用處不大,真正可以用application的,我覺得是conditional的generation,讓機器根據不同的情境產生不同的輸出。
link |
講到這邊不知道大家有沒有什麼問題要問的呢?有嗎?好像有點可憐,請說,請說。
link |
主持人問,為什麼用input的noise通常要幾個以內的?這個問題就跟其他的問題一樣,就是never要幾層是一樣的,這個東西你必須要自己設,但是你當然還是可以有一些general的想法,舉例來說,為什麼?
link |
假設你今天input的東西是十維,假設你input的是十維,那你通過這個generator以後,假設這件事你要產生的東西是圖片,那圖片當然是一個,如果你用這個vector來表示它的話,它當然不只十維,它那個圖片是很大張的。
link |
就算是at least的二八乘二八也是七百多維的,但是因為你輸入的東西是在一個十維的space上做sample,所以你把它投影到那個高維以後,投影到那個七百維的空間以後,它是一個七百維空間裡面十維的低維的manifold。
link |
那假設你設十維,就意味著說你相信說你現在要產生的圖片,它是高維空間裡面的那個十維的manifold,這樣你可以了解我的意思嗎?
link |
就好像是說,現在假設我們有一個generator,然後它輸入就是一維的東西,但是你希望它輸出是二維的東西,那因為你輸入都是一維的東西,雖然你把它變成二維的東西,它可以展開在一個平面上,但是你會發現說你點出來的這個,你sample出來的結果,它在這個二維的空間中,它就是一條線而已。
link |
那所以如果你設定你的音符是一維的話,意味著你相信說你要產生出來的東西,它在這個二維的空間中,它其實就是一條線而已,但這個通常是我們想要的結果,因為我通常假設說,比如說我今天要產生圖片的時候,這些圖片應該是在高維空間中的一個一維的manifold這樣,
link |
因為在高維的空間中,你隨便sample一個字出來,sample一個西班牙文,它通常都不是一個圖片,只有非常少量的sample,它是一個圖片。所以我相信說,你要產生的這個像是人畫的圖片,它是高維空間中的一個低維的manifold,所以我們會設定這個input的dimension是比較低的維度。
link |
但至於到底要多少,這個就取決於你的直覺,你相信說那個圖片在高維空間中會不是幾維的這樣。
link |
現在用這樣回答到你的問題,那如果是用output同樣的維度,如果跟output是同一個維度,那會最好,因為它應該包含比較簡單的狀況。
link |
就你input和output的維度一樣,本來input是normal的distribution,你把它轉成另外一個distribution,你這樣也辦得到。
link |
但是我覺得如果這樣做的話,我沒有試過結果會怎樣,但是我直覺覺得會有一些問題,因為一開始這邊我們要output的東西,它就不是散佈在這個空間裡面。
link |
假設input是700維,它的output其實還是可以變成manifold,它還是可以從manifold變成manifold,所以你這問題問得很好,我其實不知道input跟output的維度會一樣,到底會發生什麼事情。
link |
那不然你作業的時候試一下再告訴我好了,看能不能做得起來。我倒是從來沒有試過也從來沒有看別人做過input和output的維度。
link |
我其實沒有試過說如果我再產生圖片,一個100x100的圖片10000維,如果input也是10000維的高潛,到底做不做得起來。你試起來再跟我講一下,做不做得起來。
link |
我們接下來要回答的就是這兩個問題,為什麼generator不能自己學呢?事實上generator是可以自己學的,你想想看我們現在的目標是什麼。
link |
我們的目標是generator看一個vector輸出一張圖片,看另外一個vector輸出另外一張圖片,再看一個vector輸出另外一張圖片,我這邊用code來表示,在code跟vector指的是一樣的東西。
link |
如果我們要訓練這樣的generator,neural network大家都很熟,你只要給他input output gradient descent確認下去,就可以確認出那個network了。所以我們現在需要的就是input跟output,但是實作上我們只有output,因為我們可以收集到大量的圖片。
link |
但我們不知道說哪一個vector才能夠對應到哪一張圖片,那怎麼辦?我們先假設我們有辦法自己生,我們就給每一張圖片給他賦予一個vector。
link |
接下來就結束了,這是一般的training network的方法,你拿一個generator出來,這是你要train的東西,我們知道說input 0.1 0.9要產生這張圖片,你就把0.1 0.9丟進去,讓他產生這張圖片,希望他的輸出跟他的目標越接近越好,然後train下去就結束了。
link |
這個跟其他分類的問題其實也沒有什麼太大的不同,只是輸入輸出變了。現在是輸入一個低維度的東西輸出一個高維度的東西,一般在分類的時候是輸入一個高維度的東西輸出一個低維度的東西。
link |
你會希望說通常輸出就是你的class,那你會希望說他跟你的目標,你會算這個cross entropy,希望他們兩個中間的cross entropy越小越好。那這樣好像就沒有問題了,接下來剩下的問題只有怎麼給每一張圖片一個編號,怎麼給每一張圖片一個對應的vector。
link |
怎麼給每一張圖片一個對應的vector呢?我們可以認一個autoencoder,那等一下假設有人不太清楚什麼是autoencoder的話,我會用幾張圖片快速地帶過什麼是autoencoder。
link |
你就認一個autoencoder,把encoder拿出來,那encoder做的事情就是會對輸入的圖片做降維嘛,你就給他一張圖片,他就把它變成一個低維度的東西,那我就有每一張圖片的code了,接下來我再認一個generator,就結束了。
link |
那什麼是autoencoder呢?這個也許大家都已經耳熟能詳,不過我還是用幾頁投影片來跟大家秒說明一下。autoencoder是什麼?我們現在有一個encoder,他會把一張圖片變成code,有一個decoder,他會把一個code變成一張圖片。
link |
那這個encoder和decoder各自都沒辦法學,一定是要jointly learn,怎麼jointly learn呢?你把一張圖片丟進encoder,這encoder把它變成code,那decoder把這個code變成一張圖片。
link |
訓練的時候我們訓練的目標就是希望輸入的圖片,encoder和decoder合起來就是一個很大的network,encoder假設是5層,decoder是5層,合起來就是一個10層的network。你把這個9丟進這個10層的network,它輸出的這個9希望跟輸入的越接近越好,然後訓練下去,你就同時把encoder和decoder訓練出來了。
link |
這邊有沒有人想要問的,有沒有人有問題想要問的呢?好,沒有,大家都知道什麼是autoencoder,接下來我們就繼續講下去。
link |
我們剛才說,假設我們要把每一張圖片找到一個code,我們就是拿一個encoder出來,幫我們把每一張圖片都變成一個code。接下來我們有一個generator,他就是把那個code變回原來的圖片。那個generator的工作是把code變回原來的圖片,那不就跟decoder做的事情是一模一樣的嗎?
link |
所以我們其實只需要認一個autoencoder,我們就自動的得到了一個generator。其實autoencoder裡面的decoder就可以當作是我們想要的那個generator,他可以吃一個code,他可以輸出一張圖片。
link |
所以今天你認好一個autoencoder以後,你把decoder拿出來,他就是一個generator,給他一個code,他就可以輸出一張圖片。那這個結果做起來怎麼樣呢?
link |
以下是真正的結果。你可以認一個decoder,你就認一個autoencoder,他中間的code是兩維,把decoder拔出來,他是兩維的code,就可以產生一張圖片。那以下真正的結果你給他看,-1.50,他就產生0這個數字。
link |
你給他看1.50,我是用train在end list上,他就產生1這個數字。那如果你給他-1.5到1.5中間連續的變化,你給他在這個二維空間中連續的變化,你就可以看到這個首寫數的連續變化,從左邊本來都有圈圈,到右邊都沒有圈圈。
link |
然後由下到上的變化好像是角度的變化,本來是朝左看,朝左傾斜,變正,然後變成朝右傾斜。你其實可以輕易地在end list上得到類似這樣的結果。
link |
那有人可能會問一個問題說,假設現在我們的generator根據training data學到說,看到這個A這個vector,他就要產生向左斜的1,看到B這個vector,他就要產生向右斜的1。假設A跟向左斜的1,還有B跟向右斜的1,這樣的training data配合在training data裡面是有的,那機器就會學到這件事。
link |
但是可能A跟B的interpolation,A跟B的平均是training data裡面沒有的。A跟B的平均是training data裡面沒有的,當我們把它丟到generator裡面,我們就有點難想像說這個generator到底會產生什麼樣的結果。
link |
對不對?因為在training的時候,很多可能就overfit了,機器知道說,看到這個A就產生1,看到這個B就產生1。看到A加B,你可能希望它產生這兩張1的interpolation的結果,所以它可能是,本來這個是向左斜的1,這個是向右斜的1,A加B的平均丟進去以後應該產生正面的1,應該產生正向的1。
link |
但是通常事與願違,如果是你實際做一下的話,你A可以產生一個數字,B可以產生一個數字,兩者interpolation產生的根本就是noise。你可能只有training data裡面的那幾個vector是可以產生數字的。
link |
怎麼辦呢?有一套做法也許大家都知道,就是VAE。那VAE大家可能或多或少都知道,所以我們這邊就稍微講快一點。VAE就是有一個encoder,這個encoder一樣會產生一個code,但它同時會自己產生一組雜訊,然後把這個雜訊加到這個code上面。
link |
然後它把有雜訊的code丟給decoder,然後讓decoder去還原回原來的圖片。那在訓練的時候,你同樣是要minimize reconstruction error。
link |
所以今天當你用VAE的時候,你可以達到什麼樣的效果呢?本來如果沒有用VAE,你告訴機器就是說,看到這個點,你就生成數字1。但做VAE的時候,因為你會在這個code上面再加上noise,告訴機器說,有加noise的code也要產生數字1。
link |
所以機器不只學到說,看到這個點要產生數字1,看到這個點附近的區域也都應該要產生數字1。像你在做interpolate的時候,雖然interpolate的結果可能是機器沒有看過的,但它也會沒有那麼容易壞掉。
link |
然後在train的時候,除了加上reconstruction以外,另外一件做的事情是,你會對這個noise下一些constraint。因為如果你只是要minimize reconstruction error,因為noise是機器自己生成的,它生出來的noise就會是0,為了要讓reconstruction error最小,它就說它的noise是0,就結束了。
link |
所以你會強迫讓機器說,如果你的noise太小,會得到penalty。你要加上這一項,VAE才能夠把它train起來。現在看起來是沒有什麼問題,但是這整個process裡面少了什麼呢?我們來仔細想想看,到底會有可能有什麼樣的問題。
link |
你想想看這個generator,它在學習做生成這件事情的時候,它是怎麼學的?我們要minimize的對象是reconstruction error。我們在算reconstruction error的時候,我們就是把兩張image拿出來,這個是你的目標的image,這個是generator的output,或者是在autoencoder裡面,它是一個decoder的output。
link |
我們在學的時候,我們會希望generator的output跟它的目標越接近越好。但什麼叫做接近呢?我們的衡量方法就是,給兩張圖片,算一下它們pixelwise的L1node或者是L2node,你就把它們pixel by pixel的算它們之間的差異。
link |
如果今天機器可以完全地copy它的目標,今天你的generator的capacity夠大,它可以完全地複製你要它產生的對象,那聽起來好像沒有什麼問題。假設今天generator可以完全複製它要產生的對象,那其實就跟它要產生的對象一樣好,這樣聽起來好像沒有什麼太大的問題。
link |
但事實上我們並不會特別希望generator把目標的圖片就完全地背起來。假設今天generator能夠做的事情就是產生跟目標的圖片一模一樣的圖片的話,那其實這並不是我們要的,這沒有什麼特別厲害的地方,我們就把database裡面的圖片拿一張出來就好了,為什麼要generator產生跟database裡面一模一樣的圖片呢?
link |
所以通常我們會希望說generator又不要完全地copy我們的目標,犯一點小錯是可以接受的,犯一點小錯反而可以讓generator的輸出看起來更generalized,它可以產生更多樣的輸出。
link |
但是假設犯一點小錯是可以容許的話,那這個錯出現在哪裡就會變得非常的重要,而原來pixelwise的evaluation並沒有辦法反映今天一個錯誤它到底是一個很嚴重的錯誤還是一個沒有問題的錯誤。
link |
舉例來說,現在假設你的目標是這個樣子,有不同的generator,有的generator產生出來的2長得是這個樣子,它在右上角這邊多點了一個點,它有一個pixel的錯誤,這邊少點了一個點,它也是一個pixel的錯誤,而這邊多點了六個點,所以它有六個pixel的錯誤,這邊也多點了六個點,它也有六個pixel的錯誤。
link |
所以如果今天用pixelwise的衡量方法,用你一般在train autoencoder的衡量方法的話,你就會覺得說,這對autoencoder的學習過程來說,這兩個是不好的,這兩個是好的。
link |
但這個encoder decoder在學的時候,當然會盡量希望產生比較好的結果,因為我們要minimize loss嘛,你的loss的定義就是看你有幾個pixel的錯,所以今天在學的時候,network就會反而會盡量傾向於產生這種error比較少的結果。
link |
但這些error比較少的結果,用人來看,上面兩個是你覺得不行的,下面兩個其實是可以的,結果反而是今天loss比較大的generator,它產生出來的圖片,反而是你比較能夠接受的,這樣就變得非常的奇怪。
link |
而且今天另外一個重要的點是說,今天一個產生出來的結果它到底好還是不好,其實並不是因為說在這邊點了一個點,所以產生的結果就是不好的,而是今天在產生一個圖片的時候,pixel和pixel之間的correlation是非常重要的。
link |
如果你要在這邊點一個點,那請把它的鄰居也都塗上顏色。如果只有這邊塗上顏色,它的鄰居沒有塗上顏色的話,那結果就是不行的。
link |
但是並不是因為在這邊塗一個顏色不行,而是如果你今天稍微改一下,把它的鄰居也都塗上顏色的話,結果又變得其實是可以的了。所以今天component和component之間的關係是很重要的,並不是某一個位置有塗色或沒塗色是錯的,而是說component和component之間的關係有沒有放對。
link |
但是我們知道說,假設你兜了一個network,在一個network的最後一個layer,我們其實不容易控制,假設我們今天有一個network,而network最後的輸出就是對應到一張圖片,這個network裡面的最後一個layer的每一個component就對應到圖片裡面的一個pixel,而它的輸出就代表那個pixel的顏色。
link |
但我們知道說,今天最後一個layer的輸出,每一個neuron的輸出,它們之間雖然說有一些correlation,但這個correlation並不是來自於之前一個hidden layer。
link |
今天假設你遇到的狀況是,某一個neuron它決定說,我要在這個地方塗上顏色,然後它希望說它的其他的鄰居也可以跟進,然後一樣塗上顏色,但是所有的neuron在生成的時候,所有這些neuron的output在生成的時候,它就depend on前一個hidden layer。
link |
given前一個hidden layer,這些neuron的輸出其實是獨立的,所以它的鄰居是不會管它了,它們就自己按照它們的weight來做自己的事情。
link |
如果你想想看其他的一些model,舉例來說CRF,那些graphical model,你其實可以在output的地方加上一些connection,就可以把這種relation的關係模擬進去。如果你熟悉CRF的話,比如像那種PC model,它們都會模擬pixel和pixel之間應該要有correlation。
link |
但是對neuron network來說,假設沒有前面的hidden layer,你就不太容易模擬component和component之間correlation的關係。其實neuron network也不是完全做得到這件事,它必須要憑藉著go deep來做到這件事。
link |
也就是你要model correlation的關係也可以,你要憑藉著你要前面的layer就做到這件事情。或者是,假設現在這個layer的output這邊是有圖色,這邊是沒圖色,你需要在下一個layer去把這樣子的錯誤更正回來。
link |
所以今天如果你要讓你的network能夠學到component和component產生出object的時候,它能夠把component和component之間的關係好好的model起來的話,其實你會需要比較deep的network。
link |
舉例來說,你在產生圖片的時候,甚至你可能會需要用到RNN。我們在產生圖片的時候,如果你不是用game的話,有另外一套方法就是用RNN去一個一個pixel的產生一個圖片。
link |
RNN其實就是一個非常深的、非常deep的network。大家熟悉RNN,RNN把它展開,就是一個非常deep的network。所以,今天如果你要modelcomponent和component之間的relation的話,通常就會需要比較deep的network才做得到。
link |
那我們知道說deep的network其實是比較難train成功的。以下是要舉一個VAE的core example,這邊我們想要做的事情是認一個generator,這個generator的input是二維,它的輸出也是二維,分別就是這個圖上的橫軸和縱軸。
link |
那我們現在generator學習的目標是希望學習這些藍色的點。這些藍色的點就是generator學習的目標。它在學習的時候,你就認一個variational的autoencoder,你就可以得到這樣子的generator。
link |
但你認完這個variational autoencoder,你會發現說,你其實很難讓generator的output去fit你的目標的那些綠色點。這個已經是我們實驗室的同學可以做出來,在這個core example上用VAE可以做出來最好的結果了,很難再做得更好。
link |
你會發現說,這個generator的輸出,它知道這邊有很多點,它知道這邊有很多點,它知道這邊有很多點,所以確實在這些mixer的地方,點的分佈的密度是特別高的。但是mixer和mixer之間,它還是會產生很多的點,還是會產生很多的點。
link |
這個感覺就是,它並沒有把component和component之間的correlation學得特別好。舉例來說,x1如果它有很大的值,那x2可以有很大的值,可以有很小的值,都是對的。
link |
但如果是中間的值,就不行。model好像沒有學到這件事,它還是會產生很多藍色的點在這個位置。
link |
這個講的是VAE的部分,也許我們休息十分鐘,等一下再回來。
link |
它既然一直批評,為什麼不自己做呢?其實discriminator只要它想的話,它是可以自己做的。我們再複習一下discriminator是什麼。
link |
discriminator它就是一個function,它就是一個network,那它可以是deep的,它的輸入是一個object,輸出是一個數值,代表這個object的好壞。
link |
那你其實可以把這個discriminator想成就是一個binary的classifier,它就告訴你說,給你一個object,它是屬於好的還是不好的。
link |
那我們知道binary classifier,它輸出並不完全是01 discrete的值,而是一個confidence,告訴我們說它是好的的程度有多好,它是壞的程度有多壞。
link |
那其實discriminator它在不同的文獻上其實有不同的名字,舉例來說,有時候我們叫它evaluation function,有時候叫它potential function,有時候叫它energy function。
link |
但這些function它們的作用,你在文獻上常常會看到這些function,這些function的作用你可以想成是跟discriminator是一樣的。
link |
那我們可以用discriminator來產生object嗎?是可以的,怎麼做呢?在講說怎麼做之前,也許我們可以看一下,如果引入discriminator有什麼樣的好處。
link |
我們剛才說對generator來說,在產生object的時候要考慮component和component之間的relation是比較難的,但對discriminator來說,給定一個object,它要知道說這個object裡面component和component間的關係有沒有對,其實倒是一件比較容易的事情。
link |
舉例來說,假設現在有一張圖片是有一個這樣子的單一的一個點,感覺是不好的,而這張圖片沒有單一個點,對discriminator來說,它要分辨這兩種圖片是非常容易的。
link |
當這兩張圖片已經被產生以後,丟到discriminator裡面,discriminator要給左邊這張圖片低分,給右邊這張圖片高分,是非常容易學到的。對network來說,你可以輕易地架構出這種network來學這件事。
link |
舉例來說,假設你的discriminator裡面有CNN的filter,那你給它一個CNN的filter,中間的地方是1,旁邊的地方可能都是-1等等,你就可以抓出這種pattern是否存在。
link |
接下來,discriminator其實可以知道說一張圖片是好的還是不好的,它可以知道說今天這個圖片裡面component的relation是好的還是不好的。
link |
那我們能不能夠用discriminator直接產生一個object呢?我們可以用discriminator直接產生一個object,怎麼做?
link |
這個process叫做input,既然discriminator給它一個object,它可以決定好或不好,我們就窮取所有可能的input,看哪個input可以得到好的分數,就當作是輸出就結束了。這樣大家聽得懂嗎?
link |
所以今天要用discriminator產生object的process就是argmax所有可能的x,假設現在是要產生圖片的話,就是所有可能的圖片,然後把它一個一個丟到discriminator裡面去,看誰分數最高,那我們就產生x2。
link |
那如果你說我不是只要產生一張圖片,我產生要產生一百張圖片,那沒關係,就取前一百名就行了。那你可能會覺得說這個很荒謬,因為我們必須要窮取所有的x,我們要窮取所有的x一個一個丟到dx裡面,這件事情到底能不能夠做到呢?
link |
我現在的說法就是先不要想那麼多,你就假設這件事情是可以做到的,我們假設窮取所有的x這件事情反正就是可以辦到,然後我們再講接下來的東西。
link |
現在假設你已經相信說discriminator就是可以拿來產生object,就是可以這麼做。接下來的問題就是怎麼認一個discriminator,怎麼讓discriminator學會判斷一個object的好壞呢?那你當然是需要給他一些training data告訴他說,這些object是好的,這些object是不好的。
link |
但是你想想看,實際上在training的時候,我們手上真正有的只有好的object。我們要讓機器學會畫二次元人物的圖片,我們的做法是,我們收集一大堆人手繪的圖片,漫畫家畫的圖片,這些圖片都是好的。
link |
所以今天我們手上的data其實只有好的圖片,沒有不好的圖片。那只有好的圖片能不能學呢?只有好的圖片其實是沒有辦法學的,因為如果你告訴機器說,我現在都是好的圖片,看到這張你要輸出1,看到這張你要輸出1,看到這張你要輸出1,看到這張你要輸出1,最後機器學到的就只有看到任何圖片通通都輸出1而已,所以這樣是不夠的。
link |
我們一定要有negative example,我們一定要告訴機器說,什麼圖片是好的,什麼圖片是不好的,我們才能夠認出一個discriminator。就好像說discriminator他是一個小孩,他本來在成長環境裡面,他身邊的通通都是好人,他長大以後就會相信說每個人都是好人。
link |
這樣是不行的,我們要給他看一些壞人例子,告訴他說這個世界上的壞人是長什麼樣子,他才能夠學會明辨是非。那怎麼給他產生一些negative example呢?但是怎麼產生negative example這件事情其實也是很重要的。
link |
你可以說,我隨機生一些很爛的圖片當作negative example,我就給他一些random noise當作是negative example,告訴他說這個圖片是好的,人手畫的是好的,random noise當然是不好的。
link |
但這樣子的結果就是,機器不會有辦法學得很好,因為對他來說,他學到的就是,哦,這個好,這個不好。那如果給他看這個,他可能覺得說,嗯,這個大概也不錯了吧,也給他0.9分。所以這樣子是沒有辦法學出好的discriminator的。
link |
我們要學出好的discriminator,我們給他的那個假的圖片一定要越真實越好,這樣他在學的時候才能夠分辨這種真的圖片和假的圖片之間最微細的差異。
link |
所以呢,我們會希望說我們的這些假的圖片最好是能夠以假亂真的。比如說我們給他這張圖片,告訴他說這張圖片是假的,你好好找找看說這張圖片裡面哪邊可能是造成不真實的元素。
link |
如果你可以給機器這種看起來非常可以以假亂真的假的圖片,但正好他是兩隻眼睛顏色不一樣,那這個discriminator他就可以學會說,好的圖片和不好的圖片的差別是眼睛的顏色必須要是一樣,他就可以學到這件事。
link |
如果一直給他random noise當作next example,他就學不到這一件事。那現在問題就來了,怎麼產生這種非常好的假的圖片呢?因為我們現在的目標就是要產生image,但是你如果說你又要產生這種可以以假亂真的image,這不是就是我們本來要做的事情嗎?
link |
這樣就變成是雞生蛋、蛋生雞的問題了。我們要訓練出一個好的discriminator,我們可以用discriminator來產生image,我們要產生好的discriminator,我們必須要有非常好的next example。
link |
但非常好的next example又必須藉助一個非常好的機制去產生出非常真實的圖片,我們才能夠得到非常好的next example。今天我們又需要有好的生成的機制才能夠產生這些next example,但我們又需要有next example才能夠訓練出discriminator產生好的生成的機制,所以今天就變成一個雞生蛋、蛋生雞的問題。
link |
所以怎麼辦呢?In general,其實這種trained discriminator的方法有滿坑滿谷,in general而言,那個方法就像以下說的這個樣子,但不同的演算法呢,它們是會有略微的不同,但基本上不脫以下這個架構。
link |
一開始,我們有一堆positive example,就是人手畫的圖片,有一堆next example是,你就當作是random的noise。好,那我們先訓練第一代的discriminator,第一代的discriminator他在學習的時候,我們是教他說,這些圖片是好的,這些圖片是不好的,那他要給左邊這些圖片一分,給右邊這些圖片零分。
link |
我們有了一個discriminator以後,我們說我們就可以用discriminator去做生成這一件事情,就是去解argmax這個problem,那你會說怎麼解argmax的problem,我不是講過你不要想那麼多這樣,你就假設這個東西是可以解的,這個東西它是可以解的,好,那這個東西假設它是可以解的,所以你就可以產生很多negative的example。
link |
那這些negative example會比這些圖片還要好,會比這個random noise還要好,舉例來說是這個樣子的圖。好,那這個discriminator給了我們很多negative example以後,你就把這些negative example拿去再重新訓練discriminator,現在discriminator看到negative example有更接近真實的圖片,那discriminator就會變得更強,他更知道說真實的圖片和機器產生的圖片到底中間有什麼樣的差異。
link |
那你在叫這個新的discriminator去做生成圖片的時候,他又可以生成更好的圖片,然後這個process就iterative的反覆的進行。好,這樣大家可以,這邊大家有問題嗎?
link |
好,所以就是iterative的,這個就是一個iterative process,先有一些negative example產生discriminator,discriminator產生negative example,再去update他自己,然後再產生negative example,就不斷的這樣子循環下去。
link |
那以下幾頁圖片是用圖示化的方法來解釋一下這整個process,我們有一個discriminator,那我們有一些real的positive example,那我們希望說呢,我們假設現在這個positive和negative example分佈的,他的分佈就是在一維的空間上。
link |
當然實際上的分佈呢,這些example他們如果是image的話,他的分佈是一個非常高的空間,我們現在就用一維來簡單的表示一下就好。
link |
好,那在這個區域,在這個positive example有出現的區域,當然我們希望discriminator的分數越高越好,但光只有做到這件事是不夠的,我們不可以告訴discriminator說,哦,這邊這個區域你分數越高越好就可以。
link |
因為搞不好discriminator他學到的就是,不管你輸入是在哪個區域,不管你是在這邊輸入,這邊輸入,還是這邊輸入,我都輸出一兆這樣子,那就會值很大,這不是我們要的。
link |
我們希望這個discriminator同時壓低positive example沒有出現的區域,就這個區域分數拉高,我們希望這個區域分數壓低,我們希望這個區域分數壓低。
link |
那在實作上我們會遇到的問題就是,我們無法窮舉所有的沒有positive example的區域,我們沒有辦法窮舉所有沒有positive example的區域,告訴他說,這邊通通要壓低,這邊通通要壓低,沒有辦法窮舉。
link |
所以我們希望用比較聰明的方法來找出需要壓低的區域,那怎麼做呢?這個process是這樣,一開始我們有一堆negative example,而這個藍色的點就代表negative example,然後這個綠色的點就是positive example。
link |
那我們train一個discriminator,那discriminator要給綠色的點高分,藍色的點低分,那你的discriminator train出來可能是這個樣子,他確實有給綠色的點高分,有給藍色的點低分,但這邊他不知道應該要怎麼辦,因為這邊你沒有給他example嘛,那他可能就隨便給他一些分數,甚至可能比positive example這邊的分數更高,也是有可能的,反正你並沒有給這個discriminator train高,他說這邊應該要給他多少分數。
link |
好,那你有了這樣子的一個discriminator以後,那你再用這個discriminator去做生成,我們說用discriminator去做generation的時候,用discriminator去產生negative example的時候,discriminator是怎麼做的呢,discriminator的做法就是看哪邊的值最高,他就生成落在那個位置的example,對不對,我們會窮舉所有可能的example,看看在哪個地方的值最高,我們就生成那邊的example。
link |
所以如果你窮舉所有可能的example,會發現說這個區域的值最高,所以你叫discriminator在生成一些negative example的時候,他生成出來的negative example可能就落在這個位置,然後接下來你就會去再訓練一個新的discriminator,那新的discriminator長什麼樣子呢,
link |
因為你告訴新的discriminator來說,這個地方是對的,這個地方是錯的,那他訓練的時候他就會知道說,這個地方應該給他高分,這個地方應該給他低分,那你可能說這個位置沒有點怎麼辦呢,這個位置沒有點怎麼辦呢,這就是有點麻煩的地方。
link |
不同的演算法會有不同的設計,去想辦法給這個區域讓他仍然能夠保持低的分數。舉例來說,你可以把過去所有的negative example統統keep起來,所以今天你在訓練新的discriminator的時候,並不是只有這個地方有positive example,這個地方有negative example,同學告訴他說,過去我們已經看過在這個地方有negative example,所以就不要再犯同樣的錯誤。
link |
所以他在學的時候,他知道說,只有這個地方是高分的,這個地方是低分的,這個地方也是低分的。或者是有另外一個做法,假設你覺得過去的negative example太多,你沒有辦法統統keep住,那你可以說,我把過去的discriminator的參數留下來。
link |
過去的discriminator可能是一個neural network,neural network一個好的地方就是它可以做transfer learning,你可以把一個neural的參數當作另外一個neural的參數的初始值。
link |
所以你可以說,我在訓練一個新的discriminator的時候,我把這個舊的discriminator的參數當作是它的初始值。舊的discriminator已經知道說,左邊這個地方就是要低分。它只是不太確定,右邊這個地方,因為之前你沒給它東西嘛,所以它其實也不太知道這邊要給它什麼樣的分數。
link |
但你已經知道說要給它,你這邊告訴它說,這邊也是negative的,那它可能就會把這邊的分數給壓下去,但這邊可能就不會升起來。當然要怎麼樣讓這邊不會升起來?你有沒有辦法保證它不會升起來就是了啦。
link |
但是你希望說,如果藉由這邊的參數,這個discriminator的參數是這個discriminator的參數的初始值的話,也許這邊就不會升起來。
link |
最後,你可能就會希望達到這樣的結果,你的這個discriminator所產生出來的example跟real的跟positive的example是正好重合的。你產生的next example跟positive example是重合的。
link |
這個時候,你的這個discriminator在同樣的區域向上和向下的力量就抵消了,那你的discriminator就不會再被update,你的discriminator的update就會停下來,你就沒有辦法再update這個discriminator,然後你這個training的process就停下來了。
link |
這個時候,你的next example就跟positive example一樣好,你的這個discriminator所產生的next example就跟positive example一樣好。這整個process,也許你聽了覺得很陌生,但實際上它並沒有你想像的那麼陌生。
link |
Structured learning並不是一個太新的名詞,過去已經有很多相關的模型。舉例來說,graphical model就是一種structured learning的模型。
link |
我們知道說graphical model有很多種,有Bayesian network,有Markov random field,Markov random field裡面也有非常多種。過去在機器學習、機器生存與結構化裡面,會花一半的時間講structured learning,也就是講這個圖上面的東西。
link |
但為什麼後來不講了呢?因為其實大家是不想聽的。舉例來說,這整個structured learning的process裡面,在剛才那整個framework裡面,有一件事我們始終沒有解決的就是怎麼解ARGmax的問題。
link |
其實同學很喜歡問我說,那怎麼解ARGmax的問題呢?我的答案就是,假裝這個是已經被解決了,這樣可以嗎?假設那個問題已經被解決了,你就可以證很多東西。你可以證說,如果我的discriminator它是linear的話,保證會收斂,然後可以證一下收斂的speed,就跟perceptron一樣。有一個技術就叫做structured perceptron。
link |
在假設那個問題可以解的狀況下,你通常會有很多好的性質。但問題就是,那個ARGmax的問題通常是沒有辦法解的,它只有在蠻有限的task下面是可以解的。
link |
In general而言,通常是不能解的,你只能做一些approximation來想辦法approximate那個solution。所以大家聽了都很生氣,後來大家都不來上課了,所以以後就很少講structured learning。
link |
但我知道說,其實graphical model這些東西對大家來說,其實你也不陌生,只是在不同的課上面,可能講法會略有不同。但是它的整個大的framework,跟我在前面那個投影片講的,其實是一樣的。
link |
如果你一下子沒有辦法心領神會的話也沒有關係,你就回去想想看,比如說如果你很熟悉CRF,你很熟悉Markov random field的話,回去想想看Markov random field的training process,跟前面講的那個iterative process,產生active example, update模型,它們之間有什麼樣的對應關係。
link |
你會發現說,其實我們只是把discriminator換一個別的名字,比如說換成叫做potential function而已。
link |
好,那我們來比較一下,講到這邊大家有沒有什麼問題想要問的呢?沒有嗎?那接下來我們來講一下這個generator,比較一下generator和discriminator它們的優劣。
link |
那generator它的優點就是,它可以deep,我們train autoencoder的時候,你那個encoder decoder都可以很deep了,那train下去,其實反正就規定design你要幾層就行了。
link |
那這個是它的優點,它的缺點呢,我們剛剛講過說,它的學習是表面的,它並沒有辦法真的學,它只能夠學到外型,它並沒有學到那個精神,對它來說要model component和component之間的correlation是比較困難的。
link |
那discriminator呢,discriminator是top-down的去evaluate一個object,但是有一個object以後,再top-down的去evaluate它,所以它比較能夠保有大局觀。
link |
但是它的壞處呢,它的壞處是,在做generator的時候,其實是很麻煩的,因為你要寫一個Argmax的花紋,如果你今天你的discriminator是一個deep的neural network,你通常想不出什麼好的solution,可以很快地解出那個Argmax的花紋。
link |
所以discriminator就好像是一個,在政治評論節目上有很多這種人,他其實可以給你建議很容易,他可以給你批評很容易,他可以說,給個有建設性的意見吧,他就很痛苦,他生不出有建設性的意見,他只能批評而已。
link |
那所以,那我們說現在最困難的地方就是要解一個Argmax的花紋,那我們要解那個Argmax的花紋,我們才能夠產生那個example,能夠產生那個example,整個用discriminator生成object的process,它才是可行的。
link |
好,那所以接下來呢,我們就是要把generator跟discriminator把它結合在一起,怎麼把它們結合在一起,結長補短呢?我剛才說對discriminator來說最痛苦的地方就是解Argmax的花紋,所以我們把解Argmax的花紋用generator來取代它。
link |
我們說,我們認了那個generator,它所產生的object,我們認一個generator,它會產生object x tilde,它產生的這個object x tilde,其實就是Argmax的這個problem的solution。這樣你可以接受嗎?這樣你可以接受嗎?
link |
我們講一個更具體一點,怎麼認一個generator,它的output就是Argmax這個problem的solution,但它可能沒有辦法找出exact的solution,但它至少是一個approximate的結果,怎麼做?
link |
我們有一個generator,它可能是一個neural network,input一個code,它就output一個我們要生成的object,舉例來說一張image。我們有一個discriminator,discriminator是固定好的,我們現在想要做的事情是,我們找到一張image,我們希望找一些image,這些image丟到discriminator裡面,它可以產生出來的output的數值越大越好。
link |
之前我們說我們要窮舉所有的image,我們之前說我們要窮舉所有的image,感覺是不知道要怎麼做。現在怎麼辦?我們希望用generator來產生這些image,我們希望訓練這個generator,讓它可以產生image,這些image是discriminator會給它高分的。
link |
所以怎麼做呢?其實這個做法就是,我們把這個generator跟discriminator串在一起,我們generator假設它是五層的network,discriminator也是五層的network,我們可以把這個五層的network跟這個五層的network就接在一起,變成我們有一個十層的network。
link |
這個十層的network它的輸入就是從一個normal distribution裡面sample出來的meta,它通過了這個generator,再通過了這個discriminator,它得到了一個數值。而在這個碩大無窮的network裡面,它有十層,它的第五個hidden layer的output,你可以把它解讀成是一張image。
link |
假設你今天要產生的image它的大小是一百乘一百,那這個generator的output對應的這個hidden layer,它的hidden layer的size就應該是一百乘一百。這樣大家了解我的意思嗎?
link |
你有一個巨大的network,把code丟進去,通過好幾層,比如說通過五層以後,你把中間的某一個hidden layer拿出來,那個hidden layer很大,它的大小就跟一個image一樣,這個hidden layer裡面的component的數目就跟這個hidden layer裡面的neuron的數目就跟一個image裡面的pixel的數目一樣多。
link |
把那個hidden layer裡面neuron的output通通拿出來,你就可以把它兜成一張圖片。那這個hidden layer的output要再繼續通過discriminator對應的那幾個hidden layer,最後會產生一個數值。
link |
假設你沒有問題的話,那我們說我們現在的訓練的目標就是希望discriminator最後的output越大越好。怎麼做這件事情呢?你就去調generator的參數,你就用gradient ascent去調generator的參數。
link |
雖然不是用gradient descent,因為我們其實是要讓output越大越好嘛,所以是用gradient ascent。不過這個gradient ascent就是gradient descent的相反啦,這個大家知道意思就好。
link |
所以呢,我們就去調這個generator的參數,希望它可以讓你的output越大越好。在這邊注意,我們必須要把discriminator所對應的那幾個hidden layer固定住。我們說我們現在要做的事情就是,我們希望這個generator它可以產生出它的output是discriminator會給它很大的數值的。
link |
我們希望這個generator它產生出來的output丟到discriminator以後,它會產生很大的數值。實際上辦到這件事情就是把generator和discriminator接在一起,然後說現在我們有一個巨大的network,它的最後幾個hidden layer對應到discriminator的參數就固定住。
link |
那我們要調這個input的前面這幾個layer的參數,希望最後的output值越大越好。那如果我們可以做到這件事情,那你最後再把這個generator拿出來,然後丟random vector給它,它產生出來的output就是可以讓discriminator給它高分的image。這樣大家可以接受這個想法嗎?
link |
好,如果你可以接受的話,那就進入了這個完整的Gantt實際的流程。假設你前面都沒聽懂的話,那就算了。我知道說這個可能跟你在文件上看到的是不太一樣的。如果前面你都聽不太懂,或你沒辦法接受的話,就算了。
link |
那我們現在正式講Gantt的algorithm。Gantt的整個algorithm是這樣子的。我們有一個generator,我們有一個discriminator,它們都是function,它們的輸入輸出我們之前都講過了。
link |
它們的參數是隨機的,一開始它們的參數是隨機的,所以很弱。我們用generator先來產生一些negative example,我們剛才說我們要用discriminator來產生negative example。
link |
discriminator要產生negative example,要解argmax的problem,我們說generator它的輸出就等於是argmax那個problem的solution,所以我們就不需要解argmax的problem了,把generator拿出來,讓generator去產生一些negative example。
link |
那我們接下來就去訓練discriminator,discriminator訓練的目標就是這些好的真人化的example都給它一分,壞的generator產生出來的negative example都給它零分。
link |
訓練好discriminator以後,我們有一個新的discriminator,但新的discriminator要解argmax的problem的話,當然solution是不一樣的,所以你要重新去訓練你的generator。
link |
我們重新去訓練這個generator,這個generator的目標我們剛才講過,就是它希望update這個generator的參數,這個generator會使得新的discriminator給它高分,有時候這個generator它的輸出就是argmax那個problem的solution。
link |
那你有了新的generator,你就可以得到新的negative example,你有了新的negative example,這個新的negative example也都給它零分,然後再去update你的discriminator,然後這個process就反覆的繼續下去。
link |
在前面這個部分,我們會得到一個discriminator,在後面這個部分,我們會得到一個generator。如果你沒有辦法接受這個想法的話,反正你就用那個typical的想法,就是有一個generator它就產生很多很爛的結果,
link |
然後discriminator會去抓說是real的example,還是generator所產生的example,然後接下來這個generator就想要去騙過discriminator,但是不是騙這個只是擬人化的講法,你也可以說generator是要讓discriminator高興,所以它產生了這個結果。
link |
那今天如果我們有了game以後,從discriminator的角度來看,我們就是有一個比較efficient的解argmax的problem,解argmax的problem用generator取代掉。
link |
那generator它要產生example,這很容易,就fee for work就好了,它遠比解argmax的problem容易。那從generator的角度而言,之前它的好壞是看L1-null,pixel-wise的L1-null或L2-null,如果你今天是訓練autoencoder的話,它的好壞是L1-null或L2-null。
link |
但現在一個generator的好壞不是L1-null或L2-null,它是看discriminator來決定它的好壞,discriminator決定了一個generator做得好還是不好。
link |
generator要做的事情並不是去向某一張圖片,而是要讓discriminator覺得高興。它並不是產生某一張database裡面有的圖片,而是希望它產生的圖片是discriminator可以給它高分。
link |
所以今天如果你是在game的process裡面,generator並不是去模仿database裡面的某一張圖片,它是想要去討好discriminator。
link |
所以它產生的圖片會比較多樣,而不是直接看起來像是從database裡面直接取一張圖片出來。
link |
好,那這邊是一個toy example來show一下這個game的performance。好,那現在跟剛才一樣,我們就是input一個二維的Gaussian的normal distribution,output是一個二維的vector。
link |
那今天只是,跟剛才那個VAE的例子是一模一樣的,只是換了顏色而已。機器今天要產生的目標是藍色的這些點。
link |
那如果你今天用game train下去以後,你會發現說確實多數的點都集中在藍色的區域,那只有少數的點沒有出現在藍色的區域。
link |
相較於剛才VAE的結果,game產生的結果,它是更貼近我們要它產生的distribution,它比較不會產生一些落在這些位置的東西。
link |
如果你比較這個VAE跟game的結果的話,你會發現說,這是文件上的結果,VAE產生的圖片通常是比較模糊的,而這個比較模糊的圖片就對應到出現在這個位置的圖片。
link |
那game產生的圖片通常是比較清晰的,因為它確實會落在我們想要它有的data distribution裡面,確實它的sample會跟原來的distribution是比較接近的。
link |
接下來我們要講的是conditional generation。剛才我們只講了讓機器隨機產生一些圖片,接下來我們要講的是讓機器根據我們所下的指令,根據我們給它的condition,產生對應的圖片。
link |
舉例來說,你畫一個紅頭髮的女孩,它就畫一個左眼的夏娜,畫一個有綁黃絲帶的女孩,它就畫一個涼宮春日。
link |
我們今天大概就來講不同的conditional generation的方法。首先我們剛才講說,其實input給generator的code就影響了generator的output,input的code的每一個dimension都有某些特殊的含義,對應到輸出的圖片的某些特質。
link |
但現在的問題就是,我們並不知道每一個dimension它對應到什麼樣的特質。那我們要怎麼把輸入的這個input的這個vector的每一個dimension跟它輸出的圖片的特質把它聯繫在一起呢?
link |
這邊假設的前提就是,每一張圖片都已經有attribute,就在training data裡面,每一張圖片都已經有標註說,這張圖片就是attractive,這張圖片它的特色就是黑頭髮等等。
link |
接下來我們要做的事情是,把這些敘述跟我們說的input generator的那個vector的每一個dimension把它聯繫起來。我們想要知道說,哪些dimension會造成產生的圖片黑頭髮。
link |
如果你知道這件事,之後你只要調那幾個dimension,就可以產生黑頭髮的人物,這是我們要做的事情。但現在遇到的第一個難題就是,我們並不知道這些圖片它對應的input的那個vector是什麼。
link |
對不對,就是給你一個generator,假設你已經訓練好一個generator,輸入一個從normal distribution sample出來的vector,它的輸出就是一張圖片,這個沒有問題。
link |
但現在的問題是,給你一張圖片,這些圖片是training database裡面有的,就training database你就收集一大堆圖片,那這些圖片也都有label它的attribute。但是你不知道說這些圖片,如果我們要用一個vector產生那些圖片的話,到底要用什麼樣的vector才能夠產生這些圖片。
link |
因為這些圖片並不是我們生成的啊,我們不知道哪些vector,這些圖片都是路上拍的,所以你也不知道說哪些vector可以產生這些人物的頭像。
link |
那怎麼辦?我們只有generator,我們只要generator看一個vector,就可以output一個人物的頭像。那我們想要認一個generator的inverse function,輸入一張圖片,輸入一個人物的頭像,它就產生一個vector,而這個vector可以產生一模一樣的人物的頭像。
link |
怎麼做?你就需要用到很類似autoencoder的概念。你就拿一張image x進來,然後通過一個encoder把它變成一個code,再通過你的generator,那generator是事先訓練好的,所以它的參數是固定的,然後再把它變成一張image。
link |
那你在訓練的時候,你只會去調這個encoder,你不會去調這個generator,你只調encoder,那希望輸入跟輸出越接近越好。
link |
你就固定住這個generator,那這個encoder你的參數可以用discriminator做initialize,不做也行啦,encoder的參數可以用discriminator做initialize,來input一個x,然後把它變成z,然後再把z變回原來的x,然後你去認這個encoder,如果你認好了以後,如果你可以確實把x變成z,再把z變成x,那這個encoder就可以幫你找出一張人物頭像,它對的code長什麼樣子。
link |
假設這件事情已經可以做到以後,你就把database裡面的每張人物頭像,它對應的vector通通找出來,然後你已經知道說這些圖片就是長髮的,它們對應的vector是藍色這些點,你把藍色這些點平均起來,你就得到一個長髮的vector。
link |
這些圖片都是短髮的,你把這些短髮的vector平均起來,你就得到一個短髮的vector。如果你今天想要把一個短髮的圖變成長髮的圖,你就知道說,你只要把vector從這個地方挪到這個地方,你就可以把一個短髮的圖變成長髮的圖。
link |
我們假設這個方向的這個vector,我們叫做Zlow,它代表的是一個長髮的向量。所以你就可以把一張短髮的圖變成長髮的圖,怎麼做?
link |
一張短髮的圖片進來,你通過一個encoder得到它的code,這邊寫成ENX,就是這個短髮圖片的code。你再把這個code加上這一個方向的vector,就有一張圖片,不管這張圖片位置在哪裡,都把它加上這個方向的vector。
link |
你把它加上Zlow,你得到一個Z',然後你再把Z'丟到generator裡面,讓它產生一張圖片,希望你產生出來的就是長髮的圖片了。
link |
以下有一個demo,這個demo應該是NVIDIA做的demo,他們就是做了一個你可以想成是智能的photoshop。這個智能的photoshop它右邊有一些旋鈕,你可以調一下這些旋鈕,就可以產生不同的圖片。
link |
你就可以把人都變禿頭,然後再變頭髮濃密,再變回來。
link |
都變黑頭髮,都變金頭髮,都變戴眼鏡,都變男的,反過來就都變女的,這都長鬍子。
link |
通通都笑了,都不笑了,通通變年輕,然後變attractive,變attractive就會變成是女的比較多,但是學出來就是這個樣子,也是沒有辦法。
link |
最後就調出一個作者心中覺得最完美的比例,這個demo就是這個樣子,你可以在youtube上面找到這個NVIDIA的demo。
link |
接下來就進入我們作業要大家做的事情。這個conditional game,我們現在要大家做的事情是輸入文字,產生對應的圖片。
link |
那今天要讓機器能夠做到輸入文字,產生對應的圖片,你必須要有一些label data,你必須要告訴機器說看到這張圖片就對應到a dog is running,看到這張圖片就對應到a bird is flying。
link |
接下來你任意的network,其實如果你只是要讓機器看文字,產生圖片,甚至你不需要用到game的概念,你可能也做得起來,你就訓練一個network,輸入是一段文字,輸出就是它對應的圖片。
link |
因為你現在有label data,你告訴機器說a dog is running就對應到這張圖片,所以你的network就是吃a dog is running,然後產生一張圖片,然後希望它的output跟這張狗在跑的圖片越接近越好。
link |
但這樣會產生什麼問題呢?一個常見的問題是,你產生的圖片會非常模糊,而一個可能的原因是,可能在你的training data裡面,以火車為例,可能有很多種不同的火車,有正心面的火車,有側面的火車,它們看起來非常不一樣。
link |
但在學的時候,每一台火車都是火車,所以告訴機器說,我輸入火車的時候,你要產生這一張,也要產生這一張,也要產生這一張,也要產生這三張,最後機器學到的就是產生這些圖片的平均。
link |
其實它產生出來的結果,像是這種火車也可以,像是正面火車也可以,產生側面火車也可以,但是如果要同時產生正面跟側面的火車,你就會產生奇奇怪怪的結果,那這個不是我們要的。
link |
機器不管是產生這種火車也可以、這種火車也可以,兩種一起產生,那其實就不是我們要的。所以我們今天要引入GAME的概念。當我們引入GAME的概念的時候,機器並不是去學某一張圖片,而是去跟著那個discriminator學。
link |
它跟著discriminator學的時候,它會學到說,它要嘛就是產生這種火車,要嘛就是產生這種火車,而不是產生這兩種類型的火車之間的平均。
link |
那我們看一下,如果要把GAME用在這邊的話,是怎麼用的。你有一個generator,那這個generator是一個conditional的generator,所以conditional generator的意思是說,它吃一個你給它的input,不是隨機的,你給它的一個input,然後它會產生一個對應的output。
link |
那今天在這個例子裡面就給它一段文字的敘述,讓它產生對應這個文字敘述的圖片。那有時候呢,你還會除了這個input的敘述以外,你還會多給它一個random的noise,你還會多給它一個從Gaussian distribution裡面sample出來的vector。
link |
那這樣做的好處就是,如果你加了這個vector,你每次輸入火車的時候,它輸出的結果都會不一樣,而它就會學到說,你輸入火車的時候,有時候它是產生這種火車,有時候它是產生這種火車,但它不會產生兩種火車的疊加,它會選一種火車來生成,那由這個prior的distribution來控制它產生什麼樣的火車。
link |
好,那接下來discriminator要怎麼設計呢?剛才在前面的lecture裡面呢,我們只講說,哦,discriminator就是輸入一張image,然後輸出就是,哦,這張圖好還是不好。
link |
那今天我們discriminator輸出的這個數值,它的意思就是告訴我們說,這張圖片有多麼的真實。那要訓練這種discriminator,我們就是要給它positive example真實的圖片,還有negative example,可能是generator產生出來的圖片。
link |
但是光這麼做是不夠的,為什麼?因為假設你的discriminator只會看generator的輸出,它就只會判斷說,一張image是好的還是不好的。
link |
所以學到最後你會發現說,generator就無視這個input的文字敘述,因為反正它只要讓discriminator高興就好,它只要discriminator覺得它畫得好就好,根本discriminator又不在乎說輸入的是什麼東西。
link |
所以generator就會不管你輸入什麼都無視它,不管你輸入什麼它都畫一隻貓出來,反正只要discriminator覺得那一隻貓畫得是好的就可以了,可是這個不是我們要的。
link |
所以今天在這種conditional game的case下面,我們的discriminator它的輸入不能夠只看generator的輸出,這個discriminator的輸入必須同時看generator的輸入與輸出。
link |
discriminator要同時看generator的輸入與輸出,discriminator同時看generator的輸入與輸出給它一個分數,這個分數其實代表了兩件事,這個分數同時去evaluate兩件事,一件事情是輸入的這張圖片有多真實,另外一件事情是輸入的這兩張圖片有多匹配。
link |
那要訓練這種,因為現在你的discriminator會看說這個generator的input跟output有沒有匹配,所以generator就不可以無視輸入的這個指令而畫一些不相干的東西,那要訓練出這種discriminator,當然你的positive example就是這個樣子,就是正確的圖片跟它是好的圖片對應它正確的敘述。
link |
但是你的negative example會有兩種,一種是你有文字敘述,但是你的圖片是generator所產生的圖片,另外一個case是你有文字敘述,但是也有好的圖片,但這個圖片是不匹配的圖片,你就輸入文字貓,但是給它一個火車,那這樣discriminator會學到說,這樣子的case是不匹配的。
link |
那它會學到說,這樣子的case,這個image可能是模糊的,也是應該要給它低分的case。所以在文線上呢,當你做conditional generator的時候,你會採取右邊這個做法。
link |
那以下是一些文線上的例子,告訴你說,現在如果做這種conditional generation,根據文字產生圖片,machine可以做到什麼樣的地步?這邊是叫機器畫一些白色的花瓣、黃色的花蕊畫出來,就像右邊這樣。
link |
讓機器畫一些有黃色的花心、紫色的花瓣的花畫出來,就像右邊這樣。畫一些有粉紅色的花瓣的花畫出來,就是這個樣子。
link |
當然你可能會懷疑說,機器會不會其實也沒什麼看懂文字敘述,也許它就是看到這段文字敘述,然後看看training database裡面有沒有一樣差不多類似的文字敘述,然後再把這些圖片丟出來就好了,也許它根本就只是做這件事。
link |
所以你要測試這種根據文字指令產生圖片的機械效能的時候,你要輸入那種很奇怪的文字的敘述,你要輸入那種現實生活中可能會沒有的東西。
link |
舉例來說,我試著輸入紅色的花,然後黑色的中心,那它畫出來的圖片就是這個樣子。那我猜training database裡面可能是沒有黑色的中心,我沒有仔細確認過,但是應該是不太可能有黑色中心的花瓣。
link |
但是它畫出來的確實就有黑色的中心跟紅色的花瓣,也可以產生更複雜的東西,這個也是文獻上的結果,你可以說一群人在打棒球,畫出來就是這樣,看起來像是棒球場一樣,或一群人去滑雪,看起來就是這樣,一群人有人在衝浪,看起來就是這樣,所以畫得還蠻好的。
link |
好,那這邊其實也應該要講一下,用剛才是輸入文字產生圖片,那一模一樣的技術,你也可以輸入圖片產生圖片,當然你用的network架構可能要略微修改就是了,本來輸入是文字,你可能會先用RNN去process那個文字,
link |
那現在輸入是圖片,你可能會先用convolution去處理這個圖片,但是就大的framework而言,整個train the process是一樣的,你就是有一個generator,輸入condition,輸出就是你要產生的結果。
link |
那在文件上可以看到說,把簡單的幾何圖形變成真實的圖片,黑白的圖片變彩色的圖片,下雪天變晚上,樹苗變真實的商品等等。
link |
那這個怎麼做呢?我們剛才講說,假設你有pair data,假設你已經告訴machine說,看到這個東西就要對應到這張圖,那你當然可以用一般的supervised learning的方法來解,輸入簡單的幾何圖形,它輸出的目標就是這張真實的圖片。
link |
但是如果你只有這樣做,在文件上看到的結果是這樣子的,你會產生模糊的圖片。我們之前有講過說,如果你說一般的supervised learning的方法沒有引入game的話,你產生的圖片通常是比較模糊的。
link |
那接下來呢,你可以把game引進來,那game引進來的時候,這個discriminator做的事情是什麼呢?我們剛才講說discriminator不可以只看generator的output,它要同時看generator的input和output,看看它們是否匹配,然後輸出一個值,代表說input這兩張圖片是否匹配,還有這張圖片它有多真實。
link |
那在文件上看到的結果,如果你用game的話,產生的結果是這個樣子的。那你會發現game它產生了一些不存在的東西。舉例來說,它產生了煙囪,原來圖片是沒有煙囪的,這個是game自己加上去的,因為你也沒有說它不能夠產生煙囪嘛,所以它自己產生了一個煙囪。
link |
那如果你希望game不要產生太多不合理的結果的話,你可以再下一個constraint說,generator可以產生image去討好discriminator,但是同時你又希望說它產生的這個image不要跟原來的圖片差太多,這樣你的generator就不會加上奇奇怪怪額外的東西,那你產生出來的結果呢,看起來就像是這個樣子,就沒有煙囪,然後這個房子看起來是蠻寫實的。
link |
那一模一樣的技術也可以用來做這個image的super resolution,那這些細節我想都不用再解釋了,那個generator輸入是模糊的圖片,輸出是清晰的圖片,就結束了,然後其他跟剛才講的是大同小異的,沒有必要再多做解釋。
link |
那最右邊這四張圖當然是蠻有名的啦,這個圖是原始的圖,這個圖是用傳統的方法做的,這個也是用傳統的方法做的,但是是有用到deep learning,你會發現這個方法它其實產生的圖片大致上是蠻清晰的,但是在一些細節的地方仍然沒有做得很好,比如說這個領口的花紋,還有帽子的花紋,是還沒有做得很好。
link |
而如果你用GAM的話,第三張圖片是用GAM做的,你會發現說領口的花紋還有帽子的花紋其實也是蠻清晰的,但如果你比較原始的圖片的話會發現說他們的花紋其實是不一樣的,而GAM它自己產生了自己的花紋。
link |
那同樣的技術也可以拿來做video的generation,那如果拿來做video generation看起來像是什麼樣子呢?你有一個generator,input就是影片的前半段,output就是predict,看到這個影片以後接下來應該產生什麼樣的畫面,當然這個generator的network架構你可能需要自己設計一下。
link |
那有一個discriminator,我們剛才講過discriminator它看的東西就是generator的input加output,所以把generator的input加output串起來變成一段完整的影片丟給discriminator看,那discriminator來判斷說根據這段影片的最後一個frame,它是真實的影片還是不是真實的影片。
link |
那這跟前面講的conditional的GAM其實都是一樣的,只是不同的application,你當然需要設計自己的network架構,但是整體而言大方向大的framework是一樣的。
link |
這個是我在網路上找到的結果,有人用GAM來生成小精靈,左邊是光tube,最右邊是沒有用GAM的結果,發現說沒有用GAM的一個問題就是,有些小精靈走著走著就分裂了。
link |
為什麼它會分裂呢?因為在training data裡面走到同一個轉角,有時候小精靈會往左走,有時候小精靈會往右走。
link |
如果你不用GAM的話,機器就會學到說,可以往左走也是對的,往右走也是對的,所以同時產生往左走和往右走的圖。那如果用GAM的話就比較不會這樣,它就比較不會分裂。
link |
只要用GAM,有時候也沒有辦法做到perfect,你會發現有些小精靈走著走著就不見了。另外有趣的是,你會發現它的數字會變,雖然說它的變化其實是隨機的。
link |
到目前為止我們舉的例子都是跟影像有關的,接下來我們舉一個跟語音有關的例子。GAM的技術不是只能夠用在影像而已,現在你看到的多數應用都是影像,只是因為影像走得比較快而已。
link |
其實GAM的技術,我們只要遇到生存的東西是有structure的,我相信都可以用到GAM的技術,不管是影像還是語音還是文字。這邊就舉一個語音的例子。
link |
你可以用GAM的技術把有雜訊的聲音變成沒有雜訊的聲音。當然你可以用麥克風陣列來解釋這個問題,但如果你沒有麥克風陣列的話,那你可以run一個network把有雜訊的聲音轉成沒有雜訊的聲音。
link |
怎麼做?你就需要一個generator,這個generator就是輸入有雜訊的聲音輸出是沒有雜訊的clean的speech。那怎麼訓練這樣的generator呢?你需要一個discriminator,這個generator輸出是沒有雜訊的discriminator,就是看一段有雜訊的聲音跟沒有雜訊的聲音的pair。
link |
discriminator一方面希望你產生出來的output是clean的,另外一方面他又希望你的輸入和輸出是匹配的,因為你不會希望你說I love you,然後結果generator產生出來算是clean的聲音變成I hate you這樣子,那這樣就很糟糕,你希望他們仍然是匹配的。
link |
你只要訓練一個discriminator,接下來其實你甚至network架構都不需要改太多,因為你可以把一個聲音的頻譜看作是一張圖片,你可以用很類似image processing的network架構就可以做這個問題,然後你就用剛才講過的framework train下去,你就可以解這樣子的問題了。