back to index
GAN Lecture 2 (2017): CycleGAN
link |
我也是蠻驚訝的,好,我們開始上課吧,那接下來呢,我們要講,呃,我們現在在講conditional的generation,那之前講的conditional generation是supervised的conditional generation,就跟大家在作業室做的一樣,那你需要有label data,舉例來說,在作業室裡面,我們是提供給你影像和文字的對應關係。
link |
接下來呢,我們要講unpaired conditional generation,什麼意思呢?在之前,在之前講的conditional generation,我們都有paired data,舉例來說,假設你現在的目標呢,我把我的滑鼠調出來啊,假設說你現在的目標是要從這種簡單的圖案轉成這種真實的圖片,
link |
那你就需要有這種,你就需要告訴我們訊說,看到這張圖案,就要輸出這個圖片,但是在很多時候,我們是沒有這種paired data,舉例來說,假設我們現在要做的precaution,是把一張真實的風景的照片轉成泛谷畫風的圖,我們可以收集到一堆真實的照片,
link |
我們也可以收集到一堆泛谷的圖,但是我們並沒有真實的照片和泛谷的圖之間的對應關係,甚至這種對應關係根本就不存在,隨便拿一張真實的圖片,你其實並沒有辦法找到一張泛谷的圖跟它是有對應關係的。
link |
所以怎麼辦?這邊有一個技術叫做Psychogame,那你可能會問說這個Discogame是什麼呢?其實Psychogame跟Discogame是一樣的東西,有不同的人在幾乎同樣的時間在archive上發表了一樣的技術。
link |
以下圖片是來自Psychogame那篇paper,在Psychogame那篇paper他們可以做到把斑馬轉成馬,把馬轉成斑馬,把夏天的圖轉成冬天的圖,把冬天的圖轉成夏天的圖。
link |
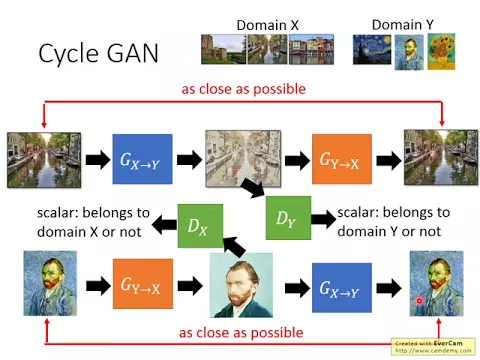
那Psychogame也是會失誤的,它會把人轉成斑馬人。那Psychogame要怎麼做呢?我們要做的事情就是把一個在DomainX的圖片轉成在DomainY的圖片。
link |
我們要把一個在DomainX的東西,這邊是真實的相片轉成DomainY的東西,這邊是犯規的圖。那你需要一個generation,你需要一個generator,你需要一個conditional的generator。
link |
這個conditional generator它的輸入就是DomainX裡面的一個object,它的輸出就是DomainY的object。
link |
那因為現在沒有label的data,在沒有label的情況下,我們要怎麼讓這個generator它的輸出是DomainY的object呢?
link |
我們就需要引入另外一個東西,就是discriminator,那這個discriminator的工作就是偵測一張圖片它是不是DomainY的圖片。
link |
在DomainY是犯規的話,它的工作就是偵測一張圖片看起來像不像是犯規的話,那你會提供給它很多真實犯規的圖片,
link |
讓這個DomainY的discriminator去學,它就會學到說什麼樣的圖片像是犯規畫的圖要給它高分,不像犯規畫的圖就給它低分。
link |
那這個generator要做的事情就是想辦法產生出圖片可以讓discriminator覺得它是高分的。
link |
這個跟game的概念,反正這個就是game的概念。
link |
但是光這樣做是不夠的,如果光這樣做會造成什麼問題呢?
link |
這樣做會造成的問題是說,今天generator為了要讓discriminator給它的輸出高分,它可能就會無視它的input。
link |
反正只要產生像犯規畫的圖就會得到高分,那我不如就畫一張從犯規畫過的圖裡面挑一張圖片出來作為生成。
link |
那discriminator覺得會高分,那這個conditional generator就會覺得它滿足它要做的事情,但它完全無視現在我們給它的condition,所以這不是我們要的。
link |
所以怎麼辦?在cycle game裡面加上了另外一個generator,這另外一個generator它是condition,我們剛才看到這個generator的輸出,而它是吃一張犯規的圖,然後把犯規的圖轉成真實的圖片。
link |
那在訓練的時候,我們會希望這兩個conditional generator它們齊心合力,使得input一張真實的圖片轉成犯規畫過的圖,犯規畫過的圖要被轉回真實的圖片,而這個輸入的真實圖片跟這個輸出的真實圖片,它們要越接近越好。
link |
舉例來說,你會minimize這個輸入和輸出的L1或L2的node,當然中間這個中間的產物它要像是一個犯規的圖,它要是discriminator給它高分的圖。
link |
而如果是這樣做的話,如果你加上了這個reconstruction mode的限制,那generator在生成犯規圖的時候它就不能隨便拿一張犯規圖來搶色,因為假設你今天不管輸入什麼input,generator的輸出都是這張犯規的自畫像,那後面的這個generator就沒有辦法把犯規的自畫像還原成原來的輸入。
link |
而這個cycle gap除了有上面這個cycle以外,它還有另外一個cycle,因為這個conditional generator它想要做的事情是把犯規的圖變成真實的圖片,但是它並沒有看過真正的犯規的圖,它看到的犯規的圖都是generator所產生的。
link |
如果只是這樣子的話,它可能沒有辦法做得很好,因為generator產生出來的犯規的圖也不見得真的很像犯規的圖。所以怎麼辦呢?在cycle gap裡面有另外一個path,你先把這個把y-domain轉x-domain,也就是犯規的圖轉真實圖片的generator拿出來,丟給它犯規的圖,然後希望它轉成真實的圖片。
link |
然後接下來呢,你再把另外一個generator拿過來,這個真實的圖片轉犯規的所謂generator拿過來,讓它是真實的圖片轉成犯規的圖。那一樣在訓練的時候,你會希望這個輸入跟這個輸出呢,它們越接近越好。
link |
那同時你也需要一個discriminator,這個discriminator的工作是偵測一張圖片是不是domain x的圖片,一張圖片是不是真實的圖片。那這個generator它需要產生出圖片是這個discriminator覺得是真實的圖片。
link |
所以整個CycleGAN的架構就是這個樣子。那在CycleGAN裡面呢,我們有兩個generator,兩個generator。要注意一下這個同樣顏色的這個橙色的generator和藍色的generator,它們就是同一個generator。
link |
所以你要想成說它們的參數是被排在一起的,雖然在這個圖片上畫了兩個block,但是並不是說有兩個generator,這兩個generator是同一個,這兩個generator是同一個,所以總共有兩個generator。那另外有兩個discriminator,一個discriminator負責偵測說一張圖片是不是犯規的圖,另外一個discriminator專門偵測說一張圖片是不是真實的圖片。
link |
所以在整個CycleGAN裡面有兩個generator,有兩個discriminator。那在整個訓練的過程中,這兩個generator要合力去minimize這個loss,然後要合力去minimize這個loss。
link |
同時他們也要想辦法讓這兩個discriminator給他高分,換句話說他們想要騙過這兩個discriminator,這個就是CycleGAN。
link |
其實像這種CycleGAN的這種或者是其他類似的方法有很多的應用,舉例來說我在網路上找到一個code是可以把世界動畫化的,不過他其實不是用CycleGAN或Discogan做的,我們今天就不講他是怎麼做的,所以現在世界如果你要做這種風格的轉換有很多不同的方法。
link |
這個code你直接載下去就可以跑了,原來說這邊有兩個死臭酸宅這樣子,那你就可以把死臭酸宅轉成萌妹子讓大家比較高興一點。
link |
但他其實也會犯錯的,舉例來說這個也是一個死臭酸宅,他轉完以後就變成這個樣子,他以為麥克風是萌發的一部分,所以整個轉完以後就壞掉這樣子,那你可能會說這個東西有什麼用,這個東西基本上沒有任何用處這樣子。
link |
就假設我也要拍線上課程的時候,我就可以用這個動畫的領域讓大家比較高興一點。
link |
接下來我想給大家看一個我覺得很潮的precaution,這個是用GAN來做智能的photoshop。
link |
接下來就是要講說剛才看那個很潮的demo是怎麼做的。
link |
這個是這樣子,首先假設你已經trained好一個Generated Adversarial Network,你已經trained好一個GAN,那這個GAN可以做的事情就是你input一個code,那他就會幫你產生一個東西。
link |
假設你現在訓練的圖片都是一些商品的圖片,那你input一個code就可以幫你產生商品。
link |
那在剛才看到的那個demo裡面是做了什麼樣的事情呢?有一張圖片進來,那基本的概念是這樣,有一張圖片進來,那先反推這張圖片他的code是長什麼樣子,如果你今天輸入這個code,他就可以產生這張圖片。
link |
被given的是圖片,所以要從圖片反推這個code。然後接下來使用者會下一個指令,舉例來說他用interface上面的toolkit,用這個筆刷在螢幕的中間刷了一下紅色的。
link |
那刷了一下紅色的以後,Machine會做什麼事情呢?Machine會做的事情是他去挪動這個code,使得說現在找到一個新的code,這個新的code產生出來的image一方面符合使用者下的這個指令,使用者要求說這個地方要是紅色的,那新的image他在這個地方確實是紅色的符合使用者的要求。
link |
但是同時另一方面你會不會希望說這兩個code越近越好。
link |
首先為什麼我們今天不是直接去更動這個image,而是在code space上面去修改這個code呢?如果你直接去更動image的話,這個結果其實可能不會是你想要的。
link |
你只要在level上,在image這個space上面把這兩張圖片夾起來,那你其實只是得到一個被弄髒的衣服而已,被油漆畫到一筆的衣服而已,這個不是你想要的。
link |
所以這邊如果你要達到剛才看到那個智能的波動效果的話,你必須要在code space上面去移動你的code,去產生新的圖片。因為今天在code space上面,假設你那個電測得夠好的話,在code space上面每一個vector丟到generator以後,它產生出來的都是一個好的image,都是一個真實的商品。
link |
所以今天如果你要sample一個code,它可以產生一張圖片是符合這個假設的,那你產生出來的會是一件完整的衣服,會是一件同樣顏色的衣服。
link |
假設你裡面的商品,這個衣服的顏色都是一樣的,不是有那種塗一筆畫把衣服弄髒的那一種,那你就會產生一個看起來比較像是真實商品的衣服。
link |
而在另外一方面,你會希望說這兩個code越近越好,之所以希望這兩個code不要差太遠的理由其實非常的直覺,因為你並不希望說本來有一件黑色的衣服,花一筆紅色又變成紅色的鞋子,所以你會希望說新的code跟舊的code越近越好。
link |
我們再看一下實作的一些細節,首先在這個process裡面,第一步是要給定一張圖片,反推它的code長什麼樣子。那要怎麼做到這件事情呢?在文獻上有不同的方法。
link |
舉例來說,假設這個黑色的衣服我們用XT來表示,那可以產生XT的code我們用Zstar來表示,怎麼找到這個Zstar呢?你可以列一個式子,這個式子是解一個optimization problem,你希望找到那個Zstar,那個Zstar有什麼樣的特性呢?
link |
它可以minimize這個式子,在這個式子裡面,G of Z代表說如果我把Z這個code丟到generator裡面,它會產生出來一個圖片,G of Z是一張圖片,那XT是我們目標的圖片,那我們希望G of Z跟XT它的距離越近越好,我們用L來define G of Z跟XT之間的距離。
link |
那至於要怎麼define這個距離,你可以有不同的做法。
link |
舉例來說,最直覺的做法是算G of Z這個image跟XT這兩張image它們pixelwise的difference,比如說它們L1的difference跟L2的difference,那如果你做得更好的話,你也可以說我拿一個已經train好的CNN出來,然後我把G of Z丟到CNN裡面,把XT也丟到CNN裡面,然後希望CNN的某個hidden layer的output越接近越好。
link |
那如果你用CNN來量距離而不是在pixel上面量距離,那你就比較能夠抓到那種concept的information,而不是很local的在pixel上面看兩張圖片像不像。
link |
那不管你這個difference怎麼定啦,你就是去找一個Z,它可以讓這兩張圖片越接近越好。
link |
那用的技術呢,就是Gradient Descent的技術就完了。
link |
好,然後呢,另外一個方法,這個方法我們其實之前有看過了,這個方法是這樣,假設你有一個generator,它可以把Z變成X,那就把這個generator固定好。
link |
接下來呢,你另一個encoder,這個encoder它學習的目標是,當把一張圖片X丟到encoder的時候,encoder會產生一個code Z,然後再把Z丟到generator,它會output一個image X。
link |
那encoder訓練的目標,就是希望輸入的這個X跟輸出的這個X越接近越好。
link |
那在訓練的時候,generator是固定的,只會調這個encoder,那如果encoder確實可以把X變成Z,Z丟到generator又可以還原成原來的X的話,那之後你把ST,右上角這個ST丟到encoder裡面,你就可以得到可以產生ST的這個Zstar。
link |
這是第二個方法,那第一個方法它的壞處是說,你今天每次進來一張image的時候,你都要去解一個gradient descent的problem,所以你每次一個新的image進來,你要花很多時間去跑很多的iteration,把這個optimization的problem解出來得到Zstar。
link |
那method2它的好處就是它是一個一勞永逸的方法,你在offline的時候先把這個encoder先想辦法訓練好,你把這個encoder訓練好以後,之後新的ST進來,你就把它丟進去,然後就可以得到輸出。
link |
那在那篇paper裡面,在我剛剛看到的demo裡面,在文獻上實際上是把method1和method2合在一起得到最後的結果,那怎麼把method1和method2合在一起呢?那其實也是非常的直覺,就是在method2你會得到一個encoder,那這個encoder可以把ST變成某一個Z。
link |
接下來,我們知道在做gradient descent的時候,你需要一個初始值,那你就把這個Z當作是你的初始值,你把這個encoder的output當作你的初始值,再去跑gradient descent。
link |
那因為你現在用這個encoder得到的output當作初始值,那你可能離optimize的結果已經非常的近了,那你就只需要比較少量的傳輸完備的次數,就可以找到Zstar。
link |
好,那最後這個相片是怎麼隨著使用者下的command來做修改呢?假設input一張image,我們已經找到它的code,這邊寫做Z0。
link |
那接下來呢,我們要去找另外一個code的Z,它是符合使用者下的這個contract,那怎麼做呢?這邊要寫一個optimization problem,這個G of Z是一張image,
link |
所以我們要找另外一個Z,這個Z丟到G這個function裡面,G of Z是一張image,這張image我們再丟到另外一個U這個function裡面,去check說這個image跟這個contract有沒有fulfill。
link |
那這個U這個function它的工作就是看說這張image它有沒有滿足使用者輸入的限制,有沒有滿足使用者輸入的指令。那至於怎麼樣叫做滿足使用者輸入的指令,那這個就是你自己定義的。
link |
所以這個U function長什麼樣子,是你自己定義的。但是光有這樣還不夠,同時呢,我們會希望說新找出來的Z跟原來的Z0,就是你輸入一張image,我們假設輸入一張image以後,它的code就是Z0。
link |
你會希望新找出來的Z,它跟Z0越接近越好,而你會希望說本來是一個鞋子,做一下anything以後它還是一個鞋子,本來是一個衣服,做一下anything以後它還是一件衣服。
link |
那在這個式子裡面它還有第三個式子,第三個式子是希望今天產生出來的圖片看起來是真實的,你並不希望說做完修改以後那個圖片就整個糊掉了,或變得鞋子變得歪七扭八了,這不是你要的。
link |
所以怎麼辦呢?把這個Z丟到generator裡面得到一個image,再把這個image,G of Z是一個image,把這個image丟到一個discriminator裡面,讓discriminator判斷說這張image是不是realistic的image。
link |
這樣就可以防止你找到一個Z,它產生出來的image其實是奇奇怪怪的image。
link |
不過據說在根據文件上的說法,最後一項其實有沒有都可以幫助不大,因為假設你也覺得ray tracing確認得非常好了,只要給它任何的Z,它的輸出都是好的圖片,那最後一項的幫助其實是沒有很大。
link |
總之今天要考慮三件事,一件事情是新找出來的圖片必須要符合使用者下的指令,同時新找出來的圖片跟舊的圖片不能相差太大,最後新找出來的圖片看起來仍然要是真實的。
link |
那這個就是剛才那個智能Photoshop的做法,講到這邊大家有沒有什麼問題要問的呢?如果沒有的話我們就進入下一個主題。